plato research dialogue system
1.0.0

هذا هو v0.3.1
يعد نظام الحوار Research Floro إطارًا مرنًا يمكن استخدامه لإنشاء وتدريب وتقييم وكلاء الذكاء الاصطناعي في بيئات مختلفة. وهو يدعم التفاعلات من خلال أعمال الكلام أو النص أو الحوار ويمكن لكل وكيل محادثة التفاعل مع البيانات أو المستخدمين البشريين أو عوامل المحادثة الأخرى (في إعداد متعدد الوكلاء). يمكن تدريب كل مكونات من كل وكيل بشكل مستقل عبر الإنترنت أو غير متصل بالإنترنت ، ويوفر أفلاطون طريقة سهلة للالتفاف حول أي نموذج موجود تقريبًا ، طالما تم الالتزام بواجهة أفلاطون.
اقتباسات النشر:
ألكساندروس بابانجيليس ، ماهدي نامازيفار ، تشاندرا خاتري ، يي تشيا وانغ ، بييرو مولينو ، وجوخان تور ، "نظام الحوار أفلاطون: منصة أبحاث محادثة مرنة" ، Arxiv preprint [Paper]
Alexandros Papangelis ، Yi-Chia Wang ، Piero Molino ، و Gokhan Tur ، "تدريب نموذج حوار متعدد الوكلاء التعاوني عبر التعلم التعزيز" ، Sigdial 2019 [Paper]
كتب أفلاطون العديد من الحوارات بين الشخصيات التي تجادل حول موضوع ما عن طريق طرح الأسئلة. تتميز العديد من هذه الحوارات سقراط بما في ذلك محاكمة سقراط. (تمت تبرئة سقراط في محاكمة جديدة عقدت في أثينا ، اليونان في 25 مايو 2012).
V0.2 : التحديث الرئيسي من V0.1 هو أن أفلاطون RDS يتم توفيره الآن كحزمة. هذا يجعل من السهل إنشاء وصيانة تطبيقات AI للمحادثة الجديدة وتم تحديث جميع البرامج التعليمية لتعكس هذا. أفلاطون الآن يأتي أيضا مع واجهة المستخدم الرسومية الاختيارية. يتمتع!
من الناحية المفاهيمية ، يحتاج وكيل المحادثة إلى تجاوز خطوات مختلفة من أجل معالجة المعلومات التي يتلقاها كمدخلات (على سبيل المثال ، "ما هو الطقس اليوم؟") وإنتاج ناتج مناسب ("الرياح ولكن ليس بارد جدًا."). الخطوات الأساسية ، التي تتوافق مع المكونات الرئيسية للهندسة المعمارية القياسية (انظر الشكل 1) ، هي:
تم تصميم أفلاطون ليكون وحدات ومرنة قدر الإمكان ؛ وهو يدعم بنيات الذكاء الاصطناعي التقليدية والمخصصة ، والأهم من ذلك ، تمكين التفاعلات متعددة الأحزاب حيث يمكن أن تتفاعل عوامل متعددة ، ربما مع أدوار مختلفة ، مع بعضها البعض ، وتدريب في وقت واحد ، وحل المشكلات الموزعة.
يوضح الشكلان 1 و 2 ، أدناه ، مثال على هياكل وكيل المحادثة في أفلاطون عند التفاعل مع المستخدمين البشريين ومع المستخدمين المحاكاة ، على التوالي. يعد التفاعل مع المستخدمين المحاكاة ممارسة شائعة تستخدم في مجتمع الأبحاث لبدء تشغيل التعلم (أي تعلم بعض السلوكيات الأساسية قبل التفاعل مع البشر). يمكن تدريب كل مكون فردي عبر الإنترنت أو غير متصل باستخدام أي مكتبة تعلم آلي (على سبيل المثال ، Ludwig أو TensorFlow أو Pytorch أو تطبيقاتك الخاصة) لأن أفلاطون هو إطار عالمي. يقوم Ludwig ، صندوق أدوات التعلم العميق مفتوح المصدر ، باختيار جيد ، لأنه لا يتطلب كتابة رمز ومتوافق تمامًا مع أفلاطون.
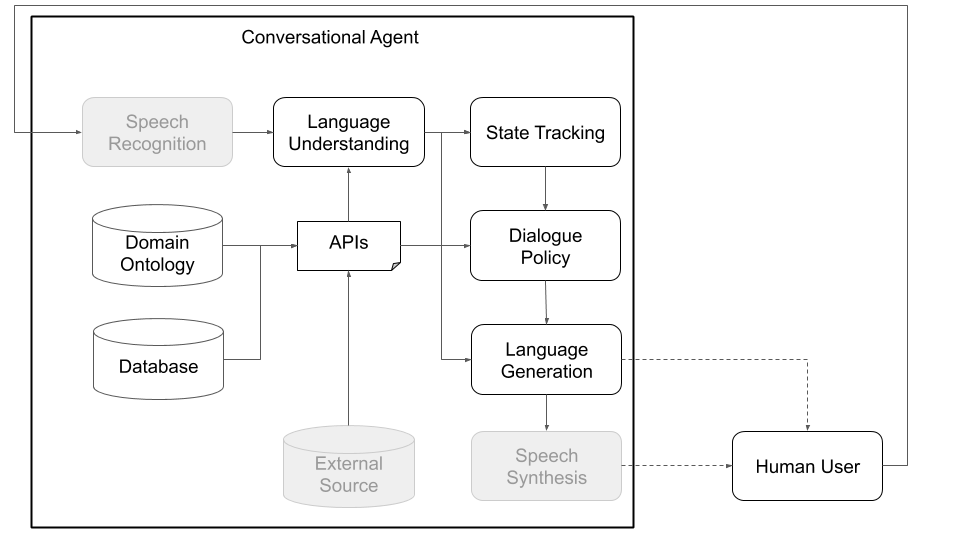 الشكل 1: تعني بنية أفلاطون المعيارية أنه يمكن تدريب أي مكون عبر الإنترنت أو غير متصل ويمكن استبداله بنماذج مخصصة أو تدريبات مسبقة. (المكونات الرمادية في هذا الرسم البياني ليست مكونات أفلاطون أساسية.)
الشكل 1: تعني بنية أفلاطون المعيارية أنه يمكن تدريب أي مكون عبر الإنترنت أو غير متصل ويمكن استبداله بنماذج مخصصة أو تدريبات مسبقة. (المكونات الرمادية في هذا الرسم البياني ليست مكونات أفلاطون أساسية.)
 الشكل 2: باستخدام مستخدم محاكاة بدلاً من مستخدم بشري ، كما في الشكل 1 ، يمكننا أن نتعثر مسبقًا النماذج الإحصائية لمكونات أفلاطون المختلفة. يمكن بعد ذلك استخدامها لإنشاء وكيل محادثة أولي يمكنه التفاعل مع المستخدمين البشريين لجمع المزيد من البيانات الطبيعية التي يمكن استخدامها لاحقًا لتدريب النماذج الإحصائية الأفضل. (المكونات الرمادية في هذا الرسم البياني ليست مكونات أفلاطون أساسية لأنها إما متاحة على أنها خارج المربع مثل Google ASR و Amazon LEX ، أو المجال والتطبيق المحدد مثل قواعد البيانات المخصصة/واجهات برمجة التطبيقات.)
الشكل 2: باستخدام مستخدم محاكاة بدلاً من مستخدم بشري ، كما في الشكل 1 ، يمكننا أن نتعثر مسبقًا النماذج الإحصائية لمكونات أفلاطون المختلفة. يمكن بعد ذلك استخدامها لإنشاء وكيل محادثة أولي يمكنه التفاعل مع المستخدمين البشريين لجمع المزيد من البيانات الطبيعية التي يمكن استخدامها لاحقًا لتدريب النماذج الإحصائية الأفضل. (المكونات الرمادية في هذا الرسم البياني ليست مكونات أفلاطون أساسية لأنها إما متاحة على أنها خارج المربع مثل Google ASR و Amazon LEX ، أو المجال والتطبيق المحدد مثل قواعد البيانات المخصصة/واجهات برمجة التطبيقات.)
بالإضافة إلى التفاعلات الواحدة الواحدة ، يدعم أفلاطون محادثات متعددة الوكلاء حيث يمكن لعوامل أفلاطون متعددة التفاعل والتعلم من بعضها البعض. على وجه التحديد ، سوف تفرخ أفلاطون عوامل المحادثة ، وتأكد من أن المدخلات والمخرجات (ما يسمعه كل عامل ويقوله) يتم تمريره إلى كل وكيل بشكل مناسب ، وتتبع المحادثة.
يمكن لهذا الإعداد تسهيل البحث في التعلم متعدد الوكلاء ، حيث يحتاج الوكلاء إلى تعلم كيفية إنشاء اللغة من أجل القيام بمهمة ، وكذلك الأبحاث في الحقول الفرعية للتفاعلات متعددة الأحزاب (تتبع حالة الحوار ، أخذ الدور ، إلخ). تحدد مبادئ الحوار ما يمكن أن يفهمه كل وكيل (علم الوجبات أو المعاني ؛ على سبيل المثال: السعر ، الموقع ، التفضيلات ، أنواع المأكولات ، وما إلى ذلك) وما يمكن أن يفعله (طلب المزيد من المعلومات ، تقديم بعض المعلومات ، استدعاء واجهة برمجة التطبيقات ، إلخ). يمكن للوكلاء التواصل عبر الكلام أو النص أو المعلومات المهيكلة (أعمال الحوار) وكل عامل لديه تكوينه الخاص. الشكل 3 ، أدناه ، يصور هذه الهندسة المعمارية ، ويوضح التواصل بين اثنين من العوامل والمكونات المختلفة:
 الشكل 3: تتيح بنية أفلاطون التدريب المتزامن لعوامل متعددة ، ولكل منها أدوار وأهداف مختلفة محتملة ، ويمكن أن تسهل البحث في مجالات مثل التفاعلات متعددة الأحزاب والتعلم متعدد الوكلاء. (المكونات الرمادية في هذا الرسم البياني ليست مكونات أفلاطون أساسية.)
الشكل 3: تتيح بنية أفلاطون التدريب المتزامن لعوامل متعددة ، ولكل منها أدوار وأهداف مختلفة محتملة ، ويمكن أن تسهل البحث في مجالات مثل التفاعلات متعددة الأحزاب والتعلم متعدد الوكلاء. (المكونات الرمادية في هذا الرسم البياني ليست مكونات أفلاطون أساسية.)
أخيرًا ، يدعم أفلاطون البنية المخصصة (على سبيل المثال تقسيم NLU إلى مكونات مستقلة متعددة) ومكونات مدربة مشتركة (مثل الحالة إلى النص ، أو النص إلى النص ، أو أي مجموعة أخرى) عبر بنية العامل العامة الموضحة في الشكل 4 أدناه. ينتقل هذا الوضع بعيدًا عن بنية وكيل المحادثة القياسية ويدعم أي نوع من الهندسة المعمارية (على سبيل المثال ، مع مكونات المشتركة ، أو نص نص إلى نص أو مكونات خطاب إلى كلام ، أو أي مجموعة أخرى) وتسمح بتحميل النماذج الموجودة أو المدربة مسبقًا في أفلاطون.
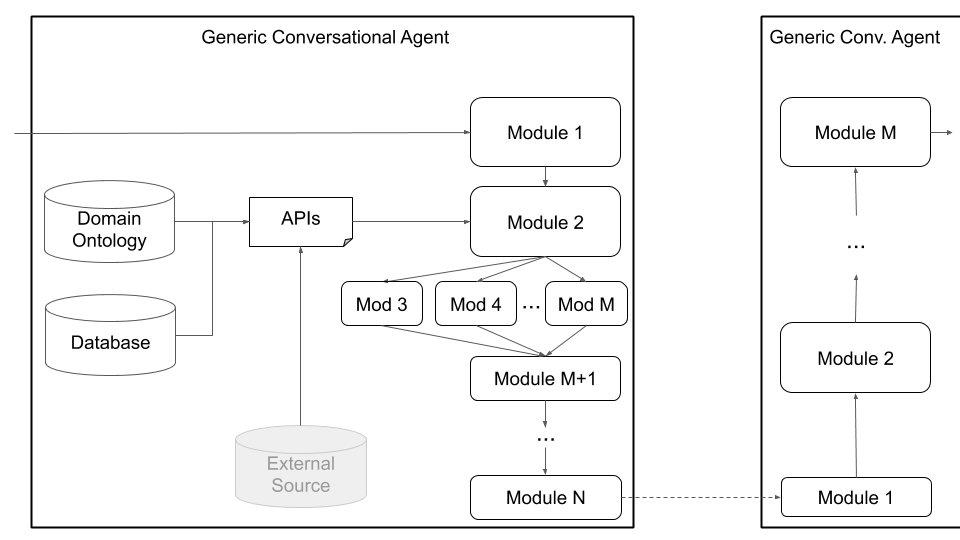 الشكل 4: تدعم بنية العامل العام في أفلاطون مجموعة واسعة من التخصيص ، بما في ذلك مكونات المفصل ، ومكونات الكلام إلى الكلام ، ومكونات النص إلى النص ، والتي يمكن تنفيذها جميعها بالتسلسل أو بالتوازي.
الشكل 4: تدعم بنية العامل العام في أفلاطون مجموعة واسعة من التخصيص ، بما في ذلك مكونات المفصل ، ومكونات الكلام إلى الكلام ، ومكونات النص إلى النص ، والتي يمكن تنفيذها جميعها بالتسلسل أو بالتوازي.
يمكن للمستخدمين تحديد الهندسة المعمارية الخاصة بهم و/أو توصيل مكوناتهم الخاصة إلى أفلاطون ببساطة عن طريق توفير اسم فئة Python ومسار الحزمة لتلك الوحدة ، وكذلك وسيطات تهيئة النموذج. كل ما يحتاج المستخدم إلى القيام به هو سرد الوحدات النمطية بالترتيب الذي يجب تنفيذه وأن يعتني أفلاطون الباقي ، بما في ذلك لف الإدخال/الإخراج ، وتسلسل الوحدات ، والتعامل مع الحوارات. يدعم أفلاطون التنفيذ التسلسلي والمواز للوحدات النمطية.
يوفر أفلاطون أيضًا دعمًا لتحسين بايزيان من بنية AI للمحادثة أو معلمات الوحدة النمطية الفردية من خلال تحسين بايزي للهياكل التوافقية (BOCS).
تأكد أولاً من أن لديك Python الإصدار 3.6 أو أعلى مثبت على جهازك. بعد ذلك ، تحتاج إلى استنساخ مستودع أفلاطون:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
بعد ذلك ، تحتاج إلى تثبيت بعض المتطلبات المسبقة:
Tensorflow:
pip install tensorflow>=1.14.0
قم بتثبيت مكتبة الكلام الإدراك لدعم الصوت:
pip install SpeechRecognition
لماكوس:
brew install portaudio
brew install gmp
pip install pyaudio
لأوبونتو/دبيان:
sudo apt-get install python3-pyaudio
بالنسبة لنظام التشغيل Windows: لا يوجد أي شيء يجب تثبيته مسبقًا
الخطوة التالية هي تثبيت أفلاطون. لتثبيت أفلاطون ، يجب عليك تثبيته مباشرة من رمز المصدر.
يتيح تثبيت أفلاطون من رمز المصدر التثبيت في وضع قابل للتحرير مما يعني أنه إذا قمت بإجراء تغييرات على الشفرة المصدرية ، فسيؤثر ذلك مباشرة على التنفيذ.
انتقل إلى دليل أفلاطون (حيث قمت باستنساخ مستودع أفلاطون في الخطوة السابقة).
نوصي بإنشاء بيئة بيثون جديدة. لإعداد بيئة بيثون الجديدة:
2.1 تثبيت VirtualEnv
sudo pip install virtualenv
2.2 إنشاء بيئة بيثون جديدة:
python3 -m venv </path/to/new/virtual/environment>
2.3 تفعيل بيئة بيثون الجديدة:
source </path/to/new/virtual/environment/bin>/bin/activate
تثبيت أفلاطون:
pip install -e .
لدعم الكلام ، من الضروري تثبيت Pyaudio ، الذي يحتوي على عدد من التبعيات التي قد لا تكون موجودة على جهاز المطور. إذا لم تنجح الخطوات المذكورة أعلاه ، فإن هذا المنشور على خطأ في تثبيت Pyaudio يتضمن تعليمات حول كيفية الحصول على هذه التبعيات وتثبيت Pyaudio.
يحتوي ملف CommonIssues.md على مشكلات شائعة وحلها الذي قد يواجهه المستخدم أثناء التثبيت.
لتشغيل أفلاطون بعد التثبيت ، يمكنك ببساطة تشغيل أمر plato في المحطة. يتلقى أمر plato 4 مخصصات فرعية:
runguidomainparse يتلقى كل من هذه الأدوات الفرعية قيمة للوسيطة --config التي تشير إلى ملف التكوين. سنصف ملفات التكوين هذه بالتفصيل لاحقًا في المستند ، لكن تذكر أن plato run --config و plato gui --config يتلقون ملف تكوين التطبيق (يمكن العثور على أمثلة هنا: example/config/application/ ، plato domain --config plato parse --config يتلقى تكوين المجال (يمكن العثور على أمثلة هنا: example/config/domain/ ). example/config/parser/ ).
بالنسبة للقيمة التي يتم تمريرها إلى --config First Plato الأول لمعرفة ما إذا كانت القيمة هي عنوان ملف على الجهاز. إذا كان الأمر كذلك ، فإن أفلاطون يحاول تحليل هذا الملف. إذا لم يكن الأمر كذلك ، يتحقق أفلاطون لمعرفة ما إذا كانت القيمة هي اسم ملف ضمن example/config/<application, domain, or parser> .
للحصول على بعض الأمثلة السريعة ، جرب ملفات التكوين التالية لنطاق مطاعم كامبريدج:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
يحتوي تطبيق ، أي نظام محادثة ، في أفلاطون على ثلاثة أجزاء رئيسية:
يتم الإعلان عن هذه الأجزاء في ملف تكوين التطبيق. يمكن العثور على أمثلة لملفات التكوين هذه على example/config/application/ في بقية هذا القسم ، نصف كل من هذه الأجزاء بالتفاصيل.
لتنفيذ نظام مربع حوار موجه نحو المهمة في أفلاطون ، يحتاج المستخدم إلى تحديد مكونين يشكلان مجال نظام الحوار:
يوفر أفلاطون أمرًا لأتمتة هذه العملية لبناء الأنطولوجيا وقاعدة البيانات. دعنا نقول على سبيل المثال أنك تريد إنشاء وكيل محادثة لمتجر الزهور ، ولديك العناصر التالية في .CSV (يمكن العثور على هذا الملف على example/data/flowershop.csv ):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
لإنشاء ملف .db SQL وملف .json ontology ، تحتاج إلى إنشاء ملف تكوين المجال الذي يجب أن تحدد فيه المسار إلى ملف CSV ، ومسارات الإخراج ، بالإضافة إلى فتحات ملحوظة ، يمكن طلبها ، ورسومها: (على سبيل example/config/domain/create_flowershop_domain.yaml ):
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
وتشغيل الأمر:
plato domain --config create_flowershop_domain.yaml
إذا سارت الأمور على ما يرام ، فيجب أن يكون لديك flowershop.json و flowershop.db في example/domains/ الدليل.
إذا تلقيت هذا الخطأ:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
وهذا يعني أنه تم إنشاء ملف .db بالفعل.
يمكنك الآن تشغيل المكونات الوهمية لأفلاطون كتحقق من العقل والتحدث إلى وكيل متجر الزهور الخاص بك:
plato run --config flowershop_text.yaml
وحدات التحكم هي الأشياء التي تنظم المحادثة بين الوكلاء. ستعمل وحدة التحكم على إنشاء إنشاء الوكلاء ، وتهيئةها لكل حوار ، وتمرير الإدخال والإخراج بشكل مناسب ، وتتبع الإحصاءات.
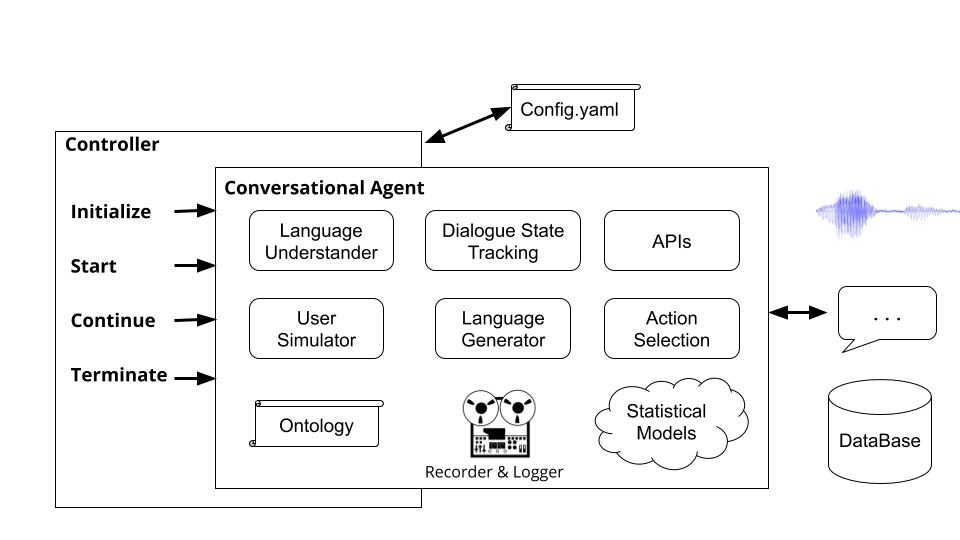
تشغيل Command plato run وحدة التحكم الأساسية في أفلاطون ( plato/controller/basic_controller.py ). يتلقى هذا الأمر قيمة للوسيطة --config التي تشير إلى ملف تكوين تطبيق أفلاطون.
لتشغيل وكيل محادثة أفلاطون ، يجب على المستخدم تشغيل الأمر التالي مع ملف التكوين المناسب:
plato run --config <FULL PATH TO CONFIG YAML FILE>
يرجى الرجوع إلى example/config/application/ على سبيل المثال ملفات التكوين التي تحتوي على إعدادات على البيئة والوكيل (العوامل) المراد إنشاؤها وكذلك مكوناتها. يمكن تشغيل الأمثلة في example/config/application/ مباشرة باستخدام اسم ملف yaml على سبيل المثال:
plato run --config <NAME OF A FILE FROM example/config/application/>
بدلاً من ذلك ، يمكن للمستخدم كتابة ملف التكوين الخاص به وتشغيل أفلاطون عن طريق تمرير المسار الكامل إلى ملف التكوين الخاص به إلى --config :
plato run --config <FULL PATH TO CONFIG YAML FILE>
بالنسبة للقيمة التي يتم تمريرها إلى --config First Plato الأول لمعرفة ما إذا كانت القيمة هي عنوان ملف على الجهاز. إذا كان الأمر كذلك ، فإن أفلاطون يحاول تحليل هذا الملف. إذا لم يكن الأمر كذلك ، يتحقق أفلاطون لمعرفة ما إذا كانت القيمة هي اسم ملف ضمن دليل example/config/application .
يمكن أن يكون لكل تطبيق منظمة العفو الدولية في أفلاطون واحد أو أكثر من عوامل. كل وكيل له دور (نظام ، مستخدم ، ...) ومجموعة من مكونات نظام الحوار القياسي (الشكل 1) ، وهي NLU ، مدير الحوار ، تعقب حالة الحوار ، السياسة ، NLG ، ومحاكاة المستخدم.
يمكن أن يكون للوكيل وحدة صريحة واحدة لكل واحد من هذه المكونات. بدلاً من ذلك ، يمكن دمج بعض هذه المكونات في وحدة واحدة أو أكثر (على سبيل المثال العوامل المفصل / الطرف) التي يمكن أن تعمل بالتتابع أو بالتوازي (الشكل 4). يتم تعريف مكونات أفلاطون في plato.agent.component وجميع الوراثة من plato.agent.component.conversational_module
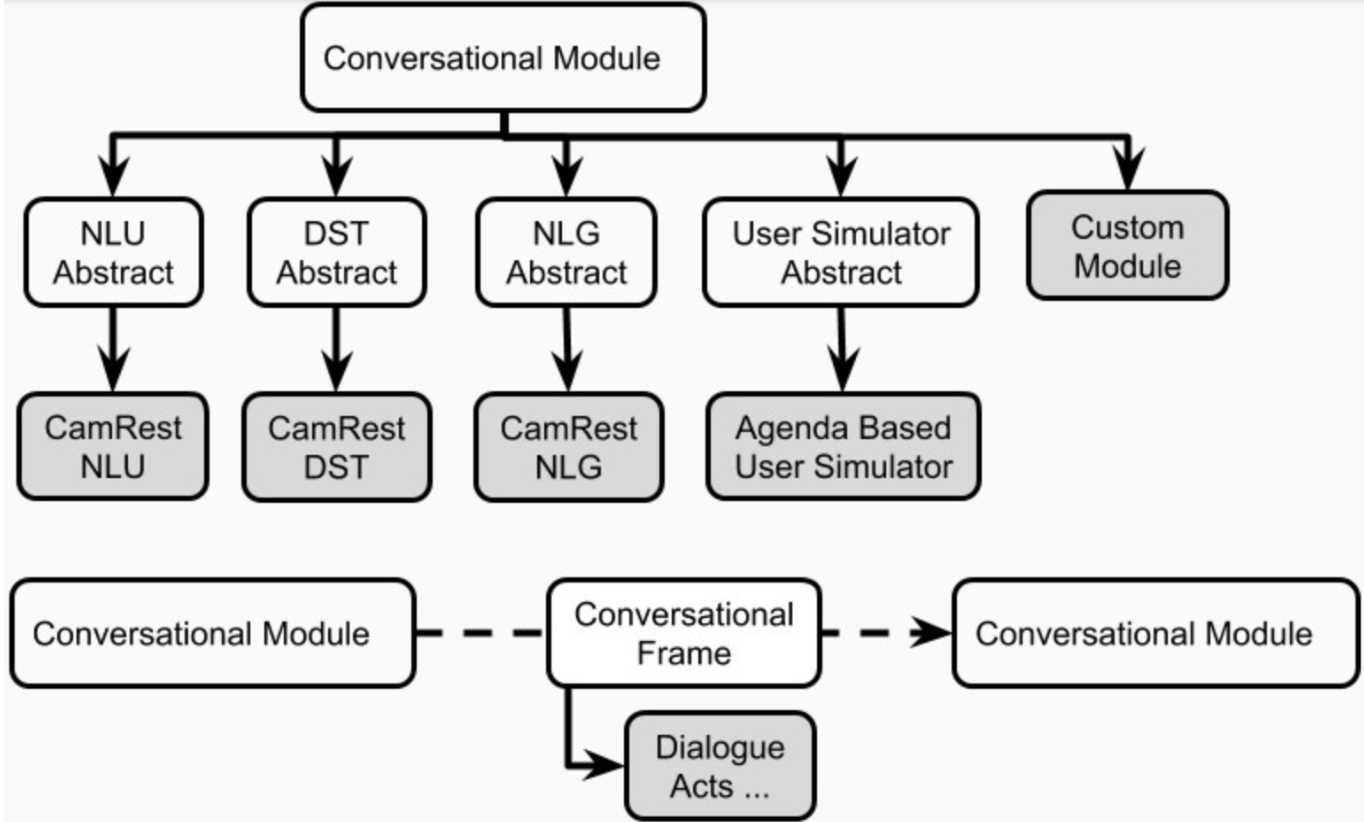 الشكل 5. مكونات وكلاء أفلاطون
الشكل 5. مكونات وكلاء أفلاطون
لاحظ أن أي تطبيقات جديدة أو وحدات مخصصة يجب أن ترث من plato.agent.component.conversational_module .
يمكن أن تكون كل واحدة من هذه الوحدات إما قائمة على القواعد أو تدريبها. في الأقسام الفرعية التالية ، سنصف كيفية بناء وحدات قائمة على القواعد والمدربين للوكلاء.
يوفر أفلاطون الإصدارات القائمة على القواعد لجميع مكونات وكيل محادثة ملء الفتحات (slot_filling_nlu ، slot_filling_dst ، slot_filling_policy ، slot_filling_nlg ، والإصدار الافتراضي من agenda_based_us). يمكن استخدامها في النماذج الأولية أو خطوط الأساس أو فحوصات العقل. على وجه التحديد ، تتبع جميع هذه المكونات القواعد أو الأنماط المشروطة على الأنطولوجيا المعطاة وأحيانًا على قاعدة البيانات المحددة ويجب معاملتها كإصدار أساسي لما ينبغي أن يفعله كل مكون.
يدعم أفلاطون تدريب وحدات مكونات الوكلاء بطريقة عبر الإنترنت (أثناء التفاعل) أو بطريقة غير متصلة بالإنترنت (من البيانات) ، باستخدام أي إطار تعلم عميق. تقريبًا يمكن تحميل أي نموذج في أفلاطون طالما يتم احترام إدخال/إخراج واجهة أفلاطون. على سبيل المثال ، إذا كان النموذج عبارة عن وحدة NLU مخصصة ، فإنها تحتاج ببساطة إلى الوراثة من فئة NLU الملخص لـ Plato ( plato.agent.component.nlu ) وتنفيذ الطرق التجريدية اللازمة.
لتسهيل التعلم عبر الإنترنت ، وتصحيح الأخطاء ، والتقييم ، يتتبع أفلاطون تجربته الداخلية في هيكل يسمى مسجل حلقة الحوار ، ( plato.utilities.dialogue_episode_recorder ) الذي يحتوي على معلومات حول حالات الحوار السابقة ، والإجراءات التي تم اتخاذها ، وحالات الحوار الحالية ، والكلمات المستلمة والكلام المنتجة ، والمكافآت التي تم استلامها ، وبعض الهياكل الأخرى التي لا يمكن استخدامها من قبل المبكر. فئات.
في نهاية الحوار أو على فترات زمنية محددة ، سيتصل كل وكيل محادثة بوظيفة القطار () لكل مكونات من مكوناته الداخلية ، ويمرر تجربة الحوار كبيانات تدريب. كل مكون يختار الأجزاء التي يحتاجها للتدريب.
لاستخدام خوارزميات التعلم التي يتم تنفيذها داخل أفلاطون ، يجب أن يتم تحليل أي بيانات خارجية ، مثل بيانات DSTC2 ، في تجربة أفلاطون هذه بحيث يمكن تحميلها واستخدامها من قبل المكون المقابل قيد التدريب.
بدلاً من ذلك ، قد يقوم المستخدمون بتحليل البيانات وتدريب نماذجهم خارج أفلاطون وتنقل النموذج المدرب ببساطة عندما يرغبون في استخدامه لعامل أفلاطون.
يعد التدريب عبر الإنترنت سهلاً مثل تقليب أعلام "Train" إلى "True" في التكوين لكل مكون يرغب المستخدمون في التدريب.
للتدريب من البيانات ، يحتاج المستخدمون ببساطة إلى تحميل التجربة التي قاموا بتحليلها من مجموعة البيانات الخاصة بهم. يوفر أفلاطون مثال محللات على مجموعات بيانات DSTC2 و MetalWoz. كمثال على كيفية استخدام هذه المحللات للتدريب غير المتصلة بالإنترنت في أفلاطون ، سنستخدم مجموعة بيانات DSTC2 ، والتي يمكن الحصول عليها من موقع تحدي تتبع حالة الحوار الثاني:
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
بمجرد اكتمال التنزيل ، تحتاج إلى فك ضغط الملف. يتم توفير ملف تكوين لحلية مجموعة البيانات هذه على example/config/parser/Parse_DSTC2.yaml . يمكنك تحليل البيانات التي قمت بتنزيلها عن طريق التحرير أولاً لقيمة data_path في example/config/parser/Parse_DSTC2.yaml للإشارة إلى المسار إلى المكان الذي قمت بتنزيله وفك بيانات DSTC2. بعد ذلك ، يمكنك تشغيل البرنامج النصي Parse على النحو التالي:
plato parse --config Parse_DSTC2.yaml
بدلاً من ذلك ، يمكنك كتابة ملف التكوين الخاص بك وتمرير العنوان المطلق إلى هذا الملف إلى الأمر:
plato parse --config <absolute pass to parse config file>
سيقوم تشغيل هذا الأمر بتشغيل البرنامج النصي المحلي لـ DSTC2 (الذي يعيش تحت plato/utilities/parser/parse_dstc2.py ) وسيقوم بإنشاء بيانات التدريب لمتتبع حالة الحوار ، NLU ، و NLG لكل من المستخدم والنظام ضمن دليل data في دليل الجذر لهذا المستودع. الآن يمكن استخدام هذه البيانات المحسورة لتدريب النماذج على مكونات مختلفة من أفلاطون.
هناك طرق متعددة لتدريب كل مكون من مكونات أفلاطون: عبر الإنترنت (حيث يتفاعل الوكيل مع الوكلاء أو المحاكاة أو المستخدمين الآخرين) أو في وضع عدم الاتصال. علاوة على ذلك ، يمكنك استخدام الخوارزميات التي تم تنفيذها في أفلاطون أو يمكنك استخدام الأطر الخارجية مثل TensorFlow و Pytorch و Keras و Ludwig ، إلخ.
Ludwig هو إطار عمل تعليمي عميق مفتوح المصدر يسمح لك بتدريب النماذج دون كتابة أي رمز. تحتاج فقط إلى تحليل بياناتك في ملفات .csv ، وإنشاء تكوين Ludwig (في YAML) ، الذي يصف البنية التي تريدها ، والتي تتميز باستخدامها من .CSV والمعلمات الأخرى ، ثم قم ببساطة بتشغيل أمر في محطة.
يوفر Ludwig أيضًا واجهة برمجة تطبيقات ، أن أفلاطون متوافق مع. يتيح هذا أفلاطون الاندماج مع طرز Ludwig ، أي تحميل أو حفظ النماذج ، وتدريبها والاستعلام عنها.
في القسم السابق ، أنشأ محلل DSTC2 من أفلاطون بعض ملفات .csv التي يمكن استخدامها لتدريب NLU و NLG. يوجد ملف NLU .csv واحد للنظام ( data/DSTC2_NLU_sys.csv ) وواحد للمستخدم ( data/DSTC2_NLU_usr.csv ). هذه تبدو مثل هذا:
| نص | نية | IOB |
|---|---|---|
| مطعم باهظ الثمن يقدم الطعام النباتي | يخبر | b-inform-pricerange ooo b-inform-food o |
| طعام نباتي | يخبر | B-Inform-Food O. |
| النوع الشرقي الآسيوي من الطعام | يخبر | B-Inform-Food I-Inform-Food OOO |
| مطعم آسيوي مطعم باهظ الثمن | يخبر | B-Inform-Pricerange OOO |
لتدريب نموذج NLU ، تحتاج إلى كتابة ملف تكوين يشبه هذا:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
يوجد مثال على ملف التكوين هذا في example/config/ludwig/ludwig_nlu_train.yaml . يمكن أن تبدأ وظيفة التدريب عن طريق الجري:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
والخطوة التالية هي تحميل النموذج في تكوين التطبيق. في example/config/application/CamRest_model_nlu.yaml نقدم تكوين تطبيق يحتوي على NLU على أساس النموذج والمكونات الأخرى غير المستندة إلى ML. من خلال تحديث المسار إلى الوضع ( model_path ) إلى القيمة التي قدمتها إلى وسيطة --output_directory عندما تقوم بتشغيل ludwig ، يمكنك تحديد نموذج NLU الذي يحتاجه الوكيل لاستخدامه في NLU:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
واختبار أن النموذج يعمل:
plato run --config CamRest_model_nlu.yaml
قام محلل بيانات DSTC2 بإنشاء ملفين .csv الذي يمكننا استخدامه لـ DST: DST_sys.csv و DST_usr.csv التي تبدو مثل هذا:
| DST_PREV_FOOD | DST_PREV_AREA | DST_PREV_PRICERANGE | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | DST_FOOD | DST_AREA | DST_Pricerange | DST_REQ_SLOT |
|---|---|---|---|---|---|---|---|---|---|---|---|
| لا أحد | لا أحد | لا أحد | يخبر | لا أحد | لا أحد | نباتي | غالي | نباتي | لا أحد | غالي | لا أحد |
| نباتي | لا أحد | غالي | يخبر | لا أحد | لا أحد | نباتي | لا أحد | نباتي | لا أحد | غالي | لا أحد |
| نباتي | لا أحد | غالي | يخبر | لا أحد | لا أحد | الشرقية الآسيوية | لا أحد | الشرقية الآسيوية | لا أحد | غالي | لا أحد |
| الشرقية الآسيوية | لا أحد | غالي | يخبر | لا أحد | لا أحد | الشرقية الآسيوية | غالي | الشرقية الآسيوية | لا أحد | غالي | لا أحد |
في الأساس ، يقوم المحلل بتتبع حالة الحوار السابقة ، والمدخلات من NLU ، وحالة الحوار الناتجة. يمكننا بعد ذلك إطعام هذا في Ludwig لتدريب متتبع حالة الحوار. إليك تكوين Ludwig الذي يمكن العثور عليه أيضًا في example/config/ludwig/ludwig_dst_train.yaml :
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
نحتاج الآن إلى تدريب نموذجنا مع Ludwig:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
وقم بتشغيل وكيل أفلاطون مع DST القائم على الطراز:
plato run --config CamRest_model_dst.yaml
يمكنك بالطبع تجربة بنيات أخرى ومعلمات التدريب.
لقد رأينا حتى الآن كيفية تدريب مكونات وكلاء أفلاطون باستخدام الأطر الخارجية (أي Ludwig). في هذا القسم ، سنرى كيفية استخدام الخوارزميات الداخلية في أفلاطون لتدريب سياسة الحوار دون اتصال ، باستخدام التعلم الخاضع للإشراف ، وعبر الإنترنت ، باستخدام التعلم التعزيز.
بصرف النظر عن ملفات .csv ، استخدم محلل DSTC2 مسجل حوار أفلاطون لإنقاذ الحوارات المحلية في سجلات تجربة أفلاطون هنا: logs/DSTC2_system و logs/DSTC2_user . تحتوي هذه السجلات على معلومات حول كل حوار ، على سبيل المثال حالة الحوار الحالية ، والحركة التي تم اتخاذها ، وحالة الحوار التالية ، والمكافأة المرصودة ، والكلام الإدخال ، والنجاح ، وما إلى ذلك. يمكن تحميل هذه السجلات مباشرة في وكيل محادثة ويمكن استخدامها لملء تجمع الخبرة.
كل ما عليك القيام به هو كتابة ملف تكوين يقوم بتحميل هذه السجلات ( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
لاحظ أننا نقوم بتشغيل هذا الوكيل فقط لحوار واحد ولكن تدرب على 100 عصر ، باستخدام التجربة التي يتم تحميلها من السجلات:
plato run --config CamRest_model_supervised_policy_train.yaml
بعد اكتمال التدريب ، يمكننا اختبار سياستنا الخاضعة للإشراف:
plato run --config CamRest_model_supervised_policy_test.yaml
في القسم السابق ، رأينا كيفية تدريب سياسة حوار خاضعة للإشراف. يمكننا الآن أن نرى كيف يمكننا تدريب سياسة التعلم التعزيز ، باستخدام خوارزمية تعزيز. للقيام بذلك ، نحدد الفئة ذات الصلة في ملف التكوين:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
لاحظ معلمات التعلم ضمن AGENT_0 والمعلمات الخاصة بالخوارزمية الخاصة بموجب وسيطات السياسة. ثم ندعو أفلاطون مع هذا التكوين:
plato run --config CamRest_model_reinforce_policy_train.yaml
واختبار نموذج السياسة المدربين:
plato run --config CamRest_model_reinforce_policy_test.yaml
لاحظ أنه يمكن أيضًا تدريب المكونات الأخرى عبر الإنترنت ، إما باستخدام واجهة برمجة تطبيقات Ludwig أو عن طريق تنفيذ خوارزميات التعلم في أفلاطون.
لاحظ أيضًا أنه يمكن تحميل ملفات السجل واستخدامها كتجمع خبرة لأي مكون وخوارزمية التعلم. ومع ذلك ، قد تحتاج إلى تنفيذ خوارزميات التعلم الخاصة بك لبعض مكونات أفلاطون.
لتدريب وحدة NLG ، تحتاج إلى كتابة ملف تكوين يشبه هذا (على سبيل المثال example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
وتدريب النموذج الخاص بك:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
والخطوة التالية هي تحميل النموذج في أفلاطون. انتقل إلى ملف تكوين CamRest_model_nlg.yaml وتحديث المسار إذا لزم الأمر:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
واختبار أن النموذج يعمل:
plato run --config CamRest_model_nlg.yaml
تذكر أن Ludwig ستقوم بإنشاء دليل جديد للتجربة _run_i في كل مرة يتم استدعاؤه ، لذا يرجى التأكد من الحفاظ على المسار الصحيح في تكوين أفلاطون محدثًا.
لاحظ أن Ludwig يوفر أيضًا طريقة لتدريب النموذج الخاص بك عبر الإنترنت ، لذلك في الممارسة العملية ، تحتاج إلى كتابة رمز صغير جدًا لإنشاء وتدريب وتقييم مكون التعلم العميق الجديد في أفلاطون.
في هذا المثال ، سنستخدم مجموعة بيانات MetalWoz التي يمكنك تنزيلها من هنا.
يدعم أفلاطون النماذج المدربة بشكل مشترك من خلال العوامل العامة. سنرى هنا الخطوات اللازمة لإنشاء وكيل محادثة SEQ2Seq بسيط من نقطة الصفر. باستخدام Metalwoz كمثال ، نحتاج إلى القيام بما يلي:
نظرًا لأننا ندرب فقط نموذج SEQ2Seq بسيط (نص إلى نص) ، نحتاج إلى محللنا لاستخراج كلمات المستخدم والنظام. سيتم حفظ هذه في ملفات .csv التي سيتم استخدامها بواسطة Ludwig في الخطوة 4.
للحصول على تنفيذ بسيط لمحلل MetalWoz ، انظر utilities/parser/Parse_MetalWOZ.py
يرجى ملاحظة أن هذا المحلل سوف يحلل ملف واحد فقط (مجال واحد). ومع ذلك ، يمكنك تعديله بسهولة لتناسب احتياجاتك. فيما يلي عينة من الإخراج الذي ينتجه المحلل الخاص بمجال طلب البيتزا:
| مستخدم | نظام |
|---|---|
| أهلاً | مرحبا كيف يمكنني مساعدتك؟ |
| أحتاج إلى تقديم طلب للحصول على مساعدة بيتزا | بالتأكيد ، ماذا تريد أن تضيف إلى طلبك؟ |
| أريد بيتزا مع الفطر والبيبروني ولحم الخنزير المقدد | لسوء الحظ ، فإن هذا الموقع خارج لحم الخنزير المقدد الذي طلبته. هل سيكون هناك تتصدر مختلفة تود استبدالها بها؟ |
| ماذا عن الأناناس | هذا القدر متاح. لقد أضفت بيتزا مع الفطر والبيبروني والأناناس إلى طلبك. ما هو الحجم الذي تريده؟ |
| واسطة | حسنا ، محدث. هل ترغب في إضافة المزيد إلى طلبك؟ |
| هذا كل شيء شكراً | حسنًا ، إجماليك هو 14.99. ستكون البيتزا جاهزة للاستلام تقريبًا. 20 دقيقة. |
لاحظ أن أول كلام مستخدم لا يوجد بالفعل في البيانات. ومع ذلك ، نحتاج إلى شيء ما لإثبات النموذج لإنتاج تحية النظام - يمكن أن نستخدم جملة فارغة ، أو أي تحية أخرى (أو مزيج من هذه).
يمكنك بعد ذلك تشغيل تحليل أفلاطون على النحو التالي:
plato parse --config Parse_MetalWOZ.yaml
للبدء ، يمكننا تدريب نموذج بسيط للغاية باستخدام Ludwig (لا تتردد في استخدام إطار التعلم العميق المفضل لديك هنا):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
يمكنك تعديل هذا التكوين لتعكس بنية اختيارك وتدريبك باستخدام Ludwig:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
تحتاج هذه الفئة ببساطة إلى التعامل مع تحميل النموذج ، والاستعلام عنه بشكل مناسب وتنسيق إخراجها بشكل مناسب. في حالتنا ، نحتاج إلى لف نص الإدخال في DataFrame Pandas ، والاستيلاء على الرموز المتوقعة من الإخراج والانضمام إليها في سلسلة سيتم إرجاعها. انظر الفصل هنا: plato.agent.component.joint_model.metal_woz_seq2seq.py
انظر example/config/application/metalwoz_generic.yaml للحصول على مثال ملف تكوين عام يتفاعل مع وكيل SEQ2Seq عبر النص. يمكنك تجربتها على النحو التالي:
plato run --config metalwoz_text.yaml
تذكر تحديث المسار إلى نموذجك المدرب إذا لزم الأمر! يفترض المسار الافتراضي أنك تقوم بتشغيل أمر Ludwig Train من دليل جذر أفلاطون.
تتيح إحدى ميزات أفلاطون الرئيسية أن يتفاعلوا مع بعضهما البعض. يمكن أن يكون لكل وكيل دور مختلف (على سبيل المثال ، النظام والمستخدم) ، أهداف مختلفة ، وتلقي إشارات مكافأة مختلفة. إذا كانت الوكلاء يتعاونون ، فيمكن مشاركة بعضها (على سبيل المثال ، ما الذي يشكل حوارًا ناجحًا).
لتشغيل العديد من وكلاء أفلاطون في مجال مطاعم كامبريدج ، نقوم بتشغيل الأوامر التالية لتدريب سياسات الحوار على الوكلاء واختبارها:
مرحلة التدريب: يتم تدريب سياسات 2 (1 لكل وكيل). يتم تدريب هذه السياسات باستخدام خوارزمية الذئب:
plato run --config MultiAgent_train.yaml
مرحلة الاختبار: تستخدم السياسة المدربة في مرحلة التدريب لإنشاء حوار بين اثنين من العوامل:
plato run --config MultiAgent_test.yaml
على الرغم من أن وحدة التحكم الأساسية تتيح حاليًا تفاعل اثنين من الوكيل ، إلا أنه من السهل إلى حد ما تمديده إلى عوامل متعددة (على سبيل المثال مع بنية السبورة ، حيث يقوم كل وكيل ببث ناتجه إلى وكلاء آخرين). يمكن أن يدعم ذلك السيناريوهات مثل المنازل الذكية ، حيث يكون كل جهاز وكيل ، وتفاعلات متعددة المستخدمين مع أدوار مختلفة ، وأكثر من ذلك.
يوفر أفلاطون التطبيقات لنوعين من أجهزة محاكاة المستخدم. أحدهما هو جهاز محاكاة المستخدم المعروف جيدًا على جدول الأعمال ، والآخر هو محاكاة تحاول محاكاة سلوك المستخدم الملاحظ في البيانات. ومع ذلك ، فإننا نشجع الباحثين على تدريب وكلاء المحادثة مع أفلاطون (أحدهما "نظام" وواحد "مستخدم") بدلاً من استخدام المستخدمين المحاكاة ، عندما يكون ذلك ممكنًا.
تم اقتراح محاكاة المستخدم المستندة إلى جدول الأعمال بواسطة Schatzmann وتم شرحها بالتفصيل في هذه الورقة. من الناحية المفاهيمية ، يحتفظ المحاكاة "أجندة" بالأشياء التي يمكن قولها ، والتي عادة ما يتم تنفيذها كمكدس. عندما يتلقى جهاز المحاكاة المدخلات ، فإنه يستشير سياسته (أو مجموعة قواعده) لمعرفة المحتوى الذي يجب دفعه إلى جدول الأعمال ، كرد فعل على المدخلات. بعد بعض التدبير المنزلي (على سبيل المثال ، إزالة التكرارات أو المحتوى الذي لم يعد صالحًا) ، ستقوم جهاز المحاكاة ببث عنصر واحد أو أكثر من جدول الأعمال الذي سيتم استخدامه لصياغة استجابته.
يحتوي محاكاة المستخدم المستندة إلى جدول الأعمال أيضًا على وحدة محاكاة للأخطاء ، والتي يمكنها محاكاة أخطاء التعرف على الكلام / فهم اللغة. استنادًا إلى بعض الاحتمالات ، سيشوه حوار المخرجات في محاكاة المحاكاة - النية أو الفتحة أو القيمة (احتمال مختلف لكل منهما). فيما يلي مثال على القائمة الكاملة للمعلمات التي يتلقاها هذا المحاكاة:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
تم تصميم هذا المحاكاة ليكون محاكاة بسيطة قائمة على السياسة ، يمكن أن تعمل على مستوى قانون الحوار أو على مستوى الكلام. لإظهار كيفية عمله ، أنشأ محلل DSTC2 ملف سياسة لهذا المحاكاة: user_policy_reactive.pkl (التفاعلي لأنه يتفاعل مع حوار النظام بدلاً من حالة محاكاة المستخدم). هذا في الواقع قاموس بسيط لـ:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
يمثل المفتاح قانون حوار الإدخال (على سبيل المثال قادم من وكيل المحادثة system ). قيمة كل مفتاح هي قاموس لعنلين ، تمثل توزيعات الاحتمالات على أعمال الحوار أو قوالب الكلام التي ستقوم بها المحاكاة.
لمشاهدة مثال ، يمكنك تشغيل التكوين التالي:
plato run --config CamRest_dtl_simulator.yaml
هناك طريقتان لإنشاء وحدة جديدة اعتمادًا على وظيفتها. إذا كانت الوحدة النمطية ، على سبيل المثال ، تنفذ طريقة جديدة لأداء سياسة NLU أو حوار ، فيجب عليك كتابة فصل يرث من الفئة التجريدية المقابلة.
ومع ذلك ، إذا كانت الوحدة النمطية لا تتناسب مع أحد المكونات الأساسية للوكيل الفردي ، على سبيل المثال ، فإنها تؤدي التعرف على الكيان المسمى أو تتنبأ بأعمال الحوار من النص ، فيجب عليك كتابة فئة ترث من conversational_module مباشرة. يمكنك بعد ذلك تحميل الوحدة النمطية عبر وكيل عام من خلال توفير مسار الحزمة المناسب واسم الفئة والوسائط في التكوين.
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
احرص! أنت مسؤول عن ضمان أنه يمكن معالجة I/O لهذه الوحدة واستهلاكها بشكل مناسب بواسطة وحدات قبل وبعد ، كما هو منصوص عليه في ملف التكوين العام.
يدعم أفلاطون أيضًا (منطقيًا) التنفيذ الموازي للوحدات النمطية. لتمكين أنك تحتاج إلى الحصول على الهيكل التالي في التكوين الخاص بك:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
احرص! سيتم تعبئة المخرجات من الوحدات النمطية التي تم تنفيذها بالتوازي في قائمة. يجب أن تكون الوحدة النمطية التالية (EG MODULE_i+1 ) قادرة على التعامل مع هذا النوع من المدخلات. لم يتم تصميم وحدات أفلاطون المقدمة للتعامل مع هذا ، ستحتاج إلى كتابة وحدة مخصصة لمعالجة الإدخال من مصادر متعددة.
تم تصميم أفلاطون ليكون قابلاً للتوسعة ، لذلك لا تتردد في إنشاء حالات الحوار الخاصة بك أو الإجراءات أو وظائف المكافآت أو الخوارزميات أو أي مكون آخر يناسب احتياجاتك المحددة. ما عليك سوى أن ترث من الفئة المقابلة للتأكد من أن تنفيذك متوافق مع أفلاطون.
يستخدم أفلاطون pysimplegui للتعامل مع واجهات المستخدم الرسومية. يتم تطبيق مثال على واجهة المستخدم الرسومية لأفلاطون على plato.controller.sgui_controller ويمكنك تجربته باستخدام الأمر التالي:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
يتمتع!


