plato research dialogue system
1.0.0

Esto es v0.3.1
El sistema de diálogo de investigación de Platón es un marco flexible que se puede utilizar para crear, entrenar y evaluar a los agentes de IA conversacionales en diversos entornos. Admite interacciones a través de actos de habla, texto o diálogo y cada agente de conversación puede interactuar con datos, usuarios humanos u otros agentes de conversación (en una configuración de múltiples agentes). Cada componente de cada agente se puede capacitar independientemente en línea o fuera de línea y Platón proporciona una manera fácil de envolver prácticamente cualquier modelo existente, siempre que la interfaz de Platón se adhiera.
Citas de publicación:
Alexandros papangelis, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino y Gokhan Tur, "Sistema de diálogo de Platón: una plataforma de investigación de IA conversacional flexible", preimpresión ARXIV [documento]
Alexandros papangelis, Yi-Chia Wang, Piero Molino y Gokhan Tur, "Entrenamiento de modelos de diálogo múltiple colaborativo a través del aprendizaje de refuerzo", Sigdial 2019 [Paper]
Platón escribió varios diálogos entre personajes que discuten sobre un tema haciendo preguntas. Muchos de estos diálogos presentan a Sócrates, incluido el juicio de Sócrates. (Sócrates fue absuelto en un nuevo juicio celebrado en Atenas, Grecia, el 25 de mayo de 2012).
V0.2 : La actualización principal de V0.1 es que Platón RDS ahora se proporciona como un paquete. Esto hace que sea más fácil crear y mantener nuevas aplicaciones de IA conversacionales y todos los tutoriales se han actualizado para reflejar esto. Platón ahora también viene con una GUI opcional. ¡Disfrutar!
Conceptualmente, un agente de conversación debe seguir varios pasos para procesar la información que recibe como entrada (por ejemplo, "¿Cómo es el clima hoy?") Y producir una salida apropiada ("viento pero no demasiado frío"). Los pasos principales, que corresponden a los componentes principales de una arquitectura estándar (ver Figura 1), son:
Platón ha sido diseñado para ser lo más modular y flexible posible; Admite arquitecturas de IA conversacionales tradicionales y personalizadas y, lo que es más importante, permite interacciones multipartidistas donde múltiples agentes, potencialmente con diferentes roles, pueden interactuar entre sí, entrenar simultáneamente y resolver problemas distribuidos.
Las Figuras 1 y 2, a continuación, representan un ejemplo de arquitecturas de agente de conversación de Platón al interactuar con usuarios humanos y con usuarios simulados, respectivamente. Interactuar con usuarios simulados es una práctica común utilizada en la comunidad de investigación para impulsar el aprendizaje (es decir, aprender algunos comportamientos básicos antes de interactuar con los humanos). Cada componente individual se puede capacitar en línea o fuera de línea utilizando cualquier biblioteca de aprendizaje automático (por ejemplo, Ludwig, TensorFlow, Pytorch o sus propias implementaciones) ya que Platón es un marco universal. Ludwig, la caja de herramientas de aprendizaje profundo de código abierto de Uber, es una buena opción, ya que no requiere código de escritura y es totalmente compatible con Platón.
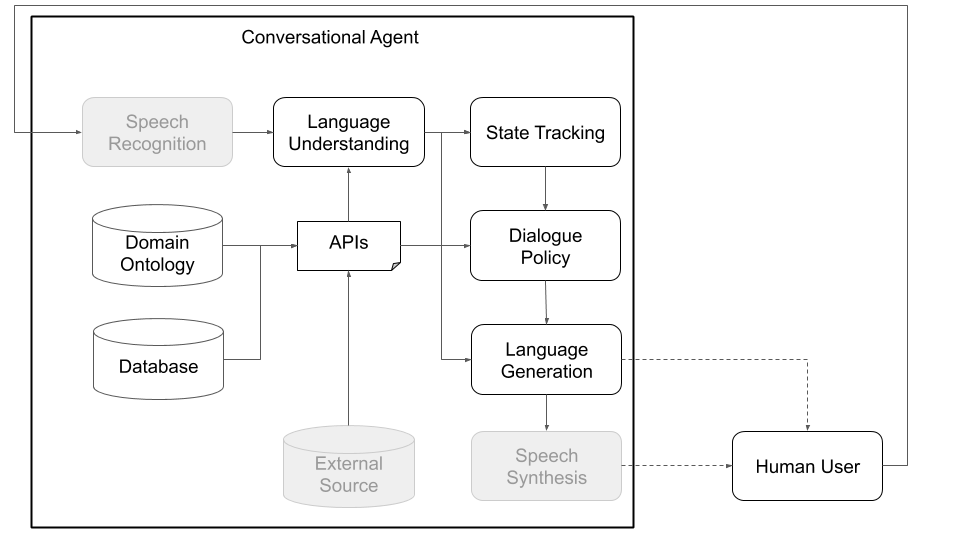 Figura 1: La arquitectura modular de Platón significa que cualquier componente puede ser capacitado en línea o fuera de línea y puede ser reemplazado por modelos personalizados o pre-capacitados. (Los componentes grises en este diagrama no son componentes centrales de Platón).
Figura 1: La arquitectura modular de Platón significa que cualquier componente puede ser capacitado en línea o fuera de línea y puede ser reemplazado por modelos personalizados o pre-capacitados. (Los componentes grises en este diagrama no son componentes centrales de Platón).
 Figura 2: Uso de un usuario simulado en lugar de un usuario humano, como en la Figura 1, podemos pre-entrenar modelos estadísticos para los diversos componentes de Platón. Estos se pueden usar para crear un prototipo de agente de conversación que pueda interactuar con los usuarios humanos para recopilar datos más naturales que se pueden utilizar posteriormente para capacitar mejores modelos estadísticos. (Los componentes grises en este diagrama no son componentes centrales de Platón, ya que están disponibles como fuera de la caja, como Google ASR y Amazon Lex, o dominio y la aplicación específicos, como bases de datos/API personalizadas).
Figura 2: Uso de un usuario simulado en lugar de un usuario humano, como en la Figura 1, podemos pre-entrenar modelos estadísticos para los diversos componentes de Platón. Estos se pueden usar para crear un prototipo de agente de conversación que pueda interactuar con los usuarios humanos para recopilar datos más naturales que se pueden utilizar posteriormente para capacitar mejores modelos estadísticos. (Los componentes grises en este diagrama no son componentes centrales de Platón, ya que están disponibles como fuera de la caja, como Google ASR y Amazon Lex, o dominio y la aplicación específicos, como bases de datos/API personalizadas).
Además de las interacciones de un solo agente, Platón admite conversaciones de múltiples agentes donde múltiples agentes de Platón pueden interactuar y aprender entre sí. Específicamente, Platón generará los agentes de conversación, se asegurará de que las entradas y salidas (lo que cada agente escucha y dice) pasen a cada agente de manera adecuada y realice un seguimiento de la conversación.
Esta configuración puede facilitar la investigación en el aprendizaje de múltiples agentes, donde los agentes necesitan aprender cómo generar lenguaje para realizar una tarea, así como la investigación en subcampos de interacciones multipartidistas (seguimiento del estado de diálogo, toma de turnos, etc.). Los principios del diálogo definen lo que cada agente puede entender (una ontología de entidades o significados; por ejemplo: precio, ubicación, preferencias, tipos de cocina, etc.) y qué puede hacer (solicite más información, proporcione información, llame a una API, etc.). Los agentes pueden comunicarse sobre el habla, el texto o la información estructurada (actos de diálogo) y cada agente tiene su propia configuración. La Figura 3, a continuación, muestra esta arquitectura, que describe la comunicación entre dos agentes y los diversos componentes:
 Figura 3: La arquitectura de Platón permite el entrenamiento concurrente de múltiples agentes, cada uno con roles y objetivos potencialmente diferentes, y puede facilitar la investigación en campos como interacciones multipartidistas y aprendizaje de agentes múltiples. (Los componentes grises en este diagrama no son componentes centrales de Platón).
Figura 3: La arquitectura de Platón permite el entrenamiento concurrente de múltiples agentes, cada uno con roles y objetivos potencialmente diferentes, y puede facilitar la investigación en campos como interacciones multipartidistas y aprendizaje de agentes múltiples. (Los componentes grises en este diagrama no son componentes centrales de Platón).
Finalmente, Platón admite arquitecturas personalizadas (por ejemplo, dividir NLU en múltiples componentes independientes) y componentes entrenados conjuntamente (por ejemplo, estado de texto a diálogo, texto a texto o cualquier otra combinación) a través de la arquitectura de agente genérico que se muestra en la Figura 4, a continuación. Este modo se aleja de la arquitectura de agente conversacional estándar y admite cualquier tipo de arquitectura (por ejemplo, con componentes conjuntos, componentes de texto a texto o voz a voz, o cualquier otra configuración) y permite cargar modelos existentes o pre-capacitados en Platón.
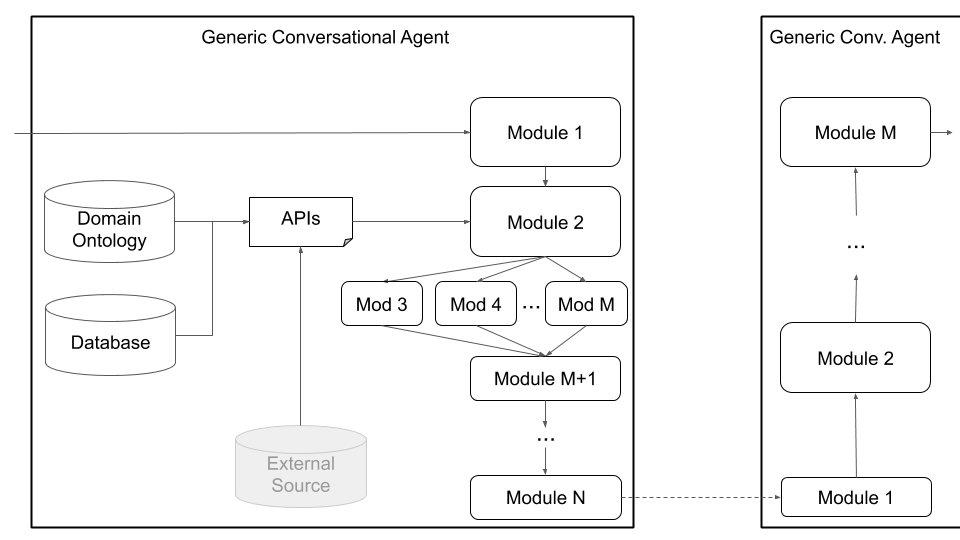 Figura 4: La arquitectura de agente genérico de Platón admite una amplia gama de personalización, incluidos componentes conjuntos, componentes de voz a voz y componentes de texto a texto, todos los cuales pueden ejecutarse en serie o en paralelo.
Figura 4: La arquitectura de agente genérico de Platón admite una amplia gama de personalización, incluidos componentes conjuntos, componentes de voz a voz y componentes de texto a texto, todos los cuales pueden ejecutarse en serie o en paralelo.
Los usuarios pueden definir su propia arquitectura y/o conectar sus propios componentes a Platón simplemente proporcionando un nombre de clase de Python y una ruta de paquete a ese módulo, así como los argumentos de inicialización del modelo. Todo lo que el usuario debe hacer es enumerar los módulos en el orden que deben ejecutarse y Platón se encarga del resto, incluida la envoltura de entrada/salida, encadenando los módulos y manejar los diálogos. Platón admite la ejecución en serie y paralela de módulos.
Platón también proporciona soporte para la optimización bayesiana de arquitecturas de IA conversacionales o parámetros de módulos individuales a través de la optimización bayesiana de estructuras combinatorias (BOC).
Primero asegúrese de tener Python versión 3.6 o más instalado en su máquina. A continuación, debe clonar el repositorio de Platón:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
A continuación, debe instalar algunos requisitos previos:
TensorFlow:
pip install tensorflow>=1.14.0
Instale la biblioteca de reseñas de SpeechRecognition para soporte de audio:
pip install SpeechRecognition
Para macOS:
brew install portaudio
brew install gmp
pip install pyaudio
Para Ubuntu/Debian:
sudo apt-get install python3-pyaudio
Para Windows: no es necesario preinstalar nada
El siguiente paso es instalar Platón. Para instalar Platón, debe instalarlo directamente desde el código fuente.
La instalación de Platón del código fuente permite la instalación en modo editable, lo que significa que si realiza cambios en el código fuente, efectuará directamente la ejecución.
Navegue al directorio de Platón (donde clonó el repositorio de Platón en el paso anterior).
Recomendamos crear un nuevo entorno de Python. Para configurar el nuevo entorno de Python:
2.1 instalar virtualenv
sudo pip install virtualenv
2.2 Crear un nuevo entorno de Python:
python3 -m venv </path/to/new/virtual/environment>
2.3 Active el nuevo entorno de Python:
source </path/to/new/virtual/environment/bin>/bin/activate
Instale Platón:
pip install -e .
Para apoyar el discurso, es necesario instalar Pyaudio, que tiene una serie de dependencias que podrían no existir en la máquina de un desarrollador. Si los pasos anteriores no tienen éxito, esta publicación en un error de instalación de Pyaudio incluye instrucciones sobre cómo obtener estas dependencias e instalar Pyaudio.
El archivo CommonIssues.md contiene problemas comunes y su resolución que un usuario podría encontrar mientras la instalación.
Para ejecutar Platón después de la instalación, simplemente puede ejecutar el comando plato en el terminal. El comando plato recibe 4 subcomcomandos:
runguidomainparse Cada uno de estos subcomcomandos recibe un valor para el argumento --config que apunta a un archivo de configuración. Describiremos estos archivos de configuración en detalle más adelante en el documento, pero recuerde que plato run --config y plato gui --config reciben un archivo de configuración de la aplicación (los ejemplos se pueden encontrar aquí: example/config/application/ ), plato domain --config recibe una configuración de dominio de dominio (ejemplos se pueden encontrar aquí: example/config/domain/ ) y plato parse --config recibe un archivo parser (los ejemplos (ejemplos se pueden encontrar aquí: ejemplo/configuración aquí. example/config/parser/ ).
Para el valor que se pasa al --config Platón primero verifica si el valor es la dirección de un archivo en la máquina. Si es así, Platón intenta analizar ese archivo. Si no es así, Platón verifica si el valor es un nombre de un archivo dentro del directorio example/config/<application, domain, or parser> .
Para algunos ejemplos rápidos, intente los siguientes archivos de configuración para el dominio de los restaurantes de Cambridge:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
Una aplicación, es decir, el sistema de conversación, en Platón contiene tres partes principales:
Estas piezas se declaran en un archivo de configuración de la aplicación. Se pueden encontrar ejemplos de dichos archivos de configuración en example/config/application/ En el resto de esta sección, describimos cada una de estas partes en detalle.
Para implementar un sistema de diálogo orientado a tareas en Platón, el usuario debe especificar dos componentes que constituyan el dominio del sistema de diálogo:
Platón proporciona un comando para automatizar este proceso de construcción de la ontología y la base de datos. Digamos, por ejemplo, que desea construir un agente de conversación para una florería, y tiene los siguientes elementos en un .csv (este archivo se puede encontrar en example/data/flowershop.csv ):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
Para generar automáticamente un archivo .DB SQL y un archivo de ontología .json, debe crear un archivo de configuración de dominio dentro del cual debe especificar la ruta al archivo CSV, las rutas de salida, así como las ranuras informables, solicitables y requeribles del sistema: (EG example/config/domain/create_flowershop_domain.yaml
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
y ejecuta el comando:
plato domain --config create_flowershop_domain.yaml
Si todo salió bien, debes tener un flowershop.json y un flowershop.db en el example/domains/ directorio.
Si recibe este error:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
Significa que el archivo .db ya se ha creado.
Ahora puede simplemente ejecutar los componentes ficticios de Platón como una verificación de cordura y hablar con su agente de flores:
plato run --config flowershop_text.yaml
Los controladores son objetos que orquestan la conversación entre los agentes. El controlador instanciará a los agentes, los inicializará para cada diálogo, pasará la entrada y la salida adecuadamente, y realizará un seguimiento de las estadísticas.
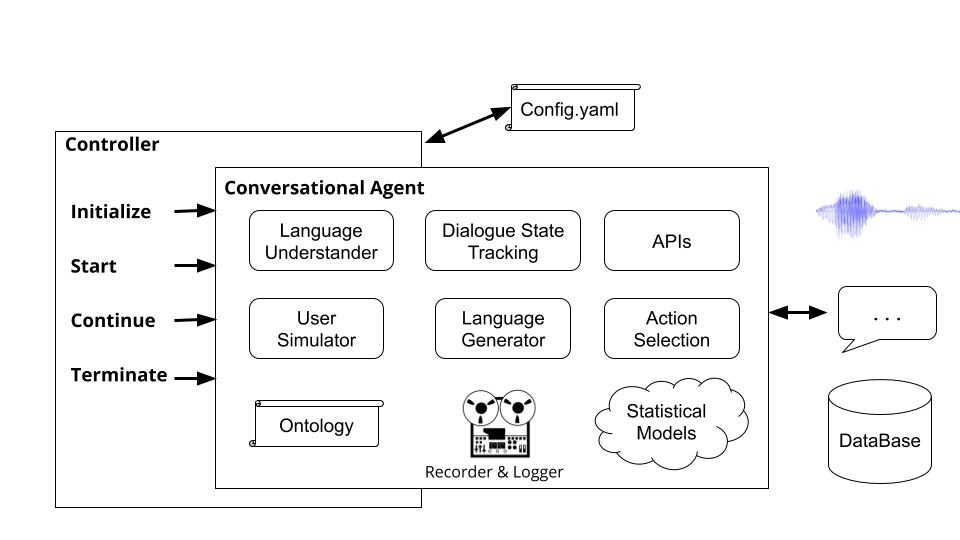
Ejecutando el comando plato run ejecuta el controlador básico de Platón ( plato/controller/basic_controller.py ). Este comando recibe un valor para el argumento --config que apunta a un archivo de configuración de la aplicación Platón.
Para ejecutar un agente de conversación de Platón, el usuario debe ejecutar el siguiente comando con el archivo de configuración apropiado:
plato run --config <FULL PATH TO CONFIG YAML FILE>
Consulte example/config/application/ por ejemplo archivos de configuración que contienen configuraciones en el entorno y los agentes que se crean, así como sus componentes. Los ejemplos en example/config/application/ podrían ejecutarse directamente utilizando solo el nombre del archivo YAML de ejemplo:
plato run --config <NAME OF A FILE FROM example/config/application/>
Alternativamente, un usuario podría escribir su propio archivo de configuración y ejecutar Platón pasando la ruta completa a su archivo de configuración a --config :
plato run --config <FULL PATH TO CONFIG YAML FILE>
Para el valor que se pasa al --config Platón primero verifica si el valor es la dirección de un archivo en la máquina. Si es así, el Platón intenta analizar ese archivo. Si no es así, Platón verifica si el valor es un nombre de un archivo dentro del directorio de example/config/application .
Cada aplicación de IA conversacional en Platón podría tener uno o más agentes. Cada agente tiene un rol (sistema, usuario, ...) y un conjunto de componentes del sistema de diálogo estándar (Figura 1), a saber, NLU, administrador de diálogo, rastreador de estado de diálogo, política, NLG y simulador de usuario.
Un agente podría tener un módulo explícito para cada uno de estos componentes. Alternativamente, algunos de estos componentes podrían combinarse en uno o más módulos (p. Ej., Agentes de articulación / extremo a extremo) que pueden ejecutarse secuencialmente o en paralelo (Figura 4). Los componentes de Platón se definen en plato.agent.component y todos heredan de plato.agent.component.conversational_module
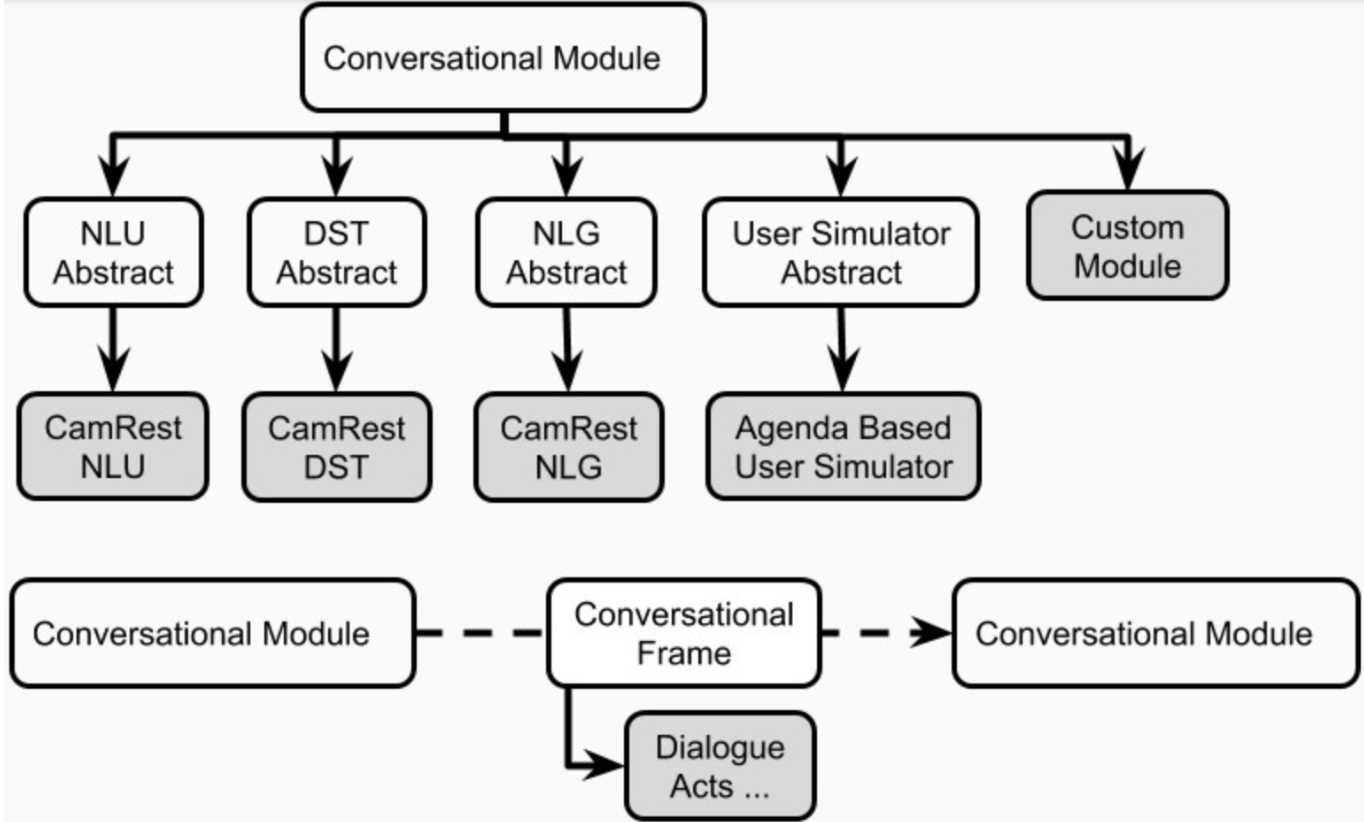 Figura 5. Componentes de los agentes de Platón
Figura 5. Componentes de los agentes de Platón
Tenga en cuenta que cualquier nueva implementación o módulos personalizados debe heredar de plato.agent.component.conversational_module .
Cada uno de estos módulos podría estar basado en reglas o entrenarse. En las siguientes subsecciones, describiremos cómo construir módulos basados en reglas y capacitados para agentes.
Platón proporciona versiones basadas en reglas de todos los componentes de un agente de conversación que llena ranura (slot_filling_nlu, slot_filling_dst, slot_filling_policy, slot_filling_nlg y la versión predeterminada de agenda_based_us). Estos se pueden usar para prototipos rápidos, líneas de base o controles de cordura. Específicamente, todos estos componentes siguen reglas o patrones condicionados a la ontología dada y, a veces, en la base de datos dada y deben tratarse como la versión más básica de lo que cada componente debería hacer.
Platón admite la capacitación de los módulos de componentes de los agentes en una manera en línea (durante la interacción) o fuera de línea (de los datos), utilizando cualquier marco de aprendizaje profundo. Prácticamente cualquier modelo se puede cargar en Platón siempre que se respeta la entrada/salida de la interfaz de Platón. Por ejemplo, si un modelo es un módulo NLU personalizado, simplemente necesita heredar de la clase de abstracto NLU de Platón ( plato.agent.component.nlu ) e implementar los métodos abstractos necesarios.
Para facilitar el aprendizaje, la depuración y la evaluación en línea, Platón realiza un seguimiento de su experiencia interna en una estructura llamada Recorder de episodios del diálogo, ( plato.utilities.dialogue_episode_recorder ) que contiene información sobre los estados de diálogo anteriores, las acciones tomadas, los estados de diálogo actuales, los medios recibidos y las oportunidades producidas, las recompensas recibidas y algunas otras estructuras que incluyen un campo personalizado que puede rastrear cualquier otra cosa que no se pueda hacer que se utilicen las mediciones que no pueden ser los que no pueden ser contenidos, los que no pueden ser contenidos, las recompensas de la que no pueden ser contenidas que no se pueden utilizar. categorías.
Al final de un diálogo o en intervalos especificados, cada agente de conversación llamará a la función TRAN () de cada uno de sus componentes internos, pasando la experiencia del diálogo como datos de capacitación. Cada componente elige las piezas que necesita para el entrenamiento.
Para usar algoritmos de aprendizaje que se implementan dentro de Platón, cualquier datos externos, como los datos de DSTC2, debe analizarse en esta experiencia de Platón para que puedan ser cargados y utilizados por el componente correspondiente en capacitación.
Alternativamente, los usuarios pueden analizar los datos y capacitar a sus modelos fuera de Platón y simplemente cargar el modelo capacitado cuando quieran usarlos para un agente de Platón.
La capacitación en línea es tan fácil como voltear las banderas de 'tren' a 'verdadero' en la configuración para cada componente que los usuarios desean entrenar.
Para entrenar de datos, los usuarios simplemente necesitan cargar la experiencia que analizaron desde su conjunto de datos. Platón proporciona analizadores de ejemplo para conjuntos de datos DSTC2 y Metalwoz. Como ejemplo de cómo usar estos analizadores para la capacitación fuera de línea en Platón, utilizaremos el conjunto de datos DSTC2, que se puede obtener del segundo sitio web del desafío de seguimiento del estado de diálogo:
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
Una vez que se completa la descarga, debe descomponer el archivo. Se proporciona un archivo de configuración para analizar este conjunto de datos en example/config/parser/Parse_DSTC2.yaml . Puede analizar los datos que descargó primero editando el valor de data_path en example/config/parser/Parse_DSTC2.yaml para señalar la ruta donde descargó y desabrochó los datos DSTC2. A continuación, puede ejecutar el script de análisis de la siguiente manera:
plato parse --config Parse_DSTC2.yaml
Alternativamente, puede escribir su propio archivo de configuración y pasar la dirección absoluta a ese archivo al comando:
plato parse --config <absolute pass to parse config file>
Ejecutando este comando ejecutará el script de análisis para DSTC2 (que vive bajo plato/utilities/parser/parse_dstc2.py ) y creará los datos de capacitación para el rastreador de estado de diálogo, NLU y NLG tanto para el usuario como para el sistema en el directorio data en el directorio raíz de este repositorio. Ahora, estos datos analizados podrían usarse para entrenar modelos para diferentes componentes de Platón.
Hay múltiples formas de entrenar cada componente de un agente de Platón: en línea (a medida que el agente interactúa con otros agentes, simuladores o usuarios) o fuera de línea. Además, puede usar algoritmos implementados en Platón o puede usar marcos externos como TensorFlow, Pytorch, Keras, Ludwig, etc.
Ludwig es un marco de aprendizaje profundo de código abierto que le permite entrenar modelos sin escribir ningún código. Solo necesita analizar sus datos en archivos .csv , crear una configuración de ludwig (en YAML), que describe la arquitectura que desea, que aparece para usar desde el .csv y otros parámetros y luego simplemente ejecute un comando en un terminal.
Ludwig también proporciona una API, con la que Platón es compatible. Esto le permite a Platón integrarse con los modelos Ludwig, es decir, carga o guardar los modelos, entrenarlos y consultarlos.
En la sección anterior, el analizador DSTC2 de Platón generó algunos archivos .csv que se pueden usar para entrenar NLU y NLG. Hay un archivo NLU .csv para el sistema ( data/DSTC2_NLU_sys.csv ) y otro para el usuario ( data/DSTC2_NLU_usr.csv ). Estos se ven así:
| transcripción | intención | IOB |
|---|---|---|
| restaurante caro que sirve comida vegetariana | informar | B-Inform-PRICERANGE OOO B-Inform-Food |
| comida vegetariana | informar | B-Inform-Food O |
| Tipo de comida oriental asiático | informar | B-Inform-Food I-Inform-Food OOO |
| Comida asiática de restaurante caro | informar | B-Inform-PRICERANGE OOO |
Para capacitar un modelo NLU, debe escribir un archivo de configuración que se vea así:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
Un ejemplo de este archivo de configuración existe en example/config/ludwig/ludwig_nlu_train.yaml . El trabajo de capacitación podría iniciarse corriendo:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
El siguiente paso es cargar el modelo en una configuración de aplicación. En example/config/application/CamRest_model_nlu.yaml proporcionamos una configuración de aplicación que tiene una NLU basada en el modelo y los otros componentes no están basados en ML. Al actualizar la ruta al modo ( model_path ) al valor que proporcionó al argumento --output_directory cuando ejecutó Ludwig, puede especificar el modelo NLU que el agente debe usar para NLU:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
y pruebe que el modelo funciona:
plato run --config CamRest_model_nlu.yaml
El analizador de datos DSTC2 generó dos archivos .csv que podemos usar para DST: DST_sys.csv y DST_usr.csv que se ven así:
| dst_prev_food | dst_prev_area | DST_PREV_PRICERANGE | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | dst_area | DST_PRICERANGE | dst_req_slot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ninguno | ninguno | ninguno | informar | ninguno | ninguno | vegetariano | caro | vegetariano | ninguno | caro | ninguno |
| vegetariano | ninguno | caro | informar | ninguno | ninguno | vegetariano | ninguno | vegetariano | ninguno | caro | ninguno |
| vegetariano | ninguno | caro | informar | ninguno | ninguno | Asiático oriental | ninguno | Asiático oriental | ninguno | caro | ninguno |
| Asiático oriental | ninguno | caro | informar | ninguno | ninguno | Asiático oriental | caro | Asiático oriental | ninguno | caro | ninguno |
Esencialmente, el analizador realiza un seguimiento del estado de diálogo anterior, la entrada de NLU y el estado de diálogo resultante. Luego podemos alimentar esto a Ludwig para entrenar a un rastreador de estado de diálogo. Aquí está la configuración de Ludwig que también se puede encontrar en example/config/ludwig/ludwig_dst_train.yaml :
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
Ahora necesitamos entrenar nuestro modelo con Ludwig:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
y ejecute un agente de Platón con el DST basado en el modelo:
plato run --config CamRest_model_dst.yaml
Por supuesto, puede experimentar con otras arquitecturas y parámetros de entrenamiento.
Hasta ahora hemos visto cómo entrenar componentes de los agentes de Platón utilizando marcos externos (es decir, ludwig). En esta sección, veremos cómo usar los algoritmos internos de Platón para capacitar una política de diálogo fuera de línea, utilizando el aprendizaje supervisado y en línea, utilizando el aprendizaje de refuerzo.
Además de los archivos .csv , el analizador DSTC2 utilizó la grabadora de episodios de diálogo de Platón para guardar también los diálogos analizados en los registros de experiencia de Platón: logs/DSTC2_system y logs/DSTC2_user . Estos registros contienen información sobre cada diálogo, por ejemplo, el estado del diálogo actual, las medidas tomadas, el siguiente estado de diálogo, la recompensa observada, el enunciado de entrada, el éxito, etc. Estos registros se pueden cargar directamente en un agente de conversación y pueden usarse para llenar el grupo de experiencia.
Todo lo que necesita hacer es escribir un archivo de configuración que cargue estos registros ( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
Tenga en cuenta que solo ejecutamos este agente para un diálogo, pero entrenamos para 100 épocas, utilizando la experiencia que se carga desde los registros:
plato run --config CamRest_model_supervised_policy_train.yaml
Después de completar la capacitación, podemos probar nuestra política supervisada:
plato run --config CamRest_model_supervised_policy_test.yaml
En la sección anterior, vimos cómo entrenar una política de diálogo supervisada. Ahora podemos ver cómo podemos capacitar a una política de aprendizaje de refuerzo, utilizando el algoritmo de refuerzo. Para hacer esto, definimos la clase relevante en el archivo de configuración:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
Tenga en cuenta los parámetros de aprendizaje en AGENT_0 y los parámetros algorítmicos específicos bajo los argumentos de la política. Luego llamamos a Platón con esta configuración:
plato run --config CamRest_model_reinforce_policy_train.yaml
y probar el modelo de política capacitado:
plato run --config CamRest_model_reinforce_policy_test.yaml
Tenga en cuenta que otros componentes también se pueden capacitar en línea, ya sea utilizando la API de Ludwig o implementando los algoritmos de aprendizaje en Platón.
Tenga en cuenta también que los archivos de registro se pueden cargar y utilizar como grupo de experiencia para cualquier componente y algoritmo de aprendizaje. Sin embargo, es posible que deba implementar sus propios algoritmos de aprendizaje para algunos componentes de Platón.
Para entrenar un módulo NLG, debe escribir un archivo de configuración que se vea así (por example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
y entrena a tu modelo:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
El siguiente paso es cargar el modelo en Platón. Vaya al archivo de configuración CamRest_model_nlg.yaml y actualice la ruta si es necesario:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
y pruebe que el modelo funciona:
plato run --config CamRest_model_nlg.yaml
Recuerde que Ludwig creará un nuevo directorio Experiment_run_i cada vez que se llama, así que asegúrese de mantener actualizado la ruta correcta en la configuración de Platón.
Tenga en cuenta que Ludwig también ofrece un método para capacitar a su modelo en línea, por lo que en la práctica debe escribir muy poco código para construir, entrenar y evaluar un nuevo componente de aprendizaje profundo en Platón.
Para este ejemplo, utilizaremos el conjunto de datos Metalwoz que puede descargar desde aquí.
Platón admite modelos entrenados conjuntamente a través de agentes genéricos. Aquí veremos los pasos necesarios para crear un agente de conversación SEQ2SEQ simple desde cero. Usando metalwoz como ejemplo, necesitamos hacer lo siguiente:
Como solo estamos entrenando un modelo SEQ2SEQ simple (texto al texto), necesitamos que nuestro analizador extraerá enunciados de usuario y sistema. Estos se guardarán en archivos .csv que Ludwig utilizarán en el paso 4.
Para una implementación simple de un analizador de metalwoz, consulte utilities/parser/Parse_MetalWOZ.py
Tenga en cuenta que este analizador solo analizará un solo archivo (un dominio). Sin embargo, puede modificarlo fácilmente para satisfacer sus necesidades. Aquí hay una muestra de la salida producida por el analizador para el dominio de pedido de pizza:
| usuario | sistema |
|---|---|
| Hola | Hola, ¿cómo puedo ayudarte? |
| Necesito hacer un pedido para una pizza necesito ayuda | Ciertamente, ¿qué le gustaría agregar a su pedido? |
| Quiero una pizza con coberturas de hongos, pepperoni y tocino | Desafortunadamente, esta ubicación está fuera del tocino que solicitó. ¿Habría una cobertura diferente con la que le gustaría reemplazarlo? |
| ¿Qué tal la piña? | Esa cobertura está disponible. Agregué una pizza con champiñones, pepperoni y piña a su pedido. ¿Qué talla te gustaría? |
| Medio | Muy bien, actualizado. ¿Le gustaría agregar más a su pedido? |
| Eso es todo, gracias | Muy bien, tu total es 14.99. Su pizza estará lista para recoger en aprox. 20 minutos. |
Tenga en cuenta que el primer enunciado del usuario en realidad no existe en los datos. Sin embargo, necesitamos algo para que el modelo produzca el saludo del sistema: podríamos haber usado una oración vacía o cualquier otro saludo (o una combinación de estos).
Luego puede ejecutar el análisis de Platón de la siguiente manera:
plato parse --config Parse_MetalWOZ.yaml
Para comenzar, podemos entrenar un modelo muy simple usando ludwig (no dude en usar su marco de aprendizaje profundo favorito aquí):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
Puede modificar esta configuración para reflejar la arquitectura de su elección y entrenar usando ludwig:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
Esta clase simplemente necesita manejar la carga del modelo, consultarlo adecuadamente y formatear su salida adecuadamente. En nuestro caso, necesitamos envolver el texto de entrada en un marco de datos de Pandas, tomar los tokens predichos de la salida y unirlos en una cadena que se devolverá. Vea la clase aquí: plato.agent.component.joint_model.metal_woz_seq2seq.py
Consulte example/config/application/metalwoz_generic.yaml para obtener un archivo de configuración genérico de ejemplo que interactúe con el agente SEQ2SEQ a través del texto. Puedes probarlo de la siguiente manera:
plato run --config metalwoz_text.yaml
¡Recuerde actualizar la ruta a su modelo capacitado si es necesario! La ruta predeterminada supone que ejecuta el comando Ludwig Train desde el directorio raíz de Platón.
Una de las características principales de Platón permite que dos agentes interactúen entre sí. Cada agente puede tener un rol diferente (por ejemplo, sistema y usuario), diferentes objetivos y recibir diferentes señales de recompensa. Si los agentes están cooperando, algunos de estos se pueden compartir (por ejemplo, lo que constituye un diálogo exitoso).
Para ejecutar múltiples agentes de Platón en el dominio de los restaurantes de Cambridge, ejecutamos los siguientes comandos para entrenar las políticas de diálogo de los agentes y probarlas:
Fase de entrenamiento: 2 políticas (1 para cada agente) están entrenadas. Estas políticas se entrenan utilizando el algoritmo de lobo:
plato run --config MultiAgent_train.yaml
Fase de prueba: utiliza la política capacitada en la fase de entrenamiento para crear diálogos entre dos agentes:
plato run --config MultiAgent_test.yaml
Si bien el controlador básico actualmente permite la interacción de dos agentes, es bastante sencillo extenderla a múltiples agentes (por ejemplo, con una arquitectura de pizarra, donde cada agente transmite su salida a otros agentes). Esto puede admitir escenarios como Smart Homes, donde cada dispositivo es un agente, interacciones múltiples con diversos roles y más.
Platón proporciona implementaciones para dos tipos de simuladores de usuarios. Uno es el muy conocido simulador de usuario basado en la agenda, y el otro es un simulador que intenta imitar el comportamiento del usuario observado en los datos. Sin embargo, alentamos a los investigadores a simplemente capacitar a dos agentes de conversación con Platón (uno es un "sistema" y otro es un "usuario") en lugar de usar usuarios simulados, cuando sea posible.
Schatzmann propuso el simulador de usuario basado en la agenda y se explica en detalle en este documento. Conceptualmente, el simulador mantiene una "agenda" de cosas que decir, que generalmente se implementa como una pila. Cuando el simulador recibe información, consulta su política (o su conjunto de reglas) para ver qué contenido empujar a la agenda, como respuesta a la entrada. Después de una limpieza (por ejemplo, eliminar duplicados o contenido que ya no es válido), el simulador aparecerá uno o más elementos de la agenda que se utilizarán para formular su respuesta.
El simulador de usuario basado en la agenda también tiene un módulo de simulación de error, que puede simular el reconocimiento de voz / errores de comprensión del lenguaje. Basado en algunas probabilidades, distorsionará los actos de diálogo de salida del simulador: la intención, la ranura o el valor (probabilidad diferente para cada uno). Aquí hay un ejemplo de la lista completa de parámetros que recibe este simulador:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
Este simulador fue diseñado para ser un simple simulador basado en políticas, que puede operar a nivel de la Ley de diálogo o en el nivel de expresión. Para demostrar cómo funciona, el analizador DSTC2 creó un archivo de política para este simulador: user_policy_reactive.pkl (Reactive porque reacciona a los actos del diálogo del sistema en lugar del estado del simulador de usuario). Este es en realidad un simple diccionario de:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
La clave representa la Ley de diálogo de entrada (por ejemplo, proviene del agente de conversación system ). El valor de cada clave es un diccionario de dos elementos, que representa distribuciones de probabilidad sobre los actos de diálogo o las plantillas de enunciado de las que el simulador muestreará.
Para ver un ejemplo, puede ejecutar la siguiente configuración:
plato run --config CamRest_dtl_simulator.yaml
Hay dos formas de crear un nuevo módulo dependiendo de su función. Si un módulo, por ejemplo, implementa una nueva forma de realizar NLU o una política de diálogo, entonces debe escribir una clase que hereda de la clase abstracta correspondiente.
Sin embargo, si un módulo no se ajusta a uno de los componentes básicos de un solo agente, por ejemplo, realiza reconocimiento de entidad nombrado o predice los actos de diálogo del texto, entonces debe escribir una clase que hereda directamente de la conversational_module . Luego puede cargar el módulo a través de un agente genérico proporcionando la ruta de paquete apropiada, el nombre de la clase y los argumentos en la configuración.
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
¡Ten cuidado! Usted es responsable de garantizar que la E/S de este módulo pueda procesarse y consumirse adecuadamente por módulos antes y después, según lo dispuesto en su archivo de configuración genérica.
Platón también admite (lógicamente) la ejecución paralela de módulos. Para habilitar que necesite tener la siguiente estructura en su configuración:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
¡Ten cuidado! Las salidas de los módulos ejecutados en paralelo se empacarán en una lista. El siguiente módulo (por ejemplo, MODULE_i+1 ) deberá poder manejar este tipo de entrada. Los módulos de Platón proporcionados no están diseñados para manejar esto, deberá escribir un módulo personalizado para procesar la entrada de múltiples fuentes.
Platón está diseñado para ser extensible, así que no dude en crear sus propios estados de diálogo, acciones, funciones de recompensa, algoritmos o cualquier otro componente para satisfacer sus necesidades específicas. Solo necesita heredar de la clase correspondiente para asegurarse de que su implementación sea compatible con Platón.
Platón usa Pysimplegui para manejar interfaces gráficas de usuario. Se implementa una GUI de ejemplo para Platón en plato.controller.sgui_controller y puede probarlo usando el siguiente comando:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
¡Disfrutar!


