plato research dialogue system
1.0.0

V0.3.1입니다
Plato Research Dialogue System은 다양한 환경에서 대화 상담원을 생성, 훈련 및 평가하는 데 사용될 수있는 유연한 프레임 워크입니다. 그것은 음성, 텍스트 또는 대화 행위를 통한 상호 작용을 지원하며 각 대화 에이전트는 데이터, 인간 사용자 또는 기타 대화 에이전트 (다중 에이전트 설정)와 상호 작용할 수 있습니다. 모든 에이전트의 모든 구성 요소는 온라인 또는 오프라인으로 독립적으로 교육을받을 수 있으며 Plato는 플라톤의 인터페이스가 준수되는 한 거의 모든 기존 모델을 감싸는 쉬운 방법을 제공합니다.
출판 인용 :
Alexandros Papangelis, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino 및 Gokhan Tur, "플라톤 대화 시스템 : 유연한 대화 AI 연구 플랫폼", Arxiv Pretrint [논문]
Alexandros Papangelis, Yi-Chia Wang, Piero Molino 및 Gokhan Tur,“강화 학습을 통한 협업 다중 에이전트 대화 모델 교육”, Sigdial 2019 [논문]
플라톤은 질문을함으로써 주제에 대해 논쟁하는 캐릭터들 사이에 몇 가지 대화를 썼습니다. 이러한 대화 중 많은 사람들이 소크라테스의 재판을 포함한 소크라테스를 특징으로합니다. (소크라테스는 2012 년 5 월 25 일 그리스 아테네에서 개최 된 새로운 재판에서 체포되었습니다).
v0.2 : v0.1의 기본 업데이트는 이제 Plato RDS가 패키지로 제공된다는 것입니다. 이를 통해 새로운 대화 AI 응용 프로그램을보다 쉽게 만들고 유지 관리 할 수 있으며 모든 튜토리얼이이를 반영하도록 업데이트되었습니다. 플라톤은 이제 옵션 GUI와 함께 제공됩니다. 즐기다!
개념적으로, 대화 상담원은 입력으로받는 정보 (예 :“오늘 날씨는 어떻습니까?”)를 처리하기 위해 다양한 단계를 거쳐야하며 적절한 출력 (“바람이 불지만 너무 추워지지 않습니다”)을 생성해야합니다. 표준 아키텍처의 주요 구성 요소 (그림 1 참조)에 해당하는 주요 단계는 다음과 같습니다.
플라톤은 가능한 한 모듈 식적이고 유연하게 설계되었습니다. 전통적인 대화식 AI 아키텍처뿐만 아니라 전통적인 대화를 지원하며 중요한 것은 다수의 상호 작용을 가능하게하여 잠재적으로 다른 역할을하는 여러 에이전트가 서로 상호 작용하고 동시에 훈련하고 분산 문제를 해결할 수있는 다자 상호 작용을 가능하게합니다.
아래의 그림 1과 2는 각각 인간 사용자와 시뮬레이션 된 사용자와 상호 작용할 때 플라톤 대화 에이전트 아키텍처를 나타냅니다. 시뮬레이션 된 사용자와의 상호 작용은 연구 커뮤니티에서 학습을 시작하는 데 사용되는 일반적인 관행입니다 (즉, 인간과 상호 작용하기 전에 몇 가지 기본 행동을 배우십시오). 플라톤이 보편적 인 프레임 워크이기 때문에 각 개별 구성 요소는 기계 학습 라이브러리 (예 : Ludwig, Tensorflow, Pytorch 또는 귀하의 구현)를 사용하여 온라인 또는 오프라인으로 교육을받을 수 있습니다. Uber의 오픈 소스 딥 러닝 툴 박스 인 Ludwig는 코드 작성이 필요하지 않으며 플라톤과 완전히 호환되므로 좋은 선택을합니다.
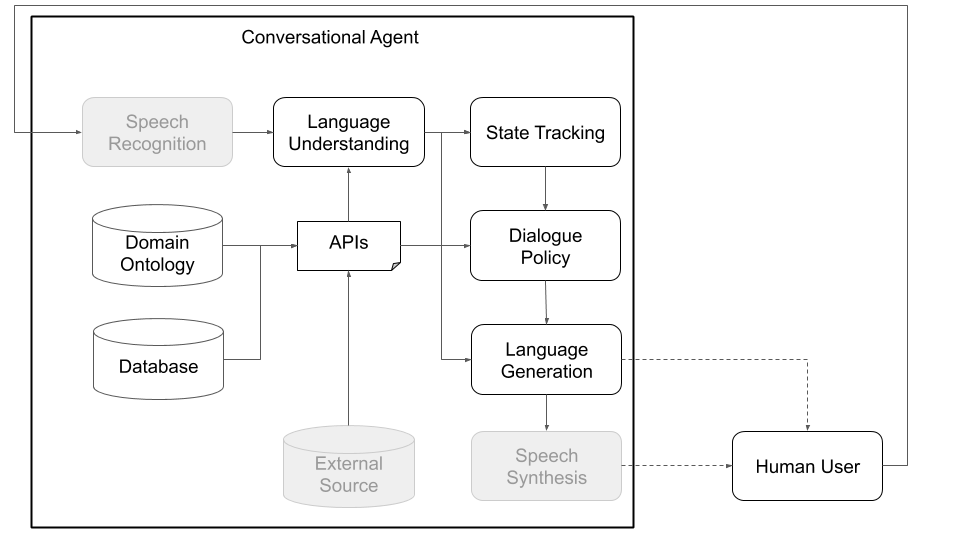 그림 1 : Plato의 모듈 식 아키텍처는 모든 구성 요소를 온라인 또는 오프라인으로 교육 할 수 있으며 사용자 정의 또는 미리 훈련 된 모델로 대체 될 수 있음을 의미합니다. (이 다이어그램의 회색 구성 요소는 핵심 플라톤 구성 요소가 아닙니다.)
그림 1 : Plato의 모듈 식 아키텍처는 모든 구성 요소를 온라인 또는 오프라인으로 교육 할 수 있으며 사용자 정의 또는 미리 훈련 된 모델로 대체 될 수 있음을 의미합니다. (이 다이어그램의 회색 구성 요소는 핵심 플라톤 구성 요소가 아닙니다.)
 그림 2 : 그림 1에서와 같이 인간 사용자가 아닌 시뮬레이션 사용자를 사용하여 플라톤의 다양한 구성 요소에 대한 통계 모델을 사전 훈련시킬 수 있습니다. 그런 다음이를 사용하여 인간 사용자와 상호 작용하여 더 나은 통계 모델을 훈련시키는 데 사용할 수있는 더 많은 자연스러운 데이터를 수집 할 수있는 프로토 타입 대화 에이전트를 만들 수 있습니다. (이 다이어그램의 회색 구성 요소는 Google ASR 및 Amazon Lex와 같은 상자에서 사용할 수 있거나 사용자 정의 데이터베이스/API와 같은 도메인 및 애플리케이션에 따라 플라톤 코어 구성 요소가 아닙니다.)
그림 2 : 그림 1에서와 같이 인간 사용자가 아닌 시뮬레이션 사용자를 사용하여 플라톤의 다양한 구성 요소에 대한 통계 모델을 사전 훈련시킬 수 있습니다. 그런 다음이를 사용하여 인간 사용자와 상호 작용하여 더 나은 통계 모델을 훈련시키는 데 사용할 수있는 더 많은 자연스러운 데이터를 수집 할 수있는 프로토 타입 대화 에이전트를 만들 수 있습니다. (이 다이어그램의 회색 구성 요소는 Google ASR 및 Amazon Lex와 같은 상자에서 사용할 수 있거나 사용자 정의 데이터베이스/API와 같은 도메인 및 애플리케이션에 따라 플라톤 코어 구성 요소가 아닙니다.)
Plato는 단일 에이전트 상호 작용 외에도 다수의 플라톤 에이전트가 서로 상호 작용하고 배울 수있는 다중 에이전트 대화를 지원합니다. 구체적으로, 플라톤은 대화 에이전트를 생성하고 입력 및 출력 (각 에이전트가 듣고 말하는 것)이 각 에이전트에게 적절하게 전달되고 대화를 추적하는지 확인합니다.
이 설정은 다중 에이전트 학습에 대한 연구를 촉진 할 수 있습니다. 이곳은 에이전트가 작업을 수행하기 위해 언어를 생성하는 방법을 배워야하고 다자간 상호 작용 하위 필드 (대화 상태 추적, 회전 복용 등)에 대한 연구를 촉진 할 수 있습니다. 대화 원칙은 각 에이전트가 이해할 수있는 내용 (실체 또는 의미의 온톨로지, 예 : 가격, 위치, 선호도, 요리 유형 등) 및 수행 할 수있는 일 (자세한 정보 요청, 일부 정보 제공, API 등)을 정의합니다. 에이전트는 음성, 텍스트 또는 구조화 된 정보 (대화 행위)를 통신 할 수 있으며 각 에이전트에는 고유 한 구성이 있습니다. 아래의 그림 3 은이 아키텍처를 나타내며, 두 에이전트와 다양한 구성 요소 간의 의사 소통을 요약합니다.
 그림 3 : Plato의 건축은 각각 잠재적으로 다른 역할과 목표를 가진 여러 에이전트의 동시 훈련을 허용하며, 다수의 상호 작용 및 다중 에이전트 학습과 같은 분야의 연구를 촉진 할 수 있습니다. (이 다이어그램의 회색 구성 요소는 핵심 플라톤 구성 요소가 아닙니다.)
그림 3 : Plato의 건축은 각각 잠재적으로 다른 역할과 목표를 가진 여러 에이전트의 동시 훈련을 허용하며, 다수의 상호 작용 및 다중 에이전트 학습과 같은 분야의 연구를 촉진 할 수 있습니다. (이 다이어그램의 회색 구성 요소는 핵심 플라톤 구성 요소가 아닙니다.)
마지막으로, Plato는 아래 그림 4에 표시된 일반 에이전트 아키텍처를 통해 사용자 정의 아키텍처 (예 : NLU를 여러 독립 구성 요소로 분할) 및 공동으로 훈련 된 구성 요소 (예 : 텍스트 대 디일 로그 상태, 텍스트-텍스트 또는 기타 조합)를 지원합니다. 이 모드는 표준 대화 에이전트 아키텍처에서 멀어지고 모든 종류의 아키텍처 (예 : 조인트 구성 요소, 텍스트-텍스트 또는 음성 음성 성분 구성 요소 또는 기타 설정)를 지원하고 기존 또는 미리 훈련 된 모델을 플라톤에로드 할 수 있습니다.
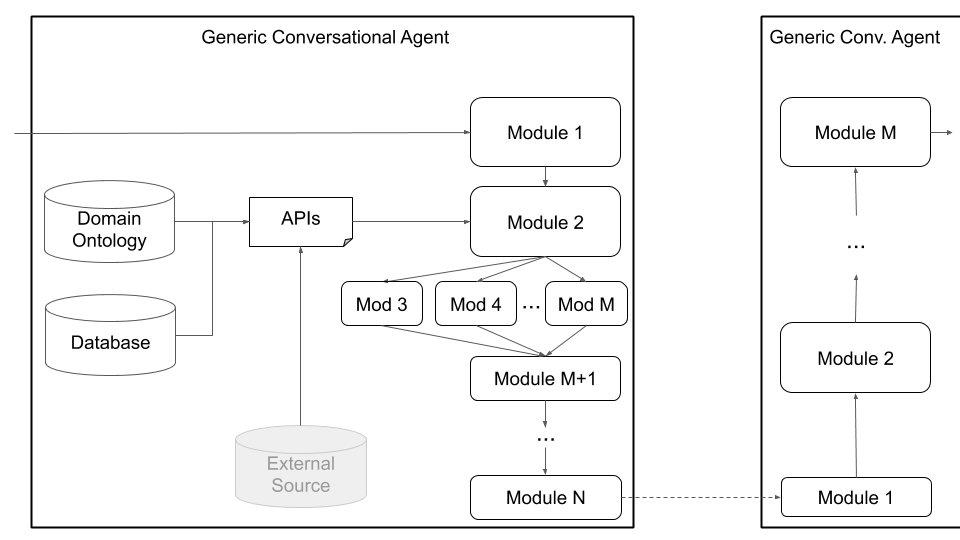 그림 4 : Plato의 일반 에이전트 아키텍처는 공동 구성 요소, 음성 음성 음성 구성 요소 및 텍스트-텍스트 구성 요소를 포함하여 광범위한 사용자 정의를 지원하며,이 모두는 일련의 또는 병렬로 실행될 수 있습니다.
그림 4 : Plato의 일반 에이전트 아키텍처는 공동 구성 요소, 음성 음성 음성 구성 요소 및 텍스트-텍스트 구성 요소를 포함하여 광범위한 사용자 정의를 지원하며,이 모두는 일련의 또는 병렬로 실행될 수 있습니다.
사용자는 자체 아키텍처를 정의하거나 단순히 Python 클래스 이름 및 패키지 경로를 해당 모듈에 제공하여 모델의 초기화 인수를 제공하여 자체 구성 요소를 플라톤에 연결할 수 있습니다. 사용자가해야 할 모든 것은 실행 해야하는 순서대로 모듈을 나열하고 Plato는 입력/출력을 감싸고, 모듈을 체인하고, 대화를 처리하는 등 나머지 부분을 처리합니다. 플라톤은 모듈의 직렬 및 병렬 실행을 지원합니다.
플라톤은 또한 조합 구조 (BOC)의 베이지안 최적화를 통해 대화식 AI 아키텍처 또는 개별 모듈 매개 변수의 베이지안 최적화를 지원합니다.
먼저 컴퓨터에 Python 버전 3.6 이상이 설치되어 있는지 확인하십시오. 다음으로 플라톤 저장소를 복제해야합니다.
git clone [email protected]:uber-research/plato-research-dialogue-system.git
다음으로 몇 가지 사전 반품을 설치해야합니다.
텐서 플로 :
pip install tensorflow>=1.14.0
오디오 지원을위한 SpeechRecognition 라이브러리 설치 :
pip install SpeechRecognition
MacOS의 경우 :
brew install portaudio
brew install gmp
pip install pyaudio
우분투/데비안의 경우 :
sudo apt-get install python3-pyaudio
Windows의 경우 : 사전 설치해야 할 필요가 없습니다
다음 단계는 플라톤을 설치하는 것입니다. 플라톤을 설치하려면 소스 코드에서 직접 설치해야합니다.
소스 코드에서 플라톤을 설치하면 편집 가능한 모드로 설치할 수 있으므로 소스 코드를 변경하면 직접 실행에 영향을 미칩니다.
플라톤 디렉토리 (이전 단계에서 플라톤 저장소를 복제 한 곳)로 이동하십시오.
새로운 파이썬 환경을 만드는 것이 좋습니다. 새로운 파이썬 환경을 설정하려면 :
2.1 VirtualEnV를 설치하십시오
sudo pip install virtualenv
2.2 새로운 파이썬 환경 만들기 :
python3 -m venv </path/to/new/virtual/environment>
2.3 새로운 파이썬 환경 활성화 :
source </path/to/new/virtual/environment/bin>/bin/activate
플라톤 설치 :
pip install -e .
음성을 지원하기 위해서는 개발자의 컴퓨터에 존재하지 않을 수있는 여러 가지 의존성이있는 Pyaudio를 설치해야합니다. 위의 단계가 실패한 경우, Pyaudio 설치 오류 의이 게시물에는 이러한 종속성을 얻고 Pyaudio를 설치하는 방법에 대한 지침이 포함되어 있습니다.
CommonIssues.md 파일에는 설치 중에 사용자가 발생할 수있는 일반적인 문제와 해상도가 포함되어 있습니다.
설치 후 플라톤을 실행하려면 터미널에서 plato 명령을 실행할 수 있습니다. plato 명령은 4 개의 하위 명령을받습니다.
runguidomainparse 이러한 각 하위 명령은 구성 파일을 가리키는 --config 그 인수에 대한 값을 수신합니다. 우리는 이러한 구성 파일이 문서의 뒷부분에서 자세히 설명하지만 plato run --config 및 plato gui --config 응용 프로그램 구성 파일을 수신 할 수 있음을 기억합니다 (예 : example/config/application/ ), plato domain --config 도메인 구성을 수신합니다 (예 : example/config/domain/ ) 및 plato parse --config a Parser Config a a Parser Parsupation (예 : 예제/config/domain). 여기에서 찾을 수 있습니다 : example/config/parser/ ).
--config Plato로 전달되는 값의 경우 먼저 값이 컴퓨터의 파일 주소인지 확인합니다. 그렇다면 플라톤은 해당 파일을 구문 분석하려고합니다. 그렇지 않은 경우 Plato는 값이 example/config/<application, domain, or parser> 디렉토리 내의 파일 이름인지 확인합니다.
몇 가지 빠른 예를 보려면 Cambridge Restaurants 도메인의 다음 구성 파일을 사용해보십시오.
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
플라톤의 응용 프로그램, 즉 대화 시스템에는 세 가지 주요 부분이 포함됩니다.
이 부분은 응용 프로그램 구성 파일로 선언됩니다. 이러한 구성 파일의 예는 example/config/application/ 이 섹션의 나머지 부분에서 이러한 각 부분을 자세히 설명 할 수 있습니다.
플라톤에서 작업 지향 대화 시스템을 구현하려면 사용자는 대화 상자 시스템의 도메인을 구성하는 두 가지 구성 요소를 지정해야합니다.
플라톤은 온톨로지 및 데이터베이스를 구축하는이 프로세스를 자동화하기위한 명령을 제공합니다. 예를 들어 꽃 가게의 대화 에이전트를 구축하려고하고 .csv에 다음 항목이 있다고 가정 해 보겠습니다 (이 파일은 example/data/flowershop.csv 에서 찾을 수 있음) :
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
.db sql 파일과 .json ontology 파일을 자동으로 생성하려면 CSV 파일, 출력 경로, 정보 가능, 요청 가능 및 시스템보고 가능한 슬롯의 경로를 지정 해야하는 도메인 example/config/domain/create_flowershop_domain.yaml 파일을 작성해야합니다.
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
명령을 실행합니다.
plato domain --config create_flowershop_domain.yaml
모든 것이 잘 진행되면 example/domains/ 디렉토리에 flowershop.json 과 flowershop.db 가 있어야합니다.
이 오류를 받으면 :
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
이는 .db 파일이 이미 작성되었음을 의미합니다.
이제 Plato의 더미 구성 요소를 Wanity Check로 실행하고 Flower Shop 요원과 대화 할 수 있습니다.
plato run --config flowershop_text.yaml
컨트롤러는 에이전트 간의 대화를 조정하는 객체입니다. 컨트롤러는 에이전트를 인스턴스화하고, 각 대화에 대해 초기화하고, 입력 및 출력을 적절하게 패스하고, 통계를 추적합니다.
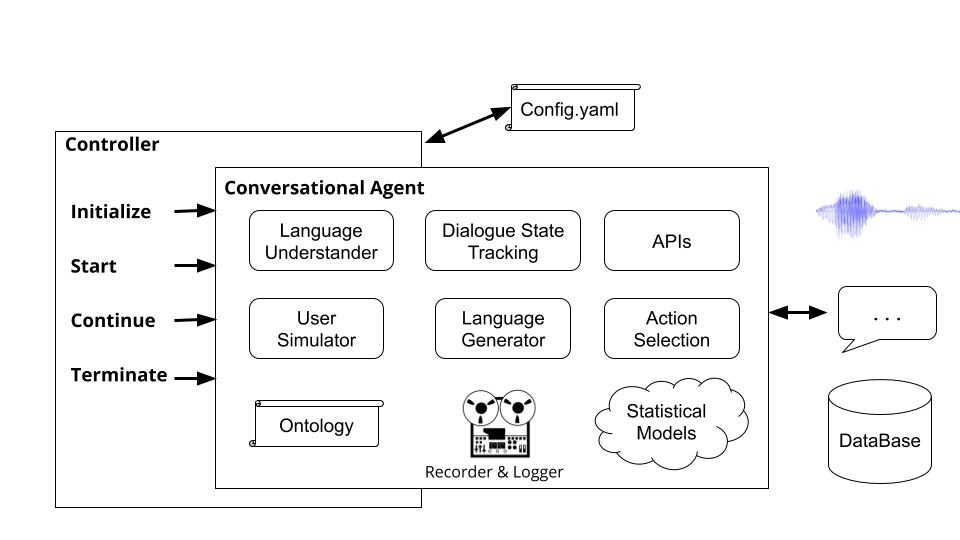
plato run 실행하면 Plato의 기본 컨트롤러 ( plato/controller/basic_controller.py )가 실행됩니다. 이 명령은 플라톤 애플리케이션 구성 파일을 가리키는 --config 그 인수에 대한 값을 수신합니다.
플라톤 대화 상담원을 실행하려면 사용자는 적절한 구성 파일로 다음 명령을 실행해야합니다.
plato run --config <FULL PATH TO CONFIG YAML FILE>
환경의 설정과 구성 요소 및 구성 요소의 구성 요소가 포함 된 구성 파일 example/config/application/ 예를 들어 참조하십시오. example/config/application/ 의 예는 예제 Yaml 파일의 이름 만 사용하여 직접 실행할 수 있습니다.
plato run --config <NAME OF A FILE FROM example/config/application/>
또는 사용자는 구성 파일의 전체 경로를 --config 로 전달하여 자체 구성 파일을 작성하고 플라톤을 실행할 수 있습니다.
plato run --config <FULL PATH TO CONFIG YAML FILE>
--config Plato로 전달되는 값의 경우 먼저 값이 컴퓨터의 파일 주소인지 확인합니다. 그렇다면 플라톤은 해당 파일을 구문 분석하려고합니다. 그렇지 않은 경우 플라톤은 값이 example/config/application 디렉토리 내의 파일 이름인지 확인합니다.
플라톤의 각 대화식 AI 응용 프로그램에는 하나 이상의 에이전트가있을 수 있습니다. 각 에이전트에는 역할 (시스템, 사용자, ...)과 표준 대화 상자 시스템 구성 요소 세트 (그림 1), 즉 NLU, 대화 관리자, 대화 상태 추적기, 정책, NLG 및 사용자 시뮬레이터가 있습니다.
에이전트는 이러한 구성 요소 각각에 대해 하나의 명시적인 모듈을 가질 수 있습니다. 대안 적으로, 이들 성분 중 일부는 순차적으로 또는 병렬로 작동 할 수있는 하나 이상의 모듈 (예 : 조인트 / 엔드 투 엔드 제제)으로 결합 될 수있다 (도 4). Plato의 구성 요소는 plato.agent.component 에 정의되어 있으며 모든 것은 plato.agent.component.conversational_module 에서 상속합니다.
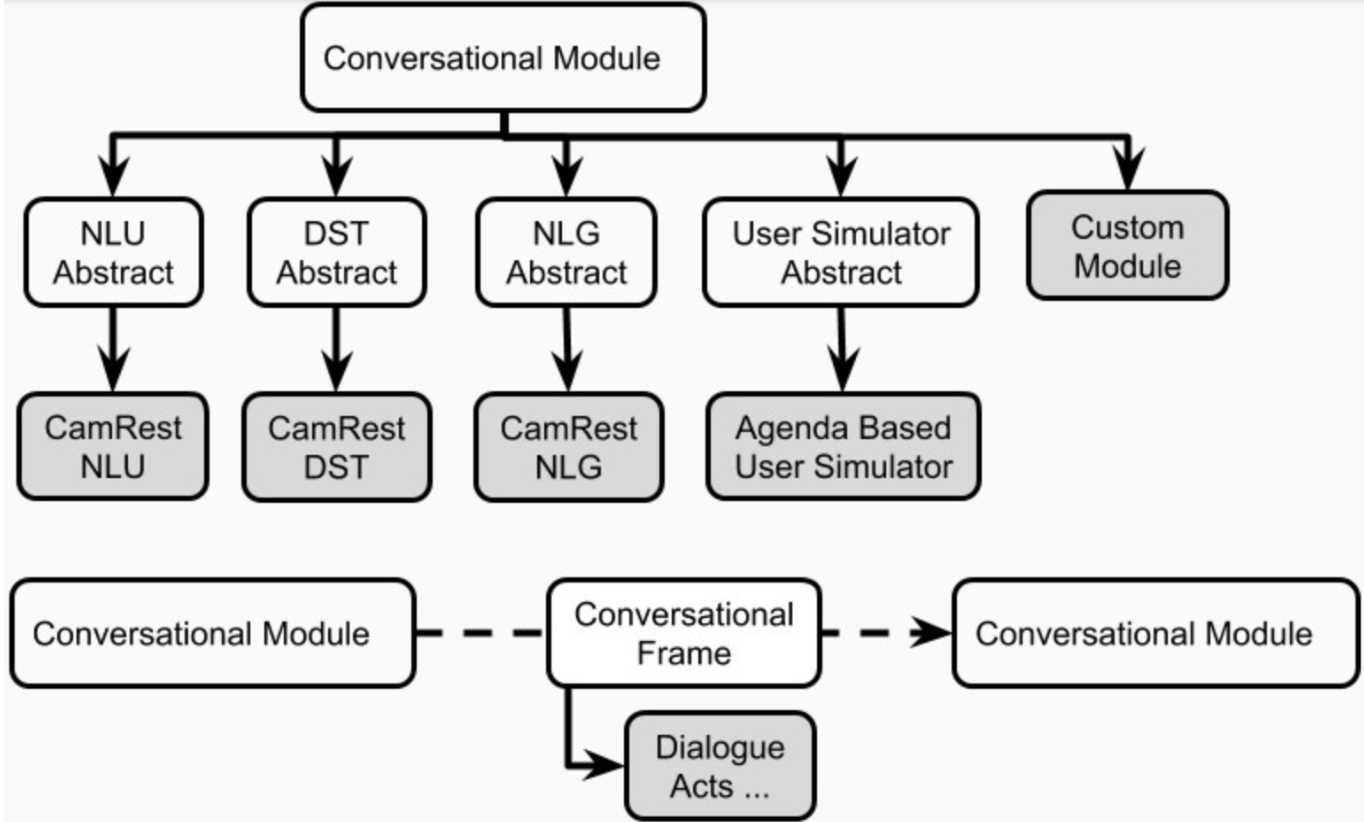 그림 5. 플라톤 에이전트의 구성 요소
그림 5. 플라톤 에이전트의 구성 요소
새로운 구현 또는 사용자 정의 모듈은 plato.agent.component.conversational_module 에서 상속해야합니다.
이러한 모듈 각각은 규칙 기반이거나 훈련 될 수 있습니다. 다음 하위 섹션에서는 에이전트를위한 규칙 기반 및 훈련 된 모듈을 구축하는 방법을 설명합니다.
Plato는 슬롯-채취 대화 에이전트의 모든 구성 요소 (slot_filling_nlu, slot_filling_dst, slot_filling_policy, slot_filling_nlg 및 genda_based_us의 기본 버전)의 규칙 기반 버전을 제공합니다. 이들은 빠른 프로토 타이핑, 기준선 또는 정신 점검에 사용할 수 있습니다. 구체적으로, 이러한 모든 구성 요소는 주어진 온톨로지 및 때로는 주어진 데이터베이스에서 조절 된 규칙 또는 패턴을 따르며 각 구성 요소가해야 할 일의 가장 기본적인 버전으로 취급되어야합니다.
Plato는 딥 러닝 프레임 워크를 사용하여 온라인 (상호 작용 중) 또는 오프라인 (데이터) 방식의 에이전트 구성 요소 모듈 교육을 지원합니다. 플라톤의 인터페이스 입력/출력이 존중되는 한 거의 모든 모델을 플라톤에로드 할 수 있습니다. 예를 들어, 모델이 사용자 정의 NLU 모듈 인 경우 Plato의 NLU Abstract Class ( plato.agent.component.nlu )에서 상속하고 필요한 추상 방법을 구현하면됩니다.
온라인 학습, 디버깅 및 평가를 촉진하기 위해 Plato는 이전 대화 상태에 대한 정보, 현재 대화 상태, 현재 대화 상태, 수신 및 발언, 수신 된 보상, 수령 된 보상 및 기타 스트러스를 포함하여 사용될 수없는 몇 가지 다른 구조를 포함하는 대화 에피소드 레코더 ( plato.utilities.dialogue_episode_recorder )라는 구조에서 내부 경험을 추적합니다. 카테고리.
대화가 끝나거나 지정된 간격으로 각 대화 에이전트는 각 내부 구성 요소의 Train () 기능을 호출하여 대화 경험을 교육 데이터로 전달합니다. 그런 다음 각 구성 요소는 교육에 필요한 부품을 선택합니다.
플라톤 내부에서 구현 된 학습 알고리즘을 사용하려면 DSTC2 데이터와 같은 외부 데이터 가이 플라톤 경험에 구문 분석되어 교육중인 해당 구성 요소에 의해로드되어 사용될 수 있어야합니다.
또는 사용자는 데이터를 구문 분석하고 플라톤 외부의 모델을 훈련시키고 플라톤 에이전트에 사용하려는 경우 훈련 된 모델을 간단히로드 할 수 있습니다.
온라인 교육은 사용자가 훈련하려는 각 구성 요소의 구성에서 'Train'플래그를 'True'로 뒤집는 것만 큼 쉽습니다.
데이터에서 훈련하려면 사용자는 단순히 데이터 세트에서 구문 분석 한 경험을로드해야합니다. Plato는 DSTC2 및 Metalwoz 데이터 세트에 대한 예제 파서를 제공합니다. 플라톤에서 오프라인 교육을 위해이 파서를 사용하는 방법의 예로, 우리는 DSTC2 데이터 세트를 사용하여 2 차 Dialogue State Tracking Challenge 웹 사이트에서 얻을 수 있습니다.
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
다운로드가 완료되면 파일을 압축해야합니다. 이 데이터 세트를 구문 분석하기위한 구성 파일은 example/config/parser/Parse_DSTC2.yaml 에서 제공됩니다. example/config/parser/Parse_DSTC2.yaml 에서 data_path 의 값을 먼저 편집하여 다운로드 한 데이터를 구문 분석하여 DSTC2 데이터를 다운로드하고 압축 한 곳으로 향하는 경로를 가리킬 수 있습니다. 다음으로 구문 분석 스크립트를 다음과 같이 실행할 수 있습니다.
plato parse --config Parse_DSTC2.yaml
또는 자신의 구성 파일을 작성하고 해당 파일에 절대 주소를 명령으로 전달할 수 있습니다.
plato parse --config <absolute pass to parse config file>
이 명령을 실행하면 DSTC2에 대한 구문 분석 스크립트 ( plato/utilities/parser/parse_dstc2.py 에 거주)를 실행 하고이 리포지토리의 루트 디렉토리의 data 디렉토리에서 사용자 및 시스템에 대한 대화 상태 추적기, NLU 및 NLG에 대한 교육 데이터를 생성합니다. 이제이 구문 분석 된 데이터는 플라톤의 다양한 구성 요소에 대한 모델을 훈련시키는 데 사용될 수 있습니다.
플라톤 에이전트의 각 구성 요소를 훈련시키는 몇 가지 방법이 있습니다. 온라인 (에이전트가 다른 에이전트, 시뮬레이터 또는 사용자와 상호 작용함에 따라) 또는 오프라인. 또한 플라톤에서 구현 된 알고리즘을 사용할 수 있거나 Tensorflow, Pytorch, Keras, Ludwig 등과 같은 외부 프레임 워크를 사용할 수 있습니다.
Ludwig는 오픈 소스 딥 러닝 프레임 워크로 코드를 쓰지 않고 모델을 훈련시킬 수 있습니다. 데이터를 .csv 파일로 구문 분석하고, Ludwig Config (YAML) 만 만들고 원하는 아키텍처를 설명하고 .csv 및 기타 매개 변수에서 사용할 수있는 기능을 설명한 다음 단기에서 명령을 실행하면됩니다.
Ludwig는 또한 플라톤이 호환되는 API를 제공합니다. 이를 통해 Plato는 Ludwig 모델과 통합, 즉 모델을로드하거나 저장하고 훈련 및 쿼리 할 수 있습니다.
이전 섹션에서 플라톤의 DSTC2 파서는 NLU 및 NLG를 훈련시키는 데 사용할 수있는 일부 .csv 파일을 생성했습니다. 시스템에는 NLU .csv 파일 ( data/DSTC2_NLU_sys.csv )과 사용자 ( data/DSTC2_NLU_usr.csv )가 하나 있습니다. 이것들은 다음과 같습니다.
| 성적 증명서 | 의지 | iob |
|---|---|---|
| 채식 음식을 제공하는 비싼 식당 | 알리다 | B-inform-picerange ooo b-inform-food o |
| 채식 음식 | 알리다 | B-inform-food o |
| 아시아 동양의 음식 유형 | 알리다 | B-inform-food i-inform-food ooo |
| 비싼 식당 아시아 음식 | 알리다 | B-inform-picerange ooo |
NLU 모델을 교육하려면 다음과 같은 구성 파일을 작성해야합니다.
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
이 구성 파일의 예는 example/config/ludwig/ludwig_nlu_train.yaml 에 존재합니다. 훈련 작업은 다음을 수행하여 시작할 수 있습니다.
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
다음 단계는 애플리케이션 구성에 모델을로드하는 것입니다. example/config/application/CamRest_model_nlu.yaml 에서는 모델 기반 NLU가 있고 다른 구성 요소가 ML 기반이 아닌 응용 프로그램 구성을 제공합니다. Ludwig를 실행했을 때 --output_directory 인수에 제공 한 값으로 모드 ( model_path )로가는 경로를 업데이트하면 에이전트가 NLU에 사용해야하는 NLU 모델을 지정할 수 있습니다.
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
모델이 작동하는지 테스트합니다.
plato run --config CamRest_model_nlu.yaml
DSTC2 Data Parser는 DST에 사용할 수있는 두 개의 .csv 파일을 생성했습니다 : DST_sys.csv 및 DST_usr.csv 는 다음과 같습니다.
| dst_prev_food | DST_PREV_AREA | DST_PREV_PRICERANGE | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | DST_AREA | DST_PRICERANGE | DST_REQ_SLOT |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 없음 | 없음 | 없음 | 알리다 | 없음 | 없음 | 채식 | 값비싼 | 채식 | 없음 | 값비싼 | 없음 |
| 채식 | 없음 | 값비싼 | 알리다 | 없음 | 없음 | 채식 | 없음 | 채식 | 없음 | 값비싼 | 없음 |
| 채식 | 없음 | 값비싼 | 알리다 | 없음 | 없음 | 아시아 동양 | 없음 | 아시아 동양 | 없음 | 값비싼 | 없음 |
| 아시아 동양 | 없음 | 값비싼 | 알리다 | 없음 | 없음 | 아시아 동양 | 값비싼 | 아시아 동양 | 없음 | 값비싼 | 없음 |
기본적으로 파서는 이전 대화 상태, NLU의 입력 및 결과 대화 상태를 추적합니다. 그런 다음 이것을 Ludwig에 공급하여 대화 상태 추적기를 훈련시킬 수 있습니다. example/config/ludwig/ludwig_dst_train.yaml 에서도 찾을 수있는 Ludwig 구성은 다음과 같습니다.
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
이제 우리는 Ludwig로 모델을 훈련시켜야합니다.
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
모델 기반 DST로 플라톤 에이전트를 실행하십시오.
plato run --config CamRest_model_dst.yaml
물론 다른 아키텍처 및 교육 매개 변수를 실험 할 수 있습니다.
지금까지 우리는 외부 프레임 워크 (예 : Ludwig)를 사용하여 플라톤 에이전트의 구성 요소를 훈련시키는 방법을 보았습니다. 이 섹션에서는 Plato의 내부 알고리즘을 사용하여 대화 정책을 오프라인으로 훈련시키고 감독 학습 및 온라인으로 강화 학습을 사용하는 방법을 살펴 봅니다.
.csv 파일 외에도 DSTC2 파서는 Plato의 대화 에피소드 레코더를 사용하여 Plato Experience Logs에 구문 분석 대화를 저장했습니다 : logs/DSTC2_system 및 logs/DSTC2_user . 이 로그에는 각 대화, 예를 들어 현재 대화 상태, 행동, 다음 대화 상태, 보상, 입력 발언, 성공 등 각 대화에 대한 정보가 포함되어 있습니다.
이 로그를로드하는 구성 파일을 작성하면됩니다 ( example/config/CamRest_model_supervised_policy_train.yaml ) :
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
우리는이 에이전트를 하나의 대화에 대해서만 실행하지만 로그에서로드 된 경험을 사용하여 100 개의 에포크를 훈련시킵니다.
plato run --config CamRest_model_supervised_policy_train.yaml
교육이 완료된 후 감독 정책을 테스트 할 수 있습니다.
plato run --config CamRest_model_supervised_policy_test.yaml
이전 섹션에서는 감독 된 대화 정책을 훈련시키는 방법을 보았습니다. 이제 강화 알고리즘을 사용하여 강화 학습 정책을 훈련시키는 방법을 확인할 수 있습니다. 이를 위해 구성 파일에서 관련 클래스를 정의합니다.
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
AGENT_0 의 학습 매개 변수와 정책의 주장에 따라 알고리즘 별 매개 변수에 주목하십시오. 그런 다음이 구성으로 플라톤을 호출합니다.
plato run --config CamRest_model_reinforce_policy_train.yaml
훈련 된 정책 모델을 테스트하십시오.
plato run --config CamRest_model_reinforce_policy_test.yaml
Ludwig의 API를 사용하거나 플라톤에서 학습 알고리즘을 구현하여 다른 구성 요소를 온라인으로 교육 할 수도 있습니다.
또한 로그 파일을 로드 하여 모든 구성 요소 및 학습 알고리즘의 경험 풀로 사용할 수 있습니다. 그러나 일부 플라톤 구성 요소에 대한 자체 학습 알고리즘을 구현해야 할 수도 있습니다.
NLG 모듈을 훈련하려면 다음과 같은 구성 파일을 작성해야합니다 (예 : example/config/application/CamRest_model_nlg.yaml ) :
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
그리고 당신의 모델을 훈련 시키십시오 :
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
다음 단계는 플라톤에 모델을로드하는 것입니다. CamRest_model_nlg.yaml 구성 파일로 이동하여 필요한 경우 경로를 업데이트하십시오.
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
모델이 작동하는지 테스트합니다.
plato run --config CamRest_model_nlg.yaml
Ludwig는 호출 될 때마다 새로운 실험 _run_i 디렉토리를 만들 것임을 기억하십시오. Plato의 구성에서 최신 경로를 최신 상태로 유지하십시오.
Ludwig는 또한 온라인으로 모델을 훈련시키는 방법을 제공하므로 실제로는 플라톤의 새로운 딥 러닝 구성 요소를 구축, 훈련 및 평가하기위한 코드를 거의 작성해야합니다.
이 예에서는 여기에서 다운로드 할 수있는 Metalwoz 데이터 세트를 사용합니다.
플라톤은 일반 에이전트를 통해 공동으로 훈련 된 모델을 지원합니다. 여기서 우리는 간단한 SEQ2SEQ 대화 에이전트를 처음부터 생성하는 데 필요한 단계를 볼 수 있습니다. Metalwoz를 예로 사용하려면 다음을 수행해야합니다.
간단한 seq2seq 모델 (텍스트 to 텍스트) 만 훈련하기 때문에 사용자 및 시스템 발화를 추출하려면 구문 분석기가 필요합니다. 이들은 4 단계에서 Ludwig에서 사용할 .CSV 파일에 저장됩니다.
Metalwoz 파서의 간단한 구현은 utilities/parser/Parse_MetalWOZ.py 참조하십시오.
이 파서는 하나의 단일 파일 (하나의 도메인) 만 구문 분석합니다. 그러나 귀하의 요구에 맞게 쉽게 수정할 수 있습니다. 다음은 피자 순서 도메인에 대한 파서가 생산 한 출력 샘플입니다.
| 사용자 | 체계 |
|---|---|
| 안녕 | 안녕하세요 어떻게 도와 드릴까요? |
| 피자를 주문하려면 도움이 필요합니다. | 확실히, 당신은 당신의 주문에 무엇을 추가하고 싶습니까? |
| 버섯, 페퍼로니, 베이컨 토핑이 들어간 피자를 원합니다. | 불행히도,이 위치는 당신이 요청한 베이컨 토핑에서 벗어났습니다. 교체하고 싶은 다른 토핑이 있습니까? |
| 파인애플은 어떻습니까 | 그 토핑을 사용할 수 있습니다. 주문에 버섯, 페퍼로니, 파인애플이 들어간 피자를 추가했습니다. 어떤 크기를 원하십니까? |
| 중간 | 좋아, 업데이트. 주문에 더 추가 하시겠습니까? |
| 그게 다야. 감사합니다 | 자, 당신의 총은 14.99입니다. 피자는 약. 20 분. |
참고 첫 번째 사용자 발화는 실제로 데이터에 존재하지 않습니다. 그러나 우리는 시스템의 인사말을 생성하기 위해 모델을 자극 할 무언가가 필요합니다. 빈 문장이나 다른 인사 (또는 이들의 조합)를 사용할 수있었습니다.
그런 다음 다음과 같이 플라톤 구문 분석을 실행할 수 있습니다.
plato parse --config Parse_MetalWOZ.yaml
시작하기 위해 Ludwig를 사용하여 매우 간단한 모델을 훈련시킬 수 있습니다 (여기에서 가장 좋아하는 딥 러닝 프레임 워크를 자유롭게 사용하십시오).
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
Ludwig를 사용하여 선택한 아키텍처를 반영 하여이 구성을 수정할 수 있습니다.
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
이 클래스는 단순히 모델의로드를 처리하고 적절하게 쿼리하고 출력을 적절하게 포맷해야합니다. 우리의 경우, 입력 텍스트를 Pandas Dataframe으로 래핑하고 출력에서 예측 된 토큰을 잡고 반환 할 문자열에 결합해야합니다. 여기에서 클래스를 참조하십시오 : plato.agent.component.joint_model.metal_woz_seq2seq.py 참조하십시오
텍스트를 통해 seq2seq 에이전트와 상호 작용하는 예제 일반 구성 파일은 example/config/application/metalwoz_generic.yaml 참조하십시오. 다음과 같이 시도해 볼 수 있습니다.
plato run --config metalwoz_text.yaml
필요한 경우 숙련 된 모델로의 경로를 업데이트해야 합니다 ! 기본 경로는 Plato의 루트 디렉토리에서 Ludwig Train 명령을 실행한다고 가정합니다.
플라톤의 주요 기능 중 하나는 두 에이전트가 서로 상호 작용할 수있게합니다. 각 에이전트는 다른 역할 (예 : 시스템 및 사용자), 다른 목표를 가질 수 있으며 다른 보상 신호를받을 수 있습니다. 에이전트가 협력하는 경우, 이들 중 일부는 공유 할 수 있습니다 (예 : 성공적인 대화를 구성하는 요소).
케임브리지 레스토랑 도메인에서 여러 플라톤 에이전트를 운영하려면 에이전트의 대화 정책을 훈련시키고 테스트하기위한 다음 명령을 실행합니다.
교육 단계 : 2 정책 (각 대리인의 1 명)이 교육을받습니다. 이 정책은 늑대 알고리즘을 사용하여 훈련됩니다.
plato run --config MultiAgent_train.yaml
테스트 단계 : 교육 단계에서 훈련 된 정책을 사용하여 두 에이전트간에 대화를 만듭니다.
plato run --config MultiAgent_test.yaml
기본 컨트롤러는 현재 두 가지 에이전트 상호 작용을 허용하지만 여러 에이전트 (예 : 각 에이전트가 다른 에이전트에 출력을 방송하는 블랙 보드 아키텍처를 사용한)를 여러 에이전트로 확장하는 것이 매우 간단합니다. 이는 모든 장치가 에이전트 인 Smart Homes와 같은 시나리오, 다양한 역할과의 다중 사용자 상호 작용 등을 지원할 수 있습니다.
Plato는 두 종류의 사용자 시뮬레이터에 대한 구현을 제공합니다. 하나는 잘 알려진 의제 기반 사용자 시뮬레이터이고, 다른 하나는 데이터에서 관찰 된 사용자 행동을 모방하려는 시뮬레이터입니다. 그러나 연구원들은 가능한 경우 시뮬레이션 사용자를 사용하는 대신 플라톤 (하나는 '시스템', 1 개는 '사용자')으로 두 명의 대화 에이전트를 훈련하도록 권장합니다.
의제 기반 사용자 시뮬레이터는 Schatzmann에 의해 제안 되었으며이 백서에서 자세히 설명되어 있습니다. 개념적으로, 시뮬레이터는 말할 것들의 "의제"를 유지하며, 이는 일반적으로 스택으로 구현됩니다. 시뮬레이터가 입력을 수신 할 때 입력에 대한 응답으로 의제에 어떤 컨텐츠를 눌러야하는지 확인하기 위해 정책 (또는 규칙 세트)을 상담합니다. 일부 하우스 키핑 후 (예 : 더 이상 유효하지 않은 복제 또는 내용을 제거) 시뮬레이터는 응답을 공식화하는 데 사용될 의제에서 하나 이상의 항목을 팝업합니다.
의제 기반 사용자 시뮬레이터에는 오류 시뮬레이션 모듈이있어 음성 인식 / 언어 이해 오류를 시뮬레이션 할 수 있습니다. 일부 확률에 따라 시뮬레이터의 출력 대화 상자 (의도, 슬롯 또는 값) (각각의 다른 확률)를 왜곡합니다. 다음은이 시뮬레이터가받는 전체 매개 변수 목록의 예입니다.
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
이 시뮬레이터는 대화 행위 수준이나 발화 수준에서 작동 할 수있는 간단한 정책 기반 시뮬레이터로 설계되었습니다. 작동 방식을 보여주기 위해 DSTC2 파서는이 시뮬레이터에 대한 정책 파일을 만들었습니다. user_policy_reactive.pkl (사용자 시뮬레이터 상태 대신 시스템 대화 상자에 반응하기 때문에 반응). 이것은 실제로 다음의 간단한 사전입니다.
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
키는 입력 대화 상자 (예 : system 대화 에이전트에서 온)를 나타냅니다. 각 키의 값은 시뮬레이터가 샘플링 할 대화 행위 또는 발화 템플릿에 대한 확률 분포를 나타내는 두 요소의 사전입니다.
예를 보려면 다음 구성을 실행할 수 있습니다.
plato run --config CamRest_dtl_simulator.yaml
기능에 따라 새 모듈을 만드는 두 가지 방법이 있습니다. 예를 들어 모듈이 NLU 또는 대화 정책을 수행하는 새로운 방법을 구현하는 경우 해당 추상 클래스에서 상속되는 클래스를 작성해야합니다.
그러나 모듈이 단일 에이전트 기본 구성 요소 중 하나에 맞지 않는 경우, 예를 들어, 이름이 지정된 엔티티 인식을 수행하거나 텍스트에서 대화를 예측하는 경우 conversational_module _module에서 직접 상속하는 클래스를 작성해야합니다. 그런 다음 구성에서 적절한 패키지 경로, 클래스 이름 및 인수를 제공하여 일반 에이전트를 통해 모듈을로드 할 수 있습니다.
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
조심하세요! 귀하는 일반 구성 파일에 제공된 대로이 모듈의 I/O를 전후에 전후에 적절하게 처리하고 소비 할 수 있음을 보장 할 책임이 있습니다.
플라톤은 또한 모듈의 (논리적으로) 병렬 실행을 지원합니다. 구성에 다음 구조가 필요할 수 있도록하십시오.
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
조심하세요! 병렬로 실행 된 모듈의 출력은 목록에 포장됩니다. 다음 모듈 (예 : MODULE_i+1 )은 이러한 종류의 입력을 처리 할 수 있어야합니다. 제공된 플라톤 모듈은이를 처리하도록 설계되지 않았으므로 여러 소스에서 입력을 처리하려면 사용자 정의 모듈을 작성해야합니다.
Plato는 확장 가능하도록 설계되었으므로 특정 요구에 맞는 대화 상태, 행동, 보상 기능, 알고리즘 또는 기타 구성 요소를 자유롭게 만들 수 있습니다. 구현이 플라톤과 호환되도록 해당 클래스에서 상속하면됩니다.
플라톤은 pysimplegui를 사용하여 그래픽 사용자 인터페이스를 처리합니다. Plato의 예제 GUI는 plato.controller.sgui_controller 에서 구현되며 다음 명령을 사용하여 시도해 볼 수 있습니다.
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
즐기다!


