plato research dialogue system
1.0.0

C'est V0.3.1
Le système de dialogue Platon Research est un cadre flexible qui peut être utilisé pour créer, former et évaluer les agents d'IA conversationnels dans divers environnements. Il prend en charge les interactions via des actes de parole, de texte ou de dialogue et chaque agent conversationnel peut interagir avec les données, les utilisateurs humains ou d'autres agents conversationnels (dans un cadre multi-agent). Chaque composant de chaque agent peut être formé indépendamment en ligne ou hors ligne et Platon offre un moyen facile de contourner pratiquement n'importe quel modèle existant, tant que l'interface de Platon est respectée.
Publication Citations:
Alexandros Papangelis, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino et Gokhan Tur, "Plato Dialog System: A Flexible Conversation AI Research Plateforme", Arxiv Preprint [Paper]
Alexandros Papangelis, Yi-Chia Wang, Piero Molino et Gokhan Tur, «Formation collaborative du modèle de dialogue multi-agent via l'apprentissage par renforcement», Sigdial 2019 [Paper]
Platon a écrit plusieurs dialogues entre les personnages qui se disputent sur un sujet en posant des questions. Beaucoup de ces dialogues présentent Socrate, y compris le procès de Socrate. (Socrate a été acquitté dans un nouveau procès organisé à Athènes, en Grèce, le 25 mai 2012).
V0.2 : La mise à jour principale de V0.1 est que Plato RDS est désormais fourni en tant que package. Cela facilite la création et la maintenance de nouvelles applications de l'IA conversationnelles et tous les tutoriels ont été mis à jour pour refléter cela. Platon est désormais également livré avec une interface graphique en option. Apprécier!
Conceptuellement, un agent conversationnel doit passer par différentes étapes afin de traiter les informations qu'elle reçoit en entrée (par exemple, «Quel temps fait-il aujourd'hui?») Et produire une sortie appropriée («venteux mais pas trop froid».). Les étapes principales, qui correspondent aux principaux composants d'une architecture standard (voir figure 1), sont:
Platon a été conçu pour être aussi modulaire et flexible que possible; Il prend en charge les architectures d'IA conversationnelles traditionnelles et personnalisées, et surtout, permet des interactions multipartites où plusieurs agents, potentiellement avec différents rôles, peuvent interagir les uns avec les autres, s'entraîner simultanément et résoudre des problèmes distribués.
Les figures 1 et 2 ci-dessous représentent des exemples d'architectures d'agent conversationnelles Platon lors de l'interaction avec les utilisateurs humains et avec les utilisateurs simulés, respectivement. Interagir avec les utilisateurs simulés est une pratique courante utilisée dans la communauté de recherche pour relancer l'apprentissage (c'est-à-dire apprendre certains comportements de base avant d'interagir avec les humains). Chaque composant individuel peut être formé en ligne ou hors ligne à l'aide de n'importe quelle bibliothèque d'apprentissage automatique (par exemple, Ludwig, Tensorflow, Pytorch ou vos propres implémentations) car Platon est un cadre universel. Ludwig, la boîte à outils en profondeur open source d'Uber, constitue un bon choix, car il ne nécessite pas d'écriture de code et est entièrement compatible avec Platon.
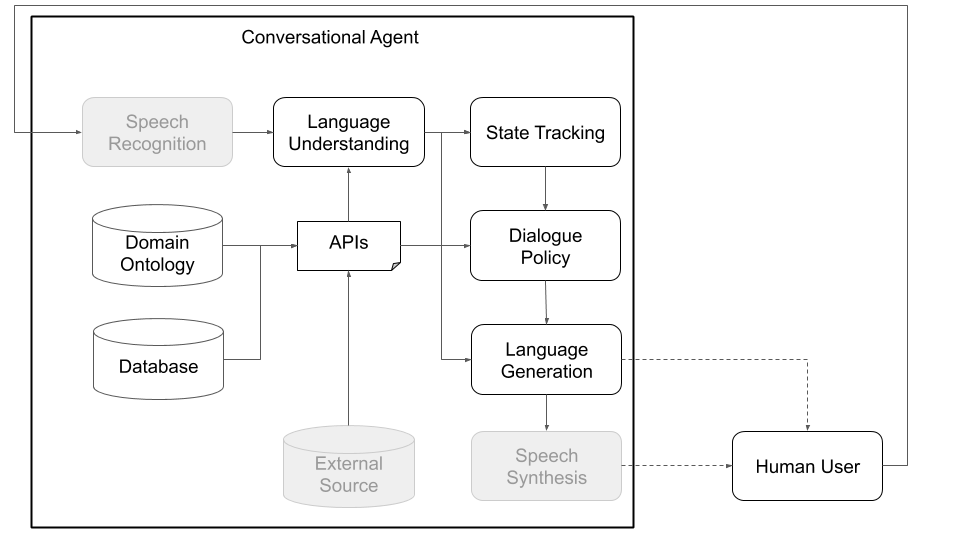 Figure 1: L'architecture modulaire de Platon signifie que tout composant peut être formé en ligne ou hors ligne et peut être remplacé par des modèles personnalisés ou pré-formés. (Les composants grisés de ce diagramme ne sont pas des composants Platon de noyau.)
Figure 1: L'architecture modulaire de Platon signifie que tout composant peut être formé en ligne ou hors ligne et peut être remplacé par des modèles personnalisés ou pré-formés. (Les composants grisés de ce diagramme ne sont pas des composants Platon de noyau.)
 Figure 2: À l'aide d'un utilisateur simulé plutôt qu'un utilisateur humain, comme dans la figure 1, nous pouvons pré-entraîner des modèles statistiques pour les différents composants de Platon. Ceux-ci peuvent ensuite être utilisés pour créer un prototype d'agent conversationnel qui peut interagir avec les utilisateurs humains pour collecter des données plus naturelles qui peuvent être utilisées par la suite pour former de meilleurs modèles statistiques. (Les composants grisés de ce diagramme ne sont pas des composants Platon Core car ils sont soit disponibles comme hors de la boîte tels que Google ASR et Amazon Lex, ou domaine et application spécifiques tels que les bases de données / API personnalisées.)
Figure 2: À l'aide d'un utilisateur simulé plutôt qu'un utilisateur humain, comme dans la figure 1, nous pouvons pré-entraîner des modèles statistiques pour les différents composants de Platon. Ceux-ci peuvent ensuite être utilisés pour créer un prototype d'agent conversationnel qui peut interagir avec les utilisateurs humains pour collecter des données plus naturelles qui peuvent être utilisées par la suite pour former de meilleurs modèles statistiques. (Les composants grisés de ce diagramme ne sont pas des composants Platon Core car ils sont soit disponibles comme hors de la boîte tels que Google ASR et Amazon Lex, ou domaine et application spécifiques tels que les bases de données / API personnalisées.)
En plus des interactions à agent unique, Platon prend en charge des conversations multi-agents où plusieurs agents Platon peuvent interagir et apprendre les uns des autres. Plus précisément, Platon engendrera les agents conversationnels, s'assurera que les entrées et les sorties (ce que chaque agent entend et dit) sont transmises à chaque agent de manière appropriée et gardent une trace de la conversation.
Cette configuration peut faciliter la recherche en apprentissage multi-agents, où les agents doivent apprendre à générer un langage afin d'effectuer une tâche, ainsi que des recherches dans des sous-champs d'interactions multipartites (suivi de l'État de dialogue, prise de virage, etc.). Les principes de dialogue définissent ce que chaque agent peut comprendre (une ontologie des entités ou des significations; par exemple: prix, emplacement, préférences, types de cuisine, etc.) et ce qu'il peut faire (demander plus d'informations, fournir des informations, appeler une API, etc.). Les agents peuvent communiquer sur la parole, le texte ou les informations structurées (actes de dialogue) et chaque agent a sa propre configuration. La figure 3, ci-dessous, illustre cette architecture, décrivant la communication entre deux agents et les différents composants:
 Figure 3: L'architecture de Platon permet une formation simultanée de plusieurs agents, chacun avec des rôles et des objectifs potentiellement différents, et peut faciliter la recherche dans des domaines tels que les interactions multipartites et l'apprentissage multi-agents. (Les composants grisés de ce diagramme ne sont pas des composants Platon de noyau.)
Figure 3: L'architecture de Platon permet une formation simultanée de plusieurs agents, chacun avec des rôles et des objectifs potentiellement différents, et peut faciliter la recherche dans des domaines tels que les interactions multipartites et l'apprentissage multi-agents. (Les composants grisés de ce diagramme ne sont pas des composants Platon de noyau.)
Enfin, Platon prend en charge les architectures personnalisées (par exemple, divisant le NLU en plusieurs composants indépendants) et composants conjointement formés (par exemple, état de texte à dialogue, texte à texte ou toute autre combinaison) via l'architecture d'agent générique illustrée à la figure 4, ci-dessous. Ce mode s'éloigne de l'architecture de l'agent conversationnel standard et prend en charge tout type d'architecture (par exemple, avec des composants conjoints, des composants de texte à texte ou de parole à discours, ou toute autre configuration) et permet de charger des modèles existants ou pré-formés dans Platon.
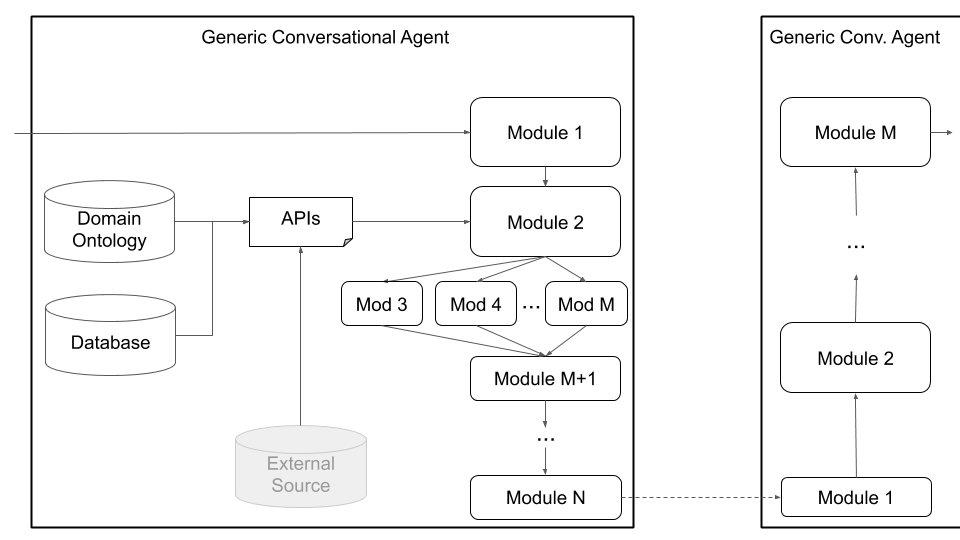 Figure 4: L'architecture d'agent générique de Platon prend en charge un large éventail de personnalisation, y compris les composants conjoints, les composants de la parole à la parole et les composants de texte à texte, qui peuvent tous être exécutés en série ou en parallèle.
Figure 4: L'architecture d'agent générique de Platon prend en charge un large éventail de personnalisation, y compris les composants conjoints, les composants de la parole à la parole et les composants de texte à texte, qui peuvent tous être exécutés en série ou en parallèle.
Les utilisateurs peuvent définir leur propre architecture et / ou brancher leurs propres composants sur Platon en fournissant simplement un nom de classe Python et un chemin de package vers ce module, ainsi que les arguments d'initialisation du modèle. Tout ce que l'utilisateur doit faire est de répertorier les modules de l'ordre, il doit être exécuté et Platon s'occupe du reste, y compris l'enveloppe de l'entrée / sortie, le chaînement des modules et la gestion des dialogues. Platon prend en charge l'exécution en série et parallèle des modules.
Platon soutient également l'optimisation bayésienne des architectures d'IA conversationnelles ou des paramètres de module individuel par l'optimisation bayésienne des structures combinatoires (BOC).
Assurez-vous d'abord que Python version 3.6 ou supérieur soit installé sur votre machine. Ensuite, vous devez cloner le référentiel Platon:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
Ensuite, vous devez installer des pré-requis:
Tensorflow:
pip install tensorflow>=1.14.0
Installez la bibliothèque de récompense de discours pour le support audio:
pip install SpeechRecognition
Pour macOS:
brew install portaudio
brew install gmp
pip install pyaudio
Pour Ubuntu / Debian:
sudo apt-get install python3-pyaudio
Pour Windows: rien n'est nécessaire pour être préinstallé
La prochaine étape consiste à installer Platon. Pour installer Platon, vous devez l'installer directement à partir du code source.
L'installation de Platon à partir du code source permet l'installation en mode modifiable, ce qui signifie que si vous apportez des modifications au code source, il affectera directement l'exécution.
Accédez au répertoire de Platon (où vous avez cloné le référentiel Platon à l'étape précédente).
Nous vous recommandons de créer un nouvel environnement Python. Pour configurer le nouvel environnement Python:
2.1 Installer VirtualEnv
sudo pip install virtualenv
2.2 Créez un nouvel environnement Python:
python3 -m venv </path/to/new/virtual/environment>
2.3 Activez le nouvel environnement Python:
source </path/to/new/virtual/environment/bin>/bin/activate
Installer Platon:
pip install -e .
Pour soutenir la parole, il est nécessaire d'installer Pyaudio, qui a un certain nombre de dépendances qui pourraient ne pas exister sur la machine d'un développeur. Si les étapes ci-dessus sont infructueuses, ce message sur une erreur d'installation de Pyaudio comprend des instructions sur la façon d'obtenir ces dépendances et d'installer Pyaudio.
Le fichier CommonIssues.md contient des problèmes communs et sa résolution qu'un utilisateur pourrait rencontrer lors de l'installation.
Pour exécuter Platon après l'installation, vous pouvez simplement exécuter la commande plato dans le terminal. La commande plato reçoit 4 sous-communs:
runguidomainparse Chacun de ces sous-communs reçoit une valeur pour l'argument --config qui pointe vers un fichier de configuration. Nous décrirons ces fichiers de configuration en détail plus loin dans le document, mais n'oubliez pas que plato run --config et plato gui --config reçoivent un fichier de configuration d'application (des exemples peuvent être trouvés ici: example/config/application/ ), plato domain --config - Config reçoit une configuration de domaine (des exemples pourraient être trouvés ici: example/config/domain/ Exemples plato parse --config example/config/parser/ ).
Pour la valeur qui est transmise à --config Platon vérifie d'abord si la valeur est l'adresse d'un fichier sur la machine. Si c'est le cas, Platon essaie d'analyser ce fichier. Si ce n'est pas le cas, Platon vérifie si la valeur est le nom d'un fichier dans l' example/config/<application, domain, or parser> répertoire.
Pour quelques exemples rapides, essayez les fichiers de configuration suivants pour le domaine des restaurants Cambridge:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
Une application, IE, le système conversationnel, à Platon, contient trois parties principales:
Ces pièces sont déclarées dans un fichier de configuration d'application. Des exemples de tels fichiers de configuration peuvent être trouvés à example/config/application/ Dans le reste de cette section, nous décrivons chacune de ces parties en détail.
Pour implémenter un système de dialogue axé sur les tâches dans Platon, l'utilisateur doit spécifier deux composants qui constituent le domaine du système de dialogue:
Platon fournit une commande pour automatiser ce processus de construction de l'ontologie et de la base de données. Disons par exemple que vous souhaitez construire un agent conversationnel pour un magasin de fleurs, et que vous avez les éléments suivants dans un .csv (ce fichier peut être trouvé à example/data/flowershop.csv ):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
To automatically generate a .db SQL file and a .json Ontology file you need to create a domain configuration file within which you should specify the path to the csv file, output paths, as well as informable, requestable, and system-requestable slots: (eg example/config/domain/create_flowershop_domain.yaml ):
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
et exécutez la commande:
plato domain --config create_flowershop_domain.yaml
Si tout s'est bien passé, vous devriez avoir un flowershop.json et un flowershop.db dans l' example/domains/ répertoire.
Si vous recevez cette erreur:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
Cela signifie que le fichier .db a déjà été créé.
Vous pouvez désormais simplement exécuter les composants factice de Platon comme un chèque de santé mentale et parler à votre agent de boutique de fleurs:
plato run --config flowershop_text.yaml
Les contrôleurs sont des objets qui orchestrent la conversation entre les agents. Le contrôleur instanciera les agents, les initialisera pour chaque dialogue, passera les entrées et les sorties de manière appropriée et suive les statistiques.
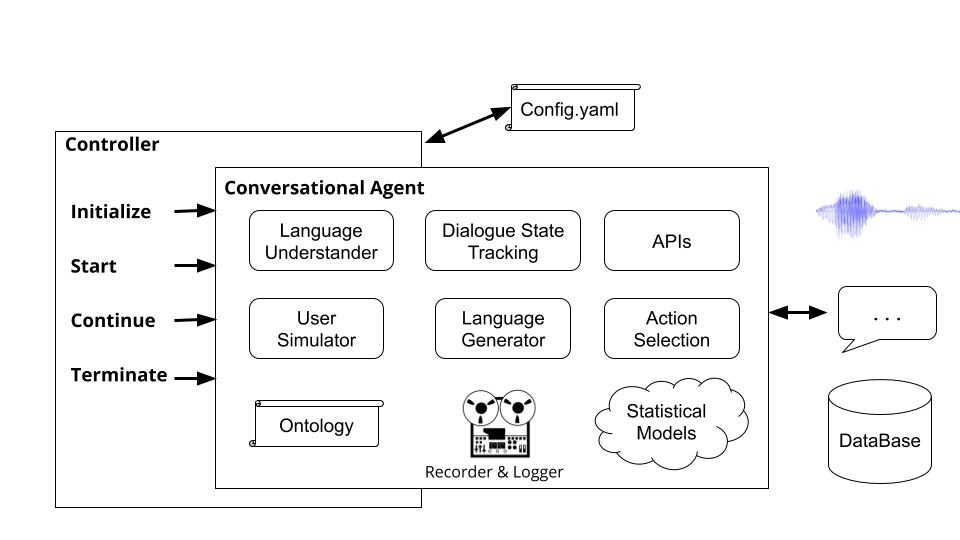
Exécution de la commande plato run exécute le contrôleur de base de Platon ( plato/controller/basic_controller.py ). Cette commande reçoit une valeur pour l'argument --config qui pointe vers un fichier de configuration d'application Platon.
Pour exécuter un agent conversationnel Platon, l'utilisateur doit exécuter la commande suivante avec le fichier de configuration approprié:
plato run --config <FULL PATH TO CONFIG YAML FILE>
Veuillez vous référer à des fichiers de configuration example/config/application/ Par exemple qui contiennent des paramètres de l'environnement et de la ou les agents à créer ainsi que leurs composants. Les exemples de example/config/application/ peuvent être exécutés directement en utilisant uniquement le nom de l'exemple de fichier YAML:
plato run --config <NAME OF A FILE FROM example/config/application/>
Alternativement, un utilisateur pourrait écrire son propre fichier de configuration et exécuter Platon en passant le chemin complet à son fichier de configuration --config :
plato run --config <FULL PATH TO CONFIG YAML FILE>
Pour la valeur qui est transmise à --config Platon vérifie d'abord si la valeur est l'adresse d'un fichier sur la machine. Si c'est le cas, le Platon essaie d'analyser ce fichier. Si ce n'est pas le cas, Platon vérifie si la valeur est le nom d'un fichier dans le répertoire example/config/application .
Chaque application de l'IA conversationnelle dans Platon pourrait avoir un ou plusieurs agents. Chaque agent a un rôle (système, utilisateur, ...) et un ensemble de composants de système de dialogue standard (figure 1), à savoir NLU, Dialog Organisation, Dialogue State Tracker, Policy, NLG et User Simulator.
Un agent pourrait avoir un module explicite pour chacun de ces composants. Alternativement, certains de ces composants pourraient être combinés en un ou plusieurs modules (par exemple, des agents articulaires / de bout en bout) qui peuvent s'exécuter séquentiellement ou en parallèle (figure 4). Les composants de Platon sont définis dans plato.agent.component et tous héritent de plato.agent.component.conversational_module
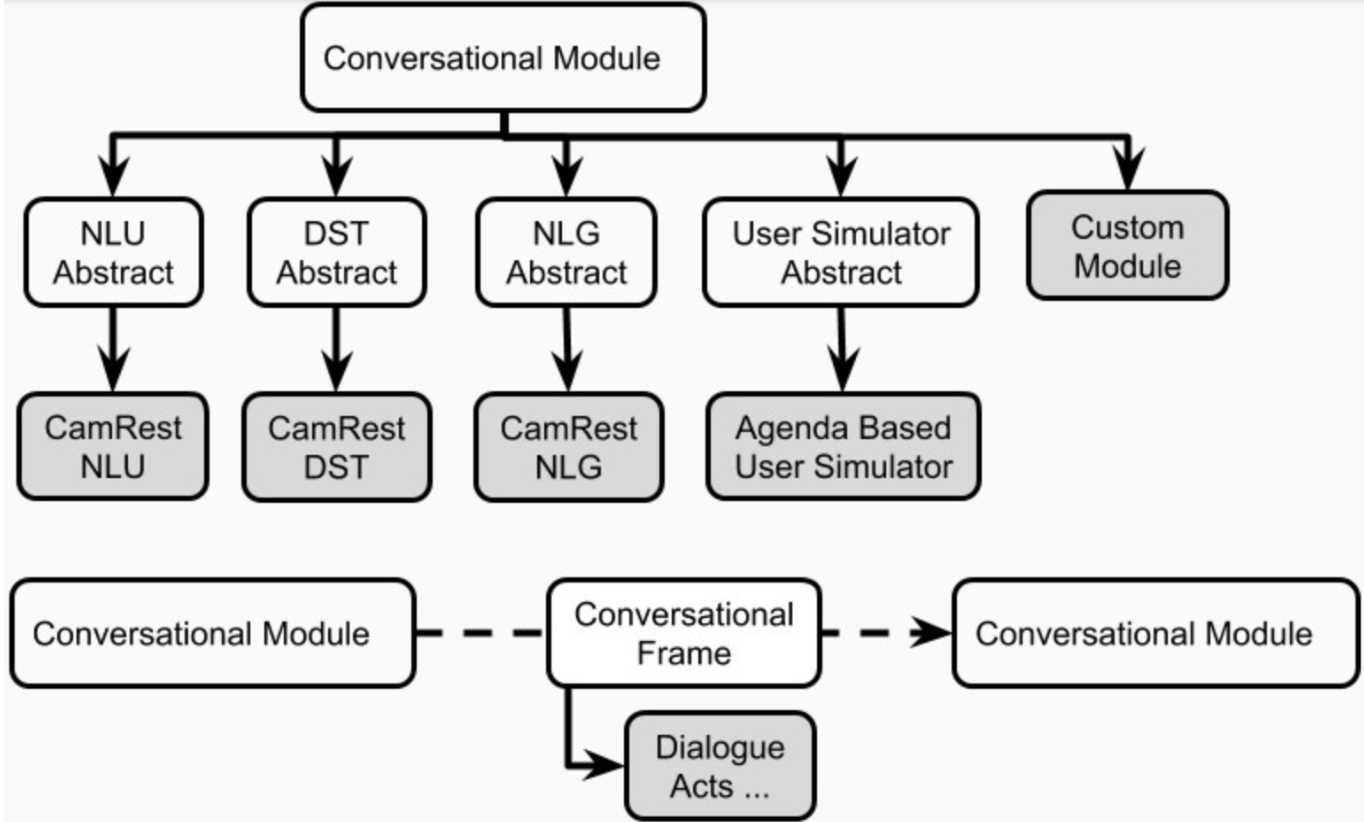 Figure 5. Composantes des agents Platon
Figure 5. Composantes des agents Platon
Notez que toutes les nouvelles implémentations ou modules personnalisés doivent hériter de plato.agent.component.conversational_module .
Chacun de ces modules pourrait être basé sur des règles ou formé. Dans les sous-sections suivantes, nous décrirons comment construire des modules basés sur des règles et formés pour les agents.
Platon fournit des versions basées sur des règles de tous les composants d'un agent conversationnel à remplissage de fentes (SLOT_FILLACH_NLU, SLOT_FILLACH_DST, SLOT_FILL_POLICY, SLOT_FILLING_NLG et la version par défaut de l'Agenda_Based_US). Ceux-ci peuvent être utilisés pour le prototypage rapide, les lignes de base ou les contrôles de santé mentale. Plus précisément, tous ces composants suivent des règles ou des modèles conditionnés à l'ontologie donnée et parfois sur la base de données donnée et doivent être traités comme la version la plus élémentaire de ce que chaque composant doit faire.
Platon soutient la formation des modules des composants des agents d'une manière en ligne (pendant l'interaction) ou hors ligne (à partir de données), en utilisant tout cadre d'apprentissage en profondeur. Pratiquement n'importe quel modèle peut être chargé dans Platon tant que l'entrée / sortie de l'interface de Platon est respectée. Par exemple, si un modèle est un module NLU personnalisé, il doit simplement hériter de la classe abstrait NLU de Platon ( plato.agent.component.nlu ) et implémenter les méthodes abstraites nécessaires.
Pour faciliter l'apprentissage, le débogage et l'évaluation en ligne, Platon garde une trace de son expérience interne dans une structure appelée The Dialog Episode Recorder, ( plato.utilities.dialogue_episode_recorder ) qui contient des informations sur les états de dialogue précédents, les actions prises, les états de dialogue actuels, les énoncés reçus et les énoncés produits, les récompenses reçus et quelques autres structures, notamment un champ personnalisé qui peut être utilisé pour suivre quoi que ce soit autre catégories.
À la fin d'un dialogue ou à des intervalles spécifiés, chaque agent conversationnel appellera la fonction Train () de chacun de ses composants internes, passant l'expérience du dialogue comme données de formation. Chaque composant choisit ensuite les pièces dont il a besoin pour la formation.
Pour utiliser des algorithmes d'apprentissage qui sont mis en œuvre à l'intérieur de Platon, toutes les données externes, telles que les données DSTC2, doivent être analysées dans cette expérience Platon afin qu'elles puissent être chargées et utilisées par le composant correspondant sous formation.
Alternativement, les utilisateurs peuvent analyser les données et former leurs modèles à l'extérieur de Platon et simplement charger le modèle formé lorsqu'ils souhaitent l'utiliser pour un agent Platon.
La formation en ligne est aussi simple que de retourner les drapeaux «Train» à «vrai» dans la configuration de chaque composant que les utilisateurs souhaitent former.
Pour s'entraîner à partir de données, les utilisateurs ont simplement besoin de charger l'expérience qu'ils ont analysé à partir de leur ensemble de données. Platon fournit des exemples d'analyseurs pour les ensembles de données DSTC2 et MetalWoz. À titre d'exemple de la façon d'utiliser ces analyseurs pour une formation hors ligne à Platon, nous utiliserons l'ensemble de données DSTC2, qui peut être obtenu à partir du deuxième site Web de Dialogue State Tracking Challenge:
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
Une fois le téléchargement terminé, vous devez décompresser le fichier. Un fichier de configuration pour l'analyse de cet ensemble de données est fourni à example/config/parser/Parse_DSTC2.yaml . Vous pouvez analyser les données que vous avez téléchargées en modifiant d'abord la valeur de data_path dans example/config/parser/Parse_DSTC2.yaml pour pointer le chemin vers l'endroit où vous avez téléchargé et décompressé les données DSTC2. Ensuite, vous pouvez exécuter le script d'analyse comme suit:
plato parse --config Parse_DSTC2.yaml
Vous pouvez également écrire votre propre fichier de configuration et passer l'adresse absolue à ce fichier à la commande:
plato parse --config <absolute pass to parse config file>
L'exécution de cette commande exécutera le script d'analyse pour DSTC2 (qui vit sous plato/utilities/parser/parse_dstc2.py ) et créera les données de formation pour Dialog State Tracker, NLU et NLG pour l'utilisateur et le système sous le répertoire data dans le répertoire racine de ce référentiel. Maintenant, ces données analysées pourraient être utilisées pour former des modèles pour différents composants de Platon.
Il existe plusieurs façons de former chaque composant d'un agent Platon: en ligne (car l'agent interagit avec d'autres agents, simulateurs ou utilisateurs) ou hors ligne. De plus, vous pouvez utiliser des algorithmes implémentés dans Platon ou vous pouvez utiliser des frameworks externes tels que TensorFlow, Pytorch, Keras, Ludwig, etc.
Ludwig est un cadre d'apprentissage en profondeur open source qui vous permet de former des modèles sans écrire de code. Il vous suffit d'analyser vos données dans des fichiers .csv , de créer une configuration Ludwig (dans YAML), qui décrit l'architecture que vous souhaitez, qui fonctionnait à partir du .csv et d'autres paramètres, puis exécutez simplement une commande dans un terminal.
Ludwig fournit également une API, avec laquelle Platon est compatible. Cela permet à Platon de s'intégrer avec des modèles Ludwig, à savoir charger ou enregistrer les modèles, les former et les interroger.
Dans la section précédente, l'analyseur DSTC2 de Platon a généré certains fichiers .csv qui peuvent être utilisés pour former NLU et NLG. Il existe un fichier NLU .csv pour le système ( data/DSTC2_NLU_sys.csv ) et un pour l'utilisateur ( data/DSTC2_NLU_usr.csv ). Ceux-ci ressemblent à ceci:
| transcription | intention | iob |
|---|---|---|
| restaurant cher qui sert de la nourriture végétarienne | informer | B-Inform-pricerange ooo b-informate |
| nourriture végétarienne | informer | B-Inform-food o |
| type oriental asiatique | informer | B-Inform-Food I-Inform-Food OOO |
| Restaurant cher Alimentation asiatique | informer | B-Inform-pricerange ooo |
Pour la formation d'un modèle NLU, vous devez écrire un fichier de configuration qui ressemble à ceci:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
Un exemple de ce fichier de configuration existe dans example/config/ludwig/ludwig_nlu_train.yaml . Le travail de formation pourrait être lancé par la course:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
L'étape suivante consiste à charger le modèle dans une configuration d'application. Dans example/config/application/CamRest_model_nlu.yaml nous fournissons une configuration d'application qui a un NLU basé sur un modèle et les autres composants sont non basés sur ML. En mettant à jour le chemin d'accès au mode ( model_path ) vers la valeur que vous avez fournie à l'argument --output_directory Lorsque vous exécutez Ludwig, vous pouvez spécifier le modèle NLU que l'agent doit utiliser pour NLU:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
et tester que le modèle fonctionne:
plato run --config CamRest_model_nlu.yaml
L'analyseur de données DSTC2 a généré deux fichiers .csv que nous pouvons utiliser pour DST: DST_sys.csv et DST_usr.csv qui ressemblent à ceci:
| dst_prev_food | dst_prev_area | dst_prev_pricerange | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | dst_area | dst_pricerange | dst_req_slot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| aucun | aucun | aucun | informer | aucun | aucun | végétarien | cher | végétarien | aucun | cher | aucun |
| végétarien | aucun | cher | informer | aucun | aucun | végétarien | aucun | végétarien | aucun | cher | aucun |
| végétarien | aucun | cher | informer | aucun | aucun | oriental asiatique | aucun | oriental asiatique | aucun | cher | aucun |
| oriental asiatique | aucun | cher | informer | aucun | aucun | oriental asiatique | cher | oriental asiatique | aucun | cher | aucun |
Essentiellement, l'analyseur garde une trace de l'état de dialogue précédent, de l'entrée de NLU et de l'état de dialogue qui en résulte. Nous pouvons ensuite nourrir cela en Ludwig pour former un tracker d'État de dialogue. Voici la configuration Ludwig qui peut également être trouvée à example/config/ludwig/ludwig_dst_train.yaml :
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
Nous devons maintenant entraîner notre modèle avec Ludwig:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
et exécuter un agent Platon avec le DST basé sur un modèle:
plato run --config CamRest_model_dst.yaml
Vous pouvez bien sûr expérimenter d'autres architectures et paramètres de formation.
Jusqu'à présent, nous avons vu comment former des composants d'agents Platon en utilisant des cadres externes (c'est-à-dire Ludwig). Dans cette section, nous verrons comment utiliser les algorithmes internes de Platon pour former une politique de dialogue hors ligne, en utilisant l'apprentissage supervisé et en ligne, en utilisant l'apprentissage du renforcement.
Outre les fichiers .csv , le Parser DSTC2 a utilisé l'enregistreur d'épisode de dialogue de Platon pour enregistrer également les dialogues analysés dans Platon Experience Logs ici: logs/DSTC2_system et logs/DSTC2_user . Ces journaux contiennent des informations sur chaque dialogue, par exemple l'état de dialogue actuel, l'action prise, le prochain état de dialogue, la récompense observée, l'énoncé d'entrée, le succès, etc. Ces journaux peuvent être directement chargés dans un agent conversationnel et peuvent être utilisés pour remplir le pool d'expérience.
Tout ce que vous avez à faire est d'écrire un fichier de configuration qui charge ces journaux ( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
Notez que nous exécutons cet agent uniquement pour un dialogue mais nous entraînons pour 100 époques, en utilisant l'expérience qui est chargée à partir des journaux:
plato run --config CamRest_model_supervised_policy_train.yaml
Une fois la formation terminée, nous pouvons tester notre politique supervisée:
plato run --config CamRest_model_supervised_policy_test.yaml
Dans la section précédente, nous avons vu comment former une politique de dialogue supervisée. Nous pouvons maintenant voir comment nous pouvons former une politique d'apprentissage de renforcement, en utilisant l'algorithme de renforcement. Pour ce faire, nous définissons la classe pertinente dans le fichier de configuration:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
Remarquez les paramètres d'apprentissage sous AGENT_0 et les paramètres spécifiques aux algorithmiques sous les arguments de la politique. Nous appelons ensuite Platon avec cette configuration:
plato run --config CamRest_model_reinforce_policy_train.yaml
et tester le modèle de politique formé:
plato run --config CamRest_model_reinforce_policy_test.yaml
Notez que d'autres composants peuvent également être formés en ligne, soit en utilisant l'API de Ludwig, soit en mettant en œuvre les algorithmes d'apprentissage de Platon.
Notez également que les fichiers journaux peuvent être chargés et utilisés comme pool d'expérience pour n'importe quel composant et algorithme d'apprentissage. Cependant, vous devrez peut-être mettre en œuvre vos propres algorithmes d'apprentissage pour certains composants Platon.
Pour former un module NLG, vous devez écrire un fichier de configuration qui ressemble à ceci (par example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
Et entraînez votre modèle:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
L'étape suivante consiste à charger le modèle dans Platon. Accédez au fichier de configuration CamRest_model_nlg.yaml et mettez à jour le chemin si nécessaire:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
et tester que le modèle fonctionne:
plato run --config CamRest_model_nlg.yaml
N'oubliez pas que Ludwig créera un nouveau répertoire Experiment_RUN_I à chaque fois qu'il est appelé, alors assurez-vous de garder le bon chemin dans la configuration de Platon à jour.
Notez que Ludwig propose également une méthode pour former votre modèle en ligne, donc dans la pratique, vous devez écrire très peu de code pour construire, former et évaluer un nouveau composant d'apprentissage en profondeur à Platon.
Pour cet exemple, nous utiliserons l'ensemble de données MetalWoz que vous pouvez télécharger à partir d'ici.
Platon soutient les modèles formés conjointement par le biais d'agents génériques. Ici, nous verrons les étapes nécessaires pour créer un simple agent conversationnel SEQ2SEQ à partir de zéro. En utilisant Metalwoz comme exemple, nous devons faire ce qui suit:
Comme nous ne formons que un modèle SEQ2SEQ simple (texte au texte), nous avons besoin de notre analyseur pour extraire les énoncés utilisateur et système. Ceux-ci seront enregistrés dans des fichiers .csv qui seront utilisés par Ludwig à l'étape 4.
Pour une simple implémentation d'un analyseur de métalwoz, voir utilities/parser/Parse_MetalWOZ.py
Veuillez noter que cet analyseur analysera un seul fichier (un domaine). Vous pouvez facilement le modifier pour répondre à vos besoins. Voici un échantillon de la sortie produite par l'analyseur pour le domaine de commande de pizza:
| utilisateur | système |
|---|---|
| Salut | Bonjour comment puis-je vous aider? |
| J'ai besoin de passer une commande pour une pizza a besoin d'aide | Certes, que souhaitez-vous ajouter à votre commande? |
| Je veux une pizza avec des garnitures de champignons, de pepperoni et de bacon | Malheureusement, cet emplacement est hors de la garniture de bacon que vous avez demandé. Y aurait-il une garniture différente avec laquelle vous aimeriez le remplacer? |
| Et l'ananas | Cette garniture est disponible. J'ai ajouté une pizza avec des champignons, du pepperoni et de l'ananas à votre commande. Quelle taille aimeriez-vous? |
| Moyen | Très bien, mis à jour. Souhaitez-vous en ajouter plus à votre commande? |
| C'est tout, merci | Très bien, votre total est de 14,99. Votre pizza sera prête pour le ramassage en env. 20 minutes. |
Remarque Le premier énoncé de l'utilisateur n'existe pas réellement dans les données. Cependant, nous avons besoin de quelque chose pour inciter le modèle à produire la salutation du système - nous aurions pu utiliser une phrase vide, ou toute autre salutation (ou une combinaison de celles-ci).
Vous pouvez ensuite exécuter Platon Parse comme suit:
plato parse --config Parse_MetalWOZ.yaml
Pour commencer, nous pouvons former un modèle très simple en utilisant Ludwig (n'hésitez pas à utiliser votre cadre de Deep Learning préféré ici):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
Vous pouvez modifier cette configuration pour refléter l'architecture de votre choix et votre formation à l'aide de Ludwig:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
Cette classe a simplement besoin de gérer le chargement du modèle, de le remettre en question de manière appropriée et de formater sa sortie de manière appropriée. Dans notre cas, nous devons envelopper le texte d'entrée dans un Pandas DataFrame, saisir les jetons prévus de la sortie et les rejoindre dans une chaîne qui sera retournée. Voir la classe ici: plato.agent.component.joint_model.metal_woz_seq2seq.py
Voir example/config/application/metalwoz_generic.yaml pour un exemple de fichier de configuration générique qui interagit avec l'agent SEQ2SEQ sur le texte. Vous pouvez l'essayer comme suit:
plato run --config metalwoz_text.yaml
N'oubliez pas de mettre à jour le chemin vers votre modèle formé si nécessaire! Le chemin par défaut suppose que vous exécutez la commande Ludwig Train à partir du répertoire racine de Platon.
L'une des principales caractéristiques de Platon permet à deux agents d'interagir les uns avec les autres. Chaque agent peut avoir un rôle différent (par exemple, système et utilisateur), différents objectifs et recevoir différents signaux de récompense. Si les agents coopèrent, certains d'entre eux peuvent être partagés (par exemple, ce qui constitue un dialogue réussi).
Pour exécuter plusieurs agents Platon sur le domaine des restaurants de Cambridge, nous exécutons les commandes suivantes pour former les politiques de dialogue des agents et les tester:
Phase de formation: 2 politiques (1 pour chaque agent) sont formées. Ces politiques sont formées à l'aide de l'algorithme de loup:
plato run --config MultiAgent_train.yaml
Phase de test: utilise la politique formée à la phase de formation pour créer des dialogues entre deux agents:
plato run --config MultiAgent_test.yaml
Bien que le contrôleur de base autorise actuellement l'interaction à deux agents, il est assez simple de l'étendre à plusieurs agents (par exemple avec une architecture à tableau noir, où chaque agent diffuse sa sortie à d'autres agents). Cela peut prendre en charge des scénarios tels que Smart Homes, où chaque appareil est un agent, des interactions multi-utilisateurs avec divers rôles, et plus encore.
Platon fournit des implémentations pour deux types de simulateurs utilisateur. L'un est le simulateur d'utilisateur basé sur l'agenda très connu, et l'autre est un simulateur qui tente d'imiter le comportement des utilisateurs observé dans les données. Cependant, nous encourageons les chercheurs à simplement former deux agents conversationnels avec Platon (l'un étant un «système» et l'un étant un «utilisateur») au lieu d'utiliser des utilisateurs simulés, lorsque cela est possible.
Le simulateur d'utilisateur basé sur l'agenda a été proposé par Schatzmann et est expliqué en détail dans cet article. Conceptuellement, le simulateur maintient un "programme" de choses à dire, qui est généralement implémentée comme une pile. Lorsque le simulateur reçoit une entrée, il consulte sa politique (ou son ensemble de règles) pour voir quel contenu pousser dans l'ordre du jour, en réponse à l'entrée. Après certains ménages (par exemple, supprimant les doublons ou le contenu qui n'est plus valide), le simulateur fera éclater un ou plusieurs éléments de l'ordre du jour qui sera utilisé pour formuler sa réponse.
Le simulateur d'utilisateur basé sur l'agenda dispose également d'un module de simulation d'erreur, qui peut simuler les erreurs de reconnaissance vocale / compréhension du langage. Sur la base de certaines probabilités, il déformera les actes de dialogue de sortie du simulateur - l'intention, la fente ou la valeur (probabilité différente pour chacun). Voici un exemple de la liste complète des paramètres que ce simulateur reçoit:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
Ce simulateur a été conçu pour être un simulateur simple basé sur des politiques, qui peut fonctionner au niveau de la loi de dialogue ou au niveau de l'énoncé. Pour démontrer comment cela fonctionne, le Parser DSTC2 a créé un fichier de stratégie pour ce simulateur: user_policy_reactive.pkl (réactif car il réagit aux actes de dialogue du système au lieu de l'état du simulateur utilisateur). Il s'agit en fait d'un simple dictionnaire de:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
La clé représente la loi sur le dialogue d'entrée (par exemple provenant de l'agent conversationnel system ). La valeur de chaque clé est un dictionnaire de deux éléments, représentant les distributions de probabilité sur les actes de dialogue ou les modèles d'énoncé d'où le simulateur échantillonnera.
Pour voir un exemple, vous pouvez exécuter la configuration suivante:
plato run --config CamRest_dtl_simulator.yaml
Il existe deux façons de créer un nouveau module en fonction de sa fonction. Si un module, par exemple, implémente une nouvelle façon d'effectuer une politique NLU ou de dialogue, vous devez écrire une classe qui hérite de la classe abstraite correspondante.
Si, cependant, un module ne correspond pas à l'un des composants de base de l'agent unique, par exemple, il effectue une reconnaissance d'entité nommée ou prédit des actes de dialogue à partir du texte, vous devez écrire une classe qui hérite directement du conversational_module . Vous pouvez ensuite charger le module via un agent générique en fournissant le chemin du package, le nom de classe et les arguments appropriés dans la configuration.
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
Sois prudent! Vous êtes responsable de garantir que les E / S de ce module peuvent être traitées et consommées de manière appropriée par des modules avant et après, comme prévu dans votre fichier de configuration générique.
Platon prend également en charge l'exécution parallèle (logiquement) des modules. Pour activer que vous devez avoir la structure suivante dans votre configuration:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
Sois prudent! Les sorties des modules exécutées en parallèle seront emballées dans une liste. Le module suivant (par exemple MODULE_i+1 ) devra être capable de gérer ce type d'entrée. Les modules Platon fournis ne sont pas conçus pour gérer cela, vous devrez écrire un module personnalisé pour traiter les entrées à partir de plusieurs sources.
Platon est conçu pour être extensible, alors n'hésitez pas à créer vos propres états de dialogue, actions, fonctions de récompense, algorithmes ou tout autre composant pour répondre à vos besoins spécifiques. Vous n'avez qu'à hériter de la classe correspondante pour vous assurer que votre implémentation est compatible avec Platon.
Platon utilise Pysimplegui pour gérer les interfaces utilisateur graphiques. Un exemple d'interface graphique pour Platon est implémenté sur plato.controller.sgui_controller et vous pouvez l'essayer en utilisant la commande suivante:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
Apprécier!


