plato research dialogue system
1.0.0

これはv0.3.1です
プラトンリサーチダイアログシステムは、さまざまな環境で会話型AIエージェントの作成、訓練、評価に使用できる柔軟なフレームワークです。音声、テキスト、または対話行為を介した相互作用をサポートし、各会話エージェントはデータ、人間のユーザー、または他の会話エージェント(マルチエージェント設定)と対話できます。すべてのエージェントのすべてのコンポーネントは、オンラインまたはオフラインで独立してトレーニングでき、プラトンはプラトンのインターフェイスが順守されている限り、事実上すべてのモデルを簡単に包む方法を提供します。
出版物の引用:
Alexandros Papangelis、Mahdi Namazifar、Chandra Khatri、Yi-Chia Wang、Piero Molino、およびGokhan Tur、「プラトンダイアログシステム:柔軟な会話AI研究プラットフォーム」、Arxiv Preprint [Paper]
Alexandros Papangelis、Yi-Chia Wang、Piero Molino、およびGokhan Tur、「補強学習による共同マルチエージェントダイアログモデルトレーニング」、Sigdial 2019 [Paper]
プラトンは、質問をすることでトピックについて議論するキャラクターの間にいくつかの対話を書きました。これらの対話の多くは、ソクラテスの裁判を含むソクラテスを特徴としています。 (ソクラテスは、2012年5月25日にギリシャのアテネで開催された新しい裁判で無罪となった)。
V0.2 :V0.1からのメインアップデートは、Plato RDSがパッケージとして提供されることです。これにより、新しい会話型AIアプリケーションの作成と維持が簡単になり、これを反映するためにすべてのチュートリアルが更新されました。プラトンには現在、オプションのGUIが付属しています。楽しむ!
概念的には、会話エージェントは、入力として受け取る情報(「今日の天気はどうですか?」)を処理し、適切な出力(「風が強いが寒すぎない」)を生成するために、さまざまな手順を実行する必要があります。標準アーキテクチャの主なコンポーネントに対応する主要な手順(図1を参照)は次のとおりです。
プラトンは、可能な限りモジュールで柔軟になるように設計されています。従来の会話およびカスタム会話のAIアーキテクチャをサポートし、重要なことには、潜在的に異なる役割を持つ複数のエージェントが互いに相互作用し、同時にトレーニングし、分布した問題を解決できるマルチパーティの相互作用を可能にすることです。
以下の図1および2は、それぞれ人間のユーザーやシミュレーションユーザーと対話するときのプラトンの会話エージェントアーキテクチャの例を示しています。シミュレートされたユーザーと対話することは、研究コミュニティで学習をジャンプするために使用される一般的な実践です(つまり、人間と対話する前にいくつかの基本的な行動を学びます)。プラトンは普遍的なフレームワークであるため、各コンポーネントは、機械学習ライブラリ(たとえば、Ludwig、Tensorflow、Pytorch、または独自の実装)を使用して、オンラインまたはオフラインでトレーニングすることができます。 UberのオープンソースディープラーニングツールボックスであるLudwigは、コードを作成する必要がなく、プラトンと完全に互換性があるため、良い選択をします。
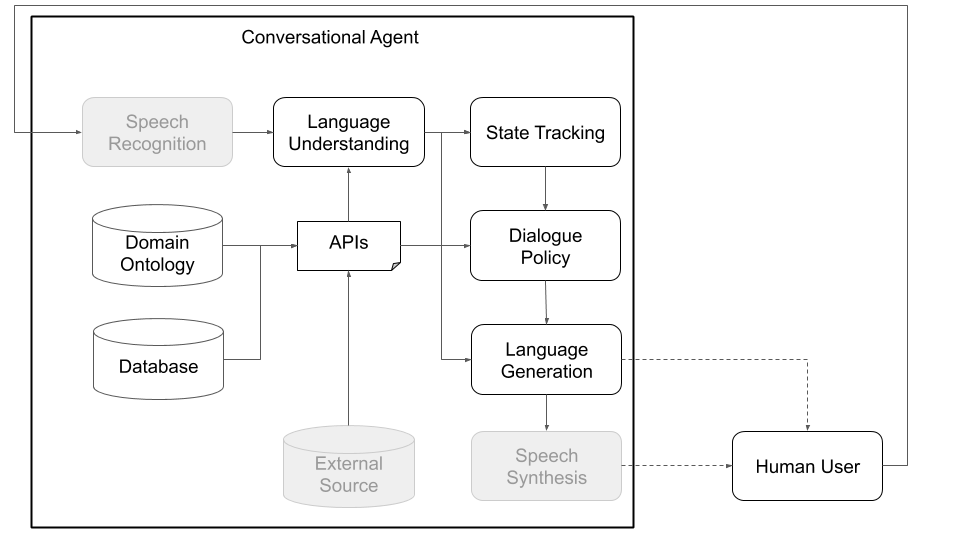 図1:プラトンのモジュラーアーキテクチャは、任意のコンポーネントをオンラインまたはオフラインでトレーニングできることを意味し、カスタムモデルまたは事前に訓練されたモデルに置き換えることができます。 (この図の灰色の成分は、プラトンのコアコンポーネントではありません。)
図1:プラトンのモジュラーアーキテクチャは、任意のコンポーネントをオンラインまたはオフラインでトレーニングできることを意味し、カスタムモデルまたは事前に訓練されたモデルに置き換えることができます。 (この図の灰色の成分は、プラトンのコアコンポーネントではありません。)
 図2:図1のように、人間のユーザーではなくシミュレートされたユーザーを使用すると、プラトンのさまざまなコンポーネントの統計モデルを事前に訓練できます。これらを使用して、人間のユーザーと対話して、より良い統計モデルをトレーニングするために使用できるより自然なデータを収集できるプロトタイプ会話エージェントを作成できます。 (この図の灰色のコンポーネントは、Google ASRやAmazon Lexなどの箱から出して利用できるため、プラトンコアコンポーネントではありません。
図2:図1のように、人間のユーザーではなくシミュレートされたユーザーを使用すると、プラトンのさまざまなコンポーネントの統計モデルを事前に訓練できます。これらを使用して、人間のユーザーと対話して、より良い統計モデルをトレーニングするために使用できるより自然なデータを収集できるプロトタイプ会話エージェントを作成できます。 (この図の灰色のコンポーネントは、Google ASRやAmazon Lexなどの箱から出して利用できるため、プラトンコアコンポーネントではありません。
シングルエージェントの相互作用に加えて、プラトンは複数のプラトンのエージェントが相互作用し、互いに学習できるマルチエージェントの会話をサポートしています。具体的には、プラトンは会話エージェントを生み出し、入力と出力(各エージェントが聞いて言うこと)が各エージェントに適切に渡され、会話を追跡することを確認します。
このセットアップは、エージェントがタスクを実行するために言語を生成する方法を学ぶ必要があるマルチエージェント学習の研究を容易にすることができ、マルチパーティの相互作用のサブフィールドでの研究(対話状態追跡、ターンテイクなど)。対話の原則は、各エージェントが理解できること(エンティティや意味のオントロジー、例:価格、場所、好み、料理の種類など)とそれができることを定義します(詳細を求めて、情報を提供し、APIを呼び出すなど)。エージェントは、音声、テキスト、または構造化された情報(対話行為)を介して通信でき、各エージェントには独自の構成があります。以下の図3は、このアーキテクチャを示しており、2つのエージェントとさまざまなコンポーネント間の通信の概要を示しています。
 図3:プラトンのアーキテクチャは、それぞれが潜在的に異なる役割と目的を持つ複数のエージェントの同時トレーニングを許可し、マルチパーティの相互作用やマルチエージェント学習などの分野での研究を促進することができます。 (この図の灰色の成分は、プラトンのコアコンポーネントではありません。)
図3:プラトンのアーキテクチャは、それぞれが潜在的に異なる役割と目的を持つ複数のエージェントの同時トレーニングを許可し、マルチパーティの相互作用やマルチエージェント学習などの分野での研究を促進することができます。 (この図の灰色の成分は、プラトンのコアコンポーネントではありません。)
最後に、プラトンは、図4に示す一般的なエージェントアーキテクチャを介して、カスタムアーキテクチャ(たとえば、NLUを複数の独立したコンポーネントに分割する)と共同訓練を受けたコンポーネント(テキスト間の状態、テキストツーテキスト、またはその他の組み合わせ)をサポートしています。このモードは、標準の会話エージェントアーキテクチャから離れて移動し、あらゆる種類のアーキテクチャ(たとえば、共同コンポーネント、テキストツーテキスト、またはスピーチツースピーチコンポーネント、またはその他のセットアップをサポートし、既存または事前に訓練されたモデルをプラトンに読み込むことができます。
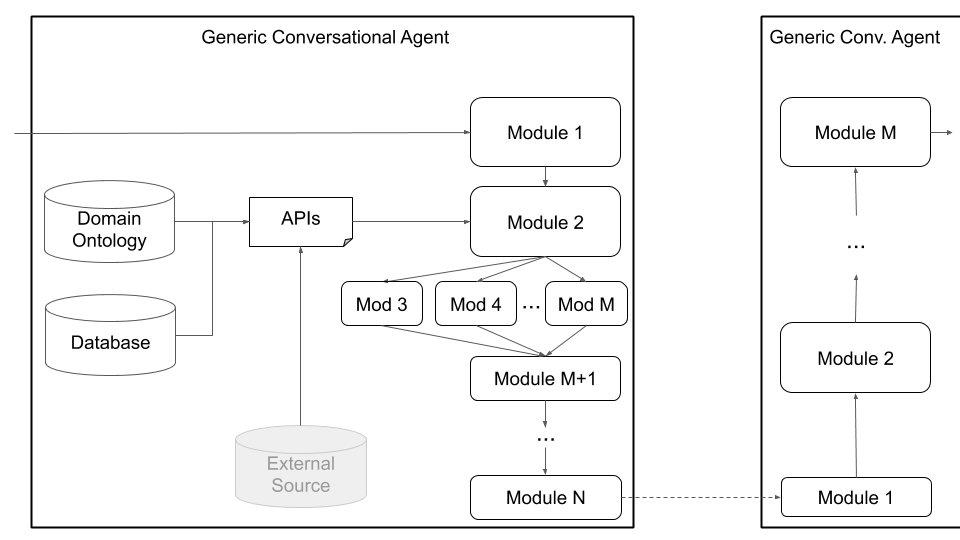 図4:Platoのジェネリックエージェントアーキテクチャは、共同コンポーネント、音声からスピーチコンポーネント、テキストツーテキストコンポーネントなど、幅広いカスタマイズをサポートしています。これらはすべて、連続的または並行して実行できます。
図4:Platoのジェネリックエージェントアーキテクチャは、共同コンポーネント、音声からスピーチコンポーネント、テキストツーテキストコンポーネントなど、幅広いカスタマイズをサポートしています。これらはすべて、連続的または並行して実行できます。
ユーザーは、独自のアーキテクチャを定義したり、Pythonクラス名とパッケージパスをそのモジュールに提供したり、モデルの初期化引数を提供することで、独自のコンポーネントをプラトンに差し込むことができます。ユーザーが行う必要があるのは、モジュールを実行する必要がある順序でリストすることです。プラトンは、入力/出力のラッピング、モジュールのチェーン、対話の処理など、残りを処理します。プラトンは、モジュールのシリアルおよび並列実行をサポートしています。
プラトンはまた、コンビナトリアル構造(BOC)のベイジアン最適化を通じて、会話型AIアーキテクチャまたは個々のモジュールパラメーターのベイズの最適化をサポートしています。
まず、マシンにPythonバージョン3.6以降がインストールされていることを確認してください。次に、プラトンリポジトリをクローンする必要があります。
git clone [email protected]:uber-research/plato-research-dialogue-system.git
次に、いくつかの前提条件をインストールする必要があります。
Tensorflow:
pip install tensorflow>=1.14.0
オーディオサポートのためにSpeechRecognitionライブラリをインストールします。
pip install SpeechRecognition
macosの場合:
brew install portaudio
brew install gmp
pip install pyaudio
ubuntu/debianの場合:
sudo apt-get install python3-pyaudio
Windowsの場合:事前にインストールする必要はありません
次のステップはプラトンのインストールです。プラトンをインストールするには、ソースコードから直接インストールする必要があります。
ソースコードからプラトンをインストールすることで、編集モードにインストールできます。つまり、ソースコードを変更すると、実行に直接影響を与えます。
プラトンのディレクトリに移動します(前のステップでプラトンリポジトリをクローニングしました)。
新しいPython環境を作成することをお勧めします。新しいPython環境をセットアップするには:
2.1 virtualenvをインストールします
sudo pip install virtualenv
2.2新しいPython環境を作成する:
python3 -m venv </path/to/new/virtual/environment>
2.3新しいPython環境をアクティブにする:
source </path/to/new/virtual/environment/bin>/bin/activate
プラトンをインストール:
pip install -e .
スピーチをサポートするには、Pyaudioをインストールする必要があります。Pyaudioには、開発者のマシンに存在しない可能性のある多くの依存関係があります。上記の手順が失敗した場合、Pyaudioのインストールエラーに関するこの投稿には、これらの依存関係を取得してPyaudioをインストールする方法に関する指示が含まれています。
CommonIssues.mdファイルには、インストール中にユーザーが遭遇する可能性のある一般的な問題とその解決策が含まれています。
インストール後にプラトンを実行するには、ターミナルでplatoコマンドを単純に実行できます。 platoコマンドは4つのサブコマンドを受け取ります。
runguidomainparseこれらのサブコマンドのそれぞれは、構成ファイルを指す--config引数の値を受け取ります。これらの構成ファイルはドキュメントの後半で詳細に説明しますが、 plato run --configとplato gui --configアプリケーション構成ファイルを受信することを覚えておいてください(例はここにあります: example/config/application/ )、 plato domain --config plato parse --configドメイン構成を受信します(例はここにあります: example/config/domain/ )。 example/config/parser/ )。
--config platoに渡される値については、最初にチェックして、値がマシン上のファイルのアドレスであるかどうかを確認します。もしそうなら、プラトンはそのファイルを解析しようとします。そうでない場合、プラトンは、値がexample/config/<application, domain, or parser>ディレクトリ内のファイルの名前であるかどうかを確認します。
いくつかの簡単な例については、ケンブリッジレストランドメインの次の構成ファイルを試してください。
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
プラトンのアプリケーション、つまり会話システムには3つの主要な部分が含まれています。
これらの部品は、アプリケーション構成ファイルで宣言されています。このような構成ファイルの例はexample/config/application/このセクションの残りの部分で、これらの各部分を詳細に説明します。
プラトンでタスク指向のダイアログシステムを実装するには、ユーザーがダイアログシステムのドメインを構成する2つのコンポーネントを指定する必要があります。
プラトンは、オントロジーとデータベースを構築するこのプロセスを自動化するためのコマンドを提供します。たとえば、フラワーショップの会話エージェントを構築したいと考えています。CSVに次のアイテムがあります(このファイルは、 example/data/flowershop.csvにあります):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
.db SQLファイルと.JSONオントロジーファイルを自動的に生成するには、CSVファイル、出力パス、および有効な、リクエスト可能な、およびシステムが要求するスロットへのパスを指定するドメイン構成ファイルをexample/config/domain/create_flowershop_domain.yaml 。
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
コマンドを実行します。
plato domain --config create_flowershop_domain.yaml
すべてがうまくいった場合は、 flowershop.jsonとflowershop.dbをexample/domains/ directoryに持っている必要があります。
このエラーを受け取った場合:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
つまり、.dbファイルがすでに作成されていることを意味します。
これで、プラトンのダミーコンポーネントを正気のチェックとして実行して、フラワーショップエージェントに相談することができます。
plato run --config flowershop_text.yaml
コントローラーは、エージェント間の会話を調整するオブジェクトです。コントローラーは、エージェントをインスタンス化し、ダイアログごとにエージェントを初期化し、入力と出力を適切に渡し、統計を追跡します。
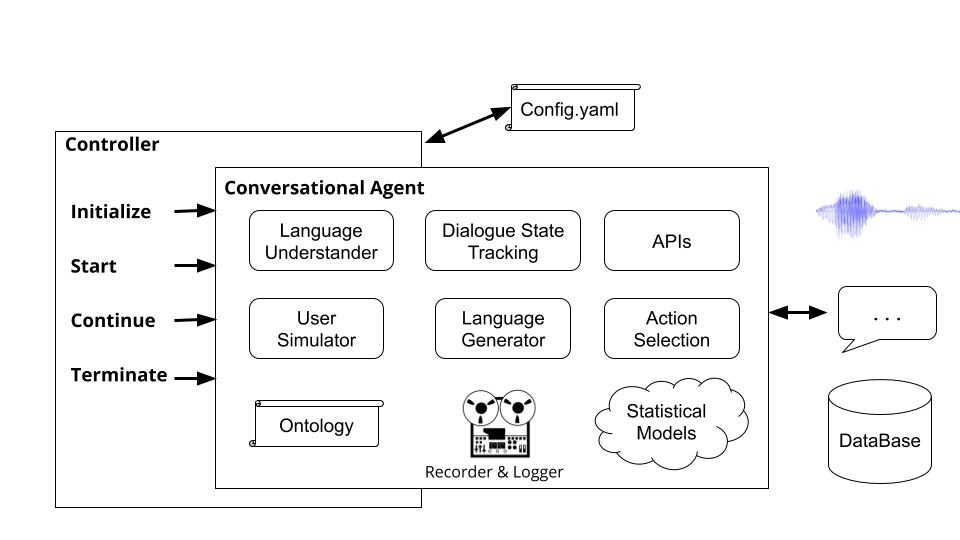
コマンドplato runを実行すると、プラトンの基本コントローラー( plato/controller/basic_controller.py )が実行されます。このコマンドは、プラトンアプリケーション構成ファイルを指す--config引数の値を受信します。
プラトンの会話エージェントを実行するには、ユーザーは適切な構成ファイルで次のコマンドを実行する必要があります。
plato run --config <FULL PATH TO CONFIG YAML FILE>
環境上の設定と作成するエージェント、およびコンポーネントを含む構成ファイルなど、 example/config/application/を参照してください。 example/config/application/の例は、yamlファイルの例の名前のみを使用して直接実行できます。
plato run --config <NAME OF A FILE FROM example/config/application/>
または、ユーザーは自分の構成ファイルを書き込み、構成ファイルへのフルパスを--configに渡すことでプラトンを実行できます。
plato run --config <FULL PATH TO CONFIG YAML FILE>
--config platoに渡される値については、最初にチェックして、値がマシン上のファイルのアドレスであるかどうかを確認します。もしそうなら、プラトンはそのファイルを解析しようとします。そうでない場合、プラトンは、値がexample/config/applicationディレクトリ内のファイルの名前であるかどうかを確認します。
プラトンの各会話型AIアプリケーションには、1つ以上のエージェントがいる可能性があります。各エージェントには、役割(システム、ユーザー、...)と一連の標準ダイアログシステムコンポーネント(図1)、つまりNLU、ダイアログマネージャー、ダイアログステートトラッカー、ポリシー、NLG、およびユーザーシミュレーターがあります。
エージェントは、これらのコンポーネントのそれぞれに対して1つの明示的なモジュールを持つことができます。あるいは、これらのコンポーネントの一部は、順次または並行して実行できる1つ以上のモジュール(ジョイント /エンドツーエンドエージェントなど)に結合することができます(図4)。プラトンのコンポーネントはplato.agent.componentで定義されており、すべてがplato.agent.component.conversational_moduleから継承されています
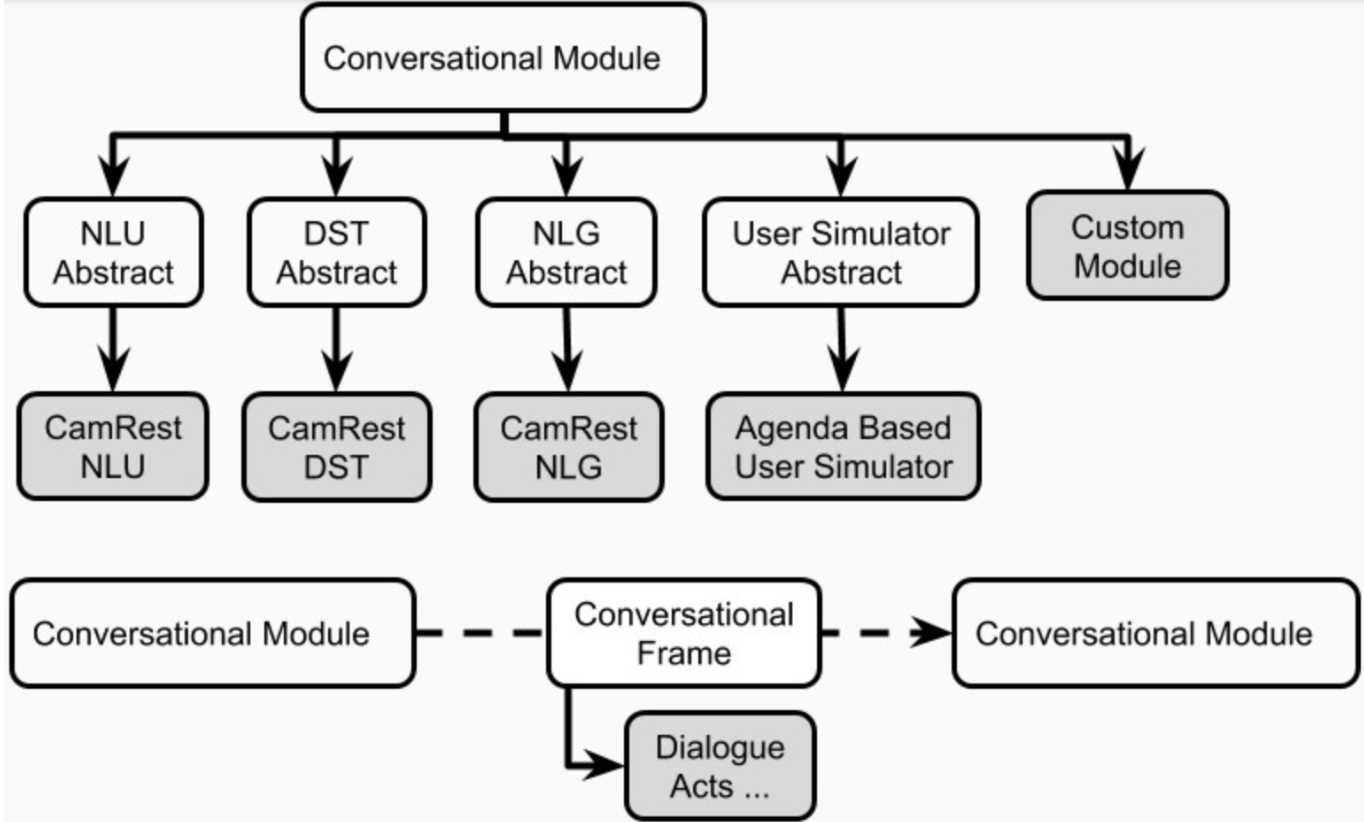 図5。プラトンエージェントのコンポーネント
図5。プラトンエージェントのコンポーネント
新しい実装またはカスタムモジュールは、 plato.agent.component.conversational_moduleから継承する必要があることに注意してください。
これらのモジュールのそれぞれは、ルールベースまたはトレーニングされている可能性があります。次のサブセクションでは、エージェント向けのルールベースのモジュールとトレーニングモジュールを構築する方法について説明します。
プラトンは、スロット充填会話エージェント(slot_filling_nlu、slot_filling_dst、slot_filling_policy、slot_filling_nlg、およびagenda_based_usのデフォルトバージョン)のすべてのコンポーネントのルールベースのバージョンを提供します。これらは、迅速なプロトタイピング、ベースライン、または正気チェックに使用できます。具体的には、これらのコンポーネントはすべて、指定されたオントロジーに条件付けられたルールまたはパターンに従い、場合によっては特定のデータベースに従います。各コンポーネントがすべきことの最も基本的なバージョンとして扱う必要があります。
プラトンは、ディープラーニングフレームワークを使用して、オンライン(インタラクション中)またはオフライン(データから)でエージェントのコンポーネントモジュールのトレーニングをサポートしています。プラトンのインターフェイス入力/出力が尊重されている限り、事実上すべてのモデルをプラトンにロードできます。たとえば、モデルがカスタムNLUモジュールである場合、プラトンのNLU抽象クラス( plato.agent.component.nlu )から継承し、必要な抽象メソッドを実装する必要があります。
オンライン学習、デバッグ、評価を促進するために、プラトンは、以前のダイアログ状態、取得したアクション、現在の対話状態、受け取った発話、生産された発表、受け取った報酬を含むいくつかの他のplato.utilities.dialogue_episode_recorderを含むいくつかの他の構造を含む他の構造を含むいくつかの他の構造を含むカスタムフィールドを含むものを含む公的な構造を含むカスタムフィールドを含むカスタムフィールドを含む他の構造を含むカスタムフィールドを含むカスタムフィールドを含むカスタムフィールドを含むものを含むカスタムフィールドを含むカスタムフィールドを含むカスタムフィールドを含むカスタムフィールドを含むものを含む、その内部経験を追跡するために、オンライン学習、デバッグ、評価を促進するために、カテゴリ。
ダイアログの終わりまたは指定された間隔で、各会話エージェントは、各内部コンポーネントの列車()関数を呼び出し、対話体験をトレーニングデータとして渡します。各コンポーネントは、トレーニングに必要な部品を選択します。
プラトン内で実装されている学習アルゴリズムを使用するには、DSTC2データなどの外部データをこのプラトンエクスペリエンスに解析して、対応するコンポーネントがトレーニング中にロードおよび使用できるようにする必要があります。
または、ユーザーはデータを解析し、プラトンの外でモデルをトレーニングし、プラトンのエージェントに使用するときに訓練されたモデルを単純にロードすることができます。
オンラインでのトレーニングは、コンポーネントごとに構成の「トレイン」フラグを「真」に反転するのと同じくらい簡単です。ユーザーはトレーニングを希望します。
データからトレーニングするには、ユーザーはデータセットから解析したエクスペリエンスを単にロードする必要があります。プラトンは、DSTC2およびMetalwozデータセットのパーサーのサンプルを提供しています。プラトンでのオフライントレーニングにこれらのパーサーを使用する方法の例として、DSTC2データセットを使用します。これは、2番目のDialogue State Tracking Challenge Webサイトから取得できます。
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
ダウンロードが完了したら、ファイルを解凍する必要があります。このデータセットを解析するための構成ファイルはexample/config/parser/Parse_DSTC2.yamlで提供されます。 data_pathの値を最初に編集することでダウンロードしたデータを解析できますexample/config/parser/Parse_DSTC2.yamlは、DSTC2データをダウンロードして解凍した場所へのパスをポイントします。次に、次のように解析スクリプトを実行できます。
plato parse --config Parse_DSTC2.yaml
または、独自の構成ファイルを書き込み、そのファイルへの絶対アドレスをコマンドに渡すことができます。
plato parse --config <absolute pass to parse config file>
このコマンドを実行すると、DSTC2( plato/utilities/parser/parse_dstc2.pyの下にある)の解析スクリプトが実行され、このリポジトリのルートディレクトリにあるデータディレクトリのデータディレクトリのdataディレクトリの下にあるユーザーとシステムの両方のダイアログ状態トラッカー、NLU、およびNLGのトレーニングデータが作成されます。これで、この解析データを使用して、プラトンのさまざまなコンポーネントのモデルをトレーニングできます。
プラトンのエージェントの各コンポーネントをトレーニングする方法は複数あります。オンライン(エージェントが他のエージェント、シミュレータ、またはユーザーと対話するとき)またはオフライン。さらに、プラトンで実装されたアルゴリズムを使用することも、Tensorflow、Pytorch、Keras、Ludwigなどの外部フレームワークを使用できます。
Ludwigは、コードを作成せずにモデルをトレーニングできるオープンソースのディープラーニングフレームワークです。データを.csvファイルに解析し、希望するアーキテクチャを記述するLudwig構成(yaml)を作成するだけで、.csvおよびその他のパラメーターから使用する機能が端末でコマンドを実行するだけです。
ルートヴィヒはまた、プラトンが互換性があるAPIを提供しています。これにより、プラトンはLudwigモデルと統合したり、モデルをロードまたは保存したり、訓練したり照会したりすることができます。
前のセクションでは、プラトンのDSTC2パーサーは、NLUとNLGのトレーニングに使用できるいくつかの.csvファイルを生成しました。システム用のNLU .csvファイル( data/DSTC2_NLU_sys.csv )とユーザー用のファイル( data/DSTC2_NLU_usr.csv )が1つあります。これらは次のように見えます:
| 転写産物 | 意図 | iob |
|---|---|---|
| ベジタリアン料理を提供する高価なレストラン | 知らせる | b-inform-pricerange oooo b-inform-food o |
| ベジタリアン料理 | 知らせる | b-inform-food o |
| アジアのオリエンタルタイプの食べ物 | 知らせる | b-inform-food i-inform-food oooo |
| 高価なレストランアジア料理 | 知らせる | b-inform-pricerange oooo |
NLUモデルをトレーニングするには、次のような構成ファイルを作成する必要があります。
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
この構成ファイルの例はexample/config/ludwig/ludwig_nlu_train.yamlに存在します。トレーニングの仕事は、実行することで開始できます。
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
次のステップは、モデルをアプリケーション構成にロードすることです。 example/config/application/CamRest_model_nlu.yamlでは、モデルベースのNLUを備えたアプリケーション構成を提供し、他のコンポーネントは非MLベースです。モード( model_path )へのパスを--output_directory引数に提供した値に更新することにより、Ludwigを実行したときに、エージェントがNLUに使用する必要があるNLUモデルを指定できます。
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
モデルが機能することをテストします。
plato run --config CamRest_model_nlu.yaml
DSTC2データパーサーは、DST: DST_sys.csvおよびDST_usr.csvに使用できる2つの.csvファイルを生成しました。
| dst_prev_food | dst_prev_area | DST_PREV_PRICERANGE | nlu_intent | req_slot | inf_area_value | inf_food_value | inf_pricerange_value | dst_food | DST_AREA | DST_PRICERANGE | DST_REQ_SLOT |
|---|---|---|---|---|---|---|---|---|---|---|---|
| なし | なし | なし | 知らせる | なし | なし | ベジタリアン | 高い | ベジタリアン | なし | 高い | なし |
| ベジタリアン | なし | 高い | 知らせる | なし | なし | ベジタリアン | なし | ベジタリアン | なし | 高い | なし |
| ベジタリアン | なし | 高い | 知らせる | なし | なし | アジアのオリエンタル | なし | アジアのオリエンタル | なし | 高い | なし |
| アジアのオリエンタル | なし | 高い | 知らせる | なし | なし | アジアのオリエンタル | 高い | アジアのオリエンタル | なし | 高い | なし |
基本的に、パーサーは、以前のダイアログ状態、NLUからの入力、および結果の対話状態を追跡します。その後、これをLudwigに供給して、ダイアログステートトラッカーを訓練できます。これがLudwigの構成です。これはexample/config/ludwig/ludwig_dst_train.yamlにもあります。
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
ここで、Ludwigでモデルをトレーニングする必要があります。
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
モデルベースのDSTでプラトンエージェントを実行します。
plato run --config CamRest_model_dst.yaml
もちろん、他のアーキテクチャやトレーニングパラメーターを試してみることができます。
これまで、外部フレームワーク(つまりLudwig)を使用してプラトンのエージェントのコンポーネントをトレーニングする方法を見てきました。このセクションでは、プラトンの内部アルゴリズムを使用して、監視された学習を使用し、オンラインで補強学習を使用して、対話ポリシーをオフラインでトレーニングする方法を確認します。
.csvファイルとは別に、DSTC2パーサーはプラトンのダイアログエピソードレコーダーを使用して、プラトンの経験ログで解析されたダイアログも保存しました: logs/DSTC2_systemとlogs/DSTC2_user 。これらのログには、各対話に関する情報、たとえば現在の対話状態、行われたアクション、次の対話状態、観察された報酬、入力発話、成功などが含まれています。これらのログは、会話エージェントに直接ロードでき、エクスペリエンスプールを埋めるために使用できます。
その後、これらのログをロードする構成ファイルを作成することだけです( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
このエージェントは1つのダイアログのみを実行しますが、ログからロードされたエクスペリエンスを使用して、100エポックのためにトレーニングすることに注意してください。
plato run --config CamRest_model_supervised_policy_train.yaml
トレーニングが完了した後、監視されたポリシーをテストできます。
plato run --config CamRest_model_supervised_policy_test.yaml
前のセクションでは、監督された対話ポリシーをトレーニングする方法を見ました。強化アルゴリズムを使用して、強化学習ポリシーをどのようにトレーニングできるかを確認できます。これを行うには、構成ファイルで関連するクラスを定義します。
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
AGENT_0の下の学習パラメーターと、ポリシーの引数の下でのアルゴリズム固有のパラメーターに注意してください。次に、この構成でプラトンに電話します。
plato run --config CamRest_model_reinforce_policy_train.yaml
訓練されたポリシーモデルをテストします。
plato run --config CamRest_model_reinforce_policy_test.yaml
LudwigのAPIを使用して、またはプラトンで学習アルゴリズムを実装することにより、他のコンポーネントをオンラインでトレーニングすることもできます。
また、ログファイルはロードされ、任意のコンポーネントおよび学習アルゴリズムのエクスペリエンスプールとして使用できることに注意してください。ただし、一部のプラトンコンポーネントに独自の学習アルゴリズムを実装する必要がある場合があります。
NLGモジュールをトレーニングするには、このような構成ファイルを記述する必要があります( example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
モデルをトレーニングしてください:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
次のステップは、プラトンにモデルをロードすることです。 CamRest_model_nlg.yaml構成ファイルに移動し、必要に応じてパスを更新してください。
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
モデルが機能することをテストします。
plato run --config CamRest_model_nlg.yaml
Ludwigは、呼び出されるたびに新しい実験_RUN_Iディレクトリを作成することに注意してください。プラトンの構成の正しいパスを最新の状態に保つようにしてください。
Ludwigはモデルをオンラインでトレーニングする方法も提供しているため、実際にはプラトンの新しい深い学習コンポーネントを構築、訓練、評価するためのコードをほとんど記述する必要があります。
この例では、ここからダウンロードできるMetalwozデータセットを使用します。
プラトンは、ジェネリックエージェントを通じて共同で訓練されたモデルをサポートしています。ここでは、簡単なSEQ2SEQの会話エージェントをゼロから作成するために必要な手順を確認します。例としてMetalwozを使用すると、次のことを行う必要があります。
単純なSEQ2SEQモデル(テキストからテキスト)のみをトレーニングしているため、ユーザーとシステムの発話を抽出するためにパーサーが必要です。これらは、ステップ4でLudwigが使用する.CSVファイルに保存されます。
Metalwozパーサーの簡単な実装については、 utilities/parser/Parse_MetalWOZ.pyを参照してください
このパーサーは、1つのファイル(1つのドメイン)のみを解析することに注意してください。ただし、ニーズに合わせて簡単に変更できます。これは、ピザ注文ドメインのパーサーによって生成された出力のサンプルです。
| ユーザー | システム |
|---|---|
| こんにちは | こんにちは私はあなたをどのように助けることができますか? |
| ピザの必要性のために注文する必要があります | 確かに、あなたはあなたの注文に何を追加したいですか? |
| マッシュルーム、ペパロニ、ベーコンのトッピングが付いたピザが欲しい | 残念ながら、この場所はあなたが要求したベーコンのトッピングから外れています。交換したい別のトッピングはありますか? |
| パイナップルはどうですか | そのトッピングが利用可能です。私はあなたの注文にマッシュルーム、ペパロニ、パイナップルを添えたピザを追加しました。どんなサイズが欲しいですか? |
| 中くらい | さて、更新されました。注文にさらに追加しますか? |
| これで全部です、ありがとう | さて、あなたの合計は14.99です。あなたのピザは約でピックアップの準備ができています。 20分。 |
注データには実際には存在しません。ただし、システムの挨拶を作成するようにモデルに促すために何かが必要です。空の文、または他の挨拶(またはこれらの組み合わせ)を使用することもできます。
その後、次のようにプラトンパースを実行できます。
plato parse --config Parse_MetalWOZ.yaml
開始するには、Ludwigを使用して非常にシンプルなモデルをトレーニングできます(お気に入りのディープラーニングフレームワークを自由に使用してください):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
この構成を変更して、Ludwigを使用して選択したアーキテクチャとトレーニングを反映することができます。
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
このクラスは、単にモデルの読み込みを処理し、適切に照会し、出力を適切にフォーマットする必要があります。私たちの場合、入力テキストをパンダのデータフレームに包み、出力から予測されるトークンをつかみ、返される文字列に結合する必要があります。こちらのクラスを参照してください: plato.agent.component.joint_model.metal_woz_seq2seq.py
テキストを介してseq2seqエージェントと対話する一般的な構成ファイルの例についてはexample/config/application/metalwoz_generic.yamlを参照してください。次のように試してみることができます。
plato run --config metalwoz_text.yaml
必要に応じて、訓練されたモデルへのパスを更新することを忘れないでください!デフォルトのパスは、プラトンのルートディレクトリからLudwig Trainコマンドを実行することを前提としています。
プラトンの主な機能の1つは、2人のエージェントが相互作用することを可能にします。各エージェントは、異なる役割(たとえば、システムとユーザー)を持つことができ、異なる目標を持ち、異なる報酬信号を受信できます。エージェントが協力している場合、これらのいくつかは共有できます(たとえば、成功した対話を構成するもの)。
ケンブリッジレストランドメインで複数のプラトンエージェントを実行するには、次のコマンドを実行してエージェントの対話ポリシーをトレーニングしてテストします。
トレーニングフェーズ:2つのポリシー(各エージェントに1つ)がトレーニングされます。これらのポリシーは、ウルフアルゴリズムを使用してトレーニングされています。
plato run --config MultiAgent_train.yaml
テストフェーズ:トレーニングフェーズでトレーニングされたポリシーを使用して、2つのエージェント間でダイアログを作成します。
plato run --config MultiAgent_test.yaml
基本コントローラーは現在2つのエージェントインタラクションを許可していますが、複数のエージェント(たとえば、各エージェントが他のエージェントに出力をブロードキャストするブラックボードアーキテクチャを使用)に拡張することはかなり簡単です。これは、すべてのデバイスがエージェントであるスマートホーム、さまざまな役割とのマルチユーザーのやり取りなどのシナリオをサポートできます。
プラトンは、2種類のユーザーシミュレータに実装を提供します。 1つは非常によく知られているアジェンダベースのユーザーシミュレーターであり、もう1つはデータで観察されるユーザーの動作を模倣しようとするシミュレーターです。ただし、研究者は、シミュレートされたユーザーを使用する代わりに、プラトンで2人の会話エージェント(「システム」であり、「ユーザー」である)を単純にトレーニングすることをお勧めします。
アジェンダベースのユーザーシミュレーターはSchatzmannによって提案され、このペーパーで詳細に説明されています。概念的には、シミュレーターは、通常はスタックとして実装されることの「アジェンダ」を維持します。シミュレーターが入力を受信すると、入力への応答として、アジェンダに押し込むコンテンツを確認するために、ポリシー(または一連のルール)を参照します。いくつかのハウスキーピングの後(たとえば、もはや有効でない重複またはコンテンツを削除する)、シミュレータは、その応答を策定するために使用されるアジェンダから1つ以上のアイテムをポップします。
アジェンダベースのユーザーシミュレーターには、音声認識 /言語理解エラーをシミュレートできるエラーシミュレーションモジュールもあります。いくつかの確率に基づいて、シミュレータの出力ダイアログ行為 - 意図、スロット、または値(それぞれの可能性が異なる)を歪めます。このシミュレーターが受け取るパラメーターの完全なリストの例は次のとおりです。
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
このシミュレーターは、ダイアログ法レベルまたは発話レベルで動作できる、単純なポリシーベースのシミュレーターとして設計されています。それがどのように機能するかを示すために、DSTC2パーサーは、このシミュレーターのポリシーファイルを作成しました: user_policy_reactive.pkl (ユーザーシミュレーター状態の代わりにシステムダイアログ行為に反応するため、リアクティブ)。これは実際には次の単純な辞書です。
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
キーは、入力ダイアログ法(たとえば、 system会話エージェントから来る)を表します。各キーの値は、2つの要素の辞書であり、シミュレーターがサンプリングする対話行為または発話テンプレート上の確率分布を表します。
例を見るには、次の構成を実行できます。
plato run --config CamRest_dtl_simulator.yaml
その機能に応じて、新しいモジュールを作成するには2つの方法があります。たとえば、モジュールがNLUまたはダイアログポリシーを実行する新しい方法を実装する場合、対応する抽象クラスから継承するクラスを作成する必要があります。
ただし、モジュールが単一のエージェントの基本コンポーネントのいずれかに適合しない場合、たとえば、名前付きエンティティ認識を実行するか、テキストから対話行為を予測する場合は、 conversational_moduleから直接継承するクラスを作成する必要があります。その後、構成内の適切なパッケージパス、クラス名、および引数を提供することにより、一般的なエージェントを介してモジュールをロードできます。
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
気をつけて!一般的な構成ファイルで提供されているように、このモジュールのI/Oを前後にモジュールによって適切に処理および消費できることを保証する責任があります。
プラトンは、モジュールの(論理的に)並行して実行されることもサポートしています。構成に次の構造を持つ必要があることを有効にするには:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
気をつけて!並行して実行されたモジュールからの出力は、リストに詰め込まれます。次のモジュール( MODULE_i+1など)は、この種の入力を処理できる必要があります。提供されたプラトンモジュールはこれを処理するように設計されていません。複数のソースから入力を処理するためにカスタムモジュールを作成する必要があります。
プラトンは拡張可能になるように設計されているため、特定のニーズに合わせて独自の対話状態、アクション、報酬機能、アルゴリズム、またはその他のコンポーネントを自由に作成してください。実装がプラトンと互換性があることを確認するために、対応するクラスから継承するだけです。
プラトンはPysimpleguiを使用してグラフィカルユーザーインターフェイスを処理します。プラトンのGUIの例は、 plato.controller.sgui_controllerで実装されており、次のコマンドを使用して試してみることができます。
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
楽しむ!


