plato research dialogue system
1.0.0

Ini adalah V0.3.1
Sistem Dialog Penelitian Plato adalah kerangka kerja fleksibel yang dapat digunakan untuk membuat, melatih, dan mengevaluasi agen AI percakapan di berbagai lingkungan. Ini mendukung interaksi melalui tindakan pidato, teks, atau dialog dan setiap agen percakapan dapat berinteraksi dengan data, pengguna manusia, atau agen percakapan lainnya (dalam pengaturan multi-agen). Setiap komponen dari setiap agen dapat dilatih secara online atau offline secara mandiri dan Plato menyediakan cara mudah untuk membungkus hampir semua model yang ada, selama antarmuka Plato dipatuhi.
Kutipan publikasi:
Alexandros Papangelis, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, dan Gokhan Tur, "Sistem Dialog Plato: Platform Penelitian AI percakapan yang fleksibel", ARXIV Preprint [Paper]
Alexandros Papangelis, Yi-Chia Wang, Piero Molino, dan Gokhan Tur, “Pelatihan Model Dialog Multi-Agen Kolaboratif melalui Pembelajaran Penguatan”, Sigdial 2019 [Makalah]
Plato menulis beberapa dialog antara karakter yang berdebat tentang suatu topik dengan mengajukan pertanyaan. Banyak dari dialog ini menampilkan Socrates termasuk uji coba Socrates. (Socrates dibebaskan dalam persidangan baru yang diadakan di Athena, Yunani pada 25 Mei 2012).
V0.2 : Pembaruan utama dari V0.1 adalah bahwa Plato RDS sekarang disediakan sebagai paket. Ini membuatnya lebih mudah untuk membuat dan memelihara aplikasi AI percakapan baru dan semua tutorial telah diperbarui untuk mencerminkan hal ini. Plato sekarang juga dilengkapi dengan GUI opsional. Menikmati!
Secara konseptual, agen percakapan perlu melalui berbagai langkah untuk memproses informasi yang diterimanya sebagai input (misalnya, "Bagaimana cuaca seperti saat ini?") Dan menghasilkan output yang sesuai ("berangin tapi tidak terlalu dingin."). Langkah -langkah utama, yang sesuai dengan komponen utama arsitektur standar (lihat Gambar 1), adalah:
Plato telah dirancang untuk menjadi modular dan fleksibel mungkin; Ini mendukung arsitektur AI percakapan tradisional maupun kustom, dan yang penting, memungkinkan interaksi multi-partai di mana banyak agen, berpotensi dengan peran yang berbeda, dapat berinteraksi satu sama lain, melatih secara bersamaan, dan memecahkan masalah yang didistribusikan.
Gambar 1 dan 2, di bawah, menggambarkan contoh arsitektur agen percakapan Plato saat berinteraksi dengan pengguna manusia dan dengan pengguna yang disimulasikan, masing -masing. Berinteraksi dengan pengguna yang disimulasikan adalah praktik umum yang digunakan dalam komunitas penelitian untuk memulai pembelajaran (yaitu, mempelajari beberapa perilaku dasar sebelum berinteraksi dengan manusia). Setiap komponen individu dapat dilatih secara online atau offline menggunakan perpustakaan pembelajaran mesin apa pun (misalnya, Ludwig, TensorFlow, Pytorch, atau implementasi Anda sendiri) sebagai Plato adalah kerangka kerja universal. Ludwig, kotak alat pembelajaran dalam open source Uber, membuat pilihan yang baik, karena tidak memerlukan kode menulis dan sepenuhnya kompatibel dengan Plato.
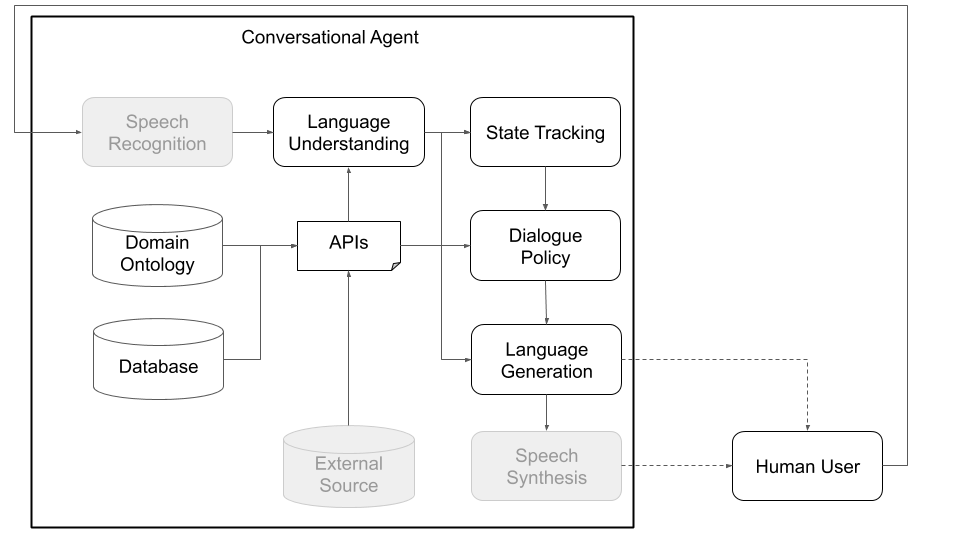 Gambar 1: Arsitektur modular Plato berarti bahwa komponen apa pun dapat dilatih secara online atau offline dan dapat diganti dengan model khusus atau pra-terlatih. (Komponen abu -abu dalam diagram ini bukan komponen inti plato.)
Gambar 1: Arsitektur modular Plato berarti bahwa komponen apa pun dapat dilatih secara online atau offline dan dapat diganti dengan model khusus atau pra-terlatih. (Komponen abu -abu dalam diagram ini bukan komponen inti plato.)
 Gambar 2: Menggunakan pengguna yang disimulasikan daripada pengguna manusia, seperti pada Gambar 1, kita dapat melakukan pra-train model statistik untuk berbagai komponen Plato. Ini kemudian dapat digunakan untuk membuat agen percakapan prototipe yang dapat berinteraksi dengan pengguna manusia untuk mengumpulkan lebih banyak data alami yang selanjutnya dapat digunakan untuk melatih model statistik yang lebih baik. (Komponen abu -abu dalam diagram ini bukan komponen inti Plato karena mereka tersedia sebagai di luar kotak seperti Google ASR dan Amazon Lex, atau domain dan spesifik aplikasi seperti database/API khusus.)
Gambar 2: Menggunakan pengguna yang disimulasikan daripada pengguna manusia, seperti pada Gambar 1, kita dapat melakukan pra-train model statistik untuk berbagai komponen Plato. Ini kemudian dapat digunakan untuk membuat agen percakapan prototipe yang dapat berinteraksi dengan pengguna manusia untuk mengumpulkan lebih banyak data alami yang selanjutnya dapat digunakan untuk melatih model statistik yang lebih baik. (Komponen abu -abu dalam diagram ini bukan komponen inti Plato karena mereka tersedia sebagai di luar kotak seperti Google ASR dan Amazon Lex, atau domain dan spesifik aplikasi seperti database/API khusus.)
Selain interaksi agen tunggal, Plato mendukung percakapan multi-agen di mana beberapa agen Plato dapat berinteraksi dan belajar dari satu sama lain. Secara khusus, Plato akan menelurkan agen percakapan, memastikan bahwa input dan output (apa yang masing -masing agen dengar dan katakan) diteruskan ke masing -masing agen dengan tepat, dan melacak percakapan.
Pengaturan ini dapat memfasilitasi penelitian dalam pembelajaran multi-agen, di mana agen perlu belajar bagaimana menghasilkan bahasa untuk melakukan tugas, serta penelitian di sub-bidang interaksi multi-partai (pelacakan negara dialog, pengambilan giliran, dll.). Prinsip -prinsip dialog menentukan apa yang dapat dipahami oleh masing -masing agen (ontologi entitas atau makna; misalnya: harga, lokasi, preferensi, jenis masakan, dll.) Dan apa yang dapat dilakukan (mintalah informasi lebih lanjut, berikan beberapa informasi, hubungi API, dll.). Agen dapat berkomunikasi melalui pidato, teks, atau informasi terstruktur (tindakan dialog) dan masing -masing agen memiliki konfigurasi sendiri. Gambar 3, di bawah, menggambarkan arsitektur ini, menguraikan komunikasi antara dua agen dan berbagai komponen:
 Gambar 3: Arsitektur Plato memungkinkan pelatihan bersamaan dari beberapa agen, masing-masing dengan peran dan tujuan yang berpotensi berbeda, dan dapat memfasilitasi penelitian di bidang seperti interaksi multi-partai dan pembelajaran multi-agen. (Komponen abu -abu dalam diagram ini bukan komponen inti plato.)
Gambar 3: Arsitektur Plato memungkinkan pelatihan bersamaan dari beberapa agen, masing-masing dengan peran dan tujuan yang berpotensi berbeda, dan dapat memfasilitasi penelitian di bidang seperti interaksi multi-partai dan pembelajaran multi-agen. (Komponen abu -abu dalam diagram ini bukan komponen inti plato.)
Akhirnya, Plato mendukung arsitektur khusus (misalnya pemisahan NLU menjadi beberapa komponen independen) dan komponen yang terlatih bersama (misalnya keadaan teks-ke-dialog, teks-ke-teks, atau kombinasi lainnya) melalui arsitektur agen generik yang ditunjukkan pada Gambar 4, di bawah ini. Mode ini menjauh dari arsitektur agen percakapan standar dan mendukung segala jenis arsitektur (misalnya, dengan komponen gabungan, komponen teks-ke-teks atau ucapan-ke-pidato, atau pengaturan lainnya) dan memungkinkan memuat model yang ada atau terlatih ke dalam plato.
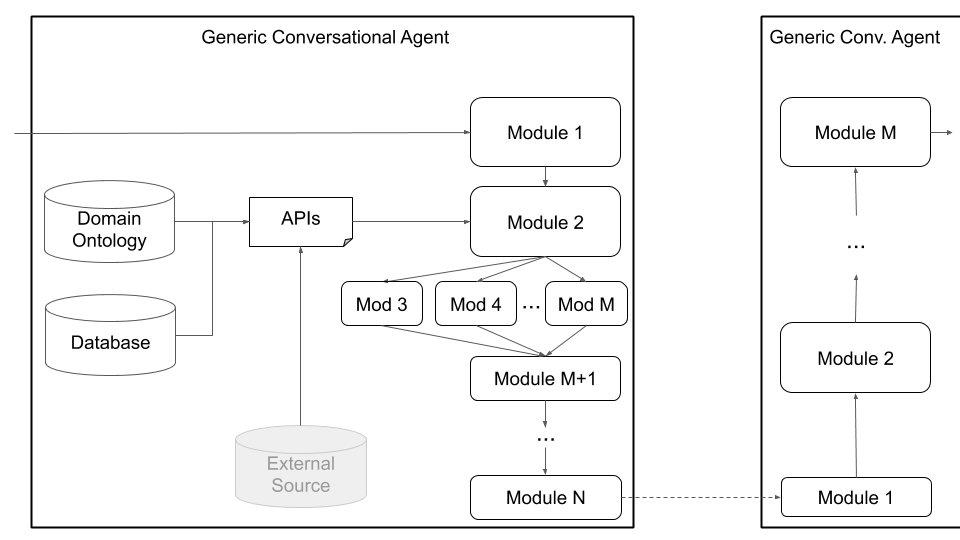 Gambar 4: Arsitektur agen generik Plato mendukung berbagai kustomisasi, termasuk komponen gabungan, komponen ucapan-ke-pidato, dan komponen teks-ke-teks, yang semuanya dapat dieksekusi secara serial atau paralel.
Gambar 4: Arsitektur agen generik Plato mendukung berbagai kustomisasi, termasuk komponen gabungan, komponen ucapan-ke-pidato, dan komponen teks-ke-teks, yang semuanya dapat dieksekusi secara serial atau paralel.
Pengguna dapat mendefinisikan arsitektur mereka sendiri dan/atau mencolokkan komponen mereka sendiri ke Plato hanya dengan memberikan nama kelas Python dan jalur paket ke modul itu, serta argumen inisialisasi model. Yang perlu dilakukan pengguna adalah mendaftar modul dalam urutan yang harus mereka lakukan dan Plato menangani sisanya, termasuk membungkus input/output, merantai modul, dan menangani dialog. Plato mendukung eksekusi modul serial dan paralel.
Plato juga memberikan dukungan untuk optimalisasi Bayesian arsitektur AI percakapan atau parameter modul individu melalui optimalisasi Bayesian dari struktur kombinatorial (BOC).
Pertama, pastikan Anda memiliki Python Versi 3.6 atau lebih tinggi diinstal pada mesin Anda. Selanjutnya Anda perlu mengkloning repositori Plato:
git clone [email protected]:uber-research/plato-research-dialogue-system.git
Selanjutnya Anda perlu menginstal beberapa prasyarat:
Tensorflow:
pip install tensorflow>=1.14.0
Instal Pustaka Perpustakaan Pidato untuk Dukungan Audio:
pip install SpeechRecognition
Untuk macOS:
brew install portaudio
brew install gmp
pip install pyaudio
Untuk Ubuntu/Debian:
sudo apt-get install python3-pyaudio
Untuk windows: tidak ada yang diperlukan untuk dipasang sebelumnya
Langkah selanjutnya adalah memasang Plato. Untuk menginstal Plato, Anda harus langsung menginstalnya dari kode sumber.
Menginstal Plato dari kode sumber memungkinkan instalasi dalam mode yang dapat diedit yang berarti bahwa jika Anda membuat perubahan pada kode sumber, itu akan secara langsung mempengaruhi eksekusi.
Arahkan ke direktori Plato (tempat Anda mengkloning repositori Plato pada langkah sebelumnya).
Kami merekomendasikan untuk membuat lingkungan Python baru. Untuk mengatur lingkungan Python yang baru:
2.1 Instal VirtualEnv
sudo pip install virtualenv
2.2 Buat lingkungan Python baru:
python3 -m venv </path/to/new/virtual/environment>
2.3 Aktifkan lingkungan Python yang baru:
source </path/to/new/virtual/environment/bin>/bin/activate
Instal Plato:
pip install -e .
Untuk mendukung pidato, perlu menginstal Pyaudio, yang memiliki sejumlah dependensi yang mungkin tidak ada pada mesin pengembang. Jika langkah -langkah di atas tidak berhasil, posting ini pada kesalahan instalasi Pyaudio mencakup instruksi tentang cara mendapatkan dependensi ini dan menginstal Pyaudio.
File CommonIssues.md berisi masalah umum dan resolusi mereka yang mungkin ditemui pengguna saat instalasi.
Untuk menjalankan Plato setelah pemasangan, Anda dapat dengan mudah menjalankan perintah plato di terminal. Perintah plato menerima 4 Sub-Komandan:
runguidomainparse Masing-masing sub-komandan ini menerima nilai untuk --config argumen yang menunjuk ke file konfigurasi. We will describe these configuration files in detail later in the document but remember that plato run --config and plato gui --config receive an application configuration file (examples could be found here: example/config/application/ ), plato domain --config receives a domain configuration (examples could be found here: example/config/domain/ ), and plato parse --config receives a parser configuration file (examples could be found here: example/config/parser/ ).
Untuk nilai yang diteruskan ke --config Plato pertama memeriksa untuk melihat apakah nilainya adalah alamat file pada mesin. Jika ya, maka Plato mencoba mengurai file itu. Jika tidak, Plato memeriksa untuk melihat apakah nilainya adalah nama file dalam direktori example/config/<application, domain, or parser> .
Untuk beberapa contoh cepat, coba file konfigurasi berikut untuk domain Cambridge Restaurants:
plato run --config CamRest_user_simulator.yaml
plato run --config CamRest_text.yaml
plato run --config CamRest_speech.yaml
Aplikasi, yaitu sistem percakapan, di Plato berisi tiga bagian utama:
Bagian -bagian ini dinyatakan dalam file konfigurasi aplikasi. Contoh file konfigurasi tersebut dapat ditemukan di example/config/application/ Di seluruh bagian ini kami menjelaskan masing -masing bagian ini secara detail.
Untuk menerapkan sistem dialog berorientasi tugas di Plato, pengguna perlu menentukan dua komponen yang merupakan domain sistem dialog:
Plato menyediakan perintah untuk mengotomatisasi proses pembangunan ontologi dan database ini. Katakanlah misalnya bahwa Anda ingin membangun agen percakapan untuk toko bunga, dan Anda memiliki barang -barang berikut di .csv (file ini dapat ditemukan di example/data/flowershop.csv ):
id,type,color,price,occasion
1,rose,red,cheap,any
2,rose,white,cheap,anniversary
3,rose,yellow,cheap,celebration
4,lilly,white,moderate,any
5,orchid,pink,expensive,any
6,dahlia,blue,expensive,any
Untuk secara otomatis menghasilkan file .db sql dan file ontologi .json Anda perlu membuat file konfigurasi domain di mana Anda harus menentukan jalur ke file CSV, jalur output, serta slot yang dapat diinformasikan, diminta, dan dapat dipertanyakan sistem: (EG example/config/domain/create_flowershop_domain.yaml ): (eg example/domain/domain/create_flowershop_yamled.
GENERAL:
csv_file_name: example/data/flowershop.csv
db_table_name: flowershop
db_file_path: example/domains/flowershop-dbase.db
ontology_file_path: example/domains/flowershop-rules.json
ONTOLOGY: # Optional
informable_slots: [type, price, occasion]
requestable_slots: [price, color]
System_requestable_slots: [type, price, occasion]
dan jalankan perintah:
plato domain --config create_flowershop_domain.yaml
Jika semuanya berjalan dengan baik, Anda harus memiliki flowershop.json flowershop.db example/domains/
Jika Anda menerima kesalahan ini:
sqlite3.IntegrityError: UNIQUE constraint failed: flowershop.id
Ini berarti bahwa file .db telah dibuat.
Anda sekarang dapat dengan mudah menjalankan komponen dummy Plato sebagai pemeriksaan kewarasan dan berbicara dengan agen toko bunga Anda:
plato run --config flowershop_text.yaml
Pengontrol adalah objek yang mengatur percakapan antara agen. Pengontrol akan membuat instansi agen, menginisialisasi mereka untuk setiap dialog, lulus input dan output dengan tepat, dan melacak statistik.
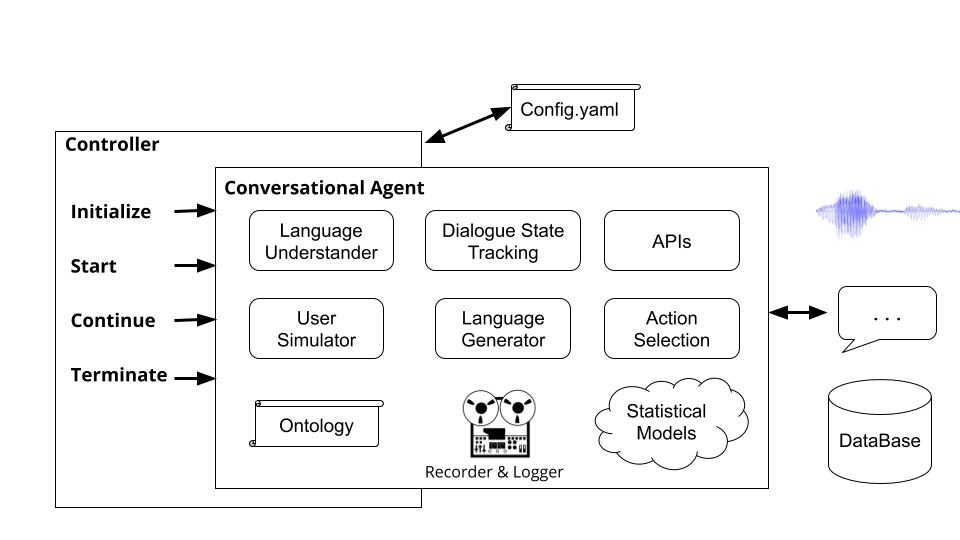
Menjalankan Perintah plato run Runs Plato's Basic Controller ( plato/controller/basic_controller.py ). Perintah ini menerima nilai untuk argumen --config yang menunjuk ke file konfigurasi aplikasi Plato.
Untuk menjalankan agen percakapan Plato, pengguna harus menjalankan perintah berikut dengan file konfigurasi yang sesuai:
plato run --config <FULL PATH TO CONFIG YAML FILE>
Silakan merujuk ke example/config/application/ misalnya file konfigurasi yang berisi pengaturan pada lingkungan dan agen yang akan dibuat serta komponennya. Contoh dalam example/config/application/ dapat dijalankan secara langsung menggunakan hanya nama file contoh yaml:
plato run --config <NAME OF A FILE FROM example/config/application/>
Atau pengguna dapat menulis file konfigurasi mereka sendiri dan menjalankan Plato dengan meneruskan jalur lengkap ke file konfigurasi mereka ke --config :
plato run --config <FULL PATH TO CONFIG YAML FILE>
Untuk nilai yang diteruskan ke --config Plato pertama memeriksa untuk melihat apakah nilainya adalah alamat file pada mesin. Jika ya, Plato mencoba mengurai file itu. Jika tidak, Plato memeriksa untuk melihat apakah nilainya adalah nama file dalam direktori example/config/application .
Setiap aplikasi AI percakapan di Plato dapat memiliki satu atau lebih agen. Setiap agen memiliki peran (sistem, pengguna, ...) dan satu set komponen sistem dialog standar (Gambar 1), yaitu NLU, Manajer Dialog, Pelacak Negara Dialog, Kebijakan, NLG, dan Simulator Pengguna.
Agen dapat memiliki satu modul eksplisit untuk masing -masing komponen ini. Atau, beberapa komponen ini dapat digabungkan menjadi satu atau lebih modul (misalnya agen sambungan / end-to-end) yang dapat berjalan secara berurutan atau paralel (Gambar 4). Komponen Plato didefinisikan dalam plato.agent.component dan semua warisan dari plato.agent.component.conversational_module
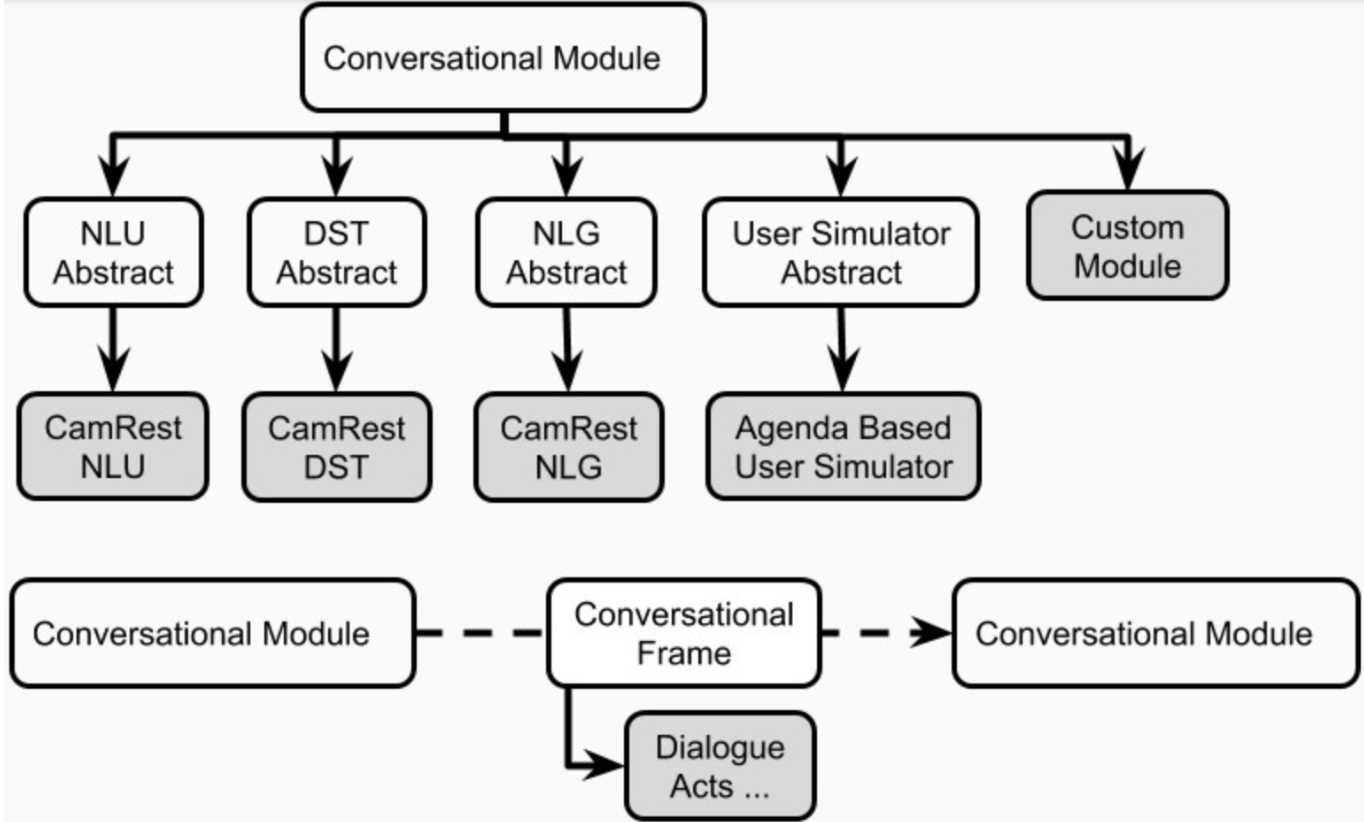 Gambar 5. Komponen agen plato
Gambar 5. Komponen agen plato
Perhatikan bahwa setiap implementasi atau modul kustom baru harus diwariskan dari plato.agent.component.conversational_module .
Masing-masing modul ini dapat berbasis aturan atau dilatih. Dalam subbagian berikut, kami akan menjelaskan cara membangun modul berbasis aturan dan terlatih untuk agen.
Plato menyediakan versi berbasis aturan dari semua komponen agen percakapan yang mengisi slot (slot_filling_nlu, slot_filling_dst, slot_filling_policy, slot_filling_nlg, dan versi default agenda_based_us). Ini dapat digunakan untuk prototipe cepat, baseline, atau cek kewarasan. Secara khusus, semua komponen ini mengikuti aturan atau pola yang dikondisikan pada ontologi yang diberikan dan kadang -kadang pada database yang diberikan dan harus diperlakukan sebagai versi paling mendasar dari apa yang harus dilakukan masing -masing komponen.
Plato mendukung pelatihan modul komponen agen dengan cara online (selama interaksi) atau offline (dari data), menggunakan kerangka kerja pembelajaran yang mendalam. Hampir setiap model dapat dimuat ke Plato selama input/output antarmuka Plato dihormati. Misalnya, jika model adalah modul NLU khusus, ia hanya perlu mewarisi dari kelas abstrak NLU Plato ( plato.agent.component.nlu ) dan mengimplementasikan metode abstrak yang diperlukan.
To facilitate online learning, debugging, and evaluation, Plato keeps track of its internal experience in a structure called the Dialogue Episode Recorder, ( plato.utilities.dialogue_episode_recorder ) which contains information about previous dialogue states, actions taken, current dialogue states, utterances received and utterances produced, rewards received, and a few other structs including a custom field that can be used to track anything else that cannot be contained by the aforementioned kategori.
Pada akhir dialog atau pada interval yang ditentukan, setiap agen percakapan akan menyebut fungsi kereta () dari masing -masing komponen internalnya, meneruskan pengalaman dialog sebagai data pelatihan. Setiap komponen kemudian memilih bagian yang dibutuhkan untuk pelatihan.
Untuk menggunakan algoritma pembelajaran yang diimplementasikan di dalam Plato, data eksternal apa pun, seperti data DSTC2, harus diuraikan ke dalam pengalaman plato ini sehingga dapat dimuat dan digunakan oleh komponen yang sesuai di bawah pelatihan.
Atau, pengguna dapat menguraikan data dan melatih model mereka di luar Plato dan cukup memuat model terlatih ketika mereka ingin menggunakannya untuk agen Plato.
Pelatihan online semudah membalik bendera 'kereta' ke 'benar' dalam konfigurasi untuk setiap komponen yang ingin dilatih oleh pengguna.
Untuk melatih dari data, pengguna hanya perlu memuat pengalaman yang mereka puring dari dataset mereka. Plato memberikan contoh parser untuk dataset DSTC2 dan Metalwoz. Sebagai contoh cara menggunakan parser ini untuk pelatihan offline di Plato, kami akan menggunakan dataset DSTC2, yang dapat diperoleh dari situs web Tantangan Pelacakan Negara Dialog ke -2:
http://camdial.org/~mh521/dstc/downloads/dstc2_traindev.tar.gz
Setelah unduhan selesai, Anda perlu membuka ritsleting file. File konfigurasi untuk parsing dataset ini disediakan pada example/config/parser/Parse_DSTC2.yaml . Anda dapat menguraikan data yang Anda unduh dengan mengedit terlebih dahulu nilai data_path dalam example/config/parser/Parse_DSTC2.yaml untuk menunjuk ke jalur ke tempat Anda mengunduh dan membuka ritsleting data DSTC2. Selanjutnya Anda dapat menjalankan skrip parse sebagai berikut:
plato parse --config Parse_DSTC2.yaml
Atau Anda dapat menulis file konfigurasi Anda sendiri dan meneruskan alamat absolut ke file itu ke perintah:
plato parse --config <absolute pass to parse config file>
Menjalankan perintah ini akan menjalankan skrip parsing untuk DSTC2 (yang hidup di bawah plato/utilities/parser/parse_dstc2.py ) dan akan membuat data pelatihan untuk pelacak negara dialog, NLU, dan NLG untuk pengguna dan sistem di bawah direktori data di direktori root repositori ini. Sekarang data yang diuraikan ini dapat digunakan untuk melatih model untuk komponen plato yang berbeda.
Ada beberapa cara untuk melatih setiap komponen agen Plato: online (karena agen berinteraksi dengan agen lain, simulator, atau pengguna) atau offline. Selain itu, Anda dapat menggunakan algoritma yang diimplementasikan di Plato atau Anda dapat menggunakan kerangka kerja eksternal seperti TensorFlow, Pytorch, Kera, Ludwig, dll.
Ludwig adalah kerangka pembelajaran mendalam sumber terbuka yang memungkinkan Anda melatih model tanpa menulis kode apa pun. Anda hanya perlu menguraikan data Anda ke dalam file .csv , membuat konfigurasi ludwig (di YAML), yang menjelaskan arsitektur yang Anda inginkan, fitur mana yang digunakan dari .csv dan parameter lainnya dan kemudian cukup jalankan perintah di terminal.
Ludwig juga menyediakan API, yang kompatibel dengan Plato. Ini memungkinkan Plato untuk berintegrasi dengan model Ludwig, yaitu memuat atau menyimpan model, melatih dan menanyakannya.
Pada bagian sebelumnya, parser DSTC2 dari Plato menghasilkan beberapa file .csv yang dapat digunakan untuk melatih NLU dan NLG. Ada satu file nlu .csv untuk sistem ( data/DSTC2_NLU_sys.csv ) dan satu untuk pengguna ( data/DSTC2_NLU_usr.csv ). Ini terlihat seperti ini:
| salinan | maksud | IOB |
|---|---|---|
| restoran mahal yang menyajikan makanan vegetarian | memberitahukan | B-inform-pricerange OOO B-inform-food o |
| makanan vegetarian | memberitahukan | B-inform-food o |
| Jenis makanan oriental Asia | memberitahukan | B-inform-food i-inform-food ooo |
| Restoran Mahal Makanan Asia | memberitahukan | Ooo b-inform-pricerange |
Untuk melatih model NLU, Anda perlu menulis file konfigurasi yang terlihat seperti ini:
input_features:
-
name: transcript
type: sequence
reduce_output: null
encoder: parallel_cnn
output_features:
-
name: intent
type: set
reduce_output: null
-
name: iob
type: sequence
decoder: tagger
dependencies: [intent]
reduce_output: null
training:
epochs: 100
early_stop: 50
learning_rate: 0.0025
dropout: 0.5
batch_size: 128
Contoh file konfigurasi ini ada dalam example/config/ludwig/ludwig_nlu_train.yaml . Pekerjaan pelatihan bisa dimulai dengan berlari:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlu_train.yaml
--data_csv data/DSTC2_NLU_sys.csv
--output_directory models/camrest_nlu/sys/
Langkah selanjutnya adalah memuat model dalam konfigurasi aplikasi. Dalam example/config/application/CamRest_model_nlu.yaml kami menyediakan konfigurasi aplikasi yang memiliki NLU berbasis model dan komponen lainnya berbasis ML. Dengan memperbarui jalur ke mode ( model_path ) ke nilai yang Anda berikan ke argumen --output_directory saat Anda menjalankan Ludwig, Anda dapat menentukan model NLU yang perlu digunakan agen untuk NLU:
...
MODULE_0:
package: applications.cambridge_restaurants.camrest_nlu
class: CamRestNLU
arguments:
model_path: <PATH_TO_YOUR_MODEL>/model
...
dan menguji bahwa model berfungsi:
plato run --config CamRest_model_nlu.yaml
Parser data DSTC2 menghasilkan dua file .csv yang dapat kita gunakan untuk dst: DST_sys.csv dan DST_usr.csv yang terlihat seperti ini:
| dst_prev_food | dst_prev_area | dst_prev_pricerange | nlu_intent | req_slot | inf_area_value | inf_food_value | INF_PRICERANGE_VALUE | dst_food | dst_area | dst_pricerange | dst_req_slot |
|---|---|---|---|---|---|---|---|---|---|---|---|
| tidak ada | tidak ada | tidak ada | memberitahukan | tidak ada | tidak ada | vegetarian | mahal | vegetarian | tidak ada | mahal | tidak ada |
| vegetarian | tidak ada | mahal | memberitahukan | tidak ada | tidak ada | vegetarian | tidak ada | vegetarian | tidak ada | mahal | tidak ada |
| vegetarian | tidak ada | mahal | memberitahukan | tidak ada | tidak ada | Asia Oriental | tidak ada | Asia Oriental | tidak ada | mahal | tidak ada |
| Asia Oriental | tidak ada | mahal | memberitahukan | tidak ada | tidak ada | Asia Oriental | mahal | Asia Oriental | tidak ada | mahal | tidak ada |
Pada dasarnya, parser melacak keadaan dialog sebelumnya, input dari NLU, dan keadaan dialog yang dihasilkan. Kami kemudian dapat memberi makan ini ke Ludwig untuk melatih pelacak negara dialog. Inilah konfigurasi ludwig yang juga dapat ditemukan di example/config/ludwig/ludwig_dst_train.yaml :
input_features:
-
name: dst_prev_food
type: category
-
name: dst_prev_area
type: category
-
name: dst_prev_pricerange
type: category
-
name: dst_intent
type: category
-
name: dst_slot
type: category
-
name: dst_value
type: category
output_features:
-
name: dst_food
type: category
-
name: dst_area
type: category
-
name: dst_pricerange
type: category
-
name: dst_req_slot
type: category
training:
epochs: 100
Kita sekarang perlu melatih model kita dengan Ludwig:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_dst_train.yaml
--data_csv data/DST_sys.csv
--output_directory models/camrest_dst/sys/
dan menjalankan agen Plato dengan DST berbasis model:
plato run --config CamRest_model_dst.yaml
Tentu saja Anda dapat bereksperimen dengan arsitektur dan parameter pelatihan lainnya.
Sejauh ini kita telah melihat cara melatih komponen agen Plato menggunakan kerangka kerja eksternal (yaitu Ludwig). Di bagian ini, kita akan melihat cara menggunakan algoritma internal Plato untuk melatih kebijakan dialog secara offline, menggunakan pembelajaran yang diawasi, dan online, menggunakan pembelajaran penguatan.
Terlepas dari file .csv , parser DSTC2 menggunakan perekam episode dialog Plato untuk juga menyimpan dialog yang diuraikan dalam log pengalaman Plato di sini: logs/DSTC2_system dan logs/DSTC2_user . Log ini berisi informasi tentang setiap dialog, misalnya keadaan dialog saat ini, tindakan yang diambil, keadaan dialog berikutnya, hadiah yang diamati, ucapan input, kesuksesan, dll. Log ini dapat secara langsung dimuat ke dalam agen percakapan dan dapat digunakan untuk mengisi kumpulan pengalaman.
Yang perlu Anda lakukan adalah menulis file konfigurasi yang memuat log ini ( example/config/CamRest_model_supervised_policy_train.yaml ):
GENERAL:
...
experience_logs:
save: False
load: True
path: logs/DSTC2_system
...
DIALOGUE:
# Since this configuration file trains a supervised policy from data loaded
# from the logs, we only really need one dialogue just to trigger the train.
num_dialogues: 1
initiative: system
domain: CamRest
AGENT_0:
role: system
max_turns: 15
train_interval: 1
train_epochs: 100
save_interval: 1
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.supervised_policy
class: SupervisedPolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_supervised_data
...
Perhatikan bahwa kami hanya menjalankan agen ini untuk satu dialog tetapi melatih untuk 100 zaman, menggunakan pengalaman yang dimuat dari log:
plato run --config CamRest_model_supervised_policy_train.yaml
Setelah pelatihan selesai, kami dapat menguji kebijakan kami yang diawasi:
plato run --config CamRest_model_supervised_policy_test.yaml
Pada bagian sebelumnya, kami melihat cara melatih kebijakan dialog yang diawasi. Kita sekarang dapat melihat bagaimana kita dapat melatih kebijakan pembelajaran penguatan, menggunakan algoritma penguat. Untuk melakukan ini, kami mendefinisikan kelas yang relevan dalam file konfigurasi:
...
AGENT_0:
role: system
max_turns: 15
train_interval: 500
train_epochs: 3
train_minibatch: 200
save_interval: 5000
...
DM:
package: plato.agent.component.dialogue_manager.dialogue_manager_generic
class: DialogueManagerGeneric
arguments:
DST:
package: plato.agent.component.dialogue_state_tracker.slot_filling_dst
class: SlotFillingDST
policy:
package: plato.agent.component.dialogue_policy.deep_learning.reinforce_policy
class: ReinforcePolicy
arguments:
train: True
learning_rate: 0.9
exploration_rate: 0.995
discount_factor: 0.95
learning_decay_rate: 0.95
exploration_decay_rate: 0.995
policy_path: models/camrest_policy/sys/sys_reinforce
...
Perhatikan parameter pembelajaran di bawah AGENT_0 dan parameter khusus algoritmik di bawah argumen kebijakan. Kami kemudian memanggil Plato dengan konfigurasi ini:
plato run --config CamRest_model_reinforce_policy_train.yaml
dan menguji model kebijakan yang terlatih:
plato run --config CamRest_model_reinforce_policy_test.yaml
Perhatikan bahwa komponen lain juga dapat dilatih secara online, baik menggunakan API Ludwig atau dengan menerapkan algoritma pembelajaran di Plato.
Perhatikan juga bahwa file log dapat dimuat dan digunakan sebagai kumpulan pengalaman untuk setiap komponen dan algoritma pembelajaran. Namun, Anda mungkin perlu menerapkan algoritma pembelajaran Anda sendiri untuk beberapa komponen Plato.
Untuk melatih modul NLG, Anda perlu menulis file konfigurasi yang terlihat seperti ini (misalnya example/config/application/CamRest_model_nlg.yaml ):
---
input_features:
-
name: nlg_input
type: sequence
encoder: rnn
cell_type: lstm
output_features:
-
name: nlg_output
type: sequence
decoder: generator
cell_type: lstm
training:
epochs: 20
learning_rate: 0.001
dropout: 0.2
dan latih model Anda:
ludwig experiment
--model_definition_file example/config/ludwig/ludwig_nlg_train.yaml
--data_csv data/DSTC2_NLG_sys.csv
--output_directory models/camrest_nlg/sys/
Langkah selanjutnya adalah memuat model di Plato. Buka file konfigurasi CamRest_model_nlg.yaml dan perbarui jalur jika perlu:
...
NLG:
package: applications.cambridge_restaurants.camrest_nlg
class: CamRestNLG
arguments:
model_path: models/camrest_nlg/sys/experiment_run/model
...
dan menguji bahwa model berfungsi:
plato run --config CamRest_model_nlg.yaml
Ingatlah bahwa Ludwig akan membuat direktori Experiment_Run_i baru setiap kali dipanggil, jadi pastikan Anda menjaga jalur yang benar di konfigurasi Plato up to date.
Perhatikan bahwa Ludwig juga menawarkan metode untuk melatih model Anda secara online, jadi dalam praktiknya Anda perlu menulis kode yang sangat sedikit untuk membangun, melatih, dan mengevaluasi komponen pembelajaran mendalam baru di Plato.
Untuk contoh ini, kami akan menggunakan dataset MetalWoz yang dapat Anda unduh dari sini.
Plato mendukung model yang terlatih bersama melalui agen generik. Di sini kita akan melihat langkah -langkah yang diperlukan untuk membuat agen percakapan SEQ2SEQ sederhana dari awal. Menggunakan Metalwoz sebagai contoh, kita perlu melakukan hal berikut:
Karena kami hanya melatih model SEQ2SEQ sederhana (teks ke teks), kami membutuhkan parser kami untuk mengekstrak ucapan pengguna dan sistem. Ini akan disimpan dalam file .csv yang akan digunakan oleh Ludwig pada Langkah 4.
Untuk implementasi sederhana dari parser metalwoz, lihat utilities/parser/Parse_MetalWOZ.py
Harap dicatat bahwa parser ini hanya akan mengurai satu file tunggal (satu domain). Anda dapat dengan mudah memodifikasinya, agar sesuai dengan kebutuhan Anda. Berikut adalah contoh output yang dihasilkan oleh parser untuk domain pemesanan pizza:
| pengguna | sistem |
|---|---|
| Hai | Halo bagaimana saya bisa membantu Anda? |
| Saya perlu melakukan pemesanan untuk pizza membutuhkan bantuan | Tentu saja, apa yang ingin Anda tambahkan ke pesanan Anda? |
| Saya ingin pizza dengan topping jamur, pepperoni, dan bacon | Sayangnya, lokasi ini keluar dari topping bacon yang Anda minta. Apakah akan ada topping berbeda yang ingin Anda gantikan? |
| Bagaimana dengan nanas | Topping itu tersedia. Saya telah menambahkan pizza dengan jamur, pepperoni, dan nanas ke pesanan Anda. Ukuran apa yang Anda inginkan? |
| Sedang | Baiklah, diperbarui. Apakah Anda ingin menambahkan lebih banyak ke pesanan Anda? |
| Itu saja, terima kasih | Baiklah, total Anda adalah 14,99. Pizza Anda akan siap untuk dipetik dengan kira -kira. 20 menit. |
Perhatikan ucapan pengguna pertama tidak benar -benar ada dalam data. Namun, kami membutuhkan sesuatu untuk mendorong model untuk menghasilkan salam sistem - kami bisa menggunakan kalimat kosong, atau salam lainnya (atau kombinasi dari ini).
Anda kemudian dapat menjalankan Plato Parse sebagai berikut:
plato parse --config Parse_MetalWOZ.yaml
Untuk memulai, kami dapat melatih model yang sangat sederhana menggunakan Ludwig (jangan ragu untuk menggunakan kerangka pembelajaran mendalam favorit Anda di sini):
input_features:
-
name: user
type: text
level: word
encoder: rnn
cell_type: lstm
reduce_output: null
output_features:
-
name: system
type: text
level: word
decoder: generator
cell_type: lstm
attention: bahdanau
training:
epochs: 100
Anda dapat memodifikasi konfigurasi ini untuk mencerminkan arsitektur pilihan Anda dan melatih menggunakan Ludwig:
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file example/config/ludwig/metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
Kelas ini hanya perlu menangani pemuatan model, menanyakannya dengan tepat dan memformat outputnya dengan tepat. Dalam kasus kami, kami perlu membungkus teks input ke dalam DataFrame PANDAS, ambil token yang diprediksi dari output dan bergabunglah dalam string yang akan dikembalikan. Lihat kelas di sini: plato.agent.component.joint_model.metal_woz_seq2seq.py
Lihat example/config/application/metalwoz_generic.yaml untuk contoh file konfigurasi generik yang berinteraksi dengan agen seq2seq melalui teks. Anda dapat mencobanya sebagai berikut:
plato run --config metalwoz_text.yaml
Ingatlah untuk memperbarui jalur ke model terlatih Anda jika perlu! Jalur default mengasumsikan Anda menjalankan perintah kereta Ludwig dari direktori root Plato.
Salah satu fitur utama Plato memungkinkan dua agen untuk berinteraksi satu sama lain. Setiap agen dapat memiliki peran yang berbeda (misalnya, sistem dan pengguna), tujuan yang berbeda, dan menerima sinyal hadiah yang berbeda. Jika agen bekerja sama, beberapa di antaranya dapat dibagikan (misalnya, apa yang merupakan dialog yang sukses).
Untuk menjalankan beberapa agen Plato di domain Cambridge Restaurants, kami menjalankan perintah berikut untuk melatih kebijakan dialog agen dan mengujinya:
Fase Pelatihan: 2 Kebijakan (1 untuk setiap agen) dilatih. Kebijakan ini dilatih menggunakan algoritma serigala:
plato run --config MultiAgent_train.yaml
Fase Pengujian: Menggunakan kebijakan yang dilatih dalam fase pelatihan untuk membuat dialog antara dua agen:
plato run --config MultiAgent_test.yaml
Sementara pengontrol dasar saat ini memungkinkan dua interaksi agen, cukup mudah untuk memperluasnya ke beberapa agen (misalnya dengan arsitektur papan tulis, di mana setiap agen menyiarkan outputnya ke agen lain). Ini dapat mendukung skenario seperti Smart Homes, di mana setiap perangkat adalah agen, interaksi multi-pengguna dengan berbagai peran, dan banyak lagi.
Plato menyediakan implementasi untuk dua jenis simulator pengguna. Salah satunya adalah simulator pengguna berbasis agenda yang sangat terkenal, dan yang lainnya adalah simulator yang mencoba meniru perilaku pengguna yang diamati dalam data. Namun, kami mendorong para peneliti untuk hanya melatih dua agen percakapan dengan Plato (satu menjadi 'sistem' dan satu menjadi 'pengguna') alih -alih menggunakan pengguna yang disimulasikan, jika memungkinkan.
Simulator pengguna berbasis agenda diusulkan oleh Schatzmann dan dijelaskan secara rinci dalam makalah ini. Secara konseptual, simulator mempertahankan "agenda" hal -hal yang dapat dikatakan, yang biasanya diimplementasikan sebagai tumpukan. Ketika simulator menerima input, ia berkonsultasi dengan kebijakannya (atau set aturannya) untuk melihat konten apa yang harus didorong ke dalam agenda, sebagai respons terhadap input. Setelah beberapa rumah tangga (misalnya menghapus duplikat atau konten yang tidak lagi valid), simulator akan mengeluarkan satu atau lebih item dari agenda yang akan digunakan untuk merumuskan responsnya.
Simulator pengguna berbasis agenda juga memiliki modul simulasi kesalahan, yang dapat mensimulasikan kesalahan pengenalan ucapan / pemahaman bahasa. Berdasarkan beberapa probabilitas, itu akan mendistorsi tindakan dialog output simulator - niat, slot, atau nilai (probabilitas yang berbeda untuk masing -masing). Berikut adalah contoh dari daftar lengkap parameter yang diterima simulator ini:
patience: 5 # Stop after <patience> consecutive identical inputs received
pop_distribution: [0.8, 0.15, 0.05] # pop 1 act with 0.8 probability, 2 acts with 0.15, etc.
slot_confuse_prob: 0.05 # probability by which the error model will alter the output dact slot
op_confuse_prob: 0.01 # probability by which the error model will alter the output dact operator
value_confuse_prob: 0.01 # probability by which the error model will alter the output dact value
nlu: slot_filling # type of NLU the simulator will use
nlg: slot_filling # type of NLG the simulator will use
Simulator ini dirancang untuk menjadi simulator berbasis kebijakan sederhana, yang dapat beroperasi di tingkat Undang-Undang Dialog atau di tingkat ucapan. Untuk menunjukkan cara kerjanya, parser DSTC2 membuat file kebijakan untuk simulator ini: user_policy_reactive.pkl (reaktif karena bereaksi terhadap dialog sistem bertindak alih -alih status simulator pengguna). Ini sebenarnya kamus sederhana dari:
System Dial. Act 1 --> {'dacts': {User Dial. Act 1: probability}
{User Dial. Act 2: probability}
...
'responses': {User utterance 1: probability}
{User utterance 2: probability}
...
System Dial. Act 2 --> ...
Kunci tersebut mewakili Undang -Undang Dialog Input (misalnya berasal dari Agen Percakapan system ). Nilai masing -masing kunci adalah kamus dari dua elemen, mewakili distribusi probabilitas atas tindakan dialog atau templat ucapan yang akan sampel simulator.
Untuk melihat contoh, Anda dapat menjalankan konfigurasi berikut:
plato run --config CamRest_dtl_simulator.yaml
Ada dua cara untuk membuat modul baru tergantung pada fungsinya. Jika sebuah modul, misalnya, mengimplementasikan cara baru untuk melakukan NLU atau kebijakan dialog, maka Anda harus menulis kelas yang mewarisi dari kelas abstrak yang sesuai.
Namun, jika modul tidak sesuai dengan salah satu komponen dasar agen tunggal, misalnya, ia melakukan pengenalan entitas yang disebutkan atau memprediksi tindakan dialog dari teks, maka Anda harus menulis kelas yang mewarisi dari conversational_module secara langsung. Anda kemudian dapat memuat modul melalui agen generik dengan memberikan jalur paket yang sesuai, nama kelas, dan argumen dalam konfigurasi.
...
MODULE_i:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
Hati-hati! Anda bertanggung jawab untuk menjamin bahwa I/O dari modul ini dapat diproses dan dikonsumsi dengan tepat oleh modul sebelum dan sesudah, sebagaimana ditentukan dalam file konfigurasi generik Anda.
Plato juga mendukung eksekusi paralel modul (secara logis). Untuk memungkinkan Anda perlu memiliki struktur berikut di konfigurasi Anda:
...
MODULE_i:
parallel_modules: 5
PARALLEL_MODULE_0:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/myModule/parameters/
...
PARALLEL_MODULE_1:
package: my_package.my_module
Class: MyModule
arguments:
model_path: models/my_module/parameters/
...
...
...
Hati-hati! Output dari modul yang dieksekusi secara paralel akan dikemas ke dalam daftar. Modul berikutnya (misalnya MODULE_i+1 ) harus dapat menangani input semacam ini. Modul Plato yang disediakan tidak dirancang untuk menangani ini, Anda perlu menulis modul khusus untuk memproses input dari berbagai sumber.
Plato dirancang agar dapat diperluas, jadi silakan membuat negara bagian dialog Anda sendiri, tindakan, fungsi hadiah, algoritma, atau komponen lain yang sesuai dengan kebutuhan spesifik Anda. Anda hanya perlu mewarisi dari kelas yang sesuai untuk memastikan implementasi Anda kompatibel dengan Plato.
Plato menggunakan pysimplui untuk menangani antarmuka pengguna grafis. Contoh GUI untuk Plato diimplementasikan di plato.controller.sgui_controller dan Anda dapat mencobanya menggunakan perintah berikut:
plato gui --config CamRest_GUI_speech.yaml
Special thanks to Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, Michael Pearce, Zack Kaden, and Gokhan Tur for their contributions and support, and to studio FF3300 for allowing us to use the Messapia font.
Please understand that many features are still being implemented and some use cases may not be supported yet.
Menikmati!


