TextBrewer
TextBrewer 0.2.1
英語|中文說明

TextBrewer是一種基於Pytorch的模型蒸餾工具包,用於自然語言處理。它包括來自NLP和CV領域的各種蒸餾技術,並提供了易於使用的蒸餾框架,該框架使用戶可以快速嘗試使用最新的蒸餾方法來以相對較小的性能犧牲,從而增加推理速度和減少記憶使用情況。
通過ACL選集或ARXIV預印刷檢查我們的論文。
完整的文檔
2021年12月17日
2021年10月24日
7月8日,2021年
2021年3月1日
Bert-Emd和自定義蒸餾器
更新的MNLI示例
2020年11月11日
更新為0.2.1 :
更靈活的蒸餾:支持向學生和老師餵食不同的批次。這意味著學生和老師的批次不再需要相同。它可用於具有不同詞彙的蒸餾模型(例如,從羅伯塔到伯特)。
更快的蒸餾速度:用戶現在可以預先計算和緩存老師的輸出,然後將緩存饋送到蒸餾器中,以節省老師的前進時間。
有關上述功能的詳細信息,請參閱學生和老師的不同批次,供給緩存的值。
MultiTaskDistiller現在支持中間功能匹配損失。
張板現在記錄了更詳細的損失(KD損失,硬標籤損失,匹配損失...)。
請參閱發行中的詳細信息。
2020年8月27日
我們很高興地宣布,我們的模型位於膠水基準的頂部,Check Legardboard。
2020年8月24日
MultiTaskDistiller和培訓循環中的錯誤。7月29日,2020年
DistributedDataParallel : TrainingConfig現在正調光local_rank參數。有關詳細信息,請參見TrainingConfig的文檔。2020年7月14日
fp16設置為True TrainingConfig 。有關詳細信息,請參見TrainingConfig的文檔。TrainingConfig中添加了data_parallel選項,以啟用數據並行培訓和混合精度培訓一起工作。2020年4月26日
2020年4月22日
2020年3月17日
2020年3月11日
2020年3月2日
| 部分 | 內容 |
|---|---|
| 介紹 | 簡介Textbrewer |
| 安裝 | 如何安裝 |
| 工作流程 | Textbrewer工作流的兩個階段 |
| Quickstart | 示例:將bert鹼蒸餾到3層伯特 |
| 實驗 | 典型英語和中文數據集的蒸餾實驗 |
| 核心概念 | 簡要說明Textbrewer中的核心概念 |
| 常問問題 | 常見問題 |
| 已知問題 | 已知問題 |
| 引用 | 引用Textbrewer |
| 跟著我們 | - |
TextBrewer專為NLP模型的知識蒸餾而設計。它提供了各種蒸餾方法,並提供了一個快速設置實驗的蒸餾框架。
Textbrewer的主要特徵是:
Textbrewer目前已採用以下蒸餾技術:
Textbrewer包括:
要開始蒸餾,用戶需要提供
Textbrewer在幾個典型的NLP任務上取得了令人印象深刻的結果。參見實驗。
有關詳細用法,請參見完整的文檔。
要求
從PYPI安裝
pip install textbrewer從GitHub源安裝
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer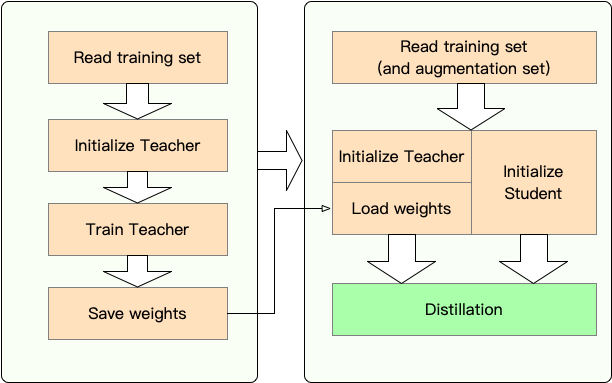
階段1 :準備:
第2階段:與Textbrewer蒸餾:
在這裡,我們通過將Bert-Base蒸餾到3層Bert來顯示Textbrewer的用法。
在蒸餾之前,我們假設用戶提供了:
teacher_model (Bert-base)和接受訓練的學生模型student_model (3層BERT)。optimizer和學習率構建器或類scheduler_class及其ARGS dict dict scheduler_dict的dataloader 。與Textbrewer提煉:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )帶有變壓器4的筆記本示例4
示例/Random_token_example:一個簡單的可運行玩具示例,演示了TextBrewer的用法。此示例將隨機令牌作為輸入對文本分類任務進行蒸餾。
示例/cmrc2018_example(中文):使用DRCD作為數據增強的中文MRC任務進行CMRC 2018蒸餾。
示例/mnli_example(英語):MNLI上的蒸餾,英語句子對任務。此示例還顯示瞭如何執行多教師蒸餾。
示例/conll2003_example(英語):Conll-2003英語NER任務上的蒸餾,該任務的形式為序列標籤。
示例/MSRA_NER_EXAMPE(中文):此示例通過分佈式數據並行訓練(單節點,多GPU)在MSRA NER任務上提取中文 - 電子基礎模型。
我們已經對幾個典型的英語和中文NLP數據集進行了蒸餾實驗。設置和配置在下面列出。
我們已經測試了不同的學生模型。為了與公共結果進行比較,學生模型是由標準變壓器塊構建的,除了Bigru是單層雙向GRU。體系結構在下面列出。請注意,參數的數量包括嵌入層,但不包括每個特定任務的輸出層。
| 模型 | #layers | 隱藏尺寸 | 進料尺寸 | #params | 相對大小 |
|---|---|---|---|---|---|
| 伯特 - 基準(老師) | 12 | 768 | 3072 | 108m | 100% |
| T6(學生) | 6 | 768 | 3072 | 65m | 60% |
| T3(學生) | 3 | 768 | 3072 | 44m | 41% |
| T3-small(學生) | 3 | 384 | 1536年 | 17m | 16% |
| T4微小(學生) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano(學生) | 12 | 256 | 1024 | 17m | 16% |
| Bigru(學生) | - | 768 | - | 31m | 29% |
| 模型 | #layers | 隱藏尺寸 | 進料尺寸 | #params | 相對大小 |
|---|---|---|---|---|---|
| Roberta-wwm-ext(老師) | 12 | 768 | 3072 | 102m | 100% |
| 伊萊克斯基(老師) | 12 | 768 | 3072 | 102m | 100% |
| T3(學生) | 3 | 768 | 3072 | 38m | 37% |
| T3-small(學生) | 3 | 384 | 1536年 | 14m | 14% |
| T4微小(學生) | 4 | 312 | 1200 | 11m | 11% |
| electra-small(學生) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values不同模型的matches不同:
| 模型 | 比賽 |
|---|---|
| Bigru | 沒有任何 |
| T6 | L6_HIDDER_MSE + L6_HIDDER_SMMD |
| T3 | L3_HIDDER_MSE + L3_HIDDER_SMMD |
| T3-small | L3N_HIDDER_MSE + L3_HIDDER_SMMD |
| T4小型 | L4T_HIDDER_MSE + L4_HIDDER_SMMD |
| T12-nano | small_hidden_mse + small_hidden_smmd |
| Electra-small | small_hidden_mse + small_hidden_smmd |
比賽的定義是在示例/匹配/匹配中。
我們在所有蒸餾實驗中使用GeneralDistiller。
我們在以下典型的英語數據集上進行實驗:
| 數據集 | 任務類型 | 指標 | #火車 | #dev | 筆記 |
|---|---|---|---|---|---|
| mnli | 文本分類 | m/mm acc | 393K | 20k | 句子對3類分類 |
| 小隊1.1 | 閱讀理解 | EM/F1 | 88K | 11k | 跨摘除機讀取理解 |
| Conll-2003 | 序列標記 | F1 | 23k | 6k | 命名實體識別 |
我們列出了Distilbert,Bert-PKD,Bert-of Theseus,Tinybert的公共結果以及下面的結果以進行比較。
公眾結果:
| 模型(公共) | mnli | 隊 | Conll-2003 |
|---|---|---|---|
| Distilbert(T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| BERT 6 -PKD(T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| 這些伯(T6) | 82.4/ 82.1 | - | - |
| Bert 3 -pkd(T3) | 76.7 / 76.3 | - | - |
| Tinybert(T4微小) | 82.8 / 82.9 | 72.7 / 82.1 | - |
我們的結果:
| 模型(我們的) | mnli | 隊 | Conll-2003 |
|---|---|---|---|
| 伯特 - 基準(老師) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4小型 | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
筆記:
我們在以下典型的中文數據集上進行實驗:
| 數據集 | 任務類型 | 指標 | #火車 | #dev | 筆記 |
|---|---|---|---|---|---|
| xnli | 文本分類 | ACC | 393K | 2.5k | 中文翻譯版本的mnli |
| LCQMC | 文本分類 | ACC | 239k | 8.8k | 句子對匹配,二進制分類 |
| CMRC 2018 | 閱讀理解 | EM/F1 | 10k | 3.4k | 跨摘除機讀取理解 |
| drcd | 閱讀理解 | EM/F1 | 27k | 3.5k | 跨度挖掘機閱讀理解(傳統中文) |
| MSRA NER | 序列標記 | F1 | 45k | 3.4k(#test) | 中文命名實體認可 |
結果如下列出。
| 模型 | xnli | LCQMC | CMRC 2018 | drcd |
|---|---|---|---|---|
| Roberta-wwm-ext (老師) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4小型 | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| 模型 | xnli | LCQMC | CMRC 2018 | drcd | MSRA NER |
|---|---|---|---|---|---|
| 伊萊克斯(老師)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electra-small | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
筆記:
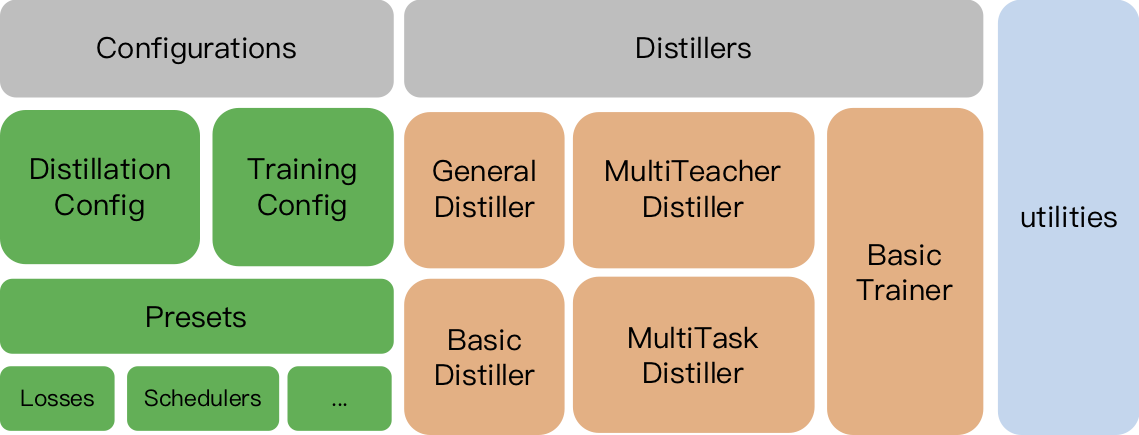
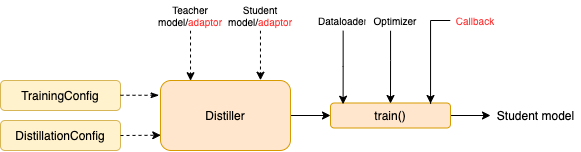
TrainingConfig :與一般深度學習模型培訓有關的配置DistillationConfig :與蒸餾方法有關的配置釀酒師負責進行實際的實驗。可用以下釀酒廠:
BasicDistiller :單師單任務蒸餾,提供了基本的蒸餾策略。GeneralDistiller (推薦):單師單任務蒸餾,支持中間功能匹配。大多數時候推薦。MultiTeacherDistiller :多教師蒸餾器,將多個教師模型(同一任務)提煉成單個學生模型。該類不支持中間功能匹配。MultiTaskDistiller :多任務蒸餾,將多個教師模型(不同任務)提煉成一個學生。BasicTrainer :監督培訓標記數據集上的單個模型,而不是用於蒸餾。它可用於培訓教師模型。在TextBrewer中,用戶應該實現兩個功能:回調和適配器。
在每個檢查點,保存學生模型後,蒸餾器將調用回調功能。可以使用回調來評估每個檢查點學生模型的性能。
它將模型輸入和輸出轉換為指定的格式,以便可以通過蒸餾器識別它們,並可以計算蒸餾損失。在每個訓練步驟中,批處理和模型輸出將傳遞給適配器;適配器重組數據並返回字典。
有關更多詳細信息,請參閱完整文檔中的說明。
問:如何初始化學生模型?
答:學生模型可以隨機初始化(即沒有先驗知識),也可以通過預先訓練的權重初始化。例如,當將BERT基本模型提煉為三層BERT時,您可以使用RBT3(用於中文任務)或BERT(用於英語任務)的前三層來初始化學生模型,以避免冷啟動問題。我們建議用戶盡可能使用預訓練的學生模型來充分利用大規模的預培訓。
問:如何為蒸餾實驗設置訓練超參數?
答:知識蒸餾通常需要比標記的數據集上的培訓更多的培訓時期和更高的學習率。例如,BERT鹼基上的訓練小隊通常需要3個時代,而LR = 3E-5。但是,蒸餾需要30〜50個時期,而LR = 1E-4。結論是基於我們的實驗,建議您嘗試自己的數據。
問:我的老師模型和學生模型採用不同的輸入(它們不共享詞彙),那麼我該如何提煉?
答:您需要向老師和學生提供不同的批次。請參閱該部分為學生和老師提供不同的批次,並在完整文檔中為緩存的值提供。
問:我已經存儲了老師模型的邏輯。我可以在蒸餾中使用它們來節省前進時間嗎?
答:是的,請參閱本部分向學生和老師提供不同的批次,在完整文檔中為緩存的值提供。
DataParallel提供。如果您發現Textbrewer很有幫助,請引用我們的論文:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}請按照我們的官方微信帳戶進行最新技術!



