TextBrewer
TextBrewer 0.2.1
英語|中文说明

TextBrewerは、自然言語処理のためのPytorchベースのモデル蒸留ツールキットです。これには、NLPフィールドとCVフィールドの両方からのさまざまな蒸留技術が含まれており、使いやすい蒸留フレームワークを提供するため、ユーザーはパフォーマンスの比較的小さな犠牲でモデルを圧縮し、推論速度を高め、メモリ使用量を減らすことができます。
ACLアンソロジーまたはARXIVプリプリントを通じて論文を確認してください。
完全なドキュメント
2021年12月17日
2021年10月24日
2021年7月8日
2021年3月1日
Bert-EMDおよびカスタム蒸留器
MNLIの例を更新しました
2020年11月11日
0.2.1に更新:
より柔軟な蒸留:生徒と教師にさまざまなバッチを与えることをサポートします。これは、生徒と教師のバッチが同じである必要がなくなることを意味します。異なる語彙(ロベルタからバートまで)でモデルを蒸留するために使用できます。
より速い蒸留:ユーザーは、教師の出力を事前に計算してキャッシュし、キャッシュを蒸留器に供給して、教師の前方パス時間を節約できるようになりました。
上記の機能の詳細については、学生と教師へのさまざまなバッチのフィードを参照してください。
MultiTaskDistiller 、中間機能のマッチング損失をサポートするようになりました。
Tensorboardは、より詳細な損失(KD損失、ハードラベル損失、一致する損失...)を記録しました。
リリースの詳細を参照してください。
2020年8月27日
私たちのモデルが接着剤ベンチマークの上にあることをお知らせします。
2020年8月24日
MultiTaskDistillerとトレーニングループのバグを修正しました。2020年7月29日
DistributedDataParallel : TrainingConfigを使用した分散データパラレルトレーニングのサポートを追加しました。Configはlocal_rank引数を説明しました。詳細については、 TrainingConfigのドキュメントを参照してください。2020年7月14日
TrainingConfigでfp16 Trueに設定するだけです。詳細については、 TrainingConfigのドキュメントを参照してください。TrainingConfigにdata_parallelオプションを追加しました。2020年4月26日
2020年4月22日
2020年3月17日
2020年3月11日
2020年3月2日
| セクション | コンテンツ |
|---|---|
| 導入 | TextBrewerの紹介 |
| インストール | インストール方法 |
| ワークフロー | TextBrewerワークフローの2つの段階 |
| クイックスタート | 例:バートベースを3層バートに蒸留します |
| 実験 | 典型的な英語と中国のデータセットでの蒸留実験 |
| コアコンセプト | TextBrewerのコア概念の簡単な説明 |
| よくある質問 | よくある質問 |
| 既知の問題 | 既知の問題 |
| 引用 | TextBrewerへの引用 |
| 私たちに従ってください | - |
TextBrewerは、NLPモデルの知識蒸留用に設計されています。さまざまな蒸留方法を提供し、実験を迅速に設定するための蒸留フレームワークを提供します。
TextBrewerの主な機能は次のとおりです。
TextBrewerは現在、次の蒸留技術を添加しています。
TextBrewerが含まれます。
蒸留を開始するには、ユーザーが提供する必要があります
TextBrewerは、いくつかの典型的なNLPタスクで印象的な結果を達成しました。実験を参照してください。
詳細な使用については、完全なドキュメントを参照してください。
要件
Pypiからインストールします
pip install textbrewerGitHubソースからインストールします
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer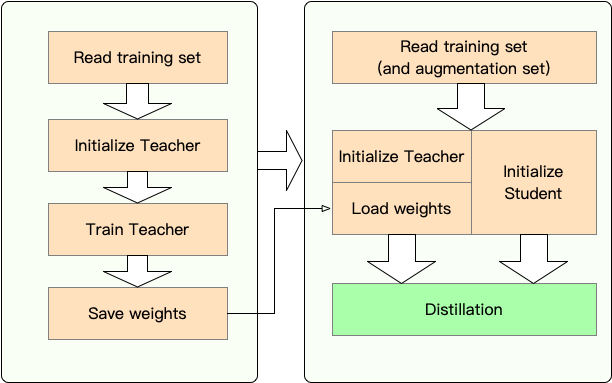
ステージ1 :準備:
ステージ2 :TextBrewerによる蒸留:
ここでは、バートベースを3層バートに蒸留することにより、テキストブリューアの使用を示します。
蒸留前に、ユーザーが提供していると想定しています。
teacher_model (Bert-Base)と訓練を受けた学生モデルstudent_model (3層Bert)。dataloader 、 optimizer 、学習レートビルダーまたはクラスscheduler_classおよびそのargs dict scheduler_dict 。TextBrewerで蒸留する:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )トランスのあるノートブックの例4
Examples/random_token_example:TextBrewerの使用を示す単純な実行可能なおもちゃの例。この例は、入力としてランダムトークンを使用したテキスト分類タスクの蒸留を実行します。
Examples/CMRC2018_Example(中国語):DRCDをデータ増強として使用する中国のMRCタスクであるCMRC 2018の蒸留。
例/mnli_example(英語):MNLIの蒸留、英語の文章分類タスク。この例は、マルチティーチャーの蒸留を実行する方法も示しています。
Examples/conll2003_example(英語):CONLL-2003英語NERタスクの蒸留。これは、シーケンスラベルの形式です。
例/msra_ner_example(中国語):この例では、分散並列トレーニング(シングルノード、マルチGPU)を使用して、MSRA NERタスクの中国電気ベースモデルを蒸留します。
いくつかの典型的な英語と中国のNLPデータセットで蒸留実験を実施しました。セットアップと構成は以下にリストされています。
さまざまな学生モデルをテストしました。公的な結果と比較するために、学生モデルは、単一層の双方向GRUであるBigruを除く標準的な変圧器ブロックで構築されます。アーキテクチャは以下にリストされています。パラメーターの数には埋め込み層が含まれていますが、各特定のタスクの出力層は含まれていないことに注意してください。
| モデル | #Layers | 隠されたサイズ | フィードフォワードサイズ | #params | 相対サイズ |
|---|---|---|---|---|---|
| バートベースケース(教師) | 12 | 768 | 3072 | 108m | 100% |
| T6(学生) | 6 | 768 | 3072 | 65m | 60% |
| T3(学生) | 3 | 768 | 3072 | 44m | 41% |
| T3-Small(学生) | 3 | 384 | 1536 | 17m | 16% |
| T4-TINY(学生) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano(学生) | 12 | 256 | 1024 | 17m | 16% |
| Bigru(学生) | - | 768 | - | 31m | 29% |
| モデル | #Layers | 隠されたサイズ | フィードフォワードサイズ | #params | 相対サイズ |
|---|---|---|---|---|---|
| roberta-wwm-ext(教師) | 12 | 768 | 3072 | 102m | 100% |
| エレクトラベース(教師) | 12 | 768 | 3072 | 102m | 100% |
| T3(学生) | 3 | 768 | 3072 | 38m | 37% |
| T3-Small(学生) | 3 | 384 | 1536 | 14m | 14% |
| T4-TINY(学生) | 4 | 312 | 1200 | 11m | 11% |
| Electra-Small(学生) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default valuesモデルごとにmatches異なります:
| モデル | マッチ |
|---|---|
| Bigru | なし |
| T6 | l6_hidden_mse + l6_hidden_smmd |
| T3 | l3_hidden_mse + l3_hidden_smmd |
| T3-Small | l3n_hidden_mse + l3_hidden_smmd |
| T4-tiny | l4t_hidden_mse + l4_hidden_smmd |
| T12-Nano | Small_hidden_mse + small_hidden_smmd |
| Electra-Small | Small_hidden_mse + small_hidden_smmd |
一致の定義は、例/matches/matches.pyにあります。
すべての蒸留実験でGeneralDistillerを使用しています。
次の典型的な英語のデータセットで実験します。
| データセット | タスクタイプ | メトリック | #電車 | #dev | 注記 |
|---|---|---|---|---|---|
| mnli | テキスト分類 | m/mm acc | 393k | 20k | 文章3クラス分類 |
| 分隊1.1 | 読解 | EM/F1 | 88k | 11k | スパン抽出マシンの読解 |
| CONLL-2003 | シーケンスラベル付け | F1 | 23k | 6k | 名前付きエンティティ認識 |
Distilbert、Bert-PKD、Bert-of-Sheseus、Tinybertの結果と、比較のために以下の結果をリストしています。
公的な結果:
| モデル(パブリック) | mnli | 分隊 | CONLL-2003 |
|---|---|---|---|
| Distilbert(T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| バート6 -pkd(T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| バートオブセセウス(T6) | 82.4/ 82.1 | - | - |
| バート3 -pkd(T3) | 76.7 / 76.3 | - | - |
| Tinybert(T4-Tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
私たちの結果:
| モデル(私たちのもの) | mnli | 分隊 | CONLL-2003 |
|---|---|---|---|
| バートベースケース(教師) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-Small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4-tiny | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-Nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
注記:
次の典型的な中国のデータセットで実験します。
| データセット | タスクタイプ | メトリック | #電車 | #dev | 注記 |
|---|---|---|---|---|---|
| xnli | テキスト分類 | acc | 393k | 2.5k | MNLIの中国語翻訳バージョン |
| LCQMC | テキスト分類 | acc | 239k | 8.8k | 文章マッチング、バイナリ分類 |
| CMRC 2018 | 読解 | EM/F1 | 10k | 3.4k | スパン抽出マシンの読解 |
| DRCD | 読解 | EM/F1 | 27k | 3.5k | スパン抽出マシンの読解力(伝統的な中国語) |
| Msra Ner | シーケンスラベル付け | F1 | 45k | 3.4k(#test) | 中国の名前付きエンティティ認識 |
結果を以下に示します。
| モデル | xnli | LCQMC | CMRC 2018 | DRCD |
|---|---|---|---|---|
| roberta-wwm-ext (教師) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-Small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4-tiny | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| モデル | xnli | LCQMC | CMRC 2018 | DRCD | Msra Ner |
|---|---|---|---|---|---|
| エレクトラベース(教師)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electra-Small | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
注記:
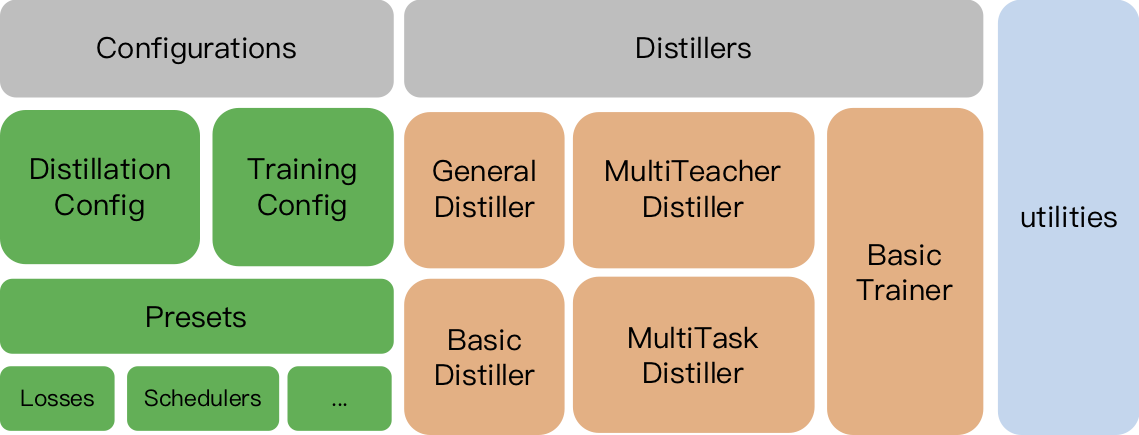
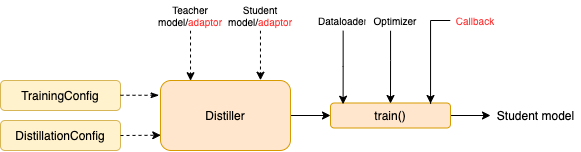
TrainingConfig :一般的なディープラーニングモデルトレーニングに関連する構成DistillationConfig :蒸留方法に関連する構成蒸留器は、実際の実験の実施を担当しています。次の蒸留器が利用可能です。
BasicDistiller :シングルテーカーのシングルタスク蒸留は、基本的な蒸留戦略を提供します。GeneralDistiller (推奨):シングルテーカーのシングルタスク蒸留は、中間機能のマッチングをサポートします。ほとんどの場合お勧めします。MultiTeacherDistiller :複数の教師モデル(同じタスクの)を単一の学生モデルに蒸留するマルチティーチャーの蒸留。このクラスは、中間機能のマッチングをサポートしていません。MultiTaskDistiller :マルチタスク蒸留。これにより、複数の教師モデル(異なるタスクの)が1人の生徒に蒸留されます。BasicTrainer :蒸留用ではなく、ラベル付きデータセット上の単一モデルを監視したトレーニング。教師モデルのトレーニングに使用できます。TextBrewerには、ユーザーが実装する必要がある2つの関数があります。コールバックとアダプターです。
各チェックポイントで、学生モデルを保存した後、コールバック関数は蒸留器によって呼び出されます。コールバックを使用して、各チェックポイントでの学生モデルのパフォーマンスを評価できます。
モデル入力と出力を指定された形式に変換して、蒸留器によって認識されるようになり、蒸留損失を計算できます。各トレーニングステップで、バッチとモデルの出力がアダプターに渡されます。アダプターはデータを再編成し、辞書を返します。
詳細については、完全なドキュメントの説明を参照してください。
Q :学生モデルを初期化する方法は?
A :学生モデルは、ランダムに初期化され(つまり、事前知識なし)、事前に訓練された重みで初期化することができます。たとえば、Bertベースモデルを3層Bertに蒸留する場合、Cold Startの問題を回避するために、RBT3(中国のタスクの場合)またはBertの最初の3層(英語のタスク)で学生モデルを初期化することができます。可能な限り、ユーザーは事前に訓練された学生モデルを使用して、大規模な事前トレーニングを完全に活用することをお勧めします。
Q :蒸留実験のためにトレーニングハイパーパラメーターを設定する方法
A :知識の蒸留には、通常、ラベル付きデータセットでのトレーニングよりも多くのトレーニングエポックとより大きな学習率が必要です。たとえば、Bert-Baseでのトレーニング分隊は通常、LR = 3E-5で3つのエポックを取ります。ただし、蒸留にはLR = 1E-4で30〜50個の時代が必要です。結論は私たちの実験に基づいており、あなたはあなた自身のデータを試すことをお勧めします。
Q :私の教師モデルと学生モデルは、さまざまな入力(語彙を共有していません)を取ります。どうすれば蒸留できますか?
A :教師と生徒にさまざまなバッチを供給する必要があります。セクションが生徒と教師にさまざまなバッチを送り、完全なドキュメントでキャッシュされた値を供給します。
Q :教師モデルからロジットを保存しました。蒸留でそれらを使用して、前方のパス時間を節約できますか?
A :はい、セクションが生徒と教師にさまざまなバッチを供給し、完全なドキュメントでキャッシュされた値を供給します。
DataParallelを通じてのみ利用できます。TextBrewerが役立つ場合は、私たちの論文を引用してください。
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}公式のWeChatアカウントをフォローして、最新のテクノロジーを最新の状態に保ちます!



