TextBrewer
TextBrewer 0.2.1
Englisch |中文说明

TextBrewer ist ein Pytorch-basierter Modelldestillations-Toolkit für die Verarbeitung natürlicher Sprache. Es enthält verschiedene Destillationstechniken sowohl aus dem NLP- als auch aus dem Lebenslauffeld und bietet ein benutzerfreundliches Destillations-Framework, mit dem Benutzer schnell mit den hochmodernen Destillationsmethoden experimentieren können, um das Modell mit einem relativ kleinen Opfer in der Leistung zu komprimieren und die Inferenzgeschwindigkeit zu reduzieren und die Speicherverwendung zu reduzieren.
Überprüfen Sie unser Papier über ACL-Anthologie oder Arxiv-Vorabdruck.
Vollständige Dokumentation
17. Dezember 2021
24. Oktober 2021
8. Juli 2021
1. März 2021
Bert-EMD und benutzerdefinierte Brenner
Aktualisiertes MNLI -Beispiel
11. November 2020
Aktualisiert auf 0.2.1 :
Flexiblere Destillation : Unterstützt das Füttern verschiedener Chargen an Schüler und Lehrer. Dies bedeutet, dass die Chargen für Schüler und Lehrer nicht mehr gleich sein müssen. Es kann zum Destillieren von Modellen mit unterschiedlichen Vokabeln verwendet werden (z. B. von Roberta bis Bert).
Schnellere Destillation : Benutzer können jetzt die Lehrerausgaben voraberhalten und zwischenspeichern und dann den Cache in den Destiller füttern, um die Vorwärtspasszeit des Lehrers zu speichern.
Weitere Informationen zu den oben genannten Merkmalen finden Sie unter Aussagen verschiedener Chargen an Schüler und Lehrer.
MultiTaskDistiller unterstützt jetzt den Intermediate -Feature -Matching -Verlust.
Tensorboard zeichnet jetzt detailliertere Verluste auf (KD -Verlust, Hard -Label -Verlust, übereinstimmende Verluste ...).
Siehe Details in Veröffentlichungen.
27. August 2020
Wir freuen uns, Ihnen mitteilen zu können, dass unser Modell über den Leim -Benchmark und die Check -Rangliste steht.
24. August 2020
MultiTaskDistiller und Trainingsschleifen behoben.29. Juli 2020
DistributedDataParallel : TrainingConfig ist jetzt das Argument local_rank genau aufmerksam. Details finden Sie in der Dokumentation von TrainingConfig .14. Juli 2020
fp16 in TrainingConfig auf True ein. Details finden Sie in der Dokumentation von TrainingConfig .data_parallel in TrainingConfig hinzugefügt, um Daten parallele Schulungen und gemischte Präzisionstrainings zusammen zu aktivieren.26. April 2020
22. April 2020
17. März 2020
11. März 2020
2. März 2020
| Abschnitt | Inhalt |
|---|---|
| Einführung | Einführung in Textbrewer |
| Installation | So installieren |
| Workflow | Zwei Phasen des Textbrewer -Workflows |
| QuickStart | Beispiel: Bert-Base zu einer 3-Schicht-Bert destillieren |
| Experimente | Destillationsexperimente an typischen englischen und chinesischen Datensätzen |
| Kernkonzepte | Kurze Erklärungen der Kernkonzepte in Textbrewer |
| FAQ | Häufig gestellte Fragen |
| Bekannte Probleme | Bekannte Probleme |
| Zitat | Zitat zu Textbrewer |
| Folgen Sie uns | - - |
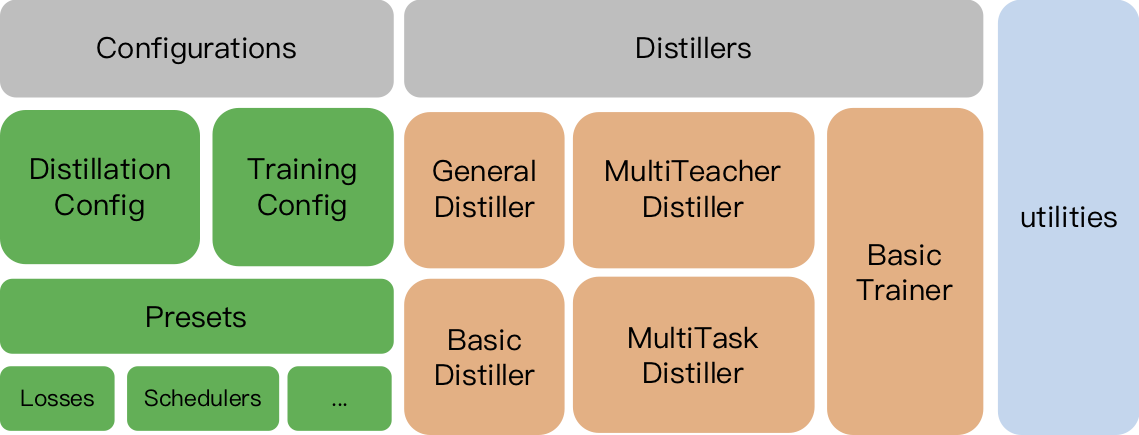
Textbrewer ist für die Wissensdestillation von NLP -Modellen ausgelegt. Es bietet verschiedene Destillationsmethoden und bietet ein Destillationsrahmen für die schnelle Einrichtung von Experimenten.
Die Hauptmerkmale von Textbrewer sind:
Textbrewer wird derzeit mit den folgenden Destillationstechniken versendet:
Textbrewer enthält:
Um die Destillation zu beginnen, müssen Benutzer bereitstellen
Textbrewer hat bei mehreren typischen NLP -Aufgaben beeindruckende Ergebnisse erzielt. Siehe Experimente.
In der vollständigen Dokumentation finden Sie detaillierte Verwendungen.
Anforderungen
Installieren Sie von PYPI
pip install textbrewerInstallieren Sie aus der Github -Quelle
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer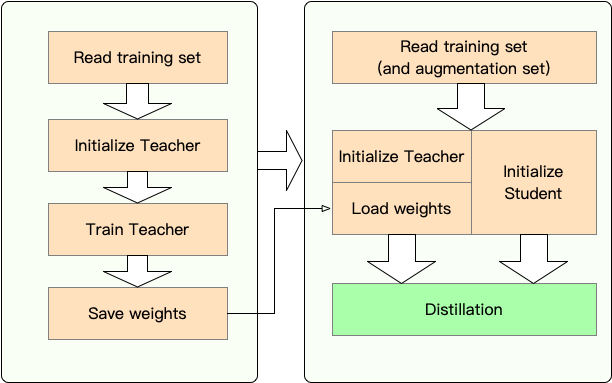
Stufe 1 : Vorbereitung:
Stufe 2 : Destillation mit Textbrewer:
Hier zeigen wir die Verwendung von Textbrewer, indem wir Bert-Base zu einem 3-Schicht-Bert destillieren.
Vor der Destillation gehen wir davon aus, dass Benutzer bereitgestellt haben:
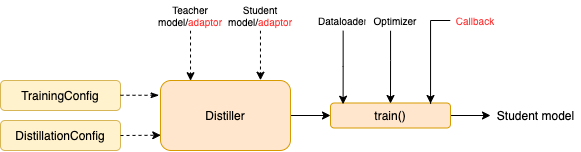
teacher_model (Bert-Base) und ein zu-BE-ausgebildeter Schülermodell student_model (3-Layer-Bert).dataloader des Datensatzes, ein optimizer und ein Lernrate -Bauunternehmer oder scheduler_class und seine Argumente dict scheduler_dict .Destilly mit Textbrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )Notizbuchbeispiele mit Transformers 4
Beispiele/random_token_example: Ein einfaches Spielspielzeugbeispiel, das die Verwendung von Textbrewer demonstriert. Dieses Beispiel führt eine Destillation in der Textklassifizierungsaufgabe mit zufälligen Token als Eingaben durch.
Beispiele/CMRC2018_example (Chinese): Destillation auf CMRC 2018, eine chinesische MRC -Aufgabe, die DRCD als Datenerweiterung verwendet.
Beispiele/mnli_example (englisch): Destillation auf MNLI, eine englische Klassifizierungsaufgabe für Satzpaare. Dieses Beispiel zeigt auch, wie die Destillation mit mehreren Lehrern durchführt.
Beispiele/conll2003_example (englisch): Destillation auf Conll-2003 English Ner-Aufgabe, die in Form der Sequenzmarkierung steht.
Beispiele/msra_ner_example (chinesische): Dieses Beispiel destilliert ein chinesisch-elektrafase-Modell für die MSRA-NER-Aufgabe mit verteiltem datenparallelem Training (Einzelknoten, Multi-GPU).
Wir haben Destillationsexperimente an mehreren typischen englischen und chinesischen NLP -Datensätzen durchgeführt. Die Setups und Konfigurationen sind unten aufgeführt.
Wir haben verschiedene Studentenmodelle getestet. Um mit den öffentlichen Ergebnissen zu vergleichen, werden die Studentenmodelle mit Standard-Transformatorblöcken mit Ausnahme von Bigru gebaut, einem bidirektionalen Gru mit einer Schicht. Die Architekturen sind unten aufgeführt. Beachten Sie, dass die Anzahl der Parameter die Einbettungsschicht enthält, jedoch nicht die Ausgangsschicht jeder spezifischen Aufgabe enthält.
| Modell | #Layer | Versteckte Größe | Futtermittelgröße | #Params | Relative Größe |
|---|---|---|---|---|---|
| Bert-Base-Cased (Lehrer) | 12 | 768 | 3072 | 108 m | 100% |
| T6 (Student) | 6 | 768 | 3072 | 65 m | 60% |
| T3 (Student) | 3 | 768 | 3072 | 44 m | 41% |
| T3-Small (Student) | 3 | 384 | 1536 | 17m | 16% |
| T4-Tiny (Student) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano (Student) | 12 | 256 | 1024 | 17m | 16% |
| Bigru (Student) | - - | 768 | - - | 31m | 29% |
| Modell | #Layer | Versteckte Größe | Futtermittelgröße | #Params | Relative Größe |
|---|---|---|---|---|---|
| Roberta-wwm-text (Lehrer) | 12 | 768 | 3072 | 102 m | 100% |
| Elektrik-Basis (Lehrer) | 12 | 768 | 3072 | 102 m | 100% |
| T3 (Student) | 3 | 768 | 3072 | 38m | 37% |
| T3-Small (Student) | 3 | 384 | 1536 | 14m | 14% |
| T4-Tiny (Student) | 4 | 312 | 1200 | 11m | 11% |
| Electra-Small (Student) | 12 | 256 | 1024 | 12 m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches sind für verschiedene Modelle unterschieden:
| Modell | Übereinstimmungen |
|---|---|
| Bigru | Keiner |
| T6 | L6_hidden_mse + l6_hidden_smmd |
| T3 | L3_hidden_mse + l3_hidden_smmd |
| T3-Small | L3n_hidden_mse + l3_hidden_smmd |
| T4-tiny | L4t_hidden_mse + l4_hidden_smmd |
| T12-Nano | small_hidden_mse + small_hidden_smmd |
| Electra-Small | small_hidden_mse + small_hidden_smmd |
Die Definitionen von Übereinstimmungen erfolgen bei Beispielen/Übereinstimmungen/Übereinstimmungen.py.
Wir verwenden Generaldistiller in allen Destillationsexperimenten.
Wir experimentieren mit den folgenden typischen englischen Datensätzen:
| Datensatz | Aufgabentyp | Metriken | #Zug | #Dev | Notiz |
|---|---|---|---|---|---|
| Mnli | Textklassifizierung | m/mm ACC | 393K | 20k | Satzpaar 3-Klasse-Klassifizierung |
| Kader 1.1 | Leseverständnis | EM/F1 | 88k | 11k | Span-Extraction Machine Leseverständnis |
| Conll-2003 | Sequenzmarkierung | F1 | 23k | 6k | genannte Entitätserkennung |
Wir listen die öffentlichen Ergebnisse von Distilbert, Bert-PKD, Bert-of-theseus, Tinybert und unseren Ergebnissen zum Vergleich.
Öffentliche Ergebnisse:
| Modell (öffentlich) | Mnli | Kader | Conll-2003 |
|---|---|---|---|
| Distilbert (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - - |
| Bert 6 -pkd (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - - |
| Bert-of-theseus (T6) | 82.4/ 82.1 | - - | - - |
| Bert 3 -pkd (T3) | 76,7 / 76.3 | - - | - - |
| Tinybert (T4-Tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - - |
Unsere Ergebnisse:
| Modell (unser) | Mnli | Kader | Conll-2003 |
|---|---|---|---|
| Bert-Base-Cased (Lehrer) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - - | - - | 85.3 |
| T6 | 83,5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76,4 / 84.9 | 87,5 |
| T3-Small | 81.3 / 81.7 | 72.3 / 81.4 | 78,6 |
| T4-tiny | 82.0 / 82.6 | 75,2 / 84.0 | 89.1 |
| T12-Nano | 83.2 / 83.9 | 79.0 / 86.6 | 89,6 |
Notiz :
Wir experimentieren mit den folgenden typischen chinesischen Datensätzen:
| Datensatz | Aufgabentyp | Metriken | #Zug | #Dev | Notiz |
|---|---|---|---|---|---|
| Xnli | Textklassifizierung | Acc | 393K | 2,5K | Chinesische Übersetzungsversion von MNLI |
| LCQMC | Textklassifizierung | Acc | 239K | 8,8K | Satzpaar Matching, binäre Klassifizierung |
| CMRC 2018 | Leseverständnis | EM/F1 | 10k | 3.4k | Span-Extraction Machine Leseverständnis |
| DRCD | Leseverständnis | EM/F1 | 27k | 3,5K | Span-Extraction Machine Leseverständnis (traditionelles Chinesisch) |
| MSRA NER | Sequenzmarkierung | F1 | 45k | 3.4k (#Test) | Chinesisch genannte Entitätserkennung |
Die Ergebnisse sind unten aufgeführt.
| Modell | Xnli | LCQMC | CMRC 2018 | DRCD |
|---|---|---|---|---|
| Roberta-wwm-text (Lehrer) | 79,9 | 89,4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78,4 | 89.0 | 66,4 / 84.2 | 78,2 / 86.4 |
| T3-Small | 76.0 | 88.1 | 58.0 / 79.3 | 75,8 / 84.8 |
| T4-tiny | 76,2 | 88,4 | 61.8 / 81.8 | 77.3 / 86.1 |
| Modell | Xnli | LCQMC | CMRC 2018 | DRCD | MSRA NER |
|---|---|---|---|---|---|
| Electra-Base (Lehrer)) | 77,8 | 89,8 | 65,6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electra-Small | 77,7 | 89.3 | 66,5 / 84.9 | 85,5 / 91.3 | 93.48 |
Notiz :
TrainingConfig : Konfiguration im Zusammenhang mit dem allgemeinen Deep -Learning -ModelltrainingDistillationConfig : Konfiguration im Zusammenhang mit DestillationsmethodenBrenner sind für die Durchführung der tatsächlichen Experimente verantwortlich. Die folgenden Brenner sind verfügbar:
BasicDistiller : Single-Tacher-Single- Destillation, liefert grundlegende Destillationsstrategien.GeneralDistiller (empfohlen): Ein-Task-Destillation mit einer Einführung von Einzelbechern unterstützt die Übereinstimmung mit Zwischenmerkmalen. Empfohlen die meiste Zeit .MultiTeacherDistiller : Multitacher- Destillation, die mehrere Lehrermodelle (derselben Aufgabe) in ein einzelnes Schülermodell verwandelt. Diese Klasse unterstützt keine Zwischenfunktionen, die die Übereinstimmung mit den Übereinstimmungen unterstützen.MultiTaskDistiller : Multi-Task -Destillation, die mehrere Lehrermodelle (unterschiedlicher Aufgaben) in einen einzelnen Schüler verwandelt.BasicTrainer : Übersichtliches Training Ein einzelnes Modell auf einem beschrifteten Datensatz, nicht für die Destillation. Es kann verwendet werden, um ein Lehrermodell auszubilden .In Textbrewer gibt es zwei Funktionen, die von Benutzern implementiert werden sollten: Rückruf und Adapter .
An jedem Checkpoint wird nach dem Speichern des Studentenmodells die Rückruffunktion vom Distiller aufgerufen. Ein Rückruf kann verwendet werden, um die Leistung des Schülermodells an jedem Kontrollpunkt zu bewerten.
Es konvertiert die Modelleingänge und -ausgänge in das angegebene Format, sodass sie durch den Destiller erkannt werden können, und die Destillationsverluste können berechnet werden. Bei jedem Trainingsschritt werden Batch- und Modellausgaben an den Adapter übergeben. Der Adapter organisiert die Daten neu und gibt ein Wörterbuch zurück.
Weitere Informationen finden Sie in den Erklärungen in vollständiger Dokumentation.
F : Wie kann man das Schülermodell initialisieren?
A : Das Schülermodell kann zufällig initialisiert werden (dh ohne Vorkenntnisse) oder durch vorgebliebene Gewichte initialisiert werden. Wenn Sie beispielsweise ein Bert-Base-Modell in einen 3-Schicht-Bert destillieren, können Sie das Schülermodell mit RBT3 (für chinesische Aufgaben) oder den ersten drei Schichten von Bert (für englische Aufgaben) initialisieren, um kaltes Startproblem zu vermeiden. Wir empfehlen, dass Benutzer vorhandene Schülermodelle verwenden, um die groß angelegte Vorausbildung vollständig zu nutzen.
F : So setzen Sie Trainingshyperparameter für die Destillationsexperimente?
A : Wissensdestillation erfordert in der Regel mehr Trainings -Epochen und größere Lernrate als das Training auf dem beschrifteten Datensatz. Zum Beispiel benötigt die Trainingsqualcher auf Bert-Base normalerweise 3 Epochen mit LR = 3E-5; Die Destillation erfordert jedoch 30 ~ 50 Epochen mit LR = 1E-4. Die Schlussfolgerungen basieren auf unseren Experimenten, und es wird Ihnen empfohlen, Ihre eigenen Daten auszuprobieren .
F : Mein Lehrermodell und ein Schülermodell nehmen unterschiedliche Eingaben (sie teilen keine Vokabularien). Wie kann ich also destillieren?
A : Sie müssen dem Lehrer und dem Schüler verschiedene Chargen füttern. Siehe Abschnitt Füttere unterschiedliche Chargen an Schüler und Lehrer und füttere zwischengespeicherte Werte in der vollständigen Dokumentation.
F : Ich habe die Logits von meinem Lehrermodell gespeichert. Kann ich sie in der Destillation verwenden, um die Vorwärts -Pass -Zeit zu speichern?
A : Ja, siehe Abschnitt Füttere verschiedene Chargen an Schüler und Lehrer und füttere zwischengespeicherte Werte in der vollständigen Dokumentation.
DataParallel verfügbar.Wenn Sie feststellen, dass Textbrewer hilfreich ist, zitieren Sie bitte unser Papier:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}Folgen Sie unserem offiziellen WeChat -Konto, um über unsere neuesten Technologien auf dem Laufenden zu bleiben!



