TextBrewer
TextBrewer 0.2.1
英语|中文说明

TextBrewer是一种基于Pytorch的模型蒸馏工具包,用于自然语言处理。它包括来自NLP和CV领域的各种蒸馏技术,并提供了易于使用的蒸馏框架,该框架使用户可以快速尝试使用最新的蒸馏方法来以相对较小的性能牺牲,从而增加推理速度和减少记忆使用情况。
通过ACL选集或ARXIV预印刷检查我们的论文。
完整的文档
2021年12月17日
2021年10月24日
7月8日,2021年
2021年3月1日
Bert-Emd和自定义蒸馏器
更新的MNLI示例
2020年11月11日
更新为0.2.1 :
更灵活的蒸馏:支持向学生和老师喂食不同的批次。这意味着学生和老师的批次不再需要相同。它可用于具有不同词汇的蒸馏模型(例如,从罗伯塔到伯特)。
更快的蒸馏速度:用户现在可以预先计算和缓存老师的输出,然后将缓存馈送到蒸馏器中,以节省老师的前进时间。
有关上述功能的详细信息,请参阅学生和老师的不同批次,供给缓存的值。
MultiTaskDistiller现在支持中间功能匹配损失。
张板现在记录了更详细的损失(KD损失,硬标签损失,匹配损失...)。
请参阅发行中的详细信息。
2020年8月27日
我们很高兴地宣布,我们的模型位于胶水基准的顶部,Check Legardboard。
2020年8月24日
MultiTaskDistiller和培训循环中的错误。7月29日,2020年
DistributedDataParallel : TrainingConfig现在正调光local_rank参数。有关详细信息,请参见TrainingConfig的文档。2020年7月14日
fp16设置为True TrainingConfig 。有关详细信息,请参见TrainingConfig的文档。TrainingConfig中添加了data_parallel选项,以启用数据并行培训和混合精度培训一起工作。2020年4月26日
2020年4月22日
2020年3月17日
2020年3月11日
2020年3月2日
| 部分 | 内容 |
|---|---|
| 介绍 | 简介Textbrewer |
| 安装 | 如何安装 |
| 工作流程 | Textbrewer工作流的两个阶段 |
| Quickstart | 示例:将bert碱蒸馏到3层伯特 |
| 实验 | 典型英语和中文数据集的蒸馏实验 |
| 核心概念 | 简要说明Textbrewer中的核心概念 |
| 常问问题 | 常见问题 |
| 已知问题 | 已知问题 |
| 引用 | 引用Textbrewer |
| 跟着我们 | - |
TextBrewer专为NLP模型的知识蒸馏而设计。它提供了各种蒸馏方法,并提供了一个快速设置实验的蒸馏框架。
Textbrewer的主要特征是:
Textbrewer目前已采用以下蒸馏技术:
Textbrewer包括:
要开始蒸馏,用户需要提供
Textbrewer在几个典型的NLP任务上取得了令人印象深刻的结果。参见实验。
有关详细用法,请参见完整的文档。
要求
从PYPI安装
pip install textbrewer从GitHub源安装
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer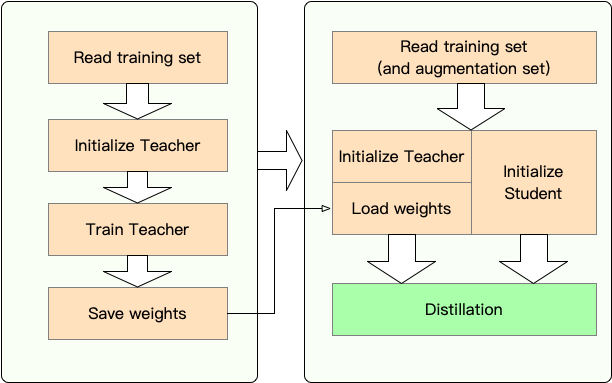
阶段1 :准备:
第2阶段:与Textbrewer蒸馏:
在这里,我们通过将Bert-Base蒸馏到3层Bert来显示Textbrewer的用法。
在蒸馏之前,我们假设用户提供了:
teacher_model (Bert-base)和接受训练的学生模型student_model (3层BERT)。optimizer和学习率构建器或类scheduler_class及其ARGS dict dict scheduler_dict的dataloader 。与Textbrewer提炼:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )带有变压器4的笔记本示例4
示例/Random_token_example:一个简单的可运行玩具示例,演示了TextBrewer的用法。此示例将随机令牌作为输入对文本分类任务进行蒸馏。
示例/cmrc2018_example(中文):使用DRCD作为数据增强的中文MRC任务进行CMRC 2018蒸馏。
示例/mnli_example(英语):MNLI上的蒸馏,英语句子对任务。此示例还显示了如何执行多教师蒸馏。
示例/conll2003_example(英语):Conll-2003英语NER任务上的蒸馏,该任务的形式为序列标签。
示例/MSRA_NER_EXAMPE(中文):此示例通过分布式数据并行训练(单节点,多GPU)在MSRA NER任务上提取中文 - 电子基础模型。
我们已经对几个典型的英语和中文NLP数据集进行了蒸馏实验。设置和配置在下面列出。
我们已经测试了不同的学生模型。为了与公共结果进行比较,学生模型是由标准变压器块构建的,除了Bigru是单层双向GRU。体系结构在下面列出。请注意,参数的数量包括嵌入层,但不包括每个特定任务的输出层。
| 模型 | #layers | 隐藏尺寸 | 进料尺寸 | #params | 相对大小 |
|---|---|---|---|---|---|
| 伯特 - 基准(老师) | 12 | 768 | 3072 | 108m | 100% |
| T6(学生) | 6 | 768 | 3072 | 65m | 60% |
| T3(学生) | 3 | 768 | 3072 | 44m | 41% |
| T3-small(学生) | 3 | 384 | 1536年 | 17m | 16% |
| T4微小(学生) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano(学生) | 12 | 256 | 1024 | 17m | 16% |
| Bigru(学生) | - | 768 | - | 31m | 29% |
| 模型 | #layers | 隐藏尺寸 | 进料尺寸 | #params | 相对大小 |
|---|---|---|---|---|---|
| Roberta-wwm-ext(老师) | 12 | 768 | 3072 | 102m | 100% |
| 伊莱克斯基(老师) | 12 | 768 | 3072 | 102m | 100% |
| T3(学生) | 3 | 768 | 3072 | 38m | 37% |
| T3-small(学生) | 3 | 384 | 1536年 | 14m | 14% |
| T4微小(学生) | 4 | 312 | 1200 | 11m | 11% |
| electra-small(学生) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values不同模型的matches不同:
| 模型 | 比赛 |
|---|---|
| Bigru | 没有任何 |
| T6 | L6_HIDDER_MSE + L6_HIDDER_SMMD |
| T3 | L3_HIDDER_MSE + L3_HIDDER_SMMD |
| T3-small | L3N_HIDDER_MSE + L3_HIDDER_SMMD |
| T4小型 | L4T_HIDDER_MSE + L4_HIDDER_SMMD |
| T12-nano | small_hidden_mse + small_hidden_smmd |
| Electra-small | small_hidden_mse + small_hidden_smmd |
比赛的定义是在示例/匹配/匹配中。
我们在所有蒸馏实验中使用GeneralDistiller。
我们在以下典型的英语数据集上进行实验:
| 数据集 | 任务类型 | 指标 | #火车 | #dev | 笔记 |
|---|---|---|---|---|---|
| mnli | 文本分类 | m/mm acc | 393K | 20k | 句子对3类分类 |
| 小队1.1 | 阅读理解 | EM/F1 | 88K | 11k | 跨摘除机读取理解 |
| Conll-2003 | 序列标记 | F1 | 23k | 6k | 命名实体识别 |
我们列出了Distilbert,Bert-PKD,Bert-of Theseus,Tinybert的公共结果以及下面的结果以进行比较。
公众结果:
| 模型(公共) | mnli | 队 | Conll-2003 |
|---|---|---|---|
| Distilbert(T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| BERT 6 -PKD(T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| 这些伯(T6) | 82.4/ 82.1 | - | - |
| Bert 3 -pkd(T3) | 76.7 / 76.3 | - | - |
| Tinybert(T4微小) | 82.8 / 82.9 | 72.7 / 82.1 | - |
我们的结果:
| 模型(我们的) | mnli | 队 | Conll-2003 |
|---|---|---|---|
| 伯特 - 基准(老师) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4小型 | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
笔记:
我们在以下典型的中文数据集上进行实验:
| 数据集 | 任务类型 | 指标 | #火车 | #dev | 笔记 |
|---|---|---|---|---|---|
| xnli | 文本分类 | ACC | 393K | 2.5k | 中文翻译版本的mnli |
| LCQMC | 文本分类 | ACC | 239k | 8.8k | 句子对匹配,二进制分类 |
| CMRC 2018 | 阅读理解 | EM/F1 | 10k | 3.4k | 跨摘除机读取理解 |
| drcd | 阅读理解 | EM/F1 | 27k | 3.5k | 跨度挖掘机阅读理解(传统中文) |
| MSRA NER | 序列标记 | F1 | 45k | 3.4k(#test) | 中文命名实体认可 |
结果如下列出。
| 模型 | xnli | LCQMC | CMRC 2018 | drcd |
|---|---|---|---|---|
| Roberta-wwm-ext (老师) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4小型 | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| 模型 | xnli | LCQMC | CMRC 2018 | drcd | MSRA NER |
|---|---|---|---|---|---|
| 伊莱克斯(老师)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electra-small | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
笔记:
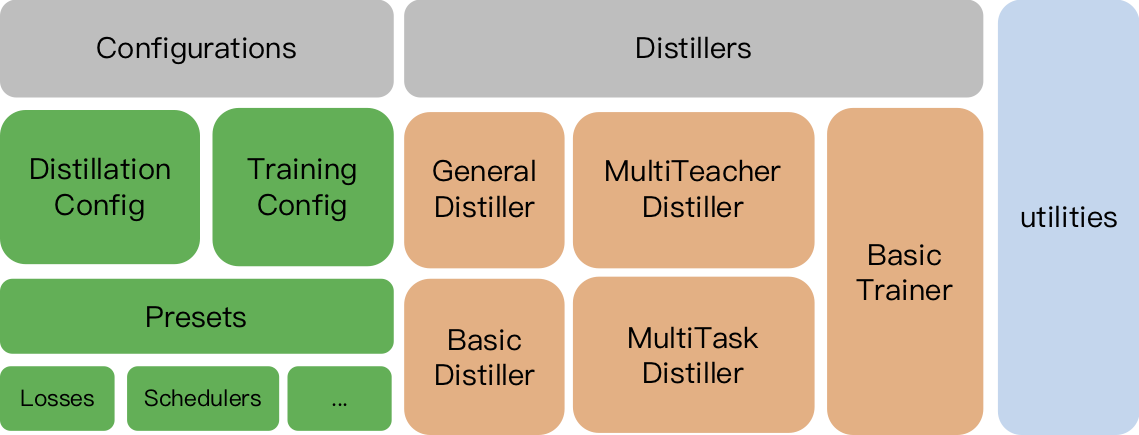
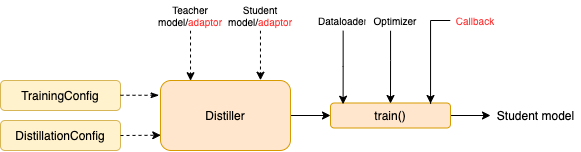
TrainingConfig :与一般深度学习模型培训有关的配置DistillationConfig :与蒸馏方法有关的配置酿酒师负责进行实际的实验。可用以下酿酒厂:
BasicDistiller :单师单任务蒸馏,提供了基本的蒸馏策略。GeneralDistiller (推荐):单师单任务蒸馏,支持中间功能匹配。大多数时候推荐。MultiTeacherDistiller :多教师蒸馏器,将多个教师模型(同一任务)提炼成单个学生模型。该类不支持中间功能匹配。MultiTaskDistiller :多任务蒸馏,将多个教师模型(不同任务)提炼成一个学生。BasicTrainer :监督培训标记数据集上的单个模型,而不是用于蒸馏。它可用于培训教师模型。在TextBrewer中,用户应该实现两个功能:回调和适配器。
在每个检查点,保存学生模型后,蒸馏器将调用回调功能。可以使用回调来评估每个检查点学生模型的性能。
它将模型输入和输出转换为指定的格式,以便可以通过蒸馏器识别它们,并可以计算蒸馏损失。在每个训练步骤中,批处理和模型输出将传递给适配器;适配器重组数据并返回字典。
有关更多详细信息,请参阅完整文档中的说明。
问:如何初始化学生模型?
答:学生模型可以随机初始化(即没有先验知识),也可以通过预先训练的权重初始化。例如,当将BERT基本模型提炼为3层BERT时,您可以使用RBT3(用于中文任务)或前三层BERT(对于英语任务)初始化学生模型来避免冷启动问题。我们建议用户尽可能使用预训练的学生模型来充分利用大规模的预培训。
问:如何为蒸馏实验设置训练超参数?
答:知识蒸馏通常需要比标记的数据集上的培训更多的培训时期和更高的学习率。例如,BERT碱基上的训练小队通常需要3个时代,而LR = 3E-5。但是,蒸馏需要30〜50个时期,而LR = 1E-4。结论是基于我们的实验,建议您尝试自己的数据。
问:我的老师模型和学生模型采用不同的输入(它们不共享词汇),那么我该如何提炼?
答:您需要向老师和学生提供不同的批次。请参阅该部分为学生和老师提供不同的批次,并在完整文档中为缓存的值提供。
问:我已经存储了老师模型的逻辑。我可以在蒸馏中使用它们来节省前进时间吗?
答:是的,请参阅本部分向学生和老师提供不同的批次,在完整文档中为缓存的值提供。
DataParallel提供。如果您发现Textbrewer很有帮助,请引用我们的论文:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}请按照我们的官方微信帐户进行最新技术!



