TextBrewer
TextBrewer 0.2.1
ภาษาอังกฤษ |中文说明

TextBrewer เป็นชุดเครื่องมือกลั่นแบบจำลอง Pytorch สำหรับการประมวลผลภาษาธรรมชาติ มันรวมถึงเทคนิคการกลั่นต่าง ๆ จากทั้ง NLP และ CV Field และให้กรอบการกลั่นที่ใช้งานง่ายซึ่งช่วยให้ผู้ใช้สามารถทดลองใช้วิธีการกลั่นที่ทันสมัยอย่างรวดเร็วเพื่อบีบอัดแบบจำลองด้วยการเสียสละที่ค่อนข้างเล็กในประสิทธิภาพเพิ่มความเร็วการอนุมานและลดการใช้หน่วยความจำ
ตรวจสอบกระดาษของเราผ่านกวีนิพนธ์ ACL หรือการพิมพ์ล่วงหน้า arxiv
เอกสารฉบับเต็ม
17 ธ.ค. 2021
24 ต.ค. 2564
8 ก.ค. 2021
1 มี.ค. 2021
bert-emd และ distiller ที่กำหนดเอง
อัปเดตตัวอย่าง MNLI
11 พ.ย. 2020
อัปเดตเป็น 0.2.1 :
การกลั่นที่ยืดหยุ่นมากขึ้น : สนับสนุนการให้อาหารแบทช์ที่แตกต่างกันให้กับนักเรียนและครู มันหมายถึงแบทช์สำหรับนักเรียนและครูไม่จำเป็นต้องเหมือนกันอีกต่อไป มันสามารถใช้สำหรับการกลั่นโมเดลที่มีคำศัพท์ที่แตกต่างกัน (เช่นจาก Roberta ถึง Bert)
การกลั่นเร็วขึ้น : ตอนนี้ผู้ใช้สามารถคำนวณล่วงหน้าและแคชเอาต์พุตของครูจากนั้นป้อนแคชให้กับผู้กลั่นเพื่อประหยัดเวลาผ่านไปข้างหน้าของครู
ดูการป้อนชุดที่แตกต่างกันให้กับนักเรียนและครูให้ค่าแคชสำหรับรายละเอียดของคุณสมบัติข้างต้น
ตอนนี้ MultiTaskDistiller รองรับการสูญเสียการจับคู่คุณลักษณะระดับกลาง
ตอนนี้ Tensorboard บันทึกการสูญเสียอย่างละเอียดมากขึ้น (การสูญเสีย KD, การสูญเสียฉลากอย่างหนัก, การสูญเสียการจับคู่ ... )
ดูรายละเอียดในรุ่น
27 สิงหาคม 2563
เรามีความยินดีที่จะประกาศว่าแบบจำลองของเราอยู่บนเกณฑ์มาตรฐานกาวตรวจสอบลีดเดอร์บอร์ด
24 ส.ค. 2020
MultiTaskDistiller และลูปการฝึกอบรม29 ก.ค. 2020
DistributedDataParallel : TrainingConfig ตอนนี้จะมีการโต้แย้ง local_rank ดูเอกสารประกอบของ TrainingConfig เพื่อดูรายละเอียด14 ก.ค. 2020
fp16 เป็น True ใน TrainingConfig ดูเอกสารประกอบของ TrainingConfig เพื่อดูรายละเอียดdata_parallel ใน TrainingConfig เพื่อเปิดใช้งานการฝึกอบรมแบบขนานข้อมูลและการฝึกอบรมที่แม่นยำแบบผสมทำงานร่วมกัน26 เม.ย. 2020
22 เม.ย. 2020
17 มี.ค. 2020
11 มี.ค. 2020
2 มี.ค. 2020
| ส่วน | สารบัญ |
|---|---|
| การแนะนำ | บทนำสู่ TextBrewer |
| การติดตั้ง | วิธีการติดตั้ง |
| เวิร์กโฟลว์ | เวิร์กโฟลว์ TextBrewer สองขั้นตอน |
| เร็ว | ตัวอย่าง: การกลั่นเบิร์ตเบสไปยังเบิร์ต 3 ชั้น |
| การทดลอง | การทดลองกลั่นเกี่ยวกับชุดข้อมูลภาษาอังกฤษและภาษาจีนทั่วไป |
| แนวคิดหลัก | คำอธิบายสั้น ๆ เกี่ยวกับแนวคิดหลักใน TextBrewer |
| คำถามที่พบบ่อย | คำถามที่พบบ่อย |
| ปัญหาที่รู้จัก | ปัญหาที่รู้จัก |
| การอ้างอิง | การอ้างอิงถึง textbrewer |
| ติดตามเรา | - |
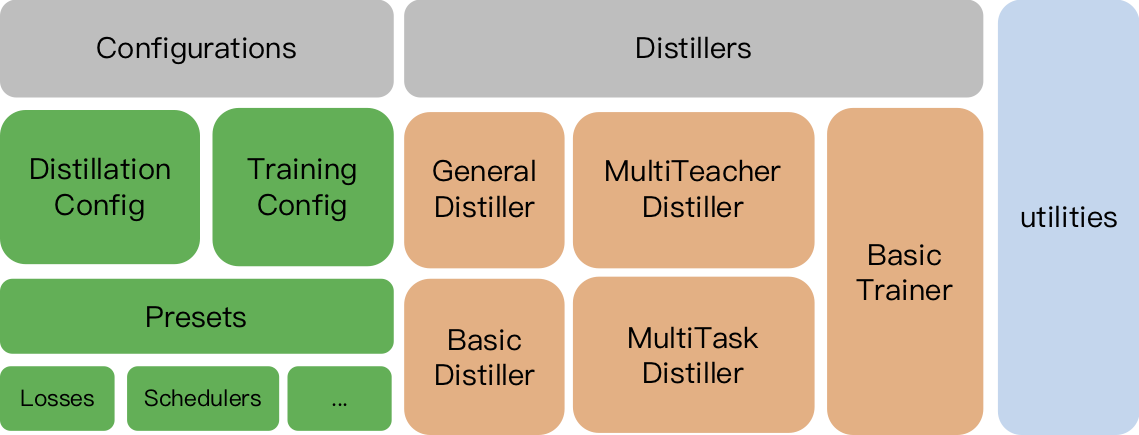
TextBrewer ได้รับการออกแบบมาสำหรับการกลั่นความรู้ของโมเดล NLP มันให้วิธีการกลั่นที่หลากหลายและเสนอกรอบการกลั่นสำหรับการตั้งค่าการทดลองอย่างรวดเร็ว
คุณสมบัติหลักของ textbrewer คือ:
ปัจจุบัน TextBrewer จัดส่งด้วยเทคนิคการกลั่นต่อไปนี้:
TextBrewer รวมถึง:
ในการเริ่มการกลั่นผู้ใช้จำเป็นต้องให้
TextBrewer ได้รับผลลัพธ์ที่น่าประทับใจในงาน NLP ทั่วไปหลายอย่าง ดูการทดลอง
ดูเอกสารฉบับเต็มสำหรับการใช้งานโดยละเอียด
ความต้องการ
ติดตั้งจาก PYPI
pip install textbrewerติดตั้งจากแหล่ง GitHub
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer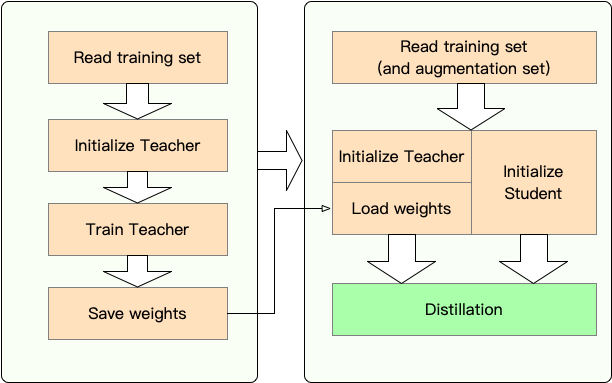
ขั้นตอนที่ 1 : การเตรียมการ:
ขั้นตอนที่ 2 : การกลั่นด้วย textbrewer:
ที่นี่เราแสดงการใช้งานของ Textbrewer โดยการกลั่นเบิร์ตฐานไปยังเบิร์ต 3 ชั้น
ก่อนการกลั่นเราถือว่าผู้ใช้ได้จัดเตรียมไว้:
teacher_model (bert-base) และนักเรียนที่ได้รับการฝึกฝนมาเป็นนักศึกษา student_model (3 ชั้นเบิร์ต)dataloader ของชุดข้อมูล optimizer และตัวสร้างอัตราการเรียนรู้หรือคลาส scheduler_class และ args dict scheduler_dictกลั่นด้วย textbrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )ตัวอย่างสมุดบันทึกด้วย Transformers 4
ตัวอย่าง/random_token_example: ตัวอย่างของเล่นที่วิ่งได้ง่ายซึ่งแสดงให้เห็นถึงการใช้งานของ TextBrewer ตัวอย่างนี้ทำการกลั่นในงานการจำแนกประเภทข้อความด้วยโทเค็นแบบสุ่มเป็นอินพุต
ตัวอย่าง/CMRC2018_EXAMPLE (จีน): การกลั่น CMRC 2018, งาน MRC จีนโดยใช้ DRCD เป็นการเพิ่มข้อมูล
ตัวอย่าง/mnli_example (ภาษาอังกฤษ): การกลั่นบน MNLI, งานจำแนกประเภทคู่ประโยคภาษาอังกฤษ ตัวอย่างนี้ยังแสดงวิธีการกลั่นหลายครู
ตัวอย่าง/conll2003_example (ภาษาอังกฤษ): การกลั่นจากงานภาษาอังกฤษ conll-2003 ซึ่งอยู่ในรูปของการติดฉลากลำดับ
ตัวอย่าง/msra_ner_example (ภาษาจีน): ตัวอย่างนี้กลั่นโมเดลเบสจีน-อิเล็กตร้าในงาน MSRA NER ด้วยการฝึกอบรมแบบขนานข้อมูลแบบกระจาย (โหนดเดี่ยว, Multi-GPU)
เราได้ทำการทดลองกลั่นในชุดข้อมูลภาษาอังกฤษและภาษาจีนทั่วไปหลายชุด การตั้งค่าและการกำหนดค่าแสดงอยู่ด้านล่าง
เราได้ทดสอบแบบจำลองนักเรียนที่แตกต่างกัน เพื่อเปรียบเทียบกับผลลัพธ์สาธารณะโมเดลนักเรียนจะถูกสร้างขึ้นด้วยบล็อกหม้อแปลงมาตรฐานยกเว้น Bigru ซึ่งเป็น GRU แบบสองชั้นเดียว สถาปัตยกรรมอยู่ด้านล่าง โปรดทราบว่าจำนวนพารามิเตอร์รวมถึงเลเยอร์การฝัง แต่ไม่รวมเลเยอร์เอาต์พุตของแต่ละงานเฉพาะ
| แบบอย่าง | #layers | ขนาดที่ซ่อน | ขนาดฟีดไปข้างหน้า | #params | ขนาดสัมพัทธ์ |
|---|---|---|---|---|---|
| เบิร์ต-เบส (ครู) | 12 | 768 | 3072 | 108m | 100% |
| T6 (นักเรียน) | 6 | 768 | 3072 | 65m | 60% |
| T3 (นักเรียน) | 3 | 768 | 3072 | 44m | 41% |
| T3-Small (นักเรียน) | 3 | 384 | ค.ศ. 1536 | 17m | 16% |
| T4-tiny (นักเรียน) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano (นักเรียน) | 12 | 256 | 1024 | 17m | 16% |
| Bigru (นักเรียน) | - | 768 | - | 31m | 29% |
| แบบอย่าง | #layers | ขนาดที่ซ่อน | ขนาดฟีดไปข้างหน้า | #params | ขนาดสัมพัทธ์ |
|---|---|---|---|---|---|
| Roberta-WWM-EXT (ครู) | 12 | 768 | 3072 | 102m | 100% |
| Electra-base (ครู) | 12 | 768 | 3072 | 102m | 100% |
| T3 (นักเรียน) | 3 | 768 | 3072 | 38m | 37% |
| T3-Small (นักเรียน) | 3 | 384 | ค.ศ. 1536 | 14m | 14% |
| T4-tiny (นักเรียน) | 4 | 312 | 1200 | 11m | 11% |
| Electra-Small (นักเรียน) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches แตกต่างกันสำหรับรุ่นที่แตกต่างกัน:
| แบบอย่าง | การจับคู่ |
|---|---|
| บิ๊กรู | ไม่มี |
| T6 | l6_hidden_mse + l6_hidden_smmd |
| T3 | l3_hidden_mse + l3_hidden_smmd |
| T3-small | L3N_HIVEND_MSE + L3_HIVEND_SMMD |
| T4-tiny | L4T_HIVEND_MSE + L4_HIVEND_SMMD |
| T12-Nano | small_hidden_mse + small_hidden_smmd |
| ควันเล็ก ๆ | small_hidden_mse + small_hidden_smmd |
คำจำกัดความของการจับคู่อยู่ที่ตัวอย่าง/matches/matches.py
เราใช้ GeneralDistiller ในการทดลองการกลั่นทั้งหมด
เราทดลองเกี่ยวกับชุดข้อมูลภาษาอังกฤษทั่วไปต่อไปนี้:
| ชุดข้อมูล | ประเภทงาน | ตัวชี้วัด | #รถไฟ | #DEV | บันทึก |
|---|---|---|---|---|---|
| mnli | การจำแนกข้อความ | m/mm acc | 393K | 20k | การจำแนกประเภท 3 คลาสคู่ |
| ทีม 1.1 | การอ่านความเข้าใจ | EM/F1 | 88K | 11K | ความเข้าใจในการอ่านเครื่องสกัด |
| Conll-2003 | การติดฉลากลำดับ | F1 | 23K | 6K | การจดจำเอนทิตีชื่อ |
เราแสดงรายการผลลัพธ์สาธารณะจาก Distilbert, Bert-PKD, Bert-of-Theseus, Tinybert และผลลัพธ์ของเราด้านล่างสำหรับการเปรียบเทียบ
ผลลัพธ์สาธารณะ:
| แบบจำลอง (สาธารณะ) | mnli | ทีม | Conll-2003 |
|---|---|---|---|
| Distilbert (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| Bert 6 -pkd (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| Bert-of-theseus (T6) | 82.4/ 82.1 | - | - |
| Bert 3 -pkd (T3) | 76.7 / 76.3 | - | - |
| Tinybert (T4-tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
ผลลัพธ์ของเรา:
| โมเดล (ของเรา) | mnli | ทีม | Conll-2003 |
|---|---|---|---|
| เบิร์ต-เบส (ครู) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| บิ๊กรู | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4-tiny | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-Nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
บันทึก :
เราทดลองเกี่ยวกับชุดข้อมูลภาษาจีนทั่วไปต่อไปนี้:
| ชุดข้อมูล | ประเภทงาน | ตัวชี้วัด | #รถไฟ | #DEV | บันทึก |
|---|---|---|---|---|---|
| xnli | การจำแนกข้อความ | ACC | 393K | 2.5k | MNLI เวอร์ชันแปลภาษาจีน |
| LCQMC | การจำแนกข้อความ | ACC | 239K | 8.8k | การจับคู่ประโยคคู่การจำแนกไบนารี |
| CMRC 2018 | การอ่านความเข้าใจ | EM/F1 | 10k | 3.4K | ความเข้าใจในการอ่านเครื่องสกัด |
| DRCD | การอ่านความเข้าใจ | EM/F1 | 27k | 3.5k | ความเข้าใจในการอ่านเครื่องสกัดเครื่อง (จีนดั้งเดิม) |
| msra ner | การติดฉลากลำดับ | F1 | 45K | 3.4k (#test) | การรับรู้เอนทิตีชื่อจีน |
ผลลัพธ์แสดงอยู่ด้านล่าง
| แบบอย่าง | xnli | LCQMC | CMRC 2018 | DRCD |
|---|---|---|---|---|
| Roberta-WWM-EXT (ครู) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4-tiny | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| แบบอย่าง | xnli | LCQMC | CMRC 2018 | DRCD | msra ner |
|---|---|---|---|---|---|
| Electra-base (ครู)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| ควันเล็ก ๆ | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
บันทึก :
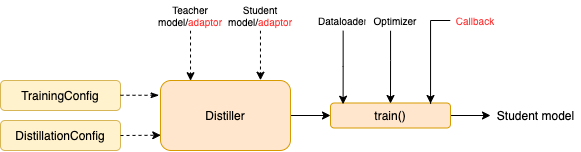
TrainingConfig : การกำหนดค่าที่เกี่ยวข้องกับการฝึกอบรมแบบจำลองการเรียนรู้ทั่วไปทั่วไปDistillationConfig : การกำหนดค่าที่เกี่ยวข้องกับวิธีการกลั่นโรงกลั่นมีหน้าที่ดำเนินการทดลองจริง มีโรงกลั่นต่อไปนี้:
BasicDistiller : การกลั่น เดี่ยว-ครูเดี่ยว ให้กลยุทธ์การกลั่นขั้นพื้นฐานGeneralDistiller (แนะนำ): การกลั่น เดี่ยวครูเดี่ยว รองรับการจับคู่คุณสมบัติระดับกลาง แนะนำเกือบตลอดเวลาMultiTeacherDistiller : การกลั่น หลายครู ซึ่งกลั่นกรองครูหลายรุ่น (ของงานเดียวกัน) เป็นรุ่นนักเรียนเดียว คลาสนี้ไม่รองรับการจับคู่คุณสมบัติระดับกลางMultiTaskDistiller : การกลั่นแบบ หลายงาน ซึ่งกลั่นกรองครูหลายรุ่น (ของงานที่แตกต่างกัน) เป็นนักเรียนคนเดียวBasicTrainer : ดูแลการฝึกอบรมแบบจำลองเดียวในชุดข้อมูลที่มีป้ายกำกับไม่ใช่สำหรับการกลั่น มันสามารถใช้ในการฝึกอบรมรูปแบบครูใน TextBrewer มีสองฟังก์ชั่นที่ผู้ใช้ควรใช้: การโทรกลับ และ อะแดปเตอร์
ในแต่ละจุดตรวจสอบหลังจากบันทึกโมเดลนักเรียนฟังก์ชันการโทรกลับจะถูกเรียกโดยผู้กลั่น สามารถใช้การโทรกลับเพื่อประเมินประสิทธิภาพของโมเดลนักเรียนในแต่ละจุดตรวจ
มันแปลงอินพุตของโมเดลและเอาต์พุตเป็นรูปแบบที่ระบุเพื่อให้พวกเขาสามารถรับรู้ได้จากเครื่องกลั่นและการสูญเสียการกลั่นสามารถคำนวณได้ ในแต่ละขั้นตอนการฝึกอบรมแบทช์และโมเดลเอาต์พุตจะถูกส่งผ่านไปยังอะแดปเตอร์ อะแดปเตอร์จัดระเบียบข้อมูลอีกครั้งและส่งคืนพจนานุกรม
สำหรับรายละเอียดเพิ่มเติมดูคำอธิบายในเอกสารฉบับเต็ม
ถาม : จะเริ่มต้นโมเดลนักเรียนได้อย่างไร?
ตอบ : โมเดลนักเรียนสามารถเริ่มต้นแบบสุ่ม (เช่นไม่มีความรู้มาก่อน) หรือเริ่มต้นด้วยน้ำหนักที่ได้รับการฝึกอบรมมาก่อน ตัวอย่างเช่นเมื่อกลั่นแบบจำลองเบิร์ตเบสไปยังเบิร์ต 3 ชั้นคุณสามารถเริ่มต้นโมเดลนักเรียนด้วย RBT3 (สำหรับงานจีน) หรือ Bert สามชั้นแรก (สำหรับงานภาษาอังกฤษ) เพื่อหลีกเลี่ยงปัญหาการเริ่มต้นเย็น เราขอแนะนำให้ผู้ใช้ใช้โมเดลนักเรียนที่ผ่านการฝึกอบรมมาก่อนเมื่อใดก็ตามที่เป็นไปได้เพื่อใช้ประโยชน์จากการฝึกอบรมล่วงหน้าขนาดใหญ่อย่างเต็มที่
ถาม : วิธีการตั้งค่าพารามิเตอร์การฝึกอบรมสำหรับการทดลองการกลั่น??
ตอบ : การกลั่นความรู้มักจะต้องใช้ช่วงการฝึกอบรมและอัตราการเรียนรู้ที่ใหญ่กว่าการฝึกอบรมในชุดข้อมูลที่มีป้ายกำกับ ตัวอย่างเช่นทีมฝึกอบรมบนเบิร์ตฐานมักจะใช้ 3 ยุคด้วย LR = 3E-5; อย่างไรก็ตามการกลั่นใช้เวลา 30 ~ 50 Epochs ด้วย LR = 1E-4 ข้อสรุปขึ้นอยู่กับการทดลองของเราและคุณควรลองใช้ข้อมูลของคุณเอง
ถาม : โมเดลครูและแบบจำลองนักเรียนของฉันใช้อินพุตที่แตกต่างกัน (พวกเขาไม่แบ่งปันคำศัพท์) ดังนั้นฉันจะกลั่นได้อย่างไร
ตอบ : คุณต้องป้อนแบทช์ที่แตกต่างให้กับครูและนักเรียน ดูส่วนฟีดแบทช์ที่แตกต่างกันให้กับนักเรียนและครูให้อาหารค่าแคชในเอกสารฉบับเต็ม
ถาม : ฉันเก็บบันทึกจากรุ่นครูของฉัน ฉันสามารถใช้มันในการกลั่นเพื่อประหยัดเวลาผ่านไปข้างหน้าได้หรือไม่?
ตอบ : ใช่ดูที่ส่วนฟีดแบทช์ที่แตกต่างกันให้กับนักเรียนและครูให้อาหารค่าแคชในเอกสารเต็มรูปแบบ
DataParallel ในปัจจุบันหากคุณพบว่า TextBrewer มีประโยชน์โปรดอ้างอิงกระดาษของเรา:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}ทำตามบัญชี WeChat อย่างเป็นทางการของเราเพื่ออัปเดตด้วยเทคโนโลยีล่าสุดของเรา!



