TextBrewer
TextBrewer 0.2.1
Inglés |中文说明

TextBrewer es un conjunto de herramientas de destilación modelo basado en Pytorch para el procesamiento del lenguaje natural. Incluye varias técnicas de destilación del campo NLP y CV y proporciona un marco de destilación fácil de usar, que permite a los usuarios experimentar rápidamente con los métodos de destilación de última generación para comprimir el modelo con un sacrificio relativamente pequeño en el rendimiento, aumentar la velocidad de inferencia y reducir el uso de la memoria.
Consulte nuestro trabajo a través de la antología ACL o la preimpresión ARXIV.
Documentación completa
17 de diciembre de 2021
24 de octubre de 2021
8 de julio de 2021
1 de marzo de 2021
Bert-EMD y destilador personalizado
Ejemplo de mnli actualizado
11 de noviembre de 2020
Actualizado a 0.2.1 :
Destilación más flexible : apoya la alimentación de diferentes lotes para el alumno y el maestro. Significa que los lotes para el estudiante y el maestro ya no necesitan ser los mismos. Se puede usar para destilar modelos con diferentes vocabularios (por ejemplo, desde Roberta hasta Bert).
Destilación más rápida : ahora los usuarios pueden precomputar y almacenar en caché de la salida del maestro, luego alimentar el caché al destilador para ahorrar el tiempo de pase hacia adelante del maestro.
Consulte Feed diferentes lotes para el alumno y el maestro, alimentando valores en caché para obtener detalles de las características anteriores.
MultiTaskDistiller ahora admite pérdida de coincidencia de características intermedias.
TensorBoard ahora registra pérdidas más detalladas (pérdida de KD, pérdida de etiqueta dura, pérdidas coincidentes ...).
Ver detalles en lanzamientos.
27 de agosto de 2020
Nos complace anunciar que nuestro modelo está en la cima del punto de referencia de pegamento, verifique la clasificación.
24 de agosto de 2020
MultiTaskDistiller y de entrenamiento.29 de julio de 2020
DistributedDataParallel : TrainingConfig Now acepta el argumento local_rank . Vea la documentación de TrainingConfig para obtener detalles.14 de julio de 2020
fp16 en True en TrainingConfig . Vea la documentación de TrainingConfig para obtener detalles.data_parallel en TrainingConfig para habilitar la capacitación paralela de datos y el trabajo de capacitación mixta de precisión juntos.26 de abril de 2020
22 de abril de 2020
17 de marzo de 2020
11 de marzo de 2020
2 de marzo de 2020
| Sección | Contenido |
|---|---|
| Introducción | Introducción a TextBrewer |
| Instalación | Cómo instalar |
| Flujo de trabajo | Dos etapas del flujo de trabajo TextBrewer |
| Inicio rápido | Ejemplo: destilación de Bert-Base a un Bert de 3 capas |
| Experimentos | Experimentos de destilación en conjuntos de datos típicos de inglés y chino |
| Conceptos centrales | Breves explicaciones de los conceptos centrales en TextBrewer |
| Preguntas frecuentes | Preguntas frecuentes |
| Problemas conocidos | Problemas conocidos |
| Citación | Cita a TextBrewer |
| Síganos | - |
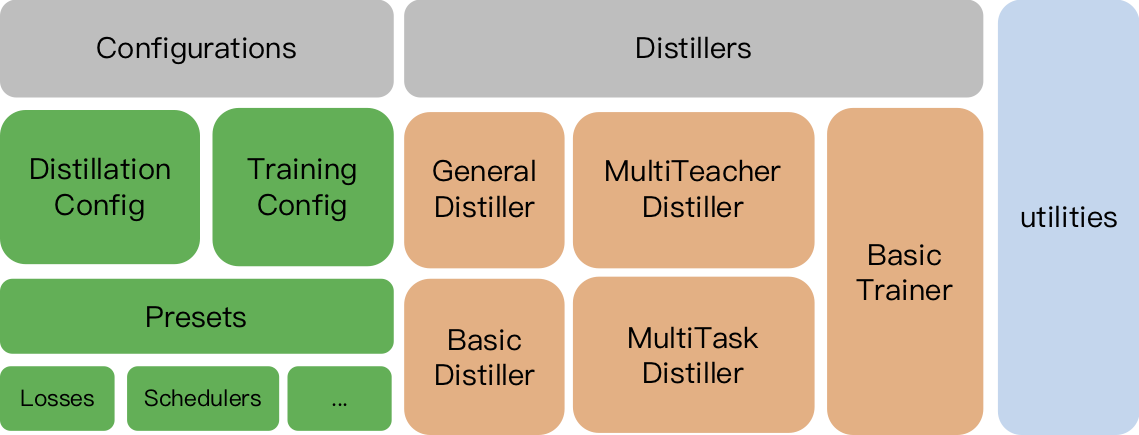
TextBrewer está diseñado para la destilación de conocimiento de los modelos PNL. Proporciona varios métodos de destilación y ofrece un marco de destilación para configurar rápidamente experimentos.
Las características principales de TextBrewer son:
TextBrewer actualmente se envía con las siguientes técnicas de destilación:
TextBrewer incluye:
Para comenzar la destilación, los usuarios deben proporcionar
TextBrewer ha logrado resultados impresionantes en varias tareas de PNL típicas. Ver experimentos.
Vea la documentación completa para usos detallados.
Requisitos
Instalar desde PYPI
pip install textbrewerInstalar desde la fuente de GitHub
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer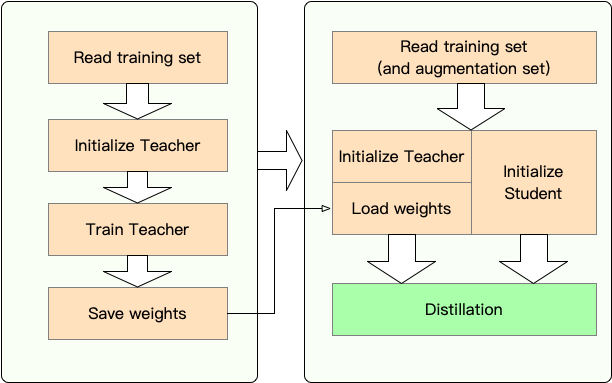
Etapa 1 : Preparación:
Etapa 2 : Destilación con TextBrewer:
Aquí mostramos el uso de TextBrewer destilando Bert-Base a un Bert de 3 capas.
Antes de la destilación, asumimos que los usuarios han proporcionado:
teacher_model (Bert-Base) y un modelo de estudiante de estudiante para ser student_model (3 capas de 3 capas).dataloader del conjunto de datos, un optimizer y un constructor de tarifas de aprendizaje o clase scheduler_class y sus args Dict scheduler_dict .Distill con TextBrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )Ejemplos de cuaderno con Transformers 4
Ejemplos/Random_token_example: un ejemplo simple de juguete ejecutable que demuestra el uso de TextBrewer. Este ejemplo realiza la destilación en la tarea de clasificación de texto con tokens aleatorios como entradas.
Ejemplos/CMRC2018_Example (chino): destilación en CMRC 2018, una tarea MRC china, utilizando DRCD como aumento de datos.
Ejemplos/mnli_example (inglés): destilación en mnli, una tarea de clasificación de par de oraciones en inglés. Este ejemplo también muestra cómo realizar la destilación de múltiples maestros.
Ejemplos/Conll2003_example (inglés): destilación en la tarea NER de Conll-2003 en inglés, que está en forma de etiquetado de secuencia.
Ejemplos/msra_ner_example (chino): este ejemplo destila un modelo de base de electra china en la tarea MSRA ner con el entrenamiento distribuido de datos paralelos (nodo único, multi-GPU).
Hemos realizado experimentos de destilación en varios conjuntos de datos de PNL en inglés y chino típicos. Las configuraciones y configuraciones se enumeran a continuación.
Hemos probado diferentes modelos de estudiantes. Para compararse con los resultados públicos, los modelos de estudiantes se construyen con bloques de transformador estándar, excepto BigRu, que es un Gru bidireccional de una sola capa. Las arquitecturas se enumeran a continuación. Tenga en cuenta que el número de parámetros incluye la capa de incrustación, pero no incluye la capa de salida de cada tarea específica.
| Modelo | #Lapas | Tamaño oculto | Tamaño de avance | #Params | Tamaño relativo |
|---|---|---|---|---|---|
| Bert-base (maestro) | 12 | 768 | 3072 | 108m | 100% |
| T6 (estudiante) | 6 | 768 | 3072 | 65m | 60% |
| T3 (estudiante) | 3 | 768 | 3072 | 44m | 41% |
| T3-Small (estudiante) | 3 | 384 | 1536 | 17m | 16% |
| T4 pequeño (estudiante) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano (estudiante) | 12 | 256 | 1024 | 17m | 16% |
| Bigru (estudiante) | - | 768 | - | 31m | 29% |
| Modelo | #Lapas | Tamaño oculto | Tamaño de avance | #Params | Tamaño relativo |
|---|---|---|---|---|---|
| Roberta-wwm-ext (maestro) | 12 | 768 | 3072 | 102m | 100% |
| Electra-base (profesor) | 12 | 768 | 3072 | 102m | 100% |
| T3 (estudiante) | 3 | 768 | 3072 | 38m | 37% |
| T3-Small (estudiante) | 3 | 384 | 1536 | 14m | 14% |
| T4 pequeño (estudiante) | 4 | 312 | 1200 | 11m | 11% |
| Electra-Small (estudiante) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches no son diferentes para diferentes modelos:
| Modelo | partidos |
|---|---|
| Bigru | Ninguno |
| T6 | L6_hidden_mse + l6_hidden_smmd |
| T3 | L3_hidden_mse + l3_hidden_smmd |
| T3-Small | L3n_hidden_mse + l3_hidden_smmd |
| T4 pequeño | L4t_hidden_mse + l4_hidden_smmd |
| T12-nano | small_hidden_mse + small_hidden_smmd |
| Electro-pequeña | small_hidden_mse + small_hidden_smmd |
Las definiciones de partidos son en ejemplos/partidos/partidos.py.
Utilizamos GeneralDistiller en todos los experimentos de destilación.
Experimentamos en los siguientes conjuntos de datos en inglés típicos:
| Conjunto de datos | Tipo de tarea | Métrica | #Tren | #Dev | Nota |
|---|---|---|---|---|---|
| Mnli | clasificación de texto | m/mm ACC | 393k | 20k | clasificación de 3 clases |
| Escuadrón 1.1 | comprensión de lectura | EM/F1 | 88k | 11k | Comprensión de lectura a la máquina de extracción de la amplia extracción |
| Conll-2003 | etiquetado de secuencia | F1 | 23k | 6k | Reconocimiento de entidad nombrado |
Enumeramos los resultados públicos de Distilbert, Bert-PKD, Bert-of-Thesus, Tinybert y nuestros resultados a continuación para la comparación.
Resultados públicos:
| Modelo (público) | Mnli | Equipo | Conll-2003 |
|---|---|---|---|
| Distilbert (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| Bert 6 -PKD (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| Bert-of-esteus (T6) | 82.4/ 82.1 | - | - |
| Bert 3 -PKD (T3) | 76.7 / 76.3 | - | - |
| Tinybert (T4 Tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
Nuestros resultados:
| Modelo (nuestro) | Mnli | Equipo | Conll-2003 |
|---|---|---|---|
| Bert-base (maestro) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-Small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4 pequeño | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
Nota :
Experimentamos en los siguientes conjuntos de datos chinos típicos:
| Conjunto de datos | Tipo de tarea | Métrica | #Tren | #Dev | Nota |
|---|---|---|---|---|---|
| Xnli | clasificación de texto | Accidentista | 393k | 2.5k | Versión de traducción china de Mnli |
| LCQMC | clasificación de texto | Accidentista | 239k | 8.8k | Clasificación de pares de oraciones, clasificación binaria |
| CMRC 2018 | comprensión de lectura | EM/F1 | 10k | 3.4k | Comprensión de lectura a la máquina de extracción de la amplia extracción |
| Guarnalda | comprensión de lectura | EM/F1 | 27k | 3.5k | Comprensión de lectura a la máquina de extracción de expansión (chino tradicional) |
| MSRA NER | etiquetado de secuencia | F1 | 45k | 3.4k (#test) | Reconocimiento de entidades con nombre chino |
Los resultados se enumeran a continuación.
| Modelo | Xnli | LCQMC | CMRC 2018 | Guarnalda |
|---|---|---|---|---|
| Roberta-wwm-ext (maestro) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-Small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4 pequeño | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| Modelo | Xnli | LCQMC | CMRC 2018 | Guarnalda | MSRA NER |
|---|---|---|---|---|---|
| Electra-base (maestro)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electro-pequeña | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
Nota :
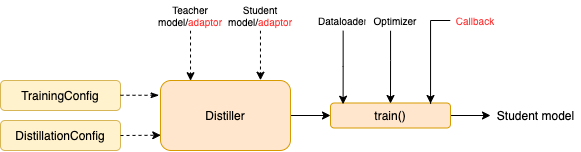
TrainingConfig : Configuración relacionada con la capacitación general del modelo de aprendizaje profundoDistillationConfig : Configuración relacionada con los métodos de destilaciónLos destiladores están a cargo de realizar los experimentos reales. Los siguientes destiladores están disponibles:
BasicDistiller : destilación de una sola tarea de maestría , proporciona estrategias de destilación básica.GeneralDistiller (recomendado): destilación de tareas únicas de una sola maestra admite la coincidencia de características intermedias. Recomendado la mayor parte del tiempo .MultiTeacherDistiller : destilación de múltiples maestros , que destila múltiples modelos de maestros (de la misma tarea) en un solo modelo de estudiante. Esta clase no es compatible con las características intermedias.MultiTaskDistiller : destilación de múltiples tareas , que destila múltiples modelos de maestros (de diferentes tareas) en un solo estudiante.BasicTrainer : capacitación supervisada Un modelo único en un conjunto de datos etiquetado, no para la destilación. Se puede usar para capacitar a un modelo de maestro .En TextBrewer, hay dos funciones que los usuarios deben implementar: devolución de llamada y adaptador .
En cada punto de control, después de guardar el modelo de estudiante, el destilador llamará a la función de devolución de llamada. Se puede utilizar una devolución de llamada para evaluar el rendimiento del modelo de estudiante en cada punto de control.
Convierte las entradas y salidas del modelo en el formato especificado para que el destilador pueda reconocerlos, y se pueden calcular las pérdidas de destilación. En cada paso de entrenamiento, las salidas por lotes y modelos se pasarán al adaptador; El adaptador reorganiza los datos y devuelve un diccionario.
Para obtener más detalles, consulte las explicaciones en documentación completa.
P : ¿Cómo inicializar el modelo de estudiante?
R : El modelo de estudiante podría inicializarse aleatoriamente (es decir, sin conocimiento previo) o ser inicializado por pesos previamente capacitados. Por ejemplo, al destilar un modelo Bert-Base a un Bert de 3 capas, puede inicializar el modelo de estudiante con RBT3 (para tareas chinas) o las primeras tres capas de Bert (para tareas de inglés) para evitar el problema de inicio en frío. Recomendamos que los usuarios usen modelos de estudiantes previamente capacitados siempre que sea posible para aprovechar completamente el pre-entrenamiento a gran escala.
P : Cómo establecer hiperparámetros de entrenamiento para los experimentos de destilación?
R : La destilación del conocimiento generalmente requiere más épocas de capacitación y una mayor tasa de aprendizaje que la capacitación en el conjunto de datos etiquetado. Por ejemplo, el equipo de entrenamiento en Bert-Base generalmente toma 3 épocas con LR = 3E-5; Sin embargo, la destilación toma 30 ~ 50 épocas con LR = 1E-4. Las conclusiones se basan en nuestros experimentos, y se le recomienda que pruebe sus propios datos .
P : Mi modelo de maestro y mi modelo de alumno toman diferentes entradas (no comparten vocabularios), entonces, ¿cómo puedo destilar?
R : Debe alimentar diferentes lotes al maestro y al alumno. Consulte la sección Feed diferentes lotes para el alumno y el maestro, alimente los valores en caché en la documentación completa.
P : He almacenado los logits de mi modelo de maestro. ¿Puedo usarlos en la destilación para ahorrar el tiempo de pase hacia adelante?
R : Sí, consulte la sección Alimentar diferentes lotes para el alumno y el maestro, alimente los valores en caché en la documentación completa.
DataParallel actualmente.Si encuentra que TextBrewer es útil, cite nuestro documento:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}¡Siga nuestra cuenta oficial de WeChat para mantenerse actualizado con nuestras últimas tecnologías!



