TextBrewer
TextBrewer 0.2.1
اللغة الإنجليزية |中文说明

TextBrewer هي مجموعة أدوات التقطير النموذجية المعتمدة على Pytorch لمعالجة اللغة الطبيعية. ويتضمن العديد من تقنيات التقطير من كل من حقل NLP و CV ويوفر إطارًا لتقطير سهلة الاستخدام ، والذي يسمح للمستخدمين بتجربة أساليب التقطير الحديثة بسرعة لضغط النموذج بتضحية صغيرة نسبيًا في الأداء ، وزيادة سرعة الاستدلال وخفض استخدام الذاكرة.
تحقق من ورقتنا من خلال مختارات ACL أو Arxiv pre-print.
الوثائق الكاملة
17 ديسمبر 2021
24 أكتوبر ، 2021
8 يوليو ، 2021
1 مارس 2021
Bert-EMD و Custom Distiller
تحديث مثال mnli
11 نوفمبر 2020
تم تحديثه إلى 0.2.1 :
التقطير الأكثر مرونة : يدعم تغذية دفعات مختلفة للطالب والمعلم. وهذا يعني أن دفعات الطالب والمعلم لم تعد بحاجة إلى أن تكون هي نفسها. يمكن استخدامه في نماذج تقطير مع مفردات مختلفة (على سبيل المثال ، من روبرتا إلى بيرت).
التقطير بشكل أسرع : يمكن للمستخدمين الآن أن يخرج المعلم وتخزينه ، ثم تغذي ذاكرة التخزين المؤقت إلى التقطير لحفظ وقت تمرير المعلم.
شاهد تغذية مجموعات مختلفة للطالب والمعلم ، وتغذية القيم المخبأة للحصول على تفاصيل الميزات أعلاه.
يدعم MultiTaskDistiller الآن خسارة مطابقة الميزات الوسيطة.
تسجل Tensorboard الآن خسائر أكثر تفصيلاً (خسارة KD ، وفقدان التسمية الصلب ، وخسائر مطابقة ...).
انظر التفاصيل في الإصدارات.
27 أغسطس 2020
يسعدنا أن نعلن أن نموذجنا على قمة Glue Benchmark ، تحقق من لوحة المتصدرين.
24 أغسطس 2020
MultiTaskDistiller وحلقات التدريب.29 يوليو ، 2020
DistributedDataParallel : TrainingConfig الآن على accected حجة local_rank . راجع وثائق TrainingConfig لمزيد من التفاصيل.14 يوليو 2020
fp16 على True في TrainingConfig . راجع وثائق TrainingConfig لمزيد من التفاصيل.data_parallel في TrainingConfig لتمكين التدريب المتوازي للبيانات والتدريب الدقيق المختلط معًا.26 أبريل 2020
22 أبريل 2020
17 مارس 2020
11 مارس 2020
2 مارس 2020
| قسم | محتويات |
|---|---|
| مقدمة | مقدمة إلى TextBrewer |
| تثبيت | كيفية التثبيت |
| سير العمل | مرحلتان من سير العمل |
| Quickstart | مثال: تقطير Bert-base إلى Bert من 3 طبقات |
| التجارب | تجارب التقطير على مجموعات البيانات الإنجليزية والصينية النموذجية |
| المفاهيم الأساسية | تفسيرات موجزة للمفاهيم الأساسية في مجرى النصي |
| التعليمات | الأسئلة المتداولة |
| القضايا المعروفة | القضايا المعروفة |
| اقتباس | الاقتباس لبروير |
| تابعنا | - |
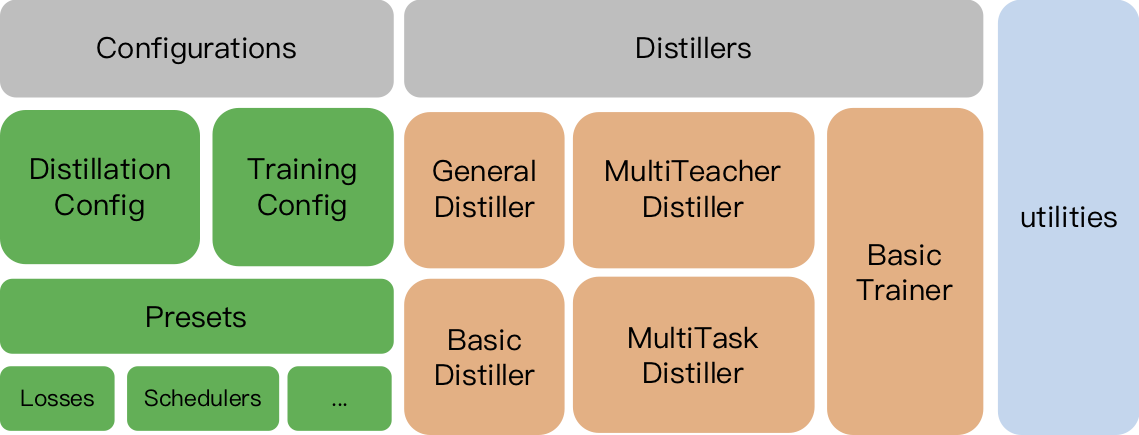
تم تصميم TextBrewer للتقطير المعرفة لنماذج NLP. إنه يوفر طرق التقطير المختلفة ويوفر إطارًا للتقطير لإنشاء التجارب بسرعة.
الميزات الرئيسية لـ TextBrewer هي:
يتم شحن textbrewer حاليا مع تقنيات التقطير التالية:
يتضمن TextBrewer :
لبدء التقطير ، يحتاج المستخدمون إلى توفيره
حقق TextBrewer نتائج رائعة على العديد من مهام NLP النموذجية. انظر التجارب.
انظر الوثائق الكاملة للاستخدامات التفصيلية.
متطلبات
تثبيت من PYPI
pip install textbrewerتثبيت من مصدر جيثب
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer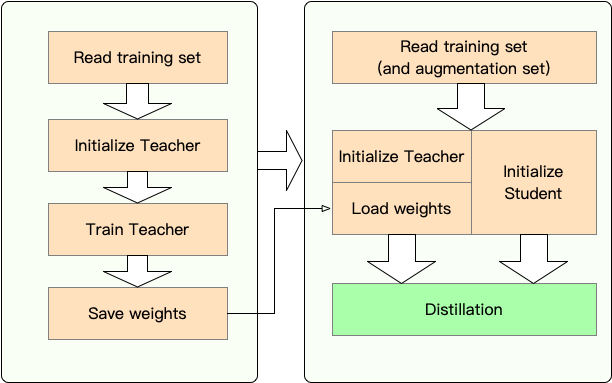
المرحلة 1 : التحضير:
المرحلة 2 : التقطير مع خير النص:
نعرض هنا استخدام TextBrewer عن طريق تقطير Bert-Base إلى Bert من 3 طبقات.
قبل التقطير ، نفترض أن المستخدمين قدموا:
teacher_model (Bert-Base) ونموذج الطالب المدرب على درب درب student_model (3 طبقات Bert).dataloader من مجموعة البيانات ، optimizer وباني أسعار تعليمي أو scheduler_class و args scheduler_dict .تقطير مع Textbrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )أمثلة دفتر مع Transformers 4
أمثلة/random_token_example: مثال لعبة بسيطة يمكن تشغيله يوضح استخدام sextbrewer. يؤدي هذا المثال التقطير على مهمة تصنيف النص مع الرموز العشوائية كمدخلات.
أمثلة/CMRC2018_EXAMPLE (صينية): التقطير على CMRC 2018 ، وهي مهمة MRC صينية ، باستخدام DRCD كزيادة للبيانات.
أمثلة/mnli_example (الإنجليزية): التقطير على MNLI ، مهمة تصنيف جملة اللغة الإنجليزية. يوضح هذا المثال أيضًا كيفية إجراء التقطير متعدد المعلمين.
أمثلة/conll2003_example (الإنجليزية): التقطير على مهمة conll-2003 الإنجليزية ner ، والتي هي في شكل علامة تسلسل.
أمثلة/MSRA_NER_EXAMPLE (صينية): هذا المثال يقطر نموذجًا صينيًا للقاعدة الإلكترونية في مهمة MSRA NER مع تدريب موازى موزع للبيانات (عقدة واحدة ، متعددة GPU).
لقد أجرينا تجارب التقطير على العديد من مجموعات بيانات NLP الإنجليزية والصينية النموذجية. يتم سرد الإعدادات والتكوينات أدناه.
لقد اختبرنا نماذج الطلاب المختلفة. للمقارنة مع النتائج العامة ، تم تصميم نماذج الطلاب مع كتل محول قياسية باستثناء Bigru وهي GRU ثنائية الاتجاه ذات الطبقة الواحدة. البنى مدرجة أدناه. لاحظ أن عدد المعلمات يتضمن طبقة التضمين ولكن لا يتضمن طبقة الإخراج لكل مهمة محددة.
| نموذج | #layers | الحجم المخفي | حجم التغذية إلى الأمام | #Params | الحجم النسبي |
|---|---|---|---|---|---|
| Bert-Base Cazed (معلم) | 12 | 768 | 3072 | 108 م | 100 ٪ |
| T6 (طالب) | 6 | 768 | 3072 | 65 م | 60 ٪ |
| T3 (طالب) | 3 | 768 | 3072 | 44 م | 41 ٪ |
| T3-Small (طالب) | 3 | 384 | 1536 | 17m | 16 ٪ |
| T4-Tiny (طالب) | 4 | 312 | 1200 | 14m | 13 ٪ |
| T12-Nano (طالب) | 12 | 256 | 1024 | 17m | 16 ٪ |
| Bigru (طالب) | - | 768 | - | 31M | 29 ٪ |
| نموذج | #layers | الحجم المخفي | حجم التغذية إلى الأمام | #Params | الحجم النسبي |
|---|---|---|---|---|---|
| روبرتا ووي إم (مدرس) | 12 | 768 | 3072 | 102m | 100 ٪ |
| Electra-Base (معلم) | 12 | 768 | 3072 | 102m | 100 ٪ |
| T3 (طالب) | 3 | 768 | 3072 | 38 م | 37 ٪ |
| T3-Small (طالب) | 3 | 384 | 1536 | 14m | 14 ٪ |
| T4-Tiny (طالب) | 4 | 312 | 1200 | 11 م | 11 ٪ |
| Electra-Small (طالب) | 12 | 256 | 1024 | 12m | 12 ٪ |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches مختلفة للنماذج المختلفة:
| نموذج | المباريات |
|---|---|
| Bigru | لا أحد |
| T6 | l6_hidden_mse + l6_hidden_smmd |
| T3 | l3_hidden_mse + l3_hidden_smmd |
| T3-Small | l3n_hidden_mse + l3_hidden_smmd |
| T4-tiny | l4t_hidden_mse + l4_hidden_smmd |
| T12-Nano | small_hidden_mse + small_hidden_smmd |
| Electra-Small | small_hidden_mse + small_hidden_smmd |
تعريفات المباريات هي في أمثلة/مباريات/مباريات.
نستخدم GeneralDistiller في جميع تجارب التقطير.
نحن نختبر على مجموعات البيانات الإنجليزية النموذجية التالية:
| مجموعة البيانات | نوع المهمة | المقاييس | #يدرب | #ديف | ملحوظة |
|---|---|---|---|---|---|
| mnli | تصنيف النص | م/ملم ACC | 393K | 20k | تصنيف الجملة 3 فئة |
| فرقة 1.1 | القراءة الفهم | م/F1 | 88 كيلو | 11k | الفهم القراءة لآلة الجهاز |
| Conll-2003 | تسلسل العلامات | F1 | 23K | 6K | اسم التعرف على الكيان |
ندرج النتائج العامة من Distilbert و Bert-PKD و Bert-Of-Of Thate و Tinybert ونتائجنا أدناه للمقارنة.
النتائج العامة:
| نموذج (عام) | mnli | فريق | Conll-2003 |
|---|---|---|---|
| Distilbert (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| بيرت 6 -PKD (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| بيرت من هذا (T6) | 82.4/ 82.1 | - | - |
| بيرت 3 -PKD (T3) | 76.7 / 76.3 | - | - |
| Tinybert (T4-Tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
نتائجنا:
| نموذج (لنا) | mnli | فريق | Conll-2003 |
|---|---|---|---|
| Bert-Base Cazed (معلم) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-Small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4-tiny | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-Nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
ملحوظة :
نختبر على مجموعات البيانات الصينية النموذجية التالية:
| مجموعة البيانات | نوع المهمة | المقاييس | #يدرب | #ديف | ملحوظة |
|---|---|---|---|---|---|
| Xnli | تصنيف النص | ACC | 393K | 2.5k | نسخة الترجمة الصينية من mnli |
| LCQMC | تصنيف النص | ACC | 239k | 8.8k | مطابقة زوج الجملة ، تصنيف ثنائي |
| CMRC 2018 | القراءة الفهم | م/F1 | 10K | 3.4k | الفهم القراءة لآلة الجهاز |
| DRCD | القراءة الفهم | م/F1 | 27K | 3.5k | الفهم القراءة لآلة الجهاز (الصينيين التقليديين) |
| MSRA ner | تسلسل العلامات | F1 | 45k | 3.4k (#اختبار) | صينية اسم التعرف على الكيان |
النتائج مدرجة أدناه.
| نموذج | Xnli | LCQMC | CMRC 2018 | DRCD |
|---|---|---|---|---|
| روبرتا ووي إم (مدرس) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-Small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4-tiny | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| نموذج | Xnli | LCQMC | CMRC 2018 | DRCD | MSRA ner |
|---|---|---|---|---|---|
| Electra-Base (معلم)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electra-Small | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
ملحوظة :
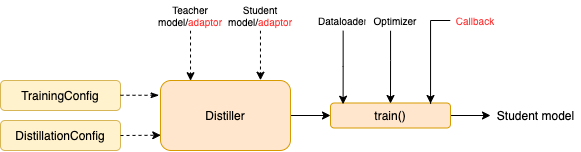
TrainingConfig : التكوين المتعلق بتدريب نموذج التعلم العميق العامDistillationConfig : التكوين المتعلق بطرق التقطيرتقطير المسؤول عن إجراء التجارب الفعلية. تتوفر تقطير التالي:
BasicDistiller : يوفر التقطير المفرد المفرد ، استراتيجيات التقطير الأساسية.GeneralDistiller (الموصى به): تدعم التقطير في المهمة الواحدة أحادية المعلمين ، يدعم مطابقة الميزات الوسيطة. أوصى معظم الوقت .MultiTeacherDistiller : تقطير متعدد المعلمين ، والذي يقوم بتقطير نماذج المعلمين المتعددة (من نفس المهمة) في نموذج طالب واحد. لا يدعم هذا الفئة مطابقة الميزات الوسيطة.MultiTaskDistiller : تقطير متعدد المهام ، والذي يقوم بتقطير نماذج المعلمين المتعددة (من المهام المختلفة) إلى طالب واحد.BasicTrainer : تدريب خاضع للإشراف نموذجًا واحدًا على مجموعة بيانات مصممة ، وليس للتقطير. يمكن استخدامه لتدريب نموذج المعلم .في TextBrewer ، هناك وظيفتان يجب تنفيذه من قبل المستخدمين: رد الاتصال والمحول .
في كل نقطة تفتيش ، بعد حفظ نموذج الطالب ، سيتم استدعاء وظيفة رد الاتصال بواسطة التقطير. يمكن استخدام رد الاتصال لتقييم أداء نموذج الطالب في كل نقطة تفتيش.
إنه يحول مدخلات النموذج والمخرجات إلى التنسيق المحدد بحيث يمكن التعرف عليها بواسطة التقطير ، ويمكن حساب خسائر التقطير. في كل خطوة تدريب ، سيتم نقل مخرجات الدُفعات والنموذج إلى المحول ؛ يعيد المحول تنظيم البيانات ويعيد قاموسًا.
لمزيد من التفاصيل ، راجع التفسيرات في الوثائق الكاملة.
س : كيفية تهيئة نموذج الطالب؟
ج : يمكن تهيئة نموذج الطالب بشكل عشوائي (أي ، بدون معرفة مسبقة) أو تهيئته بواسطة الأوزان التي تم تدريبها مسبقًا. على سبيل المثال ، عند تقطير نموذج Bert-Base إلى Bert من 3 طبقات ، يمكنك تهيئة نموذج الطالب باستخدام RBT3 (للمهام الصينية) أو الطبقات الثلاث الأولى من Bert (للمهام الإنجليزية) لتجنب مشكلة البدء الباردة. نوصي المستخدمين باستخدام نماذج الطلاب المدربين مسبقًا كلما أمكن ذلك للاستفادة الكاملة من التدريب المسبق على نطاق واسع.
س : كيفية ضبط أجهزة التدريب المفرطة على تجارب التقطير?
ج : عادة ما يتطلب تقطير المعرفة المزيد من عصر التدريب ومعدل التعلم الأكبر من التدريب على مجموعة البيانات المسمى. على سبيل المثال ، عادةً ما يأخذ فرقة التدريب على Bert-Base 3 عصر مع LR = 3E-5 ؛ ومع ذلك ، يستغرق التقطير 30 ~ 50 عصرًا مع LR = 1E-4. تستند الاستنتاجات إلى تجاربنا ، ويُنصح بتجربتك على بياناتك .
س : يأخذ نموذج المعلمين ونموذج الطالب مدخلات مختلفة (لا يشاركون المفردات) ، فكيف يمكنني التقطير؟
ج : تحتاج إلى إطعام دفعات مختلفة للمعلم والطالب. راجع القسم تغذي دفعات مختلفة للطالب والمعلم ، وتغذية القيم المخبأة في الوثائق الكاملة.
س : لقد قمت بتخزين السجلات من نموذج المعلمين الخاص بي. هل يمكنني استخدامها في التقطير لحفظ وقت النجاح للأمام؟
ج : نعم ، راجع القسم تغذي دفعات مختلفة للطالب والمعلم ، وقم بتغذية القيم المخبأة في الوثائق الكاملة.
DataParallel حاليًا.إذا وجدت أن TextBrewer مفيد ، فيرجى الاستشهاد بالورقة:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}اتبع حساب WeChat الرسمي الخاص بنا للحفاظ على تحديثه مع أحدث التقنيات لدينا!



