TextBrewer
TextBrewer 0.2.1
Anglais |中文说明

TextBrewer est une boîte à outils de distillation de modèle basée sur Pytorch pour le traitement du langage naturel. Il comprend diverses techniques de distillation du champ NLP et CV et fournit un cadre de distillation facile à utiliser, qui permet aux utilisateurs d'expérimenter rapidement les méthodes de distillation de pointe pour comprimer le modèle avec un sacrifice relativement petit dans les performances, augmentant la vitesse d'inférence et réduisant l'utilisation de la mémoire.
Vérifiez notre article via ACL Anthology ou ARXIV Pré-imprimée.
Documentation complète
17 décembre 2021
24 octobre 2021
8 juillet 2021
1er mars 2021
Bert-EMD et distiller personnalisé
Exemple MNLI mis à jour
11 novembre 2020
Mise à jour à 0.2.1 :
Distillation plus flexible : soutient l'alimentation des différents lots à l'élève et à l'enseignant. Cela signifie que les lots pour l'élève et l'enseignant n'ont plus besoin d'être les mêmes. Il peut être utilisé pour les modèles de distillation avec différents vocabulaires (par exemple, de Roberta à Bert).
Distillation plus rapide : les utilisateurs peuvent désormais pré-comparer et mettre en cache les sorties de l'enseignant, puis alimenter le cache au distillateur pour sauver le temps de passe avant de l'enseignant.
Voir alimenter différents lots à l'élève et à l'enseignant, alimentez les valeurs mises en cache pour plus de détails sur les fonctionnalités ci-dessus.
MultiTaskDistiller prend désormais en charge la perte de correspondance des fonctionnalités intermédiaires.
Tensorboard enregistre désormais des pertes plus détaillées (perte de kd, perte d'étiquette dure, pertes de correspondance ...).
Voir les détails dans les versions.
27 août 2020
Nous sommes heureux d'annoncer que notre modèle est au-dessus de la référence de colle, vérifiez le classement.
24 août 2020
MultiTaskDistiller et des boucles de formation.29 juillet 2020
DistributedDataParallel : TrainingConfig affiche désormais l'argument local_rank . Voir la documentation de TrainingConfig pour le détail.14 juillet 2020
fp16 sur True dans TrainingConfig . Voir la documentation de TrainingConfig pour le détail.data_parallel dans TrainingConfig pour permettre une formation parallèle aux données et une formation de précision mixte fonctionne ensemble.26 avril 2020
22 avril 2020
17 mars 2020
11 mars 2020
2 mars 2020
| Section | Contenu |
|---|---|
| Introduction | Introduction à TextBrewer |
| Installation | Comment installer |
| Flux de travail | Deux étapes du flux de travail TextBrewer |
| Start | Exemple: distillant Bert-base à un Bert à 3 couches |
| Expériences | Expériences de distillation sur les ensembles de données anglais et chinois typiques |
| Concepts de base | Brèves explications des concepts de base de TextBrewer |
| FAQ | Questions fréquemment posées |
| Problèmes connus | Problèmes connus |
| Citation | Citation à TextBrewer |
| Suivez-nous | - |
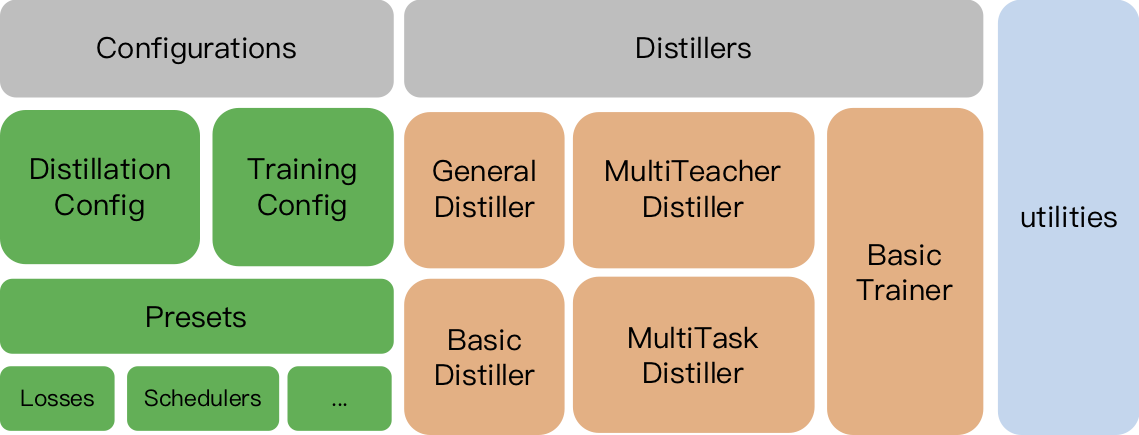
TextBrewer est conçu pour la distillation de la connaissance des modèles NLP. Il fournit diverses méthodes de distillation et propose un cadre de distillation pour la mise en place rapidement des expériences.
Les principales caractéristiques de TextBrewer sont:
TextBrewer est actuellement expédié avec les techniques de distillation suivantes:
TextBrewer comprend:
Pour commencer la distillation, les utilisateurs doivent fournir
TextBrewer a obtenu des résultats impressionnants sur plusieurs tâches NLP typiques. Voir les expériences.
Voir la documentation complète pour des usages détaillés.
Exigences
Installer à partir de PYPI
pip install textbrewerInstaller à partir de la source GitHub
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer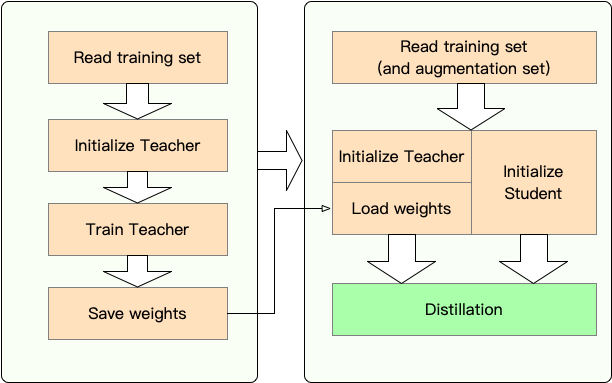
Étape 1 : Préparation:
Étape 2 : Distillation avec TextBrewer:
Ici, nous montrons l'utilisation de TextBrewer en distillant Bert-Base à un Bert à 3 couches.
Avant la distillation, nous supposons que les utilisateurs ont fourni:
teacher_model (Bert-Base) et un modèle d'étudiant étudiant student_model (3 couches Bert).dataloader de l'ensemble de données, un optimizer et un constructeur de taux d'apprentissage ou un scheduler_class de classe_classe et son args dict scheduler_dict .Distiller avec TextBrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )Exemples de cahiers avec Transformers 4
Exemples / random_token_example: un exemple de jouet couleable simple qui démontre l'utilisation de TextBrewer. Cet exemple effectue une distillation sur la tâche de classification de texte avec des jetons aléatoires comme entrées.
Exemples / CMRC2018_Example (chinois): Distillation sur CMRC 2018, une tâche chinoise de MRC, en utilisant le DRCD comme augmentation des données.
Exemples / mnli_example (anglais): distillation sur Mnli, une tâche de classification de phrase en anglais. Cet exemple montre également comment effectuer une distillation multi-enseignants.
Exemples / Conll2003_Example (anglais): Distillation sur la tâche CONLL-2003 Anglais NER, qui est sous forme d'étiquetage de séquence.
Exemples / msra_ner_example (chinois): Cet exemple distille un modèle de base chinois-électrasé
Nous avons effectué des expériences de distillation sur plusieurs ensembles de données NLP anglais et chinois typiques. Les configurations et configurations sont répertoriées ci-dessous.
Nous avons testé différents modèles d'étudiants. Pour comparer avec les résultats publics, les modèles étudiants sont construits avec des blocs de transformateurs standard à l'exception de Bigru qui est un GRU bidirectionnel unique. Les architectures sont répertoriées ci-dessous. Notez que le nombre de paramètres comprend la couche d'intégration mais n'inclut pas la couche de sortie de chaque tâche spécifique.
| Modèle | #Layers | Taille cachée | Feed-Forward Taille | #Params | Taille relative |
|---|---|---|---|---|---|
| Bert-base basé (professeur) | 12 | 768 | 3072 | 108m | 100% |
| T6 (étudiant) | 6 | 768 | 3072 | 65m | 60% |
| T3 (étudiant) | 3 | 768 | 3072 | 44m | 41% |
| T3-Small (étudiant) | 3 | 384 | 1536 | 17m | 16% |
| T4-Tiny (étudiant) | 4 | 312 | 1200 | 14m | 13% |
| T12-nano (étudiant) | 12 | 256 | 1024 | 17m | 16% |
| Bigru (étudiant) | - | 768 | - | 31m | 29% |
| Modèle | #Layers | Taille cachée | Feed-Forward Taille | #Params | Taille relative |
|---|---|---|---|---|---|
| ROBERTA-WWM-Text (professeur) | 12 | 768 | 3072 | 102m | 100% |
| Electra-base (professeur) | 12 | 768 | 3072 | 102m | 100% |
| T3 (étudiant) | 3 | 768 | 3072 | 38m | 37% |
| T3-Small (étudiant) | 3 | 384 | 1536 | 14m | 14% |
| T4-Tiny (étudiant) | 4 | 312 | 1200 | 11m | 11% |
| Electra-Small (étudiant) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches sont différentes pour différents modèles:
| Modèle | matchs |
|---|---|
| Bigru | Aucun |
| T6 | L6_hidden_mse + l6_hidden_smmd |
| T3 | L3_hidden_mse + l3_hidden_smmd |
| T3-petit | L3n_hidden_mse + l3_hidden_smmd |
| T4-tiny | L4t_hidden_mse + l4_hidden_smmd |
| T12-nano | small_hidden_mse + small_hidden_smmd |
| Électra-petit | small_hidden_mse + small_hidden_smmd |
Les définitions des correspondances sont à des exemples / correspondances / matchs.py.
Nous utilisons GeneralDistiller dans toutes les expériences de distillation.
Nous expérimentons sur les ensembles de données anglais typiques suivants:
| Ensemble de données | Type de tâche | Métrique | #Former | #Dev | Note |
|---|---|---|---|---|---|
| MNLI | Classification de texte | m / mm acc | 393K | 20K | Classification de 3 classes de phrases |
| Escouade 1.1 | compréhension de la lecture | EM / F1 | 88K | 11K | compréhension de la lecture de la machine d'extraction |
| Conll-2003 | marquage de séquence | F1 | 23K | 6K | Reconnaissance d'entité nommée |
Nous énumérons les résultats publics de Distilbert, Bert-PKD, Bert-of-Thisheus, Tinybert et nos résultats ci-dessous pour comparaison.
Résultats du public:
| Modèle (public) | MNLI | Équipe | Conll-2003 |
|---|---|---|---|
| Distilbert (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| Bert 6 -PKD (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| Bert-de-thèse (T6) | 82.4 / 82.1 | - | - |
| Bert 3 -PKD (T3) | 76.7 / 76.3 | - | - |
| Tinybert (T4-Tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
Nos résultats:
| Modèle (le nôtre) | MNLI | Équipe | Conll-2003 |
|---|---|---|---|
| Bert-base basé (professeur) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - | - | 85.3 |
| T6 | 83,5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-petit | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4-tiny | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
Note :
Nous expérimentons sur les ensembles de données chinois typiques suivants:
| Ensemble de données | Type de tâche | Métrique | #Former | #Dev | Note |
|---|---|---|---|---|---|
| Xnli | Classification de texte | Accrocheur | 393K | 2,5k | Version de traduction chinoise de MNLI |
| LCQMC | Classification de texte | Accrocheur | 239k | 8,8k | correspondance de paires de phrases, classification binaire |
| CMRC 2018 | compréhension de la lecture | EM / F1 | 10k | 3,4k | compréhension de la lecture de la machine d'extraction |
| DRCD | compréhension de la lecture | EM / F1 | 27K | 3,5k | compréhension de lecture de la machine à extraction (chinois traditionnel) |
| MSRA NER | marquage de séquence | F1 | 45k | 3,4k (#test) | Reconnaissance de l'entité nommée chinoise |
Les résultats sont répertoriés ci-dessous.
| Modèle | Xnli | LCQMC | CMRC 2018 | DRCD |
|---|---|---|---|---|
| ROBERTA-WWM-Text (professeur) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-petit | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4-tiny | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| Modèle | Xnli | LCQMC | CMRC 2018 | DRCD | MSRA NER |
|---|---|---|---|---|---|
| Electra-base (professeur)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Électra-petit | 77.7 | 89.3 | 66.5 / 84.9 | 85,5 / 91.3 | 93.48 |
Note :
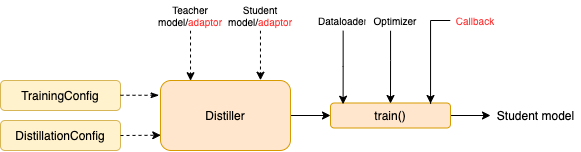
TrainingConfig : Configuration liée à la formation générale du modèle d'apprentissage en profondeurDistillationConfig : configuration liée aux méthodes de distillationLes distillateurs sont chargés de mener les expériences réelles. Les distillateurs suivants sont disponibles:
BasicDistiller : Distillation à tâches mono-enseignantes , fournit des stratégies de distillation de base.GeneralDistiller (recommandé): Distillation à tâche unique monocaste , prend en charge la correspondance des fonctionnalités intermédiaires. Recommandé la plupart du temps .MultiTeacherDistiller : distillation multi-enseignants , qui distille plusieurs modèles d'enseignants (de la même tâche) en un seul modèle d'élève. Cette classe ne prend pas en charge les fonctionnalités intermédiaires correspondant.MultiTaskDistiller : distillation multi-tâches , qui distille plusieurs modèles d'enseignants (de différentes tâches) en un seul élève.BasicTrainer : formation supervisée un modèle unique sur un ensemble de données étiqueté, pas pour la distillation. Il peut être utilisé pour former un modèle d'enseignant .Dans TextBrewer, il existe deux fonctions qui doivent être implémentées par les utilisateurs: rappel et adaptateur .
À chaque point de contrôle, après avoir enregistré le modèle étudiant, la fonction de rappel sera appelée par le distillateur. Un rappel peut être utilisé pour évaluer les performances du modèle étudiant à chaque point de contrôle.
Il convertit les entrées et sorties du modèle au format spécifié afin qu'ils puissent être reconnus par le distillateur, et les pertes de distillation peuvent être calculées. À chaque étape de formation, les sorties par lots et modèles seront transmises à l'adaptateur; L'adaptateur réorganise les données et renvoie un dictionnaire.
Pour plus de détails, consultez les explications dans la documentation complète.
Q : Comment initialiser le modèle étudiant?
R : Le modèle étudiant pourrait être initialisé au hasard (c'est-à-dire sans connaissance préalable) ou être initialisés par des poids pré-formés. Par exemple, lors de la distillation d'un modèle de base Bert à un Bert à 3 couches, vous pouvez initialiser le modèle étudiant avec RBT3 (pour les tâches chinoises) ou les trois premières couches de Bert (pour les tâches anglaises) pour éviter le problème de démarrage à froid. Nous recommandons aux utilisateurs d'utiliser des modèles d'étudiants pré-formés chaque fois que possible pour profiter pleinement de la pré-formation à grande échelle.
Q : Comment définir des hyperparamètres de formation pour les expériences de distillation?
R : La distillation des connaissances nécessite généralement plus d'époches de formation et un taux d'apprentissage plus important que la formation sur l'ensemble de données étiqueté. Par exemple, l'escouade d'entraînement sur Bert-base prend généralement 3 époques avec LR = 3E-5; Cependant, la distillation prend 30 ~ 50 époques avec LR = 1E-4. Les conclusions sont basées sur nos expériences et il est conseillé d'essayer vos propres données .
Q : Mon modèle de professeur et mon modèle d'élève prennent des intrants différents (ils ne partagent pas de vocabulaires), alors comment puis-je distiller?
R : Vous devez nourrir différents lots à l'enseignant et à l'élève. Voir la section Faire les différents lots de l'élève et de l'enseignant, alimentez les valeurs mises en cache dans la documentation complète.
Q : J'ai stocké les logits de mon modèle de professeur. Puis-je les utiliser dans la distillation pour économiser le temps de passe avant?
R : Oui, consultez la section alimenter différents lots à l'élève et à l'enseignant, alimentez les valeurs mises en cache dans la documentation complète.
DataParallel actuellement.Si vous trouvez que TextBrewer est utile, veuillez citer notre article:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}Suivez notre compte WECHAT officiel pour rester à jour avec nos dernières technologies!



