TextBrewer
TextBrewer 0.2.1
영어 |中文说明

TextBrewer 는 자연어 처리를위한 Pytorch 기반 모델 증류 툴킷입니다. 여기에는 NLP 및 CV 필드의 다양한 증류 기술이 포함되어 있으며 사용하기 쉬운 증류 프레임 워크를 제공하여 사용자는 최첨단 증류 방법을 신속하게 실험하여 성능 속도에서 비교적 작은 희생으로 모델을 압축하고 추론 속도를 높이고 메모리 사용량을 줄일 수 있습니다.
ACL Anthology 또는 Arxiv 프리 인쇄를 통해 논문을 확인하십시오.
전체 문서
2021 년 12 월 17 일
2021 년 10 월 24 일
2021 년 7 월 8 일
2021 년 3 월 1 일
버트 -EMD 및 맞춤형 증류기
업데이트 된 MNLI 예제
2020 년 11 월 11 일
0.2.1로 업데이트 :
보다 유연한 증류 : 학생과 교사에게 다른 배치를 먹이는 것을 지원합니다. 그것은 학생과 교사의 배치가 더 이상 동일 할 필요가 없다는 것을 의미합니다. 어휘가 다른 모델 (예 : Roberta에서 Bert까지)을 증류하는 데 사용할 수 있습니다.
더 빠른 증류 : 사용자는 이제 교사 출력을 사전 압축하고 캐시 한 다음 캐시를 증류기에 공급하여 교사의 전진 패스 시간을 절약 할 수 있습니다.
위의 기능에 대한 자세한 내용은 학생 및 교사에 대한 다른 배치, 학생 및 교사에 대한 다른 배치를 참조하십시오.
MultiTaskDistiller 이제 중간 기능 일치 손실을 지원합니다.
Tensorboard는 이제 더 자세한 손실 (KD 손실, 하드 레이블 손실, 일치 손실 ...)을 기록합니다.
릴리스의 세부 사항을 참조하십시오.
2020 년 8 월 27 일
우리는 우리의 모델이 접착제 벤치 마크, 리더 보드를 확인하고 있음을 발표하게되어 기쁩니다.
2020 년 8 월 24 일
MultiTaskDistiller 및 교육 루프에서 버그를 수정했습니다.2020 년 7 월 29 일
DistributedDataParallel 사용하여 분산 데이터 평행 교육에 대한 지원을 추가했습니다. TrainingConfig 이제 local_rank 인수를 계산합니다. 자세한 내용은 TrainingConfig 의 문서를 참조하십시오.2020 년 7 월 14 일
TrainingConfig 에서 fp16 True 로 설정하십시오. 자세한 내용은 TrainingConfig 의 문서를 참조하십시오.TrainingConfig 에 data_parallel 옵션이 추가되어 데이터 병렬 교육 및 혼합 정밀 교육이 함께 작동 할 수 있습니다.2020 년 4 월 26 일
2020 년 4 월 22 일
2020 년 3 월 17 일
2020 년 3 월 11 일
2020 년 3 월 2 일
| 부분 | 내용물 |
|---|---|
| 소개 | TextBrewer 소개 |
| 설치 | 설치 방법 |
| 워크 플로 | 텍스트 브루어 워크 플로의 두 단계 |
| QuickStart | 예 : 3 층 베르트에 버트베이스를 증류합니다 |
| 실험 | 전형적인 영어 및 중국 데이터 세트에 대한 증류 실험 |
| 핵심 개념 | 텍스트 브루어의 핵심 개념에 대한 간단한 설명 |
| FAQ | 자주 묻는 질문 |
| 알려진 문제 | 알려진 문제 |
| 소환 | 텍스트 브루어에 대한 인용 |
| 우리를 따르십시오 | - |
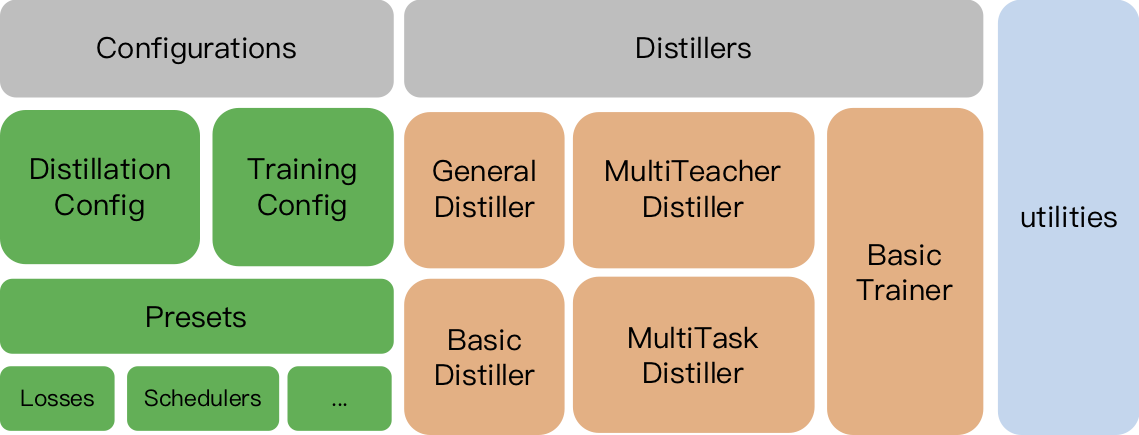
TextBrewer는 NLP 모델의 지식 증류를 위해 설계되었습니다. 다양한 증류 방법을 제공하고 실험을 신속하게 설정하기위한 증류 프레임 워크를 제공합니다.
텍스트 브루어 의 주요 기능은 다음과 같습니다.
TextBrewer 는 현재 다음과 같은 증류 기술이 있습니다.
TextBrewer 는 다음과 같습니다.
증류를 시작하려면 사용자가 제공해야합니다
TextBrewer는 여러 일반적인 NLP 작업에서 인상적인 결과를 얻었습니다. 실험을 참조하십시오.
자세한 사용법은 전체 문서를 참조하십시오.
요구 사항
PYPI에서 설치하십시오
pip install textbrewerGitHub 소스에서 설치하십시오
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer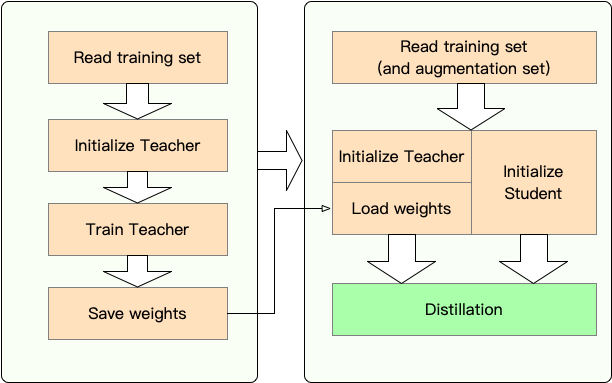
1 단계 : 준비 :
2 단계 : TextBrewer와의 증류 :
여기서 우리는 Bert-Base를 3 층 버트로 증류하여 TextBrewer의 사용을 보여줍니다.
증류 전에 사용자가 다음을 제공했다고 가정합니다.
teacher_model (bert-base) 및 훈련 된 학생 모델 student_model (3 층 버트).optimizer 및 학습 속도 빌더 또는 클래스 scheduler_class 및 args dict scheduler_dict 의 dataloader .텍스트 브루어로 증류 :
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )트랜스포머가있는 노트북 예 4
예제/random_token_example : TextBrewer의 사용을 보여주는 간단한 런닝 가능한 장난감 예제. 이 예제는 입력으로 임의의 토큰으로 텍스트 분류 작업에서 증류를 수행합니다.
예제/CMRC2018_Example (중국어) : DRCD를 데이터 증강으로 사용하는 중국 MRC 작업 인 CMRC 2018의 증류.
예제/mnli_example (영어) : 영어 문장 쌍 분류 작업 인 Mnli의 증류. 이 예제는 또한 다중 교사 증류를 수행하는 방법을 보여줍니다.
예/conll2003_example (영어) : Conll-2003 영어 ner 작업의 증류.
예제/msra_ner_example (중국어) :이 예제는 분산 된 데이터 평행 교육 (단일 노드, 멀티 -GPU)으로 MSRA NER 작업의 중국-전자 기반 모델을 증류합니다.
우리는 몇 가지 전형적인 영어 및 중국 NLP 데이터 세트에서 증류 실험을 수행했습니다. 설정 및 구성은 다음과 같습니다.
우리는 다른 학생 모델을 테스트했습니다. 공개 결과와 비교하기 위해, 학생 모델은 단일 계층 양방향 GRU 인 Bigru를 제외한 표준 변압기 블록으로 구축됩니다. 아키텍처는 아래에 나열되어 있습니다. 매개 변수 수에는 임베딩 층이 포함되지만 각 특정 작업의 출력 계층은 포함되지 않습니다.
| 모델 | #Layers | 숨겨진 크기 | 피드 포워드 크기 | #Params | 상대 크기 |
|---|---|---|---|---|---|
| 버트베이스 사례 (교사) | 12 | 768 | 3072 | 108m | 100% |
| T6 (학생) | 6 | 768 | 3072 | 65m | 60% |
| T3 (학생) | 3 | 768 | 3072 | 44m | 41% |
| T3-Small (학생) | 3 | 384 | 1536 | 17m | 16% |
| T4-TINY (학생) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano (학생) | 12 | 256 | 1024 | 17m | 16% |
| Bigru (학생) | - | 768 | - | 31m | 29% |
| 모델 | #Layers | 숨겨진 크기 | 피드 포워드 크기 | #Params | 상대 크기 |
|---|---|---|---|---|---|
| Roberta-WWM-EXT (교사) | 12 | 768 | 3072 | 102m | 100% |
| 전기 기반 (교사) | 12 | 768 | 3072 | 102m | 100% |
| T3 (학생) | 3 | 768 | 3072 | 38m | 37% |
| T3-Small (학생) | 3 | 384 | 1536 | 14m | 14% |
| T4-TINY (학생) | 4 | 312 | 1200 | 11m | 11% |
| Electra-Small (학생) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches 는 모델마다 다르지만.
| 모델 | 성냥 |
|---|---|
| 빅루 | 없음 |
| T6 | l6_hidden_mse + l6_hidden_smmd |
| T3 | l3_hidden_mse + l3_hidden_smmd |
| T3-Small | l3n_hidden_mse + l3_hidden_smmd |
| T4-TINY | l4t_hidden_mse + l4_hidden_smmd |
| T12-Nano | small_hidden_mse + small_hidden_smmd |
| 전자식 | small_hidden_mse + small_hidden_smmd |
경기의 정의는 예제/매치/매치에 있습니다.
우리는 모든 증류 실험에서 GeneralDistiller를 사용합니다.
다음과 같은 일반적인 영어 데이터 세트를 실험합니다.
| 데이터 세트 | 작업 유형 | 메트릭 | #기차 | #dev | 메모 |
|---|---|---|---|---|---|
| mnli | 텍스트 분류 | m/mm Acc | 393K | 20k | 문장 쌍 3 클래스 분류 |
| 분대 1.1 | 독해력 | EM/F1 | 88K | 11k | 스팬 추출 기계 읽기 이해력 |
| Conll-2003 | 시퀀스 라벨링 | F1 | 23k | 6k | 지명 된 엔티티 인식 |
우리는 Distilbert, Bert-PKD, Bert-of Thissus, Tinybert 및 비교를 위해 아래 결과의 공개 결과를 나열합니다.
공개 결과 :
| 모델 (공개) | mnli | 분대 | Conll-2003 |
|---|---|---|---|
| Distilbert (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| 버트 6 -pkd (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| Bert-of thisesus (T6) | 82.4/ 82.1 | - | - |
| 버트 3 -pkd (T3) | 76.7 / 76.3 | - | - |
| Tinybert (T4-Tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
우리의 결과 :
| 모델 (우리의) | mnli | 분대 | Conll-2003 |
|---|---|---|---|
| 버트베이스 사례 (교사) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| 빅루 | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-Small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4-TINY | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-Nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
메모 :
우리는 다음과 같은 전형적인 중국 데이터 세트를 실험합니다.
| 데이터 세트 | 작업 유형 | 메트릭 | #기차 | #dev | 메모 |
|---|---|---|---|---|---|
| xnli | 텍스트 분류 | acc | 393K | 2.5K | MNLI의 중국어 번역 버전 |
| LCQMC | 텍스트 분류 | acc | 239K | 8.8k | 문장 쌍 일치, 이진 분류 |
| CMRC 2018 | 독해력 | EM/F1 | 10k | 3.4k | 스팬 추출 기계 읽기 이해력 |
| DRCD | 독해력 | EM/F1 | 27K | 3.5k | 스팬 추출 기계 독해 (전통 중국어) |
| MSRA NER | 시퀀스 라벨링 | F1 | 45K | 3.4K (#Test) | 중국어 명명 된 엔티티 인식 |
결과는 아래에 나열되어 있습니다.
| 모델 | xnli | LCQMC | CMRC 2018 | DRCD |
|---|---|---|---|---|
| Roberta-WWM-EXT (교사) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-Small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4-TINY | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| 모델 | xnli | LCQMC | CMRC 2018 | DRCD | MSRA NER |
|---|---|---|---|---|---|
| 전기 기반 (교사)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| 전자식 | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
메모 :
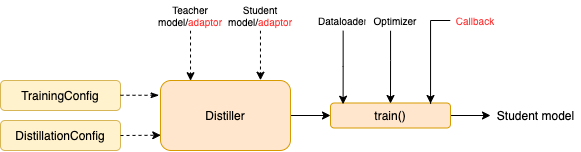
TrainingConfig : 일반 딥 러닝 모델 교육과 관련된 구성DistillationConfig : 증류 방법과 관련된 구성증류기는 실제 실험을 수행합니다. 다음 증류기를 사용할 수 있습니다.
BasicDistiller : 단일 교사 단일 태스크 증류, 기본 증류 전략을 제공합니다.GeneralDistiller (권장) : 단일 교사 단일 태스크 증류는 중간 기능 일치를 지원합니다. 대부분의 시간을 권장했습니다 .MultiTeacherDistiller : 다중 교사 증류로, 동일한 작업의 여러 교사 모델을 단일 학생 모델로 증류합니다. 이 클래스는 중간 기능 일치를 지원하지 않습니다.MultiTaskDistiller : 다중 태스크 증류로 여러 교사 모델 (다른 작업)을 단일 학생으로 증류합니다.BasicTrainer : 감독 훈련 증류가 아닌 라벨이 붙은 데이터 세트의 단일 모델. 교사 모델을 훈련시키는 데 사용될 수 있습니다 .TextBrewer에는 사용자가 구현 해야하는 두 가지 기능, 즉 콜백 및 어댑터가 있습니다.
각 체크 포인트에서 학생 모델을 저장 한 후 콜백 함수는 증류기에서 호출됩니다. 콜백을 사용하여 각 체크 포인트에서 학생 모델의 성능을 평가할 수 있습니다.
모델 입력 및 출력을 지정된 형식으로 변환하여 증류기에 의해 인식 될 수 있으며 증류 손실을 계산할 수 있습니다. 각 훈련 단계에서 배치 및 모델 출력이 어댑터로 전달됩니다. 어댑터는 데이터를 재구성하고 사전을 반환합니다.
자세한 내용은 전체 문서의 설명을 참조하십시오.
Q : 학생 모델을 초기화하는 방법은 무엇입니까?
A : 학생 모델은 무작위로 초기화되거나 (사전 지식없이) 미리 훈련 된 가중치로 초기화 될 수 있습니다. 예를 들어, Bert-Base 모델을 3 층 BERT로 증류 할 때 콜드 스타트 문제를 피하기 위해 RBT3 (중국 작업) 또는 처음 3 개의 Bert (영어 작업)로 학생 모델을 초기화 할 수 있습니다. 사용자는 가능한 한 미리 훈련 된 학생 모델을 사용하여 대규모 사전 훈련을 완전히 활용하는 것이 좋습니다.
Q : 증류 실험을위한 훈련 초반 미터를 설정하는 방법?
A : 지식 증류는 일반적으로 라벨이 붙은 데이터 세트에 대한 교육보다 더 많은 훈련 에포크와 더 큰 학습 속도가 필요합니다. 예를 들어, Bert-Base에 대한 훈련 분대는 일반적으로 LR = 3E-5 인 3 개의 에포크를 취합니다. 그러나 증류는 LR = 1E-4 인 30 ~ 50 에포크가 필요합니다. 결론은 우리의 실험을 기반으로하며, 귀하는 자신의 데이터를 시도하는 것이 좋습니다 .
Q : 선생님 모델과 학생 모델은 다른 입력을 취합니다 (어휘를 공유하지 않음). 어떻게 증류 할 수 있습니까?
A : 교사와 학생에게 다른 배치를 공급해야합니다. 섹션이 학생 및 교사에게 다른 배치를 피드, 전체 문서에서 캐시 된 값을 공급하십시오.
Q : 선생님 모델에서 로그를 저장했습니다. 전방 통과 시간을 절약하기 위해 증류에 사용할 수 있습니까?
A : 그렇습니다. 섹션이 학생 및 교사에게 다른 배치를 피드, 전체 문서에서 캐시 된 값을 피드하십시오.
DataParallel 통해서만 제공됩니다.TextBrewer가 도움이된다면, 우리 논문을 인용하십시오.
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}공식 WeChat 계정을 따라 최신 기술로 업데이트하십시오!



