TextBrewer
TextBrewer 0.2.1
Английский |中文说明

TextBrewer -это инструментарий для дистилляции модели на основе Pytorch для обработки естественного языка. Он включает в себя различные методы дистилляции как с NLP, так и с CV-поля и обеспечивают простую в использовании структуру дистилляции, которая позволяет пользователям быстро экспериментировать с современными методами дистилляции для сжатия модели с относительно небольшой жертвой в производительности, увеличивая скорость вывода и уменьшая использование памяти.
Проверьте нашу статью с помощью антологии ACL или Arxiv Pre Print.
Полная документация
17 декабря 2021 года
24 октября 2021 года
8 июля 2021 года
1 марта 2021 года
Берт-Эмд и пользовательский дистиллятор
Обновленный пример MNLI
11 ноября 2020 года
Обновлено до 0.2.1 :
Более гибкая дистилляция : поддерживает кормление различных партий ученику и учителю. Это означает, что партии для ученика и учителя больше не нужно быть такими же. Его можно использовать для дистилляции моделей с различными словари (например, от Роберты до Берта).
Более быстрая дистилляция : пользователи теперь могут предварительно выпустить и кэшировать результаты учителя, а затем подавать кэш в дистиллятор, чтобы сохранить время вперед учителя.
См. Feed разные партии для ученика и учителя, кормить кэшированные значения для получения подробной информации о функциях выше.
MultiTaskDistiller теперь поддерживает промежуточную потерю сопоставления функций.
Tensorboard теперь записывает более подробные потери (потери KD, потери жесткой метки, соответствующие потери ...).
Смотрите детали в выпусках.
27 августа 2020 года
Мы рады сообщить, что наша модель находится на вершине клея, проверьте таблицу лидеров.
24 августа 2020 года
MultiTaskDistiller и тренировочных петлях.29 июля 2020 года
DistributedDataParallel : TrainingConfig теперь активирует аргумент local_rank . Смотрите документацию TrainingConfig для деталей.14 июля 2020 года
fp16 True в TrainingConfig . Смотрите документацию TrainingConfig для деталей.data_parallel в TrainingConfig , чтобы обеспечить параллельную обучение данных и смешанную точную тренировку вместе.26 апреля 2020 года
22 апреля 2020 года
17 марта 2020 года
11 марта 2020 года
2 марта 2020 года
| Раздел | Содержимое |
|---|---|
| Введение | Введение в TextBrewer |
| Установка | Как установить |
| Рабочий процесс | Два стадии рабочего процесса текстовых пивоваров |
| QuickStart | Пример: перевести базу BERT в 3-слойный берт |
| Эксперименты | Эксперименты по дистилляции на типичных наборах данных по английскому и китайскому |
| Основные понятия | Краткие объяснения основных концепций в TextBrewer |
| Часто задаваемые вопросы | Часто задаваемые вопросы |
| Известные проблемы | Известные проблемы |
| Цитирование | Цитация TextBrewer |
| Подписывайтесь на нас | - |
TextBrewer предназначен для дистилляции знаний моделей NLP. Он обеспечивает различные методы дистилляции и предлагает структуру дистилляции для быстрого настройки экспериментов.
Основные особенности TextBrewer :
TextBrewer в настоящее время поставляется со следующими методами дистилляции:
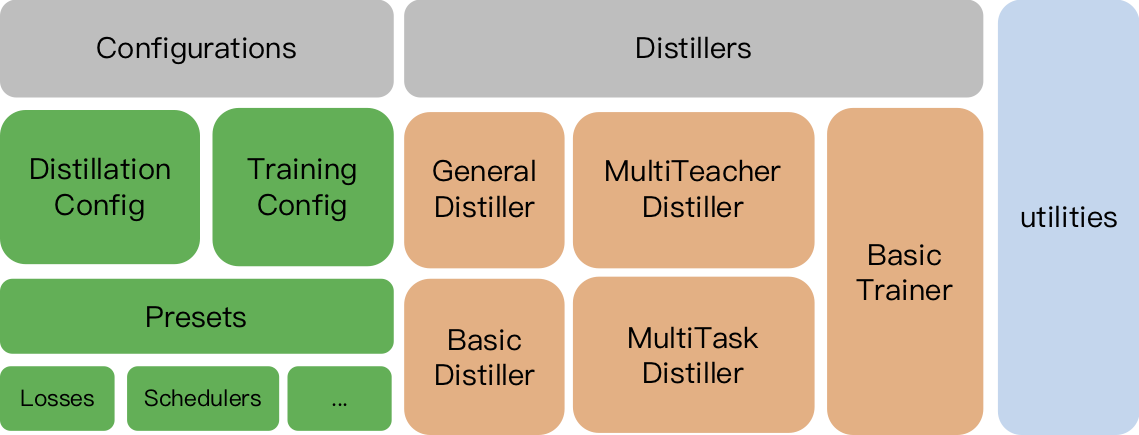
TextBrewer включает в себя:
Чтобы начать дистилляцию, пользователи должны предоставить
TextBrewer достиг впечатляющих результатов по нескольким типичным задачам NLP. Смотрите эксперименты.
Смотрите полную документацию для подробного использования.
Требования
Установите из PYPI
pip install textbrewerУстановите из источника GitHub
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer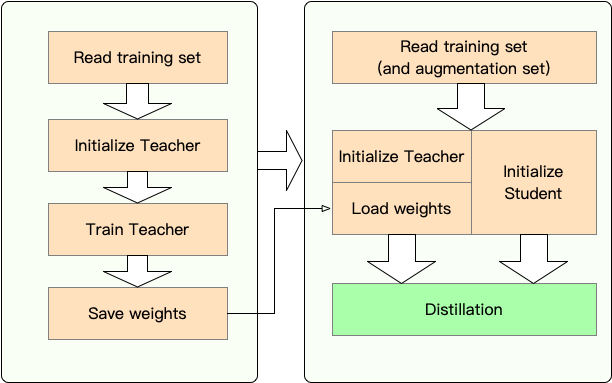
Этап 1 : подготовка:
Этап 2 : дистилляция с помощью TextBrewer:
Здесь мы показываем использование TextBrewer, перегоняя Bert-Base в 3-слойный Bert.
Перед дистилляцией мы предполагаем, что пользователи предоставили:
teacher_model (BERT-BASE) и обученная ученической модели student_model (3-слойный BERT).dataloader данных, optimizer и строитель обучения или scheduler_class и его ARGS DICT DICT scheduler_dict .Distill с TextBrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )Примеры ноутбуков с трансформаторами 4
Примеры/random_token_example: простой пример игрушек, который демонстрирует использование TextBrewer. Этот пример выполняет дистилляцию в задаче классификации текста со случайными токенами в качестве входных данных.
Примеры/CMRC2018_Example (китайский): дистилляция на CMRC 2018, китайская задача MRC, используя DRCD в качестве расширения данных.
Примеры/mnli_example (английский): дистилляция на MNLI, задача классификации пары английского предложения. Этот пример также показывает, как выполнить дистилляцию с несколькими учителями.
Примеры/conll2003_example (английский): дистилляция на задаче Conll-2003 English NER, которая находится в форме маркировки последовательности.
Примеры/msra_ner_example (китайский): этот пример дистирует модель китайской электро-базы по задаче MSRA с распределенным обучением данных-параллельной подготовкой (один узел, мульти-GPU).
Мы провели эксперименты по дистилляции на нескольких типичных наборах данных по английскому и китайскому НЛП. Настройки и конфигурации перечислены ниже.
Мы протестировали разные студенческие модели. Для сравнения с общественными результатами модели студентов построены со стандартными блоками трансформатора, за исключением Bigru, который является односторонним двунаправленным GRU. Архитектуры перечислены ниже. Обратите внимание, что количество параметров включает в себя слой встраивания, но не включает выходной слой каждой конкретной задачи.
| Модель | #Layers | Скрытый размер | Размер подачи | #Парамы | Относительный размер |
|---|---|---|---|---|---|
| Берт-базовый (учитель) | 12 | 768 | 3072 | 108 м | 100% |
| T6 (студент) | 6 | 768 | 3072 | 65м | 60% |
| T3 (студент) | 3 | 768 | 3072 | 44 м | 41% |
| T3-Small (студент) | 3 | 384 | 1536 | 17 м | 16% |
| T4-Tiny (студент) | 4 | 312 | 1200 | 14 м | 13% |
| T12-nano (студент) | 12 | 256 | 1024 | 17 м | 16% |
| Бигру (студент) | - | 768 | - | 31 м | 29% |
| Модель | #Layers | Скрытый размер | Размер подачи | #Парамы | Относительный размер |
|---|---|---|---|---|---|
| Роберта-WWM-EXT (учитель) | 12 | 768 | 3072 | 102 м | 100% |
| Электрабаза (учитель) | 12 | 768 | 3072 | 102 м | 100% |
| T3 (студент) | 3 | 768 | 3072 | 38м | 37% |
| T3-Small (студент) | 3 | 384 | 1536 | 14 м | 14% |
| T4-Tiny (студент) | 4 | 312 | 1200 | 11m | 11% |
| Electra-Small (студент) | 12 | 256 | 1024 | 12 м | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches отличаются для разных моделей:
| Модель | матчи |
|---|---|
| Бигру | Никто |
| T6 | L6_hidden_mse + l6_hidden_smmd |
| T3 | L3_hidden_mse + l3_hidden_smmd |
| T3-Small | L3n_hidden_mse + l3_hidden_smmd |
| T4-ininy | L4T_HIDDEN_MSE + L4_HIDDEN_SMMD |
| T12-Nano | small_hidden_mse + small_hidden_smmd |
| Электра-Смалл | small_hidden_mse + small_hidden_smmd |
Определения совпадений приведены в примерах/матчах/матчах.py.
Мы используем GeneralDistiller во всех экспериментах по дистилляции.
Мы экспериментируем на следующих типичных наборах данных английского языка:
| Набор данных | Тип задачи | Метрики | #Тренироваться | #Dev | Примечание |
|---|---|---|---|---|---|
| Mnli | текстовая классификация | М/мм акк | 393K | 20K | Классификация PAIR PAIR 3-го класса |
| Отряд 1.1 | Понимание прочитанного | EM/F1 | 88к | 11K | Понимание прочитанного прочитанного прочтения |
| Conll-2003 | Маркировка последовательности | F1 | 23K | 6K | Названное признание сущности |
Мы перечислим общественные результаты от Distilbert, Bert-PKD, Bert-of Thezeus, Tinybert и наших результатов ниже для сравнения.
Общественные результаты:
| Модель (публичная) | Mnli | Отряд | Conll-2003 |
|---|---|---|---|
| Дистильберт (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| Bert 6 -pkd (T6) | 81.5 / 81.0 | 77,1 / 85,3 | - |
| Берт-это (T6) | 82,4/ 82,1 | - | - |
| Bert 3 -pkd (T3) | 76,7 / 76,3 | - | - |
| Tinybert (t4-ininy) | 82,8 / 82,9 | 72,7 / 82,1 | - |
Наши результаты:
| Модель (наша) | Mnli | Отряд | Conll-2003 |
|---|---|---|---|
| Берт-базовый (учитель) | 83,7 / 84,0 | 81,5 / 88,6 | 91.1 |
| Бигру | - | - | 85,3 |
| T6 | 83,5 / 84,0 | 80,8 / 88.1 | 90.7 |
| T3 | 81,8 / 82,7 | 76,4 / 84,9 | 87.5 |
| T3-Small | 81.3 / 81.7 | 72,3 / 81,4 | 78.6 |
| T4-ininy | 82,0 / 82,6 | 75,2 / 84,0 | 89.1 |
| T12-Nano | 83,2 / 83,9 | 79,0 / 86,6 | 89,6 |
Примечание :
Мы экспериментируем на следующих типичных китайских наборах данных:
| Набор данных | Тип задачи | Метрики | #Тренироваться | #Dev | Примечание |
|---|---|---|---|---|---|
| Xnli | текстовая классификация | Акк | 393K | 2,5k | Китайский перевод версии MNLI |
| LCQMC | текстовая классификация | Акк | 239K | 8,8k | Сопоставление пары с предложением, бинарная классификация |
| CMRC 2018 | Понимание прочитанного | EM/F1 | 10K | 3.4K | Понимание прочитанного прочитанного прочтения |
| DRCD | Понимание прочитанного | EM/F1 | 27K | 3,5k | Понимание прочитанного прочитываемого прочитываемости SPAN (традиционные китайцы) |
| MSRA NER | Маркировка последовательности | F1 | 45к | 3.4K (#Test) | Признание китайцев по имени сущность |
Результаты перечислены ниже.
| Модель | Xnli | LCQMC | CMRC 2018 | DRCD |
|---|---|---|---|---|
| Роберта-WWM-EXT (учитель) | 79,9 | 89.4 | 68,8 / 86,4 | 86,5 / 92,5 |
| T3 | 78.4 | 89,0 | 66,4 / 84,2 | 78.2 / 86.4 |
| T3-Small | 76.0 | 88.1 | 58,0 / 79,3 | 75,8 / 84,8 |
| T4-ininy | 76.2 | 88.4 | 61,8 / 81,8 | 77.3 / 86.1 |
| Модель | Xnli | LCQMC | CMRC 2018 | DRCD | MSRA NER |
|---|---|---|---|---|---|
| Electra-Base (учитель)) | 77.8 | 89,8 | 65,6 / 84,7 | 86,9 / 92,3 | 95.14 |
| Электра-Смалл | 77.7 | 89.3 | 66,5 / 84,9 | 85,5 / 91,3 | 93,48 |
Примечание :
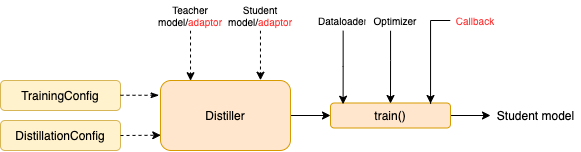
TrainingConfig : конфигурация, связанная с общим обучением модели глубокого обученияDistillationConfig : конфигурация, связанная с методами дистилляцииДистилляторы отвечают за проведение фактических экспериментов. Доступны следующие дистилляторы:
BasicDistiller : однократная дистилляция с одним заданием , обеспечивает основные стратегии дистилляции.GeneralDistiller (рекомендуется): дистилляция одно задания однократного учителя , поддерживает сопоставление промежуточных функций. Рекомендуется большую часть времени .MultiTeacherDistiller : дистилляция с несколькими учителями , которая перегоняет несколько моделей учителей (одинаковой задачи) в одну модель ученика. Этот класс не поддерживает сопоставление промежуточных функций.MultiTaskDistiller : многозадачная дистилляция, которая перегоняет несколько моделей учителей (разных задач) в одного ученика.BasicTrainer : Подготовленная подготовка одной модели на маркированном наборе данных, а не для дистилляции. Это может быть использовано для обучения модели учителя .В TextBrewer есть две функции, которые должны быть реализованы пользователями: обратный вызов и адаптер .
На каждом контрольно -пропускном пункте, после сохранения модели студента, функция обратного вызова будет вызвана дистиллятором. Обратный вызов может быть использован для оценки производительности модели студента на каждом контрольно -пропускном пункте.
Он преобразует входы и выходы модели в указанный формат, чтобы их можно было распознавать дистиллятором, а потери дистилляции могут быть рассчитаны. На каждом этапе обучения выходы партии и модели будут переданы в адаптер; Адаптер реорганизует данные и возвращает словарь.
Для получения более подробной информации см. Объяснения в полной документации.
В : Как инициализировать модель студента?
A : Студенческая модель может быть случайным образом инициализирована (т.е. без предварительного знания) или инициализироваться предварительно обученными весами. Например, при перебоке модели BERT-базы в 3-слойную BERT вы можете инициализировать модель студента с помощью RBT3 (для китайских задач) или первыми тремя уровнями BERT (для английских задач), чтобы избежать проблемы с холодным началом. Мы рекомендуем, чтобы пользователи использовали предварительно обученные модели студентов, когда это возможно, чтобы полностью воспользоваться крупномасштабными предварительными тренировками.
В : Как установить обучение гиперпараметрам для экспериментов по дистилляции?
A : Растилляция знаний обычно требует большего обучения эпохам и большей скорости обучения, чем обучение на маркированном наборе данных. Например, тренировочная команда на BERT-базе обычно занимает 3 эпохи с LR = 3E-5; Однако дистилляция занимает 30 ~ 50 эпох с LR = 1E-4. Выводы основаны на наших экспериментах, и вам рекомендуется попробовать свои собственные данные .
В : Моя модель учителя и модель ученика вносят разные вклад (они не делятся словами), так как же я могу пережить?
A : Вам нужно кормить различные партии учителю и ученику. См. Раздел «Кормление разных партий ученику и учителю», подачи кэшированные значения в полной документации.
В : Я сохранил логиты от моей модели учителя. Могу ли я использовать их в дистилляции, чтобы сохранить время перехода вперед?
A : Да, см. Раздел «Кормление разных партий ученику и учителю», подача кэшированных значений в полной документации.
DataParallel в настоящее время.Если вы обнаружите, что TextBrewer полезен, пожалуйста, цитируйте нашу газету:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}Следуйте нашей официальной учетной записи WeChat, чтобы продолжать обновлять наши последние технологии!



