TextBrewer
TextBrewer 0.2.1
Bahasa Inggris |中文说明

TextBrewer adalah alat distilasi model berbasis pytorch untuk pemrosesan bahasa alami. Ini mencakup berbagai teknik distilasi dari bidang NLP dan CV dan menyediakan kerangka distilasi yang mudah digunakan, yang memungkinkan pengguna untuk dengan cepat bereksperimen dengan metode distilasi canggih untuk mengompres model dengan pengorbanan yang relatif kecil dalam kinerja, meningkatkan kecepatan inferensi dan mengurangi penggunaan memori.
Periksa makalah kami melalui antologi ACL atau pra-cetak ARXIV.
Dokumentasi lengkap
17 Desember 2021
24 Okt 2021
8 Jul 2021
1 Maret 2021
Bert-Emd dan penyuling khusus
Contoh MNLI yang Diperbarui
11 Nov 2020
Diperbarui ke 0.2.1 :
Distilasi yang lebih fleksibel : Mendukung memberi makan batch yang berbeda untuk siswa dan guru. Itu berarti batch untuk siswa dan guru tidak perlu lagi sama. Ini dapat digunakan untuk model penyulingan dengan kosakata yang berbeda (misalnya, dari Roberta ke Bert).
Distilasi yang lebih cepat : Pengguna sekarang dapat pra-komputasi dan menyimpan output guru, kemudian memberi makan cache ke penyuling untuk menghemat waktu lewat guru.
Lihat Feed Batch yang Berbeda untuk Siswa dan Guru, Nilai Feed Daged untuk detail fitur -fitur di atas.
MultiTaskDistiller sekarang mendukung kerugian pencocokan fitur menengah.
Tensorboard sekarang mencatat kerugian yang lebih rinci (kerugian KD, kerugian label keras, kerugian pencocokan ...).
Lihat detail dalam rilis.
27 Agustus 2020
Kami dengan senang hati mengumumkan bahwa model kami ada di atas tolok ukur lem, periksa papan periksa.
24 Agustus 2020
MultiTaskDistiller dan loop pelatihan.29 Jul 2020
DistributedDataParallel : TrainingConfig sekarang mempercepat argumen local_rank . Lihat dokumentasi TrainingConfig untuk detail.14 Jul 2020
fp16 ke True in TrainingConfig . Lihat dokumentasi TrainingConfig untuk detail.data_parallel Opsi yang ditambahkan dalam TrainingConfig untuk memungkinkan pelatihan paralel data dan pelatihan presisi campuran bekerja bersama.26 Apr 2020
22 Apr 2020
17 Maret 2020
11 Mar 2020
2 Maret 2020
| Bagian | Isi |
|---|---|
| Perkenalan | Pengantar TextBrewer |
| Instalasi | Cara menginstal |
| Alur kerja | Dua tahap alur kerja TextBrewer |
| QuickStart | Contoh: Distilling Bert-Base ke Bert 3-lapis |
| Eksperimen | Eksperimen Distilasi pada Dataset Bahasa Inggris dan Cina Khas |
| Konsep inti | Penjelasan singkat tentang konsep inti di TextBrewer |
| FAQ | Pertanyaan yang sering diajukan |
| Masalah yang diketahui | Masalah yang diketahui |
| Kutipan | Kutipan untuk TextBrewer |
| Ikuti kami | - |
TextBrewer dirancang untuk distilasi pengetahuan model NLP. Ini menyediakan berbagai metode distilasi dan menawarkan kerangka kerja distilasi untuk memulai eksperimen dengan cepat.
Fitur utama dari TextBrewer adalah:
TextBrewer saat ini dikirimkan dengan teknik distilasi berikut:
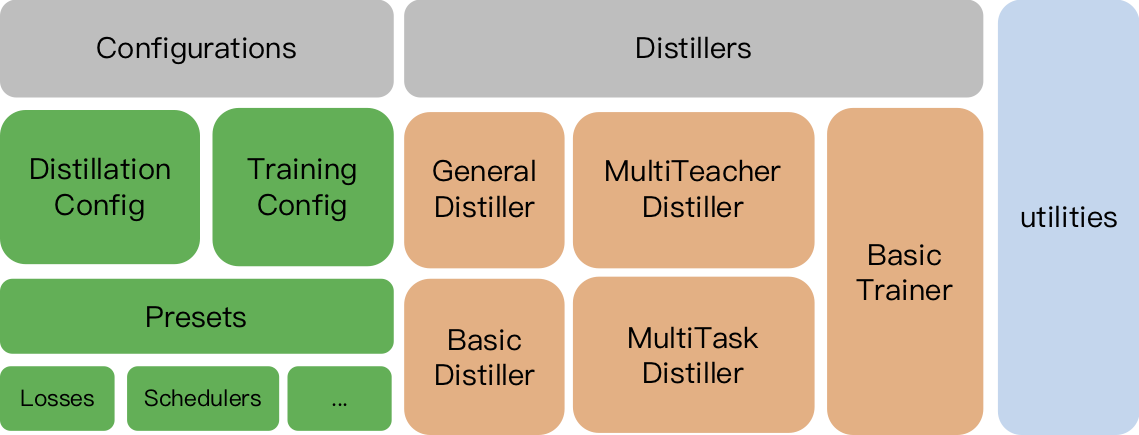
TextBrewer termasuk:
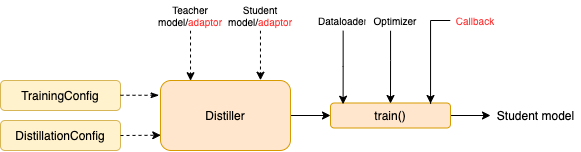
Untuk memulai distilasi, pengguna perlu menyediakan
TextBrewer telah mencapai hasil yang mengesankan pada beberapa tugas NLP yang khas. Lihat Eksperimen.
Lihat dokumentasi lengkap untuk penggunaan terperinci.
Persyaratan
Instal dari PYPI
pip install textbrewerInstal dari sumber GitHub
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer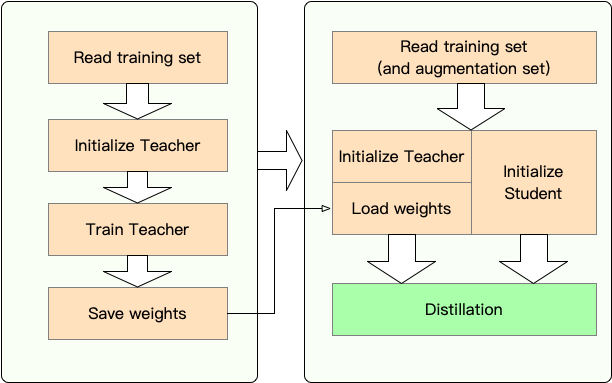
Tahap 1 : Persiapan:
Tahap 2 : Distilasi dengan TextBrewer:
Di sini kami menunjukkan penggunaan TextBrewer dengan menyuling Bert-Base ke Bert 3-layer.
Sebelum distilasi, kami menganggap pengguna telah menyediakan:
teacher_model (Bert-base) dan model siswa yang dilatih student_model (3-layer Bert).dataloader dari dataset, optimizer dan pembangun tingkat pembelajaran atau class scheduler_class dan args -nya dikt scheduler_dict .Distill dengan TextBrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )Contoh notebook dengan Transformers 4
Contoh/acak_token_example: Contoh mainan yang dapat dijalankan sederhana yang menunjukkan penggunaan TextBrewer. Contoh ini melakukan distilasi pada tugas klasifikasi teks dengan token acak sebagai input.
Contoh/CMRC2018_Example (Cina): Distilasi pada CMRC 2018, tugas MRC Cina, menggunakan DRCD sebagai augmentasi data.
Contoh/mnli_example (bahasa Inggris): Distilasi pada MNLI, tugas klasifikasi pasangan kalimat bahasa Inggris. Contoh ini juga menunjukkan cara melakukan distilasi multi-guru.
Contoh/conll2003_example (bahasa Inggris): Distilasi pada CONLL-2003 Tugas Bahasa Inggris Ner, yang dalam bentuk pelabelan urutan.
Contoh/msra_ner_example (Cina): Contoh ini menyaring model basis-elektra Cina pada tugas msra ner dengan pelatihan data-paralel terdistribusi (node tunggal, multi-GPU).
Kami telah melakukan percobaan distilasi pada beberapa dataset NLP bahasa Inggris dan Cina yang khas. Pengaturan dan konfigurasi tercantum di bawah ini.
Kami telah menguji model siswa yang berbeda. Untuk membandingkan dengan hasil publik, model siswa dibangun dengan blok transformator standar kecuali untuk bigru yang merupakan gru dua lapis tunggal. Arsitektur tercantum di bawah ini. Perhatikan bahwa jumlah parameter termasuk lapisan embedding tetapi tidak termasuk lapisan output dari setiap tugas tertentu.
| Model | #Layers | Ukuran tersembunyi | Ukuran feed-forward | #Params | Ukuran relatif |
|---|---|---|---|---|---|
| Bert-Base-Cased (guru) | 12 | 768 | 3072 | 108m | 100% |
| T6 (siswa) | 6 | 768 | 3072 | 65m | 60% |
| T3 (siswa) | 3 | 768 | 3072 | 44m | 41% |
| T3-Small (siswa) | 3 | 384 | 1536 | 17m | 16% |
| T4-Tiny (siswa) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano (siswa) | 12 | 256 | 1024 | 17m | 16% |
| Bigru (siswa) | - | 768 | - | 31m | 29% |
| Model | #Layers | Ukuran tersembunyi | Ukuran feed-forward | #Params | Ukuran relatif |
|---|---|---|---|---|---|
| Roberta-WWM-EXT (guru) | 12 | 768 | 3072 | 102m | 100% |
| Electra-base (guru) | 12 | 768 | 3072 | 102m | 100% |
| T3 (siswa) | 3 | 768 | 3072 | 38m | 37% |
| T3-Small (siswa) | 3 | 384 | 1536 | 14m | 14% |
| T4-Tiny (siswa) | 4 | 312 | 1200 | 11m | 11% |
| Electra-Small (Siswa) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches berbeda untuk model yang berbeda:
| Model | pertandingan |
|---|---|
| Bigru | Tidak ada |
| T6 | L6_hidden_mse + l6_hidden_smmd |
| T3 | L3_hidden_mse + l3_hidden_smmd |
| T3-Small | L3n_hidden_mse + l3_hidden_smmd |
| T4-Tiny | L4t_hidden_mse + l4_hidden_smmd |
| T12-nano | small_hidden_mse + small_hidden_smmd |
| Electra-Small | small_hidden_mse + small_hidden_smmd |
Definisi kecocokan ada di contoh/pertandingan/matches.py.
Kami menggunakan GeneralDistiller dalam semua percobaan distilasi.
Kami bereksperimen pada dataset khas bahasa Inggris berikut:
| Dataset | Jenis tugas | Metrik | #Kereta | #Dev | Catatan |
|---|---|---|---|---|---|
| Mnli | Klasifikasi Teks | M/MM ACC | 393k | 20K | Kalimat Kalimat 3 Klasifikasi Kelas |
| Skuad 1.1 | pemahaman membaca | EM/F1 | 88K | 11k | pemahaman pembacaan mesin span-ekstraksi |
| Conll-2003 | pelabelan urutan | F1 | 23K | 6k | pengakuan entitas yang disebutkan |
Kami mencantumkan hasil publik dari Distilbert, Bert-PKD, Bert-of-Theseus, Tinybert dan hasil kami di bawah ini untuk perbandingan.
Hasil publik:
| Model (publik) | Mnli | Pasukan | Conll-2003 |
|---|---|---|---|
| Distilbert (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| Bert 6 -PKD (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| Bert-of-Theseus (T6) | 82.4/ 82.1 | - | - |
| Bert 3 -pkd (T3) | 76.7 / 76.3 | - | - |
| Tinybert (T4-Tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
Hasil kami:
| Model (milik kami) | Mnli | Pasukan | Conll-2003 |
|---|---|---|---|
| Bert-Base-Cased (guru) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-Small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4-Tiny | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
Catatan :
Kami bereksperimen pada dataset khas Tiongkok berikut:
| Dataset | Jenis tugas | Metrik | #Kereta | #Dev | Catatan |
|---|---|---|---|---|---|
| Xnli | Klasifikasi Teks | ACC | 393k | 2.5K | Versi terjemahan mnli Cina |
| LCQMC | Klasifikasi Teks | ACC | 239k | 8.8k | pencocokan pasangan kalimat, klasifikasi biner |
| CMRC 2018 | pemahaman membaca | EM/F1 | 10K | 3.4k | pemahaman pembacaan mesin span-ekstraksi |
| Drcd | pemahaman membaca | EM/F1 | 27K | 3.5k | pemahaman pembacaan mesin span-ekstraksi (Cina tradisional) |
| MSRA NER | pelabelan urutan | F1 | 45k | 3.4k (#test) | Pengakuan Entitas Nama Cina |
Hasilnya tercantum di bawah ini.
| Model | Xnli | LCQMC | CMRC 2018 | Drcd |
|---|---|---|---|---|
| Roberta-WWM-EXT (guru) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-Small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4-Tiny | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| Model | Xnli | LCQMC | CMRC 2018 | Drcd | MSRA NER |
|---|---|---|---|---|---|
| Electra-base (guru)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electra-Small | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
Catatan :
TrainingConfig : Konfigurasi Terkait dengan Pelatihan Model Pembelajaran Mendalam UmumDistillationConfig : Konfigurasi Terkait dengan Metode DistilasiPenyuling bertugas melakukan percobaan yang sebenarnya. Penyulingan berikut tersedia:
BasicDistiller : Distilasi tugas tunggal guru tunggal , memberikan strategi distilasi dasar.GeneralDistiller (Direkomendasikan): Distilasi tugas tunggal guru-guru , mendukung pencocokan fitur menengah. Merekomendasikan sebagian besar waktu .MultiTeacherDistiller : Distilasi multi-guru , yang menyaring beberapa model guru (dari tugas yang sama) menjadi model siswa tunggal. Kelas ini tidak mendukung pencocokan fitur perantara.MultiTaskDistiller : Distilasi multi-tugas , yang menyuling beberapa model guru (dari tugas yang berbeda) menjadi satu siswa.BasicTrainer : Pelatihan yang diawasi satu model tunggal pada dataset berlabel, bukan untuk distilasi. Ini dapat digunakan untuk melatih model guru .Di TextBrewer, ada dua fungsi yang harus diimplementasikan oleh pengguna: callback dan adaptor .
Di setiap pos pemeriksaan, setelah menyimpan model siswa, fungsi panggilan balik akan dipanggil oleh penyuling. Panggilan balik dapat digunakan untuk mengevaluasi kinerja model siswa di setiap pos pemeriksaan.
Ini mengonversi input dan output model ke format yang ditentukan sehingga dapat dikenali oleh penyuling, dan kerugian distilasi dapat dihitung. Pada setiap langkah pelatihan, output batch dan model akan diteruskan ke adaptor; Adaptor itu mengatur kembali data dan mengembalikan kamus.
Untuk detail lebih lanjut, lihat penjelasan dalam dokumentasi lengkap.
T : Bagaimana cara menginisialisasi model siswa?
A : Model siswa dapat diinisialisasi secara acak (yaitu, tanpa pengetahuan sebelumnya) atau diinisialisasi dengan bobot pra-terlatih. Misalnya, saat menyaring model BERT-BASE ke Bert 3-layer, Anda dapat menginisialisasi model siswa dengan RBT3 (untuk tugas-tugas Cina) atau tiga lapisan Bert pertama (untuk tugas bahasa Inggris) untuk menghindari masalah awal yang dingin. Kami merekomendasikan agar pengguna menggunakan model siswa pra-terlatih bila memungkinkan untuk sepenuhnya memanfaatkan pra-pelatihan skala besar.
T : Cara mengatur pelatihan hyperparameters untuk percobaan distilasi?
A : Distilasi pengetahuan biasanya membutuhkan lebih banyak zaman pelatihan dan tingkat pembelajaran yang lebih besar daripada pelatihan pada dataset berlabel. Misalnya, skuad pelatihan di BERT-BASE biasanya mengambil 3 zaman dengan LR = 3E-5; Namun, distilasi membutuhkan 30 ~ 50 zaman dengan LR = 1E-4. Kesimpulannya didasarkan pada eksperimen kami, dan Anda disarankan untuk mencoba data Anda sendiri .
T : Model guru dan model siswa saya mengambil input yang berbeda (mereka tidak berbagi kosa kata), jadi bagaimana saya bisa menyaring?
A : Anda perlu memberi makan batch yang berbeda untuk guru dan siswa. Lihat bagian memberi makan batch yang berbeda untuk siswa dan guru, memberi makan nilai -nilai yang di -cache dalam dokumentasi lengkap.
T : Saya telah menyimpan log dari model guru saya. Dapatkah saya menggunakannya dalam penyulingan untuk menghemat waktu lewat ke depan?
A : Ya, lihat bagian ini memberi makan batch yang berbeda untuk siswa dan guru, memberi makan nilai -nilai yang di -cache dalam dokumentasi lengkap.
DataParallel saat ini.Jika Anda menemukan TextBrewer bermanfaat, silakan kutip kertas kami:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}Ikuti akun WeChat resmi kami untuk terus diperbarui dengan teknologi terbaru kami!



