TextBrewer
TextBrewer 0.2.1
Inglês |中文说明

O TextBrewer é um kit de ferramentas de destilação de modelo baseado em Pytorch para processamento de linguagem natural. Ele inclui várias técnicas de destilação do campo PNL e CV e fornece uma estrutura de destilação fácil de usar, que permite que os usuários experimentem rapidamente os métodos de destilação de última geração para comprimir o modelo com um sacrifício relativamente pequeno no desempenho, aumentando a velocidade de inferência e reduzindo o uso da memória.
Verifique nosso artigo através da ACL Anthology ou ARXIV pré-impressão.
Documentação completa
17 de dezembro de 2021
24 de outubro de 2021
8 de julho de 2021
1 de março de 2021
Bert-IMD e destilador personalizado
Exemplo MNLI atualizado
11 de novembro de 2020
Atualizado para 0.2.1 :
Destilação mais flexível : apoia a alimentação de diferentes lotes para o aluno e o professor. Isso significa que os lotes para o aluno e o professor não precisam mais ser os mesmos. Pode ser usado para destilar modelos com diferentes vocabulários (por exemplo, de Roberta a Bert).
Destilação mais rápida : os usuários agora podem pré-computar e armazenar em cache as saídas do professor e, em seguida, alimentam o cache ao destilador para salvar o tempo de passagem para a frente do professor.
Consulte alimentar lotes diferentes para aluno e professor, alimente os valores em cache para obter detalhes dos recursos acima.
MultiTaskDistiller agora suporta perda intermediária de correspondência de recursos.
O Tensorboard agora registra perdas mais detalhadas (perda de kd, perda de etiqueta dura, perdas correspondentes ...).
Veja detalhes em lançamentos.
27 de agosto de 2020
Estamos felizes em anunciar que nosso modelo está no topo da referência de cola, verifique a tabela de classificação.
24 de agosto de 2020
MultiTaskDistiller e de treinamento.29 de julho de 2020
DistributedDataParallel : TrainingConfig agora acessa o argumento local_rank . Consulte a documentação do TrainingConfig para obter detalhes.14 de julho de 2020
fp16 como True no TrainingConfig . Consulte a documentação do TrainingConfig para obter detalhes.data_parallel no TrainingConfig para permitir que o treinamento paralelo de dados e o treinamento de precisão misto trabalhem juntos.26 de abril de 2020
22 de abril de 2020
17 de março de 2020
11 de março de 2020
2 de março de 2020
| Seção | Conteúdo |
|---|---|
| Introdução | Introdução ao TextBrewer |
| Instalação | Como instalar |
| Fluxo de trabalho | Dois estágios do fluxo de trabalho do TextBrewer |
| Investir rápido | Exemplo: destilar Bert-Base para um Bert de 3 camadas |
| Experimentos | Experimentos de destilação em conjuntos de dados típicos em inglês e chinês |
| Conceitos principais | Breves explicações dos conceitos principais em TextBrewer |
| Perguntas frequentes | Perguntas frequentes |
| Questões conhecidas | Questões conhecidas |
| Citação | Citação para TextBrewer |
| Siga -nos | - |
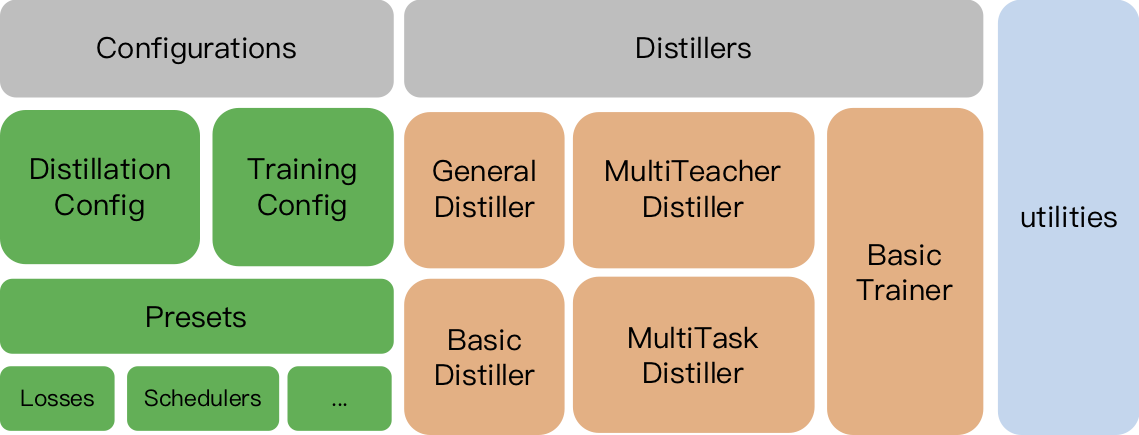
O TextBrewer foi projetado para a destilação do conhecimento dos modelos de PNL. Ele fornece vários métodos de destilação e oferece uma estrutura de destilação para configurar rapidamente experimentos.
As principais características do TextBrewer são:
Atualmente, o TextBrewer é enviado com as seguintes técnicas de destilação:
TextBrewer inclui:
Para iniciar a destilação, os usuários precisam fornecer
A TextBrewer alcançou resultados impressionantes em várias tarefas típicas de PNL. Veja experimentos.
Consulte a documentação completa para obter usos detalhados.
Requisitos
Instale a partir de Pypi
pip install textbrewerInstale a fonte do GitHub
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer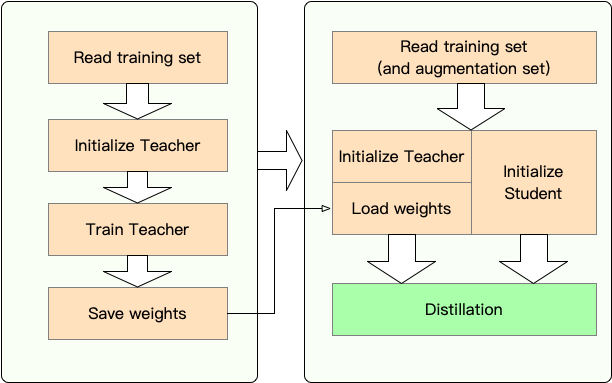
Etapa 1 : Preparação:
Etapa 2 : Destilação com TextBrewer:
Aqui mostramos o uso do TextBrewer destilando Bert-Base em um Bert de 3 camadas.
Antes da destilação, assumimos que os usuários forneceram:
teacher_model (Bert-Base) e um modelo de estudante a ser treinado student_model (Bert de 3 camadas).dataloader do conjunto de dados, um optimizer e um construtor de taxas de aprendizado ou agendamento de classe scheduler_class e seu args dict scheduler_dict .Destilar com textbrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig , DistillationConfig
# Show the statistics of model parameters
print ( " n teacher_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( teacher_model , max_level = 3 )
print ( result )
print ( "student_model's parametrers:" )
result , _ = textbrewer . utils . display_parameters ( student_model , max_level = 3 )
print ( result )
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor ( batch , model_outputs ):
# The second and third elements of model outputs are the logits and hidden states
return { 'logits' : model_outputs [ 1 ],
'hidden' : model_outputs [ 2 ]}
# Training configuration
train_config = TrainingConfig ()
# Distillation configuration
# Matching different layers of the student and the teacher
distill_config = DistillationConfig (
intermediate_matches = [
{ 'layer_T' : 0 , 'layer_S' : 0 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 },
{ 'layer_T' : 8 , 'layer_S' : 2 , 'feature' : 'hidden' , 'loss' : 'hidden_mse' , 'weight' : 1 }])
# Build distiller
distiller = GeneralDistiller (
train_config = train_config , distill_config = distill_config ,
model_T = teacher_model , model_S = student_model ,
adaptor_T = simple_adaptor , adaptor_S = simple_adaptor )
# Start!
with distiller :
distiller . train ( optimizer , dataloader , num_epochs = 1 , scheduler_class = scheduler_class , scheduler_args = scheduler_args , callback = None )Exemplos de notebooks com Transformers 4
Exemplos/Random_Token_Example: Um exemplo de brinquedo simples de execução que demonstra o uso do TextBrewer. Este exemplo executa a destilação na tarefa de classificação de texto com tokens aleatórios como entradas.
Exemplos/CMRC2018_Example (chinês): destilação no CMRC 2018, uma tarefa chinesa MRC, usando o DRCD como aumento de dados.
Exemplos/mnli_example (inglês): Destilação no MNLI, uma tarefa de classificação de pares de frases em inglês. Este exemplo também mostra como executar a destilação de vários professores.
Exemplos/CONLL2003_Example (Inglês): Destilação na tarefa NER ENGLL-2003, que está na forma de marcação de sequência.
Exemplos/msra_ner_example (chinês): Este exemplo destila um modelo chinês-eletrica-base na tarefa do MSRA ner com treinamento paralela de dados distribuído (nó único, multi-GPU).
Realizamos experimentos de destilação em vários conjuntos de dados típicos de NLP em inglês e chinês. As configurações e configurações estão listadas abaixo.
Testamos diferentes modelos de alunos. Para comparar com os resultados do público, os modelos de estudantes são construídos com blocos de transformadores padrão, exceto Bigru, que é um GRU bidirecional de camada única. As arquiteturas estão listadas abaixo. Observe que o número de parâmetros inclui a camada de incorporação, mas não inclui a camada de saída de cada tarefa específica.
| Modelo | #Layers | Tamanho oculto | Tamanho de alimentação | #Params | Tamanho relativo |
|---|---|---|---|---|---|
| Bert-Base (Professor) | 12 | 768 | 3072 | 108m | 100% |
| T6 (aluno) | 6 | 768 | 3072 | 65m | 60% |
| T3 (aluno) | 3 | 768 | 3072 | 44m | 41% |
| T3-Small (aluno) | 3 | 384 | 1536 | 17m | 16% |
| T4 Tiny (estudante) | 4 | 312 | 1200 | 14m | 13% |
| T12-Nano (estudante) | 12 | 256 | 1024 | 17m | 16% |
| Bigru (aluno) | - | 768 | - | 31m | 29% |
| Modelo | #Layers | Tamanho oculto | Tamanho de alimentação | #Params | Tamanho relativo |
|---|---|---|---|---|---|
| Roberta-Wwm-EXT (professor) | 12 | 768 | 3072 | 102m | 100% |
| Electra-Base (professor) | 12 | 768 | 3072 | 102m | 100% |
| T3 (aluno) | 3 | 768 | 3072 | 38m | 37% |
| T3-Small (aluno) | 3 | 384 | 1536 | 14m | 14% |
| T4 Tiny (estudante) | 4 | 312 | 1200 | 11m | 11% |
| Electra-small (aluno) | 12 | 256 | 1024 | 12m | 12% |
distill_config = DistillationConfig ( temperature = 8 , intermediate_matches = matches )
# Others arguments take the default values matches são diferentes para modelos diferentes:
| Modelo | partidas |
|---|---|
| Bigru | Nenhum |
| T6 | L6_hidden_mse + l6_hidden_smmd |
| T3 | L3_hidden_mse + l3_hidden_smmd |
| T3-small | L3n_hidden_mse + l3_hidden_smmd |
| T4 pequeno | L4t_hidden_mse + l4_hidden_smmd |
| T12-NANO | small_hidden_mse + small_hidden_smmd |
| Electra-small | small_hidden_mse + small_hidden_smmd |
As definições de correspondências estão em exemplos/fósforos/fósforos.py.
Utilizamos o GeneralDistiller em todas as experiências de destilação.
Experimentamos os seguintes conjuntos de dados típicos em inglês:
| Conjunto de dados | Tipo de tarefa | Métricas | #Trem | #Dev | Observação |
|---|---|---|---|---|---|
| Mnli | Classificação de texto | m/mm acc | 393k | 20k | Classificação de 3 classes do par de frases |
| Esquadrão 1.1 | compreensão de leitura | Em/F1 | 88k | 11k | Compreensão de leitura da máquina de extração de span |
| CONLL-2003 | marcação de sequência | F1 | 23K | 6k | reconhecimento de entidade nomeado |
Listamos os resultados públicos de Distilbert, Bert-PKD, Bert-of-Teseus, Tinybert e nossos resultados abaixo para comparação.
Resultados do público:
| Modelo (público) | Mnli | Esquadrão | CONLL-2003 |
|---|---|---|---|
| Distilbert (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| Bert 6 -pkd (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| Bert-de-theseus (T6) | 82.4/ 82.1 | - | - |
| Bert 3 -pkd (T3) | 76.7 / 76.3 | - | - |
| Tinybert (T4 Tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
Nossos resultados:
| Modelo (nosso) | Mnli | Esquadrão | CONLL-2003 |
|---|---|---|---|
| Bert-Base (Professor) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| Bigru | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4 pequeno | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-NANO | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
Observação :
Experimentamos os seguintes conjuntos de dados chineses típicos:
| Conjunto de dados | Tipo de tarefa | Métricas | #Trem | #Dev | Observação |
|---|---|---|---|---|---|
| Xnli | Classificação de texto | Acc | 393k | 2.5k | Versão de tradução chinesa do MNLI |
| LCQMC | Classificação de texto | Acc | 239K | 8.8k | Classificação de pares de frases, classificação binária |
| CMRC 2018 | compreensão de leitura | Em/F1 | 10k | 3.4K | Compreensão de leitura da máquina de extração de span |
| Drcd | compreensão de leitura | Em/F1 | 27k | 3,5k | Compreensão de leitura da máquina de extração de span (chinês tradicional) |
| MSRA NER | marcação de sequência | F1 | 45k | 3.4K (#Test) | Reconhecimento de entidade nomeado chinês |
Os resultados estão listados abaixo.
| Modelo | Xnli | LCQMC | CMRC 2018 | Drcd |
|---|---|---|---|---|
| Roberta-Wwm-EXT (professor) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4 pequeno | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| Modelo | Xnli | LCQMC | CMRC 2018 | Drcd | MSRA NER |
|---|---|---|---|---|---|
| Electra-Base (professor)) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electra-small | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
Observação :
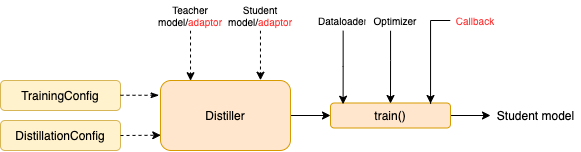
TrainingConfig : Configuração relacionada ao Treinamento do Modelo de Aprendizagem Deep Geral DeepDistillationConfig : Configuração relacionada aos métodos de destilaçãoOs destiladores são responsáveis por conduzir os experimentos reais. Os seguintes destiladores estão disponíveis:
BasicDistiller : A destilação de uma tarefa única única , fornece estratégias básicas de destilação.GeneralDistiller (recomendado): A destilação de uma tarefa única única , suporta a correspondência de recursos intermediários. Recomendou a maior parte do tempo .MultiTeacherDistiller : Destilação de vários professores , que destila vários modelos de professores (da mesma tarefa) em um único modelo de aluno. Esta classe não suporta recursos intermediários correspondentes.MultiTaskDistiller : Destilação de várias tarefas , que destila vários modelos de professores (de tarefas diferentes) em um único aluno.BasicTrainer : Treinamento supervisionado Um modelo único em um conjunto de dados rotulado, não para destilação. Pode ser usado para treinar um modelo de professor .No TextBrewer, existem duas funções que devem ser implementadas pelos usuários: retorno de chamada e adaptador .
Em cada ponto de verificação, depois de salvar o modelo do aluno, a função de retorno de chamada será chamada pelo destilador. Um retorno de chamada pode ser usado para avaliar o desempenho do modelo do aluno em cada ponto de verificação.
Ele converte as entradas e saídas do modelo no formato especificado para que eles possam ser reconhecidos pelo destilador, e as perdas de destilação podem ser calculadas. Em cada etapa de treinamento, saídas em lote e modelo serão passadas para o adaptador; O adaptador reorganiza os dados e retorna um dicionário.
Para mais detalhes, consulte as explicações em documentação completa.
P : Como inicializar o modelo do aluno?
R : O modelo do aluno pode ser inicializado aleatoriamente (ou seja, sem conhecimento prévio) ou ser inicializado por pesos pré-treinados. Por exemplo, ao destilar um modelo Bert-Base em um Bert de 3 camadas, você pode inicializar o modelo do aluno com RBT3 (para tarefas chinesas) ou as três primeiras camadas de Bert (para tarefas em inglês) para evitar problemas de partida a frio. Recomendamos que os usuários usem modelos de alunos pré-treinados sempre que possível para aproveitar completamente o pré-treinamento em larga escala.
P : Como definir hiperparâmetros de treinamento para os experimentos de destilação?
R : A destilação do conhecimento geralmente requer mais épocas de treinamento e maior taxa de aprendizado do que o treinamento no conjunto de dados rotulado. Por exemplo, o esquadrão de treinamento no Bert-Base geralmente leva 3 épocas com LR = 3E-5; No entanto, a destilação leva 30 ~ 50 épocas com LR = 1E-4. As conclusões são baseadas em nossos experimentos e você é aconselhado a experimentar seus próprios dados .
P : Meu modelo de professor e modelo de aluno recebem insumos diferentes (eles não compartilham vocabulários), então como posso destilar?
R : Você precisa alimentar lotes diferentes para o professor e o aluno. Consulte a seção alimentar diferentes lotes para aluno e professor, alimente os valores em cache na documentação completa.
P : Eu armazenei os logits do meu modelo de professor. Posso usá -los na destilação para salvar o tempo de passe para a frente?
R : Sim, consulte a seção alimentar diferentes lotes para o aluno e o professor, alimente os valores em cache na documentação completa.
DataParallel .Se você achar que o TextBrewer é útil, cite nosso papel:
@InProceedings { textbrewer-acl2020-demo ,
title = " {T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing " ,
author = " Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
year = " 2020 " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-demos.2 " ,
pages = " 9--16 " ,
}Siga nossa conta oficial do WeChat para manter -se atualizado com nossas mais recentes tecnologias!



