text_classification
1.0.0
該存儲庫的目的是探索NLP中的文本分類方法,並深入學習。
免費在三分鐘內自定義NLP API,免費:NLP API演示
中文的語言理解評估基準(線索基準):運行10個任務和9個基線,並具有一行代碼,性能比較與詳細信息。
在中國國慶日期間,使用30G+原始的中國語料庫,XXLARGE,XLARGE等釋放預先訓練的Albert_chinese培訓模型,以符合中文,2019- OCT-7的最新表現狀態,以符合中文的最新表現狀態!
提供大量的NLP中國語料庫!
Google的Bert使用語言模型中的Pre-Train在NLP中的10多個任務中實現了新的最新成果
微調。預訓練TEXCNN:來自Bert的想法,用於使用運行代碼和數據集的語言理解
它具有各種用於文本分類的基線模型。
它還支持多標籤分類,其中多標籤與句子或文檔相關聯。
儘管其中許多模型很簡單,並且可能不會讓您達到任務的最高水平。但是其中一些模型非常
經典,因此可以用作基線模型可能很好。每個模型在模型類下都有一個測試功能。你可以運行
它首先執行玩具任務。該模型獨立於數據集。
在此處查看與深度學習的大規模多標籤文本分類的正式報告
這裡的幾種模型也可以用於建模問題答案(有或沒有上下文),也可以用於進行序列生成。
我們探索了兩個SEQ2SEQ模型(您需要的是Transformer注意的SEQ2SEQ)進行文本分類。
而且這兩個模型也可以用於生成和其他任務的序列。如果您的任務是多標籤分類,
您可以將問題投入到序列生成。
我們實現兩個內存網絡。一個是動態內存網絡。以前它已經達到了有關的現狀
回答,情感分析和序列生成任務。這樣被稱為一個模型來執行幾個不同的任務,
並達到高性能。它有四個模塊。關鍵組件是情節內存模塊。它使用門機構
性能關注,並使用蓋特格魯(Gated-gru
性能隱藏狀態更新。它具有進行及物推理的能力。
我們實施的第二個內存網絡是經常性實體網絡:跟踪世界狀態。它有
鑰匙值對作為內存,並並行運行,實現新的先進狀態。它可用於建模問題
用上下文(或歷史)回答。例如,您可以讓模型讀取一些句子(作為上下文),並詢問
問題(作為查詢),然後要求模型預測答案;如果您的故事與查詢相同,那麼它可以做到
分類任務。
要討論ML/DL/NLP問題並獲得彼此的技術支持,您可以加入QQ組:836811304
fastText
textcnn
BERT:深層雙向變壓器的預訓練以了解語言理解
Textrnn
rcnn
分層注意力網絡
seq2seq引起了人們的注意
變壓器(“參加您需要的一切”)
動態內存網絡
實體網絡:跟踪世界狀態
合奏模型
提升:
對於單個模型,將相同的模型堆疊在一起。每一層都是模型。結果將基於添加的邏輯。層之間的唯一連接是標籤的重量。前層的每個標籤的預測錯誤率將成為下一層的重量。這些錯誤率高的標籤將具有很大的重量。因此,後來的一層將更多地關注那些錯誤預測的標籤,並嘗試解決以前層的以前錯誤。結果,我們將獲得一個強大的模型。檢查a00_boosting/boosting.py
和其他模型:
Bilstmtextrelation;
Twocnntextrelation;
Bilstmtextrelationtwornn
(Mulit標籤標籤預測任務,要求預測前5個,300萬培訓數據,完整分數:0.5)
| 模型 | fastText | textcnn | Textrnn | rcnn | Hierattenet | seq2seqattn | EntityNet | 動態信息 | 變壓器 |
|---|---|---|---|---|---|---|---|---|---|
| 分數 | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| 訓練 | 10m | 2H | 10H | 2H | 2H | 3H | 3H | 5H | 7H |
BERT模型在驗證集的前9個時期後達到0.368。
TextCNN,EntityNet,DynamicMemory的合奏:0.411
集合EntityNet,DynamicMemory:0.403
注意:
m站了幾分鐘; h站了幾個小時;
HierAtteNet表示分層注意力網絡;
Seq2seqAttn的意思是seq2seq。
DynamicMemory表示DynamicMemoryNetwork;
Transformer代表模型的“注意力就是您所需要的”。
xxx_model.py中xxx_train.py訓練模型xxx_predict.py進行推理(測試)。每個模型都有模型類下的測試方法。您可以首先運行測試方法,以檢查模型是否可以正常工作。
Python 2.7+ TensorFlow 1.8
(TensorFlow 1.1至1.13也應起作用;大多數模型也應在其他張量Flow版本中正常工作,因為我們
在某些版本中使用很少的功能。
如果您使用Python3,只要您遇到任何錯誤,只要更改打印/嘗試捕獲功能,就可以了。
TextCNN模型已經轉移到Python 3.6
為了幫助您運行此存儲庫,當前我們重新生成培訓/驗證/測試數據和詞彙/標籤,並保存
它們使用H5PY作為緩存文件。我們建議您從上面的鏈接下載它。
它包含運行此存儲庫所需的所有內容:數據已預處理,您可以在一分鐘內開始訓練該模型。
這是一個約1.8克的拉鍊文件,包含300萬個培訓數據。儘管在解開拉鍊後很大,但是在
HDF5,在培訓過程中,僅需要正常的計算機內存(例如或更少)。
我們使用jupyter筆記本:預處理.ipynb進行預處理數據。您可以更好地了解此任務,並且
通過查看數據。您還可以按照自己的方式獨自生成數據,只需更改幾行代碼
使用此Jupyter筆記本。
如果要立即嘗試模型,則可以從上方劃入緩存文件,然後轉到文件夾“ A02_TEXTCNN”,運行
python p7_TextCNN_train.py
它將使用來自緩存文件的數據來訓練模型,並定期打印損失和F1分數。
舊示例數據源:如果您需要在Word2Vec上進行的一些示例數據和單詞嵌入,則可以在封閉的問題中找到它,例如:第3期。
您還可以在文件夾“數據”上找到一些示例數據。它包含兩個文件:“ sample_single_label.txt”,包含50k數據
帶有單標籤; 'sample_multiple_label.txt'包含具有多個標籤的20K數據。輸入和標籤由“標籤”分開。
如果您想了解有關文本分類或任務數據集的更多詳細信息,則可以使用這些模型,其中之一就是以下:
https://biendata.com/competition/zhihu/
您可以使用此存儲庫的一種方法:
步驟1:您可以閱讀本文。您將了解用於進行文本分類的各種經典模型的一般想法。
步驟2:預處理數據和/或下載緩存文件。
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
步驟3:在此處運行一些模型列表,並根據需要更改一些代碼和配置,以獲得良好的性能。
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
此外,寫有關此主題的文章,您可以遵循紙張的樣式寫。您可能需要閱讀一些論文
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
在“ data/sample_multiple_label.txt”中替換數據,並確保格式如下:
'Word1 Word2 Word3 __label__l1 __label __l2 __label __l3'
其中part1:'Word1 Word2 Word3'是輸入(x),part2:'__label__l1 __label __l2 __l2 __label __label__l3'
代表三個標籤:[L1,L2,L3]。在第1部分和第2部分之間,應該有一個空字符串:''。
例如:每行(多個標籤)類似:
'w5466 w138990 w1638 w4301 w6 w470 w202 c1834 c1400 c134 c57 c73 c699 c317 c184 __label__5626661657638885119 __label__4921793805334628695 __LABEL __8904735555009151318'
其中“ 5626661657638885119','4921793805334628695',','8904735555009151318'是與此輸入字符串'W5466 W138990 ...
注意:
data_util.py中的一些util函數;檢查data_util的load_data_multilabel(),以獲取從原始數據中輸入和標籤的方式。
有一個功能可以加載並為模型分配預貼的單詞嵌入,其中word2vec或fastText介紹了單詞嵌入。
如果word2vec.load不起作用,則可以加載驗證的單詞嵌入,特別是對於中文嵌入使用以下行:
導入Gensim
從Gensim.Models導入鍵盤向量
word2vec_model = keyedVectors.load_word2vec_format(word2vec_model_path,binary = true,unicode_errors ='nighore')#
或者,您可以使用將標誌嵌入為false到禁用加載單詞嵌入的fallain Word嵌入。
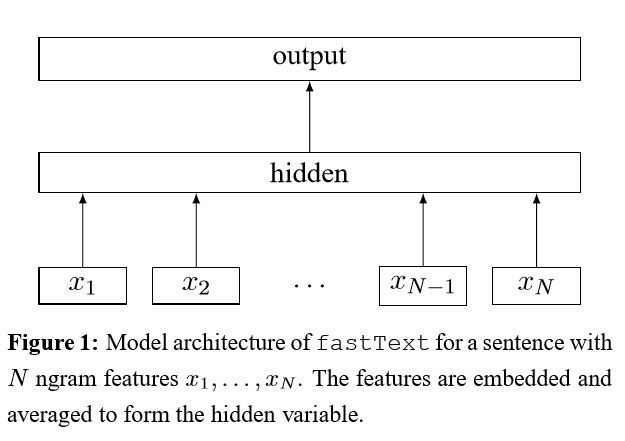
暗示技巧袋,以進行有效的文本分類
將每個單詞嵌入句子中後,然後將該單詞表示形式平均為文本表示形式,而文本表示形式又將其饋送到線性分類器中。 IT使用SoftMax函數來計算預定義類的概率分佈。然後使用熵來計算損失。單詞表示袋不考慮單詞順序。為了考慮單詞順序,n-gram功能用於捕獲有關本地單詞順序的一些部分信息;當類的數量很大時,計算線性分類器的計算昂貴。因此,它使用hhierharchical softmax來加快訓練過程。
結果:性能與紙張一樣好,速度也很快。
檢查:p5_fasttextb_model.py
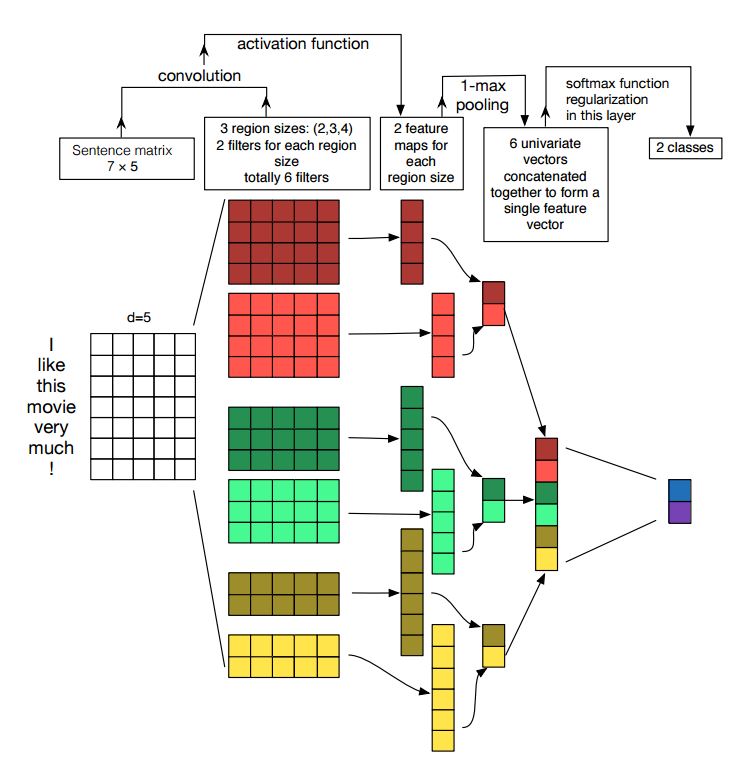
卷積神經網絡的實施句子分類
結構:嵌入---> CONS --->最大池化--->完全連接的圖層--------> SoftMax
檢查:p7_textcnn_model.py
為了通過TextCNN獲得非常好的結果,您還需要仔細閱讀有關本文的敏感性分析(以及從業者的指南)卷積神經網絡進行句子分類:它為您提供了一些可能影響性能的事物的見解。儘管您需要根據特定任務更改某些設置。
卷積神經網絡是用於解決計算機視覺問題的主建築框。現在,我們將展示如何將CNN用於NLP,尤其是文本分類。句子長度從一個到另一個會不同。因此,我們將使用墊子獲得固定長度,n。對於句子中的每個令牌,我們將使用單詞嵌入來獲取固定的尺寸向量,d。因此,我們的輸入是一個2維矩陣:(n,d)。這與CNN的圖像相似。
首先,我們將對輸入進行卷積操作。它是元素的乘積在濾波器和一部分輸入之間乘以。我們使用k數量的過濾器,每個過濾器大小都是2維矩陣(F,d)。現在,輸出將為k列表。每個列表的長度為n-f+1。每個元素都是標量。請注意,第二維將始終是單詞嵌入的維度。我們正在使用不同大小的過濾器來從文本輸入中獲得豐富的功能。這與n-gram功能類似。
其次,我們將對卷積操作的輸出進行最大池。對於k的列表,我們將獲得k數量的標量。
第三,我們將串聯標量形成最終功能。它是固定尺寸的向量。它獨立於我們使用的過濾器的大小。
最後,我們將使用線性層將這些功能投影到人均標籤。
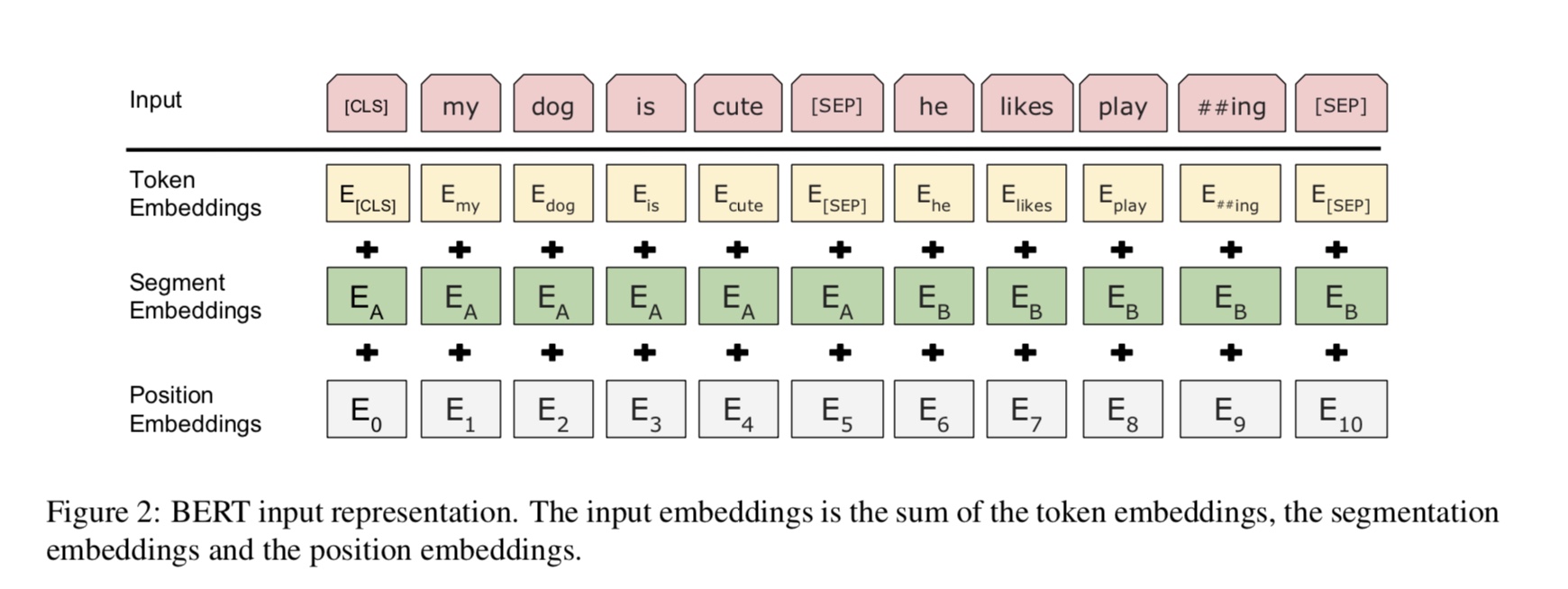
目前,BERT在10個以上的NLP任務上實現了最先進的結果。該模型背後的關鍵思想是我們可以
通過使用具有大量原始數據的一種語言模型來預先訓練模型,您可以輕鬆找到它。
由於該模型的大多數參數都是預訓練的,因此只需要用於分類器的最後一層需要使用不同的任務。
結果,該模型是通用且非常強大的。您可以根據預先訓練的模型進行微調
短時間。
但是,這個模型很大。序列長度為128,您可能只能以32批量的批量訓練;長時間
諸如序列長度512之類的文檔,它只能訓練正常GPU(11克)的批量4;很少有人
可以從頭開始預先訓練該模型,因為訓練需要數天或幾週,而正常的GPU記憶太小
對於此模型。
特別是,骨幹模型是變壓器,您需要在這裡找到它。它使用兩種
預先培訓模型的任務。
一般而言,給定句子,掩蓋了一定比例的單詞,您需要預測掩蓋的單詞
基於這個蒙面的句子。蒙面的單詞被隨機封閉。
我們通過深層變壓器編碼器饋入輸入,然後使用對應於蒙版的最終隱藏狀態
可以預測哪個單詞被掩蓋的位置,就像我們將訓練語言模型一樣。
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
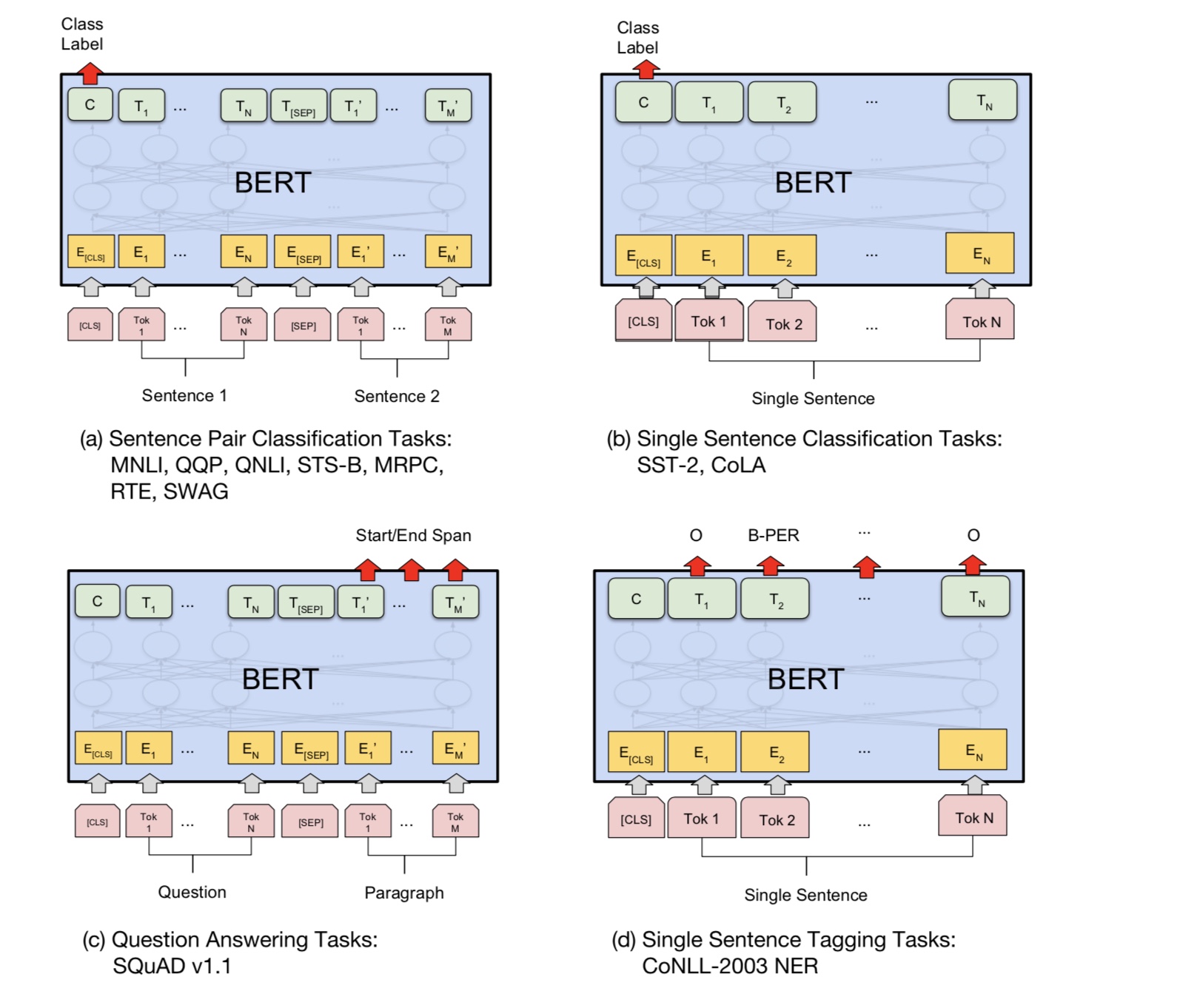
許多語言理解任務,例如問答,推論,需要理解關係
在句子之間。但是,語言模型只能在沒有句子的情況下理解。下一個句子
預測是一項示例任務,可以幫助模型在這類任務中更好地理解。
機會的50%是第二句話的下一個句子,而不是下一個句子的50%。
給定兩個句子,要求該模型預測第二句是否是真實的下一個句子
第一個。
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
基本上,您可以下載預訓練的模型,只能使用自己的數據對您的任務進行微調。
對於分類任務,您可以添加處理器來定義要允許輸入和從源數據標籤的格式。
在文件夾A00_Bert下運行以下命令:
python train_bert_multi-label.py
它在9個時期後達到0.368。或者,您可以使用BERT使用BERT運行多標籤分類
sentiment_analysis_fine_grain帶有bert
您可以使用會話和供稿樣式來恢復模型和供稿數據,然後獲取邏輯以進行在線預測。
用伯特在線預測
最初,它基於文件而不是在線訓練或評估模型。
首先,您可以使用Google的預訓練模型下載。在您的數據集上運行一些時代,並找到合適的
序列長度。
其次,您可以在自己的數據中預先培訓基本模型,只要您找到與
您的任務,然後對您的特定任務進行微調。
第三,您可以更改損失功能和最後一層,以更好地適合您的任務。
此外,您可以添加定義一些預訓練的任務,這些任務將幫助模型更好地了解您的任務。
正如我們從實驗中獲得的那樣,預訓練的任務獨立於模型,並且預訓練並不局限於
上面的任務。
結構V1:嵌入--->雙向LSTM ---> Concat輸出---->平均-----> SoftMax層
檢查:p8_textrnn_model.py
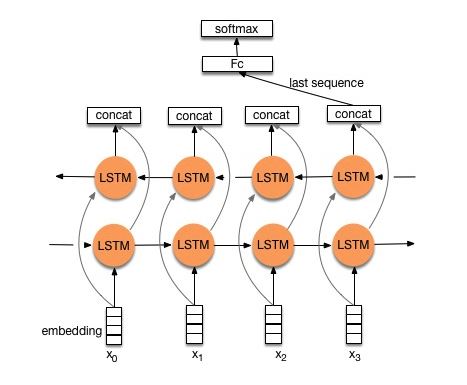
結構V2:嵌入 - >雙向LSTM ---->輟學 - > Concat Ouput ---> lstm ---> lstm ---> droput-> fc layer-> softmax layer
檢查:p8_textrnn_model_multilayer.py
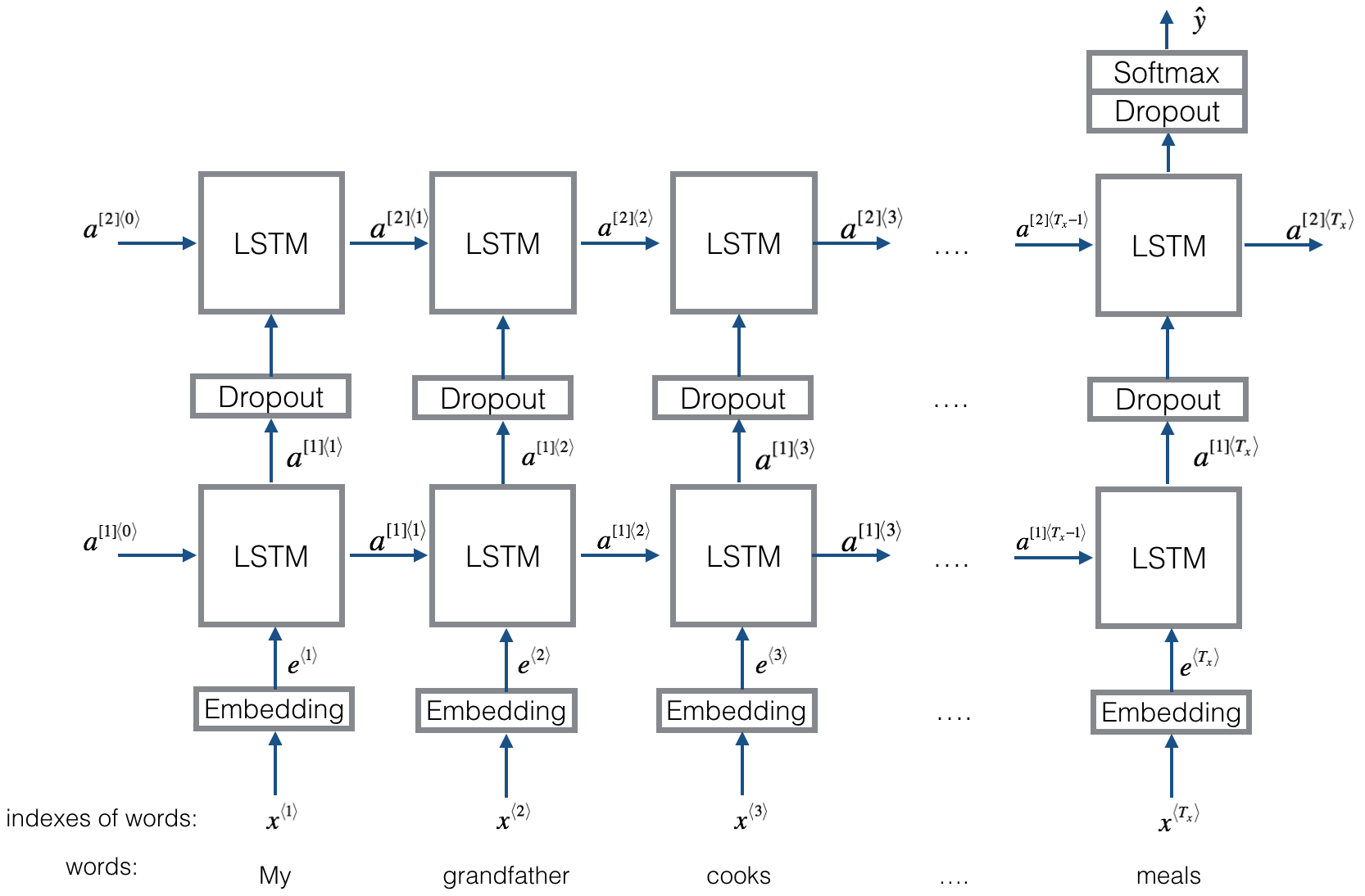
結構與Textrnn相同。但是輸入是特殊設計的。 eginput:“計算機是多少?筆記本電腦的EOS價格”。其中“ eos”是一個特殊的令牌問題1和Question2。
檢查:p9_bilstmtextrelation_model.py
結構:首先使用兩個不同的捲積來提取兩個句子的特徵。然後加入兩個功能。使用線性變換層將投影投影到目標標籤,然後將SoftMax投影。
檢查:p9_twocnntextrelation_model.py
結構:一個句子的一個雙向LSTM(獲取輸出1),另一個句子的另一個雙向LSTM(get Uptown2)。然後:SoftMax(輸出1 M輸出2)
檢查:p9_bilstmtextrelationtwornn_model.py
有關更多詳細信息,您可以轉到:聊天機器人的深度學習,第2部分 - 在TensorFlow中實現基於檢索的模型
用於文本分類的捲積神經網絡
用於文本分類的捲積神經網絡的實施
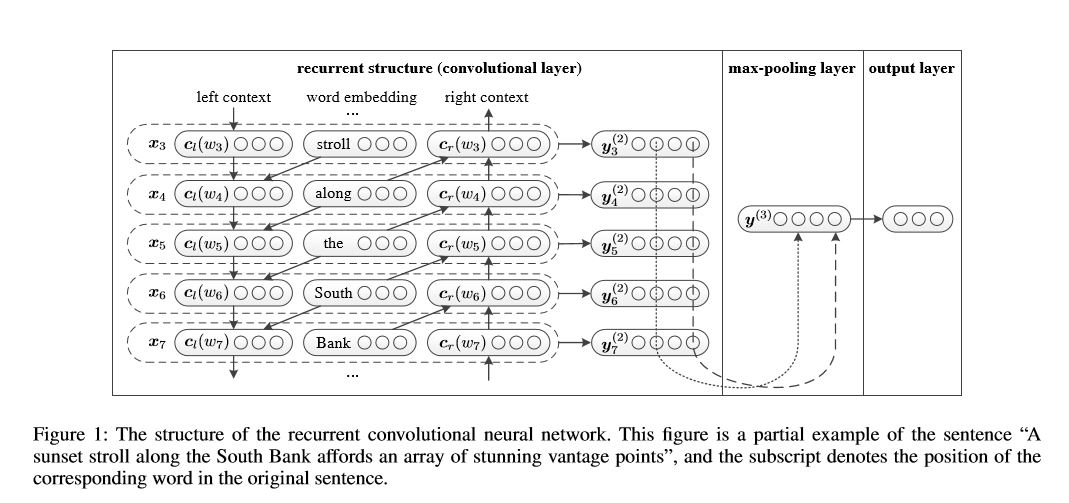
結構:1)經常性結構(卷積層)2)最大池3)完全連接的層+softmax
它在句子或左側上下文中的句子或文檔中學習代表每個單詞:
表示當前詞= [left_side_context_vector,current_word_embedding,right_side_context_vecotor]。
對於左側上下文,它使用經常性結構,是前一個單詞的無線性轉換和左側上下文。類似於右側上下文。
檢查:p71_textrcnn_model.py
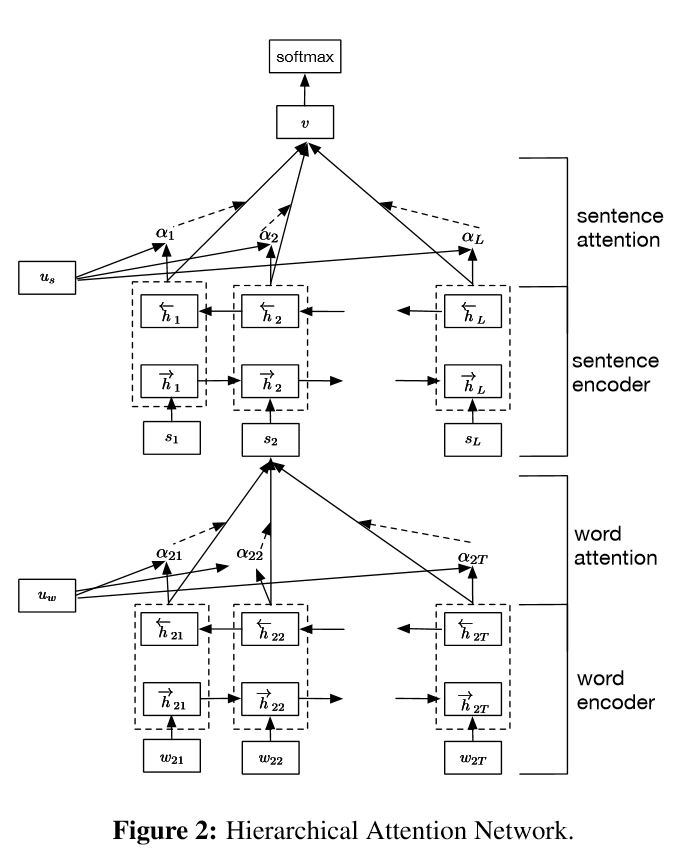
實施用於文檔分類的分層注意網絡
結構:
嵌入
單詞編碼器:單詞級別的雙向gru,以獲取單詞的豐富代表
單詞注意:單詞級別的關注以獲取句子中的重要信息
句子編碼器:句子級別的雙向gru以豐富的句子代表
句子口:句子級別的關注以在句子中獲得重要句子
FC+SoftMax
在NLP中,可以對單句進行文本分類,但也可以用於多個句子。我們可以稱其為文檔分類。單詞是形式的句子。和句子是要記錄的形式。在這種情況下,可能存在一種內在結構。那麼,我們如何對這些任務進行建模呢?文檔的所有部分是否同樣相關?以及我們如何確定哪個部分比另一部分更重要?
它有兩個獨特的功能:
1)它具有層次結構,反映了文檔的層次結構;
2)它在單詞和句子級別上使用了兩個級別的注意機制。它使模型能夠以不同級別捕獲重要信息。
單詞編碼器:對於句子中的每個單詞,它都嵌入分佈向量空間中的單詞向量中。它使用雙向gru來編碼句子。通過來自兩個方向的串聯矢量,它現在可以形成句子的表示,這也可以捕獲上下文信息。
單詞注意:對於句子而言,相同的單詞比另一個更重要。因此使用注意機制。它首先使用一層MLP來獲取句子的隱藏表示形式,然後測量單詞作為UIT與單詞級別上下文vector uw的相似性的重要性,並通過SoftMax函數獲得正常的重要性。
句子編碼器:對於句子向量,雙向gru用於編碼它。類似於Word編碼器。
句子注意:句子級向量用於衡量句子之間的重要性。類似於單詞關注。
數據輸入:
一般而言,此模型的輸入應具有服務器句子而不是Sinle句子。形狀為:[無,句子_lenght]。沒有任何意思是batch_size。
在我的培訓數據中,在每個示例中,我都有四個部分。每個部分的長度相同。我將四個部分圍成一個句子。該模型將將句子分為四個部分,以形成形狀的張量:[none,num_sentence,stone_length]。其中num_sesence是句子的數量(在我的設置中等於4)。
檢查:p1_hierarchicalatetention_model.py
為了細心的關注,您可以檢查專心的關注
實施SEQ2SEQ,通過共同學習對齊和翻譯,從神經機器翻譯中引起了人們的注意
I.結構:
1)嵌入2)Bi-Gru也從源句子(向前和向後)獲得豐富的代表。 3)引起注意的解碼器。
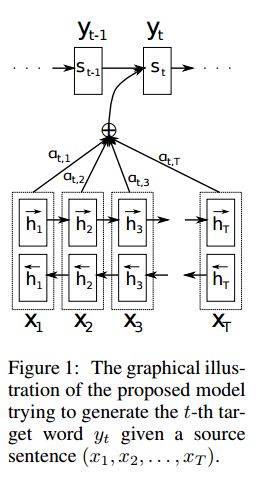
II.數據輸入:
有兩種輸入:1)編碼器輸入,這是一個句子; 2)解碼器輸入,它是具有固定長度的標籤列表; 3)目標標籤,也是標籤列表。
例如,標籤為:“ L1 L2 L3 L4”,然後解碼器輸入為:[_ GO,L1,L2,L2,L2,L3,_PAD];目標標籤將是:[L1,L2,L3,L3,_END,_PAD]。長度固定為6,任何超過的標籤都將被捕捉,如果標籤不足以填充,將墊板。
III。注意機制:
傳輸編碼器輸入列表和解碼器的隱藏狀態
計算隱藏狀態與每個編碼器輸入的相似性,以獲取每個編碼器輸入的可能性分佈。
基於可能性分佈的編碼器輸入的加權總和。
使用此權重總和與解碼器輸入一起使用RNN單元格,以獲取新的隱藏狀態
iv.如何香草編碼器解碼器作品:
源句子將使用RNN作為固定大小向量(“思想向量”)編碼。然後在解碼器中:
當訓練時,將使用另一個RNN嘗試通過使用此“思想向量”作為初始狀態來獲取一個單詞,並在每個時間戳上從解碼器輸入中獲取輸入。解碼器從特殊令牌“ _go”開始。執行一步後,將獲得新的隱藏狀態並與新輸入一起,我們可以繼續此過程,直到達到特殊的令牌“ _end”。我們可以通過計算橫向熵損失和目標標籤來計算損失。 logits通過隱藏狀態的投影層獲得(用於解碼器步驟的輸出(在GRU中,我們可以將隱藏狀態使用解碼器作為輸出)。
測試時,沒有標籤。因此,我們應該為我們從以前的時間戳提供輸出,並繼續我們到達“ _ end”令牌的過程。
v.notices:
在這裡,我使用兩種詞彙。一個來自詞,由編碼器使用;另一個用於標籤,解碼器使用
對於lables的詞彙,我插入了三個特殊令牌:“ _ go”,“ _ end”,“ _ pad”; “ _unk”不使用,因為所有標籤均已預定。
狀態:它能夠進行任務分類。並能夠在玩具任務中生成其序列的反向順序。您可以通過在模型中運行測試功能來檢查它。檢查:a2_train_classification.py(train)或a2_transformer_classification.py(型號)
我們以相相的樣式進行操作。模型中還使用了降落器歸一化,殘留連接和掩碼。
對於每個構建塊,我們在下面的每個文件中都包含一個測試功能,並且我們已經成功測試了每個小部分。
序列序列序列是一個典型的模型,以解決序列產生問題,例如翻譯,對話系統。大多數時候,它使用RNN作為Buidling Block來完成這些任務。 UTIT最近,人們還將捲積神經網絡應用於序列問題。但是,變壓器僅在註意力中心執行這些任務。它是快速的,並實現了新的最新結果。
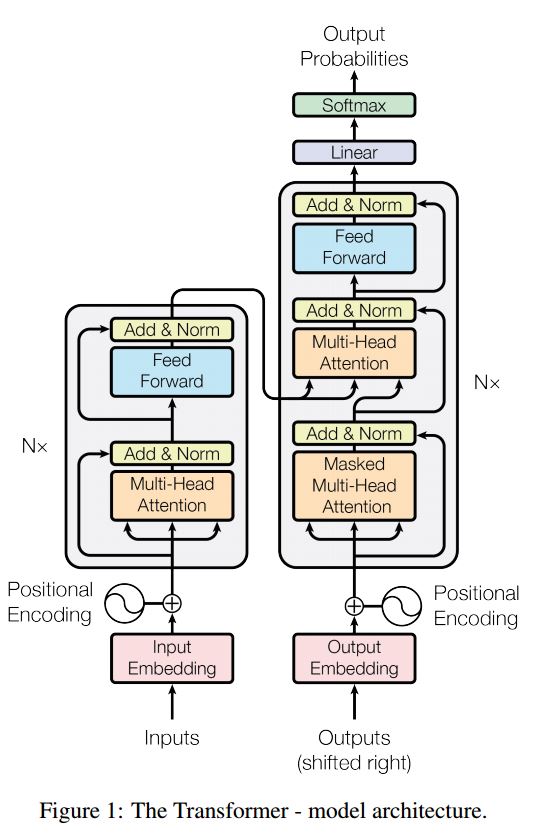
它也有兩個主要部分:編碼器和解碼器。以下是紙上的desc:
編碼器:
6層。每個層有兩個子層。第一個是多頭的自我注意機制。第二個是位置完全連接的前饋網絡。對於每個子層。使用Layernorm(x+sublayer(x))。所有維度= 512。
解碼器:
主要帶走了這個模型:
使用此模型進行任務分類:
在這裡,我們僅使用編碼零件進行任務分類,刪除了Resdiual Connection,僅使用1層。無需使用掩碼。我們使用多頭關注和後饋前進,以提取輸入句子的特徵,然後使用線性層進行投影以獲取邏輯。
有關模型的詳細信息,請檢查:a2_transformer_classification.py
輸入:1。故事:作為上下文是多語言。 2.試驗:一個句子,這是一個問題,3。 Ansewr:一個標籤。
模型結構:
輸入編碼:使用單詞袋來編碼故事(上下文)和查詢(問題);使用位置面具考慮位置
通過使用雙向RNN編碼故事和查詢,性能從0.392提高到0.398,增加了1.5%。
動態內存:
一個。使用鍵的“相似性”來計算門,並帶有故事輸入的值。
b。通過轉換每個密鑰,值和輸入來獲取候選狀態。
c。結合門和候選隱藏狀態以更新當前隱藏狀態。
b。使用可能性分佈獲得隱藏狀態的加權總和。
c。查詢和隱藏狀態的非線性轉換以獲得預測標籤。
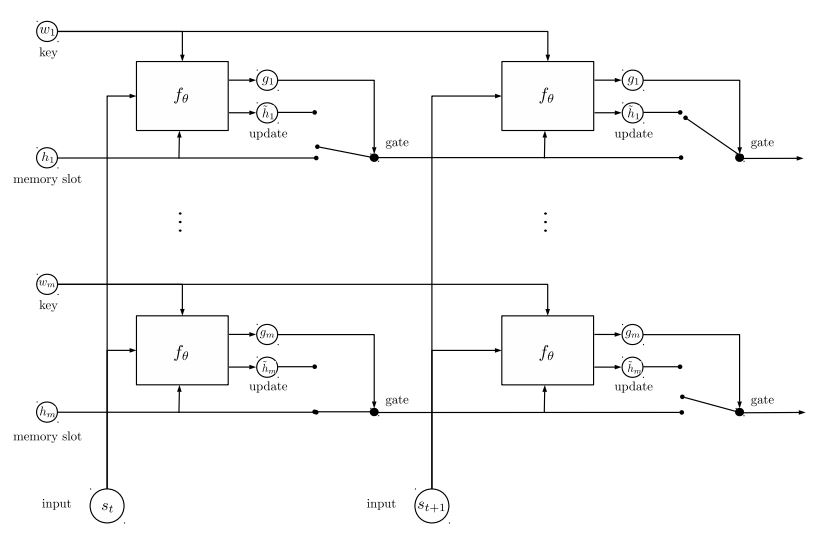
主要帶走了這個模型:
使用彼此獨立的鍵和值塊。因此可以並行運行。
一起建模上下文和問題。使用記憶跟踪世界狀態;並使用隱藏狀態和問題(查詢)的非線性轉換來做出預測。
簡單的模型也可以實現非常好的性能。簡單的編碼用作使用袋。
有關模型的詳細信息,請檢查:a3_entity_network.py
在此模型下,它具有一個測試功能,該功能要求該模型計算故事(上下文)和查詢(問題)的數字。但是故事的重量比查詢小。
模型的前景:
1.輸入模塊:將原始文本編碼為向量表示
2.問題模塊:編碼問題到向量表示
3. episodic內存模塊:使用輸入,它選擇了通過注意機制重點關注的輸入的哪些部分,考慮到問題和先前的內存=====>它使“內存” vecotr調整。
4.答案模塊:從最終內存向量生成答案。
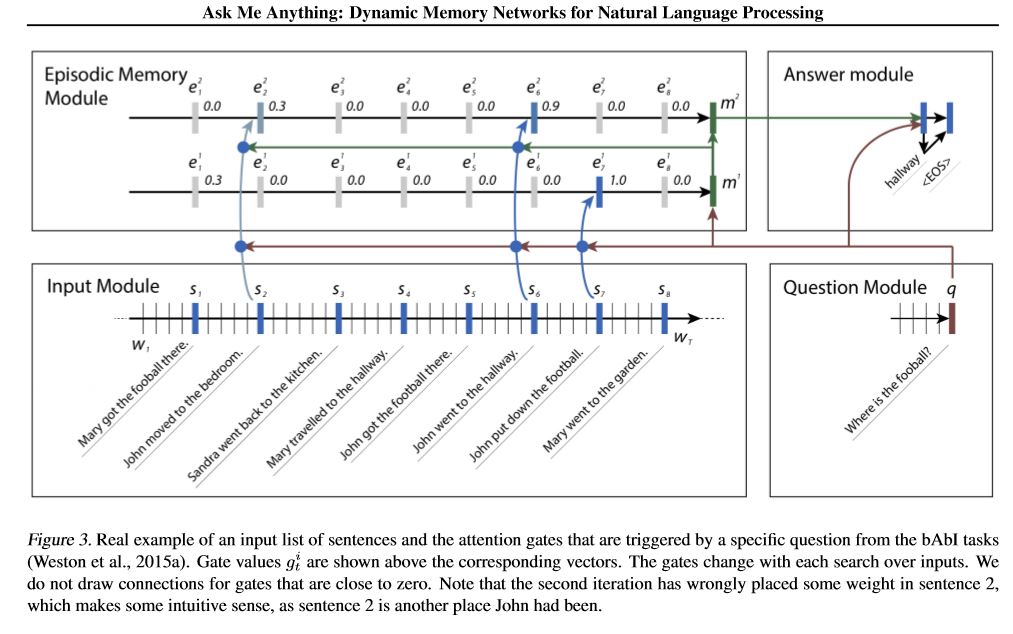
細節:
1.輸入模塊:
A.single句子:使用Gru獲取隱藏狀態B.句子列表:使用Gru為每個句子獲取隱藏狀態。例如[隱藏狀態1,隱藏狀態2,隱藏狀態...,隱藏狀態N]
2.問題模塊:使用gru獲得隱藏狀態
3. Episodic內存模塊:
使用注意機制和經常性網絡來更新其內存。
一個。門作為註意機制:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B.內存更新機制:採用候選句子,門和以前的隱藏狀態,它使用封閉式gu來更新隱藏狀態。喜歡:h = f(c,h_previous,g)。最終隱藏狀態是答案模塊的輸入。
C.需要多個情節===>及時推理。
例如,問足球在哪裡?它將參加“約翰放下足球”的判決),然後在第二次通過,需要參加約翰的位置。
4.答案模塊:採用最終的epoidic內存,問題,它更新隱藏的答案模塊狀態。
1.字符級卷積網絡用於文本分類
2.跨文本分類的捲積神經網絡:淺詞級與深角色級別
3.文本分類的深度卷積網絡
4.半監督文本分類的對流培訓方法
5.啟用模型
在進行大規模多標籤分類的過程中,已經學習了服務器課程,以及某些列表如下:
達到高精度的最重要的是什麼?這取決於您正在執行的任務。從我們在這裡執行的任務中,我們認為,基於從多個功能,字符和描述字符的多個功能訓練的模型的集合模型可以幫助達到很高的Accuarcy;但是,在某些情況下,正如Alphago Zero所證明的那樣,算法比數據或計算能力更重要,實際上Alphago Zero沒有使用任何Humam數據。
是否有任何特定模型或算法的天花板?答案是肯定的。這裡使用了許多不同的模型,我們發現許多模型具有相似的性能,即使結構有很大不同。在某種程度上,性能的差異並不大。
錯誤的案例研究有用嗎?我認為這非常有用,尤其是當您做了許多不同的事情時,但是達到了限制。例如,通過進行案例研究,您可以找到模型可以做出正確預測以及它們犯錯誤的標籤。並通過增加這些錯誤的預測標籤的權重或從數據中找到潛在錯誤來提高性能。
我們如何成為機器學習特定的專家?我認為,加入機器學習競爭對手或使用大量數據開始任務,然後閱讀論文並實施一些是一個很好的起點。因此,我們將有一些真正的經驗和思想來處理特定任務,並知道它的挑戰。但是,更重要的是,我們不僅應該遵循論文的想法,而且應該探索一些我們認為可能有助於解決這個問題的新想法。例如,通過更改經典模型的結構,甚至發明了一些新的結構,我們可能能夠以更好的方式解決問題,因為它可能更適合我們正在執行的任務。
1.有效文本分類的技巧
2.驗證神經網絡用於句子分類
3.(以及實踐指南)卷積神經網絡的敏感性分析句子分類
4.聊天機器人的深度學習,第2部分 - 從www.wildml.com中實現基於檢索的模型
5.文本分類的捲積卷積神經網絡
6.文檔分類的層次結構注意網絡
7.神經機器翻譯通過共同學習對齊和翻譯
8.注意是您需要的
9.掩蓋我任何東西:自然語言處理的動態記憶網絡
10.通過經常性實體網絡跟踪世界狀態
11.從模型庫中選擇
12.Bert:深層雙向變壓器的預訓練以了解語言理解
13.Google-Research/Bert
待續。對於任何問題,conbat [email protected]


