text_classification
1.0.0
Le but de ce référentiel est d'explorer des méthodes de classification de texte dans la PNL avec l'apprentissage en profondeur.
Personnalisez une API NLP en trois minutes, gratuitement: démo API NLP
Compréhension du langage Référence d'évaluation pour chinois (indice de référence): exécutez 10 tâches et 9 lignes de base avec une ligne de code, comparaison des performances avec les détails.
Sortir le modèle pré-formé de la formation Albert_Chinese avec 30 g + Corpus chinois brut, xxlarge, xlarge et plus, cibler pour correspondre à la performance de la pointe en Chine, 2019-oct-7, pendant la Journée nationale de la Chine!
Grande quantité de corpus chinois pour PNL disponible!
Bert de Google a obtenu un nouveau résultat de pointe sur plus de 10 tâches dans la PNL en utilisant le modèle de pré-trains dans le modèle de langage
réglage fin. Texcnn pré-train: idée de Bert pour la compréhension du langage avec le code en cours d'exécution et l'ensemble de données
Il a toutes sortes de modèles de base pour la classification du texte.
Il prend également en charge la classification multi-étiquettes où plusieurs étiquettes s'associent à une phrase ou un document.
Bien que beaucoup de ces modèles soient simples et ne vous amènent pas au niveau supérieur de la tâche. Mais certains de ces modèles sont très
Classic, ils peuvent donc être bons pour servir de modèles de référence. Chaque modèle a une fonction de test sous la classe de modèle. tu peux courir
Il est d'abord de la tâche du jouet de performance. Le modèle est indépendant de l'ensemble de données.
Vérifiez ici le rapport officiel de la classification de texte multi-étiquettes à grande échelle avec apprentissage en profondeur
Plusieurs modèles ici peuvent également être utilisés pour modéliser la réponse aux questions (avec ou sans contexte), ou pour faire des séquences générant.
Nous explorons deux modèles SEQ2SEQ (SEQ2SEQ avec une attention, le transformateur-Attention est tout ce dont vous avez besoin) pour faire la classification du texte.
Et ces deux modèles peuvent également être utilisés pour la génération de séquences et d'autres tâches. Si votre tâche est une classification multi-étiquettes,
Vous pouvez lancer le problème aux séquences générant.
Nous implémentons deux réseau de mémoire. L'un est un réseau de mémoire dynamique. Auparavant, il atteignait l'état de l'art en question
Réponse, analyse des sentiments et tâches de génération de séquences. Il est ainsi appelé un modèle pour effectuer plusieurs tâches différentes,
et atteindre des performances élevées. Il a quatre modules. Le composant clé est le module de mémoire épisodique. il utilise le mécanisme de la porte pour
Attention aux performances et utilisez Gated-Gru pour mettre à jour la mémoire de l'épisode, puis il a un autre GRU (dans une direction verticale) pour
Performance Mise à jour de l'état caché. Il a la capacité de faire une inférence transitive.
Le deuxième réseau de mémoire que nous avons implémenté est le réseau d'entités récurrentes: suivi l'état du monde. il a des blocs de
Les paires de valeurs clés comme mémoire, exécutent en parallèle, qui atteignent un nouvel état d'art. il peut être utilisé pour la question de modélisation
répondre avec des contextes (ou l'histoire). Par exemple, vous pouvez laisser le modèle pour lire certaines phrases (comme contexte) et demander un
Question (en tant que requête), alors demandez au modèle de prédire une réponse; Si vous nourrissez l'histoire identique à la requête, alors il peut faire
tâche de classification.
Pour discuter des problèmes ML / DL / NLP et obtenir un support technologique les uns des autres, vous pouvez rejoindre QQ Group: 836811304
texte rapide
Textcnn
Bert: pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage
Textrnn
RCNN
Réseau d'attention hiérarchique
seq2seq avec attention
Transformateur ("Assister est tout ce dont vous avez besoin")
Réseau de mémoire dynamique
EntityNetwork: suivi l'état du monde
Modèles d'ensemble
Boosting:
Pour un seul modèle, empilez ensemble des modèles identiques. Chaque couche est un modèle. Le résultat sera basé sur des logits additionnés. La seule connexion entre les couches est le poids de l'étiquette. Le taux d'erreur de prédiction de la couche avant de chaque étiquette deviendra un poids pour les couches suivantes. Ces étiquettes avec un taux d'erreur élevé auront un gros poids. Ainsi, la couche ultérieure accordera plus d'attention à ces étiquettes mal prédirées et tentera de corriger l'erreur précédente de l'ancienne couche. En conséquence, nous obtiendrons un modèle beaucoup solide. Vérifiez a00_boosting / boost.py
et d'autres modèles:
Bilstmtextrelation;
TwocnntExtrelation;
Bilstmtextrelationtwornn
(Tâche de prédiction de l'étiquette de l'étiquette Mulit, demandez à la prédiction TOP5, 3 millions de données de formation, score complet: 0,5)
| Modèle | texte rapide | Textcnn | Textrnn | RCNN | Hiérassette | Seq2seqattn | Entité | Dynamiquemory | Transformateur |
|---|---|---|---|---|---|---|---|---|---|
| Score | 0,362 | 0,405 | 0,358 | 0,395 | 0,398 | 0,322 | 0,400 | 0,392 | 0,322 |
| Entraînement | 10m | 2h | 10h | 2h | 2h | 3h | 3h | 5h | 7h |
Le modèle Bert atteint 0,368 après la première époque de la première époque de l'ensemble de validation.
Ensemble de textcnn, EntityNet, DynamicMemory: 0,411
Ensemble EntityNet, DynamicMemory: 0,403
Avis:
m Tenez des minutes ; h Tenez-vous pendant des heures ;
HierAtteNet signifie un réseau d'attention hiérarchique;
Seq2seqAttn signifie seq2seq avec attention;
DynamicMemory signifie DynamicMemoryNetwork;
Transformer représente le modèle de «l'attention est tout ce dont vous avez besoin».
xxx_model.pyxxx_train.py pour former le modèlexxx_predict.py pour faire l'inférence (test).Chaque modèle a une méthode de test sous la classe de modèle. Vous pouvez d'abord exécuter la méthode de test pour vérifier si le modèle peut fonctionner correctement.
Python 2.7+ Tensorflow 1.8
(TensorFlow 1.1 à 1.13 devrait également fonctionner; la plupart des modèles devraient également fonctionner bien dans une autre version TensorFlow, puisque nous
Utilisez très peu de fonctionnalités liées à une certaine version.
Si vous utilisez Python3, ce sera bien tant que vous modifierez la fonction d'impression / essayez de capter au cas où vous rencontrerez une erreur.
Le modèle textcnn est déjà transfomé à Python 3.6
Pour vous aider à exécuter ce référentiel, nous rénovons actuellement les données de formation / validation / test et le vocabulaire / étiquettes, et enregistré
eux comme fichier de cache à l'aide de H5Py. Nous vous suggérons de le télécharger à partir du lien ci-dessus.
Il contient tout ce dont vous avez besoin pour exécuter ce référentiel: les données sont prétraitées, vous pouvez commencer à former le modèle en une minute.
C'est un fichier zip d'environ 1,8 g, contient 3 millions de données de formation. Bien qu'après décomploter, c'est assez grand, mais avec l'aide de
HDF5, il n'a besoin que d'une taille normale de mémoire d'ordinateur (par exemple) pendant l'entraînement.
Nous utilisons Jupyter Notebook: pré-processus.Ipynb pour prétraiter les données. vous pouvez mieux comprendre cette tâche et
Données en y examinant. Vous pouvez également générer des données par vous-même dans la façon dont votre besoin, il suffit de changer quelques lignes de code
Utilisation de ce cahier Jupyter.
Si vous souhaitez essayer un modèle maintenant, vous pouvez Dowload File Cached Fichier ci-dessus, puis accédez au dossier 'a02_textcnn', exécutez
python p7_TextCNN_train.py
Il utilisera les données des fichiers en cache pour former le modèle, et imprimera la perte et le score F1 périodiquement.
Old Exemple de source de données: Si vous avez besoin de données d'échantillons et d'incorporation de mots par formation sur Word2Vec, vous pouvez les trouver dans des questions fermées, telles que: Numéro 3.
Vous pouvez également trouver des exemples de données dans le dossier "données". Il contient deux fichiers: 'Sample_single_label.txt', contient des données 50K
avec une seule étiquette; «Sample_Multiple_label.txt», contient 20k de données avec plusieurs étiquettes. L'entrée et l'étiquette de sont séparées par " étiquette ".
Si vous souhaitez en savoir plus sur l'ensemble de données de classification ou de tâche de texte, ces modèles peuvent être utilisés, l'un de Choose est ci-dessous:
https://biendata.com/competition/zhihu/
Vous pouvez utiliser ce référentiel:
Étape 1: Vous pouvez lire cet article. Vous aurez une idée générale de divers modèles classiques utilisés pour faire la classification du texte.
Étape 2: Données de prétraitement et / ou télécharger un fichier mis en cache.
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
Étape 3: exécutez certains modèles liste ici et modifiez certains codes et configurations comme vous le souhaitez, pour obtenir de bonnes performances.
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
De plus, écrivez votre article sur ce sujet, vous pouvez suivre le style du papier à écrire. Vous devrez peut-être lire certains articles
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
Remplacez les données dans «Data / Sample_Multiple_label.txt» et assurez-vous que le format ci-dessous:
'word1 word2 word3 __label__l1 __label__l2 __label__l3'
où la partie 1: 'word1 word2 word3' est entrée (x), partie 2: '__label__l1 __label__l2 __label__l3'
Représentant il y a trois étiquettes: [L1, L2, L3]. Entre Part1 et Part2, il devrait y avoir une chaîne vide: ''.
Par exemple: chaque ligne (plusieurs étiquettes) comme:
'W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __Label__562666165763885119 __Label__4921793805334628695 __Label__8904735555009151318 '
où '5626661657638885119', '4921793805334628695' , '8904735555009151318' sont trois labels associés à cette chaîne d'entrée 'W5466 W138990 ... C699 C317 C184'
Avis:
Une fonction util est dans data_util.py; Vérifiez LOAD_DATA_MULTILABEL () de Data_Util pour la façon dont l'entrée et les étiquettes de traitement des données brutes.
Il existe une fonction pour charger et attribuer un mot pré-entraîné incorporer le modèle, où l'intégration des mots est pré-entraînée dans Word2Vec ou FastText.
Si word2Vec.load ne fonctionne pas, vous pouvez charger l'incorporation de mots pré-entraînés, en particulier pour l'incorporation de mots chinois Utilisez les lignes suivantes:
importer gensim
à partir de gensim.models importe des vecteurs clés
word2vec_model = keyedvectors.load_word2vec_format (word2vec_model_path, binary = true, unicode_errors = 'ignore') #
Ou vous pouvez désactiver utiliser un indicateur d'intégration de mot avant dynamisme pour désactiver le chargement des mots incorpore.
IMPLICATION DE SAG DE TOUCHES POUR UNE CLASSIFICATION DE Texte efficace
Après avoir intégré chaque mot dans la phrase, ces représentations de mots sont ensuite moyennées en une représentation de texte, qui est à son tour alimentée en un classificateur linéaire. Ensuite, l'entropie croisée est utilisée pour calculer la perte. Le sac de représentation des mots ne considère pas l'ordre des mots. Afin de tenir compte de l'ordre des mots, les fonctionnalités N-gram sont utilisées pour capturer certaines informations partielles sur l'ordre des mots locaux; Lorsque le nombre de classes est important, le calcul du classificateur linéaire est coûteux. Il utilise donc le processus de formation SoftMax pour accélérer.
Résultat: Les performances sont aussi bonnes que le papier, la vitesse également très rapidement.
Vérifier: p5_fastTextB_Model.py
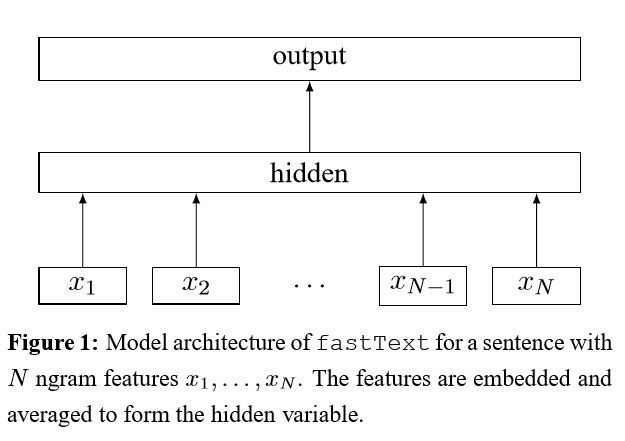
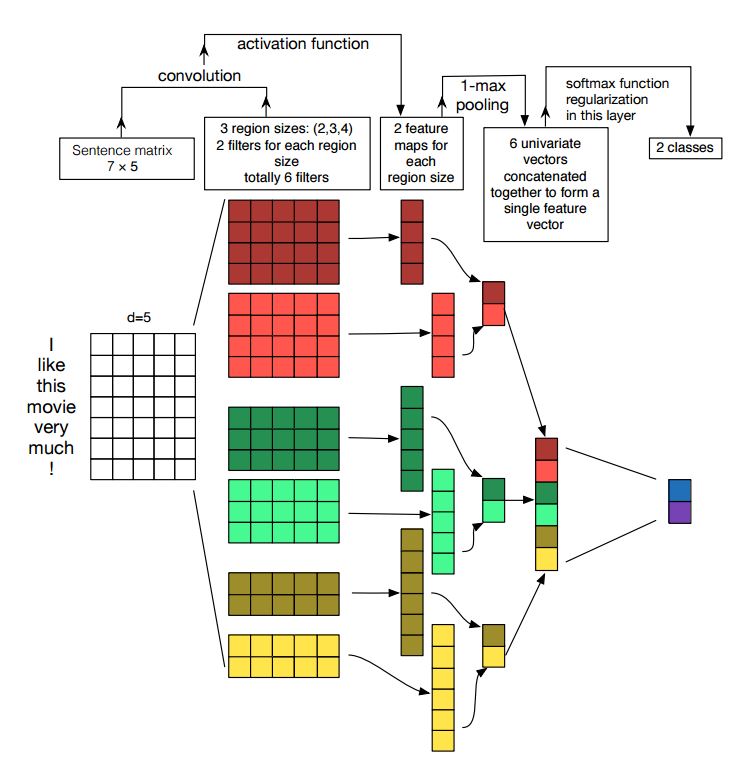
Mise en œuvre de réseaux de neurones convolutionnels pour la classification des phrases
Structure: Incorporation ---> conv ---> Pooling max ---> Couche entièrement connectée --------> Softmax
Vérifier: p7_textcnn_model.py
Afin d'obtenir un très bon résultat avec TextCNN, vous devez également lire attentivement sur cet article une analyse de sensibilité des réseaux de neurones convolutionnels (et des praticiens du Guide des) pour la classification des phrases: il vous donne un aperçu des choses qui peuvent affecter les performances. Bien que vous deviez modifier certains paramètres en fonction de votre tâche spécifique.
Le réseau neuronal convolutionnel est le principal boîtier de construction pour résoudre les problèmes de vision par ordinateur. Nous allons maintenant montrer comment CNN peut être utilisé pour la NLP, en particulier la classification du texte. La durée de la phrase sera différente de l'une à l'autre. Nous allons donc utiliser un pad pour obtenir une longueur fixe, n. Pour chaque jeton de la phrase, nous utiliserons l'intégration de mots pour obtenir un vecteur de dimension fixe, d. Notre entrée est donc une matrice à 2 dimensions: (n, d). Ceci est similaire à l'image pour CNN.
Premièrement, nous ferons un fonctionnement convolutionnel à notre entrée. Il s'agit d'une multiplication par élément entre le filtre et la partie de l'entrée. Nous utilisons K Nombre de filtres, chaque taille de filtre est une matrice à 2 dimensions (F, D). Maintenant, la sortie sera K Nombre de listes. Chaque liste a une longueur de N-F + 1. Chaque élément est un scalaire. Notez que la deuxième dimension sera toujours la dimension de l'intégration des mots. Nous utilisons une taille différente de filtres pour obtenir des fonctionnalités riches des entrées de texte. Et c'est quelque chose de similaire avec les fonctionnalités n-gram.
Deuxièmement, nous ferons un regroupement maximum pour la sortie de l'opération convolutionnelle. Pour le nombre k de listes, nous obtiendrons K nombre de scalaires.
Troisièmement, nous concaterons les scalaires pour former des fonctionnalités finales. Il s'agit d'un vecteur de taille fixe. Et il est indépendant de la taille des filtres que nous utilisons.
Enfin, nous utiliserons la couche linéaire pour projeter ces fonctionnalités sur des étiquettes par définies.
Bert obtient actuellement des résultats de pointe sur plus de 10 tâches NLP. Les idées clés derrière ce modèle est que nous pouvons
Pré-entraînez le modèle en utilisant un type de modèle de langue avec une énorme quantité de données brutes, où vous pouvez la trouver facilement.
Comme la plupart des paramètres du modèle sont pré-formés, seule la dernière couche pour le classificateur doit avoir besoin de différentes tâches.
En conséquence, ce modèle est générique et très puissant. Vous pouvez simplement affiner la base du modèle pré-formé à l'intérieur
une courte période de temps.
Cependant, ce modèle est assez grand. Avec la longueur de séquence 128, vous ne pouvez vous entraîner qu'avec une taille de lot de 32; pour longtemps
Document tel que la longueur de séquence 512, il ne peut entraîner qu'une taille de lot 4 pour un GPU normal (avec 11g); Et très peu de gens
peut pré-entraîner ce modèle à partir de zéro, car il faut plusieurs jours ou semaines pour s'entraîner, et la mémoire d'un GPU normal est trop petite
pour ce modèle.
En particulier, le modèle d'épine dorsale est Transformateur, où vous pouvez le trouver dans l'attention est tout ce dont vous avez besoin. il utilise deux types de
Tâches pour pré-entraîner le modèle.
De manière générale, étant donné une phrase, un certain pourcentage de mots est masqué, vous devrez prédire les mots masqués
basé sur cette phrase masquée. Les mots masqués sont choisis au hasard.
Nous nourrissons l'entrée via un encodeur de transformateur profond, puis utilisons les états finaux cachés correspondant au masqué
Positions pour prédire quel mot était masqué, exactement comme nous pourrions former un modèle de langue.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
De nombreuses tâches de compréhension des langues, comme la réponse aux questions, l'inférence, doivent comprendre la relation
entre la phrase. Cependant, le modèle de langue ne peut comprendre que sans phrase. phrase suivante
La prédiction est un échantillon de tâche pour aider à mieux comprendre ce type de tâche.
50% du hasard, la deuxième phrase est la phrase suivante du premier, 50% de la suivante.
Compte tenu de deux phrases, le modèle est invité à prédire si la deuxième phrase est réelle de la prochaine phrase de
le premier.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
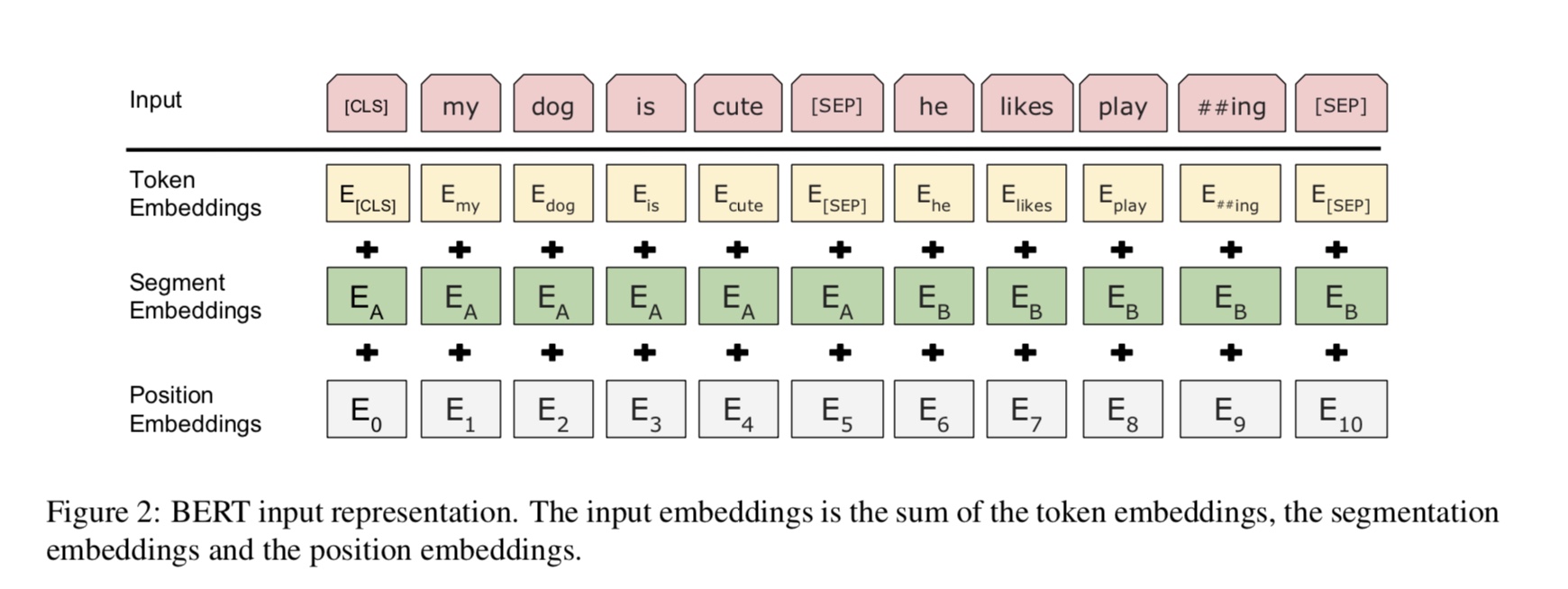
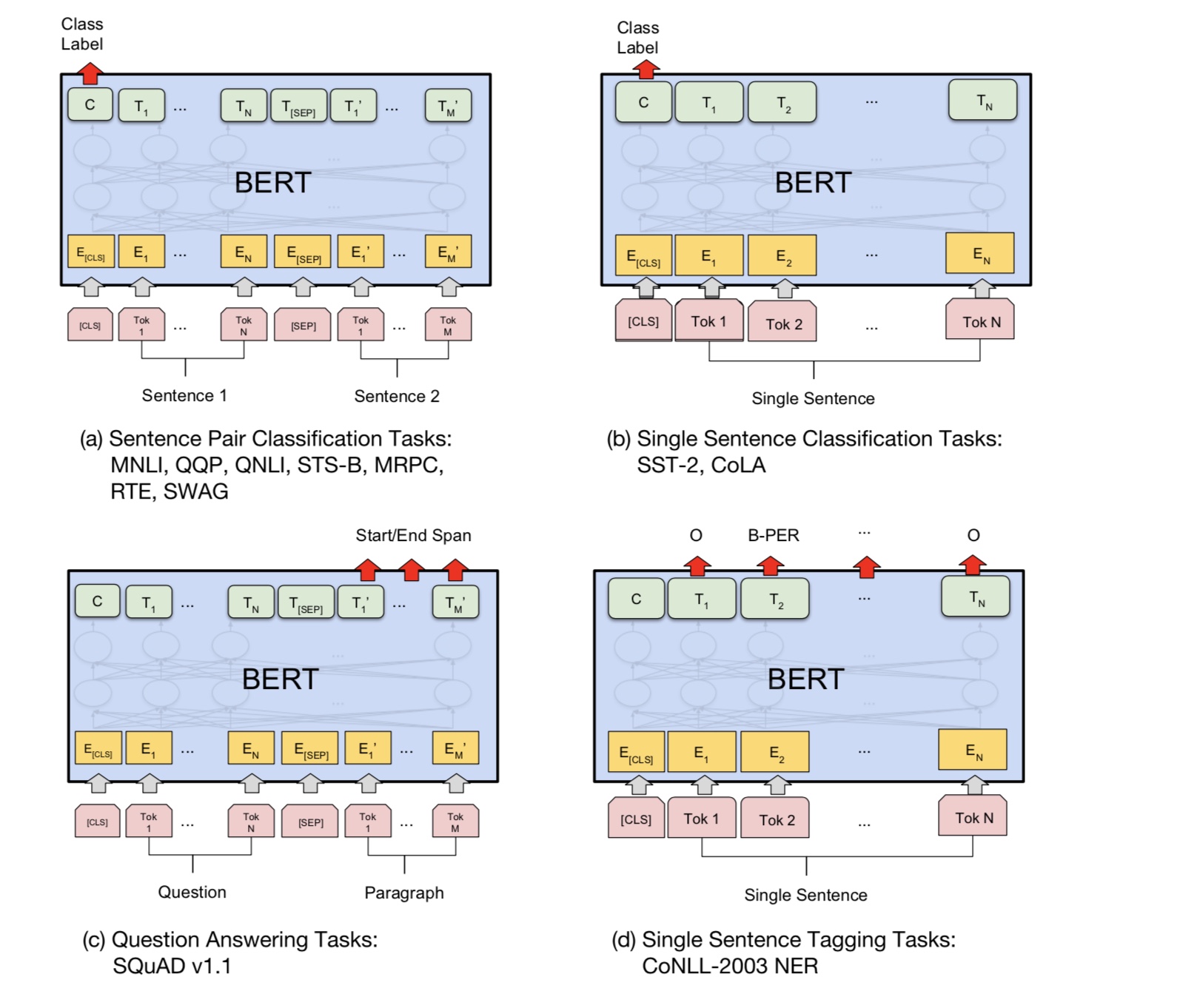
Fondamentalement, vous pouvez télécharger le modèle pré-formé, peut simplement affiner votre tâche avec vos propres données.
Pour la tâche de classification, vous pouvez ajouter du processeur pour définir le format que vous souhaitez laisser entrer les entrées et les étiquettes à partir des données source.
Exécutez la commande suivante dans le dossier a00_bert:
python train_bert_multi-label.py
Il a atteint 0,368 après 9 époques. ou vous pouvez exécuter une classification multi-étiquettes avec des données téléchargeables à l'aide de Bert à partir de
Sentiment_analysis_fine_grain avec Bert
Vous pouvez utiliser le style de session et de nourriture pour restaurer les données du modèle et de la nourriture, puis obtenir des logits pour faire une prédiction en ligne.
Prédiction en ligne avec Bert
À l'origine, il forme ou évalue le modèle en fonction du dossier, pas pour en ligne.
Tout d'abord, vous pouvez utiliser le téléchargement de modèle pré-formé depuis Google. Exécutez quelques époques sur votre ensemble de données et trouvez un
longueur de séquence.
Deuxièmement, vous pouvez pré-entraîner le modèle de base dans vos propres données tant que vous pouvez trouver un ensemble de données lié à
Votre tâche, puis affinez votre tâche spécifique.
Troisièmement, vous pouvez modifier la fonction de perte et la dernière couche pour mieux s'adapter à votre tâche.
De plus, vous pouvez ajouter définir certaines tâches pré-formées qui aideront le modèle à mieux comprendre votre tâche.
Comme nous l'avons vécu d'expériences, la tâche pré-formation est indépendante du modèle et du pré-train n'est pas limitée à
les tâches ci-dessus.
Structure V1: Incorporation ---> LSTM bidirectionnel ---> Sortie concat ---> Moyenne -----> Couche Softmax
Vérifier: p8_textrnn_model.py
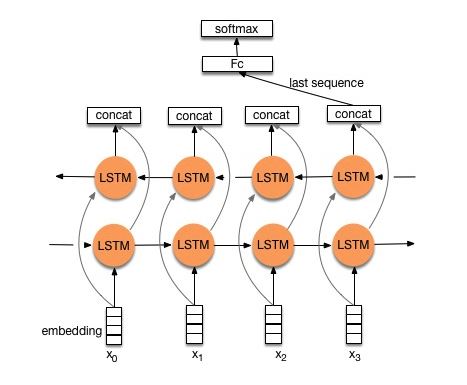
Structure V2: Incorporation -> LSTM bidirectionnel ----> Dropout -> Concat ouput ---> LSTM ---> DOPUT -> FC Couche -> Softmax Couche
Vérifier: p8_textrnn_model_multilayer.py
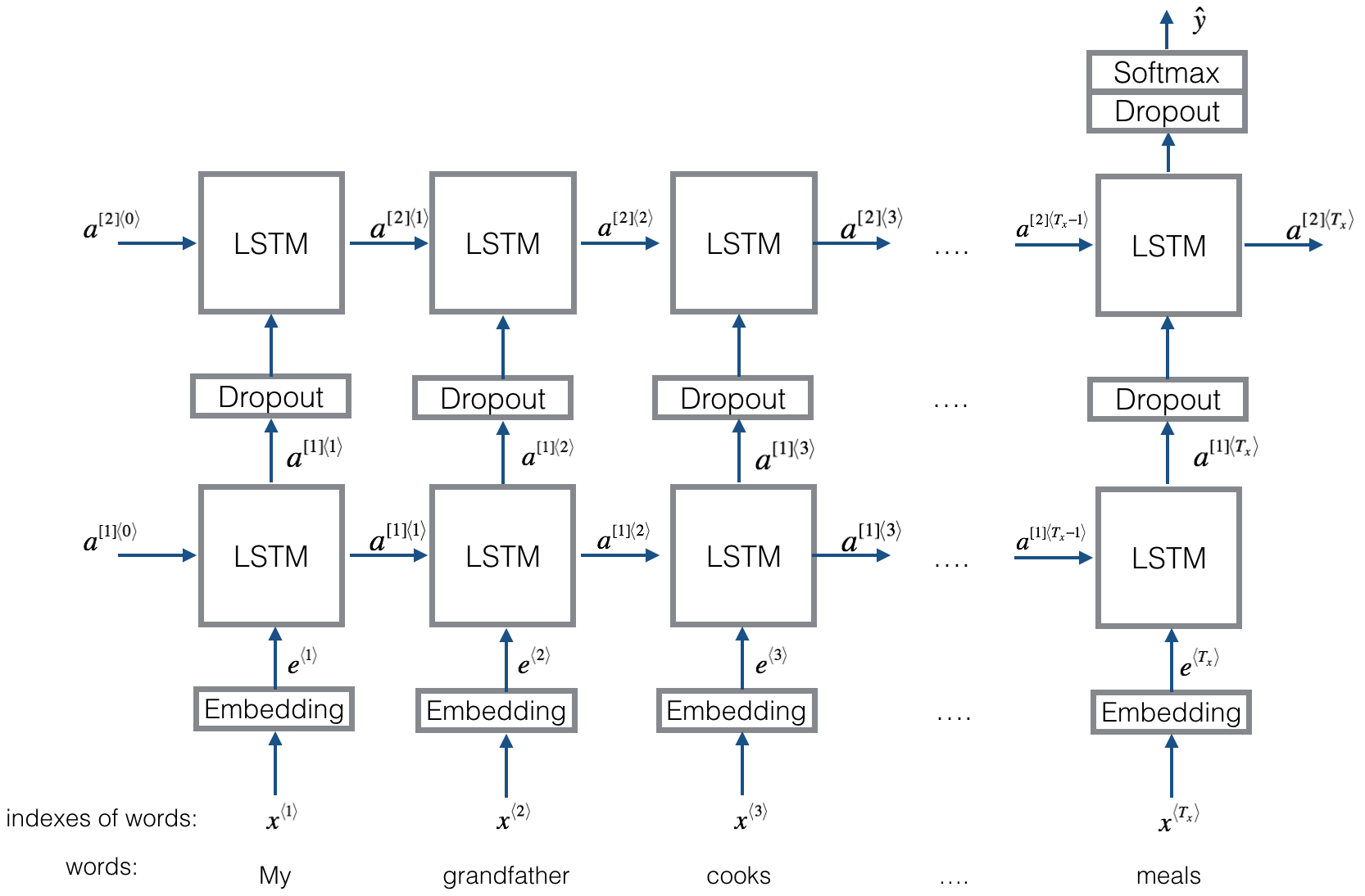
Structure identique à Textrnn. Mais l'entrée est conçue spéciale. Eginput: "Combien coûte l'ordinateur? Eos Prix de l'ordinateur portable". où «EOS» est un jeton spécial repéré la question1 et la question2.
Vérifier: p9_bilstmtextrelation_model.py
Structure: Utilisez d'abord deux caractéristiques convolutionnelles différentes pour extraire de deux phrases. puis concat deux fonctionnalités. Utilisez la couche de transformation linéaire pour sortir la projection en étiquette cible, puis Softmax.
Vérifier: p9_twocntextrelation_model.py
Structure: Un LSTM bidirectionnel pour une phrase (obtenir la sortie1), un autre LSTM bidirectionnel pour une autre phrase (obtenir une sortie2). puis: softmax (sortie 1 m de sortie2)
Vérifier: p9_bilstmtextrelationtwornn_model.py
Pour plus de détails, vous pouvez accéder à: Deep Learning for Chatbots, partie 2 - Implémentation d'un modèle basé sur la récupération dans TensorFlow
Réseau neuronal convolutionnel récurrent pour la classification du texte
Implémentation du réseau neuronal convolutionnel récurrent pour la classification du texte
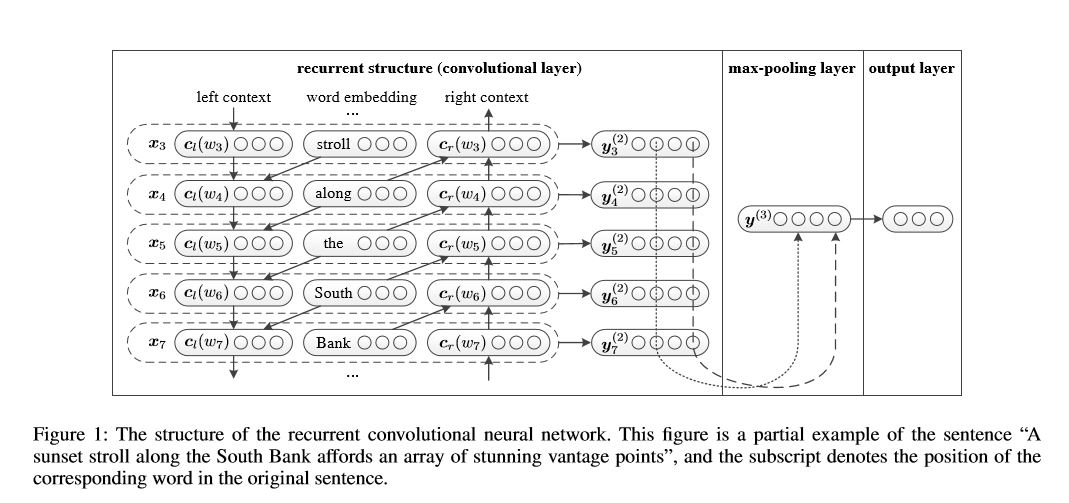
Structure: 1) Structure récurrente (couche convolutionnelle) 2) Poolage maximum 3) Couche entièrement connectée + Softmax
Il apprend la représentation de chaque mot dans la phrase ou le document avec le contexte du côté gauche et le contexte côté droit:
Représentation Current Word = [Left_side_Context_vector, Current_Word_Embedding, droite_side_context_vecotor].
Pour le contexte du côté gauche, il utilise une structure récurrente, une transfrom sans linéarité du mot précédent et du contexte précédent du côté gauche; similaire au contexte du côté droit.
Vérifier: p71_textrcnn_model.py
Implémentation de réseaux d'attention hiérarchiques pour la classification des documents
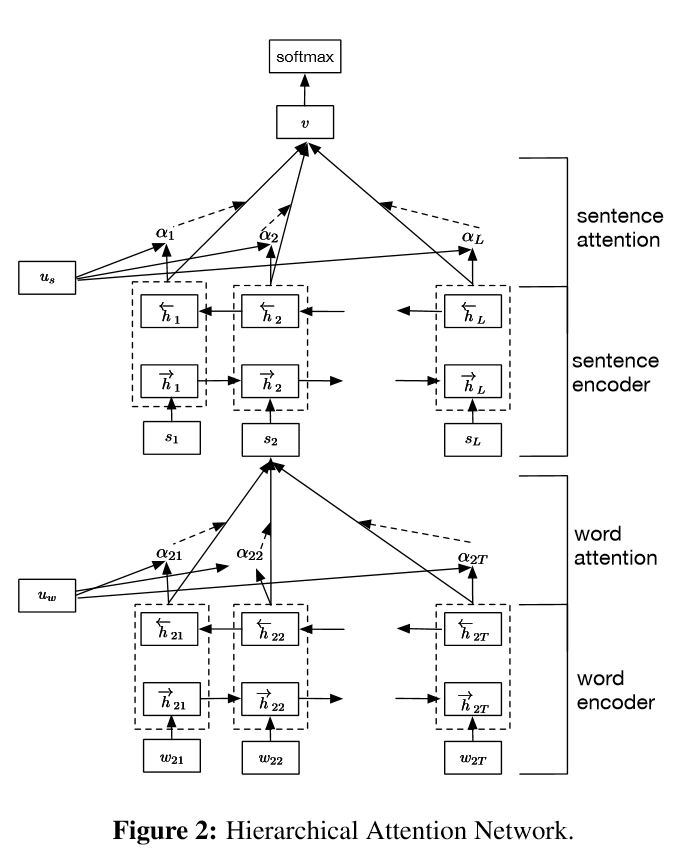
Structure:
intégration
Encodeur de mots: GRU bidirectionnel de niveau de mots pour obtenir une représentation riche des mots
ATTENTION DES MOTS: ATTENTION NIVEAU DE MOTS pour obtenir des informations importantes dans une phrase
Encodeur de phrases: GRU bidirectionnel au niveau de la phrase pour obtenir une représentation riche des phrases
Attétion des phrases: attention au niveau de la phrase pour obtenir une phrase importante parmi les phrases
FC + softmax
Dans NLP, la classification du texte peut être effectuée pour une phrase unique, mais elle peut également être utilisée pour plusieurs phrases. Nous pouvons l'appeler classification des documents. Les mots sont formés à la phrase. Et la phrase sont formées à documenter. Dans ce cas, il peut exister une structure intrinsèque. Alors, comment pouvons-nous modéliser ce type de tâche? Toutes les parties du document sont-elles également pertinentes? Et comment déterminons-nous quelle partie est la plus importante qu'une autre?
Il a deux fonctionnalités uniques:
1) Il a une structure hiérarchique qui reflète la structure hiérarchique des documents;
2) Il a deux niveaux de mécanismes d'attention utilisés au niveau du mot et de la phrase. Il permet au modèle de capturer des informations importantes à différents niveaux.
Encodeur de mots: Pour chaque mots d'une phrase, il est intégré dans un vecteur de mots dans l'espace vecteur de distribution. Il utilise un GRU bidirectionnel pour coder la phrase. En concaténate Vector de deux directions, il peut désormais former une représentation de la phrase, qui capture également des informations contextuelles.
MOT ATTENTION: Les mêmes mots sont plus importants qu'une autre pour la phrase. Le mécanisme d'attention est donc utilisé. Il utilise d'abord une couche MLP pour obtenir une représentation cachée de la phrase, puis mesurer l'importance du mot comme la similitude de l'UIT avec un vecteur de contexte de niveau de mot UW et obtenir une importance normalisée à travers une fonction Softmax.
Encodeur de phrase: Pour les vecteurs de phrase, le GRU bidirectionnel est utilisé pour le coder. Similaire à Word Encodeur.
Attention à la phrase: le vecteur au niveau de la phrase est utilisé pour mesurer l'importance des phrases. Similaire à l'attention des mots.
Entrée des données:
D'une manière générale, la saisie de ce modèle devrait avoir des phrases de serveur au lieu d'une phrase Sinle. La forme est: [Aucune, phrase_lenght]. où aucun signifie le lot_size.
Dans mes données de formation, pour chaque exemple, j'ai quatre parties. Chaque pièce a la même longueur. Je concat quatre parties pour former une seule phrase. Le modèle divisera la phrase en quatre parties, pour former un tenseur avec une forme: [Aucun, num_sence, phrase_length]. où num_sence est un nombre de phrases (égal à 4, dans mon contexte).
Vérifier: p1_hierarchicalaTentention_model.py
Pour une attention attentive, vous pouvez vérifier l'attention attentive
Implémentation seq2seq avec l'attention dérivée de la traduction machine neurale en apprenant conjointement à aligner et à traduire
I.structure:
1) Incorporer 2) Bi-gru aussi obtenir une représentation riche des phrases source (avant et arrière). 3) Décodeur avec attention.
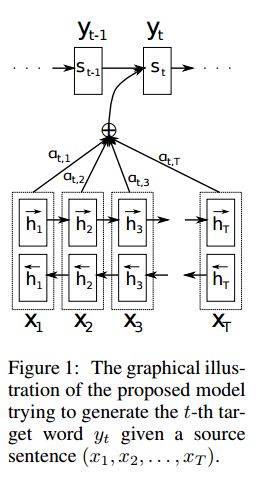
II.Input des données:
Il existe deux types de trois types d'entrées: 1) les entrées d'encodeur, qui est une phrase; 2) Entrées de décodeur, c'est la liste des étiquettes avec une longueur fixe; 3) les étiquettes cibles, c'est aussi une liste des étiquettes.
Par exemple, les étiquettes sont: "L1 L2 L3 L4", alors les entrées de décodeur seront: [_ go, l1, l2, l2, l3, _pad]; L'étiquette cible sera: [l1, l2, l3, l3, _end, _pad]. La longueur est fixée à 6, toutes les étiquettes dépassant seront gravées, se fera un pic si l'étiquette ne suffit pas à remplir.
III. Mécanisme de rétention:
Transférer la liste des entrées de l'encodeur et l'état caché du décodeur
Calculez la similitude de l'état caché avec chaque entrée de codeur, pour obtenir une distribution de possibilités pour chaque entrée de codeur.
somme pondérée de l'apport du codeur basé sur la distribution des possibilités.
Allez à travers la cellule RNN en utilisant cette somme de poids avec l'entrée du décodeur pour obtenir un nouvel état caché
Iv.Comment des travaux de décodeur de codeur de vanille:
La phrase source sera codée à l'aide de RNN comme vecteur de taille fixe ("Vector de pensée"). puis pendant le décodeur:
Lors de la formation, un autre RNN sera utilisé pour essayer d'obtenir un mot en utilisant ce "vecteur de pensée" comme état init, et prendre les commentaires de l'entrée du décodeur à chaque horodatage. Décodeur Commencer à partir de jeton spécial "_go". Une fois une étape interprétée, un nouvel état caché sera obtenu et avec de nouvelles entrées, nous pouvons continuer ce processus jusqu'à ce que nous atteignions un jeton spécial "_end". Nous pouvons calculer la perte en calculant la perte d'entropie croisée des logits et l'étiquette cible. Logits consiste à passer une couche de projection pour l'état caché (pour la sortie de l'étape de décodeur (dans GRU, nous pouvons simplement utiliser les états cachés du décodeur comme sortie).
Quand il est testé, il n'y a pas d'étiquette. Nous devons donc nourrir la sortie que nous obtenons de l'horodatage précédent et continuer le processus Utilité que nous avons atteint le jeton "_end".
V.Notices:
Ici, j'utilise deux types de vocabulaires. L'un provient de mots, utilisé par l'encodeur; Un autre est pour les étiquettes, utilisées par Decoder
Pour le vocabulaire de Lables, j'insère trois jetons spéciaux: "_ go", "_ end", "_ pad"; "_Unk" n'est pas utilisé, car toutes les étiquettes sont prédéfinies.
Statut: il a pu effectuer la classification des tâches. et capable de générer l'ordre inverse de ses séquences dans la tâche du jouet. Vous pouvez le vérifier en exécutant la fonction de test dans le modèle. Vérifier: A2_TRAIN_CLASSIFICATION.PY (Train) ou A2_TRANSFORMER_CLASSIFICATION.PY (modèle)
Nous le faisons dans le style Parallell. La normalisation des lieux, la connexion résiduelle et le masque sont également utilisés dans le modèle.
Pour chaque bloc de construction, nous incluons une fonction de test dans chaque fichier ci-dessous, et nous avons testé chaque petite pièce avec succès.
La séquence à la séquence avec l'attention est un modèle typique pour résoudre le problème de la génération de séquence, tels que Translate, le système de dialogue. La plupart du temps, il utilise RNN comme bloc de BUIDLING pour effectuer ces tâches. Util Récemment, les gens appliquent également un réseau neuronal convolutionnel pour le problème de séquence de séquence. Transformateur, cependant, il effectue ces tâches uniquement sur l'attention mechansim. Il est rapide et atteint un nouveau résultat de pointe.
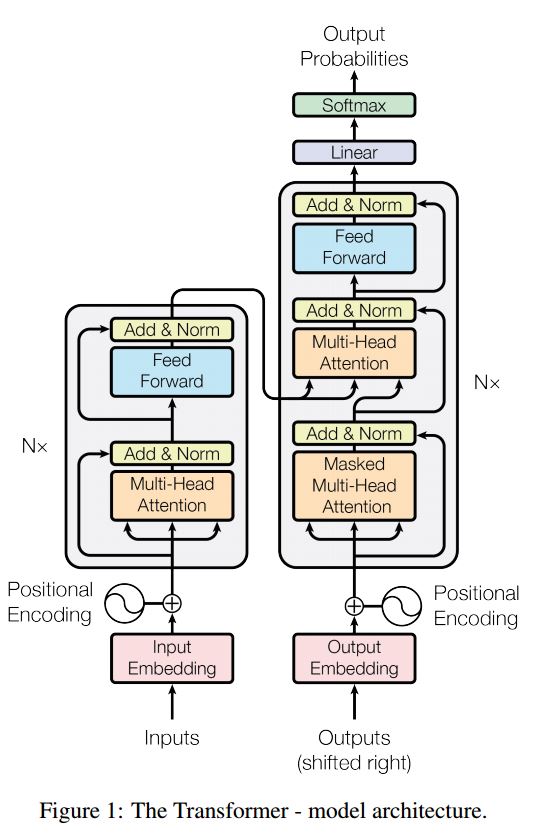
Il a également deux pièces principales: l'encodeur et le décodeur. Ci-dessous, c'est la desc du papier:
Encodeur:
6 couches.Chake couches a deux sous-couches. Le premier est le mécanisme d'auto-atténuer de plusieurs têtes; Le second est le réseau d'alimentation entièrement connecté en fonction de la position. pour chaque sous-couche. Utilisez Layernorm (x + sous-couche (x)). Toute dimension = 512.
Décodeur:
Éloignez-vous de ce modèle:
Utilisez ce modèle pour effectuer la classification des tâches:
Ici, nous utilisons uniquement la pièce d'encodage pour la classification des tâches, supprimé la connexion Resdiuale, utilisé seulement une seule couche. Pas besoin d'utiliser un masque. Nous utilisons l'attention multi-têtes et les alimentations de la possibilité pour extraire les fonctionnalités de la phrase d'entrée, puis utilisons la couche linéaire pour la projeter pour obtenir des logits.
Pour plus de détails sur le modèle, veuillez vérifier: a2_transformer_classification.py
Entrée: 1. Histoire: Ce sont des multisences, comme contexte. 2.Query: une phrase, qui est une question, 3. ANSEWR: une seule étiquette.
Structure du modèle:
Encodage d'entrée: utilisez un sac de mot pour encoder l'histoire (contexte) et la requête (question); tenir compte de la position en utilisant un masque de position
En utilisant un RNN bidirectionnel pour coder l'histoire et la requête, les performances augmentent de 0,392 à 0,398, augmentent 1,5%.
Mémoire dynamique:
un. Calculez la porte en utilisant la «similitude» des clés, valeurs avec entrée d'histoire.
né Obtenez un état caché candidat en transformant chaque clé, valeur et entrée.
c. Combinez une porte et un état caché candidat pour mettre à jour l'état caché actuel.
né Obtenez une somme pondérée de l'état caché en utilisant la distribution des possibilités.
c. Transformée de non-linéarité de la requête et de l'état caché pour obtenir l'étiquette de prédire.
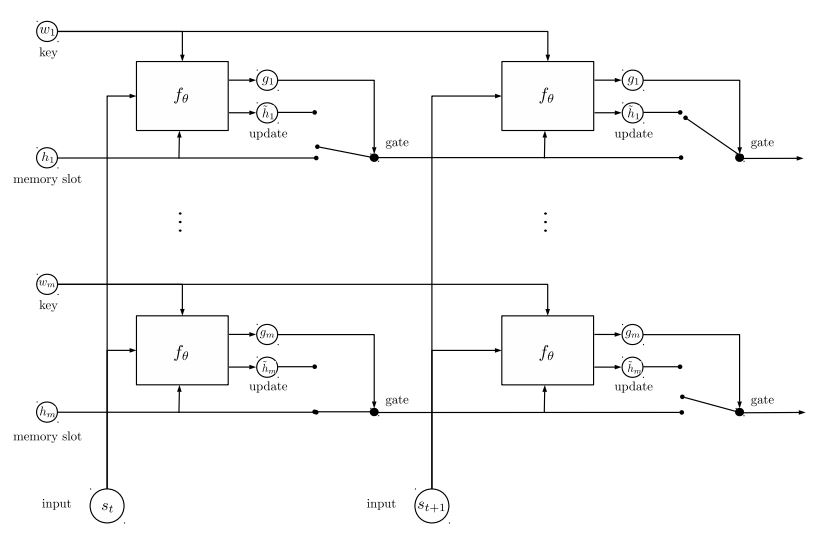
Éloignez-vous de ce modèle:
Utilisez des blocs de clés et de valeurs, qui sont indépendants les uns des autres. Il peut donc être exécuté en parallèle.
modéliser le contexte et les questions ensemble. utiliser la mémoire pour suivre l'état du monde; et utiliser la transformée de non-linéarité de l'état caché et de la question (requête) pour faire une prédiction.
Un modèle simple peut également atteindre de très bonnes performances. Encoder simple comme utilisez un sac de mot.
Pour plus de détails du modèle, veuillez vérifier: a3_entity_network.py
Selon ce modèle, il a une fonction de test, qui demande à ce modèle de compter les nombres à la fois pour l'histoire (contexte) et la question (question). Mais le poids de l'histoire est plus petit que la requête.
Perspectives du modèle:
1. Module à intérêts: coder les textes bruts dans la représentation vectorielle
2. Module de question: coder la question dans la représentation vectorielle
3. Module de mémoire épisodique: Avec les entrées, il choisit les parties des entrées sur lesquelles se concentrer via le mécanisme d'attention, en tenant compte de la question et de la mémoire précédente ===> Il pode un VECOTR de «mémoire».
4. Module de réponse: générez une réponse à partir du vecteur de mémoire final.
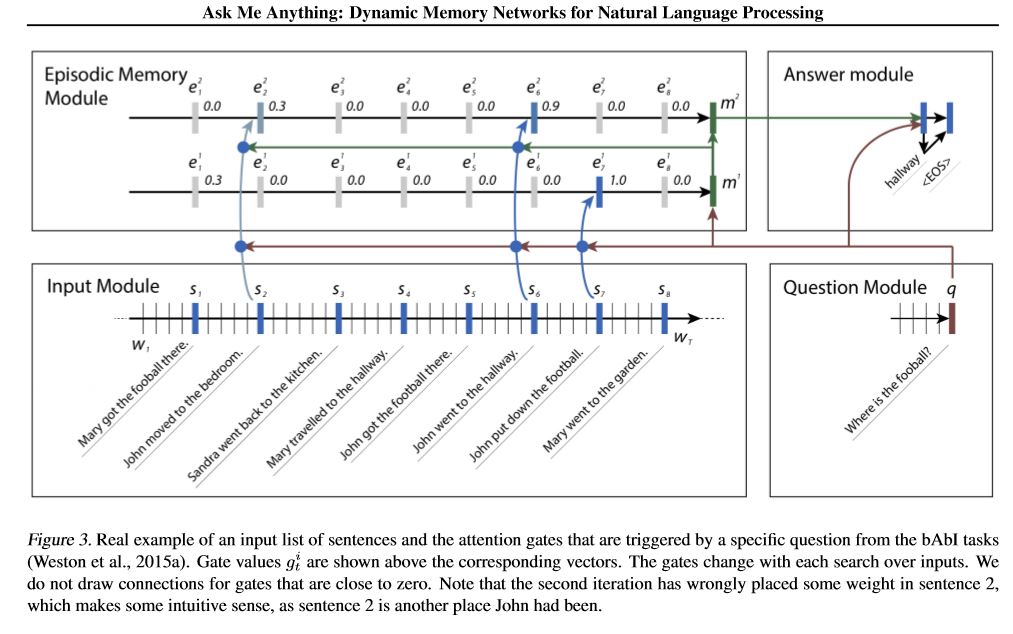
Détail:
1. Module à inscription:
A. phrase systématique: utilisez GRU pour obtenir un état caché B.List de phrases: utilisez GRU pour obtenir les états cachés pour chaque phrase. Par exemple [États cachés 1, États cachés 2, États cachés ..., état caché n]
2. Module de question: utilisez GRU pour obtenir un état caché
3. Module de mémoire épisodique:
Utilisez un mécanisme d'attention et un réseau récurrent pour mettre à jour sa mémoire.
un. Gate comme mécanisme d'attention:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B. Mécanisme de mise à jour de l'amémie: Prenez la phrase candidate, la porte et l'état caché précédent, il utilise Gated-Gru pour mettre à jour l'état caché. Comme: h = f (c, h_previous, g). L'état caché final est le module d'entrée de réponse.
C.Need pour plusieurs épisodes ===> Inférence transitive.
Par exemple, demander où est le football? Il s'occupera de la peine de "John a mis le football"), puis en deuxième passe, il doit assister à l'emplacement de John.
4. Module comprimé: prenez la dernière mémoire epsoidique, question, il met à jour le module de réponse à l'état caché.
1. Réseaux convolutionnels au niveau du caractère pour la classification du texte
2
3.Assurez des réseaux convolutionnels profonds pour la classification du texte
4. Méthodes de formation adverse pour la classification de texte semi-supervisée
5. Modèles d'insensibilité
Pendant le processus de réalisation de la classification multi-étiquettes, des leçons de serveur ont été apprises et une liste ci-dessous:
Quelle est la chose la plus importante pour atteindre une précision élevée? Cela dépend de la tâche que vous faites. D'après la tâche que nous avons menée ici, nous pensons que des modèles d'ensemble basés sur des modèles formés à partir de plusieurs fonctionnalités, notamment des mots, un caractère pour le titre et la description, peuvent aider à atteindre une très grande accurie; Cependant, dans certains cas, comme le l'a démontré Alphago Zero, l'algorithme est plus important que les données ou la puissance de calcul, en fait Alphago Zero n'a utilisé aucune donnée Humam.
Y a-t-il un plafond pour un modèle ou un algorithme spécifique? La réponse est oui. De nombreux modèles différents ont été utilisés ici, nous avons constaté que de nombreux modèles avaient des performances similaires, même s'il existe une structure très différente. Dans une certaine mesure, la différence de performance n'est pas si grande.
L'étude de cas de l'erreur est-elle utile? Je pense que c'est très utile surtout lorsque vous avez fait beaucoup de choses différentes, mais que vous avez atteint une limite. Par exemple, en faisant une étude de cas, vous pouvez trouver des étiquettes que les modèles peuvent faire une prédiction correcte et où ils font des erreurs. Et pour improvenir les performances en augmentant les poids de ces mauvaises étiquettes prédites ou en trouvant des erreurs potentielles à partir des données.
Comment pouvons-nous devenir experts dans un spécifique d'apprentissage automatique? À mon avis, rejoignez une compétition d'apprentissage automatique ou commencez une tâche avec beaucoup de données, puis lisez des articles et en mettant en œuvre, est un bon point de départ. Nous aurons donc une expérience et des idées vraiment sur la gestion d'une tâche spécifique, et en connaître les défis. Mais ce qui est plus important, c'est que nous devons non seulement suivre les idées des articles, mais aussi pour explorer de nouvelles idées que nous pensons peut aider à faire taire le problème. Par exemple, en modifiant les structures de modèles classiques ou même inventer de nouvelles structures, nous pouvons être en mesure de résoudre le problème d'une bien meilleure façon car il peut être plus adapté à la tâche que nous faisons.
1.Bag d'astuces pour une classification de texte efficace
2. Réseaux de neurones Convolutionnels pour la classification des phrases
3.Une analyse de sensibilité du (et du guide des praticiens) Réseaux de neurones convolutionnels pour la classification des phrases
4.Dep Learning for Chatbots, partie 2 - Implémentation d'un modèle basé sur la récupération dans TensorFlow, de www.wildml.com
5. Réseau neuronal convolutionnel
6. Réseaux d'attention de l'hiérarchique pour la classification des documents
7. Traduction machine en apprentissage en apprenant conjointement à aligner et à traduire
8. L'attention est tout ce dont vous avez besoin
9. SALUSEZ-moi n'importe quoi: réseaux de mémoire dynamique pour le traitement du langage naturel
10. Tracking l'état du monde avec des réseaux d'entités récurrents
11.Ensemble Sélection à partir de bibliothèques de modèles
12.bert: pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage
13.google-research / bert
à suivre. Pour tout problème, concat [email protected]


