text_classification
1.0.0
Der Zweck dieses Repositorys besteht darin, die Textklassifizierungsmethoden in NLP mit Deep Learning zu untersuchen.
Passen Sie eine NLP -API in drei Minuten kostenlos an: NLP -API -Demo
Bewertungsbenchmark für Sprachverständnisse für Chinesisch (Hinweis -Benchmark): Führen Sie 10 Aufgaben und 9 Baselines mit einer Codezeile aus, Leistungsvergleich mit Details.
Veröffentlichung des vorgeborenen Modells des Albert_Chinesischen Trainings mit 30G+ RAW Chinese Corpus, XXLarge, Xlarge und mehr, Ziel für die Kunstromplementierung der Kunstromplementierung in Chinesisch, 2019-Oct-7 am Nationalfeiertag Chinas!
Große Menge chinesischer Korpus für NLP verfügbar!
Googles Bert erzielte bei mehr als 10 Aufgaben in NLP ein neues Stand der Technik, unter Verwendung des Sprachmodells Pre-Training
Feinabstimmung. Pre-Train Texcnn: Idee von Bert für Sprachverständnis mit Auslaufcode und Datensatz
Es verfügt über alle möglichen Basismodelle für die Textklassifizierung.
Es unterstützt auch eine Multi-Label-Klassifizierung, bei der Multi-Labels mit einem Satz oder einem Dokument assoziieren.
Obwohl viele dieser Modelle einfach sind und Sie möglicherweise nicht auf die Spitze der Aufgabe bringen. Einige dieser Modelle sind jedoch sehr
Klassiker, also können sie gut als Basismodelle dienen. Jedes Modell verfügt über eine Testfunktion unter der Modellklasse. Sie können rennen
Es ist zuerst zur Performance -Spielzeugaufgabe. Das Modell ist unabhängig vom Datensatz.
Hier finden Sie einen formellen Bericht über die Multi-Label-Textklassifizierung in großem Maßstab mit Deep Learning
Mehrere Modelle können hier auch zur Modellierung von Fragen (mit oder ohne Kontext) oder zur Erzeugung von Sequenzen verwendet werden.
Wir untersuchen zwei SEQ2SEQ-Modell (SEQ2SEQ mit Aufmerksamkeit, Transformator-Beeinträchtigung ist alles, was Sie brauchen), um eine Textklassifizierung durchzuführen.
Und diese beiden Modelle können auch für die Erzeugung von Sequenzen und andere Aufgaben verwendet werden. Wenn Ihre Aufgabe eine Multi-Label-Klassifizierung ist,
Sie können das Problem an Sequenzen erzeugen.
Wir implementieren zwei Speichernetzwerk. Eines ist ein dynamisches Speichernetz. Früher erreichte es den fraglichen Stand der Technik
Beantwortung, Stimmungsanalyse und Sequenzgenerierung Aufgaben. Es ist so genannt ein Modell, mehrere verschiedene Aufgaben zu erledigen.
und hohe Leistung erreichen. Es hat vier Module. Die Schlüsselkomponente ist episodisches Speichermodul. Es verwendet den Gate -Mechanismus, um
Aufmerksamkeitsaufmerksamkeit und verwenden Sie Gated-Gru zum Aktualisieren von Episodengedächtnis
Performance Hidden State Update. Es hat die Fähigkeit, transitive Inferenz zu durchführen.
Das zweite Speichernetzwerk, das wir implementiert haben, ist ein rezidivierendes Entitätsnetzwerk: Verfolgung des Zustands der Welt. es hat Blöcke von
Schlüsselwertpaare als Gedächtnis, parallel laufen und neue Kunststoffe erreichen. Es kann zur Modellierung von Frage verwendet werden
Beantwortung mit Kontexten (oder Geschichte). Zum Beispiel können Sie das Modell zum Lesen einiger Sätze (als Kontext) lassen und a fragen
Frage (als Abfrage) und bitten Sie das Modell, eine Antwort vorherzusagen; Wenn Sie die Geschichte wie die Abfrage füttern, kann dies tun
Klassifizierungsaufgabe.
Um ML/DL/NLP -Probleme zu besprechen und technische Unterstützung voneinander zu erhalten, können Sie sich der QQ Group anschließen: 836811304
FastText
Textcnn
Bert: Vorausbildung von tiefen bidirektionalen Transformatoren für das Sprachverständnis
Textrnn
Rcnn
Hierarchischer Aufmerksamkeitsnetzwerk
SEQ2SEQ mit Aufmerksamkeit
Transformator ("Teilnahme ist alles, was Sie brauchen")
Dynamisches Speichernetzwerk
EntityNetwork: Verfolgung des Zustands der Welt
Ensemble -Modelle
Steigerung:
Stapeln Sie für ein einzelnes Modell identische Modelle zusammen. Jede Schicht ist ein Modell. Das Ergebnis basiert auf Logits, die zusammengefügt wurden. Die einzige Verbindung zwischen Schichten sind die Gewichte von Label. Die Vorhersagefehlerrate der vorderen Schicht jedes Etiketts wird für die nächsten Ebenen zu einem Gewicht. Diese Etiketten mit hoher Fehlerrate haben großes Gewicht. Daher werden die späteren Layer mehr auf diese falsch abgeschlossenen Etiketten aufmerksam machen und versuchen, den vorherigen Fehler der früheren Schicht zu beheben. Infolgedessen erhalten wir ein viel starkes Modell. Überprüfen Sie A00_Boosting/Boosting.py
und andere Modelle:
Bilstmtextrelation;
TWOCNTEXTRELATION;
Bilstmtextrelationtwornn
(Mulit-Label-Etikett-Vorhersage-Aufgabe, fragen Sie nach Vorhersage Top5, 3 Millionen Trainingsdaten, vollständige Punktzahl: 0,5)
| Modell | FastText | Textcnn | Textrnn | Rcnn | Hieratenet | Seq2seqattn | EntityNet | DynamicMemory | Transformator |
|---|---|---|---|---|---|---|---|---|---|
| Punktzahl | 0,362 | 0,405 | 0,358 | 0,395 | 0,398 | 0,322 | 0,400 | 0,392 | 0,322 |
| Ausbildung | 10 m | 2H | 10H | 2H | 2H | 3H | 3H | 5H | 7h |
Das Bert -Modell erreicht 0,368 nach der ersten 9 Epoche aus dem Validierungssatz.
Ensemble von TextCnn, EntityNet, DynamicMemory: 0,411
Ensemble entityNet, DynamicMemory: 0,403
Beachten:
m stehen Sie für Minuten ; h stehen stundenlang ;
HierAtteNet bedeutet hierarchische Aufmerksamkeitsnetzwerke;
Seq2seqAttn bedeutet seq2seq mit Aufmerksamkeit;
DynamicMemory bedeutet DynamicMemoryNetwork;
Transformer Stand für das Modell von "Aufmerksamkeit ist alles, was Sie brauchen".
xxx_model.pyxxx_train.py aus, um das Modell zu trainierenxxx_predict.py aus, um Inferenz zu machen (Test).Jedes Modell verfügt über eine Testmethode unter der Modellklasse. Sie können die Testmethode zuerst ausführen, um zu überprüfen, ob das Modell ordnungsgemäß funktionieren kann.
Python 2.7+ Tensorflow 1.8
(TensorFlow 1.1 bis 1.13 sollte auch funktionieren; die meisten Modelle sollten auch in anderen TensorFlow -Versionen gut funktionieren, da wir
Verwenden Sie nur sehr wenige Funktionen für eine bestimmte Version.
Wenn Sie Python3 verwenden, ist es in Ordnung, solange Sie die Druck-/Fangfunktion ändern, falls Sie einen Fehler erfüllen.
Das Textcnn -Modell ist bereits an Python 3.6 übertragen
Um Ihnen bei der Ausführung dieses Repositorys zu helfen, generieren wir derzeit die Schulungs-/Validierungs-/Testdaten und Vokabeln/Etiketten und gespeichert
sie als Cache -Datei mit H5PY. Wir empfehlen Ihnen, es vom obigen Link herunterzuladen.
Es enthält alles, was Sie zum Ausführen dieses Repositorys benötigen: Daten sind vorverarbeitet. Sie können das Modell in einer Minute trainieren.
Es handelt sich um eine Zip -Datei um 1,8 g, die 3 Millionen Trainingsdaten enthält. Obwohl es nach dem Unzipp ziemlich groß ist, aber mit Hilfe von
HDF5, es erfordert während des Trainings nur eine normale Speicherspeicherungsgröße (z. B. 8 g oder weniger).
Wir verwenden Jupyter Notebook: Pre-Processing.ipynb, um Daten vorzuarbeiten. Sie können diese Aufgabe besser verstehen und
Daten, indem Sie einen Blick darauf werfen. Sie können auch Daten selbst generieren, wie Sie es wünschen, nur wenige Codezeilen ändern
Verwenden Sie dieses Jupyter -Notizbuch.
Wenn Sie jetzt ein Modell ausprobieren möchten, können Sie zwischen oben zwischengespeicherte Dateien mit dem Ordner 'A02_TEXTCNN' ausführen.
python p7_TextCNN_train.py
Es wird Daten von zwischengespeicherten Dateien verwendet, um das Modell zu trainieren, und den Verlust und die F1 -Punktzahl regelmäßig ausdrucken.
Alte Beispieldatenquelle: Wenn Sie einige Beispieldaten und Word-Einbettung pro Ausbildung in Word2VEC benötigen, finden Sie diese in geschlossenen Problemen wie: Ausgabe 3.
Sie können auch einige Beispieldaten im Ordner "Daten" finden. Es enthält zwei Dateien: 'sample_single_label.txt', enthält 50k -Daten
mit einem einzigen Etikett; 'sample_multiple_label.txt' enthält 20K -Daten mit mehreren Beschriftungen. Eingabe und Etikett von ist von " Label " getrennt.
Wenn Sie mehr Details über den Datensatz von Textklassifizierung oder -aufgabe wissen möchten, können diese Modelle verwendet werden, eine der Auswahl ist unten:
https://biendata.com/competition/zhihu/
Eine Möglichkeit, dieses Repository zu verwenden:
Schritt 1: Sie können diesen Artikel durchlesen. Sie erhalten eine allgemeine Vorstellung von verschiedenen klassischen Modellen, die zur Textklassifizierung verwendet werden.
Schritt 2: Daten vor dem Prozess und/oder Download zwischengespeicherte Datei.
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
Schritt 3: Führen Sie hier einige der Modelslisten aus und ändern Sie einige Codes und Konfigurationen, um eine gute Leistung zu erzielen.
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
Schreiben Sie außerdem Ihren Artikel zu diesem Thema, Sie können Papierstil zum Schreiben folgen. Möglicherweise müssen Sie einige Papiere lesen
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
Ersetzen Sie die Daten in 'Data/sample_multiple_label.txt' und stellen Sie sicher, dass das Format wie unten:
'Word1 Word2 Word3 __label__l1 __label__l2 __label__l3'
wobei Teil1: 'Word1 Word2 Word3' eingibt (x), part2: '__label__l1 __label__l2 __label__l3'
Darstellung von drei Etiketten: [L1, L2, L3]. Zwischen Teil1 und Teil2 sollte es eine leere Zeichenfolge geben: ''.
Zum Beispiel: Jede Zeile (mehrere Etiketten) wie:
'W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __label__5626661657638885119 __label__492179380534695959595959559559559559559559559559559559559559559595 __label__8904735555009151318 '
Wo '5626661657638885119', '4921793805334628695' , '890473555009151318' sind drei Labels mit dieser Eingangszeichenfolge 'W5466 W138990 ...
Beachten:
Einige Util -Funktionen finden Sie in Data_util.py; Überprüfen Sie load_data_multilabel () von Data_util, um die Eingabe und Beschriftungen von Rohdaten zu bearbeiten.
Es gibt eine Funktion zum Laden und Zuordnen des vorgezogenen Wortes, der dem Modell einbettet, wobei die Worteinbettung in Word2VEC oder FastText vorgelegt ist.
Wenn Word2VEC.LOAD nicht funktioniert, können Sie vorgezogene Worteinbetten laden, insbesondere für die chinesische Worteinbettung. Verwenden Sie die folgenden Zeilen:
Gensim importieren
von Gensim.models importieren Keyedvektoren
WORD2VEC_MODEL = KEYEDVECTORS.LOAD_WORD2VEC_FORMAT (WORD2VEC_MODEL_PATH, BINARY = TRUE, UNICODE_ERRORS = 'Ignorieren') #
Oder Sie können ausschalten, indem Sie die Flagge der Vorbereitungswort einbetten, um false zu deaktivieren.
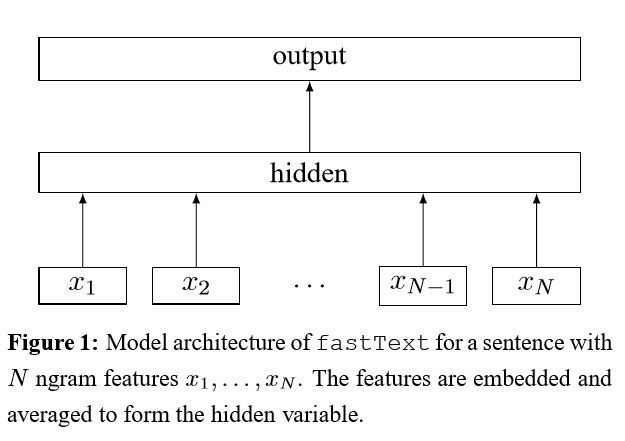
Auslöser von Tricks für eine effiziente Textklassifizierung
Nachdem jedes Wort in den Satz eingebettet ist, werden diese Wortdarstellungen dann zu einer Textdarstellung gemittelt, die zu einem linearen Klassifikator umgegeben wird. Verwenden Sie die Softmax -Funktion, um die Wahrscheinlichkeitsverteilung über die vordefinierten Klassen zu berechnen. Dann wird Cross Entropy verwendet, um den Verlust zu berechnen. Tasche mit Wortdarstellung berücksichtigt keine Wortreihenfolge. Um die Wortreihenfolge zu berücksichtigen, werden N-Gram-Funktionen verwendet, um einige teilweise Informationen über die lokale Wortreihenfolge zu erfassen. Wenn die Anzahl der Klassen groß ist, ist die Berechnung des linearen Klassifikators rechnerisch teuer. So verwendet es, dass Softmax den Trainingsprozess beschleunigt.
Ergebnis: Die Leistung ist so gut wie Papier, die Geschwindigkeit auch sehr schnell.
Überprüfen Sie: p5_fasttextb_model.py
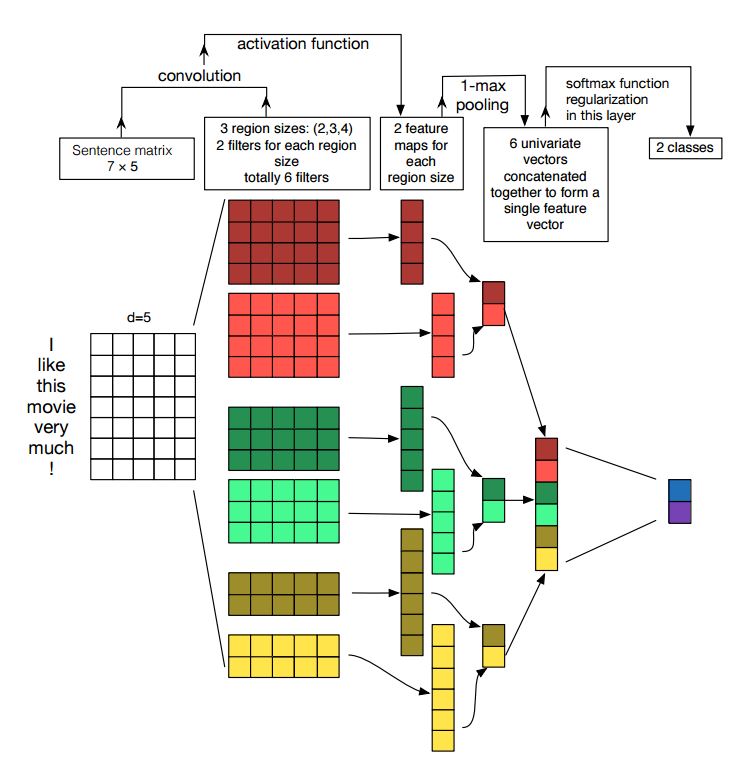
Implementierung von Faltungsnetzwerken für die Satzklassifizierung
Struktur: Einbettung ---> conv ---> Max-Pooling ---> Vollständige Schicht --------> Softmax
Überprüfen Sie: p7_textcnn_model.py
Um mit TextCnn ein sehr gutes Ergebnis zu erzielen, müssen Sie auch eine Sensitivitätsanalyse des (und der Praktizierenden der Leitfaden für) Faltungsnetzwerke für die Klassifizierung (und den Leitfaden der Praktizierenden) vorlesen: Sie erhalten einige Einblicke in Dinge, die die Leistung beeinflussen können. Sie müssen zwar einige Einstellungen entsprechend Ihrer spezifischen Aufgabe ändern.
Das neuronale Netzwerk mit Faltungsstücken ist die Hauptgebäudbox für die Lösung von Problemen des Computervisions. Jetzt werden wir zeigen, wie CNN für NLP insbesondere die Textklassifizierung verwendet werden kann. Die Satzlänge unterscheidet sich von einem zum anderen. Wir werden also Pad verwenden, um feste Länge zu erhalten, n. Für jeden Token im Satz verwenden wir eine Einbettung von Wort, um einen festen Dimensionsvektor zu erhalten, d. Unser Eingang ist also eine zweidimensionale Matrix: (n, d). Dies ähnelt mit dem Bild für CNN.
Erstens werden wir Faltungsbetrieb zu unserer Eingabe durchführen. Es ist ein Element-Multiplizieren zwischen Filter und Teil der Eingabe. Wir verwenden k-Anzahl der Filter, jede Filtergröße ist eine 2-dimensionsmatrix (f, d). Jetzt ist die Ausgabe K -Anzahl der Listen. Jede Liste hat eine Länge von N-F+1. Jedes Element ist ein Skalar. Beachten Sie, dass die zweite Dimension immer die Dimension der Worteinbettung ist. Wir verwenden eine unterschiedliche Filtergröße, um reichhaltige Funktionen von Texteingaben zu erhalten. Und das ist etwas Ähnliches mit N-Gramm-Merkmalen.
Zweitens werden wir Max -Pooling für die Ausgabe des Faltungsbetriebs durchführen. Für k -Anzahl der Listen erhalten wir K -Anzahl von Skalaren.
Drittens werden wir Skalare zu endgültigen Merkmalen verkürzen. Es ist ein Vektor mit fester Größe. Und es ist unabhängig von der Größe der Filter, die wir verwenden.
Schließlich werden wir eine lineare Ebene verwenden, um diese Funktionen in pro definierte Etiketten zu projizieren.
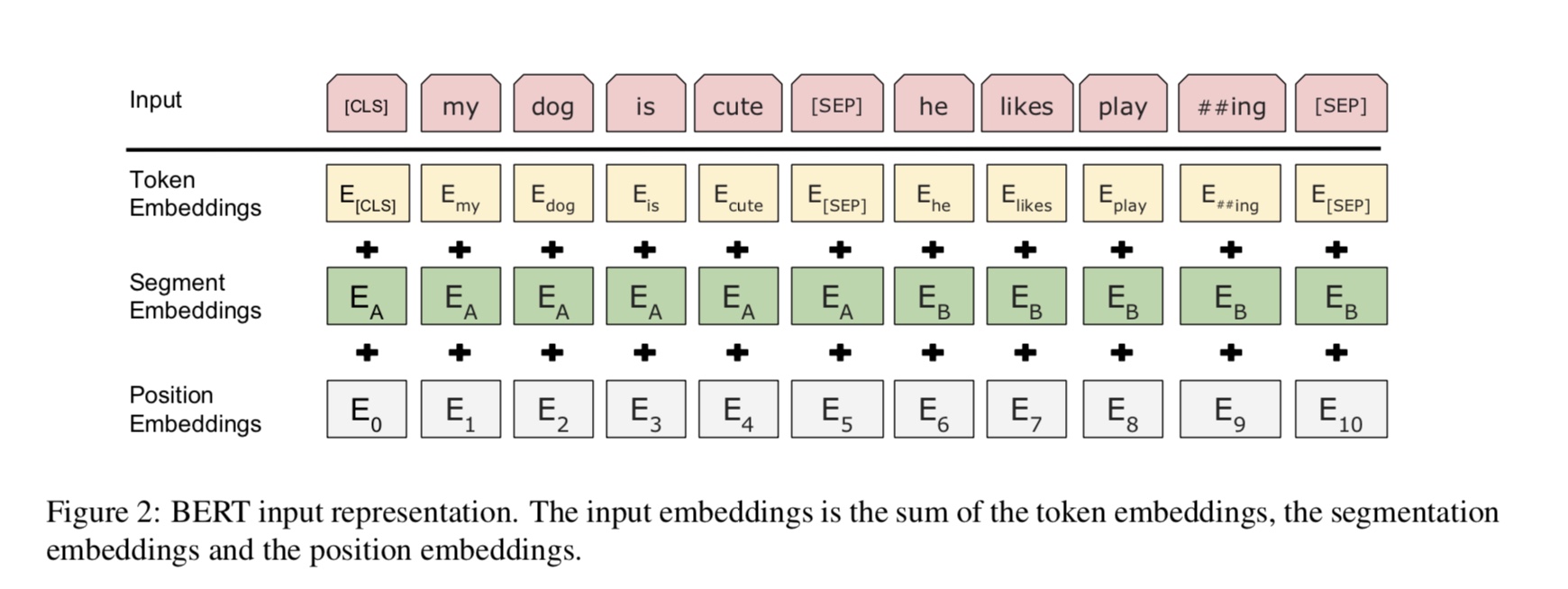
Bert erzielte derzeit hochmoderne Ergebnisse bei mehr als 10 NLP -Aufgaben. Die Schlüsselideen hinter diesem Modell sind, dass wir können
Vorhanden Sie das Modell, indem Sie ein Sprachmodell mit einer großen Menge an Rohdaten verwenden, wo Sie es leicht finden können.
Da die meisten Parameter des Modells vorgeschrieben sind, muss nur die letzte Schicht für den Klassifizierer für unterschiedliche Aufgaben benötigt werden.
Infolgedessen ist dieses Modell generisch und sehr mächtig. Sie können nur eine Feinabstimmung basierend auf dem vorgeborenen Modell innerhalb
eine kurze Zeit.
Dieses Modell ist jedoch ziemlich groß. Mit Sequenzlänge 128 können Sie nur mit einer Chargengröße von 32 trainieren. lange
Dokument wie die Sequenzlänge 512 kann es nur eine Stapelgröße 4 für eine normale GPU (mit 11 g) trainieren. und sehr wenige Leute
Kann dieses Modell von Grund auf neu trainieren, da es viele Tage oder Wochen dauert, um zu trainieren, und ein normaler GPU-Speicher zu klein ist
Für dieses Modell.
Insbesondere das Backbone -Modell ist Transformator, wo Sie es in Aufmerksamkeit finden können, was Sie brauchen. Es verwendet zwei Arten von
Aufgaben, um das Modell vorzubinden.
Im Allgemeinen müssen Sie angesichts eines Satzes ein gewisser Prozentsatz der Wörter maskiert, und müssen die maskierten Wörter vorhersagen
Basierend auf diesem maskierten Satz. Maskierte Wörter werden zufällig ausgewiesen.
Wir füttern die Eingabe durch einen tiefen Transformator -Encoder und verwenden dann die endgültigen versteckten Zustände, die dem Maskierten entsprechen
Positionen, um vorherzusagen, welches Wort maskiert wurde, genau wie wir ein Sprachmodell trainieren würden.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Viele Sprachverständnisaufgaben, wie Fragen, die Beantwortung, Inferenz, müssen die Beziehung verstehen müssen
zwischen Satz. Das Sprachmodell kann jedoch nur ohne Satz verstehen. Nächster Satz
Vorhersage ist eine Beispielaufgabe, um das Modell zu helfen, in solchen Aufgaben besser zu verstehen.
50% des Zufalls Der zweite Satz ist der nächste Satz des ersten, 50% der nächsten.
Bei zwei Satz wird das Modell gebeten, vorherzusagen, ob der zweite Satz real ist, der nächste Satz von ist
der erste.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
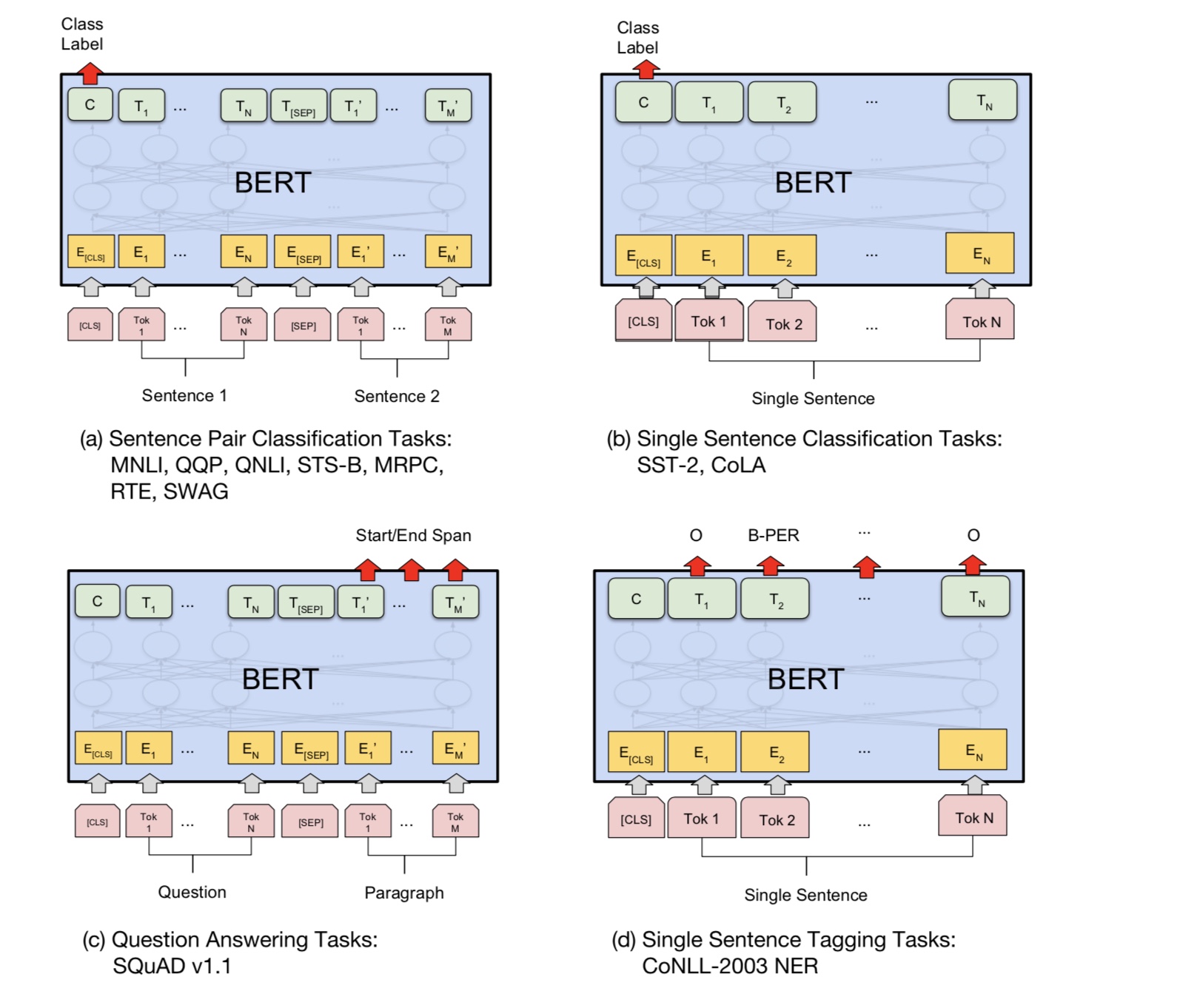
Grundsätzlich können Sie ein vorgebildetes Modell herunterladen und Ihre Aufgabe mit Ihren eigenen Daten einfach abtun.
Für die Klassifizierungsaufgabe können Sie den Prozessor hinzufügen, um das Format zu definieren, das Sie aus Eingabe und Beschriftungen aus Quelldaten lassen möchten.
Führen Sie den folgenden Befehl unter Ordner a00_bert aus:
python train_bert_multi-label.py
Es erreicht 0,368 nach 9 Epoche. oder Sie können eine Multi-Label-Klassifizierung mit herunterladbaren Daten mit Bert ausführen
Sentiment_analysis_fine_grain mit Bert
Sie können Session- und Feed -Stil verwenden, um das Modell wiederherzustellen und Daten zu füttern, und dann Protokolls abrufen, um eine Online -Vorhersage zu erstellen.
Online -Vorhersage mit Bert
Ursprünglich trainiert oder bewertet es das Modell basierend auf der Datei, nicht für online.
Zunächst können Sie vor dem Ausgebildem Modell von Google Download von Google verwenden. Führen Sie ein paar Epoche auf Ihrem Datensatz aus und finden Sie einen geeigneten
Sequenzlänge.
Zweitens können Sie das Basismodell in Ihren eigenen Daten vorvertrauen, solange Sie einen Datensatz finden, der mit
Ihre Aufgabe, dann eine Feinabstimmung in Ihrer spezifischen Aufgabe.
Drittens können Sie die Verlustfunktion und die letzte Ebene ändern, um Ihre Aufgabe besser zu passen.
Darüber hinaus können Sie einige vorgebaute Aufgaben definieren, die dem Modell helfen, Ihre Aufgabe viel besser zu verstehen.
Wie erfahren wir aus Experimenten, ist die vorgebrachte Aufgabe unabhängig vom Modell und vor dem Training ist nicht begrenzt auf
die Aufgaben oben.
Struktur V1: Einbettung ---> bidirektionales LSTM ---> Hachzeitabgabe ---> Durchschnitt ------> Softmax-Schicht
Überprüfen Sie: p8_textrnn_model.py
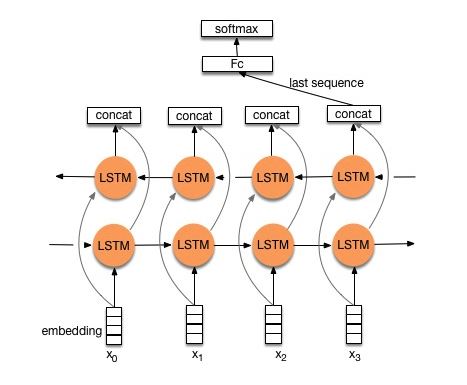
Struktur V2: Einbettung-> bidirektionales LSTM ----> Dropout-> concat Ouput ---> lstm ---> Droput-> FC-Schicht-> Softmax-Schicht
Überprüfen Sie: p8_textrnn_model_multilayer.py
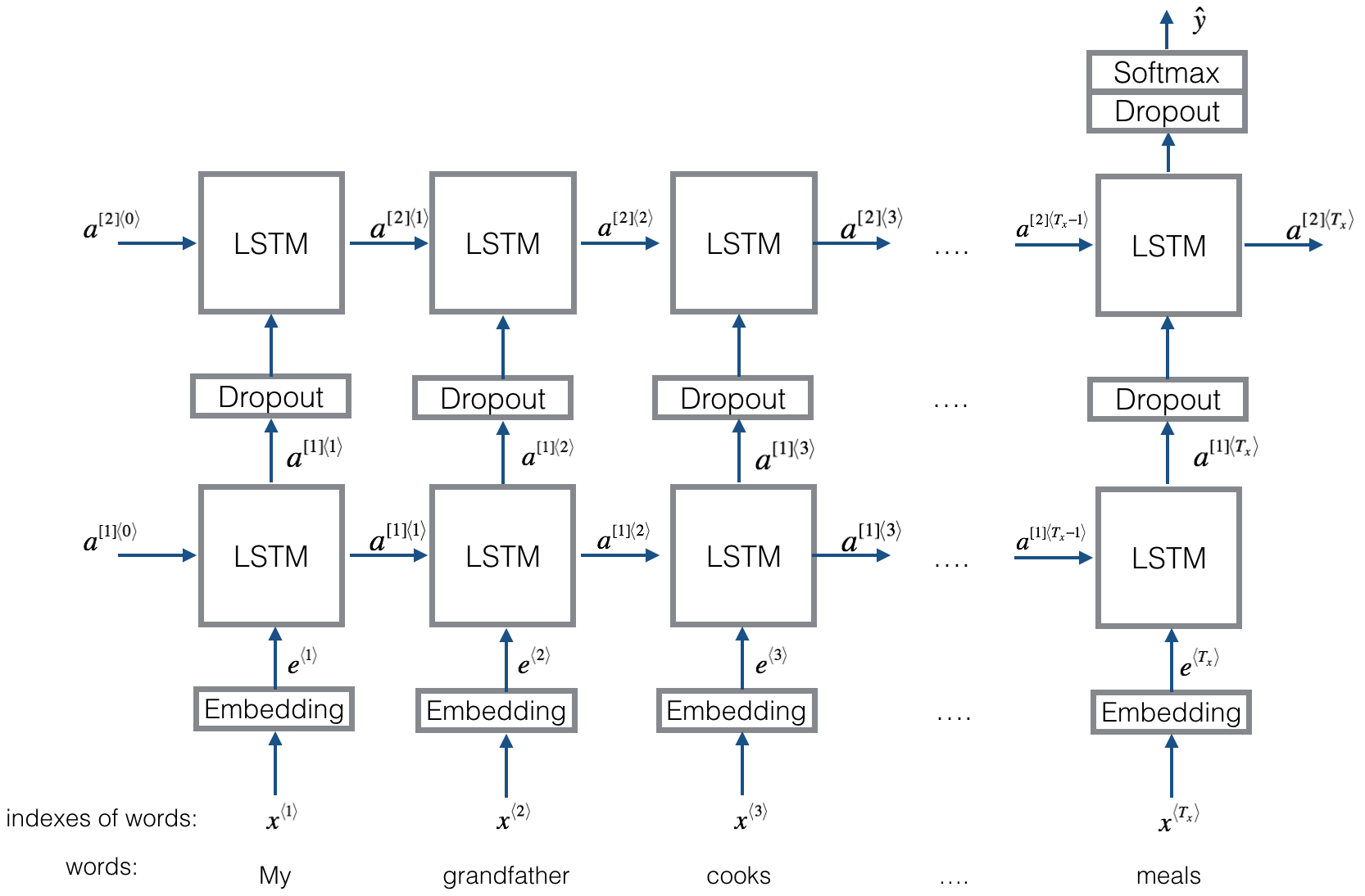
Struktur wie textrnn. Die Eingabe ist jedoch speziell gestaltet. Eginput: "Wie viel kostet der Computer? EOS -Preis für Laptop". Wo 'EOS' ein spezielles Token -Spilz -Frage 1 und Frage2 ist.
Überprüfen Sie: p9_bilstmtextrelation_model.py
Struktur: Verwenden Sie zunächst zwei verschiedene Faltungen, um das Merkmal von zwei Sätzen zu extrahieren. dann zwei Funktionen hängen. Verwenden Sie eine lineare Transformationsschicht, um Projektion aus der Zielbezeichnung und dann zu Softmax zu projizieren.
Überprüfen Sie: p9_twocntextrelation_model.py
Struktur: Ein bidirektionaler LSTM für einen Satz (Get Output1), ein weiterer bidirektionaler LSTM für einen anderen Satz (Get Output2). Dann: Softmax (Ausgang1 M output2)
Überprüfen Sie: p9_bilstmtextrelationtwornn_model.py
Für weitere Details können Sie: Deep Learning for Chatbots, Teil 2-Implementierung eines retrievalbasierten Modells in TensorFlow
Wiederkehrendes Faltungsnetzwerk für die Textklassifizierung
Implementierung eines wiederkehrenden Faltungsnetzes für die Textklassifizierung
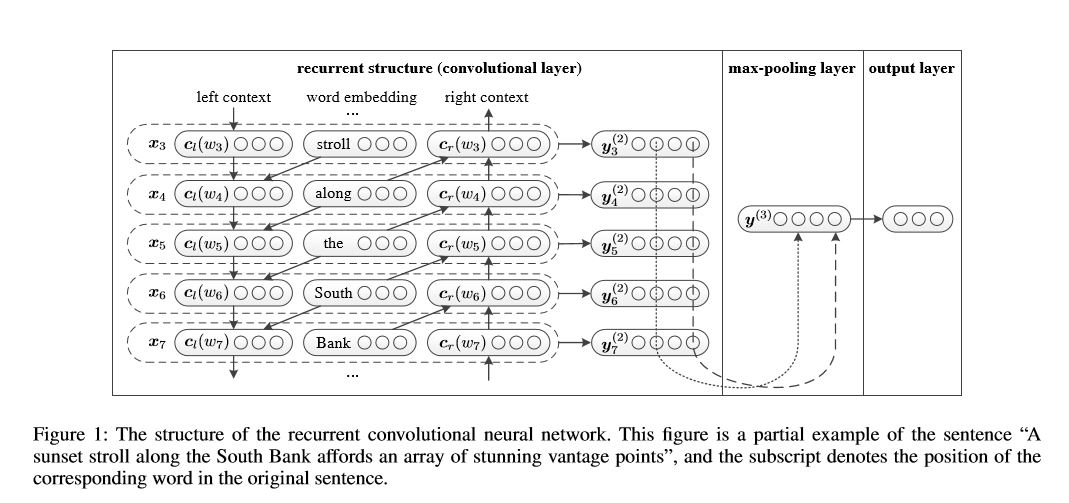
Struktur: 1) Rezidivstruktur (Faltungsschicht) 2) maximaler Pooling 3) Vollständige Schicht+Softmax
Es lernt die Repräsentation jedes Wortes im Satz oder Dokument mit dem linken Kontext und dem rechten Seitenkontext:
Repräsentation Current Word = [links_side_context_vector, current_word_embedding, right_side_context_vecotor].
Für den linken Kontext verwendet es eine wiederkehrende Struktur, eine No-Linearitäts-Übertragung des vorherigen Wortes und der frühere Kontext der linken Seite; Ähnlich wie der rechte Seitenkontext.
Überprüfen Sie: p71_textrcnn_model.py
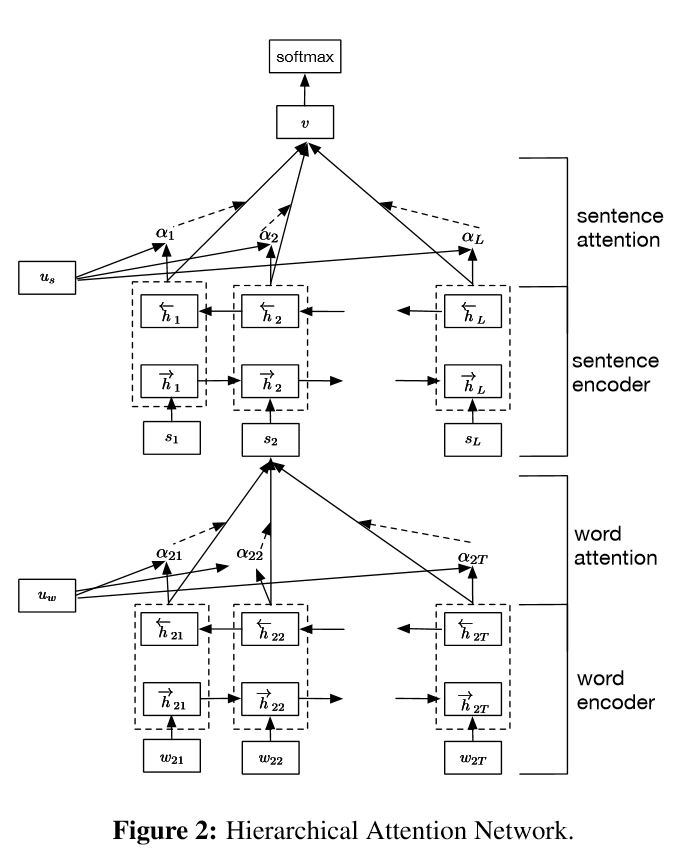
Implementierung hierarchischer Aufmerksamkeitsnetzwerke für die Klassifizierung der Dokumente
Struktur:
Einbettung
Wortcodierer: Wortebene bidirektionale Gru, um eine reichhaltige Darstellung von Wörtern zu erhalten
Aufmerksamkeit der Wortaufmerksamkeit: Aufmerksamkeit der Wortebene, um wichtige Informationen in einem Satz zu erhalten
Satz Encoder: Satzebene bidirektionale Gru, um eine reichhaltige Repräsentation von Sätzen zu erhalten
Satzträte: Satzebene Aufmerksamkeit, um einen wichtigen Satz unter den Sätzen zu erhalten
FC+Softmax
In NLP kann die Textklassifizierung für einen einzelnen Satz durchgeführt werden, kann jedoch auch für mehrere Sätze verwendet werden. Wir können es Dokumentklassifizierung nennen. Wörter sind Form zu Satz. Und Satz ist Form zum Dokumentieren. Unter diesen Umständen kann eine intrinsische Struktur existieren. Wie können wir diese Art von Aufgabe modellieren? Sind alle Teile des Dokuments gleich relevant? Und wie wir bestimmen, welcher Teil wichtiger ist als ein anderer?
Es hat zwei einzigartige Funktionen:
1) Es hat eine hierarchische Struktur, die die hierarchische Struktur von Dokumenten widerspiegelt;
2) Es hat zwei Ebenen von Aufmerksamkeitsmechanismen, die beim Wort und Satzebene verwendet werden. Es ermöglicht das Modell, wichtige Informationen auf verschiedenen Ebenen zu erfassen.
Wortcodierer: Für jedes Wörter in einem Satz ist es in den Verteilungsvektorraum in einen Wortvektor eingebettet. Es verwendet eine bidirektionale Gru, um den Satz zu codieren. Durch Verkettungsvektor aus zwei Richtungen kann es nun eine Darstellung des Satzes bilden, der auch Kontextinformationen erfasst.
Wortaufmerksamkeit: Gleiche Wörter sind wichtiger als ein anderer für den Satz. Aufmerksamkeitsmechanismus wird also verwendet. Zuerst wird eine Schicht MLP verwendet, um eine versteckte Repräsentation des Satzes zu erhalten, dann die Bedeutung des Wortes als Ähnlichkeit von UIT mit einem Word -Ebene -Kontextvektor UW und durch eine Softmax -Funktion eine normalisierte Bedeutung zu erhalten.
Satz Encoder: Für Satzvektoren wird bidirektionaler Gru verwendet, um sie zu codieren. Ähnlich wie der Wortcodierer.
Satzaufmerksamkeit: Satzebene Vektor wird verwendet, um die Bedeutung zwischen den Sätzen zu messen. Ähnlich wie die Aufmerksamkeit von Wort.
Dateneingabe:
Im Allgemeinen sollte die Eingabe dieses Modells server Sätze anstelle von Sinle -Satz haben. Form ist: [Keine, Satz_Lenght]. wo kein die batch_size bedeutet.
In meinen Trainingsdaten habe ich für jedes Beispiel vier Teile. Jeder Teil hat die gleiche Länge. Ich beschwere mich vier Teile, um einen einzelnen Satz zu bilden. Das Modell wird den Satz in vier Teile aufteilt, um einen Tensor mit Form zu bilden: [Keine, num_sento, suple_length]. wobei num_sentoce die Anzahl der Sätze ist (gleich 4 in meiner Einstellung).
Überprüfen Sie: p1_hierarchicalattention_model.py
Für aufmerksame Aufmerksamkeit können Sie die aufmerksame Aufmerksamkeit überprüfen
Implementierung SEQ2SEQ mit der Aufmerksamkeit, die aus der Übersetzung der neuronalen maschinellen Übersetzung abgeleitet wird, indem sie gemeinsam lernen, sich auszurichten und zu übersetzen
I. Struktur:
1) Einbettung 2) BI-GRU Auch erhalten eine reichhaltige Darstellung von Quellsätzen (vorwärts und rückwärts). 3) Decodierer mit Aufmerksamkeit.
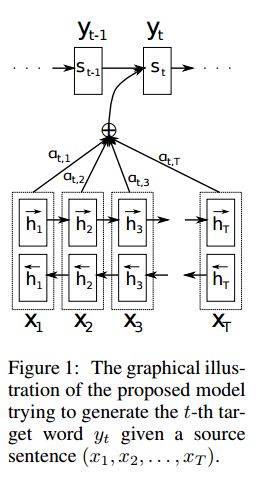
Ii.Input von Daten:
Es gibt zwei Arten von drei Arten von Eingängen: 1) Encoder -Eingänge, die ein Satz ist; 2) Decoder -Eingänge, es handelt sich um die Labelsliste mit fester Länge; 3) Zielbezeichnungen, es handelt sich auch um eine Liste von Etiketten.
Beispielsweise lautet Labels: "L1 L2 L3 L4", dann werden Decoder -Eingänge: [_ Go, L1, L2, L2, L3, _pad]; Target Label ist: [L1, L2, L3, L3, _end, _pad]. Die Länge wird auf 6 festgelegt, alle überschreitenden Etiketten werden verlegt, pad, wenn Etikett nicht ausreicht, um zu füllen.
III.Attention Mechanismus:
Übertragungs -Encoder -Eingangsliste und versteckter Decoderstaat übertragen
Berechnen Sie die Ähnlichkeit des versteckten Zustands mit jeder Encodereingabe, um die Möglichkeit für jeden Encodereingang zu erhalten.
Gewichtete Summe der Encoder -Eingaben basierend auf der Möglichkeitsverteilung.
Gehen Sie durch die RNN -Zelle mit dieser Gewichtsbetrag zusammen mit Decodereingabe, um einen neuen versteckten Zustand zu erhalten
Iv.Wie Vanilla Encoder Decoder funktioniert:
Der Quellsatz wird mit RNN als Vektor der festen Größen ("Gedankenvektor") codiert. Dann während des Decoders:
Beim Training wird ein weiterer RNN verwendet, um zu versuchen, ein Wort durch die Verwendung dieses "Gedankenvektors" als Init -Zustand zu erhalten und die Eingabe von Decodereingaben bei jedem Zeitstempel zu nutzen. Decoder starten von Special Token "_go". Nachdem ein Schritt aufgetreten ist, wird der neue versteckte Zustand erhalten und zusammen mit neuen Eingaben können wir diesen Prozess fortsetzen, bis wir zu einem speziellen Token "_end" gelangen. Wir können den Verlust durch Berechnung des Cross -Entropie -Verlusts von Logits und Zielbezeichnung berechnen. Logits wird durch eine Projektionsschicht für den versteckten Zustand (für die Ausgabe des Decoder -Schritts (in Gru können versteckte Zustände von Decodierer als Ausgabe einfach verwenden).
Wenn es testet wird, gibt es kein Etikett. Wir sollten also die Ausgabe, die wir vom vorherigen Zeitstempel erhalten, füttern und den Prozess fortsetzen, den wir "_end" -Token erreicht haben.
V.notices:
Hier verwende ich zwei Arten von Vokabeln. Einer stammt aus Wörtern, die von Encoder verwendet werden; Ein anderer ist für Etiketten, die von Decoder verwendet werden
Für das Wortschatz von Läden füge ich drei spezielle Token ein: "_ Go", "_ End", "_ Pad"; "_Unk" wird nicht verwendet, da alle Etiketten vordefiniert sind.
Status: Es war in der Lage, Aufgabenklassifizierung durchzuführen. und in der Lage, umgekehrte Reihenfolge seiner Sequenzen in Spielzeugaufgabe zu erzeugen. Sie können es überprüfen, indem Sie die Testfunktion im Modell ausführen. Überprüfen Sie: a2_train_classification.py (Zug) oder a2_transformer_classification.py (Modell)
Wir machen es im parallell -Stil. Layer -Normalisierung, Restverbindung und Maske werden auch im Modell verwendet.
Für alle Bausteine fügen wir eine Testfunktion in die folgende Datei hinzu und testen jedes kleine Stück erfolgreich.
Die Sequenz zur Aufmerksamkeit ist ein typisches Modell zur Lösung von Problemen zur Sequenzgenerierung, wie z. B. das Übersetzen des Dialogsystems. Die meiste Zeit verwendet es RNN als Buidling -Block, um diese Aufgaben zu erledigen. Util kürzlich wenden Menschen auch das neuronale Netzwerk mit Falten an, um die Sequenzprobleme zu erzielen. Transformator erledigt diese Aufgaben jedoch ausschließlich auf Aufmerksamkeitsmechansim. Es ist schnell und erzielte ein neues Ergebnis des neuesten Standes.
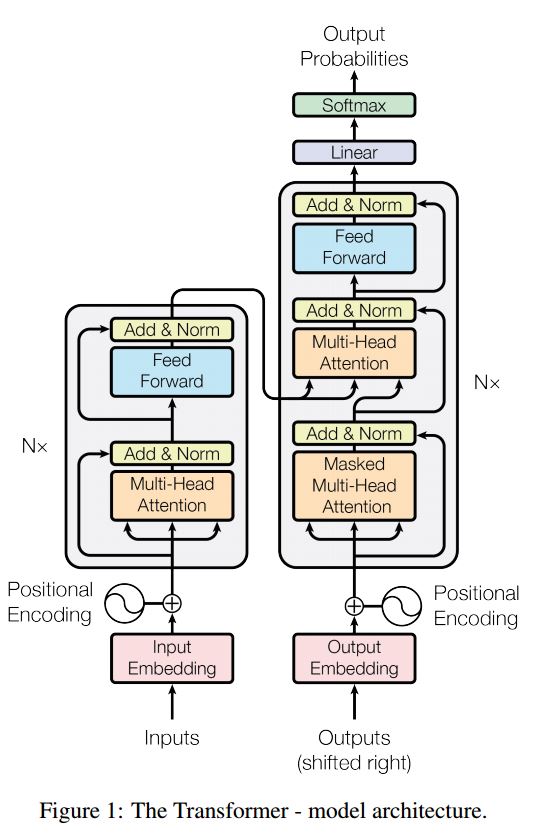
Es hat auch zwei Hauptteile: Encoder und Decoder. Unten ist Desc aus Papier:
Encoder:
6 Schichten.each-Schichten haben zwei Unterschichten. Der erste ist ein Mehrkopf-Selbstbekämpfungsmechanismus; Die zweite ist positionell, vollständig verbundenes Feed-Forward-Netzwerk. Für jeden Unterschicht. Verwenden Sie Layernorm (x+sublayer (x)). Alle Dimension = 512.
Decoder:
Hauptnake von diesem Modell:
Verwenden Sie dieses Modell, um Aufgabenklassifizierung durchzuführen:
Hier verwenden wir nur einen Encodenteil für die Aufgabenklassifizierung, die RESDIUAL -Verbindung, nur 1 Schicht verwendet. Keine Maske. Wir verwenden Multi-Head-Aufmerksamkeit und potenzielle Feed-Vorwärts, um Merkmale des Eingabegestells zu extrahieren, und dann lineare Schicht, um sie zu projizieren, um Protokoll zu erhalten.
Für Details des Modells überprüfen Sie bitte: a2_transformer_classification.py
Eingabe: 1. Geschichte: Es ist Multi-Sentces als Kontext. 2.Query: Ein Satz, der eine Frage ist, 3. Ansewr: ein einzelnes Etikett.
Modellstruktur:
Eingabecodierung: Verwenden Sie eine Word -Tasche, um die Geschichte (Kontext) und Abfrage (Frage) zu codieren; Berücksichtigen Sie die Position mit der Positionsmaske
Durch die Verwendung von bidirektionalem RNN, um Geschichte und Abfrage zu codieren, steigt der Leistungssteiger von 0,392 auf 0,398 um 1,5%.
Dynamischer Speicher:
A. Berechnen Sie Gate mithilfe von "Ähnlichkeit" von Schlüssel, Werte mit Eingabe der Geschichte.
B. Holen Sie sich den Kandidatenversteck, indem Sie jeden Schlüssel, Wert und Eingabe transformieren.
C. Kombinieren Sie Gate und Kandidat versteckter Zustand, um den aktuellen versteckten Zustand zu aktualisieren.
B. Erhalten Sie eine gewichtete Summe des versteckten Zustands mithilfe von Möglichkeitenverteilung.
C. Nichtlinearitätstransformation von Abfragen und verstecktem Zustand, um das Label vorherzusagen.
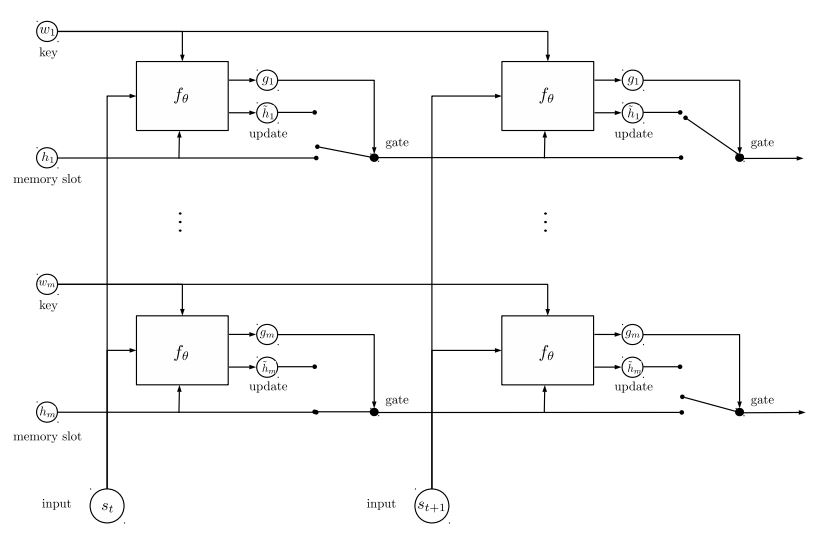
Hauptnake von diesem Modell:
Verwenden Sie Schlüssel und Werte Blöcke, die voneinander unabhängig sind. Es kann also parallel laufen.
Modellierung Kontext und Frage gemeinsam. Verwenden Sie das Speicher, um den Zustand der Welt zu verfolgen; und verwenden Sie die Nichtlinearitätstransformation des versteckten Zustands und der Frage (Abfrage), um eine Vorhersage zu machen.
Einfaches Modell kann auch eine sehr gute Leistung erzielen. Einfache Enkodierung als Word -Tasche.
Für Details des Modells überprüfen Sie bitte: a3_entity_network.py
Unter diesem Modell hat es eine Testfunktion, die dieses Modell auffordert, Zahlen sowohl für die Geschichte (Kontext) als auch für Abfrage (Frage) zu zählen. Aber Gewichte der Geschichte sind kleiner als die Abfrage.
Ausblick des Modells:
1.Inputmodul: codieren Rohtexte in Vektordarstellung
2. Frage Modul: Frage in die Vektordarstellung codieren
3.Episodisches Speichermodul: Mit Eingängen wählt es aus, auf welche Teile von Eingängen durch den Aufmerksamkeitsmechanismus unter Berücksichtigung der Frage und des vorherigen Speichers und des Vorgängers sind.
4.Answer Modul: Generieren Sie eine Antwort aus dem endgültigen Speichervektor.
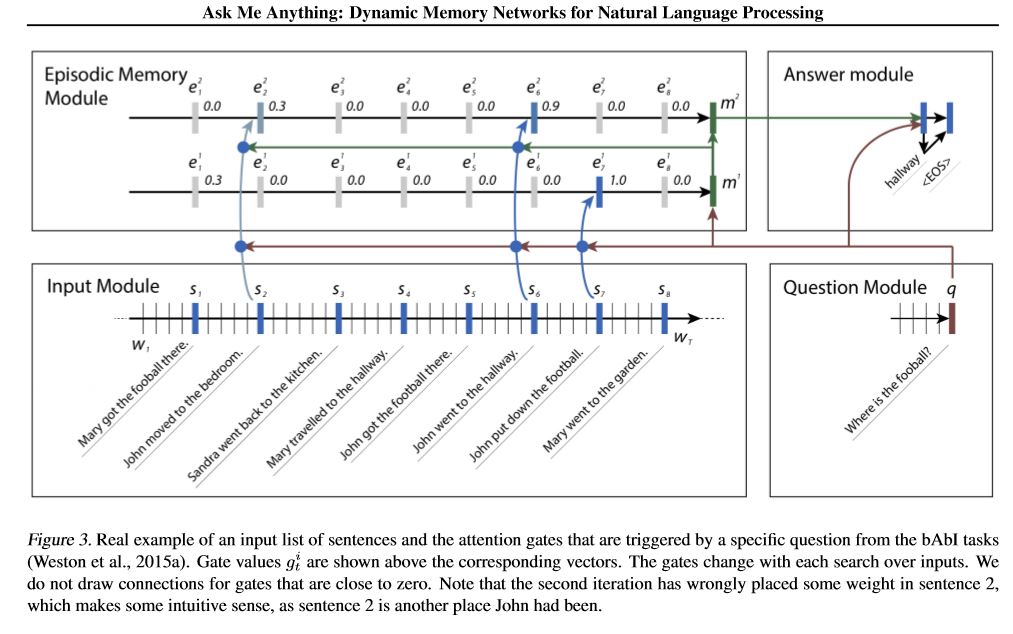
Detail:
1. Eingabemodul:
A.Single -Satz: Verwenden Sie Gru, um einen versteckten Zustand zu erhalten. EG [versteckte Zustände 1, versteckte Zustände 2, versteckte Staaten ..., versteckter Staat n]
2. Frage Modul: Verwenden Sie Gru, um einen versteckten Zustand zu erhalten
3.Episodisches Speichermodul:
Verwenden Sie einen Aufmerksamkeitsmechanismus und ein wiederkehrendes Netzwerk, um den Speicher zu aktualisieren.
A. Tor als Aufmerksamkeitsmechanismus:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B.Memory-Update-Mechanismus: Nehmen Sie Kandidatensatz, GATE und früherer versteckter Zustand. Sie verwendet Gated-Gru, um den versteckten Zustand zu aktualisieren. wie: h = f (c, h_previous, g). Der letzte versteckte Zustand ist der Eingang für das Antwortmodul.
C. Nehmen Sie für mehrere Episoden ===> transitive Inferenz.
ZB fragen Sie, wo ist der Fußball? Es wird sich um die Haftstrafe von "John setzen den Fußball nieder")) und muss dann im zweiten Pass an den Ort von John teilnehmen.
4.Answer Modul: Nehmen Sie das endgültige epsoidische Speicher, die Frage, es aktualisiert den versteckten Status des Antwortmoduls.
1. Character-Level-Faltungsnetzwerke für die Textklassifizierung
2. Konvolutionelle neuronale Netzwerke für die Kategorisierung von Text: flacher Wortniveau im Vergleich zu Deep Character-Level
3. Sehr tiefe Faltungsnetzwerke für die Textklassifizierung
4.Adversariale Trainingsmethoden für die halbüberwachende Textklassifizierung
5.ensemble Modelle
Während des großen Maßstabs der Multi-Label-Klassifizierung wurden Serverunterricht gelernt, und einige Liste wie unten:
Was ist am wichtigsten, um eine hohe Genauigkeit zu erreichen? Es hängt die Aufgabe ab, die Sie ausführen. Aus der hier durchgeführten Aufgabe glauben wir, dass Ensemble -Modelle, die auf Modellen basieren, die aus mehreren Merkmalen wie Wort, Charakter für Titel und Beschreibung geschult sind, dazu beitragen können, eine sehr hohe Akzuierung zu erreichen. In einigen Fällen, wie nur Alphago Zero demonstrierte, ist Algorithmus jedoch wichtiger als Daten oder Rechenleistung. Tatsächlich hat Alphago Zero keine Humam -Daten verwendet.
Gibt es eine Decke für ein bestimmtes Modell oder Algorithmus? Die Antwort lautet ja. Hier wurden viele verschiedene Modelle verwendet, wir haben festgestellt, dass viele Modelle ähnliche Leistungen aufweisen, obwohl es in der Struktur sehr unterschiedlich ist. In gewissem Maße ist der Leistungsunterschied nicht so groß.
Ist Fallstudie zum Fehler nützlich? Ich denke, es ist sehr nützlich, besonders wenn Sie viele verschiedene Dinge getan haben, aber eine Grenze erreicht haben. Wenn Sie beispielsweise Fallstudien durchführen, können Sie Etiketten finden, die Modelle korrekt vorhersagen können und wo sie Fehler machen. Und die Leistung zu erfassen, indem sie Gewichte dieser falschen vorhergesagten Beschriftungen erhöhen oder potenzielle Fehler aus Daten finden.
Wie können wir Experten für maschinelles Lernen werden? Treten Sie meiner Meinung nach einem Wettbewerb für maschinelles Lernen bei oder beginnen Sie eine Aufgabe mit vielen Daten. Lesen Sie dann Papiere und implementieren einige, ein guter Ausgangspunkt. Wir werden also einige wirklich Erfahrung und Ideen für die Umstellung bestimmter Aufgaben haben und die Herausforderungen kennen. Wichtiger ist jedoch, dass wir nicht nur Ideen aus Papieren befolgen sollten, sondern auch einige neue Ideen untersuchen sollten, von denen wir glauben, dass sie das Problem streichen können. Wenn wir beispielsweise Strukturen klassischer Modelle ändern oder sogar einige neue Strukturen erfinden, können wir das Problem möglicherweise auf eine viel bessere Weise angehen, da es für die Aufgabe besser geeignet ist.
1. Tricksack für eine effiziente Textklassifizierung
2. Konvolutionelle neuronale Netzwerke für die Satzklassifizierung
3. Eine Sensitivitätsanalyse von Faltungsnetzwerken für die Satzklassifizierung (und Leitfaden für Praktiker)
4. Deep Learning für Chatbots, Teil 2-Implementierung eines retrievalbasierten Modells in TensorFlow von www.wildml.com
5. Erregung mit dem neuronalen Netzwerk für die Textklassifizierung
6.Hierarchische Aufmerksamkeitsnetzwerke für die Klassifizierung der Dokumente
7.Neural -maschinelles Übersetzung durch gemeinsames Lernen, sich auszurichten und zu übersetzen
8.Attention ist alles was Sie brauchen
9. Made mir alles: Dynamische Speichernetzwerke für die Verarbeitung natürlicher Sprache
10. Übertragen Sie den Zustand der Welt mit wiederkehrenden Unternehmensnetzwerken
11.Eensemble Auswahl aus Bibliotheken von Modellen
12.BERT: Vorausbildung von tiefen bidirektionalen Transformatoren für das Sprachverständnis
13.Google-Research/Bert
fortgesetzt werden. [email protected] für ein Problem


