text_classification
1.0.0
このリポジトリの目的は、深い学習を使用してNLPのテキスト分類方法を検討することです。
NLP APIを3分で無料でカスタマイズします:NLP APIデモ
中国語の言語理解評価ベンチマーク(手がかりのベンチマーク):1つのコードを使用して10のタスクと9ベースラインを実行し、パフォーマンスを詳細と比較します。
30g+生の中国のコーパス、xxlarge、xlargeなどでAlbert_chineseトレーニングの事前訓練を受けたモデルをリリースし、中国の国立日中の2019年〜oct-7のアートパフォーマンスを一致させることを目標としています!
利用可能なNLP用の大量の中国コーパス!
Google's Bertは、言語モデルのプリトレインを使用して、NLPの10を超えるタスクで新しいARTの結果を達成しました。
微調整。プリトレインTexcnn:実行中のコードとデータセットを使用した言語理解のためのBertのアイデア
テキスト分類のためのあらゆる種類のベースラインモデルがあります。
また、マルチラベルが文または文書に関連付けられているマルチラベル分類をサポートしています。
これらのモデルの多くは単純であり、タスクのトップレベルに到達することはできない場合があります。しかし、これらのモデルのいくつかは非常にです
クラシックなので、彼らはベースラインモデルとして役立つかもしれません。各モデルには、モデルクラスの下でテスト関数があります。実行できます
最初にパフォーマンスのおもちゃのタスクに。モデルはデータセットから独立しています。
深い学習を用いた大規模なマルチラベルテキスト分類の正式なレポートについては、こちらをご覧ください
ここでのいくつかのモデルは、(コンテキストの有無にかかわらず)質問への回答をモデル化したり、シーケンスを生成するために使用することもできます。
テキスト分類を行うために、2つのSeq2Seqモデル(注意を払ってSEQ2SEQ、Transformer-Attentionが必要なすべて)を調査します。
また、これらの2つのモデルは、シーケンス生成およびその他のタスクにも使用できます。あなたのタスクがマルチラベル分類である場合、
問題をシーケンス生成にキャストできます。
2つのメモリネットワークを実装します。 1つは動的メモリネットワークです。以前は問題の芸術状態に達しました
回答、感情分析、およびシーケンス生成タスク。いくつかの異なるタスクを実行することは、1つのモデルと呼ばれます。
そして、高性能に達します。 4つのモジュールがあります。重要なコンポーネントは、エピソードメモリモジュールです。ゲートメカニズムを使用します
パフォーマンスの注意を払い、Gated-Gruを使用してエピソードメモリを更新すると、別のGRUがあります(垂直方向)
パフォーマンス隠された状態の更新。推移的な推論を行う能力があります。
実装した2番目のメモリネットワークは、Recurrent Entity Network:Tracking State of the Worldです。のブロックがあります
メモリとしてのキー価値のペアは、並行して実行され、新しい芸術状態を達成します。質問のモデリングに使用できます
コンテキスト(または歴史)で答える。たとえば、モデルに(コンテキストとして)いくつかの文章を読んでもらうことができます。
質問(クエリとして)、モデルに答えを予測するように依頼します。クエリと同じストーリーをフィードする場合、それはできます
分類タスク。
ML/DL/NLPの問題について話し合い、お互いから技術サポートを取得するには、QQグループに参加できます:836811304
fastText
textcnn
BERT:言語理解のための深い双方向変圧器の事前訓練
Textrnn
rcnn
階層的な注意ネットワーク
注意を払ってseq2seq
トランス(「出席はあなたが必要とするすべてです」))
動的メモリネットワーク
EntityNetwork:世界の状態を追跡します
アンサンブルモデル
ブースト:
単一のモデルの場合、同一のモデルを一緒に積み重ねます。各レイヤーはモデルです。結果は、一緒に追加されたロジットに基づいています。レイヤー間の唯一の接続は、ラベルの重みです。各ラベルのフロントレイヤーの予測エラー率は、次のレイヤーの重量になります。エラー率が高いこれらのラベルには、重量が大きくなります。そのため、後のレイヤーはこれらの誤った予測ラベルにもっと注意を払い、以前の層の以前の間違いを修正しようとします。その結果、はるかに強力なモデルが得られます。 a00_boosting/boosting.pyを確認してください
およびその他のモデル:
bilstmtextrelation;
twocnntextrelation;
bilstmtextrelationtwornn
(Mulit-Labelラベル予測タスク、予測に依頼するTop5、300万トレーニングデータ、フルスコア:0.5)
| モデル | fastText | textcnn | Textrnn | rcnn | Hierattenet | seq2seqattn | EntityNet | DynamicMemory | トランス |
|---|---|---|---|---|---|---|---|---|---|
| スコア | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| トレーニング | 10m | 2H | 10H | 2H | 2H | 3H | 3H | 5H | 7時間 |
Bert Modelは、検証セットから最初の9エポックの後に0.368を達成します。
TextCnn、EntityNet、dynamicMemoryのアンサンブル:0.411
Ensemble EntityNet、DynamicMemory:0.403
知らせ:
m数分間立っています。 h何時間も立っています。
HierAtteNet 、階層的な注意networkkを意味します。
Seq2seqAttn注意を払ってseq2seqを意味します。
DynamicMemoryとは、dynamicmemorynetworkを意味します。
「注意はあなたが必要とするすべて」からモデルのTransformerスタンドです。
xxx_model.pyにありますxxx_train.pyを実行して、モデルをトレーニングしますxxx_predict.pyを実行して推論(テスト)を行います。各モデルには、モデルクラスの下にテスト方法があります。最初にテスト方法を実行して、モデルが適切に機能するかどうかを確認できます。
Python 2.7+ Tensorflow 1.8
(Tensorflow 1.1〜1.13も機能するはずです。ほとんどのモデルは、他のTensorflowバージョンでも正常に機能するはずです。
特定のバージョンへの非常に少数の機能ボンドを使用します。
Python3を使用している場合、エラーを満たしている場合に備えて、印刷/キャッチ機能を変更する限り、それは問題ありません。
TextCNNモデルはすでにPython 3.6にトランスフォームされています
このリポジトリの実行を支援するために、現在、トレーニング/検証/テストデータと語彙/ラベルを再生成し、保存しました
それらはH5PYを使用してキャッシュファイルとして。上記のリンクからダウンロードすることをお勧めします。
このリポジトリを実行するために必要なすべてが含まれています。データは前処理されており、モデルのトレーニングを1分で開始できます。
これは約1.8gのZIPファイルで、300万のトレーニングデータが含まれています。解凍した後、それは非常に大きいですが、の助けを借りて
HDF5では、トレーニング中にコンピューターのメモリ(EG8 g以下)の通常のサイズのみが必要です。
jupyterノートブック:pre-processing.ipynbを使用して処理データを使用します。あなたはこのタスクをよりよく理解することができ、
それを見てデータ。また、自分で自分でデータを生成することもできます。コードの数行を数回変更するだけです
このJupyterノートを使用してください。
今すぐモデルを試してみたい場合は、上からキャッシュファイルをダウロードしてから、フォルダー 'a02_textcnn'に移動して実行できます。
python p7_TextCNN_train.py
キャッシュされたファイルのデータを使用してモデルをトレーニングし、定期的に損失とF1スコアを印刷します。
古いサンプルデータソース:Word2Vecでトレーニングごとにサンプルデータと単語の埋め込みが必要な場合は、次のような閉じた問題で見つけることができます。
フォルダー「データ」でサンプルデータを見つけることもできます。 'sample_single_label.txt'の2つのファイルが含まれており、50kデータが含まれています
シングルラベル付き; 'sample_multiple_label.txt'には、複数のラベルを備えた20kのデータが含まれています。入力とラベルは「ラベル」によって分離されています。
テキスト分類またはタスクのデータセットに関する詳細を知りたい場合は、これらのモデルを使用できます。
https://biendata.com/competition/zhihu/
このリポジトリを使用する1つの方法:
ステップ1:この記事を読むことができます。テキスト分類を行うために使用されるさまざまなクラシックモデルの一般的なアイデアが得られます。
ステップ2:処理データおよび/またはキャッシュファイルをダウンロードします。
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
ステップ3:ここでモデルリストの一部を実行し、必要に応じてコードと構成を変更して、優れたパフォーマンスを得ます。
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
さらに、このトピックに関する記事を書くと、紙のスタイルを書いて書くことができます。いくつかの論文を読む必要があるかもしれません
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
'data/sample_multiple_label.txt'のデータを置き換え、以下の形式を確認してください。
'word1 word2 word3 __label__l1 __label__l2 __label__l3'
part1: 'word1 word2 word3'は入力(x)、part2: '__label__l1 __label__l2 __label__l3'です '
[L1、L2、L3]の3つのラベルがあります。 PART1とPART2の間には、空の文字列が必要です: ''。
例:各行(複数のラベル)のようなもの:
'W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __LABEL__56266661657638885119 __label__8904735555009151318 '
'56266661657638885119'、 '4921793805334628695'、 '890473555555009151318'は、この入力文字列 'W5466 W138990 ... C317 C184' W5466 W138990に関連する3つのラベルです
知らせ:
一部のUTIL関数はdata_util.pyにあります。 Raw_utilのload_data_multilabel()を確認してください。
モデルに埋め込まれた前提条件の埋め込みをロードして割り当てる関数があります。ここでは、単語の埋め込みがWord2vecまたはfastTextで前提とされています。
word2vec.loadが機能しない場合、特に中国語の単語埋め込みの使用については、次の行を使用する場合は、次の行をロードできます。
EMENSIMをインポートします
Gensim.ModelsからKeyEdVectorsをインポートします
word2vec_model = keyedvectors.load_word2vec_format(word2vec_model_path、binary = true、unicode_errors = 'nignore')#
または、オフにすることができます、前の単語埋め込みフラグをfalseに使用して、ロードワードの埋め込みを無効にします。
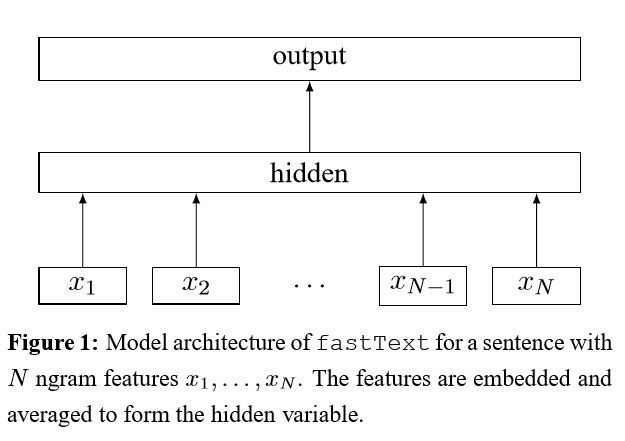
効率的なテキスト分類のためのトリックのバッグの実装
文に各単語を埋め込んだ後、この単語表現はテキスト表現に平均化され、線形分類器に供給されます。それを使用して、事前定義されたクラスで確率分布を計算します。次に、クロスエントロピーを使用して損失を計算します。単語表現の袋は、語順を考慮していません。語順を考慮するために、n-gram機能を使用して、ローカルの語順に関する一部の情報をキャプチャします。クラスの数が多い場合、線形分類器を計算することは計算高価です。したがって、トレーニングプロセスを高速化するためにHierarchical SoftMaxを使用します。
結果:パフォーマンスは紙と同じくらい優れており、スピードも非常に高速です。
チェック:p5_fasttextb_model.py
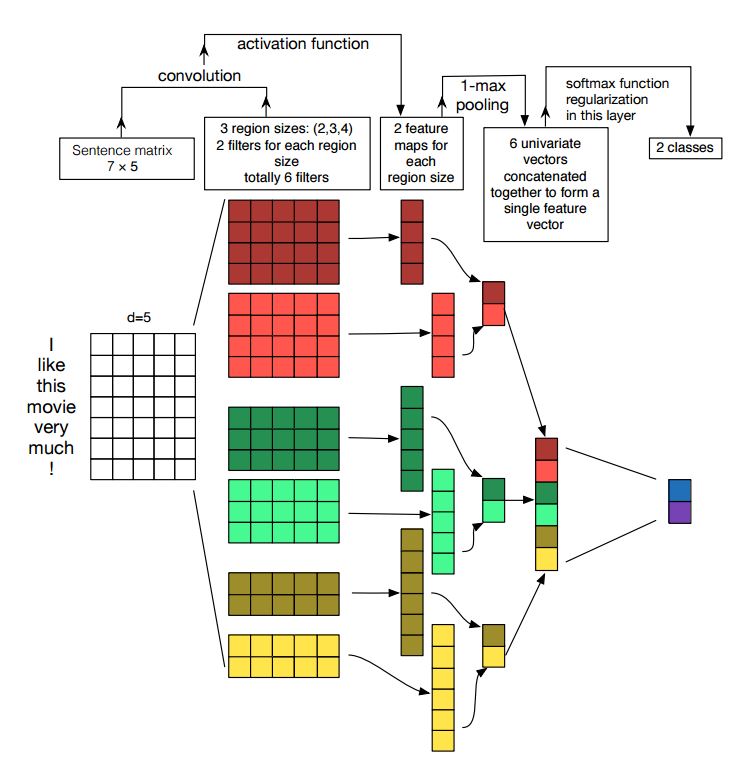
文の分類のための畳み込みニューラルネットワークの実装
構造:埋め込み---> conv ---> maxプーリング--->完全に接続されたレイヤー--------> softmax
チェック:p7_textcnn_model.py
TextCNNで非常に良い結果を得るためには、このペーパーについても注意深く読む必要があります。文化分類のための畳み込みニューラルネットワークの(および実務家のガイド)の感度分析:パフォーマンスに影響を与える可能性のあるものの洞察を提供します。ただし、特定のタスクに従っていくつかの設定を変更する必要があります。
畳み込みニューラルネットワークは、コンピュータービジョンの問題を解決するためのメインビルディングボックスです。次に、CNNをNLP、特にテキスト分類に使用する方法を示します。文の長さは、あるものによって異なります。したがって、パッドを使用して固定長を取得します。文の各トークンについて、単語の埋め込みを使用して、固定寸法ベクトルdを取得します。したがって、入力は2次元マトリックスです:(n、d)。これは、CNNの画像と同様です。
まず、入力に対して畳み込み操作を行います。これは、フィルターと入力の一部の間の要素ごとの増殖です。 kフィルターの数を使用し、各フィルターサイズは2次元マトリックス(f、d)です。これで、出力はk数のリストになります。各リストの長さはn-f+1です。各要素はスカラーです。 2番目の次元は、常に単語の埋め込みの次元になることに注意してください。さまざまなサイズのフィルターを使用して、テキスト入力からリッチな機能を取得しています。そして、これはn-gram機能に似たものです。
第二に、畳み込み操作の出力のために最大プーリングを行います。 kリストの数については、kスカラーの数を取得します。
第三に、スカラーを連結して最終的な機能を形成します。固定サイズのベクトルです。そして、それは私たちが使用するフィルターのサイズから独立しています。
最後に、線形層を使用して、これらの機能を定義されたラベルに投影します。
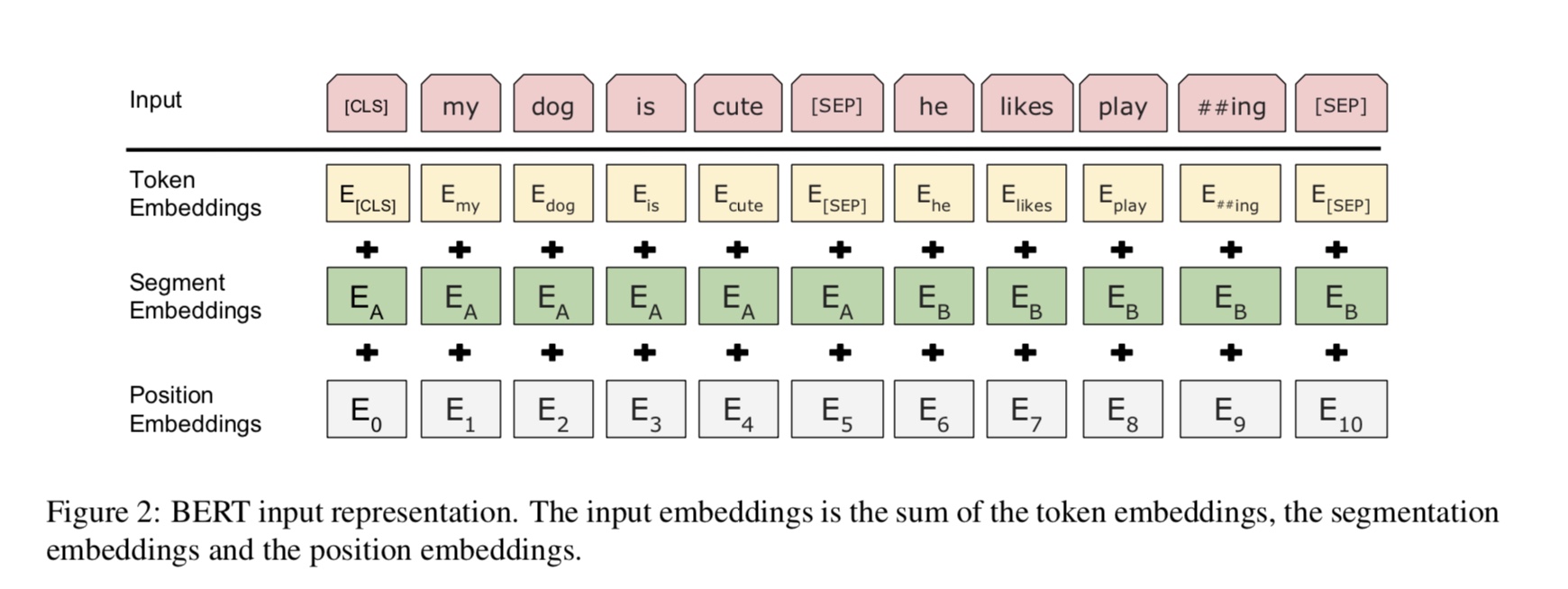
Bertは現在、10を超えるNLPタスクでARTの結果を達成しています。このモデルの背後にある重要なアイデアは、私たちができるということです
膨大な量の生データを使用して、1つの種類の言語モデルを使用してモデルをプリトレーニングし、簡単に見つけることができます。
モデルのパラメーターのほとんどは事前に訓練されているため、分類器の最後のレイヤーのみが異なるタスクを必要とする必要があります。
その結果、このモデルは一般的で非常に強力です。内の事前に訓練されたモデルに基づいて微調整することができます
短期間。
ただし、このモデルは非常に大きいです。シーケンス長128を使用すると、32のバッチサイズでのみトレーニングできます。長い間
シーケンス長512などのドキュメントでは、通常のGPU(11g)のバッチサイズ4をトレーニングできます。そして、非常に少数の人
訓練に何日もまたは数週間かかるので、このモデルをゼロから事前に訓練することができます、そして通常のGPUの記憶が小さすぎます
このモデルの場合。
特に、バックボーンモデルは変圧器であり、注意して見つけることができます。 2種類を使用します
モデルを事前にトレーニングするタスク。
一般的に言えば、文を考えると、単語の一部がマスクされているため、マスクされた単語を予測する必要があります
このマスクされた文に基づいています。マスクされた単語はランダムに選択されます。
ディープトランスエンコーダーを介して入力をフィードし、マスクに対応する最終的な非表示状態を使用します
言語モデルを訓練するのとまったく同じように、どんな単語がマスクされたかを予測するポジション。
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
質問の回答、推論、関係のような多くの言語理解タスクは、関係を理解する必要があります
文の間。ただし、言語モデルは文なしでのみ理解することができます。次の文
予測は、この種のタスクでモデルがよりよく理解できるようにするためのサンプルタスクです。
チャンスの50%2番目の文は、最初の文の次の文であり、次の文の50%です。
2文が与えられた場合、モデルは2番目の文が実際の次の文であるかどうかを予測するように求められます
最初のもの。
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
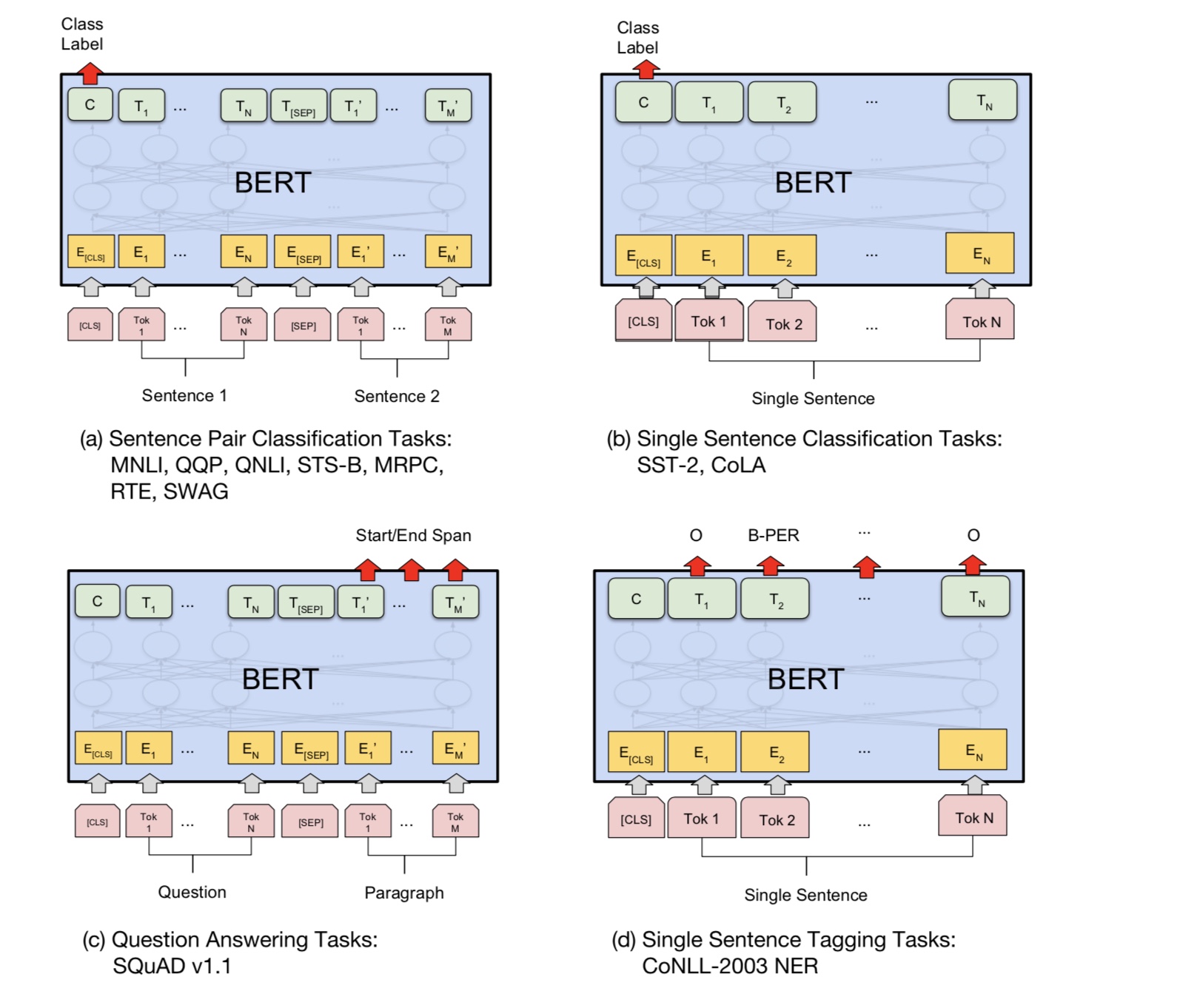
基本的に、事前に訓練されたモデルをダウンロードでき、独自のデータでタスクを微調整できます。
分類タスクの場合、プロセッサを追加して、ソースデータから入力とラベルを削減する形式を定義できます。
フォルダーa00_bertで次のコマンドを実行します。
python train_bert_multi-label.py
9エポックの後に0.368を達成します。または、bertを使用してダウンロード可能なデータでマルチラベル分類を実行することもできます
sentiment_analysis_fine_grain with bert
セッションとフィードスタイルを使用してモデルデータを復元してフィードデータを復元し、ロジットを取得してオンライン予測を作成できます。
バートとのオンライン予測
もともとは、オンラインではなく、ファイルに基づいてモデルをトレーニングまたは評価します。
まず、Googleから事前に訓練されたモデルダウンロードを使用できます。データセットでいくつかのエポックを実行して、適切なものを見つけます
シーケンス長。
第二に、に関連するデータセットを見つけることができる限り、あなたはあなた自身のデータでベースモデルを事前に訓練することができます
あなたのタスク、そしてあなたの特定のタスクを微調整します。
第三に、損失関数と最後のレイヤーを変更して、タスクにより適しています。
さらに、モデルがタスクをよりよく理解するのに役立つ事前に訓練されたタスクを定義することを追加できます。
実験から得られた経験があるように、事前に訓練されたタスクはモデルから独立しており、プリトレインは制限されていません
上記のタスク。
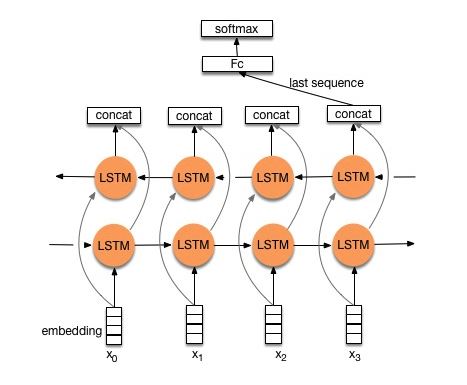
構造V1:埋め込み--->双方向LSTM ---> concat出力--->平均-----> SoftMaxレイヤー
チェック:p8_textrnn_model.py
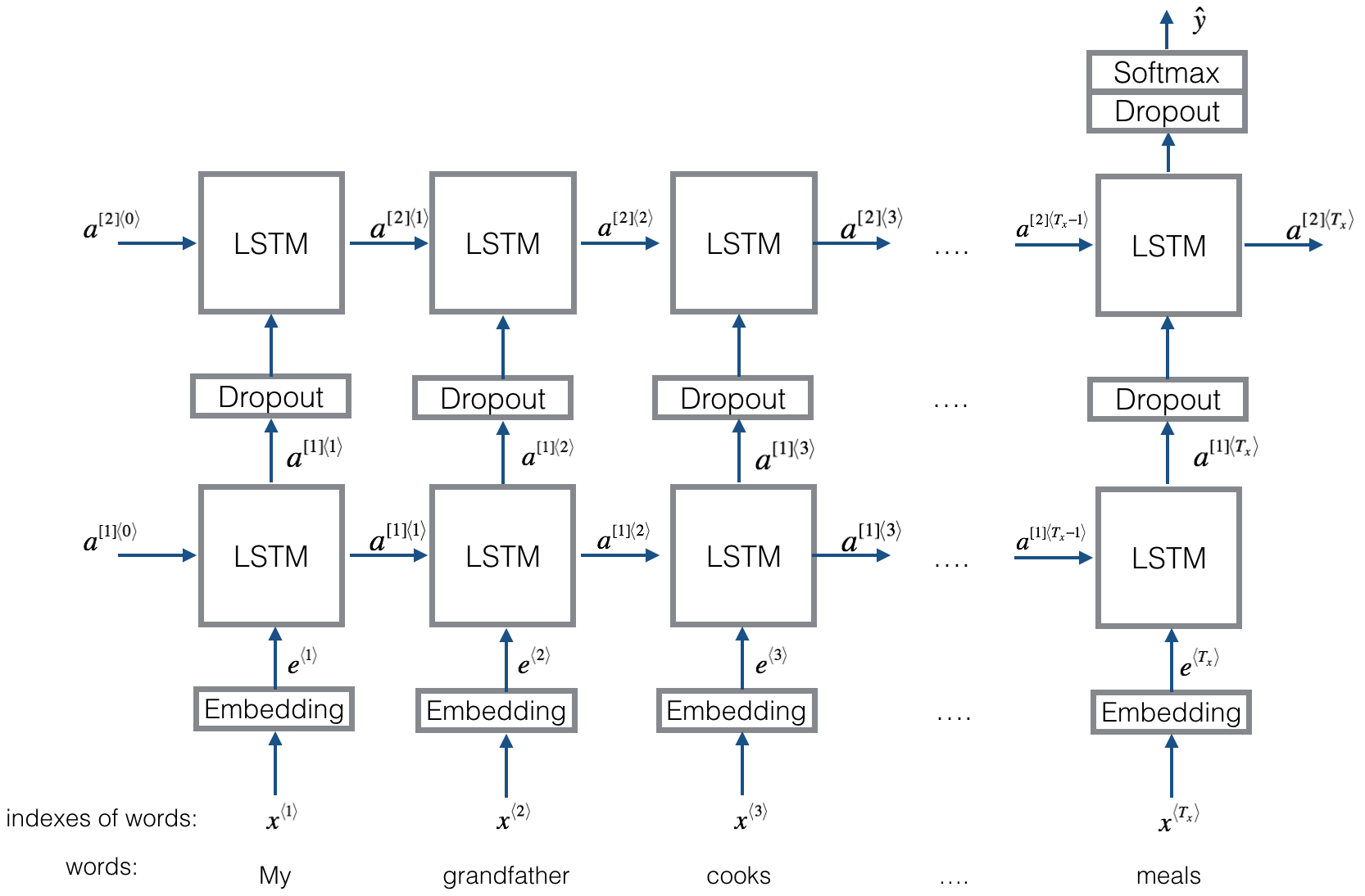
構造V2:埋め込み - >双方向LSTM ----->ドロップアウト - > concat ouput - > lstm - > droput-> fc layer-> softmaxレイヤー
チェック:P8_TEXTRNN_MODEL_MULTILAYER.py
textrnnと同じ構造。しかし、入力は特別な設計です。 EGINPUT:「コンピューターはいくらですか?ラップトップのEOS価格」。ここで、「EOS」は特別なトークンが質問1と質問2です。
チェック:p9_bilstmtextrelation_model.py
構造:最初に2つの異なる畳み込みを使用して、2つの文の特徴を抽出します。次に、2つの機能を連結します。線形変換層を使用して、ターゲットラベル、次にSoftMaxに投影を出力します。
チェック:p9_twocnntextrelation_model.py
構造:1つの文(get output1)の1つの双方向LSTM、別の文の別の双方向LSTM(get output2)。次に:softmax(output1m output2 )
チェック:p9_bilstmtextrelationtwornn_model.py
詳細については、チャットボットのディープラーニング、パート2 - Tensorflowで検索ベースのモデルの実装
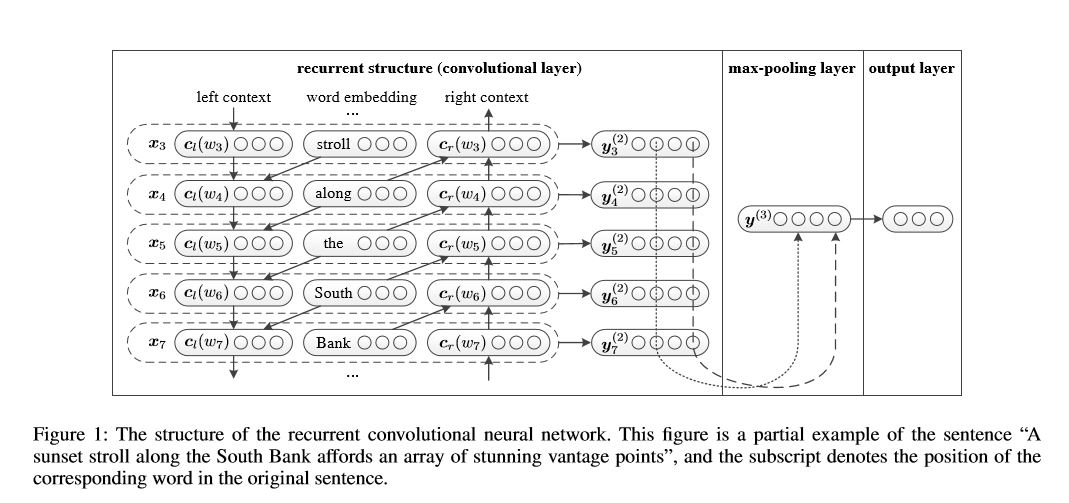
テキスト分類のための再発畳み込みニューラルネットワーク
テキスト分類のための再発畳み込みニューラルネットワークの実装
構造:1)再発構造(畳み込み層)2)最大プーリング3)完全に接続されたレイヤー+ソフトマックス
左側のコンテキストと右側のコンテキストを使用した文またはドキュメント内の各単語の表現を学習します。
表現current word = [left_side_context_vector、current_word_embedding、right_side_context_vecotor]。
左側のコンテキストでは、再発構造、以前の単語と左側の前のコンテキストの直線性のトランスフロムを使用します。右側のコンテキストと同様。
チェック:P71_TEXTRCNN_MODEL.py
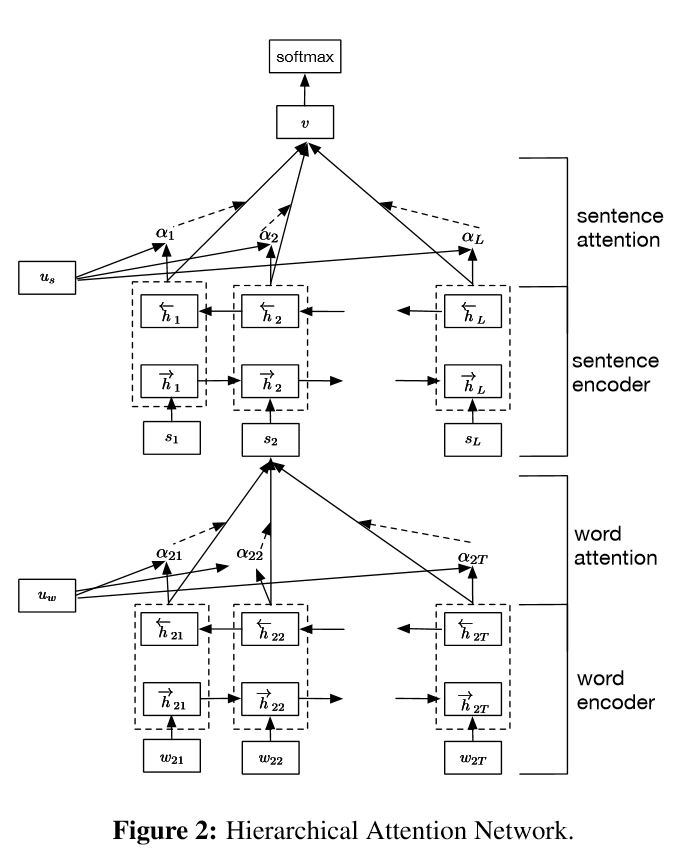
ドキュメント分類のための階層的な注意ネットワークの実装
構造:
埋め込み
単語エンコーダー:単語レベルの双方向GRUを取得する単語の豊かな表現を取得する
単語の注意:文で重要な情報を得るための単語レベルの注意
文エンコーダー:文の豊富な表現を得るための文レベルの双方向GRU
文の態度:文の間で重要な文を得るための文レベルの注意
FC+SoftMax
NLPでは、単一文でテキスト分類を行うことができますが、複数の文にも使用できます。ドキュメント分類と呼ぶことができます。単語は文の形です。文は文書化するフォームです。この状況では、本質的な構造が存在する可能性があります。それでは、この種のタスクをどのようにモデル化できますか?ドキュメントのすべての部分は等しく関連していますか?そして、どの部分が他の部分よりも重要であるかをどのように判断しますか?
2つのユニークな機能があります。
1)ドキュメントの階層構造を反映する階層構造があります。
2)単語と文レベルで使用される2つのレベルの注意メカニズムがあります。モデルが異なるレベルで重要な情報をキャプチャできるようになります。
単語エンコーダー:文の各単語について、分布ベクトル空間に単語ベクトルに埋め込まれます。双方向GRUを使用して文をエンコードします。 2方向からベクトルを連結することにより、文脈情報をキャプチャする文の表現を形成することができます。
単語の注意:同じ言葉は、文の他の言葉よりも重要です。したがって、注意メカニズムが使用されます。最初に1つのレイヤーMLPを使用して、文のUIT隠された表現を取得し、次にWordレベルコンテキストベクトルUWでUITの類似性として単語の重要性を測定し、SoftMax関数を通じて正規化された重要性を取得します。
文エンコーダー:文ベクトルの場合、双方向GRUを使用してエンコードします。 Wordエンコーダーと同様に。
文の注意:文レベルベクトルは、文の重要性を測定するために使用されます。同様にWordの注意と同様です。
データの入力:
一般的に言えば、このモデルの入力には、sinle文の代わりにサーバー文があるはずです。形状は次のとおりです。[なし、cente_lenght]。ここでは、batch_sizeを意味しません。
私のトレーニングデータには、例ごとに4つの部分があります。各部分には同じ長さがあります。 4つの部分を連結して、1つの文を形成します。モデルは文を4つの部分に分割し、形状のテンソルを形成します:[なし、num_sentence、cente_length]。ここで、num_sentenceは文の数です(私の設定では4に等しい)。
チェック:p1_hierarchicalattention_model.py
注意深い注意のために、注意深い注意をチェックできます
実装seq2seqは、共同で調整して翻訳することを学習することにより、神経機械の翻訳から派生した注意を払っています
I.Structure:
1)埋め込み2)bi-gruもソース文(前方および後方)から豊かな表現を取得します。 3)注意を払ったデコーダー。
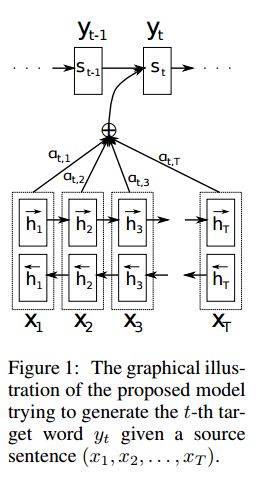
ii.データのインプット:
3種類の入力には2種類あります。1)エンコーダー入力、これは文です。 2)デコーダー入力は、固定長のラベルリストです; 3)ターゲットラベル、ラベルのリストでもあります。
たとえば、ラベルは次のとおりです。「L1 L2 L3 L4」、デコーダー入力は[_ go、l1、l2、l2、l3、_pad];ターゲットラベルは次のとおりです。[L1、L2、L3、L3、_END、_PAD]。長さは6に固定されており、ラベルが充填されていない場合は、ラベルを超えるラベルがトランサーになります。
iii.attentionメカニズム:
エンコーダー入力リストとデコーダーの非表示状態
各エンコーダー入力で非表示状態の類似性を計算して、各エンコーダ入力の可能性分布を取得します。
可能性分布に基づくエンコーダー入力の加重合計。
この重量合計を使用してデコーダー入力を使用してRNNセルに移動して、新しい非表示状態を取得します
IV.バニラエンコーダーデコーダーの動作方法:
ソース文は、RNNを固定サイズベクトル(「思考ベクトル」)として使用してエンコードされます。次に、デコーダー中:
トレーニングの場合、この「思考ベクトル」をinit状態として使用して単語を取得し、各タイムスタンプでデコーダー入力から入力を取得するために、別のRNNが使用されます。デコーダー特別トークン「_go」から起動します。 1つのステップが実行された後、新しいHidden状態が取得され、新しい入力と一緒になります。特別なトークン「_end」に到達するまでこのプロセスを継続できます。ロジットのクロスエントロピー損失とターゲットラベルを計算することにより、損失を計算できます。ロジットは、隠された状態の投影層を通過します(デコーダーステップの出力の場合(GRUでは、デコーダーからの非表示状態を出力として使用できます)。
テストしているとき、ラベルはありません。したがって、以前のタイムスタンプから得られる出力に供給し、「_end」トークンに到達したプロセスを続行する必要があります。
V.Notices:
ここでは、2種類の語彙を使用します。 1つは、エンコーダで使用される単語からです。もう1つは、デコーダーで使用されるラベル用です
レーブルの語彙については、3つの特別なトークンを挿入します: "_ go"、 "_ end"、 "_ pad";すべてのラベルが事前に定義されているため、「_unk」は使用されていません。
ステータス:タスク分類を行うことができました。おもちゃのタスクでそのシーケンスの逆の順序を生成することができます。モデルでテスト機能を実行して確認できます。チェック:a2_train_classification.py(トレイン)またはa2_transformer_classification.py(model)
Layerの正規化、残留接続、およびマスクもモデルで使用されます。
すべてのビルディングブロックについて、以下の各ファイルにテスト関数を含め、各小さなピースを正常にテストしました。
注意を払ったシーケンスへのシーケンスは、翻訳、ダイアログシステムなどのシーケンス生成の問題を解決するための典型的なモデルです。ほとんどの場合、これらのタスクを実行するためにRNNをブイドリングブロックとして使用します。最近、人々はシーケンスの問題にシーケンスのために畳み込みニューラルネットワークを適用します。ただし、トランスはこれらのタスクを注意メカンシムのみに実行します。それは速く、新しい最先端の結果を達成しています。
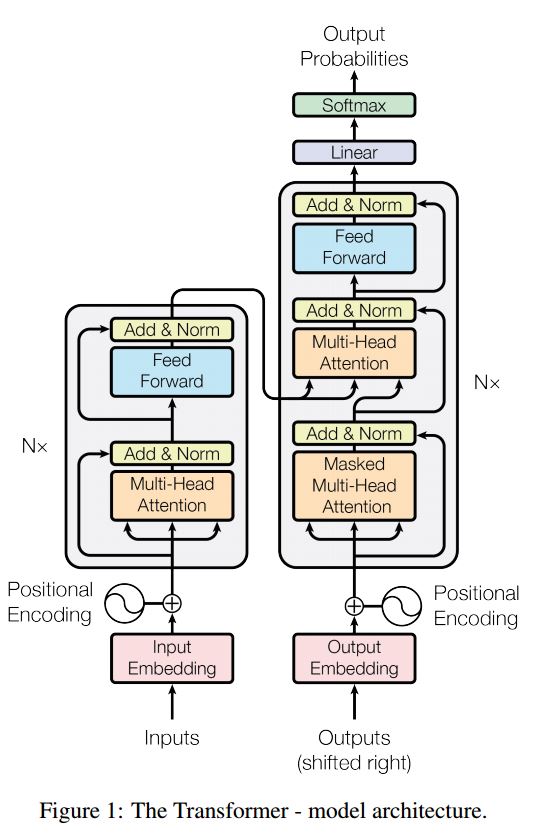
また、エンコーダーとデコーダーの2つの主要な部分もあります。以下は紙からのdescです:
エンコーダー:
6レイヤー。 1つ目は、マルチヘッドの自己関節メカニズムです。 2つ目は、位置的に完全に接続されたフィードフォワードネットワークです。各サブレイヤーに対して。 layernorm(x+sublayer(x))を使用します。すべての寸法= 512。
デコーダ:
このモデルからのメインテイク:
このモデルを使用して、タスク分類を行います。
ここでは、タスク分類にエンコードパーツのみを使用し、1レイヤーのみを使用して、マスクを使用する必要はありません。マルチヘッドの注意を使用して、ポストションワイズフィードを前方にフィードして入力文の特徴を抽出し、線形層を使用してロジットを取得するためにそれを投影します。
モデルの詳細については、a2_transformer_classification.pyを確認してください
入力:1。ストーリー:コンテキストとしてのマルチセンテンスです。 2.クエリ:質問である文、3。Ansewr:単一のラベル。
モデル構造:
入力エンコード:単語の袋を使用して、ストーリー(コンテキスト)とクエリ(質問)をエンコードします。位置マスクを使用して位置を考慮してください
双方向RNNを使用してストーリーとクエリをエンコードすることにより、パフォーマンスが0.392から0.398に向上し、1.5%増加します。
動的メモリ:
a。キーの「類似性」を使用してゲートを計算し、ストーリーの入力を含む値を使用します。
b。各キー、価値、入力を変換することにより、候補者を隠した状態にします。
c。ゲートと候補者の非表示状態を組み合わせて、現在の隠された状態を更新します。
b。可能性分布を使用して、隠された状態の加重合計を取得します。
c。予測ラベルを取得するためのクエリと非表示状態の非線形性変換。
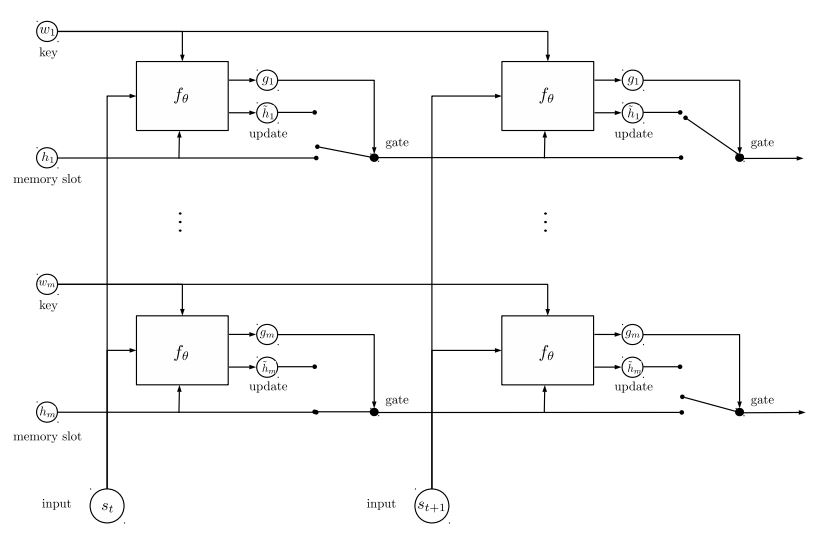
このモデルからのメインテイク:
互いに独立したキーと値のブロックを使用します。そのため、並行して実行できます。
コンテキストと質問を一緒にモデリングします。メモリを使用して、世界の状態を追跡します。隠された状態と質問(クエリ)の非線形性変換を使用して、予測を行います。
シンプルなモデルは、非常に優れたパフォーマンスを実現できます。単語のバッグを使用するように単純なエンコード。
モデルの詳細については、a3_entity_network.pyを確認してください
このモデルの下には、テスト関数があり、このモデルにストーリー(コンテキスト)とクエリ(質問)の両方に数値をカウントするように依頼します。しかし、ストーリーの重みはクエリよりも小さいです。
モデルの見通し:
1.インプットモジュール:生のテキストをベクトル表現にエンコードします
2.質問モジュール:質問をベクトル表現にエンコードします
3.エピソードメモリモジュール:入力を使用すると、質問と以前のメモリを考慮して、注意メカニズムを通じて焦点を合わせる入力の部分を選択します。
4.回答モジュール:最終的なメモリベクトルから回答を生成します。
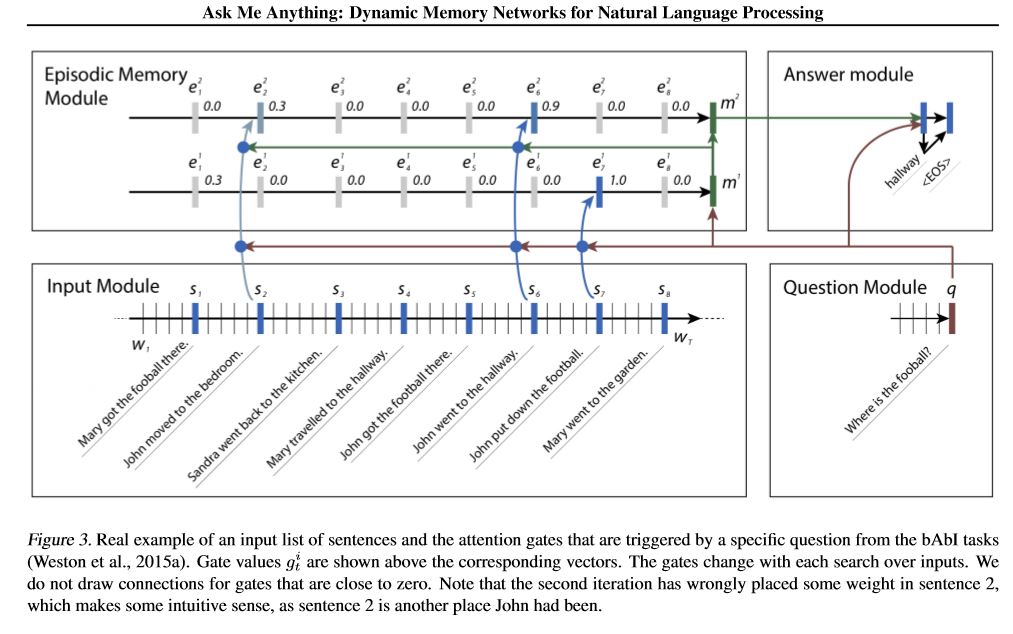
詳細:
1.インプットモジュール:
A.Single文:GRUを使用して隠された状態を取得します。文のリスト:GRUを使用して、各文の非表示状態を取得します。例[Hidden States 1、Hidden States 2、Hidden States ...、Hidden State n]
2.質問モジュール:GRUを使用して隠された状態を取得します
3.エピソードメモリモジュール:
注意メカニズムと再発ネットワークを使用して、そのメモリを更新します。
a。注意メカニズムとしてのゲート:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B.メモリの更新メカニズム:候補の文、ゲート、および以前の隠された状態を取り、Gated-Gruを使用して非表示状態を更新します。 like:h = f(c、h_previous、g)。最後の隠された状態は、回答モジュールの入力です。
C.複数のエピソードの必要===>推移的推論。
たとえば、サッカーはどこにありますか? 「ジョンはサッカーを落とした」という文に出席し、2回目のパスでは、ジョンの場所に出席する必要があります。
4.回答モジュール:最終的なepsoidicメモリ、質問をして、回答モジュールの隠された状態を更新します。
1.テキスト分類のためのCharacter-Level畳み込みネットワーク
2.テキスト分類のためのコンボリューションニューラルネットワーク:浅い単語レベルとディープキャラクターレベル
3.テキスト分類のための非常に深い畳み込みネットワーク
4.半監視テキスト分類のための逆数トレーニング方法
5.イネ型モデル
大規模なマルチラベル分類を行う過程で、サーバーレッスンが学習され、以下のリストがいくつかあります。
高い精度に達するために最も重要なことは何ですか?それはあなたがしているタスクに依存します。ここで実施したタスクから、単語、タイトルのキャラクター、説明を含む複数の機能からトレーニングされたモデルに基づいたアンサンブルモデルは、非常に高いaccuarcyに到達するのに役立つと考えています。ただし、場合によっては、Alphago Zeroが実証したように、アルゴリズムはデータや計算能力よりも重要です。実際、Alphago ZeroはHumamデータを使用しませんでした。
特定のモデルまたはアルゴリズムの上限はありますか?答えはイエスです。ここでは多くの異なるモデルが使用されていましたが、構造がまったく異なっているにもかかわらず、多くのモデルが同様のパフォーマンスを持っていることがわかりました。ある程度、パフォーマンスの違いはそれほど大きくありません。
エラーのケーススタディは有用ですか?特に多くの異なることをしたことがあるが、制限に達したとき、それは非常に便利だと思います。たとえば、ケーススタディを行うことで、モデルが正しい予測を行うことができ、どこで間違いを犯すかというラベルを見つけることができます。また、これらの間違った予測されたラベルの重みを増やしたり、データから潜在的なエラーを見つけたりすることにより、パフォーマンスを輸入します。
どうすれば機械学習の特定の専門家になることができますか?私の意見では、機械学習能力に参加するか、多くのデータを使用してタスクを開始してから、論文を読んでいくつかを実装することは良い出発点です。したがって、特定のタスクを処理するいくつかの実際の経験とアイデアがあり、それの課題を知っています。しかし、さらに重要なのは、論文からのアイデアに従うだけでなく、問題を緩和するのに役立つと思われるいくつかの新しいアイデアを探るべきだということです。たとえば、古典的なモデルの構造を変更したり、いくつかの新しい構造を発明することで、私たちが行っているタスクにより適している可能性があるため、問題により良い方法で取り組むことができます。
1.効率的なテキスト分類のためのトリックのバグ
2.文化分類のための構成的ニューラルネットワーク
3.文化分類のための畳み込みニューラルネットワークの(および開業医ガイド)の感度分析
4.チャットボットのディープラーニング、パート2 - www.wildml.comからTensorflowで検索ベースのモデルを実装する
5.テキスト分類のための再流行畳み込みニューラルネットワーク
6.ドキュメント分類のためのhierarchical注意ネットワーク
7.共同で整列して翻訳することを学ぶことによるネーラルの機械翻訳
8.必要なすべてです
9.何でも尋ねる:自然言語処理のための動的メモリネットワーク
10.リカレントエンティティネットワークで世界の状態を追跡します
11.モデルのライブラリからの選択
12.BERT:言語理解のための深い双方向変圧器の事前訓練
13.Google-Research/Bert
つづく。いずれかの問題については、concat [email protected]


