text_classification
1.0.0
الغرض من هذا المستودع هو استكشاف أساليب تصنيف النص في NLP مع التعلم العميق.
تخصيص واجهة برمجة تطبيقات NLP في ثلاث دقائق ، مجانًا: NLP API Demo
معايير تقييم فهم اللغة للصينيين (معيار فكرة): قم بتشغيل 10 مهام و 9 خطوط أساسية مع سطر واحد من التعليمات البرمجية ، ومقارنة الأداء مع التفاصيل.
إطلاق نموذج تدريب مسبقًا للتدريب على Albert_Chinese مع 3G+ Raw الصيني ، XXLarge ، XLARGE وأكثر من ذلك ، هدف مطابقة الأداء الصيني ، 2019-OCT-7 ، خلال اليوم الوطني للصين!
كمية كبيرة من المجموعة الصينية لـ NLP المتاحة!
حقق BERT من Google نتيجة جديدة من الفنون على أكثر من 10 مهام في NLP باستخدام ما قبل التدريب في نموذج اللغة بعد ذلك
الكون المثالى. Texcnn قبل التدريب: فكرة من Bert لفهم اللغة مع تشغيل التعليمات البرمجية ومجموعة البيانات
لديها جميع أنواع النماذج الأساسية لتصنيف النص.
كما أنه يدعم تصنيف العلامات المتعددة حيث تربط العلامات المتعددة مع جملة أو وثيقة.
على الرغم من أن العديد من هذه النماذج بسيطة ، وقد لا تنقلك إلى المستوى الأعلى للمهمة. لكن بعض هذه النماذج جدا
الكلاسيكية ، لذلك قد يكون من الجيد أن تكون نماذج أساسية. كل نموذج لديه وظيفة اختبار ضمن فئة النموذج. يمكنك الجري
انها مهمة لعبة الأداء أولا. النموذج مستقل عن مجموعة البيانات.
تحقق هنا للحصول على تقرير رسمي عن تصنيف النص متعدد الملصقات على نطاق واسع مع التعلم العميق
يمكن أيضًا استخدام العديد من النماذج هنا في الإجابة على أسئلة النمذجة (مع أو بدون سياق) ، أو للقيام بتوليد تسلسلات.
نستكشف نموذجين seq2seq (SEQ2Seq مع الاهتمام ، والتحول هو كل ما تحتاجه) للقيام بتصنيف النص.
ويمكن أيضًا استخدام هذين النموذجين لتوليد التسلسلات والمهام الأخرى. إذا كانت مهمتك عبارة عن تصنيف متعدد العلامات
يمكنك إلقاء المشكلة على توليد التسلسلات.
نحن ننفذ شبكة ذاكرة. واحد هو شبكة الذاكرة الديناميكية. في السابق وصلت إلى حالة فنية في السؤال
الرد ، تحليل المشاعر ومهام توليد التسلسل. يطلق عليه نموذج واحد للقيام بعدة مهام مختلفة ،
والوصول إلى الأداء العالي. لديها أربع وحدات. المكون الرئيسي هو وحدة الذاكرة العرضية. يستخدم آلية البوابة ل
انتباه الأداء ، واستخدم بوابات الجرو لتحديث ذاكرة الحلقة ، ثم يحتوي على GRU آخر (في اتجاه عمودي) إلى
تحديث الحالة المخفية للأداء. لديها القدرة على القيام بالاستدلال العابر.
شبكة الذاكرة الثانية التي قمنا بتنفيذها هي شبكة الكيانات المتكررة: تتبع حالة العالم. لديها كتل من
أزواج القيمة الرئيسية كذاكرة ، تسير بالتوازي ، والتي تحقق حالة فنية جديدة. يمكن استخدامه لنمذجة سؤال
الرد مع السياقات (أو التاريخ). على سبيل المثال ، يمكنك السماح للنموذج بقراءة بعض الجمل (كسياق) ، واطلب أ
سؤال (كاستعلام) ، ثم اطلب النموذج للتنبؤ بإجابة ؛ إذا قمت بإطعام قصة نفس الاستعلام ، فيمكنها القيام بذلك
مهمة التصنيف.
لمناقشة مشاكل ML/DL/NLP والحصول على الدعم الفني من بعضها البعض ، يمكنك الانضمام إلى مجموعة QQ: 836811304
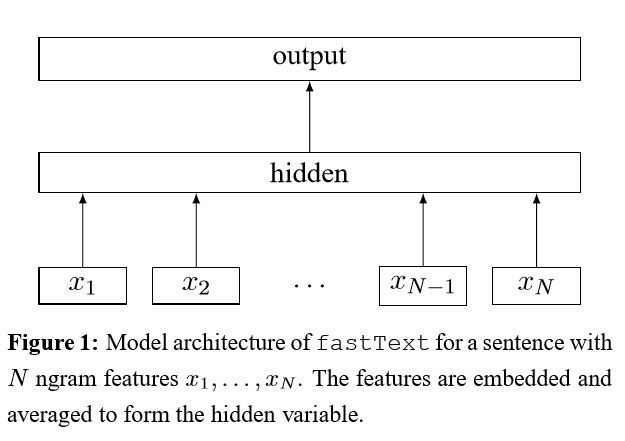
fasttext
TextCnn
بيرت: ما قبل التدريب من محولات ثنائية الاتجاه العميقة لفهم اللغة
Textrnn
rcnn
شبكة الاهتمام الهرمية
SEQ2SEQ مع الاهتمام
المحول ("الحضور هو كل ما تحتاجه")
شبكة الذاكرة الديناميكية
entitynetwork: تتبع حالة العالم
نماذج الفرقة
التعزيز:
لنموذج واحد ، مكدس النماذج المتطابقة معا. كل طبقة هي نموذج. ستستند النتيجة إلى سجلات الأشكال معًا. العلاقة الوحيدة بين الطبقات هي أوزان التسمية. سيصبح معدل خطأ التنبؤ في الطبقة الأمامية لكل تسمية الوزن للطبقات التالية. تلك الملصقات ذات معدل الخطأ المرتفع سيكون لها وزن كبير. لذا ، ستولي Layer في وقت لاحق المزيد من الاهتمام لتلك الملصقات التي تم تساقطها ، ومحاولة إصلاح الخطأ السابق للطبقة السابقة. نتيجة لذلك ، سنحصل على نموذج قوي. تحقق من A00_Boosting/BOOSTING.PY
ونماذج أخرى:
bilstmtextrelation.
twocnntextrelation.
bilstmtextrelationtwornn
(مهمة التنبؤ بتسمية Mulit-Label ، اطلب التنبؤ Top5 ، 3 ملايين بيانات التدريب ، النتيجة الكاملة: 0.5)
| نموذج | fasttext | TextCnn | Textrnn | rcnn | Hierattenet | Seq2Seqattn | entitynet | DynamicMemory | محول |
|---|---|---|---|---|---|---|---|---|---|
| نتيجة | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| تمرين | 10 م | 2H | 10H | 2H | 2H | 3H | 3H | 5H | 7H |
يحقق نموذج Bert 0.368 بعد أول 9 حقبة من مجموعة التحقق من الصحة.
فرقة TextCnn ، entitynet ، DynamicMemory: 0.411
Ensemble entitynet ، DynamicMemory: 0.403
يلاحظ:
m يقف لدقائق . h يقف لساعات ؛
HierAtteNet تعني الاهتمام الهرمي networkk ؛
Seq2seqAttn يعني seq2seq مع الاهتمام.
DynamicMemory تعني DynamicMemoryNetwork ؛
Transformer Stand for Model من "الانتباه هو كل ما تحتاجه".
xxx_model.pyxxx_train.py لتدريب النموذجxxx_predict.py للقيام بالاستدلال (اختبار).كل نموذج لديه طريقة اختبار ضمن فئة النموذج. يمكنك تشغيل طريقة الاختبار أولاً للتحقق مما إذا كان النموذج يمكن أن يعمل بشكل صحيح.
Python 2.7+ Tensorflow 1.8
(يجب أن يعمل TensorFlow 1.1 إلى 1.13 أيضًا ؛ يجب أن تعمل معظم النماذج أيضًا بشكل جيد في إصدار TensorFlow الآخر ، لأننا نحن
استخدم عدد قليل جدًا من الميزات الرابطة لإصدار معين.
إذا كنت تستخدم Python3 ، فسيكون الأمر جيدًا طالما قمت بتغيير وظيفة الطباعة/المحاولة في حالة تلبية أي خطأ.
تم نقل نموذج TextCnn بالفعل إلى Python 3.6
لمساعدتك في تشغيل هذا المستودع ، نقوم حاليًا بإعادة تجميع بيانات التدريب/التحقق/الاختبار والمفردات/الملصقات ، وحفظها
لهم كملف ذاكرة التخزين المؤقت باستخدام H5Py. نقترح عليك تنزيله من الرابط أعلاه.
إنه يحتوي على كل ما تحتاجه لتشغيل هذا المستودع: البيانات معالجة مسبقًا ، يمكنك البدء في تدريب النموذج في دقيقة واحدة.
إنه ملف مضغوط حوالي 1.8 جم ، يحتوي على 3 ملايين بيانات تدريب. على الرغم من أنه بعد فك الضغط ، إلا أنه كبير جدًا ، ولكن بمساعدة من
HDF5 ، لا يحتاج إلا إلى حجم طبيعي لذاكرة الكمبيوتر (EG8 G أو أقل) أثناء التدريب.
نستخدم دفتر Jupyter Notebook: precessing.ipynb لبيانات العملية المسبقة. يمكنك الحصول على فهم أفضل لهذه المهمة و
البيانات عن طريق إلقاء نظرة عليه. يمكنك أيضًا إنشاء بيانات بنفسك بالطريقة التي تريدها ، فقط قم بتغيير أسطر قليلة من التعليمات البرمجية
باستخدام دفتر الملاحظات Jupyter هذا.
إذا كنت ترغب في تجربة نموذج الآن ، فيمكنك Dowload Cached File من الأعلى ، ثم انتقل إلى المجلد "A02_TextCnn" ، قم بتشغيله
python p7_TextCNN_train.py
سيستخدم البيانات من الملفات المخزنة مؤقتًا لتدريب النموذج ، وطباعة فقدان النتيجة F1 بشكل دوري.
مصدر بيانات العينة القديم: إذا كنت بحاجة إلى بعض البيانات وتضمين الكلمات لكل تدريب على Word2Vec ، فيمكنك العثور عليها في مشكلات مغلقة ، مثل: العدد 3.
يمكنك أيضًا العثور على بعض البيانات في المجلد "البيانات". أنه يحتوي على ملفين: 'sample_single_label.txt' ، يحتوي على 50 ألف بيانات
مع تسمية واحدة ؛ "sample_multiple_label.txt" ، يحتوي على 20K بيانات مع ملصقات متعددة. إدخال وتسمية منفصلة بواسطة " Label ".
إذا كنت ترغب في معرفة المزيد من التفاصيل حول مجموعة بيانات تصنيف النص أو المهمة ، فيمكن استخدام هذه النماذج ، واحدة من الاختيار أدناه:
https://biendata.com/competition/zhihu/
إحدى الطرق التي يمكنك من خلالها استخدام هذا المستودع:
الخطوة 1: يمكنك قراءة هذه المقالة. ستحصل على فكرة عامة عن مختلف النماذج الكلاسيكية المستخدمة للقيام بتصنيف النص.
الخطوة 2: البيانات المسبقة و/أو تنزيل الملف المخبوق.
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
الخطوة 3: قم بتشغيل بعض قائمة الطرز هنا ، وقم بتغيير بعض الرموز والتكوينات كما تريد ، للحصول على أداء جيد.
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
بالإضافة إلى ذلك ، اكتب مقالتك حول هذا الموضوع ، يمكنك اتباع نمط الورق للكتابة. قد تحتاج إلى قراءة بعض الأوراق
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
استبدل البيانات في "Data/sample_multiple_label.txt" ، وتأكد من التنسيق على النحو التالي:
'Word1 Word2 Word3 __label__l1 __label__l2 __label__l3'
حيث part1: 'Word1 Word2 Word3' هو الإدخال (x) ، part2: '__label__l1 __label__l2 __label__l3'
تمثل هناك ثلاث علامات: [L1 ، L2 ، L3]. بين Part1 و Part2 يجب أن يكون هناك سلسلة فارغة: ''.
على سبيل المثال: كل سطر (ملصقات متعددة) مثل:
'W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 c699 C317 __label____8904735555009151318 '
حيث '5626661657638885119' ، '4921793805334628695' , '89047355555009151318' هي ثلاثة ملصقات مشتركة مع سلسلة الإدخال هذه "W5466 W138990 ... C699 C184"
يلاحظ:
بعض وظيفة util موجودة في data_util.py ؛ تحقق من load_data_multilabel () من Data_Util للحصول على كيفية إدخال وعلامات المعالجة من البيانات الأولية.
هناك دالة لتحميل وتعيين كلمة تضمين الكلمات المسبقة على النموذج ، حيث يتم تضمين الكلمات في Word2Vec أو FastText.
إذا كان Word2Vec.Load لا يعمل ، فيمكنك تحميل تضمين الكلمات المسبق ، وخاصةً لضمان تضمين الكلمات الصينية الخطوط التالية:
استيراد Gensim
من gensim.models استيراد keyedvectors
word2vec_model = keyedVectors.load_word2vec_format (word2vec_model_path ، binary = true ، unicode_errors = 'تجاهل') #
أو يمكنك إيقاف تشغيل استخدام علامة تضمين كلمة ما قبل الكلمة لتدوين تضمين كلمة التحميل.
تنفس حقيبة الحيل لتصنيف النص الفعال
بعد تضمين كل كلمة في الجملة ، يتم حساب متوسط تمثيل الكلمة هذه إلى تمثيل نص ، والذي بدوره يتم تغذيته إلى مصنف خطي. استخدام وظيفة softmax لحساب توزيع الاحتمالات على الفئات المحددة مسبقًا. ثم يتم استخدام الانتروبيا المتقاطعة لحساب الخسارة. كيس تمثيل الكلمات لا يعتبر ترتيب الكلمات. من أجل مراعاة ترتيب الكلمات ، يتم استخدام ميزات N-Gram لالتقاط بعض المعلومات الجزئية حول ترتيب الكلمات المحلي ؛ عندما يكون عدد الفئات كبيرًا ، فإن حساب المصنف الخطي مكلف. لذلك فهو softmax usehierarchical لتسريع عملية التدريب.
النتيجة: الأداء جيد مثل الورق ، والسرعة أيضا بسرعة كبيرة.
تحقق: p5_fasttextb_model.py
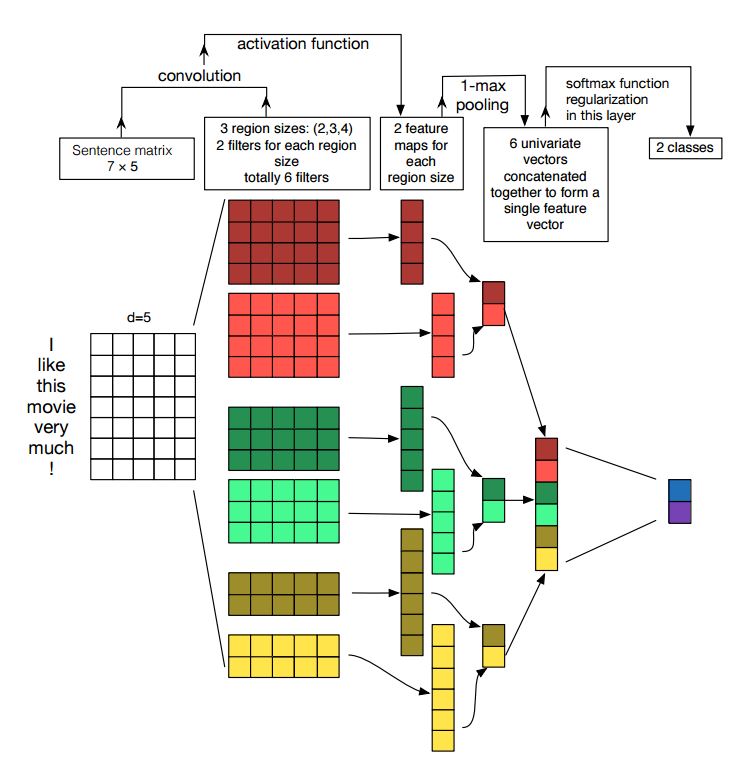
تنفيذ الشبكات العصبية التلافيفية لتصنيف الجملة
الهيكل: التضمين ---> Conv ---> Max Pooling ---> طبقة متصلة بالكامل --------> softmax
تحقق: p7_textcnn_model.py
من أجل الحصول على نتيجة جيدة للغاية مع TextCnn ، تحتاج أيضًا إلى القراءة بعناية حول هذه الورقة تحليل حساسية للشبكات العصبية التنازلية (ودليل الممارسين) لتصنيف الجملة: يمنحك بعض الأفكار للأشياء التي يمكن أن تؤثر على الأداء. على الرغم من أنك بحاجة إلى تغيير بعض الإعدادات وفقًا لمهمتك المحددة.
الشبكة العصبية التلافيفية هي صندوق بناء رئيسي لحل مشاكل رؤية الكمبيوتر. الآن سوف نوضح كيف يمكن استخدام CNN في NLP ، على وجه الخصوص ، تصنيف النص. سيكون طول الجملة مختلفًا عن واحد إلى آخر. لذلك سوف نستخدم PAD للحصول على طول ثابت ، ن. لكل رمز في الجملة ، سوف نستخدم تضمين الكلمات للحصول على ناقل الأبعاد الثابت ، د. لذلك فإن مدخلاتنا هي مصفوفة ثنائية الأبعاد: (N ، D). هذا مشابه مع صورة CNN.
أولاً ، سنقوم بتشغيل تلغيرات لمدخلاتنا. إنه عنصر مضاعف بين المرشح وجزء من الإدخال. نستخدم عدد المرشحات K ، كل حجم مرشح هو مصفوفة ثنائية الأبعاد (F ، D). الآن سيكون الإخراج عدد من القوائم. كل قائمة لها طول N-F+1. كل عنصر هو العددية. لاحظ أن البعد الثاني سيكون دائمًا بعد تضمين الكلمات. نحن نستخدم حجم مختلف من المرشحات للحصول على ميزات غنية من مدخلات النص. وهذا شيء مشابه لميزات N-Gram.
ثانياً ، سنقوم بتجميع الحد الأقصى لإخراج العملية التلافيفية. بالنسبة لعدد القوائم K ، سنحصل على عدد من العدادات.
ثالثًا ، سنقوم بتسلسل الأرقام لتشكيل الميزات النهائية. إنه متجه ثابت الحجم. وهي مستقلة عن حجم المرشحات التي نستخدمها.
أخيرًا ، سوف نستخدم الطبقة الخطية لإسقاط هذه الميزات إلى الملصقات المحددة لكل.
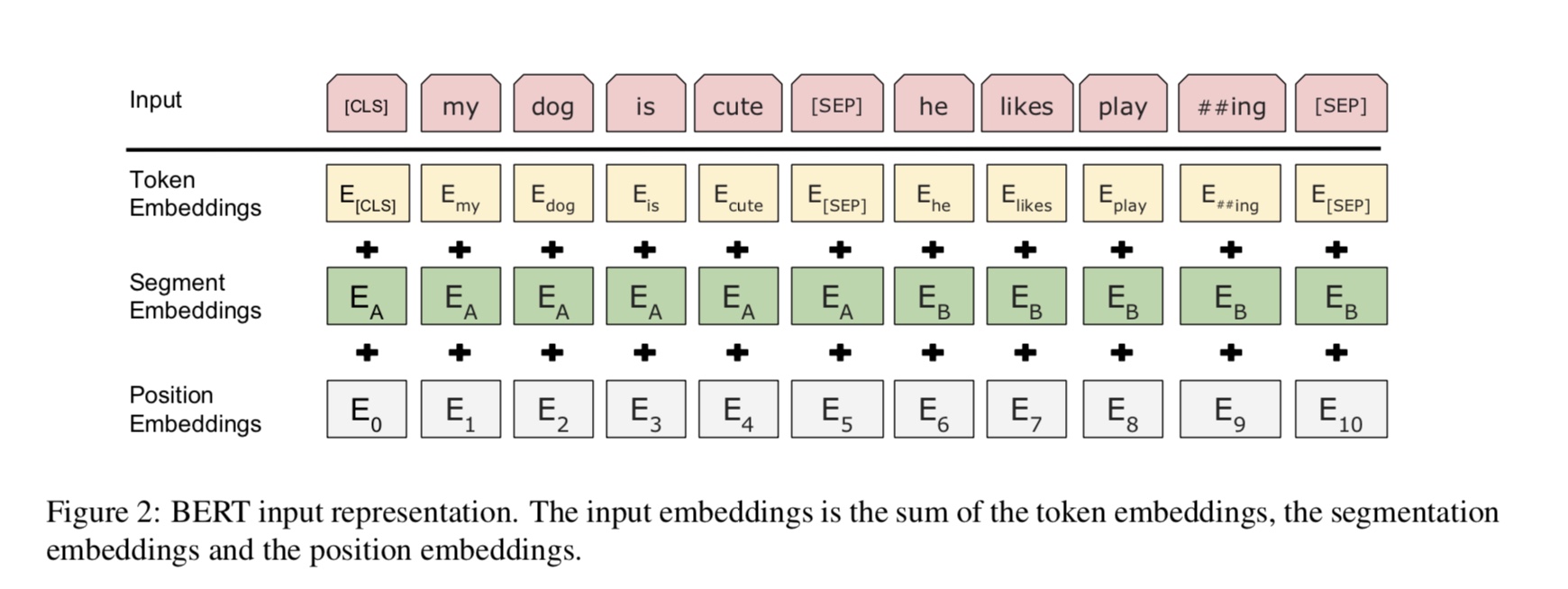
BERT يحقق حاليًا نتائج الحالة الفنية على أكثر من 10 مهام NLP. الأفكار الرئيسية وراء هذا النموذج هي أننا نستطيع
قبل تدريب النموذج باستخدام نوع واحد من نموذج اللغة مع كمية هائلة من البيانات الخام ، حيث يمكنك العثور عليه بسهولة.
نظرًا لأن معظم معلمات النموذج مدربة مسبقًا ، فإن الطبقة الأخيرة فقط للمصنف تحتاج إلى أن تكون بحاجة إلى مهام مختلفة.
نتيجة لذلك ، هذا النموذج عام وقوي للغاية. يمكنك فقط التكييف بناءً على النموذج الذي تم تدريبه مسبقًا في الداخل
فترة زمنية قصيرة.
ومع ذلك ، هذا النموذج كبير جدا. مع طول التسلسل 128 ، قد تتمكن فقط من التدريب بحجم دفعة 32 ؛ لفترة طويلة
وثيقة مثل طول التسلسل 512 ، يمكنه فقط تدريب حجم الدُفعة 4 على وحدة معالجة الرسومات العادية (مع 11G) ؛ وعدد قليل جدا من الناس
يمكن تدريب هذا النموذج مسبقًا من نقطة الصفر ، حيث يستغرق التدريب عدة أيام أو أسابيع ، وذاكرة GPU العادية صغيرة جدًا
لهذا النموذج.
على وجه الخصوص ، نموذج العمود الفقري هو محول ، حيث يمكنك العثور عليه في الانتباه هو كل ما تحتاجه. يستخدم نوعين من
مهام لتدريب النموذج مسبقًا.
بشكل عام ، بالنظر إلى جملة ، يتم إخفاء بعض النسبة المئوية من الكلمات ، وستحتاج إلى التنبؤ بالكلمات المقنعة
بناء على هذه الجملة المقنعة. يتم اختيار الكلمات المقنعة بشكل عشوائي.
نقوم بتغذية المدخلات من خلال تشفير محول عميق ثم نستخدم الحالات المخفية النهائية المقابلة للقناع
مواقف للتنبؤ بالكلمة التي تم إخفاءها ، تمامًا كما كنا سنقوم بتدريب نموذج اللغة.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
العديد من مهمة فهم اللغة ، مثل الإجابة على الأسئلة ، والاستدلال ، تحتاج إلى فهم العلاقة
بين الجملة. ومع ذلك ، فإن نموذج اللغة قادر فقط على الفهم بدون جملة. الجملة القادمة
التنبؤ بمهمة عينة للمساعدة في فهم النموذج بشكل أفضل في هذه الأنواع من المهام.
50 ٪ من الصدفة على الجملة الثانية هي الجملة التالية من أول واحد ، 50 ٪ من ليست الجمل التالية.
بالنظر إلى جملة ، يُطلب من النموذج التنبؤ بما إذا كانت الجملة الثانية هي الجملة القادمة الحقيقية
الأول.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
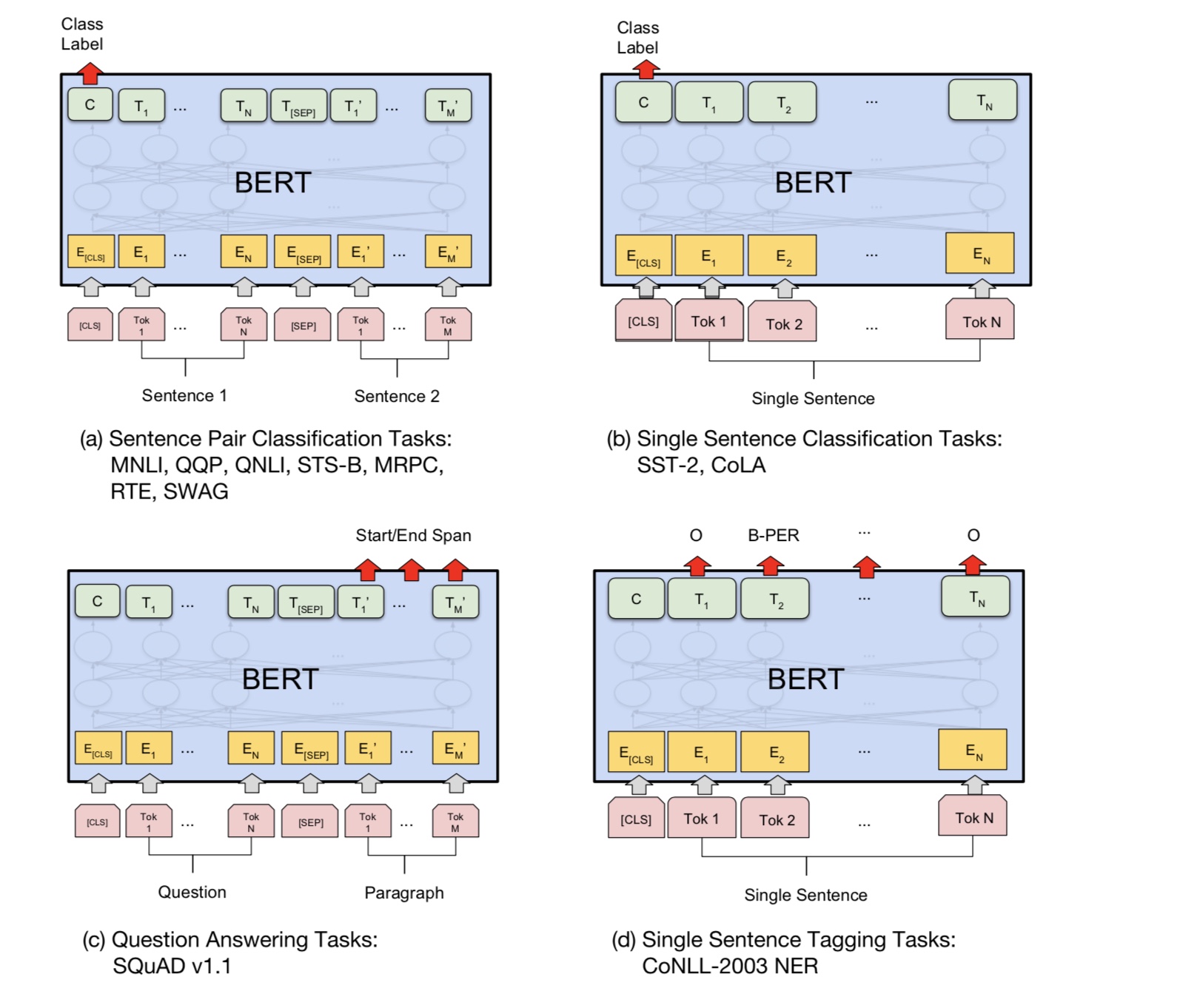
في الأساس ، يمكنك تنزيل النموذج الذي تم تدريبه مسبقًا ، ويمكنك فقط ضبط مهمتك مع بياناتك الخاصة.
لمهمة التصنيف ، يمكنك إضافة معالج لتحديد التنسيق الذي تريد السماح للإدخال والملصقات من بيانات المصدر.
قم بتشغيل الأمر التالي ضمن المجلد A00_bert:
python train_bert_multi-label.py
أنه يحقق 0.368 بعد 9 عصر. أو يمكنك تشغيل تصنيف متعدد العطلة مع بيانات قابلة للتنزيل باستخدام BERT من
sument_analysis_fine_grain مع Bert
يمكنك استخدام نمط الجلسة والتغذية لاستعادة النموذج وتغذية البيانات ، ثم الحصول على سجلات لإجراء تنبؤ عبر الإنترنت.
التنبؤ عبر الإنترنت مع بيرت
في الأصل ، يقوم بتدريب أو تقييم النموذج على أساس الملف ، وليس للإنترنت.
أولاً ، يمكنك استخدام تنزيل النموذج الذي تم تدريبه مسبقًا من Google. قم بتشغيل عدد قليل من الحقبة على مجموعة البيانات ، وابحث عن مناسبة
طول التسلسل.
ثانياً ، يمكنك مسبقًا لتدريب النموذج الأساسي في البيانات الخاصة بك طالما يمكنك العثور على مجموعة بيانات مرتبطة بـ
مهمتك ، ثم صقلها في مهمتك المحددة.
ثالثًا ، يمكنك تغيير وظيفة الخسارة والطبقة الأخيرة لتناسب مهمتك.
بالإضافة إلى ذلك ، يمكنك إضافة بعض المهام التي تم تدريبها مسبقًا والتي ستساعد النموذج على فهم مهمتك بشكل أفضل.
كما حصلنا من خبرة من تجارب ، فإن المهمة التي تم تدريبها قبل المستقلة عن النموذج والمدربة المسبقة ليست حديثة
المهام أعلاه.
الهيكل V1: التضمين ---> LSTM ثنائية الاتجاه ---> CORCAT OUTPUT ---> متوسط -----> طبقة Softmax
تحقق: p8_textrnnn_model.py
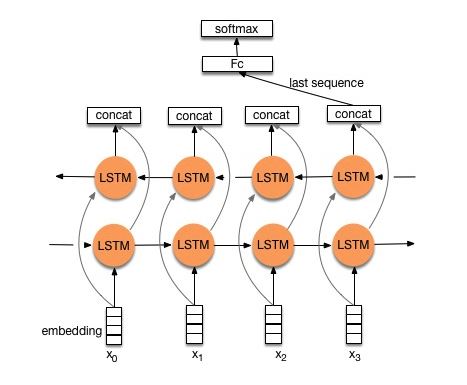
الهيكل V2: التضمين-> LSTM ثنائية الاتجاه ----> التسرب-> CONCAT OUPUT ---> LSTM ---> Droput-> FC Layer-> Softmax Layer
تحقق: p8_textrnnn_model_multilayer.py
هيكل نفس Textrnn. لكن المدخلات مصممة خاصة. Eginput: "كم هو سعر الكمبيوتر من الكمبيوتر المحمول". حيث "EOS" هو رمز خاص spished1 و Question2.
تحقق: p9_bilstmtextrelation_model.py
الهيكل: استخدم أولاً اثنين من ميزة "تجنيبين مختلفين لاستخراج جملتين. ثم تلحق ميزتين. استخدم طبقة التحويل الخطية للإسقاط خارج الملصق المستهدف ، ثم SoftMax.
تحقق: p9_twocnntextrelation_model.py
الهيكل: LSTM ثنائي الاتجاه لجمل واحدة (GET OUTPORT1) ، LSTM ثنائي الاتجاه آخر لجمل أخرى (GET OUTPORT2). ثم: softmax (Output1 m Output2)
تحقق: p9_bilstmtextrelationtwornn_model.py
لمزيد من التفاصيل ، يمكنك الانتقال إلى: التعلم العميق لـ chatbots ، الجزء 2-تنفيذ نموذج قائم على الاسترجاع في TensorFlow
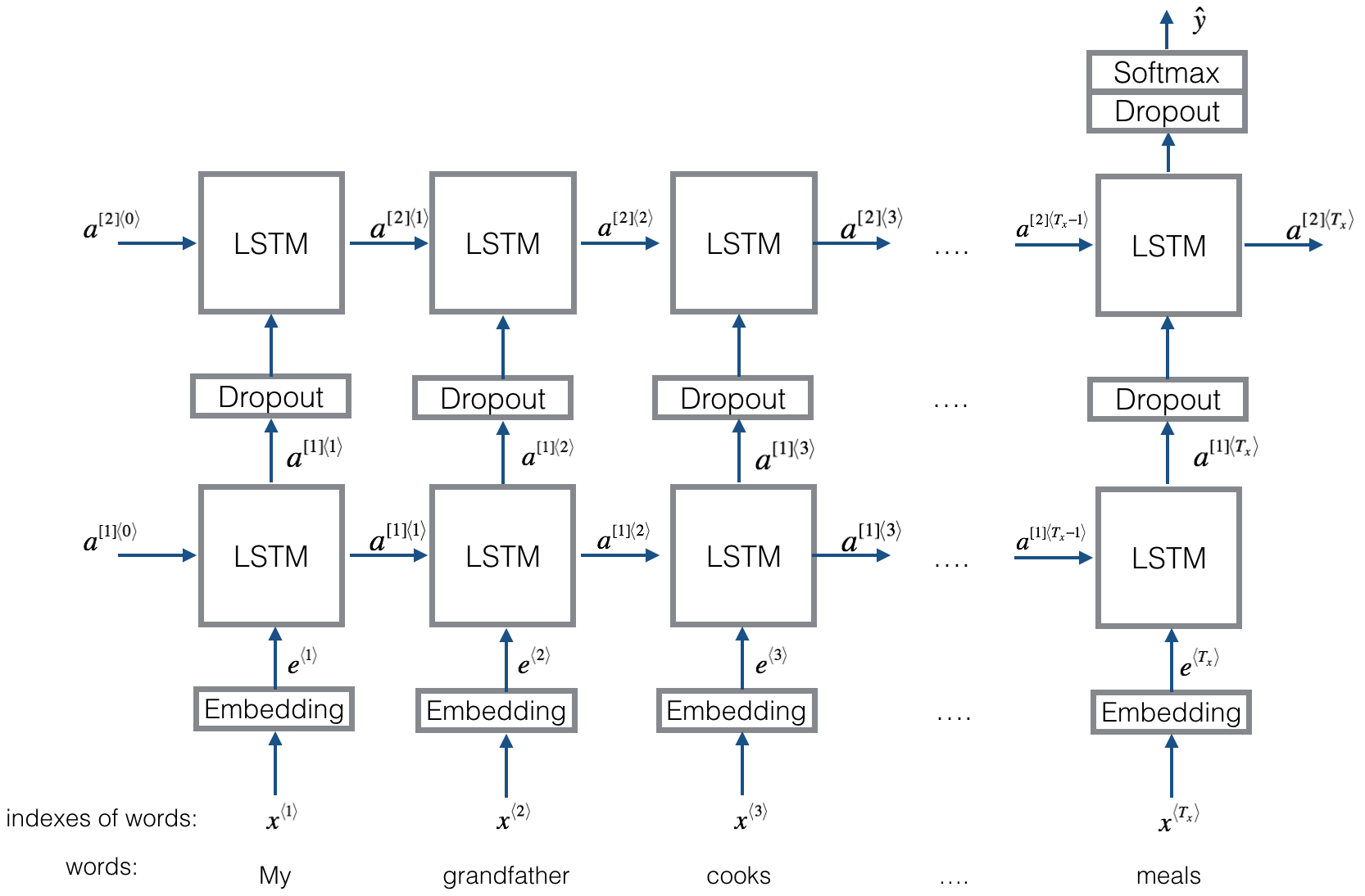
الشبكة العصبية التلافيفية المتكررة لتصنيف النص
تنفيذ الشبكة العصبية التلافيفية المتكررة لتصنيف النص
الهيكل: 1) بنية متكررة (طبقة تلافيفية) 2) أقصى تجمع 3) طبقة متصلة بالكامل+softmax
يتعلم تمثيل كل كلمة في الجملة أو المستند مع السياق الجانبي الأيسر والسياق الجانبي الأيمن:
تمثيل Word = [left_side_context_vector ، current_word_embedding ، right_side_context_vecotor].
بالنسبة للسياق الجانبي الأيسر ، فإنه يستخدم بنية متكررة ، وتجول غير خطي للكلمة السابقة والسياق السابق في الجانب الأيسر ؛ على غرار السياق الجانب الأيمن.
تحقق: p71_textrcnn_model.py
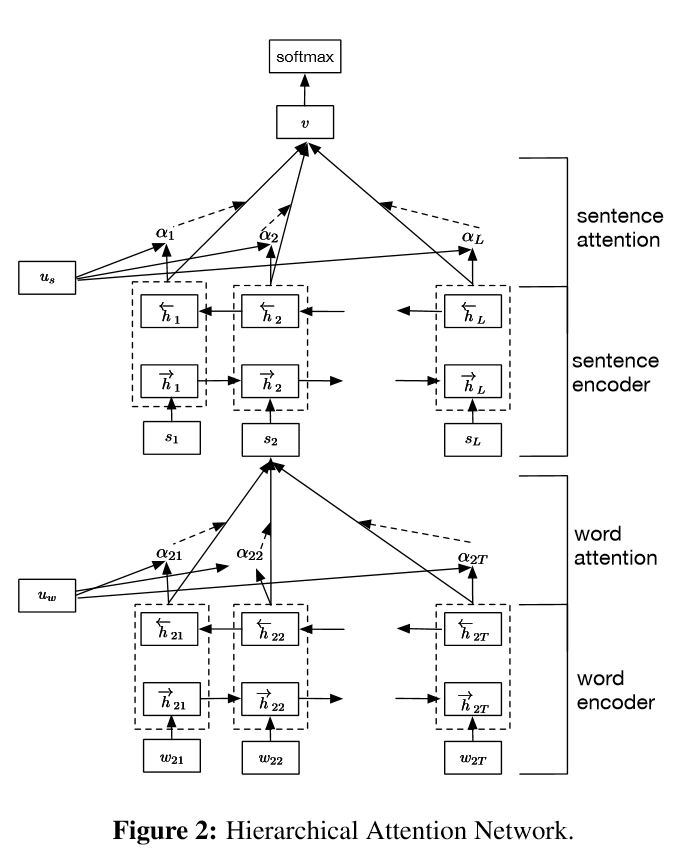
تنفيذ شبكات الاهتمام الهرمية لتصنيف المستندات
بناء:
التضمين
تشفير الكلمات: مستوى الكلمة ثنائية الاتجاهين للحصول على تمثيل غني للكلمات
اهتمام الكلمة: اهتمام مستوى الكلمة للحصول على معلومات مهمة في جملة
تشفير الجملة: مستوى الجمل ثنائية الاتجاه للحصول على تمثيل غني للجمل
جملة التوقيت: اهتمام مستوى الجملة للحصول على عقوبة مهمة بين الجمل
fc+softmax
في NLP ، يمكن إجراء تصنيف النص لجمل واحدة ، ولكن يمكن أيضًا استخدامه لجمل متعددة. قد نسميها تصنيف المستندات. الكلمات هي شكل إلى الجملة. والجملة هي شكل لتوثيق. في هذه الظروف ، قد يكون هناك بنية جوهرية. فكيف يمكننا تصميم هذه الأنواع من المهمة؟ هل جميع أجزاء المستند ذات صلة بنفس القدر؟ وكيف نحدد أي جزء أكثر أهمية من الآخر؟
لديها ميزتان فريدان:
1) له بنية هرمية تعكس الهيكل الهرمي للوثائق ؛
2) لديه مستويان من آليات الاهتمام المستخدمة في الكلمة ومستوى الجملة. يمكّن النموذج من التقاط معلومات مهمة في مستويات مختلفة.
Word Encoder: لكل عبارة في جملة ، يتم تضمينها في متجه الكلمات في مساحة متجه التوزيع. يستخدم GRU ثنائية الاتجاه لترميز الجملة. عن طريق Concatenate Vector من اتجاهين ، يمكن الآن أن تشكل تمثيلًا للجمل ، والتي تلتقط أيضًا معلومات سياقية.
اهتمام الكلمات: نفس الكلمات أكثر أهمية من أخرى بالنسبة للجمل. لذلك يتم استخدام آلية الانتباه. يستخدم أولاً طبقة واحدة MLP للحصول على تمثيل مخفي للجملة ، ثم قياس أهمية الكلمة كتشابه مع UIT مع ناقل سياق مستوى كلمة UW والحصول على أهمية تطبيع من خلال وظيفة softmax.
تشفير الجملة: بالنسبة لمتجهات الجملة ، يتم استخدام GRU ثنائية الاتجاه لتشفيره. على غرار كلمة تشفير الكلمات.
انتباه الجملة: يتم استخدام ناقل مستوى الجملة لقياس الأهمية بين الجمل. على غرار اهتمام كلمة.
إدخال البيانات:
بشكل عام ، يجب أن تحتوي إدخال هذا النموذج على جمل خادم بدلاً من جملة سينل. الشكل هو: [لا شيء ، sentence_lenght]. حيث لا شيء يعني batch_size.
في بيانات التدريب الخاصة بي ، لكل مثال ، لدي أربعة أجزاء. كل جزء له نفس الطول. أنا ألحق أربعة أجزاء لتشكيل جملة واحدة. سيقوم النموذج بتقسيم الجملة إلى أربعة أجزاء ، لتشكيل موتر مع الشكل: [لا شيء ، num_sentence ، sentence_length]. حيث num_sentence هو عدد الجمل (يساوي 4 ، في الإعداد الخاص بي).
تحقق: p1_hierarchicalattention_model.py
من أجل الاهتمام اليقظة ، يمكنك التحقق من الاهتمام اليقظة
تنفيذ SEQ2SEQ مع الاهتمام المستمد من الترجمة الآلية العصبية من خلال تعلم مشترك للمحاذاة والترجمة
I. Structure:
1) التضمين 2) احصل على تمثيل غني للغاية من جمل المصدر (إلى الأمام والخلف). 3) فك التشفير مع الاهتمام.
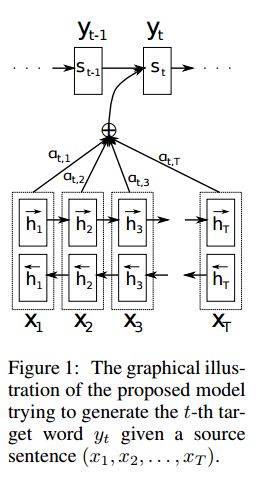
II.Input of Data:
هناك نوعان من ثلاثة أنواع من المدخلات: 1) مدخلات التشفير ، وهي جملة ؛ 2) مدخلات وحدة فك الترميز ، إنها قائمة تسميات بطول ثابت ؛ 3) تسميات مستهدفة ، وهي أيضًا قائمة بالعلامات.
على سبيل المثال ، تسميات هي: "L1 L2 L3 L4" ، ثم ستكون مدخلات وحدة فك الترميز هي: [_ GO ، L1 ، L2 ، L2 ، L3 ، _PAD] ؛ سيكون التسمية الهدف: [L1 ، L2 ، L3 ، L3 ، _end ، _pad]. يتم تثبيت الطول إلى 6 ، وسيتم ترسيخ أي ملصقات تجاوز ، وسوف يتم وضع اللوحة إذا لم تكن العلامة كافية لملءها.
III.ANTERING ACHINISM:
نقل قائمة إدخال التشفير وحالة فك الترميز المخفية
احسب تشابه الحالة المخفية مع كل إدخال تشفير ، للحصول على توزيع إمكانية لكل إدخال تشفير.
مجموع مرجح من مدخلات التشفير بناءً على توزيع إمكانية.
اذهب على الرغم من خلية RNN باستخدام هذا المبلغ الوزن مع مدخلات فك الترميز للحصول على حالة مخفية جديدة
IV.
سيتم ترميز جملة المصدر باستخدام RNN كمتجه ثابت للحجم ("Veactor Vector"). ثم أثناء فك التشفير:
عند التدريب ، سيتم استخدام RNN آخر لمحاولة الحصول على كلمة باستخدام "متجه الفكر" كحالة init ، واتخاذ مدخلات من مدخلات وحدة فك الترميز في كل طابع زمني. Decoder ابدأ من الرمز المميز الخاص "_go". بعد أن يتم تنفيذ خطوة واحدة ، سيتم الحصول على حالة مخفية جديدة ، بالإضافة إلى مدخلات جديدة ، يمكننا مواصلة هذه العملية حتى نصل إلى رمز خاص "_end". يمكننا حساب الخسارة عن طريق حساب فقدان الإنتروبيا من سجلات وتسمية الهدف. يتم الحصول على Logits من خلال طبقة إسقاط للحالة المخفية (لإخراج خطوة فك التشفير (في GRU يمكننا فقط استخدام الحالات المخفية من فك التشفير كإخراج).
عندما يكون الاختبار ، لا يوجد تسمية. لذلك يجب أن نتغذى على الإخراج الذي نحصل عليه من الطابع الزمني السابق ، ومواصلة العملية التي وصلنا إليها "_end" الرمز المميز.
v.notices:
هنا استخدم نوعين من المفردات. واحد من الكلمات ، المستخدمة من قبل التشفير. آخر هو للعلامات ، التي يستخدمها فك التشفير
بالنسبة للمفردات من Lables ، أدخل ثلاثة رمز خاص: "_ GO" ، "_ end" ، "_ pad" ؛ لا يتم استخدام "_unk" ، لأن جميع الملصقات محددة مسبقًا.
الحالة: كان قادرًا على القيام بتصنيف المهمة. وقادرة على توليد ترتيب عكسي لتسلسلها في مهمة لعبة. يمكنك التحقق من ذلك عن طريق تشغيل وظيفة الاختبار في النموذج. تحقق: a2_train_classification.py (القطار) أو A2_Transformer_Classification.py (نموذج)
نحن نفعل ذلك في Parallell Style.Layer التطبيع ، والاتصال المتبقي ، والقناع تستخدم أيضا في النموذج.
لكل لبنات بناء ، نقوم بتضمين وظيفة اختبار في كل ملف أدناه ، ونختبر كل قطعة صغيرة بنجاح.
تسلسل التسلسل مع الانتباه هو نموذج نموذجي لحل مشكلة توليد التسلسل ، مثل نظام الحوار الترجمة. في معظم الوقت ، يستخدم RNN ككتلة buidling للقيام بهذه المهام. UTIL مؤخرًا ، يطبق الأشخاص أيضًا الشبكة العصبية التلافيفية للتسلسل لمشكلة التسلسل. المحول ، ومع ذلك ، فإنه يؤدي هذه المهام فقط على الاهتمام mechansim. إنه سريع ويحقق نتيجة جديدة للدولة.
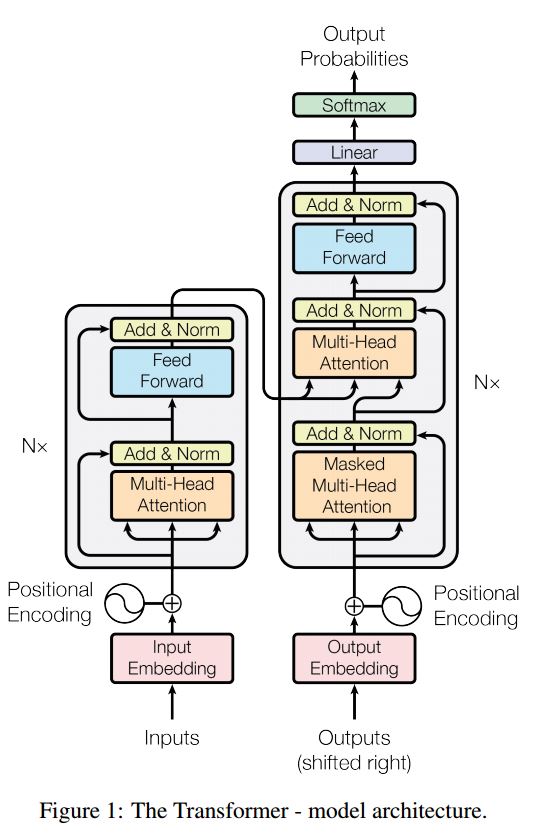
كما أن لديها جزأين رئيسيين: التشفير وفك التشفير. فيما يلي DESC من الورق:
تشفير:
6 طبقات. الطبقات لديها اثنين من الطبقة الفرعية. الأول هو آلية الاعتداء الذاتي متعددة الرأس. والثاني هو شبكة التغذية المتصلة بالكامل. لكل طبقة فرعية. استخدم layernorm (x+طبقة فرعية (x)). كل البعد = 512.
فك التشفير:
الاستيلاء الرئيسي عن هذا النموذج:
استخدم هذا النموذج للقيام بتصنيف المهام:
نحن هنا نستخدم جزءًا من التشفير فقط لتصنيف المهام ، والاتصال Resdiual الذي تمت إزالته ، والذي استخدم فقط طبقة واحدة. لا تحتاج إلى استخدام قناع. نحن نستخدم الاهتمام متعدد الرأس وتغذية العرض إلى الأمام لاستخراج ميزات جملة الإدخال ، ثم استخدم الطبقة الخطية لإسقاطها للحصول على سجلات.
للحصول على تفاصيل النموذج ، يرجى التحقق من: a2_transformer_classification.py
المدخلات: 1. القصة: إنها متعددة ، كسياق. 2.query: جملة ، وهو سؤال ، 3. ansewr: ملصق واحد.
هيكل النموذج:
ترميز الإدخال: استخدم حقيبة Word لتشفير القصة (السياق) والاستعلام (سؤال) ؛ تأخذ في الاعتبار الموقف باستخدام قناع الموضع
باستخدام RNN ثنائية الاتجاه لترميز القصة والاستعلام ، زيادة الأداء من 0.392 إلى 0.398 ، وزيادة 1.5 ٪.
الذاكرة الديناميكية:
أ. حساب بوابة باستخدام "تشابه" المفاتيح ، والقيم مع إدخال القصة.
ب. احصل على مرشح مخفي الحالة عن طريق تحويل كل مفتاح وقيمة ومدخلات.
ج. الجمع بين بوابة ومرشح مخفي الدولة لتحديث الحالة الخفية الحالية.
ب. الحصول على مجموع مرجح من الحالة الخفية باستخدام توزيع إمكانية.
ج. تحويل غير الخطية للاستعلام والدولة المخفية للحصول على علامة التنبؤ.
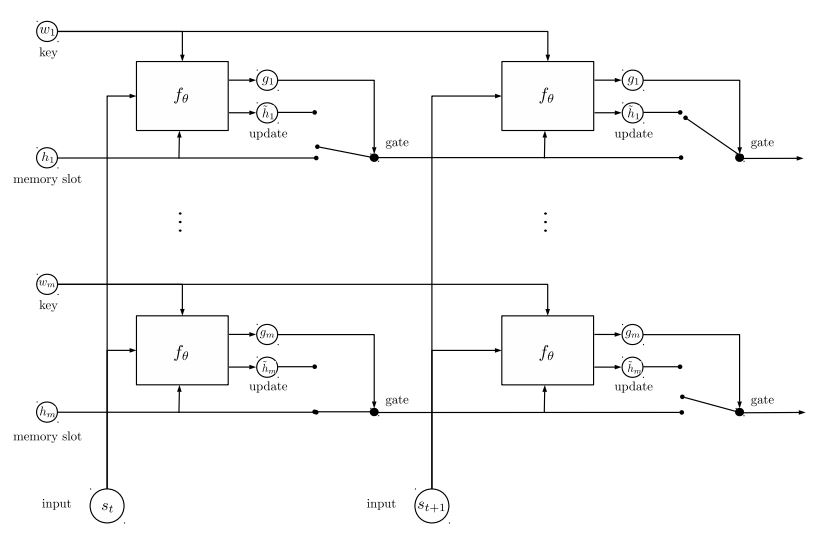
الاستيلاء الرئيسي عن هذا النموذج:
استخدم كتل المفاتيح والقيم ، وهي مستقلة عن بعضها البعض. لذلك يمكن تشغيله بالتوازي.
نمذجة السياق والسؤال معا. استخدم الذاكرة لتتبع حالة العالم ؛ واستخدام التحويل غير الخطي للحالة المخفية والسؤال (الاستعلام) لتقديم التنبؤ.
يمكن أن يحقق النموذج البسيط أداءً جيدًا جدًا. تشفير بسيط كما استخدام حقيبة الكلمة.
للحصول على تفاصيل النموذج ، يرجى التحقق من: a3_entity_network.py
بموجب هذا النموذج ، يكون له وظيفة اختبار ، تطلب من هذا النموذج حساب الأرقام لكل من القصة (السياق) والاستعلام (سؤال). لكن أوزان القصة أصغر من الاستعلام.
النظرة المستقبلية:
1. الوحدة النمطية: تشفير النصوص الخام في تمثيل المتجهات
2. وحدة التكوين: تشفير السؤال في تمثيل المتجه
3. وحدة الذاكرة البسيطة: مع المدخلات ، فإنه يختار أجزاء من المدخلات التي يجب التركيز عليها من خلال آلية الانتباه ، مع مراعاة السؤال والذاكرة السابقة ====> إنها poduce a 'memory' vecotr.
4. الوحدة النمطية: قم بإنشاء إجابة من متجه الذاكرة النهائي.
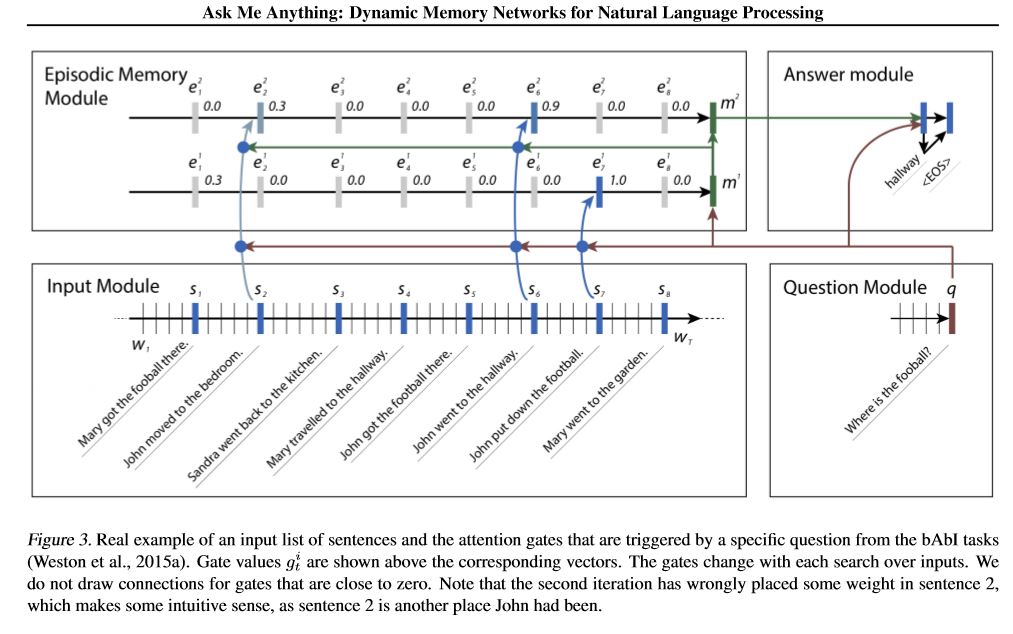
التفاصيل:
1. الوحدة النمطية:
جملة A.Single: استخدم GRU للحصول على حالة مخفية من الجمل: استخدم GRU للحصول على الحالات المخفية لكل جملة. على سبيل المثال [الدول المخفية 1 ، الحالات المخفية 2 ، الولايات الخفية ... ، الدولة الخفية n]
2. وحدة التكوين: استخدم GRU للحصول على حالة مخفية
3. وحدة الذاكرة البسيطة:
استخدم آلية الانتباه والشبكة المتكررة لتحديث ذاكرتها.
أ. بوابة آلية الانتباه:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
آلية تحديث B.Memory: خذ جملة المرشحين ، بوابة وحالة خفية سابقة ، تستخدم بوابات GU لتحديث الحالة المخفية. مثل: h = f (c ، h_previous ، g). الحالة الخفية النهائية هي المدخلات لوحدة الإجابة.
C.Deeed لحلقات متعددة ===> الاستدلال العابر.
على سبيل المثال ، اسأل أين كرة القدم؟ ستحضر عقوبة "جون وضع كرة القدم") ، ثم في الممر الثاني ، يحتاج إلى حضور موقع جون.
4. الوحدة النمطية: خذ ذاكرة Epsoidic النهائية ، سؤال ، تحديث وحدة الإجابة المخفية.
1. شبكات تلغيرات على مستوى الشرس لتصنيف النص
2. شبكات عصبية ثورية لتصنيف النص: مستوى الكلمات الضحلة مقابل مستوى الشخصية العميقة
3. الشبكات التلافيفية العميقة جدًا لتصنيف النص
4. أساليب التدريب المفروضة لتصنيف النص شبه الخاضع للإشراف
5. النماذج
أثناء عملية القيام على نطاق واسع من التصنيف متعدد العلامات ، تم تعلم دروس الخادم ، وبعض القائمة على النحو التالي:
ما هو أهم شيء للوصول إلى دقة عالية؟ تعتمد على المهمة التي تقوم بها. من المهمة التي أجريناها هنا ، نعتقد أن نماذج الفرقة تستند إلى نماذج مدربة من ميزات متعددة بما في ذلك Word ، و Actory for title and description يمكن أن تساعد في الوصول إلى accuarcy عالية جدًا ؛ ومع ذلك ، في بعض الحالات ، كما أثبتت AlphaGo Zero ، فإن الخوارزمية أكثر أهمية ثم البيانات أو القوة الحسابية ، في الواقع لم يستخدم AlphaGo Zero أي بيانات Humam.
هل يوجد سقف لأي نموذج أو خوارزمية محددة؟ الجواب نعم. تم استخدام الكثير من النماذج المختلفة هنا ، وجدنا أن العديد من النماذج لها عروض مماثلة ، على الرغم من وجود بنية مختلفة تمامًا. في حد ما ، فإن اختلاف الأداء ليس كبيرًا جدًا.
هل دراسة حالة الخطأ مفيدة؟ أعتقد أنه مفيد للغاية خاصةً عندما تكون قد فعلت العديد من الأشياء المختلفة ، ولكن وصلت إلى حد. على سبيل المثال ، من خلال إجراء دراسة حالة ، يمكنك العثور على ملصقات يمكن للموديلات أن تجعل التنبؤ الصحيح ، ومكان ارتكاب أخطاء. ولأداء الأداء من خلال زيادة أوزان هذه الملصقات الخاطئة المتوقعة أو إيجاد أخطاء محتملة من البيانات.
كيف يمكننا أن نصبح خبيرًا في التعلم الآلي؟ في رأيي ، انضم إلى تنافس التعلم الآلي أو ابدأ مهمة مع الكثير من البيانات ، ثم قراءة الأوراق وتنفيذ بعضها ، هي نقطة انطلاق جيدة. لذلك سيكون لدينا بعض الخبرة والأفكار حقًا في التعامل مع مهمة معينة ، ومعرفة تحدياتها. ولكن الأهم من ذلك هو أنه لا ينبغي لنا اتباع الأفكار من الأوراق فحسب ، بل استكشاف بعض الأفكار الجديدة التي نعتقد أنها قد تساعد في إلغاء المشكلة. على سبيل المثال ، من خلال تغيير هياكل النماذج الكلاسيكية أو حتى ابتكار بعض الهياكل الجديدة ، قد نتمكن من معالجة المشكلة بطريقة أفضل بكثير لأنها قد تكون أكثر ملاءمة للمهمة التي نقوم بها.
1. قاع الحيل لتصنيف النص الفعال
2. الشبكات العصبية التثبيقية لتصنيف الجملة
3. تحليل حساسية (ودليل الممارسين) الشبكات العصبية التلافيفية لتصنيف الجملة
4. التعلم في chatbots ، الجزء 2-تنفيذ نموذج قائم على الاسترجاع في TensorFlow ، من www.wildml.com
5. الشبكة العصبية التلافيفية المتكررة لتصنيف النص
6. شبكات الاهتمام المتسلسل لتصنيف المستندات
7. الترجمة الآلية من خلال التعلم المشترك للمحاذاة والترجمة
8.Tentation هو كل ما تحتاجه
9. ضع أي شيء: شبكات الذاكرة الديناميكية لمعالجة اللغة الطبيعية
10.Taking the State of World مع شبكات الكيانات المتكررة
11. اختيار ensemble من مكتبات النماذج
12.bert: ما قبل التدريب على محولات ثنائية الاتجاه العميقة لفهم اللغة
13.Google-Research/Bert
يتبع. لأي مشكلة ، concat [email protected]


