text_classification
1.0.0
이 저장소의 목적은 딥 러닝으로 NLP의 텍스트 분류 방법을 탐색하는 것입니다.
3 분 안에 NLP API를 무료로 사용자 정의 : NLP API 데모
언어 이해 중국어에 대한 평가 벤치 마크 (단서 벤치 마크) : 한 줄의 코드로 10 개의 작업 및 9 개의 기준선을 실행, 세부 사항과의 성능 비교.
30G+ Raw Chinese Corpus, XXLARGE, XLARGE 등의 Albert_chinese 훈련의 미리 훈련 된 모델 출시 중국의 전국의 날 동안 2019-OCT-7의 중국어 공연의 최첨단 공연을 목표로합니다!
NLP를위한 많은 양의 중국 코퍼스!
Google의 Bert는 언어 모델에서 프리 트레인을 사용하여 NLP의 10 개 이상의 작업에서 새로운 최첨단 결과를 달성했습니다.
미세 조정. 사전 훈련 Texcnn : 코드 및 데이터 세트 실행에 대한 언어 이해를위한 Bert의 아이디어
텍스트 분류를위한 모든 종류의 기준 모델이 있습니다.
또한 다중 레이블이 문장이나 문서와 관련된 다중 표지 분류를 지원합니다.
이러한 모델 중 다수는 단순하지만 최상위 수준의 작업으로 연결되지 않을 수 있습니다. 그러나 이러한 모델 중 일부는 매우 있습니다
클래식이므로 기준 모델 역할을하는 것이 좋습니다. 각 모델에는 모델 클래스에 테스트 기능이 있습니다. 당신은 달릴 수 있습니다
퍼포먼스 장난감 작업에 먼저. 모델은 데이터 세트와 독립적입니다.
딥 러닝을 통한 대규모 멀티 라벨 텍스트 분류의 공식 보고서는 여기를 확인하십시오.
여기의 여러 모델은 질문 답변을 모델링하는 데 (컨텍스트 유무에 관계없이) 또는 시퀀스 생성을 수행하는 데 사용될 수 있습니다.
우리는 텍스트 분류를 수행하기 위해 두 개의 SEQ2Seq 모델 (주의력이있는 Seq2Seq, 변압기-변환이 필요한 전부)을 탐색합니다.
이 두 모델은 시퀀스 생성 및 기타 작업에도 사용될 수 있습니다. 작업이 다중 라벨 분류 인 경우
문제를 시퀀스 생성에 시전 할 수 있습니다.
우리는 두 개의 메모리 네트워크를 구현합니다. 하나는 동적 메모리 네트워크입니다. 이전에는 해당 예술 최신에 도달했습니다
응답, 감정 분석 및 시퀀스 생성 작업. 여러 가지 작업을 수행하는 것은 하나의 모델이라고합니다.
고성능에 도달합니다. 4 개의 모듈이 있습니다. 주요 구성 요소는 에피소드 메모리 모듈입니다. 게이트 메커니즘을 사용합니다
성능주의 및 Gated-Gru를 사용하여 에피소드 메모리를 업데이트하면 다른 GRU (수직 방향)가 있습니다.
성능 숨겨진 상태 업데이트. 그것은 전이적인 추론을 할 수있는 능력이 있습니다.
우리가 구현 한 두 번째 메모리 네트워크는 반복 엔티티 네트워크 : 세계의 추적 상태입니다. 블록이 있습니다
키 값은 메모리로서 쌍을 이루고 병렬로 실행되며 새로운 최신 기술을 달성합니다. 질문을 모델링하는 데 사용할 수 있습니다
상황 (또는 역사)으로 대답합니다. 예를 들어, 모델이 일부 문장을 읽도록 허용하고 (문맥으로)
질문 (쿼리로), 모델에 답을 예측하도록 요청하십시오. 쿼리와 동일한 스토리를 공급하면
분류 작업.
ML/DL/NLP 문제를 논의하고 서로의 기술 지원을 받으려면 QQ 그룹에 가입 할 수 있습니다 : 836811304
FastText
TextCnn
BERT : 언어 이해를위한 깊은 양방향 변압기의 사전 훈련
Textrnn
RCNN
계층 적주의 네트워크
주목할만한 seq2seq
변압기 ( "참석하기 만하면됩니다")
동적 메모리 네트워크
엔티티 네트워크 : 세계의 추적 상태
앙상블 모델
부스트 :
단일 모델의 경우 동일한 모델을 함께 쌓으십시오. 각 레이어는 모델입니다. 결과는 함께 추가 된 로그를 기반으로합니다. 레이어 간의 유일한 연결은 레이블의 가중치입니다. 각 레이블의 전면 레이어의 예측 오류율은 다음 레이어의 무게가됩니다. 오류율이 높은 레이블은 무게가 크게됩니다. 따라서 나중에 계층은 잘못 예측 된 레이블에 더 많은 관심을 기울이고 이전 레이어의 이전 실수를 수정하려고합니다. 결과적으로 우리는 훨씬 강력한 모델을 얻을 것입니다. a00_boosting/boosting.py를 확인하십시오
및 기타 모델 :
bilstmtextrelation;
twocnntextrelation;
bilstmtextrelationtwornn
(Mulit-Label Label Prediction Task, Prediction Top5, 3 백만 교육 데이터, 전체 점수 : 0.5)
| 모델 | FastText | TextCnn | Textrnn | RCNN | Hierattenet | seq2seqattn | 엔티티 넷 | 동적 메모리 | 변신 로봇 |
|---|---|---|---|---|---|---|---|---|---|
| 점수 | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| 훈련 | 10m | 2h | 10h | 2h | 2h | 3H | 3H | 5h | 7h |
Bert Model은 유효성 검사 세트에서 처음 9 시대 후 0.368을 달성합니다.
TextCnn, EntityNet, DynamicMemory의 앙상블 : 0.411
Ensemble EntityNet, DynamicMemory : 0.403
알아채다:
m 몇 분 동안 서 있습니다. h 몇 시간 동안 서 있습니다.
HierAtteNet 계층 적주의 네트워크를 의미합니다.
Seq2seqAttn 주목할만한 seq2seq를 의미합니다.
DynamicMemory DynamicMemorynetwork를 의미합니다.
Transformer '주의가 필요한 전부'의 모델을위한 스탠드입니다.
xxx_model.py 에 있습니다xxx_train.py 실행하여 모델을 훈련시킵니다xxx_predict.py 실행하여 추론 (테스트)을 수행하십시오.각 모델에는 모델 클래스에 테스트 방법이 있습니다. 먼저 테스트 방법을 실행하여 모델이 제대로 작동하는지 확인할 수 있습니다.
파이썬 2.7+ 텐서 플로 1.8
(Tensorflow 1.1 ~ 1.13도 작동해야합니다. 대부분의 모델은 다른 Tensorflow 버전에서도 잘 작동해야합니다.
특정 버전에 대한 채권을 거의 사용하지 않습니다.
Python3을 사용하는 경우 오류를 충족 할 경우 인쇄/캐치 기능을 변경하는 한 괜찮습니다.
TextCNN 모델은 이미 Python 3.6으로 변형되었습니다
이 저장소를 실행하는 데 도움이 되려면 현재 교육/검증/테스트 데이터 및 어휘/레이블을 다시 생성하고 저장했습니다.
h5py를 사용하는 캐시 파일로서. 위의 링크에서 다운로드하는 것이 좋습니다.
이 저장소를 실행하는 데 필요한 모든 것이 포함되어 있습니다. 데이터는 사전 처리되어 있으며 1 분 안에 모델을 훈련시킬 수 있습니다.
약 1.8g의 zip 파일이며 3 백만 개의 교육 데이터가 포함되어 있습니다. 압축을 풀고 난 후에도 꽤 크지 만 도움으로
HDF5, 훈련 중에 컴퓨터 메모리의 정상적인 크기 (EG8 g 이하) 만 있으면됩니다.
우리는 Jupyter Notebook : pre-processing.ipynb를 사전 프로세스 데이터에 사용합니다. 이 작업을 더 잘 이해하고
그것을 살펴보면 데이터. 원하는 방식으로 직접 데이터를 생성 할 수 있으며 몇 줄의 코드를 변경하십시오.
이 Jupyter 노트북 사용.
지금 모델을 시도하려면 위에서 캐시 된 파일을 다이어로드 한 다음 폴더 'A02_TextCNN', run로 이동할 수 있습니다.
python p7_TextCNN_train.py
캐시 된 파일의 데이터를 사용하여 모델을 훈련시키고 인쇄 손실 및 F1 점수는 주기적으로 점수를 매 깁니다.
오래된 샘플 데이터 출처 : Word2VEC에 분만 된 샘플 데이터 및 Word 포함이 필요한 경우 다음과 같은 닫힌 문제에서 찾을 수 있습니다.
폴더 "데이터"에서 일부 샘플 데이터를 찾을 수도 있습니다. 'sample_single_label.txt', 50k 데이터가 포함 된 두 가지 파일이 포함되어 있습니다
단일 레이블로; 'sample_multiple_label.txt'에는 여러 레이블이있는 20k 데이터가 포함되어 있습니다. 입력 및 레이블은 " 레이블 "으로 별도입니다.
텍스트 분류 또는 작업의 데이터 세트에 대한 자세한 내용을 알고 싶다면 이러한 모델을 사용할 수 있습니다. 선택 중 하나는 다음과 같습니다.
https://biendata.com/competition/zhihu/
이 저장소를 사용할 수있는 한 가지 방법 :
1 단계 :이 기사를 읽을 수 있습니다. 텍스트 분류를 수행하는 데 사용되는 다양한 클래식 모델에 대한 일반적인 아이디어를 얻게됩니다.
2 단계 : 사전 프로세스 데이터 및/또는 캐시 된 파일 다운로드.
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
3 단계 : 여기에서 일부 모델 목록을 실행하고 원하는대로 코드와 구성을 변경하여 좋은 성능을 얻으십시오.
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
또한이 주제에 대한 기사를 작성하면 종이 스타일을 따라 쓸 수 있습니다. 논문을 읽어야 할 수도 있습니다
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
'data/sample_multiple_label.txt'의 데이터를 교체하고 다음과 같이 형식을 확인하십시오.
'Word1 Word2 Word3 __label__l1 __label__l2 __label__l3'
여기서 Part1 : 'Word1 Word2 Word3'은 입력 (x), Part2 : '__label__l1 __Label__l2 __label__l3'
[L1, L2, L3]의 세 가지 라벨이 있습니다. Part1과 Part2 사이에 빈 문자열이 있어야합니다. ''.
예를 들어 : 각 라인 (다중 라벨)과 같은 것 :
'W5466 W138990 W1638 W4301 W6 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __Label__5626661657638885119 __LABEL_492179380534628695 __Label__89047355555009151318 '
여기서 '5626661657638885119', '4921793805334628695', '890473555555009151318'은이 입력 문자열과 관련된 3 개의 레이블 'W5466 W138990 ... C699 C317 C184'입니다.
알아채다:
일부 util 기능은 data_util.py에 있습니다. Data_util의 Load_Data_Multilabel ()에서 프로세스 입력 및 원시 데이터의 레이블을 확인하십시오.
Word2Vec 또는 FastText에서 Word Embedding이 사전에 사전이되는 모델에 전처리 된 단어 임베딩을로드하고 할당하는 기능이 있습니다.
Word2veec.load가 작동하지 않으면 사전 상충되는 Word Embedding을로드 할 수 있습니다.
수입 세대
Gensim에서 모델 import keyedvectors를 가져옵니다
Word2Vec_model = keyedVectors.load_word2vec_format (word2vec_model_path, binary = true, unicode_errors = 'ingore') #
또는 프리 트레인 단어 임베딩 플래그를 false로 끄면 단어 임베딩을로드 할 수 있습니다.
효율적인 텍스트 분류를위한 트릭 백의 이식
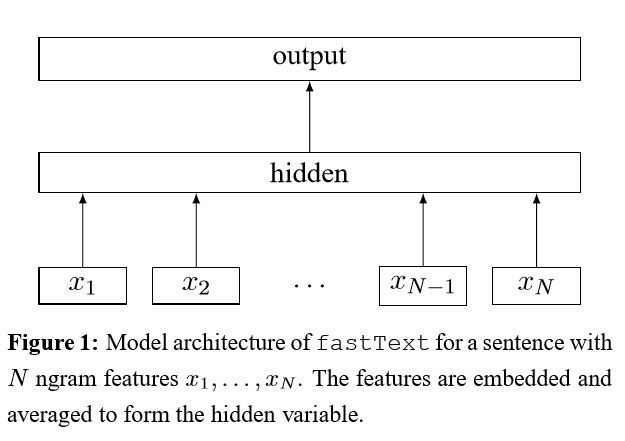
문장에 각 단어를 포함시킨 후,이 단어 표현은 텍스트 표현으로 평균화되어 선형 분류기에 공급됩니다. SoftMax 함수를 사용하여 사전 정의 된 클래스의 확률 분포를 계산합니다. 그런 다음 교차 엔트로피를 사용하여 손실을 계산합니다. 단어 표현 가방은 단어 순서를 고려하지 않습니다. 단어 순서를 고려하기 위해 N- 그램 기능은 로컬 워드 순서에 대한 일부 정보를 캡처하는 데 사용됩니다. 클래스 수가 큰 경우, 선형 분류기는 계산 비용이 많이 듭니다. 따라서 훈련 프로세스 속도를 높이기 위해 해체적 소프트 마맥스를 사용합니다.
결과 : 성능은 종이만큼 좋으며 속도도 매우 빠릅니다.
점검 : p5_fasttextb_model.py
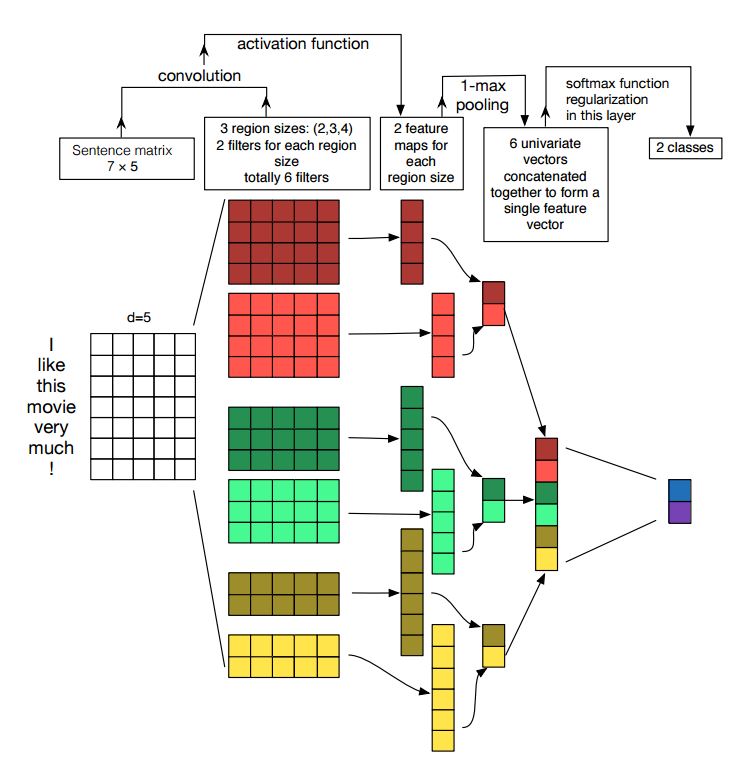
문장 분류를위한 Convolutional Neural Network의 구현
구조 : 임베딩 ---> CONV ---> MAX 풀링 ---> 완전히 연결된 레이어 --------> SoftMax
점검 : p7_textcnn_model.py
TextCNN으로 매우 좋은 결과를 얻으려면이 백서에 대해 신중하게 읽어야합니다. 문장 분류를위한 컨볼 루션 신경 네트워크에 대한 민감도 분석 : 성능에 영향을 줄 수있는 것들에 대한 통찰력을 제공합니다. 특정 작업에 따라 일부 설정을 변경해야하지만.
Convolutional Neural Network는 컴퓨터 비전 문제를 해결하기위한 메인 빌딩 박스입니다. 이제 CNN이 NLP, 특히 텍스트 분류에 어떻게 사용되는지 보여줄 것입니다. 문장 길이는 서로 다릅니다. 그래서 우리는 PAD를 사용하여 고정 길이를 얻을 것입니다. 문장의 각 토큰에 대해, 우리는 고정 차원 벡터를 얻기 위해 단어를 포함시킬 것입니다. d. 따라서 우리의 입력은 2 차원 행렬입니다 : (n, d). 이것은 CNN의 이미지와 유사합니다.
첫째, 우리는 입력에 대한 컨볼 루션 작업을 수행 할 것입니다. 필터와 입력의 일부 사이에 요소 별 곱입니다. 우리는 k 수의 필터를 사용하고 각 필터 크기는 2 차원 행렬 (f, d)입니다. 이제 출력은 k 수 목록입니다. 각 목록의 길이는 n-f+1입니다. 각 요소는 스칼라입니다. 두 번째 차원은 항상 단어 임베딩의 차원이 될 것입니다. 우리는 텍스트 입력에서 풍부한 기능을 얻기 위해 다른 크기의 필터를 사용하고 있습니다. 그리고 이것은 N-Gram 기능과 비슷한 것입니다.
둘째, Convolutional Operation의 출력을 위해 최대 풀링을 수행 할 것입니다. k 수의 목록의 경우 k 수의 스칼라를 얻게됩니다.
셋째, 스칼라를 연결하여 최종 기능을 형성 할 것입니다. 고정 크기의 벡터입니다. 그리고 그것은 우리가 사용하는 필터의 크기와 독립적입니다.
마지막으로, 선형 레이어를 사용하여 이러한 기능을 정의 된 레이블에 투사합니다.
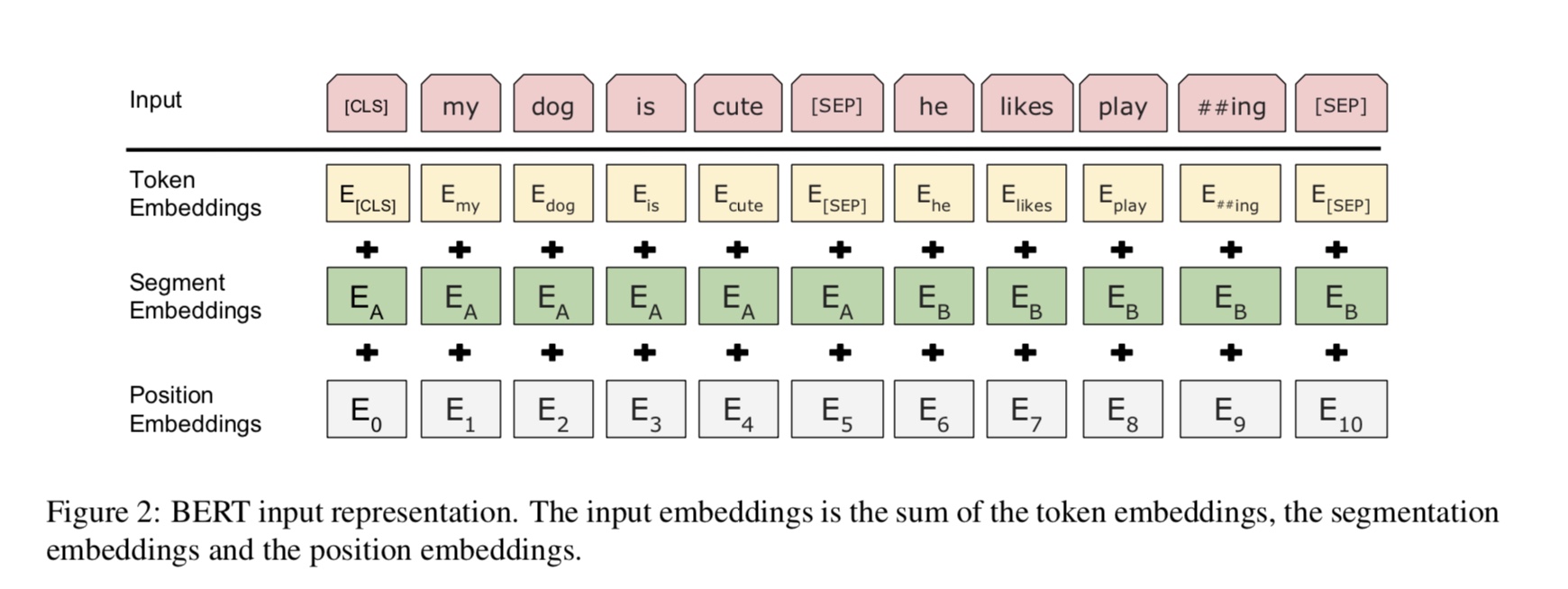
Bert는 현재 10 개 이상의 NLP 작업에서 최첨단 결과를 달성합니다. 이 모델의 주요 아이디어는
엄청난 양의 원시 데이터가있는 한 종류의 언어 모델을 사용하여 모델을 사전 훈련하여 쉽게 찾을 수 있습니다.
모델의 대부분의 매개 변수가 미리 훈련되므로 분류기를위한 마지막 레이어 만 다른 작업에 필요해야합니다.
결과적 으로이 모델은 일반적이며 매우 강력합니다. 미리 훈련 된 모델을 기준으로 미세 조정할 수 있습니다.
짧은 시간.
그러나이 모델은 상당히 큽니다. 시퀀스 길이 128을 사용하면 배치 크기가 32로 만 훈련 할 수 있습니다. 오랫동안
서열 길이 512와 같은 문서는 정상적인 GPU에 대한 배치 크기 4 만 훈련 할 수 있습니다 (11g). 그리고 거의 사람이 거의 없습니다
훈련하는 데 며칠 또는 몇 주가 걸리기 때문에이 모델이 처음부터 미리 훈련 할 수 있으며 일반 GPU의 메모리가 너무 작습니다.
이 모델의 경우.
특히 백본 모델은 변압기이며, 여기서주의를 기울일 수 있습니다. 그것은 두 종류의 두 종류를 사용합니다
모델을 사전 훈련하는 작업.
일반적으로 말하면, 문장이 주어지면 단어의 일부가 가면이 가려지면 가면을 쓴 단어를 예측해야합니다.
이 마스크 된 문장을 기반으로합니다. 마스크 된 단어는 무작위로 선택됩니다.
우리는 깊은 변압기 인코더를 통해 입력을 공급 한 다음 마스크에 해당하는 최종 숨겨진 상태를 사용합니다.
우리가 언어 모델을 훈련시키는 것처럼 어떤 단어가 가려 졌는지 예측할 수있는 위치.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
질문 응답, 추론과 같은 많은 언어 이해 작업, 관계를 이해해야합니다.
문장 사이. 그러나 언어 모델은 문장 없이만 이해할 수 있습니다. 다음 문장
예측은 이러한 종류의 작업에서 모델이 더 잘 이해하는 데 도움이되는 샘플 작업입니다.
우연의 50%는 두 번째 문장이 다음 문장의 다음 문장, 다음 문장의 다음 문장입니다.
두 문장이 주어지면 모델은 두 번째 문장이 다음의 다음 문장인지 예측하도록 요청받습니다.
첫 번째.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
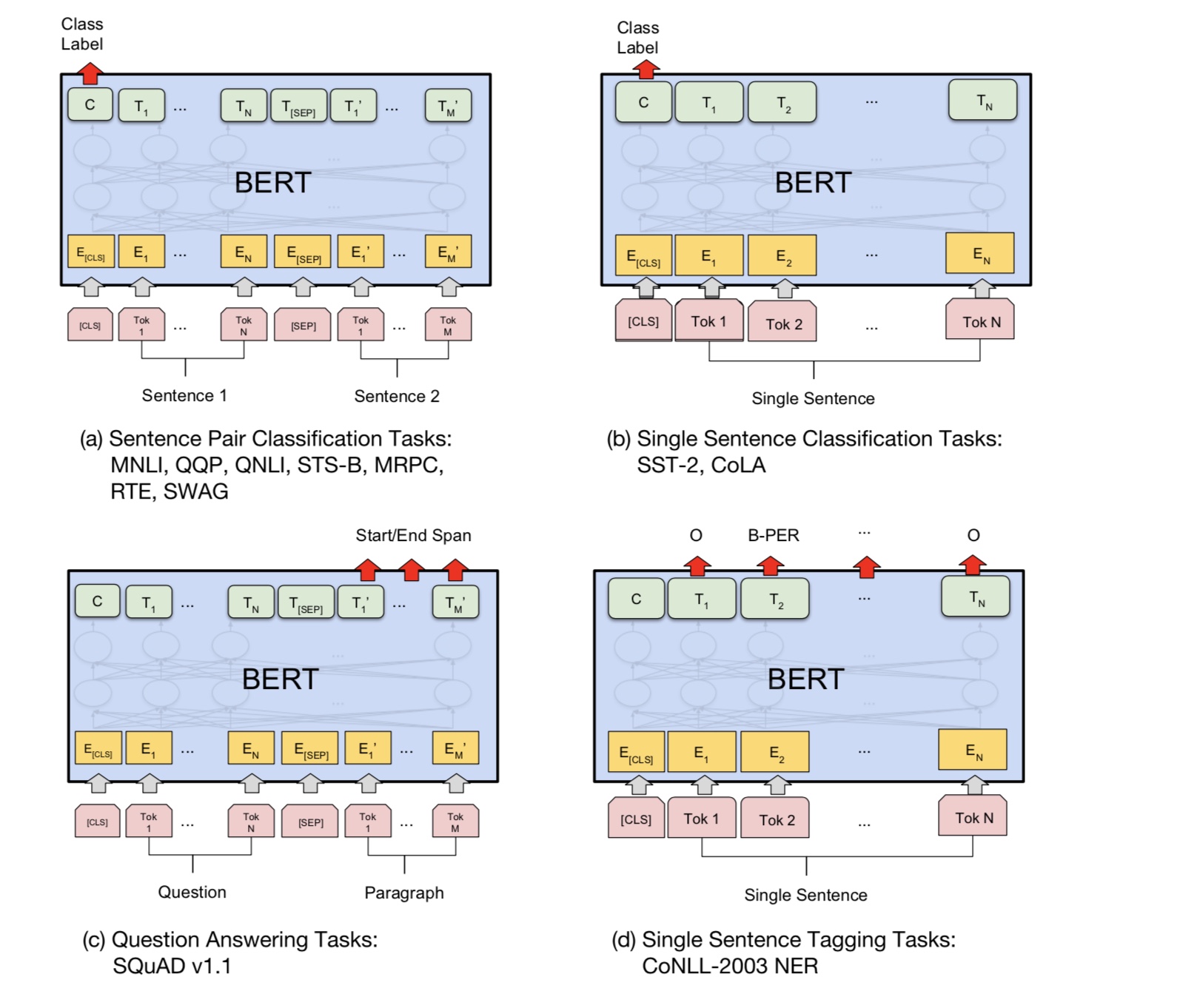
기본적으로 미리 훈련 된 모델을 다운로드 할 수 있으며 자신의 데이터로 작업을 미세 조정할 수 있습니다.
분류 작업의 경우 프로세서를 추가하여 소스 데이터에서 입력 및 레이블을 입력하려는 형식을 정의 할 수 있습니다.
폴더 a00_bert에서 다음 명령을 실행하십시오.
python train_bert_multi-label.py
9 시점 후 0.368을 달성합니다. 또는 Bert From을 사용하여 다운로드 가능한 데이터로 다중 레이블 분류를 실행할 수 있습니다.
Bert가있는 sentiment_analysis_fine_grain
세션 및 피드 스타일을 사용하여 모델 및 피드 데이터를 복원 한 다음 온라인 예측을 위해 로그를 얻을 수 있습니다.
Bert와 온라인 예측
원래 온라인이 아닌 파일을 기반으로 모델을 훈련 시키거나 평가합니다.
먼저 Google에서 미리 훈련 된 모델 다운로드를 사용할 수 있습니다. 데이터 세트에서 몇 가지 에포를 실행하고 적절한 것을 찾으십시오.
시퀀스 길이.
둘째, 관련 데이터 세트를 찾을 수있는 한 자신의 데이터에서 기본 모델을 사전 훈련 할 수 있습니다.
당신의 과제, 그런 다음 특정 작업을 미세 조정합니다.
셋째, 손실 기능과 마지막 계층을 변경하여 작업에 더 잘 어울릴 수 있습니다.
또한 모델이 작업을 훨씬 더 잘 이해하는 데 도움이되는 미리 훈련 된 작업을 정의 할 수 있습니다.
경험이 풍부한 실험에서 얻은 사전 훈련 된 작업은 모델과 독립적이며 사전 훈련이 제한되지 않습니다.
위의 작업.
구조 v1 : 임베딩 ---> 양방향 lstm ---> 출력 ---> 평균 -----> SoftMax 레이어
점검 : p8_textrnn_model.py
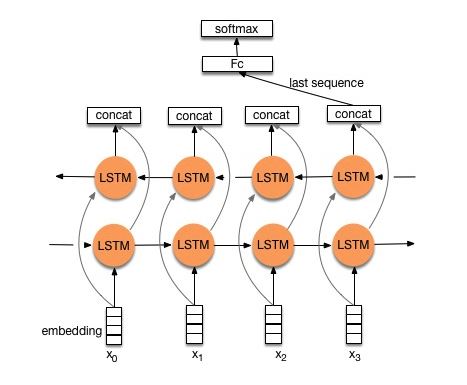
구조 v2 : 임베딩-> 양방향 LSTM ----> 드롭 아웃-> concat oput ---> lstm ---> droput-> fc layer-> softmax 레이어
점검 : p8_textrnn_model_multilayer.py
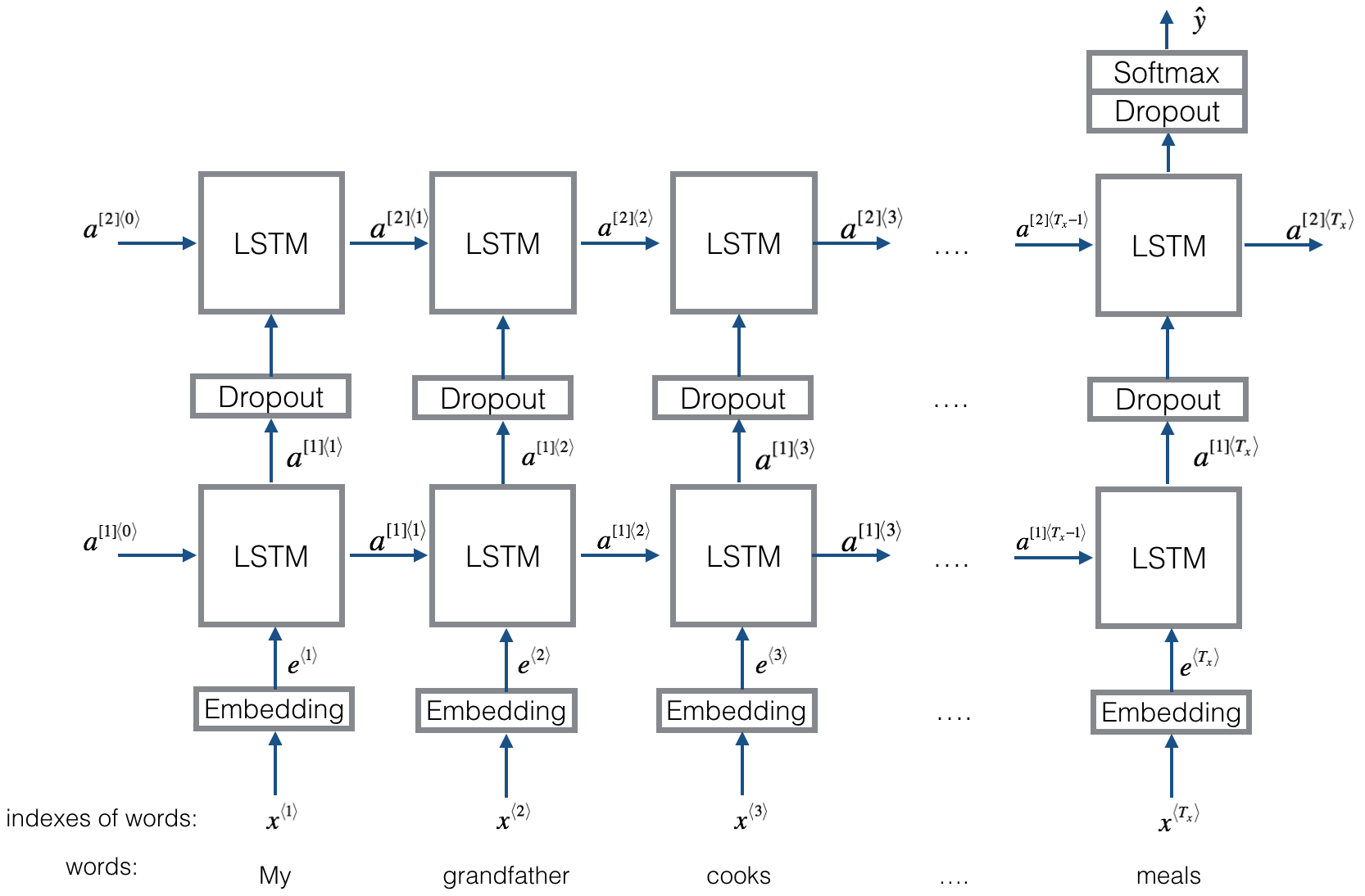
Textrnn과 동일한 구조. 그러나 입력은 특수 설계되었습니다. eginput : "컴퓨터는 얼마입니까? 노트북의 EOS 가격". 여기서 'EOS'는 특별한 토큰 스 필트 질문과 질문 2입니다.
점검 : p9_bilstmtextrelation_model.py
구조 : 먼저 두 개의 다른 컨볼 루션을 사용하여 두 문장의 특징을 추출하십시오. 그런 다음 두 가지 기능에 동의합니다. 선형 변환 레이어를 사용하여 대상 라벨에 대한 투사를 한 다음 SoftMax를 사용하십시오.
점검 : p9_twocnntextrelation_model.py
구조 : 한 문장에 대한 양방향 LSTM (get output1), 다른 문장에 대한 다른 양방향 LSTM (get output2). 그런 다음 : softmax (출력 1 m output2)
점검 : P9_BILSTMTEXTRELATIONTWORNN_MODEL.PY
자세한 내용은 챗봇 용 딥 러닝, 2 부-Tensorflow에서 검색 기반 모델 구현
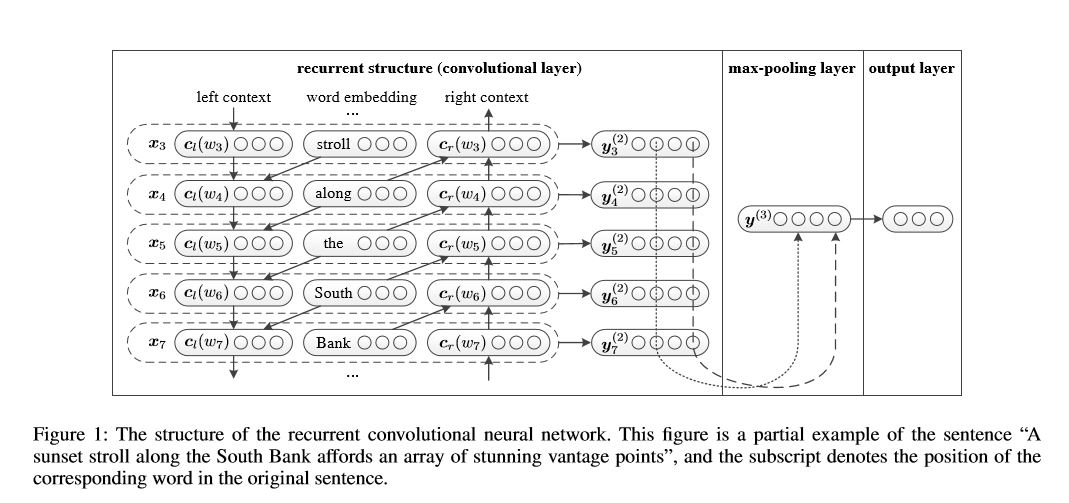
텍스트 분류를위한 반복 컨볼 루션 신경 네트워크
텍스트 분류를위한 재발 성 컨볼 루션 신경 네트워크 구현
구조 : 1) 재발 구조 (Convolutional Layer) 2) 최대 풀링 3) 완전히 연결된 레이어+SoftMax
문장에서 각 단어를 표현하거나 왼쪽 컨텍스트 및 오른쪽 컨텍스트로 문서를 배웁니다.
표현 current Word = [left_side_context_vector, current_word_embedding, right_side_context_vecotor].
왼쪽 컨텍스트의 경우, 이전 단어의 비선형 및 이전 컨텍스트의 반복적 인 구조를 사용합니다. 오른쪽 컨텍스트와 유사하게.
점검 : p71_textrcnn_model.py
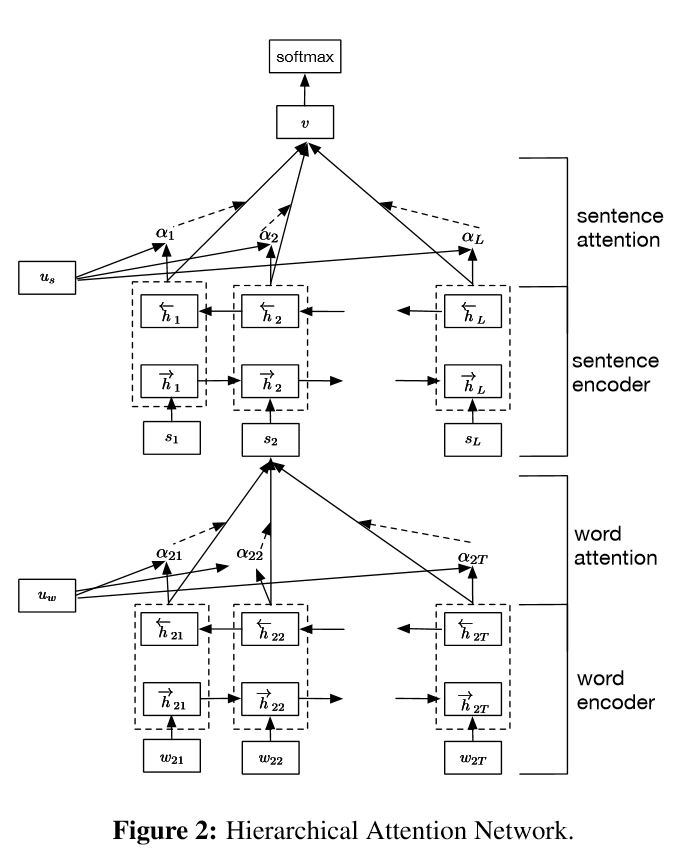
문서 분류를위한 계층 적주의 네트워크 구현
구조:
임베딩
Word Encoder : 단어 수준의 2 차 방향 Gru가 풍부한 단어를 나타냅니다.
단어 관심 : 문장에서 중요한 정보를 얻기위한 단어 수준의 관심
문장 인코더 : 문장의 풍부한 표현을 얻기위한 문장 레벨 양방향 GRU
문장 ATTETION : 문장 중 중요한 문장을 얻는 문장 수준의 관심
fc+softmax
NLP에서는 텍스트 분류는 단일 문장에 대해 수행 할 수 있지만 여러 문장에도 사용할 수 있습니다. 문서 분류라고 할 수 있습니다. 단어는 문장의 형태입니다. 문장은 문서화하는 형태입니다. 이 상황에서는 본질적인 구조가있을 수 있습니다. 그렇다면 어떻게 이런 종류의 작업을 모델링 할 수 있습니까? 문서의 모든 부분이 똑같이 관련되어 있습니까? 그리고 우리는 어떤 부분이 다른 부분보다 더 중요한 부분을 결정 하는가?
두 가지 독특한 기능이 있습니다.
1) 문서의 계층 구조를 반영하는 계층 구조가 있습니다.
2) 단어와 문장 수준에서 사용 된 두 가지 수준의주의 메커니즘이 있습니다. 모델이 다른 수준에서 중요한 정보를 캡처 할 수 있습니다.
Word Encoder : 문장의 각 단어에 대해 분포 벡터 공간의 Word 벡터에 포함됩니다. 양방향 GRU를 사용하여 문장을 인코딩합니다. 벡터를 두 방향으로 연결함으로써 이제 문장의 표현을 형성 할 수 있으며, 이는 상황 정보를 캡처합니다.
단어 관심 : 같은 단어는 문장에서 다른 단어보다 더 중요합니다. 따라서주의 메커니즘이 사용됩니다. 먼저 하나의 레이어 MLP를 사용하여 문장의 UIT 숨겨진 표현을 얻은 다음 단어의 중요성을 단어 수준 컨텍스트 벡터 UW와 UIT와 유사하게 측정하고 SoftMax 기능을 통해 정규화 된 중요성을 얻습니다.
문장 인코더 : 문장 벡터의 경우 양방향 GRU를 인코딩하는 데 사용됩니다. Word Encoder와 유사하게.
문장주의 : 문장 수준 벡터는 문장들 사이에서 중요성을 측정하는 데 사용됩니다. 단어 관심과 유사합니다.
데이터 입력 :
일반적으로,이 모델의 입력에는 릴리 문장 대신 서버 문장이 있어야합니다. 모양은 : [없음, sentence_lenght]. 어디에도 batch_size를 의미합니다.
훈련 데이터에는 각 예제에 네 부분이 있습니다. 각 부품의 길이는 동일합니다. 나는 하나의 단일 문장을 형성하기 위해 네 부분을 동의합니다. 이 모델은 문장을 네 부분으로 나누어 모양의 텐서를 형성합니다. [없음, num_sentence, sentence_length]. 여기서 num_sentence는 문장 수입니다 (내 설정에서 4와 같습니다).
점검 : p1_hierarchicalattention_model.py
세심한주의를 기울이면주의 깊은 관심을 확인할 수 있습니다
구현 SEQ2SEQ는 공동으로 조정하고 번역하는 법을 배우는 신경 기계 번역에서 파생 된주의를 기울여야합니다.
I. 구조 :
1) 임베딩 2) Bi-Gru도 소스 문장 (앞으로 및 뒤로)에서 풍부한 표현을 얻습니다. 3)주의가있는 디코더.
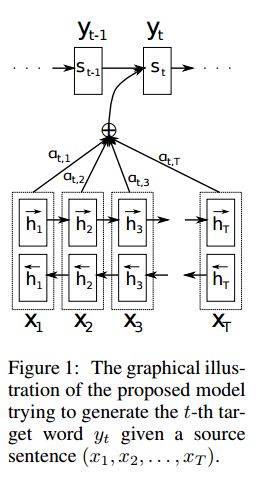
II. 데이터의 입력 :
세 가지 종류의 입력에는 다음과 같은 두 종류가 있습니다. 1) 인코더 입력, 문장입니다. 2) 디코더 입력, 길이가 고정 된 라벨 목록입니다. 3) 대상 라벨, 라벨 목록이기도합니다.
예를 들어, 라벨은 다음과 같습니다. "L1 L2 L3 L4", 디코더 입력은 다음과 같습니다. [_ GO, L1, L2, L2, L3, _PAD]; 대상 레이블은 다음과 같습니다. [L1, L2, L3, L3, _end, _PAD]. 길이는 6으로 고정되어 있고, 초과 레이블이 트랜스 킹되고, 레이블을 채우기에 충분하지 않은 경우 패드됩니다.
III.Attention 메커니즘 :
인코더 입력 목록 및 숨겨진 디코더 상태를 전송합니다
각 인코더 입력에 대한 가능성 분포를 얻으려면 각 인코더 입력과 함께 숨겨진 상태의 유사성을 계산하십시오.
가능성 분포에 기초한 인코더 입력의 가중 합.
이 중량 합계를 사용하여 RNN 셀을 사용하여 디코더 입력과 함께 새로운 숨겨진 상태를 얻으십시오.
iv. 바닐라 인코더 디코더의 작동 방식 :
소스 문장은 RNN을 고정 크기 벡터 ( "생각 벡터")로 사용하여 인코딩됩니다. 그런 다음 디코더 중에 :
훈련 할 때, 다른 RNN 은이 "생각 벡터"를 Init State로 사용하여 단어를 얻고 각 타임 스탬프에서 디코더 입력에서 입력을 취하는 데 사용됩니다. 디코더는 특수 토큰 "_go"에서 시작합니다. 한 단계가 수행되면 새로운 숨겨진 상태가 새로운 입력과 함께 모여 특별 토큰 "_end"에 도달 할 때 까지이 프로세스를 계속할 수 있습니다. 로그의 크로스 엔트로피 손실 및 대상 레이블을 계산하여 손실을 계산할 수 있습니다. 로그는 숨겨진 상태에 대한 투영 계층을 통과합니다 (Decoder 단계의 출력을 위해 (GRU에서는 디코더에서 숨겨진 상태를 출력으로 사용할 수 있음).
테스트 할 때 레이블이 없습니다. 그래서 우리는 이전 타임 스탬프에서 얻은 출력을 공급하고 "_end"토큰에 도달 한 프로세스를 계속해야합니다.
v. notices :
여기서 나는 두 종류의 어휘를 사용합니다. 하나는 인코더가 사용하는 단어에서 나온 것입니다. 다른 하나는 디코더에서 사용하는 라벨 용입니다
lables의 어휘를 위해서는 "_ go", "_ end", "_ pad"; 모든 레이블이 사전 정의되어 있으므로 "_unk"는 사용되지 않습니다.
상태 : 작업 분류를 수행 할 수있었습니다. 장난감 작업에서 시퀀스의 역순을 생성 할 수 있습니다. 모델에서 테스트 기능을 실행하여 확인할 수 있습니다. 점검 : a2_train_classification.py (기차) 또는 a2_transformer_classification.py (모델)
Layer 정규화, 잔류 연결 및 마스크도 모델에 사용됩니다.
모든 빌딩 블록의 경우 아래 각 파일에 테스트 기능이 포함되어 있으며 각 작은 조각을 성공적으로 테스트했습니다.
주의력이있는 시퀀스 시퀀스는 번역, 대화 시스템과 같은 시퀀스 생성 문제를 해결하기위한 전형적인 모델입니다. 대부분의 경우 RNN을 이러한 작업을 수행하기 위해 Buidling 블록으로 사용합니다. 최근에 사람들은 서열 문제에 대한 서열을 위해 Convolutional Neural Network를 적용합니다. 그러나 변압기는 이러한 작업을 Mechansim에만 해당합니다. 빠르며 새로운 최첨단 결과를 달성합니다.
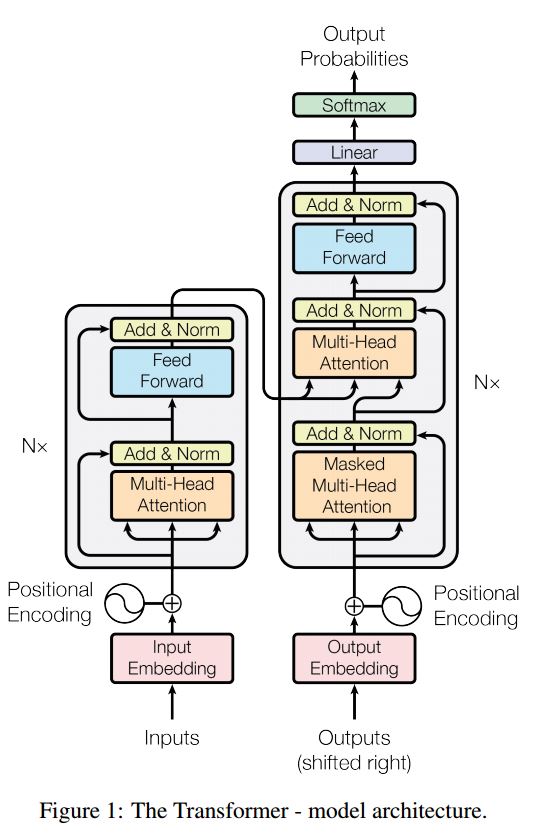
또한 인코더와 디코더의 두 가지 주요 부분이 있습니다. 아래는 종이의 DESC입니다.
인코더 :
6 개의 레이어. 각 레이어에는 2 개의 하위 계층이 있습니다. 첫 번째는 멀티 헤드 자체 정보 메커니즘입니다. 두 번째는 위치에 따라 완전히 연결된 피드 포워드 네트워크입니다. 각 하위 계이에 대해. Layernorm (x+Sublayer (x))를 사용하십시오. 모든 치수 = 512.
디코더 :
이 모델에서 메인 테이크 :
이 모델을 사용하여 작업 분류를 수행하십시오.
여기서 우리는 작업 분류에 인코딩 부분 만 사용하고, 저항 연결을 제거하고, 1 개의 레이어 만 사용합니다. 마스크를 사용할 필요가 없습니다. 우리는 다중 헤드주의와 사전 피드 포워드를 사용하여 입력 문장의 기능을 추출한 다음 선형 레이어를 사용하여 로그를 얻기 위해 투사합니다.
모델의 세부 사항은 다음을 확인하십시오 : A2_Transformer_classification.py
입력 : 1. 이야기 : 그것은 문맥과 같은 다중 문장입니다. 2. Query : 질문 인 3. Ansewr : 단일 레이블.
모델 구조 :
입력 인코딩 : 단어의 백을 사용하여 스토리 (컨텍스트) 및 쿼리 (질문); 위치 마스크를 사용하여 위치를 고려하십시오
양방향 RNN을 사용하여 스토리 및 쿼리를 인코딩하면 성능 향상은 0.392에서 0.398로 1.5%증가합니다.
동적 기억 :
에이. 키의 '유사성'을 사용하여 게이트를 계산합니다.
비. 각 키, 값 및 입력을 변환하여 후보 숨겨진 상태를 얻으십시오.
기음. 게이트와 후보 숨겨진 상태를 결합하여 현재 숨겨진 상태를 업데이트하십시오.
비. 가능성 분포를 사용하여 숨겨진 상태의 가중 합계를 얻으십시오.
기음. 예측 레이블을 얻기 위해 쿼리 및 숨겨진 상태의 비선형 변환.
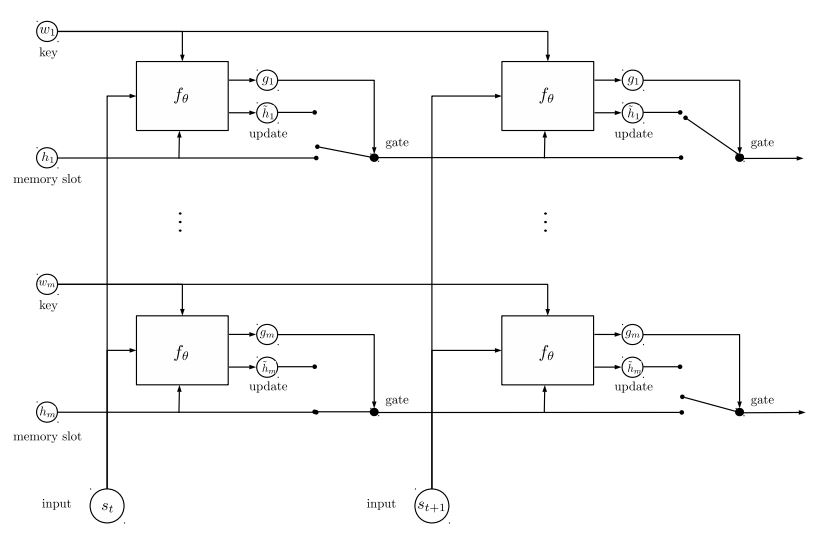
이 모델에서 메인 테이크 :
서로 독립적 인 키와 값의 블록을 사용하십시오. 따라서 병렬로 실행할 수 있습니다.
맥락과 질문을 함께 모델링합니다. 메모리를 사용하여 세계의 상태를 추적하십시오. 숨겨진 상태와 질문 (쿼리)의 비선형 변환을 사용하여 예측을합니다.
간단한 모델은 또한 매우 우수한 성능을 달성 할 수 있습니다. 단어의 사용 가방으로 간단한 인코딩.
모델의 세부 사항은 다음을 확인하십시오 : A3_entity_network.py
이 모델에는 테스트 기능이 있어이 모델에 스토리 (컨텍스트) 및 쿼리 (질문) 모두 숫자를 계산하도록 요청합니다. 그러나 이야기의 무게는 쿼리보다 작습니다.
모델의 전망 :
1. 유출 모듈 : 원시 텍스트를 벡터 표현으로 인코딩합니다
2. 질문 모듈 : 질문을 벡터 표현으로 인코딩합니다
3. 에피소드 메모리 모듈 : 입력을 사용하면 질문과 이전 메모리를 고려하여주의 메커니즘을 통해 초점을 맞출 입력 부분을 선택합니다.
4. ANSWER 모듈 : 최종 메모리 벡터에서 답을 생성합니다.
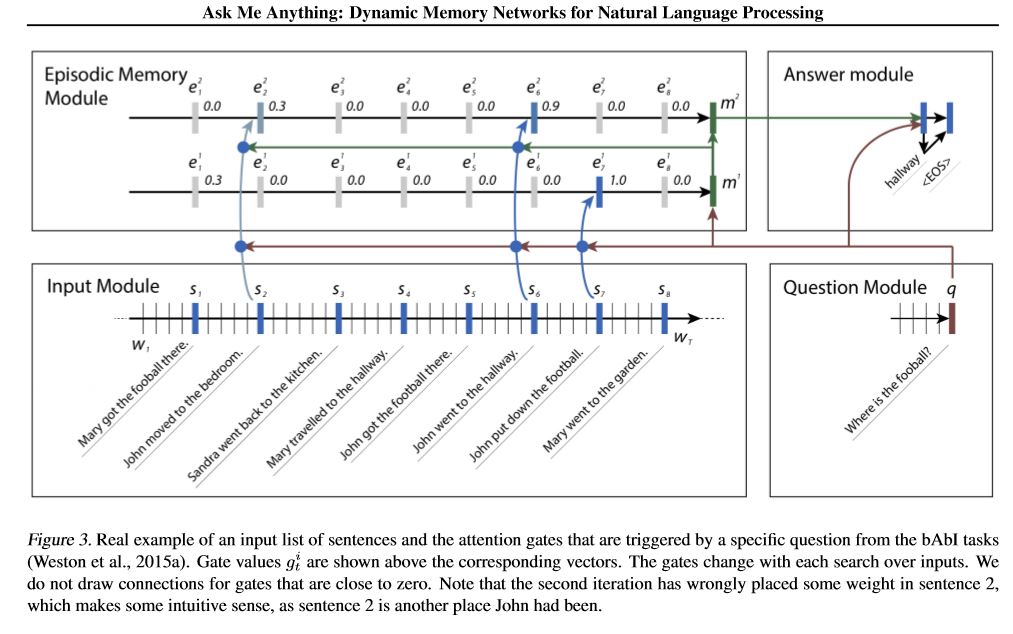
세부 사항:
1. 단지 모듈 :
A.Single 문장 : Gru를 사용하여 숨겨진 상태 B. 문장 목록 : Gru를 사용하여 각 문장에 대해 숨겨진 상태를 얻으십시오. 예 : [숨겨진 상태 1, 숨겨진 상태 2, 숨겨진 상태 ..., 숨겨진 상태 n]
2. 질문 모듈 : Gru를 사용하여 숨겨진 상태를 얻습니다
3. 에피소드 메모리 모듈 :
주의 메커니즘과 반복 네트워크를 사용하여 메모리를 업데이트하십시오.
에이. 주의 메커니즘으로서 게이트 :
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B. 메모리 업데이트 메커니즘 : 후보 문장, 게이트 및 이전 숨겨진 상태를 가져 가면 Gated-Gru를 사용하여 숨겨진 상태를 업데이트합니다. 유사 : H = F (C, H_Previous, G). 마지막 숨겨진 상태는 답변 모듈의 입력입니다.
C. 여러 에피소드의 경우 ===> 전이 적 추론.
예를 들어 축구는 어디에 있습니까? 그것은 "John이 축구를 내려 놓았다")라는 문장에 참석할 것입니다. 그리고 두 번째 패스에서 John의 위치에 참석해야합니다.
4. ANSWER 모듈 : 최종 EPSOIDIC 메모리, 질문을 사용하여 숨겨진 답변 모듈을 업데이트합니다.
1. 텍스트 분류를위한 character 수준 컨볼 루션 네트워크
2. 텍스트 분류를위한 공동 혁명 신경 네트워크 : 얕은 단어 수준 대 깊은 문자 수준
3. 텍스트 분류를위한 깊은 컨볼 루션 네트워크
4. 반 감독 된 텍스트 분류를위한 대류 훈련 방법
5. 어셈블 모델
대규모의 다중 표지 분류를 수행하는 과정에서 서버 레슨이 학습되었으며 일부는 다음과 같이 목록을 작성했습니다.
높은 정확도에 도달하는 가장 중요한 것은 무엇입니까? 그것은 당신이하고있는 일에 달려 있습니다. 우리가 여기서 수행 한 과제에서, 우리는 단어, 제목 및 설명을 포함한 여러 기능에서 훈련 된 모델을 기반으로 한 앙상블 모델이 매우 높은 어울리는 도달하는 데 도움이 될 수 있다고 생각합니다. 그러나 Alphago Zero Just 만 보여 지듯이 데이터 또는 계산 능력보다 알고리즘이 더 중요합니다. 실제로 Alphago Zero는 Humam 데이터를 사용하지 않았습니다.
특정 모델이나 알고리즘에 대한 천장이 있습니까? 대답은 예입니다. 여기서 많은 다른 모델이 사용되었으며, 우리는 구조가 상당히 다르더라도 많은 모델이 비슷한 성능을 가지고 있음을 발견했습니다. 어느 정도는 성능의 차이가 그리 크지 않습니다.
오류에 대한 사례 연구가 유용합니까? 나는 당신이 많은 다른 일을했을 때 특히 유용하지만 한계에 도달했을 때 매우 유용하다고 생각합니다. 예를 들어, 사례 연구를 통해 모델이 올바른 예측을 할 수 있고 실수를하는 위치를 찾을 수 있습니다. 이러한 잘못된 예측 레이블의 가중치를 증가 시키거나 데이터에서 잠재적 오류를 찾아 성능을 발휘합니다.
우리는 어떻게 특정 기계 학습에서 전문가가 될 수 있습니까? 제 생각에는 기계 학습 경쟁에 참여하거나 많은 데이터가있는 작업을 시작한 다음 논문을 읽고 일부를 구현하는 것이 좋은 출발점입니다. 따라서 우리는 특정 작업을 처리하는 경험과 아이디어를 가지고 있으며 그 과제를 알고 있습니다. 그러나 더 중요한 것은 논문의 아이디어를 따를뿐만 아니라 새로운 아이디어를 탐구해야한다고 생각하는 것이 문제를 잃는 데 도움이 될 수 있다는 것입니다. 예를 들어, 클래식 모델의 구조를 변경하거나 새로운 구조를 발명함으로써 우리는 우리가 수행하는 작업에 더 적합 할 수 있으므로 훨씬 더 나은 방법으로 문제를 해결할 수 있습니다.
1. 효율적인 텍스트 분류를위한 트릭 가방
2. 문장 분류를위한 공동 혁명 신경 네트워크
3. 문장 분류를위한 컨볼 루션 신경 네트워크의 민감도 분석 (및 실무자 안내서)
4. 챗봇에 대한 가파른 학습, 2 부-www.wildml.com에서 Tensorflow에서 검색 기반 모델 구현
5. 텍스트 분류를위한 컨볼 루션 컨볼 루션 신경 네트워크
6. 문서 분류를위한 계층 적주의 네트워크
7. 신경 기계 번역을 공동으로 조정하고 번역하는 법을 배우는 것
8. 소수가 필요한 전부입니다
9. 자연어 처리를위한 동적 메모리 네트워크
10. 반복적 인 엔티티 네트워크로 세계 상태를 추적합니다
11. 모델 라이브러리에서 탁월한 선택
12. 베르트 : 언어 이해를위한 깊은 양방향 변압기의 사전 훈련
13. Google-Research/Bert
계속하기 위해. 모든 문제에 대해서는 [email protected]을 연결하십시오


