text_classification
1.0.0
El propósito de este repositorio es explorar los métodos de clasificación de texto en PNL con aprendizaje profundo.
Personalice una API NLP en tres minutos, gratis: demostración de la API de NLP
Comprensión de idiomas El punto de referencia de evaluación para chino (punto de referencia de pista): ejecute 10 tareas y 9 líneas de base con una línea de código, comparación de rendimiento con detalles.
Liberando el modelo previamente entrenado de entrenamiento Albert_Chinese con 30G+ Raw Chinese Corpus, XXLarge, Xlarge y más, objetivo para igualar el rendimiento de última generación en chino, 2019-oct-7, ¡durante el Día Nacional de China!
¡Gran cantidad de corpus chino para PNL disponible!
Bert de Google logró un nuevo resultado de estado de arte en más de 10 tareas en PNL utilizando el modelo de lenguaje en el modelo de lenguaje.
sintonia FINA. PRINTO TEXCNN: IDEA DE BERT para la comprensión del lenguaje con el código de ejecución y el conjunto de datos
Tiene todo tipo de modelos de referencia para la clasificación de texto.
También admite la clasificación de múltiples etiquetas donde las etiquetas múltiples se asocian con una oración o documento.
Aunque muchos de estos modelos son simples y pueden no llevarlo al nivel superior de la tarea. Pero algunos de estos modelos son muy
clásico, por lo que pueden ser buenos para servir como modelos de referencia. Cada modelo tiene una función de prueba en la clase de modelo. Puedes correr
a la tarea de juguete de rendimiento primero. El modelo es independiente del conjunto de datos.
Consulte aquí para obtener un informe formal de clasificación de texto multiclabel a gran escala con aprendizaje profundo
Varios modelos aquí también se pueden usar para modelar la respuesta de preguntas (con o sin contexto), o para generar secuencias.
Exploramos dos modelos SEQ2SEQ (SEQ2SEQ con atención, la atención transformadora es todo lo que necesita) para hacer clasificación de texto.
y estos dos modelos también se pueden usar para secuencias generadoras y otras tareas. Si su tarea es una clasificación de múltiples etiquetas,
Puedes lanzar el problema a las secuencias generadoras.
Implementamos dos redes de memoria. Uno es la red de memoria dinámica. Anteriormente llegó al estado de arte en cuestión
Responder, análisis de sentimientos y tareas de generación de secuencias. Se llama un modelo para hacer varias tareas diferentes,
y alcanzar un alto rendimiento. Tiene cuatro módulos. El componente clave es el módulo de memoria episódica. Utiliza el mecanismo de puerta para
Atención de rendimiento y use GRU cerrado para actualizar la memoria del episodio, luego tiene otro Gru (en una dirección vertical) para
Actualización de estado oculto de rendimiento. Tiene la capacidad de hacer inferencia transitiva.
La segunda red de memoria que implementamos es la red de entidades recurrente: rastreo del estado del mundo. tiene bloques de
Los pares de valor clave como memoria se ejecutan en paralelo, que logran un nuevo estado de arte. Se puede usar para la pregunta de modelado
respondiendo con contextos (o historia). Por ejemplo, puede dejar que el modelo lea algunas oraciones (como contexto) y preguntarle a un
Pregunta (como consulta), luego pídale al modelo para predecir una respuesta; Si alimenta la historia igual que la consulta, entonces puede hacer
Tarea de clasificación.
Para discutir los problemas de ML/DL/NLP y obtener soporte técnico entre sí, puede unirse al Grupo QQ: 836811304
contenedor
Textcnn
BERT: pretruamiento de transformadores bidireccionales profundos para la comprensión del lenguaje
Textrnn
Rcnn
Red de atención jerárquica
seq2seq con atención
Transformer ("Asistir es todo lo que necesitas")
Red de memoria dinámica
EntityNetwork: Seguimiento del estado del mundo
Modelos de conjunto
Aumento:
Para un solo modelo, apila modelos idénticos juntos. Cada capa es un modelo. El resultado se basará en logits agregados. La única conexión entre las capas son los pesos de la etiqueta. La tasa de error de predicción de la capa delantera de cada etiqueta se convertirá en peso para las siguientes capas. Esas etiquetas con alta tasa de error tendrán un gran peso. Entonces, más tarde, Layer prestará más atención a esas etiquetas mal predicha e intentará corregir un error anterior de la antigua capa. Como resultado, obtendremos un modelo mucho fuerte. Verifique A00_Boosting/Boosting.py
y otros modelos:
Bilstmtextrelation;
twocnntextrelation;
Bilstmtextrelationtwornn
(Tarea de predicción de la etiqueta Mulit-Label, solicite predicción Top5, 3 millones de datos de entrenamiento, puntaje completo: 0.5)
| Modelo | contenedor | Textcnn | Textrnn | Rcnn | Jereattenet | Seq2seqattn | Entidad | DynamicMemory | Transformador |
|---|---|---|---|---|---|---|---|---|---|
| Puntaje | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| Capacitación | 10m | 2h | 10h | 2h | 2h | 3h | 3h | 5h | 7h |
El modelo Bert logra 0.368 después de la primera época del conjunto de validación.
Conjunto de textcnn, entitynet, DynamicMemory: 0.411
Entitynet EntityNet, DynamicMemory: 0.403
Aviso:
m de pie durante minutos ; h Stand durante horas ;
HierAtteNet significa Red de atención jerárquica;
Seq2seqAttn significa SEQ2SEQ con atención;
DynamicMemory significa DynamicMemoryNetwork;
Transformer Stand for Model de 'La atención es todo lo que necesitas'.
xxx_model.pyxxx_train.py para entrenar el modeloxxx_predict.py para hacer inferencia (prueba).Cada modelo tiene un método de prueba bajo la clase modelo. Primero puede ejecutar el método de prueba para verificar si el modelo puede funcionar correctamente.
Python 2.7+ TensorFlow 1.8
(TensorFlow 1.1 a 1.13 también debería funcionar; la mayoría de los modelos también deberían funcionar bien en otra versión de TensorFlow, ya que nosotros
Utilice muy pocas características Bond para determinada versión.
Si usa Python3, estará bien siempre que cambie la función de impresión/prueba de captura en caso de que cumpla con algún error.
El modelo TextCNN ya está transfomentado a Python 3.6
Para ayudarlo a ejecutar este repositorio, actualmente reiniciamos la capacitación/validación/datos de prueba y vocabulario/etiquetas, y guardamos
ellos como archivo de caché usando H5PY. Le sugerimos que lo descargue desde el enlace anterior.
Contiene todo lo que necesita para ejecutar este repositorio: los datos están preprocesados, puede comenzar a entrenar el modelo en un minuto.
Es un archivo zip de aproximadamente 1.8 g, contiene 3 millones de datos de capacitación. Aunque después de la descremisión es bastante grande, pero con la ayuda de
HDF5, solo necesita un tamaño normal de memoria de la computadora (p. Ej. G o menos) durante el entrenamiento.
Utilizamos el cuaderno Jupyter: preprocesamiento.ipynb para preprocesar datos. Puede comprender mejor esta tarea y
datos al echar un vistazo. También puede generar datos por sí mismo de la manera que desee, simplemente cambie algunas líneas de código
Usando este cuaderno Jupyter.
Si desea probar un modelo ahora, puede descargar el archivo en caché desde arriba, luego vaya a la carpeta 'a02_textcnn', ejecute
python p7_TextCNN_train.py
Utilizará datos de archivos en caché para entrenar el modelo e imprimir la pérdida y el puntaje F1 periódicamente.
Fuente de datos de muestra anterior: si necesita algunos datos de muestra e incrustación de palabras por entrenamiento en Word2Vec, puede encontrarlo en problemas cerrados, como: número 3.
También puede encontrar algunos datos de muestra en la carpeta "datos". Contiene dos archivos: 'sample_single_label.txt', contiene 50k datos
con etiqueta única; 'sample_multiple_label.txt', contiene 20k datos con múltiples etiquetas. La entrada y la etiqueta de están separadas por " etiqueta ".
Si desea saber más detalles sobre el conjunto de datos de la clasificación o tarea de texto, estos modelos se pueden usar, uno de elección está a continuación:
https://biendata.com/competition/zhihu/
Una forma en que puede usar este repositorio:
Paso 1: Puedes leer este artículo. Obtendrá una idea general de varios modelos clásicos utilizados para hacer clasificación de texto.
Paso 2: Datos de preprocesamiento y/o descargue el archivo en caché.
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
Paso 3: Ejecute algunos de los modelos Listas aquí y cambie algunos códigos y configuraciones como desee, para obtener un buen rendimiento.
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
Además, escriba su artículo sobre este tema, puede seguir el estilo de Paper para escribir. Es posible que necesite leer algunos documentos
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
Reemplace los datos en 'data/sample_multiple_label.txt', y asegúrese de formato a continuación:
'Word1 Word2 Word3 __label__L1 __label__l2 __label__l3'
donde parte1: 'word1 word2 word3' es entrada (x), parte2: '__label__l1 __label__l2 __label__l3'
Representando que hay tres etiquetas: [L1, L2, L3]. Entre Parte1 y Parte2 debe haber una cadena vacía: ''.
Por ejemplo: cada línea (varias etiquetas) como:
'W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __label__56266666165638885119 __Bel__492179380534662865 __label__8904735555009151318 '
donde '5626661657638885119', '4921793805334628695' , '8904735555009151318' son tres etiquetas asociadas con esta cadena de entrada 'W5466 W138990 ... C699 C317 C184' '
Aviso:
Alguna función Util está en data_util.py; Verifique load_data_multilabel () de data_util sobre cómo el proceso de entrada y etiquetas de los datos sin procesar.
Hay una función para cargar y asignar una incrustación de palabras previas al modelo, donde la incrustación de palabras está provocada en Word2Vec o FastText.
Si Word2Vec.Load no funciona, puede cargar una incrustación de palabras previas, especialmente para la incrustación de palabras chinas, uso de las siguientes líneas:
importar gensim
de gensim.models import keyEdvectores
word2vec_model = keyEdvectors.load_word2vec_format (word2vec_model_path, binary = true, unicode_errors = 'ignorar') #
O puede desactivar el indicador de incrustación de palabras de prehrain en falso para deshabilitar la incrustación de palabras de carga.
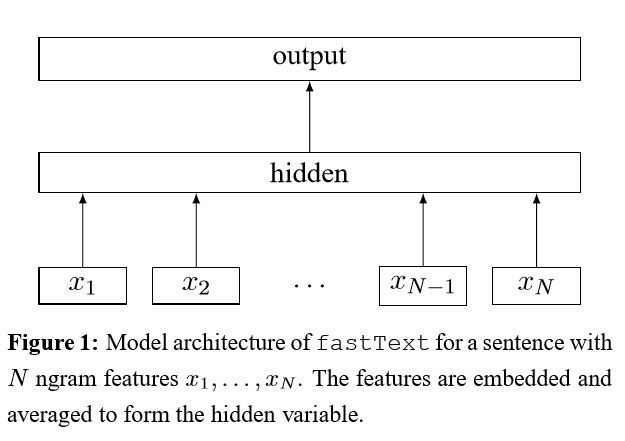
Implementación de la bolsa de trucos para una clasificación de texto eficiente
Después de incrustar cada palabra en la oración, estas representaciones de palabras se promedian en una representación de texto, que a su vez se alimenta a un clasificador lineal. Utilice la función Softmax para calcular la distribución de probabilidad sobre las clases predefinidas. Luego se usa la entropía cruzada para calcular la pérdida. La bolsa de representación de palabras no considera el orden de las palabras. Para tener en cuenta el orden de las palabras, las características de N-Gram se usan para capturar información parcial sobre el orden local de palabras; Cuando el número de clases es grande, calcular el clasificador lineal es costoso. Por lo tanto, utiliza el proceso de entrenamiento SoftMax para acelerar.
Resultado: el rendimiento es tan bueno como el papel, la velocidad también muy rápida.
Verifique: P5_FastTextB_Model.py
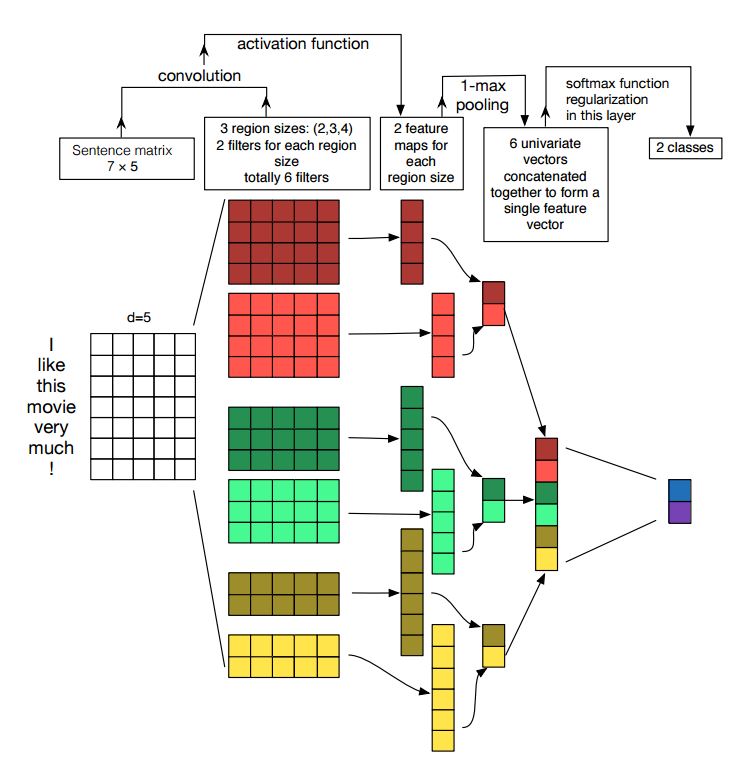
Implementación de redes neuronales convolucionales para la clasificación de oraciones
Estructura: Incrustación ---> Conv ---> Agrupación máxima ---> Capa totalmente conectada --------> Softmax
Verifique: P7_TextCnn_Model.py
Para obtener un muy buen resultado con TextCNN, también debe leer cuidadosamente sobre este documento un análisis de sensibilidad de (y la guía de profesionales para) redes neuronales convolucionales para la clasificación de oraciones: le da algunas ideas de cosas que pueden afectar el rendimiento. Aunque necesita cambiar algunas configuraciones de acuerdo con su tarea específica.
La red neuronal convolucional es la principal caja de construcción para resolver problemas de visión por computadora. Ahora mostraremos cómo se puede usar CNN para la PNL, en particular, la clasificación de texto. La longitud de la oración será diferente de una a otra. Por lo tanto, usaremos almohadilla para obtener una longitud fija, n. Para cada token en la oración, utilizaremos la incrustación de palabras para obtener un vector de dimensión fija, d. Entonces, nuestra entrada es una matriz de 2 dimensiones: (N, D). Esto es similar con la imagen para CNN.
En primer lugar, haremos una operación convolucional a nuestra entrada. Es una multiplica en cuanto al elemento entre el filtro y parte de la entrada. Usamos k número de filtros, cada tamaño del filtro es una matriz de 2 dimensiones (F, D). Ahora la salida será K número de listas. Cada lista tiene una longitud de N-F+1. Cada elemento es un escalar. Observe que la segunda dimensión será siempre la dimensión de la incrustación de palabras. Estamos utilizando diferentes tamaños de filtros para obtener funciones ricas de las entradas de texto. Y esto es algo similar con las características de N-Gram.
En segundo lugar, haremos una agrupación máxima para la salida de operación convolucional. Para K número de listas, obtendremos k número de escalares.
En tercer lugar, concatenaremos escalares para formar características finales. Es un vector de tamaño fijo. Y es independiente del tamaño de los filtros que usamos.
Finalmente, utilizaremos una capa lineal para proyectar estas características a etiquetas por definición.
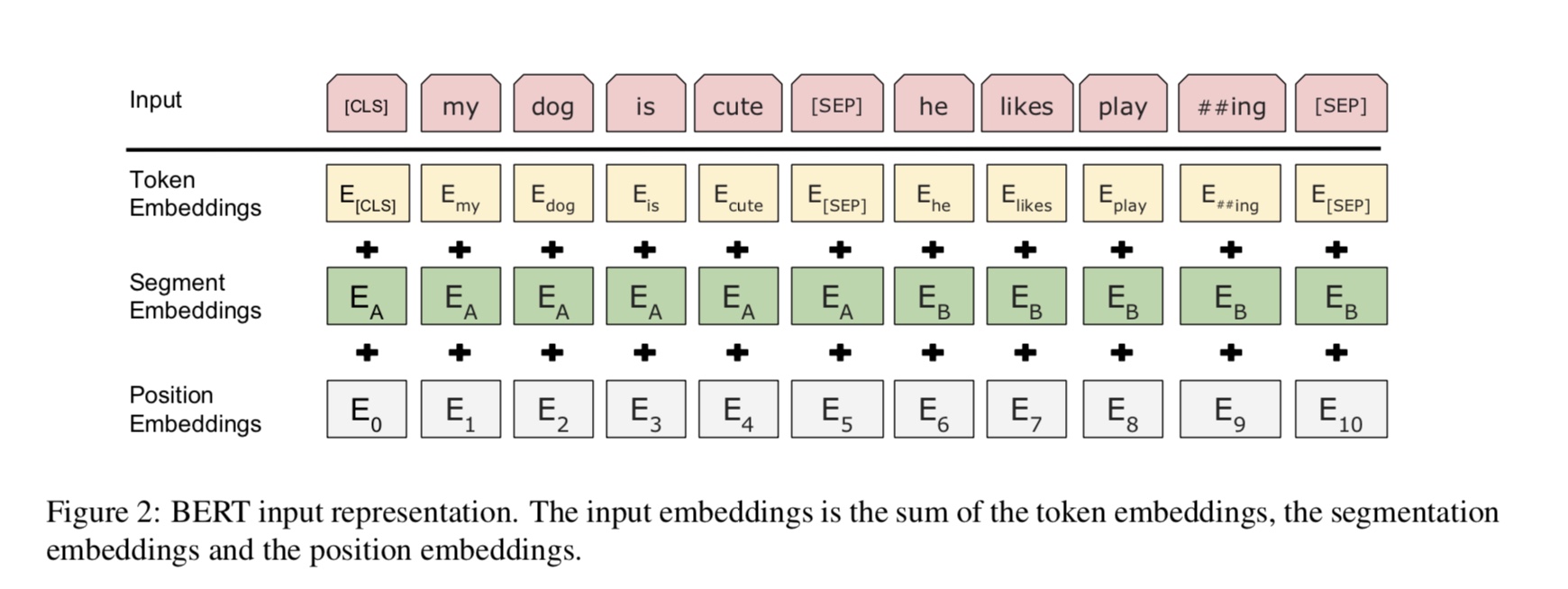
Bert actualmente logró resultados de estado de arte en más de 10 tareas de PNL. Las ideas clave detrás de este modelo es que podemos
Pre-entrenado el modelo utilizando un tipo de modelo de lenguaje con una gran cantidad de datos sin procesar, donde puede encontrarlo fácilmente.
Como la mayoría de los parámetros del modelo están previamente entrenados, solo la última capa para el clasificador debe ser necesaria para diferentes tareas.
Como resultado, este modelo es genérico y muy poderoso. puede ajustar en función del modelo previamente capacitado dentro de
un corto período de tiempo.
Sin embargo, este modelo es bastante grande. Con la longitud de secuencia 128, solo puede entrenar con un tamaño por lotes de 32; por mucho tiempo
documento como la longitud de secuencia 512, solo puede entrenar un tamaño de lote 4 para una GPU normal (con 11g); y muy pocas personas
puede pre-entrenar este modelo desde cero, ya que lleva muchos días o semanas entrenar, y la memoria de una GPU normal es demasiado pequeña
para este modelo.
Especialmente, el modelo de columna vertebral es transformador, donde puede encontrarlo en atención es todo lo que necesita. usa dos tipos de
Tareas para priorizar el modelo.
En términos generales, dada una oración, un porcentaje de palabras está enmascarado, deberá predecir las palabras enmascaradas
basado en esta oración enmascarada. Las palabras enmascaradas se chocan al azar.
Alimentamos la entrada a través de un codificador de transformador profundo y luego usamos los estados ocultos finales correspondientes al enmascarado
posiciones para predecir qué palabra estaba enmascarada, exactamente como capacitaríamos a un modelo de idioma.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
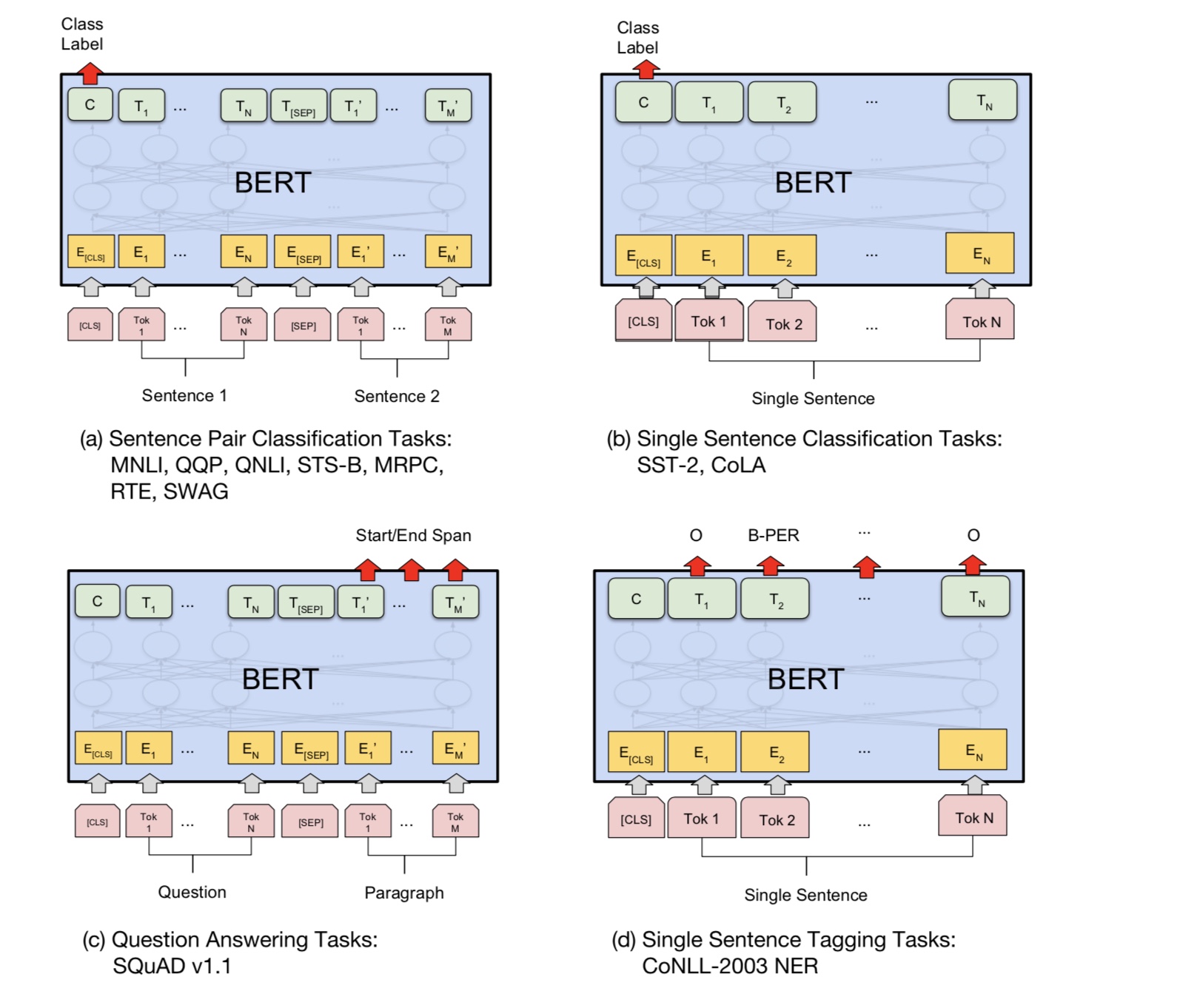
Muchas tareas de comprensión del lenguaje, como la respuesta de las preguntas, la inferencia, necesitan entender la relación
entre oración. Sin embargo, el modelo de idioma solo puede entender sin una oración. Siguiente oración
La predicción es una tarea de muestra para ayudar a modelar a comprender mejor en este tipo de tareas.
50% de la posibilidad La segunda oración es la próxima oración de la primera, el 50% de no la siguiente.
Dada dos oraciones, se le pide al modelo que predice si la segunda oración es real la próxima oración de
el primero.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
Básicamente, puede descargar el modelo previamente capacitado, puede ajustar su tarea con sus propios datos.
Para la tarea de clasificación, puede agregar procesador para definir el formato que desea dejar que la entrada y las etiquetas de los datos de origen.
Ejecute el siguiente comando en la carpeta A00_Bert:
python train_bert_multi-label.py
Logra 0.368 después de 9 época. o puede ejecutar la clasificación de múltiples etiquetas con datos descargables utilizando Bert desde
sentiment_analysis_fine_grain con Bert
Puede usar la sesión y el estilo de alimentación para restaurar los datos del modelo y la alimentación, luego obtener logits para hacer una predicción en línea.
Predicción en línea con Bert
Originalmente, capacita o evalúa el modelo basado en el archivo, no para en línea.
En primer lugar, puede usar la descarga del modelo previamente capacitado desde Google. Ejecute algunas época en su conjunto de datos y encuentre un
longitud de secuencia.
En segundo lugar, puede priorizar el modelo base en sus propios datos siempre que pueda encontrar un conjunto de datos relacionado con
Su tarea, luego ajustado en su tarea específica.
En tercer lugar, puede cambiar la función de pérdida y la última capa para adaptarse mejor a su tarea.
Además, puede agregar Definir algunas tareas previamente capacitadas que ayudarán al modelo a comprender su tarea mucho mejor.
Como experimentado, obtuvimos de los experimentos, la tarea previamente capacitada es independiente del modelo y el pre-entrenador no es límite a
las tareas anteriores.
Estructura V1: Incrustación ---> LSTM bidireccional ---> Salida de concat ---> promedio -----> Softmax capa
Verifique: P8_TEXTRNN_MODEL.PY
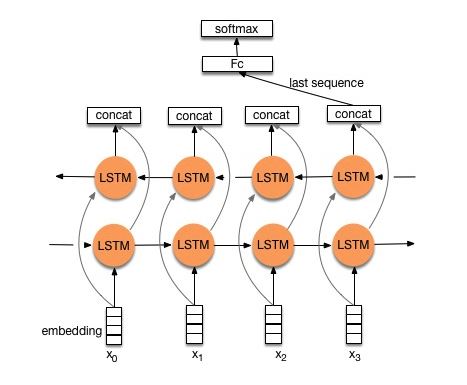
Estructura v2: incrustación-> LSTM bidireccional ----> abandono-> concat outuPut ---> lstm ---> droput-> fc capa-> capa softmax
Verifique: P8_TEXTRNN_MODEL_MULTILAYER.PY
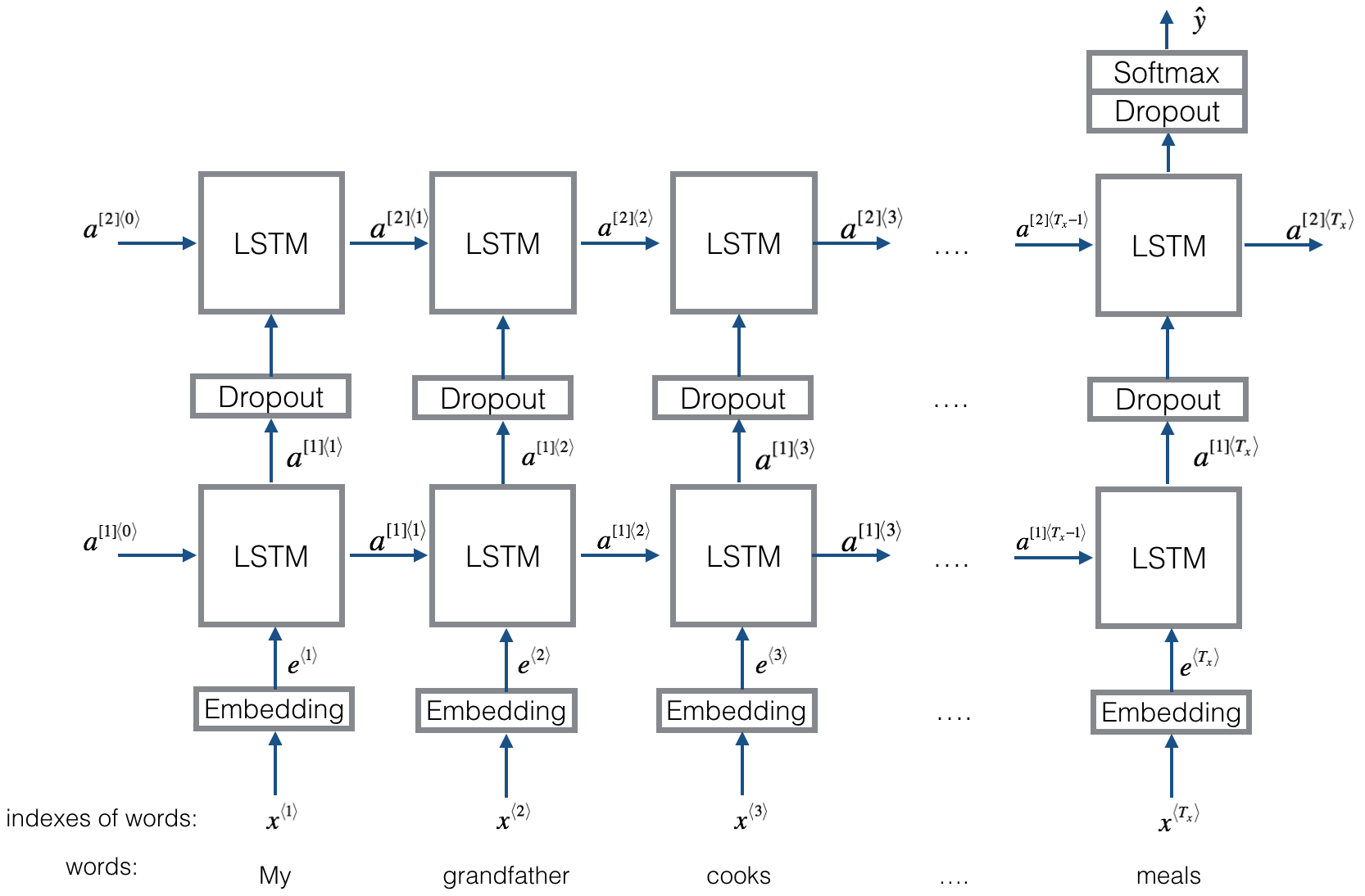
Estructura igual que Textrnn. Pero la entrada está diseñada especial. Eginput: "¿Cuánto cuesta la computadora? El precio de la computadora portátil EOS". Donde 'EOS' es una pregunta especial de token arpilada 1 y pregunta2.
Compruebe: P9_BilstMTEXtrelation_model.py
Estructura: Primero use dos características convolucionales diferentes para extraer de dos oraciones. luego concat de dos características. Use la capa de transformación lineal a la proyección de la etiqueta de destino, luego Softmax.
Verifique: P9_TWOCNNTEXTRELATION_MODEL.PY
Estructura: un LSTM bidireccional para una oración (Get Outtut1), otro LSTM bidireccional para otra oración (Get Outtide2). Entonces: Softmax (salida1 m de salida2)
Verifique: P9_BILSTMTEXTRELATIONTWORNN_MODEL.PY
Para obtener más detalles, puede ir a: Aprendizaje profundo para chatbots, Parte 2-Implementación de un modelo basado en la recuperación en TensorFlow
Red neuronal convolucional recurrente para la clasificación de texto
Implementación de una red neuronal convolucional recurrente para la clasificación de texto
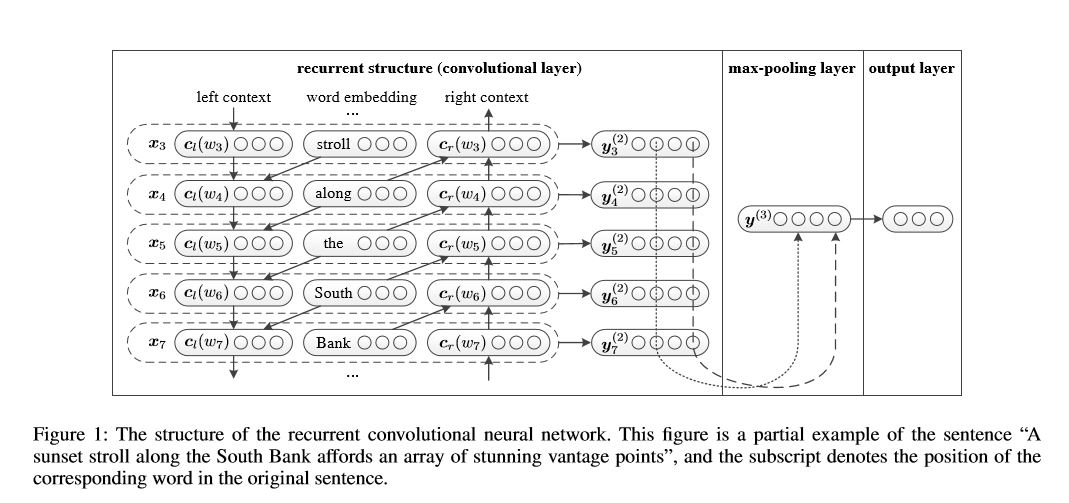
Estructura: 1) Estructura recurrente (capa convolucional) 2) Agrupación máxima 3) Capa totalmente conectada+Softmax
Aprende la representación de cada palabra en la oración o documento con contexto del lado izquierdo y contexto del lado derecho:
Representation Current Word = [Left_side_context_vector, current_word_embedding, derecho_side_context_vecotor].
Para el contexto del lado izquierdo, utiliza una estructura recurrente, una transferencia de no linealidad de la palabra anterior y el contexto anterior del lado izquierdo; Del mismo modo al contexto del lado derecho.
Verifique: P71_Textrcnn_Model.py
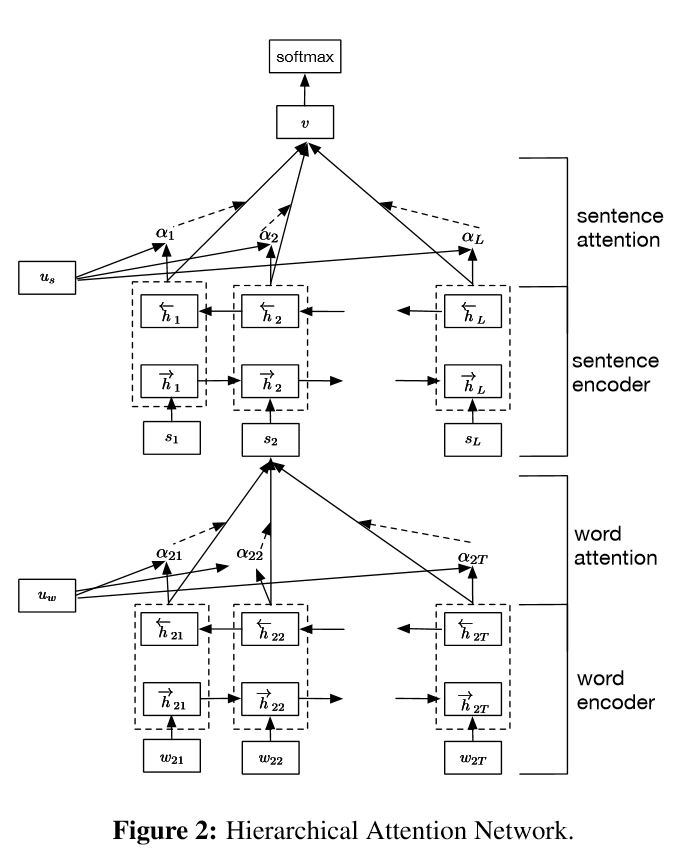
Implementación de redes de atención jerárquica para la clasificación de documentos
Estructura:
incrustación
Codador de palabras: Nivel de palabra GRU bidireccional para obtener una representación rica de las palabras
Atención de palabras: Nivel de palabra Atención para obtener información importante en una oración
Codificador de oraciones: nivel de oración Gru bidireccional para obtener una representación rica de las oraciones
Atención de oraciones: nivel de oración atención para obtener una oración importante entre las oraciones
FC+Softmax
En PNL, la clasificación de texto se puede hacer para una sola oración, pero también se puede usar para múltiples oraciones. Podemos llamarlo clasificación de documentos. Las palabras son de forma a oración. Y la oración se forman para documentar. En esta circunstancia, puede existe una estructura intrínseca. Entonces, ¿cómo podemos modelar este tipo de tareas? ¿Todas las partes del documento son igualmente relevantes? ¿Y cómo determinamos qué parte son más importantes que otra?
Tiene dos características únicas:
1) tiene una estructura jerárquica que refleja la estructura jerárquica de los documentos;
2) Tiene dos niveles de mecanismos de atención utilizados en la palabra y el nivel de oración. Permite que el modelo capture información importante en diferentes niveles.
Codador de palabras: para cada palabras en una oración, está integrado en el vector de palabras en el espacio del vector de distribución. Utiliza un Gru bidireccional para codificar la oración. Por vector concatenado desde dos direcciones, ahora puede formar una representación de la oración, que también captura información contextual.
Atención de palabras: las mismas palabras son más importantes que otra para la oración. Entonces se utiliza el mecanismo de atención. Primero usa una capa MLP para obtener una representación oculta de UIT de la oración, luego mide la importancia de la palabra como la similitud de UIT con un vector de contexto de nivel de palabra UW y obtiene una importancia normalizada a través de una función Softmax.
Codificador de oraciones: para vectores de oración, se usa Gru bidireccional para codificarlo. Del mismo modo al codificador de Word.
Atención de oraciones: el vector de nivel de oración se usa para medir la importancia entre las oraciones. Del mismo modo a la atención de la palabra.
Entrada de datos:
En términos generales, la entrada de este modelo debe tener oraciones Serveral en lugar de la oración sinle. La forma es: [ninguno, oración_lenght]. donde ninguno significa el lote_size.
En mis datos de entrenamiento, para cada ejemplo, tengo cuatro partes. Cada parte tiene la misma longitud. Concurso cuatro partes para formar una sola oración. El modelo dividirá la oración en cuatro partes, para formar un tensor con forma: [ninguno, num_sentence, orents_length]. donde num_sentence es el número de oraciones (igual a 4, en mi configuración).
Verifique: P1_HierchicalAtention_model.py
Para una atención atenta, puede verificar la atención atenta
Implementación SEQ2SEQ con atención derivada de la traducción del automóvil neuronal al aprender conjuntamente a alinear y traducir
I.STRUCTURA:
1) Incrustación 2) Bi-Gru también obtenga una representación rica de las oraciones de origen (hacia adelante y hacia atrás). 3) decodificador con atención.
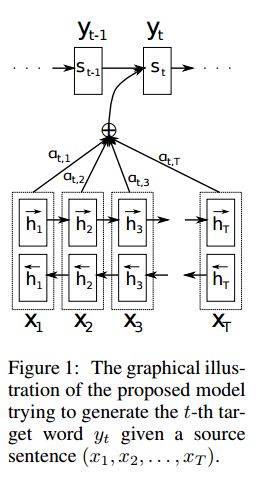
Ii.Input of Data:
Hay dos tipos de tres tipos de entradas: 1) entradas del codificador, que es una oración; 2) Entradas del decodificador, es una lista de etiquetas con longitud fija; 3) etiquetas de destino, también es una lista de etiquetas.
Por ejemplo, las etiquetas son: "L1 L2 L3 L4", luego las entradas del decodificador serán: [_ _ Go, L1, L2, L2, L3, _pad]; La etiqueta de destino será: [L1, L2, L3, L3, _END, _PAD]. La longitud se fija a 6, cualquier etiqueta excedente se trate, se enmohará si la etiqueta no es suficiente para llenar.
Iii. Mecanismo de atención:
Lista de insumos del codificador de transferencia y estado oculto del decodificador
Calcule la similitud del estado oculto con cada entrada del codificador, para obtener la distribución de posibilidades para cada entrada del codificador.
Suma ponderada de entrada del codificador basada en la distribución de posibilidades.
Vaya a través de la celda RNN usando esta suma de peso junto con la entrada del decodificador para obtener un nuevo estado oculto
IV. Cómo funciona el decodificador de codificadores de vainilla:
La oración de origen se codificará utilizando RNN como vector de tamaño fijo ("Vector de pensamiento"). Luego durante el decodificador:
Cuando se trata de capacitación, se usará otro RNN para tratar de obtener una palabra utilizando este "vector de pensamiento" como estado init, y tomar la entrada de la entrada del decodificador en cada marca de tiempo. El decodificador comienza desde el token especial "_go". Después de realizar un paso, el nuevo estado oculto se obtendrá y, junto con una nueva entrada, podemos continuar este proceso hasta llegar a un token especial "_end". Podemos calcular la pérdida al calcular la pérdida de la entropía cruzada de logits y la etiqueta de destino. Logits es pasar a través de una capa de proyección para el estado oculto (para la salida del paso del decodificador (en Gru solo podemos usar los estados ocultos del decodificador como salida).
Cuando se realiza una prueba, no hay etiqueta. Por lo tanto, debemos alimentar la salida que obtenemos de la marca de tiempo anterior, y continuar el proceso Utilizamos que alcanzamos el token "_end".
V.NOTICAS:
Aquí uso dos tipos de vocabularios. Uno es de palabras, utilizada por el codificador; otro es para etiquetas, utilizadas por decoder
Para el vocabulario de Lables, inserto tres token especial: "_ Go", "_ End", "_ Pad"; "_Unk" no se usa, ya que todas las etiquetas están predefinidas.
Estado: fue capaz de hacer la clasificación de tareas. y capaz de generar el orden inverso de sus secuencias en la tarea de juguete. Puede verificarlo ejecutando la función de prueba en el modelo. Compruebe: a2_train_classification.py (trenes) o a2_transformer_classification.py (modelo)
Lo hacemos en el estilo Parallell. La normalización de la capa, la conexión residual y la máscara también se usan en el modelo.
Para cada bloques de construcción, incluimos una función de prueba en cada archivo a continuación, y hemos probado cada pieza pequeña con éxito.
La secuencia a la secuencia con atención es un modelo típico para resolver el problema de generación de secuencias, como la traducción, el sistema de diálogo. La mayor parte del tiempo, usa RNN como bloqueo de ruptura para hacer estas tareas. Util recientemente, las personas también aplican una red neuronal convolucional para el problema de secuencia a secuencia. Transformador, sin embargo, realiza estas tareas únicamente en la atención mechansim. Es rápido y logra un nuevo resultado de última generación.
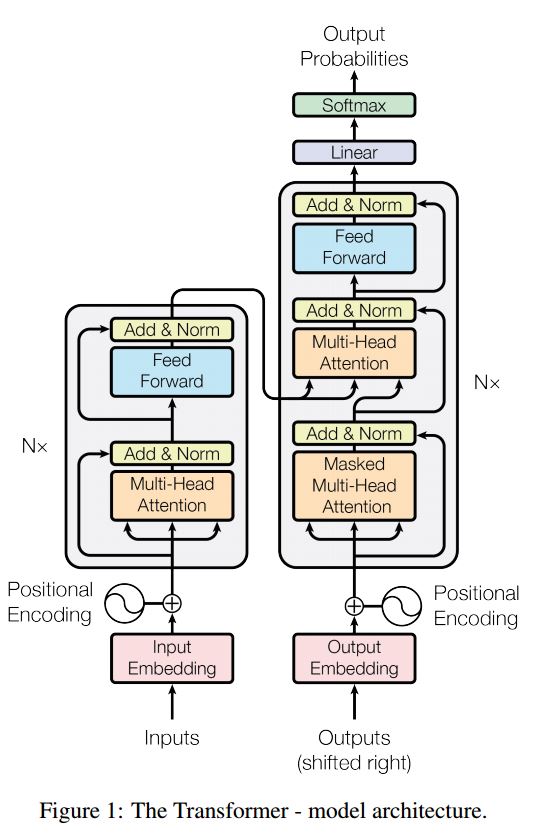
También tiene dos partes principales: codificador y decodificador. A continuación se muestra Desc del papel:
Codificador:
6 capas. Cada capas tienen dos subcapas. El primero es el mecanismo de autoatención de múltiples cabezas; El segundo es la red de alimentación completamente conectada en cuanto a posición. para cada subcapitán. Use Layernorm (X+SuBlayer (x)). Toda la dimensión = 512.
Descifrador:
Principal quitarle este modelo:
Use este modelo para hacer la clasificación de tareas:
Aquí solo usamos la parte de codificación para la clasificación de tareas, eliminó la conexión Resdiual, usamos solo 1 capa. No es necesario usar la máscara. Utilizamos la atención de múltiples cabezas y la alimentación de postes para extraer características de la oración de entrada, luego usamos una capa lineal para proyectarla para obtener logits.
Para obtener detalles del modelo, verifique: A2_Transformer_Classification.py
Entrada: 1. Historia: Es multitud de oraciones, como contexto. 2. Query: una oración, que es una pregunta, 3. Ansewr: una sola etiqueta.
Estructura del modelo:
Codificación de entrada: use la bolsa de Word para codificar la historia (contexto) y la consulta (pregunta); Tenga en cuenta la posición utilizando la máscara de posición
Al usar RNN bidireccional para codificar la historia y la consulta, el aumento del rendimiento de 0.392 a 0.398, aumente 1.5%.
Memoria dinámica:
a. Calcule la puerta utilizando 'similitud' de claves, valores con entrada de historia.
b. Obtenga el estado oculto candidato transformar cada clave, valor y entrada.
do. Combine Gate y candidato Hidden State para actualizar el estado oculto actual.
b. Obtenga una suma ponderada del estado oculto utilizando la distribución de posibilidades.
do. Transformación de no linealidad de consulta y estado oculto para obtener la etiqueta de predicción.
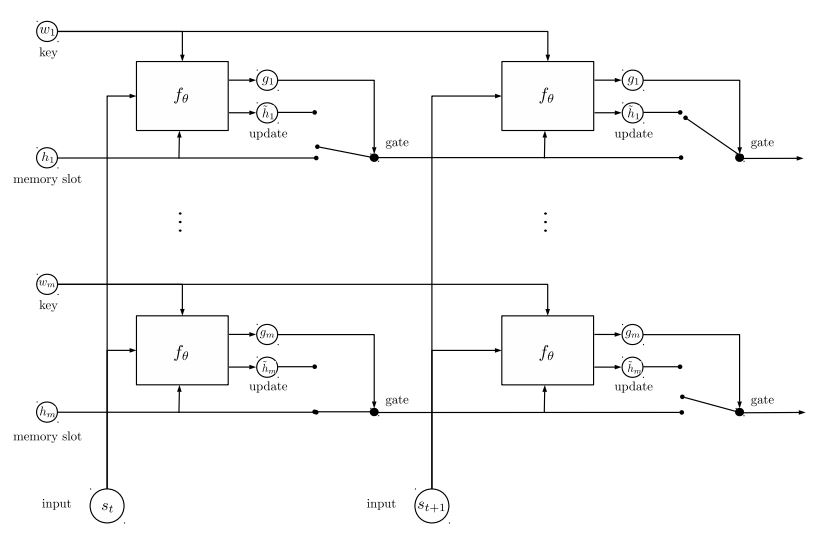
Principal quitarle este modelo:
Use bloques de claves y valores, que son independientes entre sí. Entonces se puede ejecutar en paralelo.
Modelado del contexto y la pregunta juntos. Use la memoria para rastrear el estado del mundo; y use la transformación de no linealidad del estado oculto y la pregunta (consulta) para hacer una predicción.
El modelo simple también puede lograr un muy buen rendimiento. Codificación simple como Usar bolsa de Word.
Para obtener detalles del modelo, verifique: A3_entity_network.py
Bajo este modelo, tiene una función de prueba, que pide a este modelo que cuente los números tanto para la historia (contexto) como para la consulta (pregunta). Pero los pesos de la historia son más pequeños que la consulta.
Perspectiva del modelo:
1. Módulo de entrada: codifica los textos sin procesar en la representación vectorial
2. Módulo de cuestión: codifica la pregunta en la representación vectorial
3. Módulo de memoria episódica: con las entradas, elige en qué partes de las entradas centrarse a través del mecanismo de atención, teniendo en cuenta la pregunta y la memoria previa ====> que mora un Vecotr de 'memoria'.
4. Módulo de respuesta: Genere una respuesta desde el vector de memoria final.
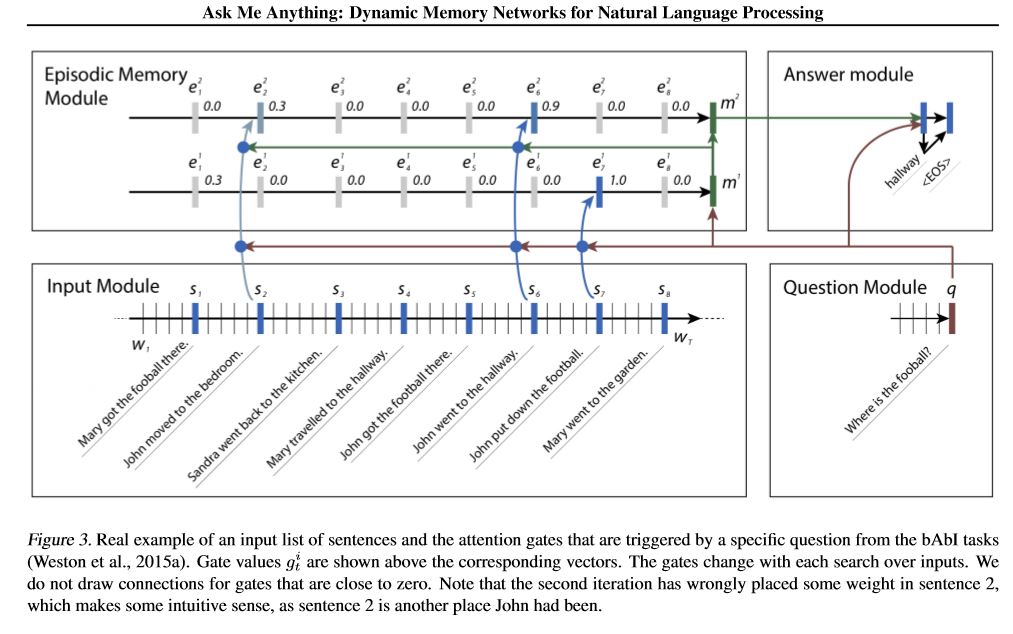
Detalle:
1. Módulo de entrada:
A. Sentencia: Use Gru para obtener el estado oculto B. Lista de oraciones: Use Gru para obtener los estados ocultos para cada oración. por ejemplo, [Estados ocultos 1, Estados ocultos 2, estados ocultos ..., Estado oculto n]
2. Módulo de cuestión: use GRU para obtener un estado oculto
3. Módulo de memoria episódica:
Use un mecanismo de atención y una red recurrente para actualizar su memoria.
a. puerta como mecanismo de atención:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B. Mecanismo de actualización de la memoria: tome la oración candidata, la puerta y el estado oculto anterior, usa Great-Gru para actualizar el estado oculto. Como: H = F (C, H_Previous, G). El estado oculto final es la entrada para el módulo de respuesta.
C.Need para múltiples episodios ===> Inferencia transitiva.
por ejemplo, preguntar ¿dónde está el fútbol? Asistirá a la oración de "John, el fútbol"), luego en el segundo pase, debe asistir a la ubicación de John.
4. Módulo de respuesta: tome la memoria epsoidica final, pregunta, actualice el módulo de estado oculto de estado.
1. Redes convolucionales a nivel de caracteres para la clasificación de texto
2. Redes neuronales conconvolutivas para la categorización de texto: nivel de palabra superficial versus a nivel de carácter profundo
3. Redes convolucionales muy profundas para la clasificación de texto
4. Métodos de entrenamiento adversario para la clasificación de texto semi-supervisado
5. Modelos de ensamblaje
Durante el proceso de hacer una gran escala de clasificación de múltiples etiquetas, se han aprendido las lecciones de Serveral, y algunas listas a continuación:
¿Qué es lo más importante para alcanzar una alta precisión? Depende de la tarea que está haciendo. De la tarea que realizamos aquí, creemos que los modelos de conjunto basados en modelos entrenados a partir de múltiples características, incluida Word, Carácter para el Título y la Descripción, pueden ayudar a alcanzar una accesorio muy alta; Sin embargo, en algunos casos, como se demostró Alphago Zero, el algoritmo es más importante que los datos o la potencia computacional, de hecho, Alphago Zero no usó ningún dato de Humam.
¿Hay un techo para algún modelo o algoritmo específico? La respuesta es sí. Aquí se usaron muchos modelos diferentes, encontramos que muchos modelos tienen actuaciones similares, a pesar de que hay una estructura bastante diferente. En cierta medida, la diferencia de rendimiento no es tan grande.
¿Es útil el estudio de caso de error? Creo que es bastante útil, especialmente cuando has hecho muchas cosas diferentes, pero alcanzaste un límite. Por ejemplo, al hacer un estudio de caso, puede encontrar etiquetas que los modelos puedan hacer una predicción correcta y dónde cometen errores. Y para el rendimiento del importancia al aumentar los pesos de estas etiquetas predichas incorrectas o encontrar posibles errores de los datos.
¿Cómo podemos convertirnos en expertos en un aprendizaje automático? En mi opinión, unirse a una competencia de aprendizaje automático o comenzar una tarea con muchos datos, luego leer documentos e implementar algunos, es un buen punto de partida. Por lo tanto, tendremos algunas experiencia e ideas realmente para manejar tareas específicas, y conocer los desafíos de la misma. Pero lo más importante es que no solo debemos seguir ideas de los documentos, sino para explorar algunas ideas nuevas que creemos que pueden ayudar a explotar el problema. Por ejemplo, al cambiar estructuras de modelos clásicos o incluso inventar algunas estructuras nuevas, podemos abordar el problema de una manera mucho mejor, ya que puede más adecuado para la tarea que estamos haciendo.
1.bag de trucos para una clasificación de texto eficiente
2. Redes neuronales conconvolutivas para la clasificación de oraciones
3. Un análisis de sensibilidad de (y la guía de profesionales para) redes neuronales convolucionales para la clasificación de oraciones
4.PRENDEDEPEP ARRENDO PARA CHATBOTS, Parte 2-Implementación de un modelo basado en la recuperación en TensorFlow, de www.wildml.com
5. Red neuronal convolucional recurrente para la clasificación de texto
6. Redes de atención humana para la clasificación de documentos
7. Traducción del automovilismo con el aprendizaje conjunta a alinear y traducir
8. La atención es todo lo que necesitas
9. Aceptarme cualquier cosa: Redes de memoria dinámica para el procesamiento del lenguaje natural
10. Contralamiento del estado del mundo con redes de entidades recurrentes
11. Selección de ensamblaje de bibliotecas de modelos
12.Bert: pretruación de transformadores bidireccionales profundos para la comprensión del lenguaje
13.google-research/bert
continuará. Para cualquier problema, concat [email protected]


