text_classification
1.0.0
วัตถุประสงค์ของที่เก็บนี้คือการสำรวจวิธีการจำแนกประเภทข้อความใน NLP ด้วยการเรียนรู้อย่างลึกซึ้ง
ปรับแต่ง NLP API ภายในสามนาทีฟรี: Demo NLP API
เกณฑ์มาตรฐานการประเมินภาษาสำหรับการทำความเข้าใจภาษาสำหรับภาษาจีน (เกณฑ์มาตรฐานเบาะแส): รัน 10 งาน & 9 baselines ที่มีรหัสหนึ่งบรรทัดการเปรียบเทียบประสิทธิภาพกับรายละเอียด
ปล่อยโมเดลที่ผ่านการฝึกอบรมมาล่วงหน้าของการฝึกอบรม Albert_chinese ด้วยคลังภาษาจีน 30G+ ดิบ, XXLARGE, XLARGE และอื่น ๆ , เป้าหมายเพื่อให้ตรงกับประสิทธิภาพของศิลปะในภาษาจีน, 2019-OCT-7 ในช่วงวันชาติของจีน!
คลังภาษาจีนจำนวนมากสำหรับ NLP ที่มีอยู่!
เบิร์ตของ Google ได้รับผลงานศิลปะใหม่ ๆ ใน NLP โดยใช้ Pre-Train ในรูปแบบภาษาแล้ว
ปรับแต่ง Pre-train texcnn: แนวคิดจาก Bert เพื่อทำความเข้าใจภาษาด้วยการเรียกใช้รหัสและชุดข้อมูล
มันมีโมเดลพื้นฐานทุกชนิดสำหรับการจำแนกประเภทข้อความ
นอกจากนี้ยังรองรับการจำแนกประเภทหลายฉลากซึ่งมีป้ายกำกับหลายรายการเชื่อมโยงกับประโยคหรือเอกสาร
แม้ว่าหลายรุ่นเหล่านี้จะง่ายและอาจไม่ได้พาคุณไปสู่ระดับสูงสุดของงาน แต่บางรุ่นเหล่านี้เป็นอย่างมาก
คลาสสิกดังนั้นพวกเขาอาจจะดีที่จะทำหน้าที่เป็นรุ่นพื้นฐาน แต่ละรุ่นมีฟังก์ชั่นการทดสอบภายใต้คลาสรุ่น คุณสามารถเรียกใช้
เป็นงานของเล่นประสิทธิภาพก่อน โมเดลเป็นอิสระจากชุดข้อมูล
ตรวจสอบรายงานอย่างเป็นทางการของการจำแนกข้อความหลายฉลากขนาดใหญ่พร้อมการเรียนรู้อย่างลึกซึ้ง
หลายรุ่นที่นี่สามารถใช้สำหรับการสร้างแบบจำลองการตอบคำถาม (มีหรือไม่มีบริบท) หรือเพื่อสร้างลำดับ
เราสำรวจโมเดล SEQ2SEQ สองรุ่น (SEQ2SEQ ด้วยความสนใจความสนใจของหม้อแปลงคือสิ่งที่คุณต้องการ) ในการจำแนกประเภทข้อความ
และทั้งสองรุ่นนี้ยังสามารถใช้สำหรับการสร้างลำดับและงานอื่น ๆ หากงานของคุณคือการจำแนกประเภทหลายฉลาก
คุณสามารถใช้ปัญหาในการสร้างลำดับ
เราใช้เครือข่ายหน่วยความจำสองเครือข่าย หนึ่งคือเครือข่ายหน่วยความจำแบบไดนามิก ก่อนหน้านี้มันมาถึงสถานะของศิลปะที่เป็นปัญหา
การตอบรับการวิเคราะห์ความเชื่อมั่นและการสร้างลำดับ มันเรียกว่ารุ่นเดียวที่จะทำงานที่แตกต่างกันหลายอย่าง
และเข้าถึงประสิทธิภาพสูง มันมีสี่โมดูล ส่วนประกอบสำคัญคือโมดูลหน่วยความจำฉาก ใช้กลไกประตูเพื่อ
ความสนใจด้านประสิทธิภาพและใช้ Gated-GRU เพื่ออัปเดตหน่วยความจำตอนจากนั้นจะมี GRU อื่น (ในทิศทางแนวตั้ง) เป็น
ประสิทธิภาพการอัปเดตสถานะซ่อนเร้น มันมีความสามารถในการอนุมานสกรรมกริยา
เครือข่ายหน่วยความจำที่สองที่เรานำไปใช้คือเครือข่ายเอนทิตีซ้ำ: การติดตามสถานะของโลก มันมีบล็อกของ
คู่คีย์-ค่าเป็นหน่วยความจำทำงานแบบขนานซึ่งบรรลุสถานะใหม่ของศิลปะ มันสามารถใช้สำหรับการสร้างแบบจำลองคำถาม
ตอบด้วยบริบท (หรือประวัติ) ตัวอย่างเช่นคุณสามารถปล่อยให้โมเดลอ่านประโยคบางอย่าง (เป็นบริบท) และถามก
คำถาม (เป็นแบบสอบถาม) จากนั้นขอให้แบบจำลองทำนายคำตอบ; หากคุณป้อนเรื่องราวเหมือนกับการสืบค้นก็สามารถทำได้
งานการจำแนกประเภท
เพื่อหารือเกี่ยวกับปัญหา ML/DL/NLP และรับการสนับสนุนด้านเทคนิคจากกันและกันคุณสามารถเข้าร่วมกลุ่ม QQ: 836811304
Fastext
ข้อความ
เบิร์ต: การฝึกอบรมหม้อแปลงสองทิศทางลึกเพื่อความเข้าใจภาษา
textrnn
RCNN
เครือข่ายความสนใจแบบลำดับชั้น
seq2seq ด้วยความสนใจ
Transformer ("เข้าร่วมคือสิ่งที่คุณต้องการ")
เครือข่ายหน่วยความจำแบบไดนามิก
EntityNetwork: การติดตามสถานะของโลก
โมเดลวงดนตรี
เพิ่ม:
สำหรับรุ่นเดียวสแต็กโมเดลที่เหมือนกันร่วมกัน แต่ละเลเยอร์เป็นแบบจำลอง ผลลัพธ์จะขึ้นอยู่กับ logits ที่เพิ่มเข้าด้วยกัน การเชื่อมต่อเพียงอย่างเดียวระหว่างเลเยอร์คือน้ำหนักของฉลาก อัตราความผิดพลาดในการทำนายของเลเยอร์ด้านหน้าของแต่ละฉลากจะกลายเป็นน้ำหนักสำหรับเลเยอร์ถัดไป ป้ายกำกับที่มีอัตราความผิดพลาดสูงจะมีน้ำหนักมาก ดังนั้นในภายหลังเลเยอร์จะให้ความสนใจกับฉลากที่คาดการณ์ผิดเหล่านั้นมากขึ้นและพยายามแก้ไขข้อผิดพลาดก่อนหน้าของเลเยอร์เดิม เป็นผลให้เราจะได้รับแบบจำลองที่แข็งแกร่งมาก ตรวจสอบ a00_boosting/boosting.py
และรุ่นอื่น ๆ :
bilstmtextrelation;
twocnntextrelation;
bilstmtextrelationtwornn
(งานทำนายฉลาก Mulit-Label ขอให้ทำนาย Top5, ข้อมูลการฝึกอบรม 3 ล้านข้อมูล, คะแนนเต็ม: 0.5)
| แบบอย่าง | Fastext | ข้อความ | textrnn | RCNN | Hierattenet | seq2seqattn | entitynet | แบบไดนามิก | หม้อแปลงไฟฟ้า |
|---|---|---|---|---|---|---|---|---|---|
| คะแนน | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| การฝึกอบรม | 10m | 2H | 10h | 2H | 2H | 3H | 3H | 5h | 7h |
Bert Model บรรลุ 0.368 หลังจาก 9 Epoch แรกจากชุดการตรวจสอบความถูกต้อง
Ensemble of Textcnn, EntityNet, DynamicMemory: 0.411
Ensemble EntityNet, DynamicMemory: 0.403
สังเกต:
m ยืนเป็น นาที ; h ยืนเป็น เวลาหลายชั่วโมง
HierAtteNet หมายถึงเครือข่ายความสนใจแบบลำดับชั้น;
Seq2seqAttn หมายถึง SEQ2SEQ ด้วยความสนใจ;
DynamicMemory หมายถึง DynamicMemoryNetwork;
Transformer Stand สำหรับแบบจำลองจาก 'ความสนใจคือสิ่งที่คุณต้องการ'
xxx_model.pyxxx_train.py เพื่อฝึกอบรมโมเดลxxx_predict.py ที่จะทำการอนุมาน (ทดสอบ)แต่ละรุ่นมีวิธีการทดสอบภายใต้คลาสรุ่น คุณสามารถเรียกใช้วิธีทดสอบก่อนเพื่อตรวจสอบว่ารุ่นสามารถทำงานได้อย่างถูกต้องหรือไม่
Python 2.7+ Tensorflow 1.8
(Tensorflow 1.1 ถึง 1.13 ควรใช้งานได้เช่นกันโมเดลส่วนใหญ่ควรทำงานได้ดีในรุ่น Tensorflow อื่น ๆ เนื่องจากเรา
ใช้คุณสมบัติน้อยมากพันธะกับเวอร์ชันบางรุ่น
หากคุณใช้ Python3 มันจะใช้ได้ตราบใดที่คุณเปลี่ยนฟังก์ชั่นการพิมพ์/ลองจับในกรณีที่คุณพบข้อผิดพลาดใด ๆ
โมเดล TextCNN ถูกเปลี่ยนไปเป็น Python 3.6 แล้ว
เพื่อช่วยให้คุณเรียกใช้ที่เก็บนี้ปัจจุบันเราสร้างการฝึกอบรม/การตรวจสอบ/ทดสอบข้อมูลใหม่อีกครั้งและคำศัพท์/ฉลากและบันทึก
พวกเขาเป็นไฟล์แคชโดยใช้ H5PY เราขอแนะนำให้คุณดาวน์โหลดจากลิงค์ด้านบน
มันมีทุกสิ่งที่คุณต้องการเรียกใช้ที่เก็บข้อมูลนี้: ข้อมูลถูกประมวลผลล่วงหน้าคุณสามารถเริ่มฝึกอบรมแบบจำลองได้ในนาที
มันเป็นไฟล์ซิปประมาณ 1.8 กรัมมีข้อมูลการฝึกอบรม 3 ล้านข้อมูล แม้ว่าหลังจากคลายซิปมันค่อนข้างใหญ่ แต่ด้วยความช่วยเหลือของ
HDF5 ต้องการเพียงขนาดหน่วยความจำปกติของคอมพิวเตอร์ (EG8 G หรือน้อยกว่า) ในระหว่างการฝึกอบรม
เราใช้สมุดบันทึก Jupyter: Pre-Processing.IPYNB เป็นข้อมูลล่วงหน้า คุณสามารถเข้าใจงานนี้ได้ดีขึ้นและ
ข้อมูลโดยการดูมัน นอกจากนี้คุณยังสามารถสร้างข้อมูลด้วยตัวเองในแบบที่คุณต้องการเพียงแค่เปลี่ยนรหัสไม่กี่บรรทัด
ใช้สมุดบันทึก Jupyter นี้
หากคุณต้องการลองใช้โมเดลตอนนี้คุณสามารถดาวน์โหลดไฟล์แคชจากด้านบนจากนั้นไปที่โฟลเดอร์ 'A02_Textcnn' เรียกใช้
python p7_TextCNN_train.py
มันจะใช้ข้อมูลจากไฟล์ที่แคชเพื่อฝึกอบรมโมเดลและการสูญเสียการพิมพ์และคะแนน F1 เป็นระยะ
แหล่งข้อมูลตัวอย่างเก่า: หากคุณต้องการข้อมูลตัวอย่างและการฝังคำต่อการฝึกอบรมต่อการฝึกอบรมบน Word2VEC คุณสามารถค้นหาได้ในปัญหาปิดเช่น: ปัญหา 3
นอกจากนี้คุณยังสามารถค้นหาข้อมูลตัวอย่างได้ที่โฟลเดอร์ "ข้อมูล" มีสองไฟล์: 'sample_single_label.txt' มีข้อมูล 50k
ด้วยฉลากเดียว 'sample_multiple_label.txt' มีข้อมูล 20k พร้อมป้ายกำกับหลายป้าย อินพุตและฉลากของ IS แยกกันด้วย " ป้ายกำกับ "
หากคุณต้องการทราบรายละเอียดเพิ่มเติมเกี่ยวกับชุดข้อมูลของการจำแนกประเภทข้อความหรืองานที่สามารถใช้โมเดลเหล่านี้ได้หนึ่งในตัวเลือกคือด้านล่าง:
https://biendata.com/competition/zhihu/
วิธีหนึ่งที่คุณสามารถใช้ที่เก็บนี้:
ขั้นตอนที่ 1: คุณสามารถอ่านบทความนี้ได้ คุณจะได้รับแนวคิดทั่วไปเกี่ยวกับรุ่นคลาสสิกต่างๆที่ใช้ในการจำแนกประเภทข้อความ
ขั้นตอนที่ 2: ข้อมูลล่วงหน้าและ/หรือดาวน์โหลดไฟล์แคช
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
ขั้นตอนที่ 3: เรียกใช้รายการบางรุ่นที่นี่และเปลี่ยนรหัสและการกำหนดค่าบางอย่างตามที่คุณต้องการเพื่อให้ได้ประสิทธิภาพที่ดี
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
นอกจากนี้เขียนบทความของคุณเกี่ยวกับหัวข้อนี้คุณสามารถติดตามสไตล์ของกระดาษเพื่อเขียน คุณอาจต้องอ่านเอกสารบางฉบับ
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
แทนที่ข้อมูลใน 'data/sample_multiple_label.txt' และตรวจสอบให้แน่ใจว่ารูปแบบด้านล่าง:
'word1 word2 word3 __label__l1 __label__l2 __label__l3'
ส่วนที่ 1: 'Word1 word2 word3' คืออินพุต (x), part2: '__label__l1 __label__l2 __label__l3'
เป็นตัวแทนของมีสามป้าย: [L1, L2, L3] ระหว่างส่วนที่ 1 ถึงตอนที่ 2 ควรมีสตริงว่าง: ''
ตัวอย่างเช่น: แต่ละบรรทัด (หลายป้ายกำกับ) เช่น:
'W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __label__5626666165763885199 __label__89047355555009151318 '
ที่ไหน '562666165763888519', '4921793805334628695', '8904735555009151318' เป็นสามป้ายที่เกี่ยวข้องกับสตริงอินพุตนี้ 'W5466 W138990 ...
สังเกต:
ฟังก์ชั่น UTIL บางอย่างอยู่ใน data_util.py; ตรวจสอบ load_data_multilabel () ของ data_util สำหรับวิธีการอินพุตและฉลากจากข้อมูลดิบ
มีฟังก์ชั่นในการโหลดและกำหนดคำที่ผ่านการปรับแต่งให้กับโมเดลซึ่งการฝังคำนั้นถูกทำให้เป็นคำศัพท์ใน Word2Vec หรือ FastText
หาก Word2Vec.load ไม่ทำงานคุณอาจโหลดคำที่ฝังไว้ล่วงหน้าโดยเฉพาะอย่างยิ่งสำหรับการฝังคำภาษาจีนการใช้บรรทัดต่อไปนี้:
นำเข้า genSim
จาก gensim.models นำเข้า keyedvectors
Word2Vec_Model = keyedVectors.load_word2vec_format (word2vec_model_path, binary = true, unicode_errors = 'ละเว้น') #
หรือคุณสามารถปิดใช้คำศัพท์การฝังคำว่าการฝังธงเพื่อปิดการใช้งานการฝังคำที่โหลด
การรวมกระเป๋าของเคล็ดลับสำหรับการจำแนกข้อความที่มีประสิทธิภาพ
หลังจากฝังแต่ละคำในประโยคแล้วการแสดงคำนี้จะถูกเฉลี่ยเป็นตัวแทนข้อความซึ่งจะถูกป้อนให้กับตัวจําแนกเชิงเส้นมันใช้ฟังก์ชัน softmax เพื่อคำนวณการกระจายความน่าจะเป็นผ่านคลาสที่กำหนดไว้ล่วงหน้า จากนั้น Cross Entropy จะใช้ในการคำนวณการสูญเสีย ถุงการแสดงคำไม่ได้พิจารณาลำดับคำ เพื่อที่จะคำนึงถึงการสั่งซื้อคำคุณลักษณะ N-GRAM ใช้เพื่อรวบรวมข้อมูลบางส่วนเกี่ยวกับลำดับคำในท้องถิ่น เมื่อจำนวนคลาสมีขนาดใหญ่การคำนวณตัวจําแนกเชิงเส้นจะมีราคาแพงในการคำนวณ ดังนั้นจึงใช้ softmax เพื่อเร่งกระบวนการฝึกอบรม
ผลลัพธ์: ประสิทธิภาพดีพอ ๆ กับกระดาษความเร็วก็เร็วมาก
ตรวจสอบ: P5_FastTextB_Model.py
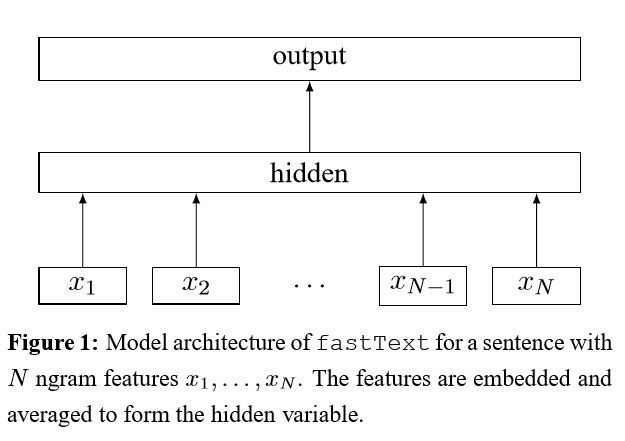
การดำเนินการตามเครือข่ายประสาทเทียมสำหรับการจำแนกประโยค
โครงสร้าง: การฝัง ---> conv ---> การรวมสูงสุด ---> เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ --------> softmax
ตรวจสอบ: p7_textcnn_model.py
เพื่อให้ได้ผลลัพธ์ที่ดีมากกับ TextCNN คุณต้องอ่านอย่างระมัดระวังเกี่ยวกับบทความนี้การวิเคราะห์ความไวของ (และคู่มือผู้ปฏิบัติงานเพื่อ) เครือข่ายประสาท Convolutional สำหรับการจำแนกประโยค: มันให้ข้อมูลเชิงลึกเกี่ยวกับสิ่งต่าง ๆ ที่อาจส่งผลกระทบต่อประสิทธิภาพการทำงาน แม้ว่าคุณจะต้องเปลี่ยนการตั้งค่าบางอย่างตามงานเฉพาะของคุณ
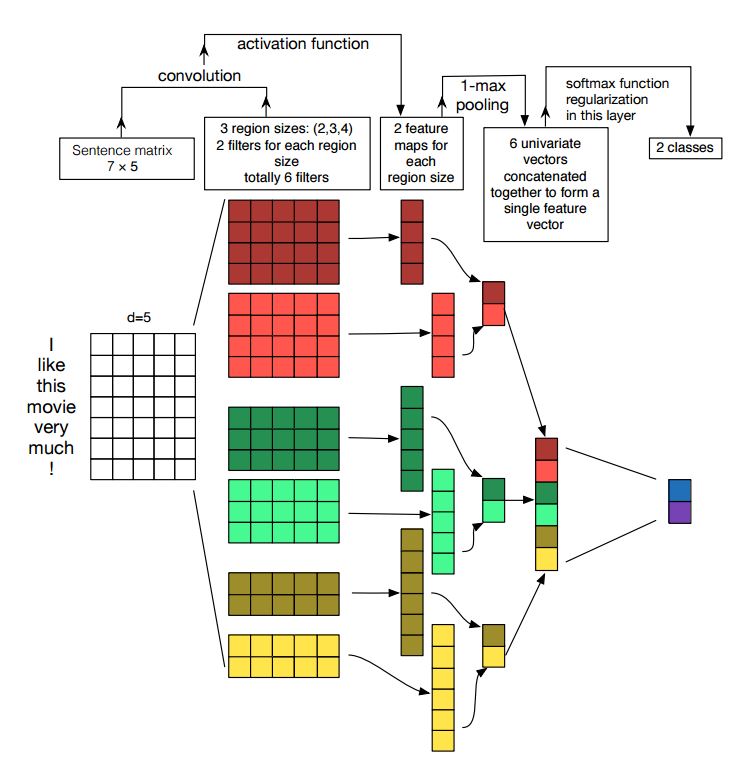
เครือข่ายประสาท Convolutional เป็นกล่องอาคารหลักสำหรับการแก้ปัญหาการมองเห็นคอมพิวเตอร์ ตอนนี้เราจะแสดงให้เห็นว่า CNN สามารถใช้กับ NLP ได้อย่างไรโดยเฉพาะการจำแนกประเภทข้อความ ความยาวประโยคจะแตกต่างจากที่หนึ่งไปอีกที่หนึ่ง ดังนั้นเราจะใช้ PAD เพื่อรับความยาวคงที่ n. สำหรับแต่ละโทเค็นในประโยคเราจะใช้การฝังคำเพื่อรับเวกเตอร์มิติคงที่ d ดังนั้นอินพุตของเราคือเมทริกซ์ 2 มิติ: (N, D) สิ่งนี้คล้ายกับรูปภาพสำหรับ CNN
ประการแรกเราจะดำเนินการ convolutional เพื่อป้อนข้อมูลของเรา มันเป็นองค์ประกอบที่หลากหลายระหว่างตัวกรองและส่วนหนึ่งของอินพุต เราใช้จำนวนตัวกรอง K ขนาดตัวกรองแต่ละตัวคือเมทริกซ์ 2 มิติ (F, D) ตอนนี้ผลลัพธ์จะเป็นจำนวนรายการ k แต่ละรายการมีความยาว N-F+1 แต่ละองค์ประกอบเป็นสเกลาร์ โปรดสังเกตว่ามิติที่สองจะเป็นมิติของการฝังคำ เรากำลังใช้ตัวกรองขนาดที่แตกต่างกันเพื่อรับคุณสมบัติที่หลากหลายจากอินพุตข้อความ และนี่คือสิ่งที่คล้ายกันกับคุณสมบัติ N-GRAM
ประการที่สองเราจะทำการรวม Max สำหรับเอาท์พุทของการดำเนินการ convolutional สำหรับจำนวนรายการ K เราจะได้รับ K จำนวนสเกลาร์
ประการที่สามเราจะต่อสเกลาร์เพื่อสร้างคุณสมบัติขั้นสุดท้าย มันเป็นเวกเตอร์ขนาดคงที่ และเป็นอิสระจากขนาดของตัวกรองที่เราใช้
ในที่สุดเราจะใช้เลเยอร์เชิงเส้นเพื่อฉายคุณสมบัติเหล่านี้ไปยังป้ายกำกับต่อที่กำหนด
ปัจจุบันเบิร์ตบรรลุผลงานศิลปะในงานมากกว่า 10 NLP แนวคิดสำคัญที่อยู่เบื้องหลังโมเดลนี้คือเราทำได้
ฝึกอบรมแบบจำลองล่วงหน้าโดยใช้แบบจำลองภาษาแบบหนึ่งที่มีข้อมูลดิบจำนวนมากซึ่งคุณสามารถค้นหาได้อย่างง่ายดาย
เนื่องจากพารามิเตอร์ส่วนใหญ่ของโมเดลได้รับการฝึกอบรมมาก่อนเลเยอร์สุดท้ายสำหรับตัวจําแนกต้องจำเป็นต้องมีงานที่แตกต่างกัน
เป็นผลให้แบบจำลองนี้เป็นแบบทั่วไปและทรงพลังมาก คุณสามารถปรับแต่งได้ตามโมเดลที่ผ่านการฝึกอบรมมาก่อน
ช่วงเวลาสั้น ๆ
อย่างไรก็ตามรุ่นนี้ค่อนข้างใหญ่ ด้วยความยาวลำดับ 128 คุณสามารถฝึกด้วยขนาดแบทช์ 32 เท่านั้น นาน
เอกสารเช่นความยาวลำดับ 512 สามารถฝึกอบรมขนาดแบทช์ 4 สำหรับ GPU ปกติ (กับ 11G); และมีคนน้อยมาก
สามารถฝึกอบรมรุ่นนี้ล่วงหน้าได้เนื่องจากต้องใช้เวลาหลายวันหรือหลายสัปดาห์ในการฝึกอบรมและหน่วยความจำของ GPU ปกตินั้นเล็กเกินไป
สำหรับรุ่นนี้
โดยเฉพาะอย่างยิ่งโมเดลกระดูกสันหลังคือหม้อแปลงซึ่งคุณสามารถค้นหาได้ในความสนใจคือสิ่งที่คุณต้องการ ใช้สองชนิด
งานเพื่อฝึกอบรมแบบจำลองล่วงหน้า
โดยทั่วไปการพูดตามประโยคบางเปอร์เซ็นต์ของคำถูกสวมหน้ากากคุณจะต้องทำนายคำที่สวมหน้ากาก
ขึ้นอยู่กับประโยคที่สวมหน้ากากนี้ คำที่สวมหน้ากากจะถูกสุ่มเลือก
เราป้อนอินพุตผ่านตัวเข้ารหัสหม้อแปลงลึกจากนั้นใช้สถานะที่ซ่อนอยู่สุดท้ายที่สอดคล้องกับหน้ากาก
ตำแหน่งที่จะทำนายว่าคำใดถูกสวมหน้ากากเหมือนที่เราจะฝึกแบบจำลองภาษา
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
งานทำความเข้าใจภาษามากมายเช่นการตอบคำถามการอนุมานต้องการความสัมพันธ์ที่เข้าใจ
ระหว่างประโยค อย่างไรก็ตามรูปแบบภาษาสามารถเข้าใจได้โดยไม่ต้องมีประโยคเท่านั้น ประโยคถัดไป
การทำนายเป็นงานตัวอย่างที่จะช่วยให้แบบจำลองเข้าใจได้ดีขึ้นในงานประเภทนี้
50% ของโอกาสประโยคที่สองคือประโยคถัดไปของประโยคแรก 50% ของไม่ใช่ประโยคถัดไป
ให้สองประโยคแบบจำลองนี้ถูกขอให้ทำนายว่าประโยคที่สองเป็นประโยคต่อไปของจริง
คนแรก
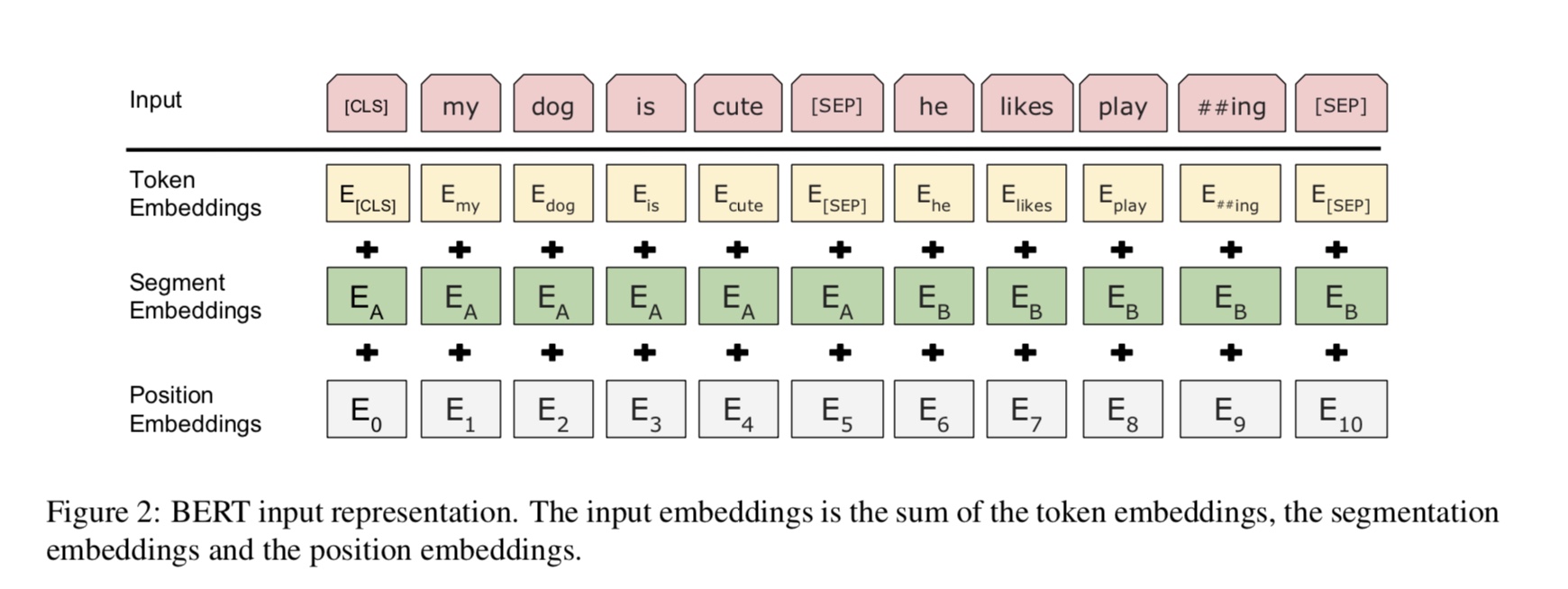
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
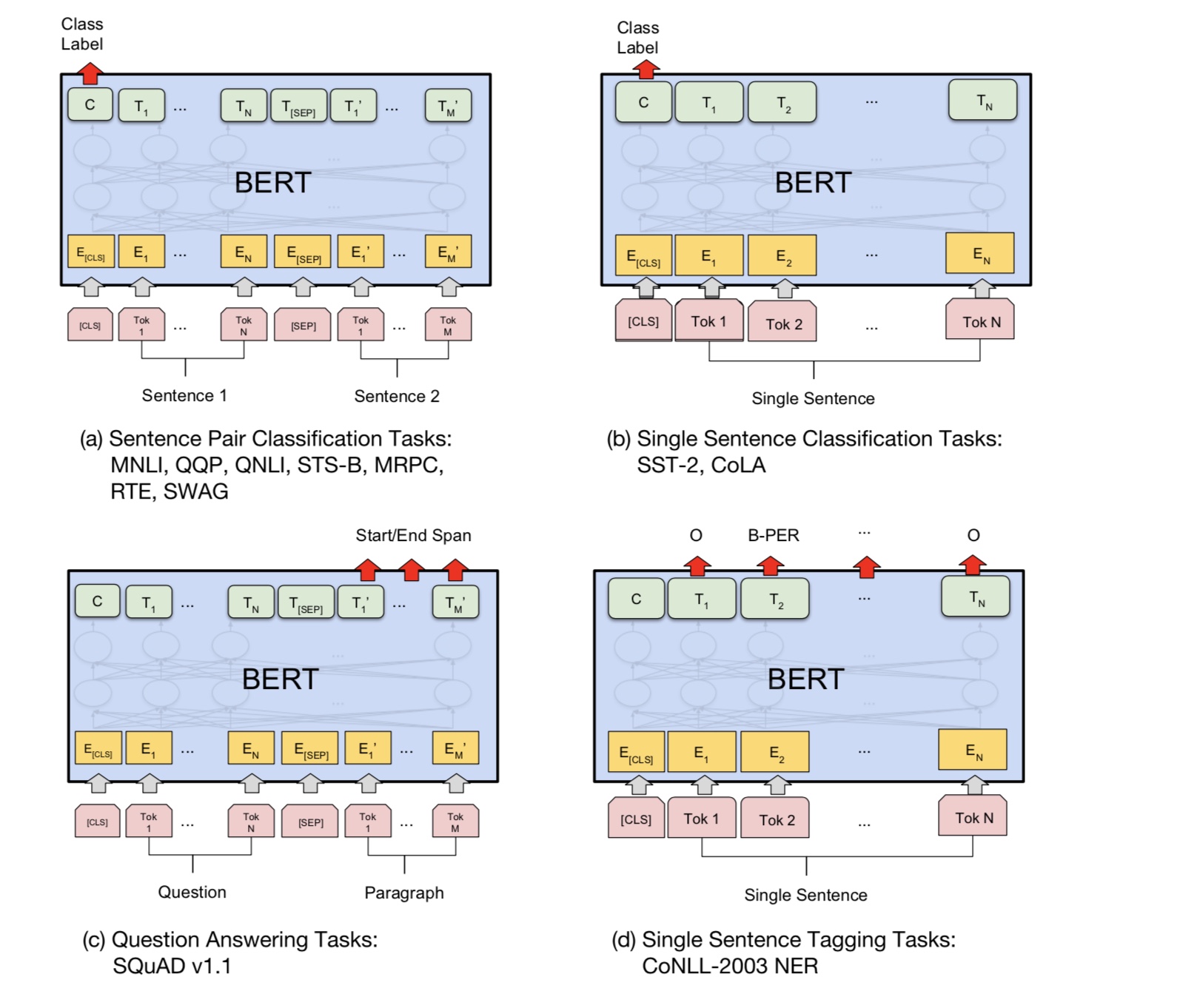
โดยพื้นฐานแล้วคุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมมาก่อนสามารถปรับแต่งงานของคุณด้วยข้อมูลของคุณเองได้
สำหรับงานการจำแนกประเภทคุณสามารถเพิ่มโปรเซสเซอร์เพื่อกำหนดรูปแบบที่คุณต้องการให้อินพุตและฉลากจากข้อมูลต้นฉบับ
เรียกใช้คำสั่งต่อไปนี้ภายใต้โฟลเดอร์ A00_BERT:
python train_bert_multi-label.py
มันบรรลุ 0.368 หลังจาก 9 ยุค หรือคุณสามารถเรียกใช้การจำแนกประเภทหลายฉลากด้วยข้อมูลที่ดาวน์โหลดได้โดยใช้ Bert From
sentiment_analysis_fine_grain กับ bert
คุณสามารถใช้เซสชันและสไตล์ฟีดเพื่อกู้คืนแบบจำลองและข้อมูลฟีดจากนั้นรับ logits เพื่อทำการคาดการณ์ออนไลน์
การทำนายออนไลน์กับเบิร์ต
เดิมทีฝึกอบรมหรือประเมินรูปแบบตามไฟล์ไม่ใช่สำหรับออนไลน์
ประการแรกคุณสามารถใช้การดาวน์โหลดรุ่นที่ผ่านการฝึกอบรมล่วงหน้าจาก Google เรียกใช้ชุดข้อมูลของคุณสองสามชุดและค้นหาสิ่งที่เหมาะสม
ความยาวลำดับ
ประการที่สองคุณสามารถฝึกอบรมแบบจำลองพื้นฐานในข้อมูลของคุณเองได้ตราบใดที่คุณสามารถหาชุดข้อมูลที่เกี่ยวข้องกับ
งานของคุณจากนั้นปรับแต่งงานเฉพาะของคุณ
ประการที่สามคุณสามารถเปลี่ยนฟังก์ชั่นการสูญเสียและเลเยอร์สุดท้ายให้เหมาะกับงานของคุณได้ดีขึ้น
นอกจากนี้คุณสามารถเพิ่มการกำหนดงานที่ผ่านการฝึกอบรมมาก่อนซึ่งจะช่วยให้โมเดลเข้าใจงานของคุณได้ดีขึ้นมาก
ตามประสบการณ์ที่เราได้รับจากการทดลองงานที่ผ่านการฝึกอบรมมาก่อนเป็นอิสระจากแบบจำลองและก่อนการฝึกอบรมไม่ จำกัด
งานด้านบน
โครงสร้าง v1: การฝัง ---> bi-directional lstm ---> concat output ---> ค่าเฉลี่ย -----> softmax layer
ตรวจสอบ: p8_textrnn_model.py
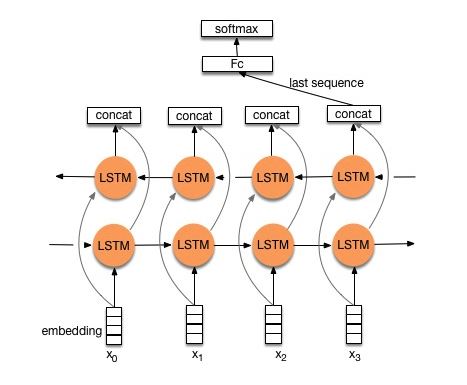
โครงสร้าง v2: การฝัง-> lstm สองทิศทาง ----> dropout-> concat ouput ---> lstm ---> droput-> เลเยอร์ fc-> เลเยอร์ Softmax
ตรวจสอบ: p8_textrnn_model_multilayer.py
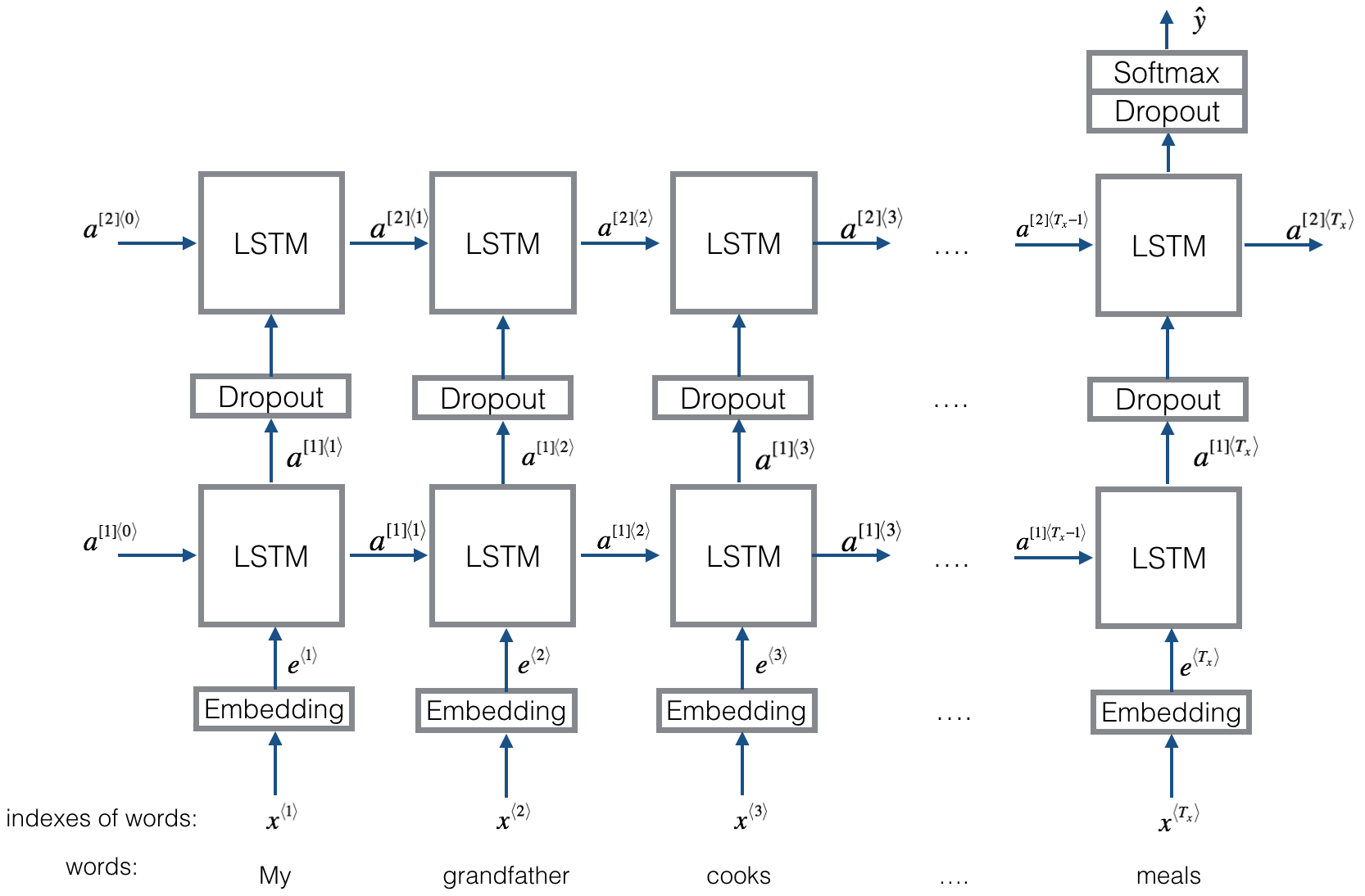
โครงสร้างเหมือนกับ textrnn แต่อินพุตได้รับการออกแบบพิเศษ eGinput: "คอมพิวเตอร์ราคาเท่าไหร่ของแล็ปท็อป" โดยที่ 'EOS' เป็นโทเค็นพิเศษที่มีคำถาม SPILTED 1 และคำถาม 2
ตรวจสอบ: p9_bilstmtextrelation_model.py
โครงสร้าง: ก่อนอื่นใช้สอง convolutional ที่แตกต่างกันเพื่อแยกคุณลักษณะของสองประโยค จากนั้นเชื่อมต่อคุณสมบัติสองอย่าง ใช้เลเยอร์การแปลงเชิงเส้นเพื่อออกการฉายไปยังป้ายกำกับเป้าหมายจากนั้น Softmax
ตรวจสอบ: p9_twocnntextrelation_model.py
โครงสร้าง: LSTM สองทิศทางสำหรับหนึ่งประโยค (รับเอาท์พุท 1), LSTM สองทิศทางอื่นสำหรับประโยคอื่น (รับเอาท์พุท 2) จากนั้น: softmax (output1 m output2)
ตรวจสอบ: p9_bilstmtextrelationtwornn_model.py
สำหรับรายละเอียดเพิ่มเติมคุณสามารถไปที่: การเรียนรู้อย่างลึกซึ้งสำหรับ chatbots ตอนที่ 2-การใช้โมเดลการดึงข้อมูลใน TensorFlow
เครือข่ายนิวรัลแบบ convolutional ที่เกิดขึ้นอีกสำหรับการจำแนกประเภทข้อความ
การดำเนินการตามเครือข่ายประสาทเทียมที่เกิดขึ้นอีกสำหรับการจำแนกประเภทข้อความ
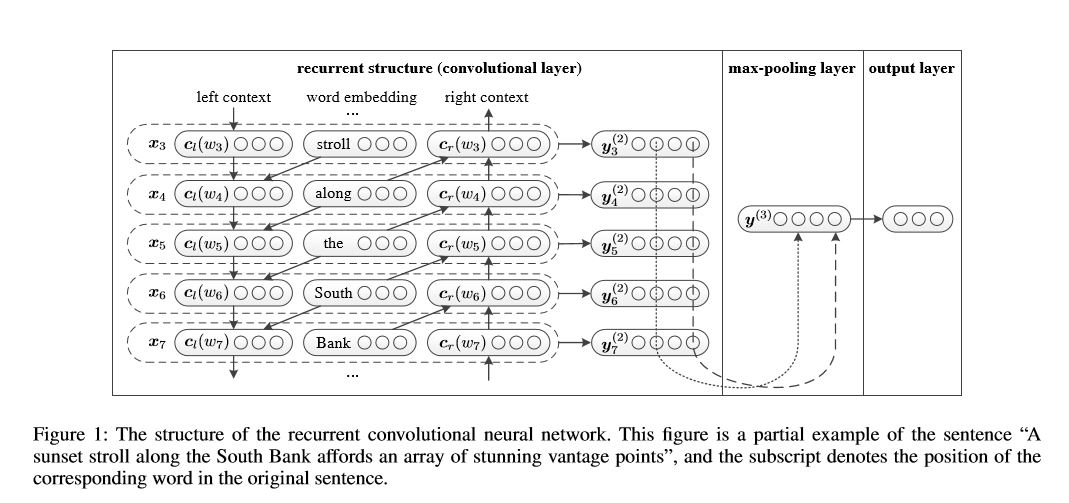
โครงสร้าง: 1) โครงสร้างกำเริบ (เลเยอร์ convolutional) 2) การรวมสูงสุด 3) เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์+softmax
มันเรียนรู้การเป็นตัวแทนของแต่ละคำในประโยคหรือเอกสารที่มีบริบทด้านซ้ายและบริบทด้านขวา:
การเป็นตัวแทน current word = [left_side_context_vector, current_word_embedding, right_side_context_vecotor]
สำหรับบริบทด้านซ้ายมันใช้โครงสร้างที่เกิดขึ้นอีกการเปลี่ยนรูปแบบไม่เชิงเส้นของคำก่อนหน้าและบริบทก่อนหน้าด้านซ้าย ในทำนองเดียวกันกับบริบทด้านขวา
ตรวจสอบ: p71_textrcnn_model.py
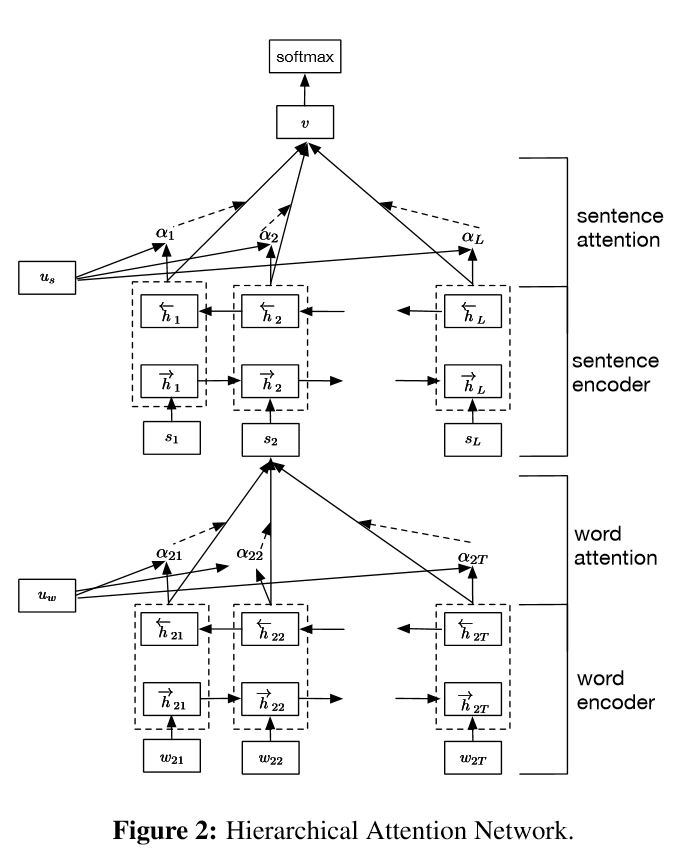
การใช้เครือข่ายความสนใจแบบลำดับชั้นสำหรับการจำแนกเอกสาร
โครงสร้าง:
การฝัง
คำเข้ารหัสคำ: ระดับคำสองทิศทาง gru เพื่อรับการเป็นตัวแทนของคำที่อุดมไปด้วย
ความสนใจของคำ: ความสนใจระดับคำเพื่อรับข้อมูลที่สำคัญในประโยค
ตัวเข้ารหัสประโยค: ระดับประโยค GRU สองทิศทางเพื่อรับการเป็นตัวแทนของประโยคที่หลากหลาย
ประโยคการเข้าชม: ระดับประโยคความสนใจเพื่อรับประโยคสำคัญระหว่างประโยค
fc+softmax
ใน NLP การจำแนกประเภทข้อความสามารถทำได้สำหรับประโยคเดียว แต่ยังสามารถใช้สำหรับหลายประโยค เราอาจเรียกมันว่าการจำแนกเอกสาร คำพูดเป็นประโยค และประโยคเป็นรูปแบบสำหรับเอกสาร ในกรณีนี้อาจมีโครงสร้างที่แท้จริง แล้วเราจะสร้างแบบจำลองงานประเภทนี้ได้อย่างไร? เอกสารทั้งหมดมีความเกี่ยวข้องเท่ากันหรือไม่? และวิธีที่เรากำหนดส่วนใดที่สำคัญกว่าส่วนใด
มีคุณสมบัติสองอย่างที่เป็นเอกลักษณ์:
1) มันมีโครงสร้างลำดับชั้นที่สะท้อนโครงสร้างลำดับชั้นของเอกสาร
2) มันมีกลไกความสนใจสองระดับที่ใช้ในคำและระดับประโยค เปิดใช้งานโมเดลในการรวบรวมข้อมูลที่สำคัญในระดับที่แตกต่างกัน
Word encoder: สำหรับแต่ละคำในประโยคมันจะถูกฝังลงในเวกเตอร์คำในพื้นที่เวกเตอร์แจกจ่าย ใช้ GRU แบบสองทิศทางเพื่อเข้ารหัสประโยค โดย concatenate เวกเตอร์จากสองทิศทางตอนนี้สามารถสร้างการเป็นตัวแทนของประโยคซึ่งยังเก็บข้อมูลบริบท
ความสนใจของคำ: คำเดียวกันมีความสำคัญมากกว่าอีกคำหนึ่งสำหรับประโยค ดังนั้นจึงใช้กลไกความสนใจ ก่อนอื่นใช้หนึ่งเลเยอร์ MLP เพื่อรับการเป็นตัวแทนของประโยคที่ซ่อนอยู่ UIT จากนั้นวัดความสำคัญของคำว่าความคล้ายคลึงกันของ UIT กับเวกเตอร์บริบทระดับคำ UW และได้รับความสำคัญปกติผ่านฟังก์ชั่น SoftMax
ตัวเข้ารหัสประโยค: สำหรับเวกเตอร์ประโยค GRU แบบสองทิศทางจะใช้เพื่อเข้ารหัส ในทำนองเดียวกันกับเครื่องเข้ารหัส Word
ความสนใจของประโยค: เวกเตอร์ระดับประโยคใช้เพื่อวัดความสำคัญระหว่างประโยค ในทำนองเดียวกันกับความสนใจของคำ
อินพุตของข้อมูล:
โดยทั่วไปการป้อนข้อมูลของโมเดลนี้ควรมีประโยคเซิร์ฟเวอร์แทนประโยค Sinle รูปร่างคือ: [ไม่มี, sentence_lenght] ในกรณีที่ไม่มีหมายถึง batch_size
ในข้อมูลการฝึกอบรมของฉันสำหรับแต่ละตัวอย่างฉันมีสี่ส่วน แต่ละส่วนมีความยาวเท่ากัน ฉันเชื่อมต่อสี่ส่วนเพื่อสร้างหนึ่งประโยคเดียว แบบจำลองจะแบ่งประโยคออกเป็นสี่ส่วนเพื่อสร้างเทนเซอร์ที่มีรูปร่าง: [ไม่มี, num_sentence, sentence_length] โดยที่ num_sentence คือจำนวนประโยค (เท่ากับ 4 ในการตั้งค่าของฉัน)
ตรวจสอบ: p1_hierarchicalattention_model.py
สำหรับความสนใจที่เอาใจใส่คุณสามารถตรวจสอบความสนใจที่เอาใจใส่
การใช้งาน SEQ2SEQ ด้วยความสนใจที่ได้มาจากการแปลของเครื่องประสาทโดยการเรียนรู้ร่วมกันเพื่อจัดตำแหน่งและแปล
I.Structure:
1) การฝัง 2) bi-gru ได้รับการเป็นตัวแทนที่อุดมไปด้วยจากประโยคต้นทาง (ไปข้างหน้าและย้อนกลับ) 3) ถอดรหัสด้วยความสนใจ
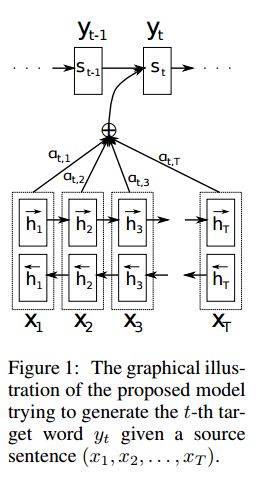
II.Input of Data:
อินพุตมีสองชนิดมีสองชนิด: 1) อินพุต ENCODER ซึ่งเป็นประโยค 2) อินพุตตัวถอดรหัสมันเป็นรายการป้ายกำกับที่มีความยาวคงที่ 3) ป้ายกำกับเป้าหมายนอกจากนี้ยังเป็นรายการของป้ายกำกับ
ตัวอย่างเช่นป้ายกำกับคือ: "L1 L2 L3 L4" จากนั้นอินพุตถอดรหัสจะเป็น: [_ GO, L1, L2, L2, L3, _Pad]; ฉลากเป้าหมายคือ: [L1, L2, L3, L3, _end, _pad] ความยาวได้รับการแก้ไขเป็น 6 ป้ายใด ๆ ที่เกินกว่าจะถูกแทงกิ่งจะติดอยู่หากฉลากไม่เพียงพอที่จะเติมเต็ม
III.Attention กลไก:
ถ่ายโอนรายการอินพุตตัวเข้ารหัสและสถานะที่ซ่อนอยู่ของตัวถอดรหัส
คำนวณความคล้ายคลึงกันของสถานะที่ซ่อนอยู่กับอินพุตตัวเข้ารหัสแต่ละตัวเพื่อรับการกระจายความเป็นไปได้สำหรับอินพุตตัวเข้ารหัสแต่ละรายการ
ผลรวมถ่วงน้ำหนักของอินพุต encoder ขึ้นอยู่กับการกระจายความเป็นไปได้
ไปแม้ว่าเซลล์ RNN โดยใช้ผลรวมน้ำหนักนี้พร้อมกับอินพุตตัวถอดรหัสเพื่อรับสถานะที่ซ่อนใหม่
IV. วิธีการถอดรหัสตัวถอดรหัสวานิลลา:
ประโยคต้นทางจะถูกเข้ารหัสโดยใช้ RNN เป็นเวกเตอร์ขนาดคงที่ ("เวกเตอร์คิด") จากนั้นในระหว่างการถอดรหัส:
เมื่อมีการฝึกอบรม RNN อื่นจะถูกใช้เพื่อพยายามรับคำโดยใช้ "เวกเตอร์ความคิด" นี้เป็นสถานะเริ่มต้นและรับข้อมูลจากอินพุตตัวถอดรหัสในแต่ละครั้ง ตัวถอดรหัสเริ่มจากโทเค็นพิเศษ "_go" หลังจากขั้นตอนเดียวดำเนินการสถานะที่ซ่อนใหม่จะได้รับและร่วมกับอินพุตใหม่เราสามารถดำเนินการต่อไปได้จนกว่าเราจะไปถึงโทเค็นพิเศษ "_end" เราสามารถคำนวณการสูญเสียโดยการคำนวณการสูญเสียเอนโทรปีข้ามของ logits และฉลากเป้าหมาย Logits ผ่านเลเยอร์ฉายภาพสำหรับสถานะที่ซ่อนอยู่ (สำหรับเอาต์พุตของขั้นตอนตัวถอดรหัส (ใน GRU เราสามารถใช้สถานะที่ซ่อนอยู่จากตัวถอดรหัสเป็นเอาต์พุต)
เมื่อเป็นการทดสอบจะไม่มีฉลาก ดังนั้นเราควรป้อนเอาต์พุตที่เราได้รับจากการประทับเวลาก่อนหน้านี้และดำเนินการต่อกระบวนการที่เราไปถึงโทเค็น "_end"
V. Notesices:
ที่นี่ฉันใช้คำศัพท์สองประเภท หนึ่งมาจากคำพูดที่ใช้โดย encoder; อีกอย่างสำหรับฉลากที่ใช้โดยตัวถอดรหัส
สำหรับคำศัพท์ของ lables ฉันแทรกโทเค็นพิเศษสามโท: "_ go", "end", "_ pad"; ไม่ได้ใช้ "_unk" เนื่องจากฉลากทั้งหมดถูกกำหนดไว้ล่วงหน้า
สถานะ: มันสามารถทำการจำแนกงานได้ และสามารถสร้างลำดับย้อนกลับของลำดับในงานของเล่น คุณสามารถตรวจสอบได้โดยใช้ฟังก์ชั่นทดสอบในรุ่น ตรวจสอบ: a2_train_classification.py (รถไฟ) หรือ a2_transformer_classification.py (รุ่น)
เราทำในรูปแบบ Parallell การทำให้เป็นมาตรฐานการเชื่อมต่อที่เหลือและหน้ากากยังใช้ในแบบจำลอง
สำหรับทุกหน่วยการสร้างเราจะรวมฟังก์ชั่นการทดสอบในแต่ละไฟล์ด้านล่างและเราทดสอบชิ้นเล็ก ๆ แต่ละชิ้นให้สำเร็จ
ลำดับที่จะลำดับด้วยความสนใจเป็นแบบจำลองทั่วไปในการแก้ปัญหาการสร้างลำดับเช่นการแปลระบบบทสนทนา เวลาส่วนใหญ่ใช้ RNN เป็น buidling block เพื่อทำงานเหล่านี้ Util เมื่อเร็ว ๆ นี้ผู้คนยังใช้เครือข่ายประสาท Convolutional สำหรับลำดับกับปัญหาลำดับ อย่างไรก็ตามหม้อแปลงมันทำงานเหล่านี้เพียงอย่างเดียวกับความสนใจ Mechansim มันรวดเร็วและบรรลุผลการศิลปะที่ทันสมัย
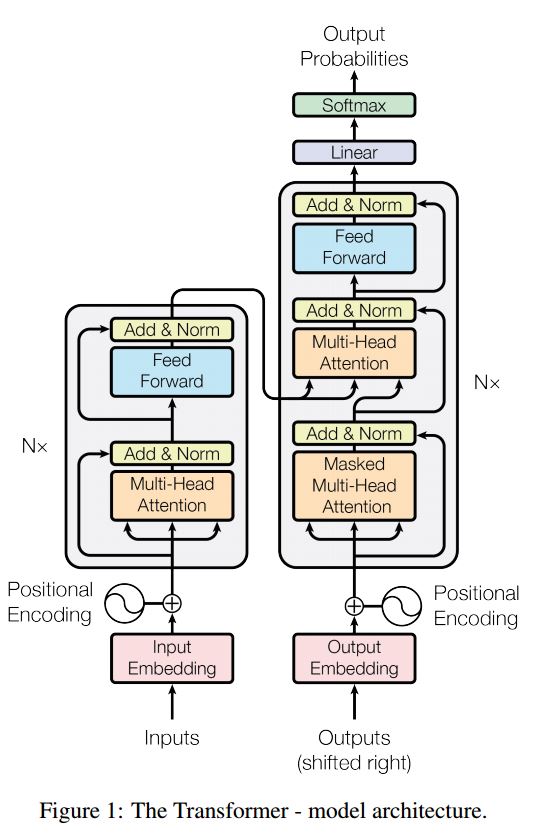
นอกจากนี้ยังมีสองส่วนหลัก: encoder และ decoder ด้านล่างนี้คือ desc จากกระดาษ:
encoder:
6 เลเยอร์เลเยอร์มีสองชั้นย่อย ประการแรกคือกลไกการดูแลตนเองหลายหัว ที่สองคือเครือข่ายฟีดไปข้างหน้าที่เชื่อมต่ออย่างสมบูรณ์ตำแหน่ง สำหรับแต่ละ sublayer ใช้ Layernorm (x+sublayer (x)) มิติทั้งหมด = 512
ตัวถอดรหัส:
หลักนำออกไปจากรุ่นนี้:
ใช้โมเดลนี้เพื่อทำการจำแนกงาน:
ที่นี่เราใช้ส่วนที่เข้ารหัสสำหรับการจำแนกประเภทงานลบการเชื่อมต่อ resdiual ลบใช้เพียง 1 layer.no จำเป็นต้องใช้หน้ากาก เราใช้ความสนใจหลายหัวและฟีด postionwise ไปข้างหน้าเพื่อแยกคุณสมบัติของประโยคอินพุตจากนั้นใช้เลเยอร์เชิงเส้นเพื่อฉายเพื่อรับ logits
สำหรับรายละเอียดของรุ่นโปรดตรวจสอบ: a2_transformer_classification.py
อินพุต: 1. เรื่องราว: มันเป็นหลายประโยคเป็นบริบท 2.Query: ประโยคซึ่งเป็นคำถาม 3. Ansewr: ป้ายกำกับเดียว
โครงสร้างแบบจำลอง:
การเข้ารหัสอินพุต: ใช้ถุงคำเพื่อเข้ารหัสเรื่องราว (บริบท) และแบบสอบถาม (คำถาม); คำนึงถึงตำแหน่งโดยใช้หน้ากากตำแหน่ง
ด้วยการใช้ RNN แบบสองทิศทางเพื่อเข้ารหัสเรื่องราวและการสืบค้นเพิ่มประสิทธิภาพจาก 0.392 เป็น 0.398 เพิ่มขึ้น 1.5%
หน่วยความจำแบบไดนามิก:
. คำนวณประตูโดยใช้ 'ความคล้ายคลึงกัน' ของคีย์ค่าที่มีอินพุตของเรื่องราว
ข. รับสถานะที่ซ่อนอยู่โดยผู้สมัครโดยแปลงแต่ละคีย์ค่าและอินพุต
ค. รวมเกตและสถานะที่ซ่อนอยู่เพื่ออัปเดตสถานะที่ซ่อนอยู่ในปัจจุบัน
ข. รับผลรวมถ่วงน้ำหนักของสถานะที่ซ่อนอยู่โดยใช้การกระจายความเป็นไปได้
ค. การแปลงแบบไม่เชิงเส้นของการสืบค้นและสถานะที่ซ่อนอยู่เพื่อรับการทำนายฉลาก
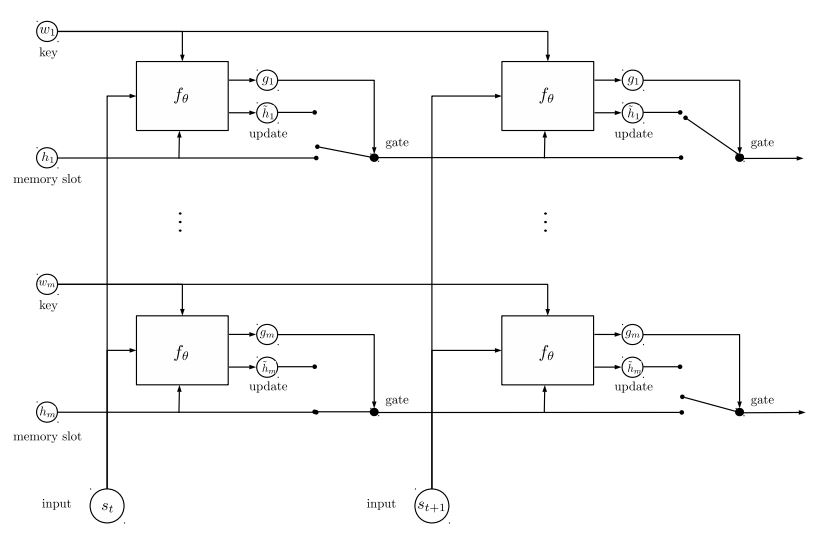
หลักนำออกไปจากรุ่นนี้:
ใช้บล็อกของคีย์และค่าซึ่งเป็นอิสระจากกัน ดังนั้นจึงสามารถทำงานได้แบบขนาน
การสร้างแบบจำลองบริบทและคำถามร่วมกัน ใช้หน่วยความจำเพื่อติดตามสถานะของโลก และใช้การแปลงที่ไม่เป็นเชิงเส้นของสถานะที่ซ่อนอยู่และคำถาม (คำถาม) เพื่อทำการทำนาย
รุ่นที่เรียบง่ายสามารถบรรลุประสิทธิภาพที่ดีมาก เข้ารหัสง่าย ๆ เป็นกระเป๋าของ Word
สำหรับรายละเอียดของรุ่นโปรดตรวจสอบ: a3_entity_network.py
ภายใต้โมเดลนี้มีฟังก์ชั่นการทดสอบซึ่งขอให้โมเดลนี้นับจำนวนทั้งสำหรับเรื่องราว (บริบท) และการสืบค้น (คำถาม) แต่น้ำหนักของเรื่องราวนั้นเล็กกว่าการสืบค้น
แนวโน้มของรุ่น:
1. โมดูลอินพุต: เข้ารหัสข้อความดิบลงในการแสดงเวกเตอร์
2. โมดูลคำถาม: เข้ารหัสคำถามลงในการแสดงเวกเตอร์
3. โมดูลหน่วยความจำที่มีความสมบูรณ์: ด้วยอินพุตมันจะเลือกส่วนใดของอินพุตที่จะโฟกัสผ่านกลไกความสนใจโดยคำนึงถึงคำถามและหน่วยความจำก่อนหน้า ====> มัน poduce 'หน่วยความจำ' vecotr
4. ตอบโมดูล: สร้างคำตอบจากเวกเตอร์หน่วยความจำสุดท้าย
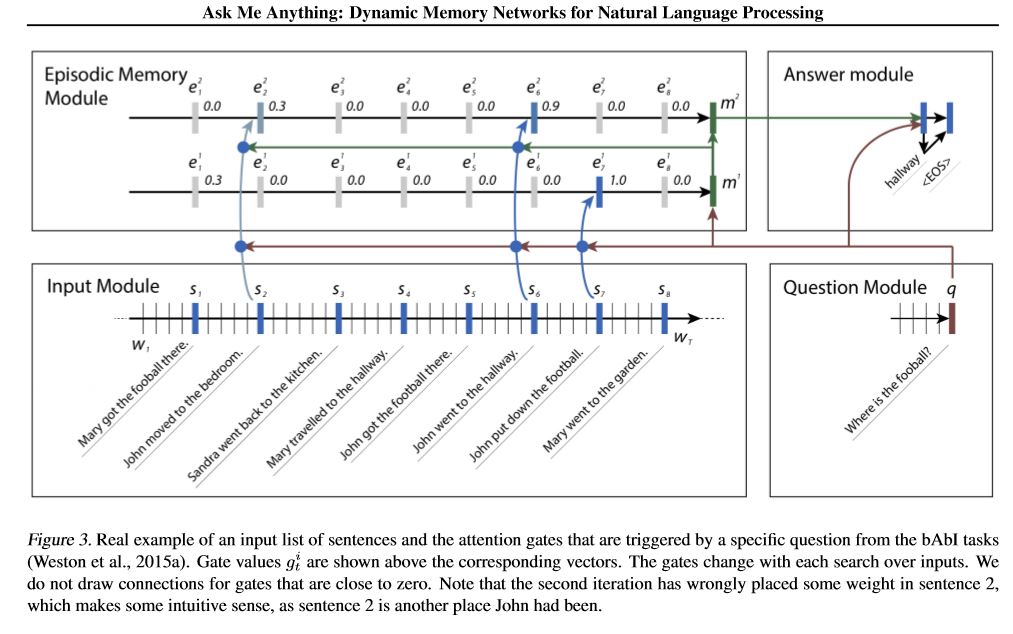
รายละเอียด:
1. โมดูล Input:
A.Single ประโยค: ใช้ GRU เพื่อรับสถานะที่ซ่อนอยู่ B.LIST ของประโยค: ใช้ GRU เพื่อรับสถานะที่ซ่อนอยู่สำหรับแต่ละประโยค เช่น [รัฐที่ซ่อนอยู่ 1, รัฐที่ซ่อนอยู่ 2, รัฐที่ซ่อนอยู่ ... , สถานะที่ซ่อนอยู่ n]
2. โมดูลคำถาม: ใช้ GRU เพื่อรับสถานะที่ซ่อนอยู่
3. โมดูลหน่วยความจำที่มีการเปลี่ยนแปลง:
ใช้กลไกความสนใจและเครือข่ายกำเริบเพื่ออัปเดตหน่วยความจำ
. ประตูเป็นกลไกความสนใจ:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
กลไกการอัพเดท B.Memory: ใช้ประโยคผู้สมัครประตูและสถานะที่ซ่อนก่อนหน้านี้ใช้ Gated-GRU เพื่ออัปเดตสถานะที่ซ่อนอยู่ ชอบ: h = f (c, h_previous, g) สถานะที่ซ่อนอยู่สุดท้ายคืออินพุตสำหรับโมดูลคำตอบ
C.Need สำหรับหลายตอน ===> การอนุมานแบบสกรรมกริยา
เช่นถามฟุตบอลอยู่ที่ไหน? มันจะเข้าร่วมประโยคของ "จอห์นวางฟุตบอล") จากนั้นในครั้งที่สองมันต้องเข้าร่วมที่ตั้งของจอห์น
4. ตอบโมดูล: ใช้หน่วยความจำ epsoidic สุดท้ายคำถามมันอัปเดตสถานะคำตอบที่ซ่อนอยู่
1. เครือข่าย convolutional ระดับตัวอักษรสำหรับการจำแนกประเภทข้อความ
2. เครือข่ายประสาทแบบ convolutional สำหรับการจัดหมวดหมู่ข้อความ: ระดับคำว่าระดับตื้นเทียบกับระดับอักขระลึก
3. เครือข่าย convolutional ลึกมากสำหรับการจำแนกข้อความ
4. วิธีการฝึกอบรม Adversarial สำหรับการจำแนกข้อความแบบกึ่งผู้ดูแล
5. รุ่นที่ใช้
ในระหว่างกระบวนการของการจำแนกประเภทหลายฉลากขนาดใหญ่บทเรียนเซิร์ฟเวอร์ได้รับการเรียนรู้และบางรายการดังต่อไปนี้:
อะไรคือสิ่งที่สำคัญที่สุดในการเข้าถึงความแม่นยำสูง? ขึ้นอยู่กับงานที่คุณทำ จากภารกิจที่เราดำเนินการที่นี่เราเชื่อว่าโมเดลวงดนตรีที่ใช้โมเดลที่ได้รับการฝึกฝนจากคุณสมบัติหลายอย่างรวมถึงคำศัพท์สำหรับชื่อเรื่องและคำอธิบายสามารถช่วยให้เข้าถึง Accuarcy ที่สูงมาก อย่างไรก็ตามในบางกรณีเช่นเดียวกับการแสดงอัลฟาโกเป็นศูนย์อัลกอริทึมมีความสำคัญมากขึ้นจากนั้นข้อมูลหรือพลังงานการคำนวณอันที่จริงอัลฟาโกเป็นศูนย์ไม่ได้ใช้ข้อมูล HUMAM ใด ๆ
มีเพดานสำหรับรุ่นหรืออัลกอริทึมเฉพาะหรือไม่? คำตอบคือใช่ มีการใช้โมเดลที่แตกต่างกันมากมายที่นี่เราพบว่าหลายรุ่นมีการแสดงที่คล้ายกันแม้ว่าจะมีโครงสร้างที่แตกต่างกันมาก ในบางระดับความแตกต่างของการแสดงไม่ใหญ่นัก
กรณีศึกษาข้อผิดพลาดมีประโยชน์หรือไม่? ฉันคิดว่ามันมีประโยชน์มากโดยเฉพาะเมื่อคุณทำสิ่งต่าง ๆ มากมาย แต่ถึงขีด จำกัด ตัวอย่างเช่นโดยการทำกรณีศึกษาคุณสามารถค้นหาฉลากที่แบบจำลองสามารถทำการคาดการณ์ที่ถูกต้องและทำผิดพลาดได้ และเพื่อแสดงประสิทธิภาพโดยการเพิ่มน้ำหนักของฉลากที่ทำนายไว้ไม่ถูกต้องเหล่านี้หรือค้นหาข้อผิดพลาดที่อาจเกิดขึ้นจากข้อมูล
เราจะเป็นผู้เชี่ยวชาญในการเรียนรู้ของเครื่องได้อย่างไร ในความคิดของฉันเข้าร่วมการแข่งขันการเรียนรู้ของเครื่องหรือเริ่มงานที่มีข้อมูลจำนวนมากจากนั้นอ่านเอกสารและนำไปใช้บางอย่างเป็นจุดเริ่มต้นที่ดี ดังนั้นเราจะมีประสบการณ์และแนวคิดในการจัดการงานเฉพาะและรู้ถึงความท้าทายของมัน แต่สิ่งที่สำคัญกว่าคือเราไม่ควรทำตามแนวคิดจากเอกสาร แต่การสำรวจความคิดใหม่ ๆ ที่เราคิดว่าอาจช่วยลดปัญหาได้ ตัวอย่างเช่นโดยการเปลี่ยนโครงสร้างของโมเดลคลาสสิกหรือแม้กระทั่งประดิษฐ์โครงสร้างใหม่บางอย่างเราอาจสามารถแก้ไขปัญหาได้ในวิธีที่ดีกว่ามากเพราะอาจเหมาะสำหรับงานที่เราทำ
1. กระเป๋าของเคล็ดลับสำหรับการจำแนกข้อความที่มีประสิทธิภาพ
2. เครือข่ายประสาทแบบ convolutional สำหรับการจำแนกประโยค
3.A การวิเคราะห์ความอ่อนไหวของ (และคู่มือผู้ปฏิบัติงาน) เครือข่ายประสาทเทียมสำหรับการจำแนกประโยค
4. การเรียนรู้แบบลึกสำหรับ chatbots ตอนที่ 2-การใช้แบบจำลองการดึงข้อมูลใน tensorflow จาก www.wildml.com
5. เครือข่ายนิวรัลแบบ convolutional สำหรับการจำแนกข้อความ
6. เครือข่ายความสนใจระดับสูงสำหรับการจำแนกเอกสาร
7. การแปลของเครื่องจักรประสาทโดยร่วมกันเรียนรู้ที่จะจัดตำแหน่งและแปล
8. ความสนใจคือทั้งหมดที่คุณต้องการ
9. อ้าปากค้างทุกอย่าง: เครือข่ายหน่วยความจำแบบไดนามิกสำหรับการประมวลผลภาษาธรรมชาติ
10. ติดตามสถานะของโลกด้วยเครือข่ายเอนทิตีที่เกิดขึ้นอีก
11. การเลือกใช้ประโยชน์จากไลบรารีของโมเดล
12. เบิร์ต: การฝึกอบรมหม้อแปลงสองทิศทางลึกเพื่อความเข้าใจภาษา
13.Google-Research/Bert
จะดำเนินการต่อ สำหรับปัญหาใด ๆ concat [email protected]


