text_classification
1.0.0
Tujuan dari repositori ini adalah untuk mengeksplorasi metode klasifikasi teks di NLP dengan pembelajaran yang mendalam.
Kustomisasi API NLP dalam tiga menit, gratis: demo API NLP
Benchmark Evaluasi Pemahaman Bahasa untuk Cina (Petunjuk Benchmark): Jalankan 10 tugas & 9 baseline dengan satu baris kode, perbandingan kinerja dengan detail.
Melepaskan model pelatihan Albert_chinese yang sudah terlatih dengan 30g+ corpus Cina mentah, xxlarge, xlarge dan banyak lagi, target untuk mencocokkan kinerja canggih dalam bahasa Cina, 2019-OCT-7, selama Hari Nasional Tiongkok!
Sejumlah besar korpus Cina untuk NLP tersedia!
Google Bert mencapai hasil seni baru pada lebih dari 10 tugas di NLP menggunakan model pra-train dalam bahasa
fine-tuning. Pra-Train Texcnn: Ide dari Bert untuk pemahaman bahasa dengan kode yang berjalan dan kumpulan data
Ini memiliki semua jenis model dasar untuk klasifikasi teks.
Ini juga mendukung klasifikasi multi-label di mana multi label terkait dengan kalimat atau dokumen.
Meskipun banyak dari model ini sederhana, dan mungkin tidak membawa Anda ke tingkat teratas dari tugas. Tetapi beberapa model ini sangat
Klasik, jadi mereka mungkin baik untuk berfungsi sebagai model dasar. Setiap model memiliki fungsi uji di bawah kelas model. Anda bisa berlari
itu untuk tugas mainan kinerja terlebih dahulu. Model ini independen dari kumpulan data.
Periksa di sini untuk laporan formal klasifikasi teks multi-label skala besar dengan pembelajaran yang mendalam
Beberapa model di sini juga dapat digunakan untuk pemodelan menjawab pertanyaan (dengan atau tanpa konteks), atau untuk menghasilkan urutan.
Kami mengeksplorasi dua model SEQ2SEQ (SEQ2SEQ dengan perhatian, semua orang yang Anda butuhkan) untuk melakukan klasifikasi teks.
Dan kedua model ini juga dapat digunakan untuk menghasilkan urutan dan tugas lainnya. Jika tugas Anda adalah klasifikasi multi-label,
Anda dapat memberikan masalah untuk menghasilkan urutan.
Kami menerapkan dua jaringan memori. Salah satunya adalah jaringan memori dinamis. sebelumnya mencapai canggih yang dimaksud
Menjawab, analisis sentimen, dan tugas yang menghasilkan urutan. Disebut satu model untuk melakukan beberapa tugas yang berbeda,
dan mencapai kinerja tinggi. Ini memiliki empat modul. Komponen utama adalah modul memori episodik. itu menggunakan mekanisme gerbang untuk
Perhatian Performa, dan gunakan Gated-Gru untuk memperbarui memori episode, maka ia memiliki Gru lain (dalam arah vertikal)
Pembaruan Negara Tersembunyi Kinerja. Ini memiliki kemampuan untuk melakukan inferensi transitif.
Jaringan memori kedua yang kami terapkan adalah jaringan entitas berulang: melacak keadaan dunia. itu memiliki blok
Pasangan bernilai kunci sebagai memori, dijalankan secara paralel, yang mencapai kondisi seni baru. Ini dapat digunakan untuk pertanyaan pemodelan
menjawab dengan konteks (atau sejarah). Misalnya, Anda dapat membiarkan model membaca beberapa kalimat (sebagai konteks), dan meminta a
pertanyaan (sebagai kueri), lalu minta model untuk memprediksi jawaban; Jika Anda memberi makan cerita yang sama dengan kueri, maka itu bisa dilakukan
tugas klasifikasi.
Untuk membahas masalah ML/DL/NLP dan mendapatkan dukungan teknis dari satu sama lain, Anda dapat bergabung dengan QQ Group: 836811304
FastText
Textcnn
Bert: Pra-pelatihan transformator dua arah yang dalam untuk pemahaman bahasa
Textrnn
Rcnn
Jaringan perhatian hierarkis
seq2seq dengan perhatian
Transformer ("hadirlah yang Anda butuhkan")
Jaringan memori dinamis
EntityNetwork: melacak keadaan dunia
Model ensemble
Meningkatkan:
Untuk model tunggal, menumpuk model yang identik bersama -sama. Setiap lapisan adalah model. Hasilnya akan didasarkan pada logit yang ditambahkan bersama. Satu -satunya koneksi antar lapisan adalah bobot label. Tingkat kesalahan prediksi lapisan depan dari setiap label akan menjadi berat untuk lapisan berikutnya. Label -label dengan tingkat kesalahan tinggi akan memiliki bobot yang besar. Jadi Layer yang lebih baru akan lebih memperhatikan label-label yang disalahgunakan itu, dan mencoba memperbaiki kesalahan sebelumnya dari Layer. Akibatnya, kami akan mendapatkan model yang jauh lebih kuat. Periksa a00_boosting/boosting.py
dan model lainnya:
Bilstmtextrelation;
twocnntextrelation;
BilstmtextrelationTwornn
(Tugas prediksi label mulit-label, minta prediksi top5, 3 juta data pelatihan, skor penuh: 0,5)
| Model | FastText | Textcnn | Textrnn | Rcnn | Hierattenet | Seq2seqattn | EntityNet | DynamicMemory | Transformator |
|---|---|---|---|---|---|---|---|---|---|
| Skor | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| Pelatihan | 10m | 2h | 10h | 2h | 2h | 3H | 3H | 5H | 7h |
Model Bert mencapai 0,368 setelah 9 zaman pertama dari set validasi.
Ensemble of Textcnn, EntityNet, DynamicMemory: 0.411
Ensemble EntityNet, DynamicMemory: 0,403
Melihat:
m berdiri selama beberapa menit ; h berdiri berjam -jam ;
HierAtteNet berarti Hierarchical Attention Networkk;
Seq2seqAttn berarti seq2seq dengan perhatian;
DynamicMemory berarti DynamicMeMoryNetwork;
Transformer Stand untuk model dari 'perhatian adalah semua yang Anda butuhkan'.
xxx_model.pyxxx_train.py untuk melatih modelxxx_predict.py untuk melakukan inferensi (tes).Setiap model memiliki metode pengujian di bawah kelas model. Anda dapat menjalankan metode pengujian terlebih dahulu untuk memeriksa apakah model dapat bekerja dengan baik.
Python 2.7+ TensorFlow 1.8
(TensorFlow 1.1 hingga 1.13 juga harus berfungsi; sebagian besar model juga harus berfungsi dengan baik dalam versi TensorFlow lainnya, karena kami
Gunakan sangat sedikit fitur ikatan ke versi tertentu.
Jika Anda menggunakan python3, itu akan baik -baik saja selama Anda mengubah fungsi cetak/coba tangkap jika Anda memenuhi kesalahan apa pun.
Model Textcnn sudah ditransfer ke Python 3.6
Untuk membantu Anda menjalankan repositori ini, saat ini kami menghasilkan kembali pelatihan/validasi/data uji dan kosa kata/label, dan disimpan
mereka sebagai file cache menggunakan h5py. Kami menyarankan Anda untuk mengunduhnya dari tautan di atas.
Ini berisi semua yang Anda butuhkan untuk menjalankan repositori ini: Data sudah diproses sebelumnya, Anda dapat mulai melatih model dalam satu menit.
Ini adalah file zip sekitar 1,8g, berisi 3 juta data pelatihan. Meskipun setelah unzip itu cukup besar, tetapi dengan bantuan
HDF5, hanya perlu ukuran normal memori komputer (EG8 g atau kurang) selama pelatihan.
Kami menggunakan Jupyter Notebook: Pre-Processing.ipynb untuk data pra-proses. Anda dapat memiliki pemahaman yang lebih baik tentang tugas ini dan
data dengan melihatnya. Anda juga dapat menghasilkan data sendiri dengan cara keinginan Anda, cukup ubah beberapa baris kode
Menggunakan buku catatan Jupyter ini.
Jika Anda ingin mencoba model sekarang, Anda dapat mengidap file cache dari atas, maka buka folder 'A02_TextCnn', jalankan
python p7_TextCNN_train.py
Ini akan menggunakan data dari file yang di -cache untuk melatih model, dan kehilangan cetak dan skor F1 secara berkala.
Sumber Data Sampel Lama: Jika Anda memerlukan beberapa data sampel dan embedding kata per terlatih di Word2VEC, Anda dapat menemukannya dalam masalah tertutup, seperti: Edisi 3.
Anda juga dapat menemukan beberapa data sampel di "data" folder. Ini berisi dua file: 'sample_single_label.txt', berisi 50k data
dengan label tunggal; 'sample_multiple_label.txt', berisi data 20k dengan banyak label. Input dan Label terpisah oleh " Label ".
Jika Anda ingin mengetahui lebih detail tentang kumpulan data klasifikasi teks atau tugas model ini dapat digunakan, salah satu pilihan di bawah ini:
https://biendata.com/competition/zhihu/
Salah satu cara Anda dapat menggunakan repositori ini:
Langkah 1: Anda dapat membaca artikel ini. Anda akan mendapatkan ide umum tentang berbagai model klasik yang digunakan untuk melakukan klasifikasi teks.
Langkah 2: Data pra-proses dan/atau unduh file cache.
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
Langkah 3: Jalankan beberapa model daftar di sini, dan ubah beberapa kode dan konfigurasi seperti yang Anda inginkan, untuk mendapatkan kinerja yang baik.
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
Selain itu, tulis artikel Anda tentang topik ini, Anda dapat mengikuti gaya kertas untuk ditulis. Anda mungkin perlu membaca beberapa makalah
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
Ganti data di 'data/sample_multiple_label.txt', dan pastikan format seperti di bawah ini:
'Word1 Word2 Word3 __label__l1 __label__l2 __label__l3'
di mana part1: 'word1 word2 word3' adalah input (x), part2: '__label__l1 __label__l2 __label__l3'
Mewakili ada tiga label: [L1, L2, L3]. Antara part1 dan part2 harus ada string kosong: ''.
Misalnya: setiap baris (beberapa label) seperti:
'W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __Label__562661638388851111119 __label__5626663838888511119 __label__4992938388885119 __label__8904735555009151318 '
Di mana '562661657638885119', '4921793805334628695' , '8904735555009151318' adalah tiga label yang terkait dengan string input 'W5466 W138990 ...
Melihat:
Beberapa fungsi util ada di data_util.py; Periksa load_data_multilabel () dari data_util untuk bagaimana input proses dan label dari data mentah.
Ada fungsi untuk memuat dan menetapkan embedding kata pretrained ke model, di mana embedding kata pretrained di word2vec atau fasttext.
Jika word2vec.load tidak berfungsi, Anda dapat memuat embedding kata pretrained, terutama untuk embedding kata Cina menggunakan baris berikut:
Impor gensim
dari gensim.models impor Keyedvectors
word2vec_model = keyedvectors.load_word2vec_format (word2vec_model_path, biner = true, unicode_errors = 'abaikan') #
atau Anda dapat mematikan bendera embedding kata pretrain ke false untuk menonaktifkan penyematan kata pemuatan.
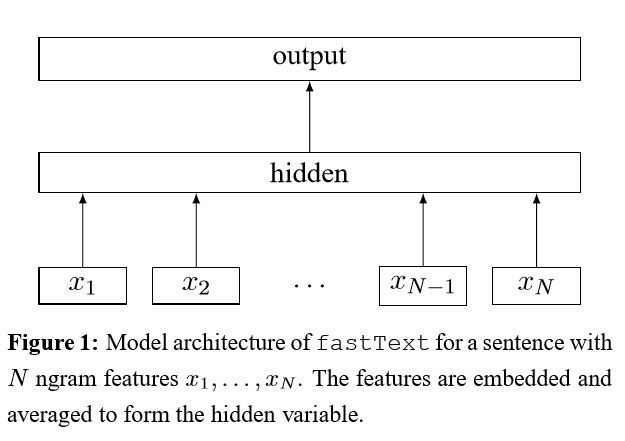
implementasi tas trik untuk klasifikasi teks yang efisien
Setelah embed setiap kata dalam kalimat, representasi kata ini kemudian dirata -rata menjadi representasi teks, yang pada gilirannya diumpankan ke classifier linier. Ini menggunakan fungsi softmax untuk menghitung distribusi probabilitas selama kelas yang telah ditentukan. Kemudian entropi silang digunakan untuk menghitung kehilangan. Kantong representasi kata tidak mempertimbangkan urutan kata. Untuk memperhitungkan urutan kata, fitur n-gram digunakan untuk menangkap beberapa informasi parsial tentang urutan kata lokal; Ketika jumlah kelas besar, menghitung classifier linier mahal. Jadi menggunakan softmax untuk mempercepat proses pelatihan.
Hasil: Kinerja sebagus kertas, kecepatan juga sangat cepat.
Periksa: p5_fasttextb_model.py
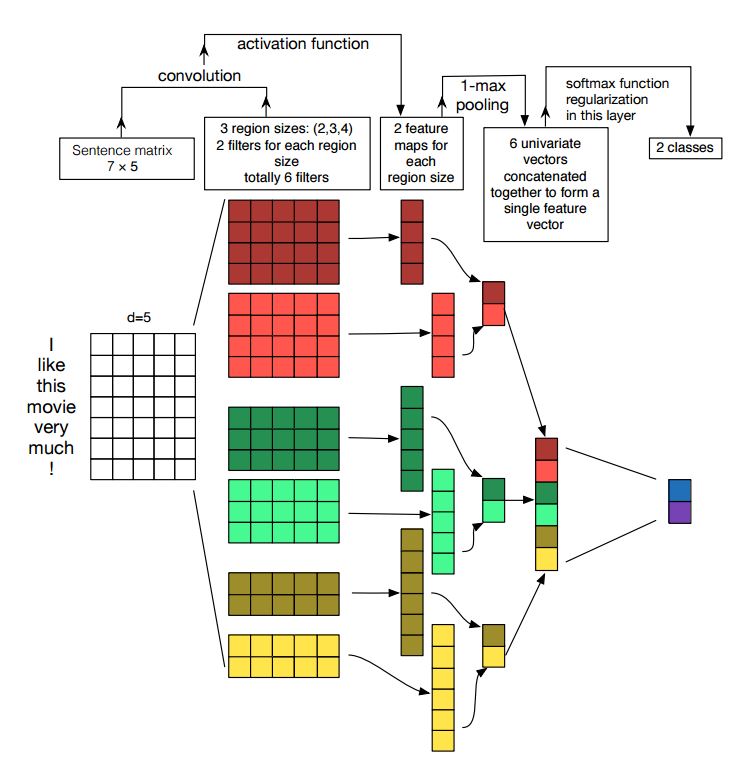
Implementasi Jaringan Saraf Konvolusional untuk Klasifikasi Kalimat
Struktur: Embedding ---> Conv ---> Max Pooling ---> Lapisan Terhubung Sepenuhnya --------> Softmax
Periksa: p7_textcnn_model.py
Untuk mendapatkan hasil yang sangat baik dengan TextCNN, Anda juga perlu membaca dengan cermat tentang makalah ini, analisis sensitivitas (dan panduan praktisi untuk) jaringan saraf konvolusional untuk klasifikasi kalimat: itu memberi Anda beberapa wawasan tentang hal -hal yang dapat memengaruhi kinerja. Meskipun Anda perlu mengubah beberapa pengaturan sesuai dengan tugas spesifik Anda.
Jaringan saraf konvolusional adalah kotak bangunan utama untuk menyelesaikan masalah visi komputer. Sekarang kita akan menunjukkan bagaimana CNN dapat digunakan untuk NLP, pada khususnya, klasifikasi teks. Panjang kalimat akan berbeda dari satu ke yang lain. Jadi kami akan menggunakan PAD untuk mendapatkan panjang tetap, n. Untuk setiap token dalam kalimat, kami akan menggunakan embedding kata untuk mendapatkan vektor dimensi tetap, d. Jadi input kami adalah matriks 2-dimensi: (n, d). Ini mirip dengan gambar untuk CNN.
Pertama, kami akan melakukan operasi konvolusional ke input kami. Ini adalah ganda elemen antara filter dan bagian dari input. Kami menggunakan jumlah filter k, setiap ukuran filter adalah matriks 2-dimensi (F, D). Sekarang outputnya akan menjadi jumlah daftar. Setiap daftar memiliki panjang N-F+1. Setiap elemen adalah skalar. Perhatikan bahwa dimensi kedua akan selalu menjadi dimensi penyematan kata. Kami menggunakan berbagai ukuran filter untuk mendapatkan fitur kaya dari input teks. Dan ini adalah sesuatu yang mirip dengan fitur N-gram.
Kedua, kami akan melakukan pengumpulan maksimal untuk output operasi konvolusional. Untuk jumlah daftar K, kami akan mendapatkan k jumlah skalar.
Ketiga, kami akan menggabungkan skatenasi untuk membentuk fitur akhir. Ini adalah vektor ukuran tetap. Dan itu independen dari ukuran filter yang kami gunakan.
Akhirnya, kami akan menggunakan Linear Layer untuk memproyeksikan fitur-fitur ini ke label yang ditentukan.
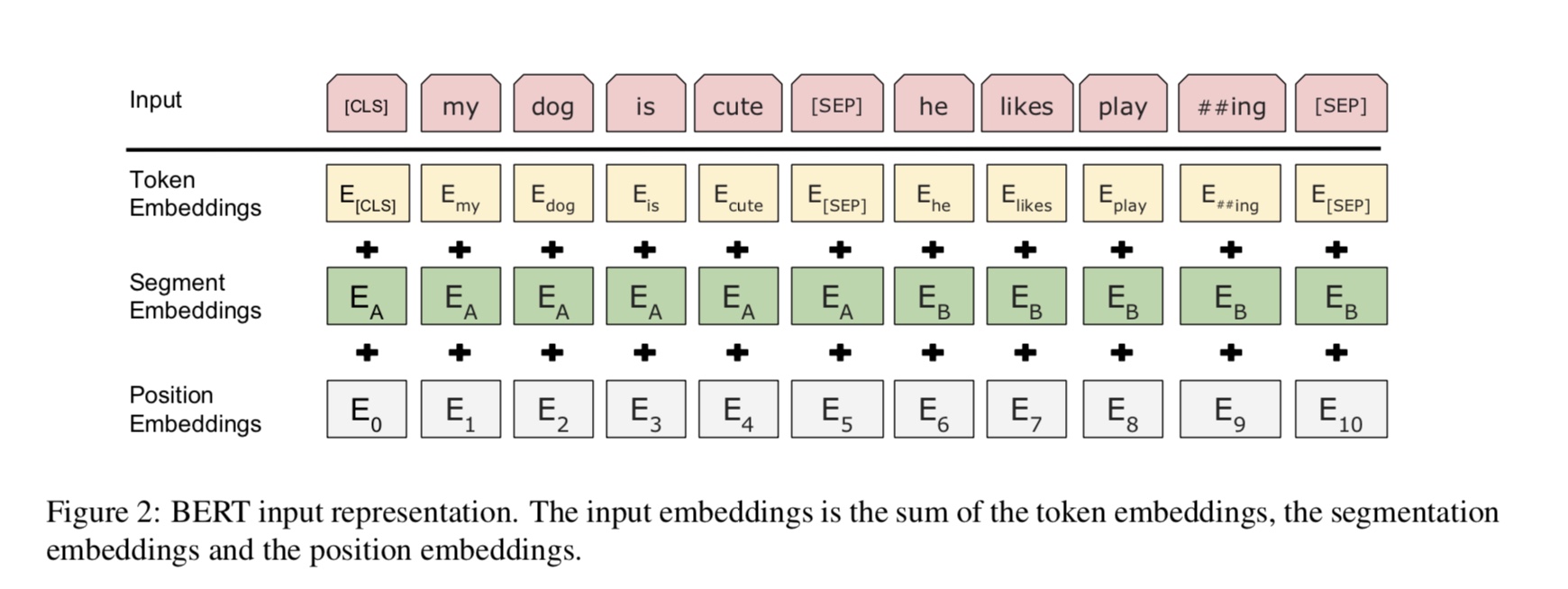
Bert saat ini mencapai hasil canggih pada lebih dari 10 tugas NLP. Ide -ide utama di balik model ini adalah bahwa kita bisa
Pra-pelatihan model dengan menggunakan satu jenis model bahasa dengan data mentah dalam jumlah besar, di mana Anda dapat menemukannya dengan mudah.
Karena sebagian besar parameter model sudah terlatih, hanya lapisan terakhir untuk classifier yang perlu dibutuhkan untuk tugas yang berbeda.
Akibatnya, model ini generik dan sangat kuat. Anda bisa menyempurnakan berdasarkan model pra-terlatih di dalam
waktu yang singkat.
Namun, model ini cukup besar. Dengan panjang urutan 128, Anda mungkin hanya dapat berlatih dengan ukuran batch 32; lama
Dokumen seperti Panjang Urutan 512, hanya dapat melatih ukuran batch 4 untuk GPU normal (dengan 11g); Dan sangat sedikit orang
Dapatkah pra-melatih model ini dari awal, karena dibutuhkan berhari-hari atau berminggu-minggu untuk berlatih, dan memori GPU normal terlalu kecil
untuk model ini.
Khususnya, model backbone adalah transformator, di mana Anda dapat menemukannya dalam perhatian adalah semua yang Anda butuhkan. itu menggunakan dua jenis
Tugas untuk pra-pelatihan model.
Secara umum, diberi kalimat, beberapa persentase kata bertopeng, Anda perlu memprediksi kata -kata bertopeng
berdasarkan kalimat bertopeng ini. Kata -kata bertopeng dipilih secara acak.
Kami memberi makan input melalui encoder transformator yang dalam dan kemudian menggunakan keadaan tersembunyi akhir yang sesuai dengan bertopeng
Posisi untuk memprediksi kata apa yang bertopeng, persis seperti kami akan melatih model bahasa.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Banyak tugas pemahaman bahasa, seperti menjawab pertanyaan, inferensi, perlu memahami hubungan
antara kalimat. Namun, model bahasa hanya dapat memahami tanpa kalimat. kalimat berikutnya
Prediksi adalah tugas sampel untuk membantu model memahami lebih baik dalam tugas semacam ini.
50% kebetulan Kalimat kedua adalah hukuman berikutnya dari yang pertama, 50% dari bukan yang berikutnya.
Mengingat dua kalimat, model ini diminta untuk memprediksi apakah kalimat kedua adalah kalimat berikutnya
yang pertama.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
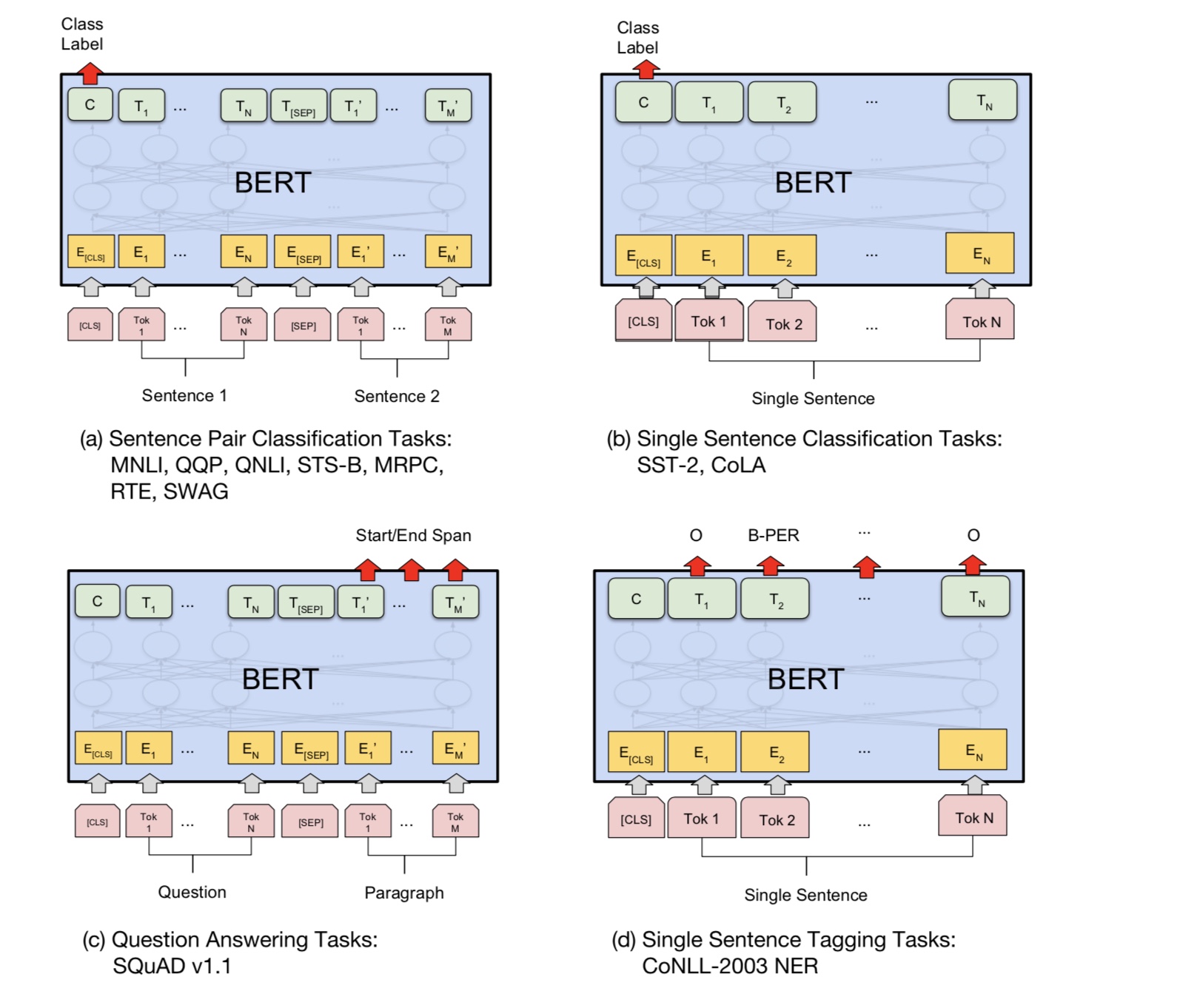
Pada dasarnya, Anda dapat mengunduh model pra-terlatih, dapat menyempurnakan tugas Anda dengan data Anda sendiri.
Untuk tugas klasifikasi, Anda dapat menambahkan prosesor untuk menentukan format yang ingin Anda biarkan input dan label dari data sumber.
Jalankan perintah berikut di bawah folder A00_Bert:
python train_bert_multi-label.py
Itu mencapai 0,368 setelah 9 zaman. atau Anda dapat menjalankan klasifikasi multi-label dengan data yang dapat diunduh menggunakan Bert dari
sentimen_analysis_fine_grain dengan Bert
Anda dapat menggunakan Sesi dan Gaya Umpan untuk mengembalikan model dan data umpan, kemudian mendapatkan login untuk membuat prediksi online.
Prediksi online dengan Bert
Awalnya, itu melatih atau mengevaluasi model berdasarkan file, bukan untuk online.
Pertama, Anda dapat menggunakan unduhan model terlatih dari Google. Jalankan beberapa zaman pada dataset Anda, dan temukan yang cocok
Panjang urutan.
Kedua, Anda dapat melakukan pra-melatih model dasar dalam data Anda sendiri selama Anda dapat menemukan dataset yang terkait dengan
Tugas Anda, lalu menyempurnakan tugas spesifik Anda.
Ketiga, Anda dapat mengubah fungsi kerugian dan lapisan terakhir yang lebih sesuai untuk tugas Anda.
Selain itu, Anda dapat menambahkan menentukan beberapa tugas pra-terlatih yang akan membantu model memahami tugas Anda jauh lebih baik.
Seperti yang kami dapatkan dari eksperimen, tugas pra-terlatih independen dari model dan pra-kereta tidak terbatas
tugas di atas.
Struktur V1: Embedding ---> Bi-directional LSTM ---> output concat ---> rata-rata -----> Lapisan Softmax
Periksa: p8_textrnn_model.py
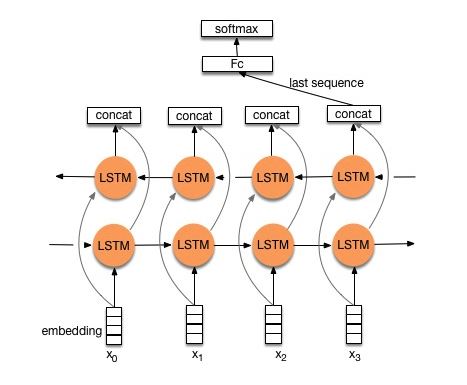
Struktur V2: Embedding-> Bi-directional lstm ----> dropout-> concat ouput ---> lstm ---> droput-> fc layer-> softmax layer
Periksa: p8_textrnn_model_multilayer.py
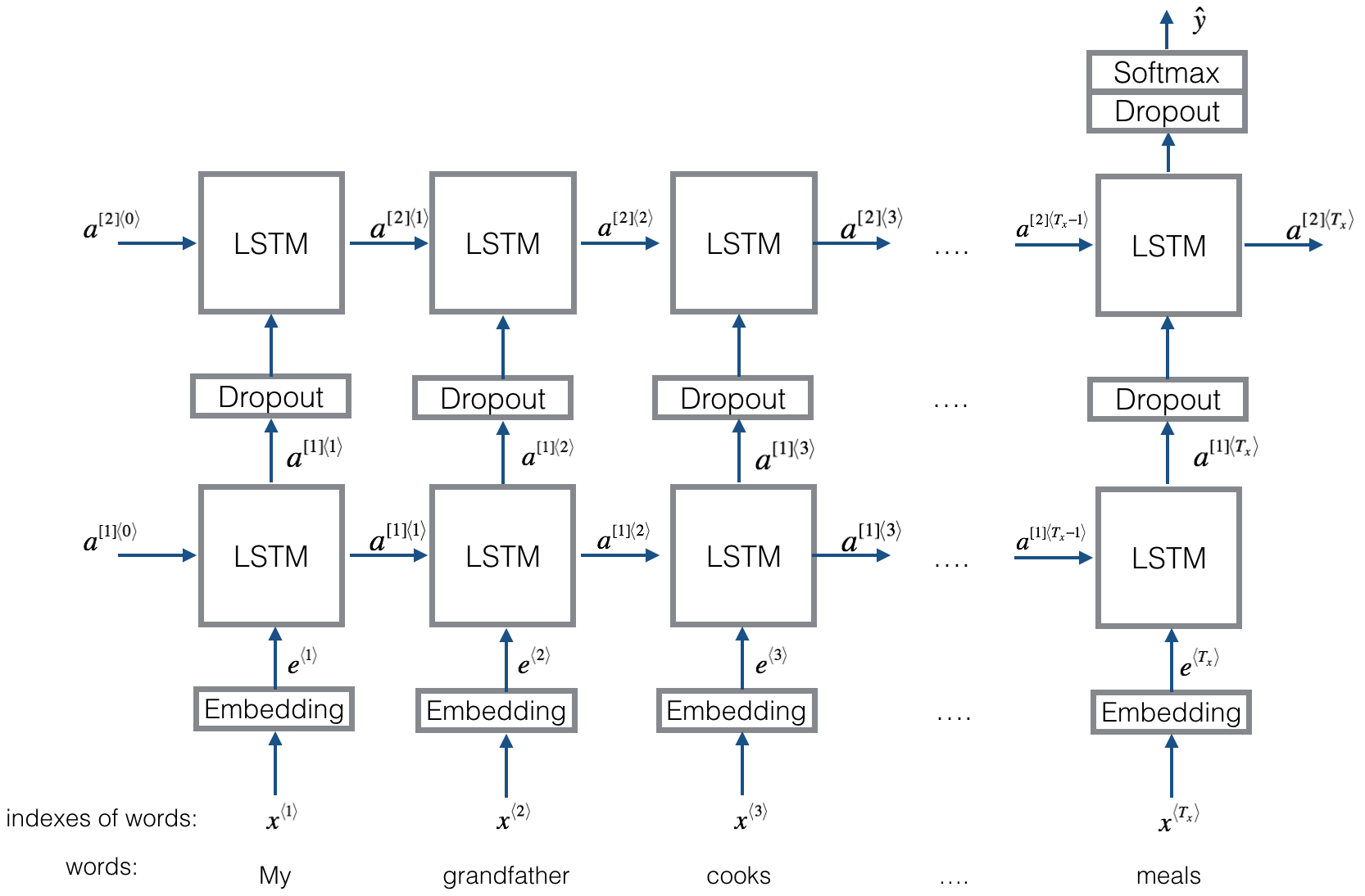
Struktur sama dengan Textrnn. tetapi input dirancang khusus. Eginput: "Berapa harga komputer? EOS laptop". Di mana 'EOS' adalah token khusus pertanyaan spilted1 dan pertanyaan2.
Periksa: p9_bilstmtextrelation_model.py
Struktur: Pertama gunakan dua konvolusional yang berbeda untuk mengekstrak fitur dua kalimat. Kemudian concat dua fitur. Gunakan lapisan transformasi linier untuk keluar proyeksi label target, lalu softmax.
Periksa: p9_twocnntextrelation_model.py
Struktur: Satu LSTM dua arah untuk satu kalimat (dapatkan output1), LSTM bi-directional lain untuk kalimat lain (dapatkan output2). Kemudian: softmax (output1 m output2)
Periksa: p9_bilstmtextrelationtwornn_model.py
Untuk detail lebih lanjut yang dapat Anda kunjungi: Pembelajaran mendalam untuk chatbots, bagian 2-menerapkan model berbasis pengambilan di TensorFlow
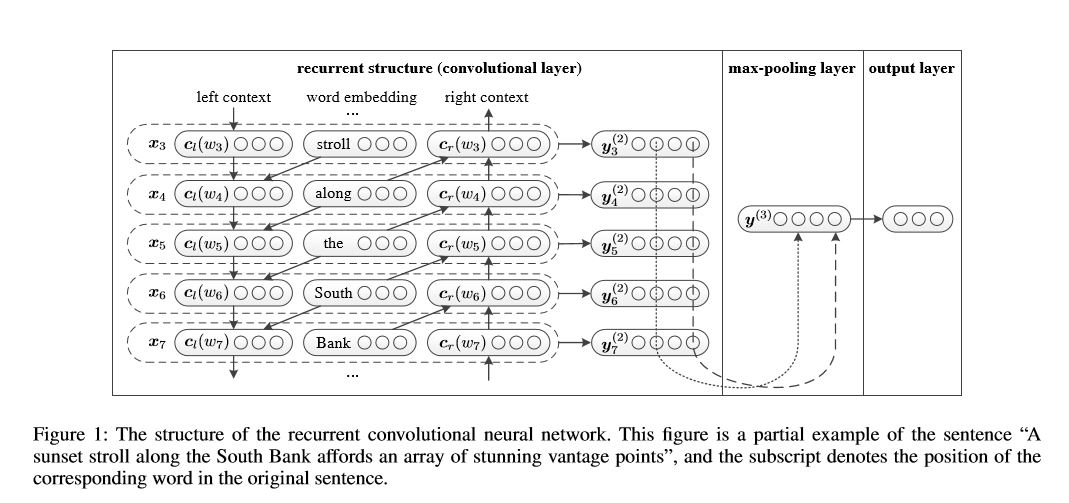
Jaringan saraf konvolusional berulang untuk klasifikasi teks
Implementasi jaringan saraf konvolusional berulang untuk klasifikasi teks
Struktur: 1) Struktur Berulang (Lapisan Konvolusional) 2) Max Pooling 3) Lapisan Terhubung Sepenuhnya+Softmax
itu belajar represenasi setiap kata dalam kalimat atau dokumen dengan konteks sisi kiri dan konteks sisi kanan:
Representasi kata saat ini = [left_side_context_vector, current_word_embedding, right_side_context_vecotor].
Untuk konteks sisi kiri, ia menggunakan struktur berulang, transfrom no-linearity dari kata sebelumnya dan sisi kiri konteks sebelumnya; Demikian pula dengan konteks sisi kanan.
Periksa: p71_textrcnn_model.py
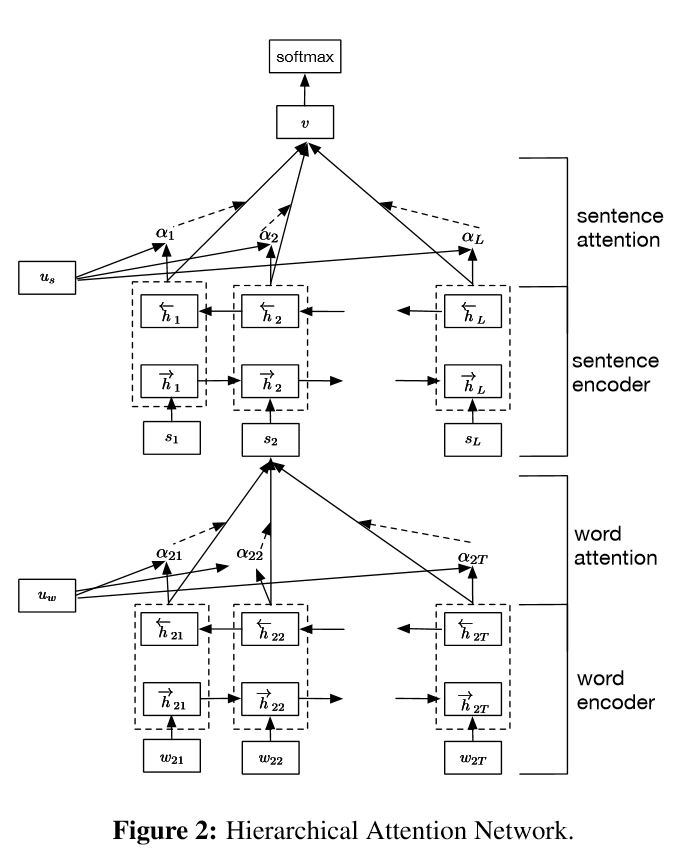
Implementasi jaringan perhatian hierarkis untuk klasifikasi dokumen
Struktur:
menanamkan
Word Encoder: Level Word BI-Directional Gru untuk mendapatkan representasi kata yang kaya
Perhatian Kata: Perhatian Level Kata untuk Mendapatkan Informasi Penting dalam Kalimat
Kalimat Encoder: Tingkat Kalimat BI-Directional Gru untuk mendapatkan representasi kalimat yang kaya
Kalimat Attetion: Tingkat Kalimat Perhatian untuk mendapatkan kalimat penting di antara kalimat
Fc+softmax
Dalam NLP, klasifikasi teks dapat dilakukan untuk kalimat tunggal, tetapi juga dapat digunakan untuk beberapa kalimat. Kami dapat menyebutnya klasifikasi dokumen. Kata -kata adalah bentuk kalimat. Dan kalimat adalah bentuk untuk didokumentasikan. Dalam keadaan ini, mungkin ada struktur intrinsik. Jadi bagaimana kita bisa memodelkan tugas semacam ini? Apakah semua bagian dokumen sama -sama relevan? Dan bagaimana kita menentukan bagian mana yang lebih penting dari yang lain?
Ini memiliki dua fitur unik:
1) ia memiliki struktur hierarkis yang mencerminkan struktur hierarkis dokumen;
2) Ini memiliki dua tingkat mekanisme perhatian yang digunakan pada tingkat kata dan kalimat. Ini memungkinkan model untuk menangkap informasi penting di berbagai tingkatan.
Word Encoder: Untuk setiap kata dalam sebuah kalimat, itu tertanam ke dalam kata vektor dalam ruang vektor distribusi. Menggunakan GRU dua arah untuk menyandikan kalimat. Dengan vektor gabungan dari dua arah, sekarang dapat membentuk representasi kalimat, yang juga menangkap informasi kontekstual.
Perhatian Kata: Kata yang sama lebih penting daripada yang lain untuk kalimat. Jadi mekanisme perhatian digunakan. Pertama -tama menggunakan satu lapisan MLP untuk mendapatkan representasi tersembunyi UIT dari kalimat, kemudian mengukur pentingnya kata sebagai kesamaan UIT dengan vektor konteks tingkat kata UW dan mendapatkan kepentingan yang dinormalisasi melalui fungsi softmax.
Kalimat Encoder: Untuk vektor kalimat, gRU dua arah digunakan untuk menyandikannya. Demikian pula dengan Word Encoder.
Perhatian kalimat: Vektor tingkat kalimat digunakan untuk mengukur kepentingan di antara kalimat. Demikian pula dengan perhatian kata.
Input data:
Secara umum, masukan dari model ini harus memiliki kalimat serveral alih -alih kalimat sinle. Bentuknya adalah: [tidak ada, kalimat_lenght]. di mana tidak ada yang berarti batch_size.
Dalam data pelatihan saya, untuk setiap contoh, saya memiliki empat bagian. Setiap bagian memiliki panjang yang sama. Saya concat empat bagian untuk membentuk satu kalimat tunggal. Model akan membagi kalimat menjadi empat bagian, untuk membentuk tensor dengan bentuk: [tidak ada, num_sentence, kalimat_length]. di mana num_sentence adalah jumlah kalimat (sama dengan 4, dalam pengaturan saya).
Periksa: p1_hierarchicalattention_model.py
Untuk perhatian yang penuh perhatian, Anda dapat memeriksa perhatian yang penuh perhatian
Implementasi seq2seq dengan perhatian yang berasal dari terjemahan mesin saraf dengan bersama -sama belajar untuk menyelaraskan dan menerjemahkan
I.Struktur:
1) Embedding 2) Bi-gru juga mendapatkan representasi kaya dari kalimat sumber (maju & mundur). 3) Decoder dengan perhatian.
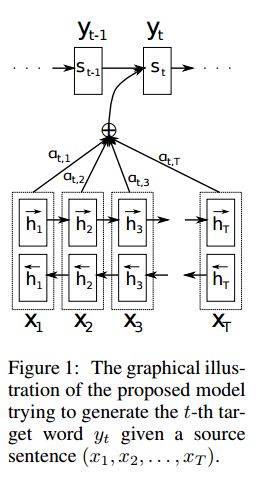
Ii.put dari data:
Ada dua jenis tiga jenis input: 1) input enkoder, yang merupakan kalimat; 2) Input dekoder, itu adalah daftar label dengan panjang tetap; 3) label target, itu juga merupakan daftar label.
Misalnya, label adalah: "L1 L2 L3 L4", maka input decoder akan menjadi: [_ go, l1, l2, l2, l3, _pad]; Label target adalah: [L1, L2, L3, L3, _end, _pad]. Panjang ditetapkan ke 6, label yang melebihi akan trancated, akan pad jika label tidak cukup untuk diisi.
III. Mekanisme Perhatian:
Transfer Daftar Input Encoder dan Status Dekoder Tersembunyi
Hitung kesamaan keadaan tersembunyi dengan setiap input encoder, untuk mendapatkan distribusi kemungkinan untuk setiap input encoder.
Jumlah input enkoder tertimbang berdasarkan distribusi kemungkinan.
Pergi meskipun sel RNN menggunakan jumlah berat ini bersama -sama dengan input decoder untuk mendapatkan keadaan tersembunyi yang baru
IV. Bagaimana Decoder Encoder Vanilla Bekerja:
Kalimat sumber akan dikodekan menggunakan RNN sebagai vektor ukuran tetap ("pemikiran vektor"). Kemudian selama decoder:
Ketika sedang berlatih, RNN lain akan digunakan untuk mencoba mendapatkan kata dengan menggunakan "vektor pemikiran" ini sebagai status init, dan mengambil input dari input dekoder di setiap cap waktu. Decoder mulai dari token khusus "_go". Setelah satu langkah dilakukan, keadaan tersembunyi baru akan didapat dan bersama dengan input baru, kita dapat melanjutkan proses ini sampai kita mencapai token khusus "_end". Kami dapat menghitung kerugian dengan menghitung kehilangan entropi logit dan label target. Logit adalah melewati lapisan proyeksi untuk keadaan tersembunyi (untuk output dari langkah decoder (di Gru kita bisa menggunakan keadaan tersembunyi dari decoder sebagai output).
Saat pengujian, tidak ada label. Jadi kita harus memberi makan output yang kita dapatkan dari cap waktu sebelumnya, dan melanjutkan proses yang kita capai "_end" token.
V.Notices:
Di sini saya menggunakan dua jenis kosa kata. Salah satunya adalah dari kata -kata, digunakan oleh encoder; Lain adalah untuk label, digunakan oleh decoder
Untuk kosakata lables, saya memasukkan tiga token khusus: "_ go", "_ end", "_ Pad"; "_Unk" tidak digunakan, karena semua label telah ditentukan sebelumnya.
Status: Itu dapat melakukan klasifikasi tugas. dan mampu menghasilkan urutan terbalik urutannya dalam tugas mainan. Anda dapat memeriksanya dengan menjalankan fungsi uji dalam model. Periksa: a2_train_classification.py (train) atau a2_transformer_classification.py (model)
Kami melakukannya dalam gaya paralell. Normalisasi pelapis, koneksi residual, dan topeng juga digunakan dalam model.
Untuk setiap blok bangunan, kami menyertakan fungsi pengujian di setiap file di bawah ini, dan kami telah menguji setiap bagian kecil dengan sukses.
Urutan untuk urutan dengan perhatian adalah model khas untuk memecahkan masalah generasi urutan, seperti terjemahan, sistem dialog. Sebagian besar waktu, menggunakan RNN sebagai blok buidling untuk melakukan tugas -tugas ini. Baru -baru ini, orang juga menerapkan jaringan saraf konvolusional untuk masalah urutan ke urutan. Transformer, bagaimanapun, melakukan tugas -tugas ini semata -mata pada Mechansim perhatian. Ini cepat dan mencapai hasil canggih yang baru.
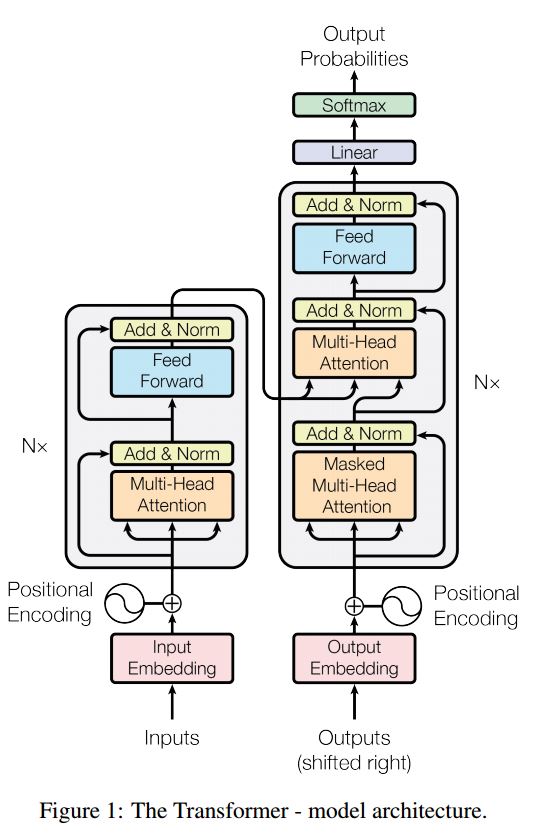
Ini juga memiliki dua bagian utama: encoder dan decoder. Di bawah ini adalah desc dari kertas:
Encoder:
6 lapisan. Lapisan masing-masing memiliki dua sub-layer. Yang pertama adalah mekanisme swadaya multi-head; Yang kedua adalah jaringan feed-forward feed-forward yang sepenuhnya terhubung. untuk setiap sublayer. Gunakan LayerNorm (X+Sublayer (X)). semua dimensi = 512.
Decoder:
Pengambilan utama dari model ini:
Gunakan model ini untuk melakukan klasifikasi tugas:
Di sini kami hanya menggunakan bagian Encode untuk klasifikasi tugas, koneksi resdiual yang dihapus, hanya menggunakan 1 lapisan. Tidak perlu menggunakan mask. Kami menggunakan perhatian multi-head dan umpan ke depan untuk mengekstrak fitur kalimat input, kemudian menggunakan lapisan linier untuk memproyeksikannya untuk mendapatkan logit.
Untuk detail model, silakan periksa: a2_transformer_classification.py
Input: 1. Cerita: Ini adalah multi-kalimat, sebagai konteks. 2.Query: Sebuah kalimat, yang merupakan pertanyaan, 3. Ansewr: Label tunggal.
Struktur Model:
Pengkodean input: Gunakan tas kata untuk menyandikan cerita (konteks) dan kueri (pertanyaan); memperhitungkan posisi dengan menggunakan mask posisi
Dengan menggunakan RNN bi-directional untuk menyandikan cerita dan kueri, peningkatan kinerja dari 0,392 menjadi 0,398, meningkat 1,5%.
Memori dinamis:
A. Hitung gerbang dengan menggunakan 'kesamaan' kunci, nilai dengan input cerita.
B. Dapatkan kandidat yang tersembunyi dengan mengubah setiap kunci, nilai dan input.
C. Gabungkan Gerbang dan Kandidat Tersembunyi untuk memperbarui keadaan tersembunyi saat ini.
B. Dapatkan jumlah tertimbang dari keadaan tersembunyi menggunakan distribusi kemungkinan.
C. Transformasi non-linearitas kueri dan keadaan tersembunyi untuk mendapatkan label prediksi.
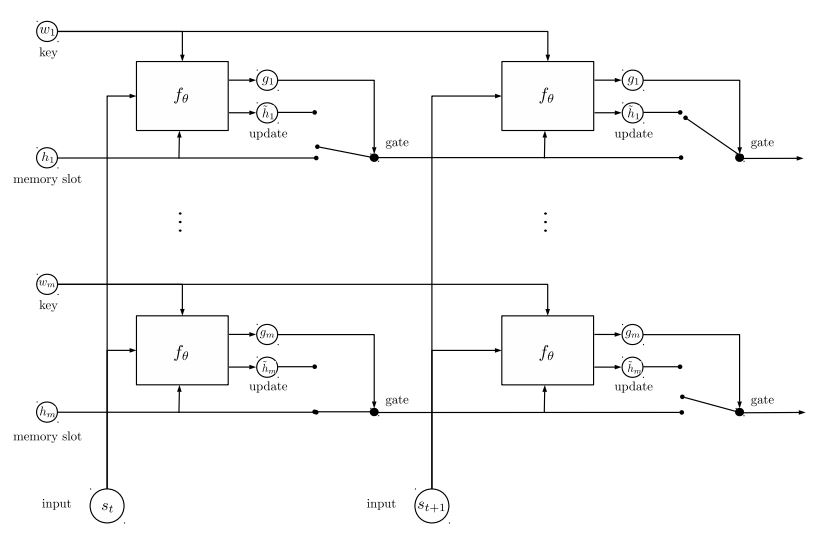
Pengambilan utama dari model ini:
Gunakan blok kunci dan nilai, yang independen satu sama lain. Jadi bisa dijalankan secara paralel.
pemodelan konteks dan pertanyaan bersama. Gunakan memori untuk melacak State of World; dan gunakan transformasi non-linearitas dari keadaan tersembunyi dan pertanyaan (kueri) untuk membuat prediksi.
Model sederhana juga dapat mencapai kinerja yang sangat baik. Encode sederhana sebagai penggunaan tas kata.
Untuk detail model, silakan periksa: a3_entity_network.py
Di bawah model ini, ia memiliki fungsi uji, yang meminta model ini untuk menghitung angka baik untuk cerita (konteks) dan kueri (pertanyaan). Tapi bobot cerita lebih kecil dari kueri.
Pandangan Model:
1. Modul Input: mengkodekan teks mentah ke dalam representasi vektor
2. Modul Pemberitahuan: Menyandikan pertanyaan ke dalam representasi vektor
3. Modul Memori Episodik: Dengan input, ia memilih bagian input mana yang harus difokuskan melalui mekanisme perhatian, dengan mempertimbangkan pertanyaan dan memori sebelumnya ====> Ini membuat vecotr 'memori'.
4.sanswer Module: Hasilkan jawaban dari vektor memori akhir.
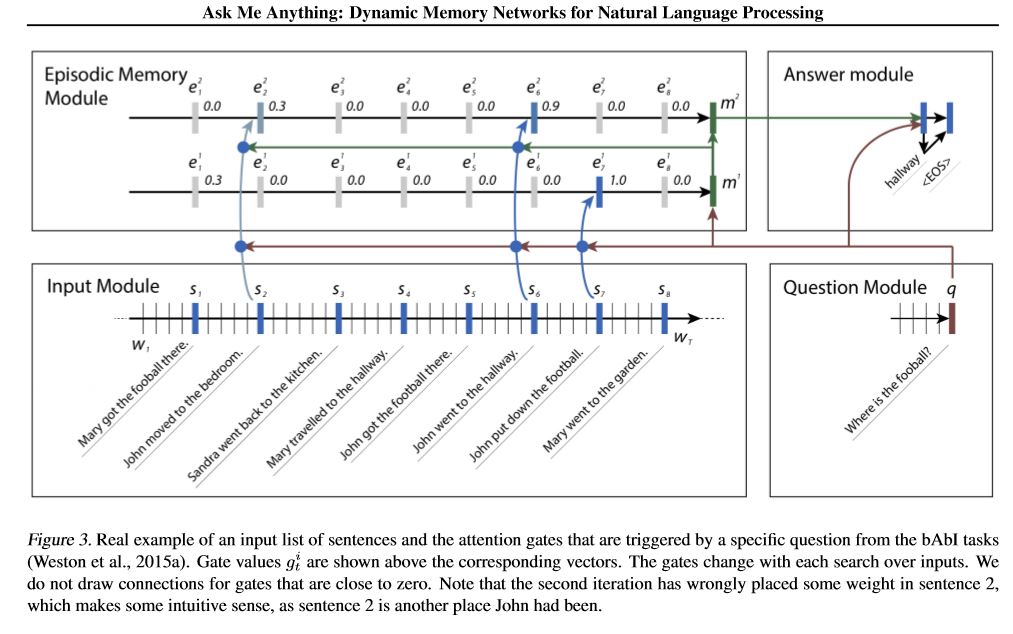
Detail:
1. Modul Input:
A.Single Kalimat: Gunakan Gru untuk mendapatkan keadaan tersembunyi B. List of Salmence: Gunakan Gru untuk mendapatkan negara yang tersembunyi untuk setiap kalimat. misalnya [Negara Tersembunyi 1, Negara Tersembunyi 2, Negara Tersembunyi ..., Negara Tersembunyi N]
2. Modul Pertanyaan: Gunakan Gru untuk mendapatkan keadaan tersembunyi
3. Modul Memori Episodik:
Gunakan mekanisme perhatian dan jaringan berulang untuk memperbarui memori.
A. gerbang sebagai mekanisme perhatian:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B. Mekanisme Pembaruan Memori: Ambil Kalimat Kandidat, Gerbang dan Keadaan Tersembunyi Sebelumnya, menggunakan Gated-Gru untuk memperbarui keadaan tersembunyi. seperti: h = f (c, h_previous, g). Keadaan tersembunyi terakhir adalah input untuk modul jawaban.
C. Kebutuhan untuk beberapa episode ===> inferensi transitif.
misalnya bertanya dimana sepak bola? Ini akan menghadiri hukuman "John meletakkan sepak bola"), lalu di pass kedua, ia perlu menghadiri lokasi John.
4.sanswer Module: Ambil memori epsoidic akhir, pertanyaan, memperbarui keadaan tersembunyi modul jawaban.
1. Jaringan konvolusional tingkat karakter untuk klasifikasi teks
2. Jaringan saraf konvolusional untuk kategorisasi teks: level kata yang dangkal vs tingkat karakter dalam
3. Jaringan konvolusional yang sangat dalam untuk klasifikasi teks
4. Metode Pelatihan LADSAD untuk klasifikasi teks semi-diawasi
5. Model yang Dibuat
Selama proses melakukan skala besar klasifikasi multi-label, pelajaran serveral telah dipelajari, dan beberapa daftar seperti di bawah ini:
Apa hal terpenting untuk mencapai akurasi tinggi? Itu tergantung tugas yang Anda lakukan. Dari tugas yang kami lakukan di sini, kami percaya bahwa model ensemble berdasarkan model yang dilatih dari beberapa fitur termasuk Word, karakter untuk judul dan deskripsi dapat membantu mencapai akuarcy yang sangat tinggi; Namun, dalam beberapa kasus, seperti yang ditunjukkan Alphago Zero, algoritma lebih penting daripada data atau kekuatan komputasi, pada kenyataannya AlphaGo Zero tidak menggunakan data Humam.
Apakah ada langit -langit untuk model atau algoritma tertentu? Jawabannya adalah ya. Banyak model yang berbeda digunakan di sini, kami menemukan banyak model memiliki kinerja yang serupa, meskipun ada struktur yang sangat berbeda. Dalam beberapa hal, perbedaan kinerja tidak begitu besar.
Apakah studi kasus kesalahan bermanfaat? Saya pikir ini cukup berguna terutama ketika Anda telah melakukan banyak hal yang berbeda, tetapi mencapai batas. Misalnya, dengan melakukan studi kasus, Anda dapat menemukan label yang model dapat membuat prediksi yang benar, dan di mana mereka membuat kesalahan. Dan untuk mempengaruhi kinerja dengan meningkatkan bobot label yang diprediksi salah ini atau menemukan kesalahan potensial dari data.
Bagaimana kita bisa menjadi ahli dalam pembelajaran mesin khusus? Menurut pendapat saya, bergabunglah dengan kompetasi pembelajaran mesin atau memulai tugas dengan banyak data, lalu baca makalah dan terapkan beberapa, adalah titik awal yang baik. Jadi kami akan memiliki beberapa pengalaman dan ide untuk menangani tugas tertentu, dan mengetahui tantangannya. Tetapi yang lebih penting adalah bahwa kita tidak hanya harus mengikuti ide -ide dari makalah, tetapi untuk mengeksplorasi beberapa ide baru yang kita pikir dapat membantu menyelipkan masalah. Misalnya, dengan mengubah struktur model klasik atau bahkan menciptakan beberapa struktur baru, kami mungkin dapat mengatasi masalah dengan cara yang jauh lebih baik karena mungkin lebih cocok untuk tugas yang kami lakukan.
1. Bag trik untuk klasifikasi teks yang efisien
2. Jaringan saraf konvolusional untuk klasifikasi kalimat
3. Analisis sensitivitas (dan panduan praktisi untuk) jaringan saraf konvolusional untuk klasifikasi kalimat
4. Pembelajaran Deep untuk Chatbots, Bagian 2-Menerapkan model berbasis pengambilan di TensorFlow, dari www.wildml.com
5. Jaringan Saraf Konvolusional Recurrent untuk Klasifikasi Teks
6. Jaringan Perhatian Hierarkis untuk Klasifikasi Dokumen
7. Penerjemahan Mesineural dengan Belajar Bersama -sama untuk Menyelaraskan dan Menerjemahkan
8. Perhatian adalah semua yang Anda butuhkan
9.Tuksi saya apa saja: Jaringan memori dinamis untuk pemrosesan bahasa alami
10. Mengatasi keadaan dunia dengan jaringan entitas berulang
11. Pilihan yang Diberikan dari Perpustakaan Model
12.Bert: Pra-pelatihan transformer dua arah yang dalam untuk pemahaman bahasa
13.Google-Research/Bert
untuk dilanjutkan. Untuk masalah apa pun, concat [email protected]


