text_classification
1.0.0
该存储库的目的是探索NLP中的文本分类方法,并深入学习。
免费在三分钟内自定义NLP API,免费:NLP API演示
中文的语言理解评估基准(线索基准):运行10个任务和9个基线,并具有一行代码,性能比较与详细信息。
在中国国庆日期间,使用30G+原始的中国语料库,XXLARGE,XLARGE等释放预先训练的Albert_chinese培训模型,以符合中文,2019- OCT-7的最新表现状态,以符合中文的最新表现状态!
提供大量的NLP中国语料库!
Google的Bert使用语言模型中的Pre-Train在NLP中的10多个任务中实现了新的最新成果
微调。预训练TEXCNN:来自Bert的想法,用于使用运行代码和数据集的语言理解
它具有各种用于文本分类的基线模型。
它还支持多标签分类,其中多标签与句子或文档相关联。
尽管其中许多模型很简单,并且可能不会让您达到任务的最高水平。但是其中一些模型非常
经典,因此可以用作基线模型可能很好。每个模型在模型类下都有一个测试功能。你可以运行
它首先执行玩具任务。该模型独立于数据集。
在此处查看与深度学习的大规模多标签文本分类的正式报告
这里的几种模型也可以用于建模问题答案(有或没有上下文),也可以用于进行序列生成。
我们探索了两个SEQ2SEQ模型(您需要的是Transformer注意的SEQ2SEQ)进行文本分类。
而且这两个模型也可以用于生成和其他任务的序列。如果您的任务是多标签分类,
您可以将问题投入到序列生成。
我们实现两个内存网络。一个是动态内存网络。以前它已经达到了有关的现状
回答,情感分析和序列生成任务。这样被称为一个模型来执行几个不同的任务,
并达到高性能。它有四个模块。关键组件是情节内存模块。它使用门机构
性能关注,并使用盖特格鲁(Gated-gru
性能隐藏状态更新。它具有进行及物推理的能力。
我们实施的第二个内存网络是经常性实体网络:跟踪世界状态。它有
钥匙值对作为内存,并并行运行,实现新的先进状态。它可用于建模问题
用上下文(或历史)回答。例如,您可以让模型读取一些句子(作为上下文),并询问
问题(作为查询),然后要求模型预测答案;如果您的故事与查询相同,那么它可以做到
分类任务。
要讨论ML/DL/NLP问题并获得彼此的技术支持,您可以加入QQ组:836811304
fastText
textcnn
BERT:深层双向变压器的预训练以了解语言理解
Textrnn
rcnn
分层注意力网络
seq2seq引起了人们的注意
变压器(“参加您需要的一切”)
动态内存网络
实体网络:跟踪世界状态
合奏模型
提升:
对于单个模型,将相同的模型堆叠在一起。每一层都是模型。结果将基于添加的逻辑。层之间的唯一连接是标签的重量。前层的每个标签的预测错误率将成为下一层的重量。这些错误率高的标签将具有很大的重量。因此,后来的一层将更多地关注那些错误预测的标签,并尝试解决以前层的以前错误。结果,我们将获得一个强大的模型。检查a00_boosting/boosting.py
和其他模型:
Bilstmtextrelation;
Twocnntextrelation;
Bilstmtextrelationtwornn
(Mulit标签标签预测任务,要求预测前5个,300万培训数据,完整分数:0.5)
| 模型 | fastText | textcnn | Textrnn | rcnn | Hierattenet | seq2seqattn | EntityNet | 动态信息 | 变压器 |
|---|---|---|---|---|---|---|---|---|---|
| 分数 | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| 训练 | 10m | 2H | 10H | 2H | 2H | 3H | 3H | 5H | 7H |
BERT模型在验证集的前9个时期后达到0.368。
TextCNN,EntityNet,DynamicMemory的合奏:0.411
集合EntityNet,DynamicMemory:0.403
注意:
m站了几分钟; h站了几个小时;
HierAtteNet表示分层注意力网络;
Seq2seqAttn的意思是seq2seq。
DynamicMemory表示DynamicMemoryNetwork;
Transformer代表模型的“注意力就是您所需要的”。
xxx_model.py中xxx_train.py训练模型xxx_predict.py进行推理(测试)。每个模型都有模型类下的测试方法。您可以首先运行测试方法,以检查模型是否可以正常工作。
Python 2.7+ TensorFlow 1.8
(TensorFlow 1.1至1.13也应起作用;大多数模型也应在其他张量Flow版本中正常工作,因为我们
在某些版本中使用很少的功能。
如果您使用Python3,只要您遇到任何错误,只要更改打印/尝试捕获功能,就可以了。
TextCNN模型已经转移到Python 3.6
为了帮助您运行此存储库,当前我们重新生成培训/验证/测试数据和词汇/标签,并保存
它们使用H5PY作为缓存文件。我们建议您从上面的链接下载它。
它包含运行此存储库所需的所有内容:数据已预处理,您可以在一分钟内开始训练该模型。
这是一个约1.8克的拉链文件,包含300万个培训数据。尽管在解开拉链后很大,但是在
HDF5,在培训过程中,仅需要正常的计算机内存(例如或更少)。
我们使用jupyter笔记本:预处理.ipynb进行预处理数据。您可以更好地了解此任务,并且
通过查看数据。您还可以按照自己的方式独自生成数据,只需更改几行代码
使用此Jupyter笔记本。
如果要立即尝试模型,则可以从上方划入缓存文件,然后转到文件夹“ A02_TEXTCNN”,运行
python p7_TextCNN_train.py
它将使用来自缓存文件的数据来训练模型,并定期打印损失和F1分数。
旧示例数据源:如果您需要在Word2Vec上进行的一些示例数据和单词嵌入,则可以在封闭的问题中找到它,例如:第3期。
您还可以在文件夹“数据”上找到一些示例数据。它包含两个文件:“ sample_single_label.txt”,包含50k数据
带有单标签; 'sample_multiple_label.txt'包含具有多个标签的20K数据。输入和标签由“标签”分开。
如果您想了解有关文本分类或任务数据集的更多详细信息,则可以使用这些模型,其中之一就是以下:
https://biendata.com/competition/zhihu/
您可以使用此存储库的一种方法:
步骤1:您可以阅读本文。您将了解用于进行文本分类的各种经典模型的一般想法。
步骤2:预处理数据和/或下载缓存文件。
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
步骤3:在此处运行一些模型列表,并根据需要更改一些代码和配置,以获得良好的性能。
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
此外,写有关此主题的文章,您可以遵循纸张的样式写。您可能需要阅读一些论文
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
在“ data/sample_multiple_label.txt”中替换数据,并确保格式如下:
'Word1 Word2 Word3 __label__l1 __label __l2 __label __l3'
其中part1:'Word1 Word2 Word3'是输入(x),part2:'__label__l1 __label __l2 __l2 __label __label__l3'
代表三个标签:[L1,L2,L3]。在第1部分和第2部分之间,应该有一个空字符串:''。
例如:每行(多个标签)类似:
'w5466 w138990 w1638 w4301 w6 w470 w202 c1834 c1400 c134 c57 c73 c699 c317 c184 __label__5626661657638885119 __label__4921793805334628695 __LABEL __8904735555009151318'
其中“ 5626661657638885119','4921793805334628695',','8904735555009151318'是与此输入字符串'W5466 W138990 ...
注意:
data_util.py中的一些util函数;检查data_util的load_data_multilabel(),以获取从原始数据中输入和标签的方式。
有一个功能可以加载并为模型分配预贴的单词嵌入,其中word2vec或fastText介绍了单词嵌入。
如果word2vec.load不起作用,则可以加载验证的单词嵌入,特别是对于中文嵌入使用以下行:
导入Gensim
从Gensim.Models导入键盘向量
word2vec_model = keyedVectors.load_word2vec_format(word2vec_model_path,binary = true,unicode_errors ='nighore')#
或者,您可以使用将标志嵌入为false到禁用加载单词嵌入的fallain Word嵌入。
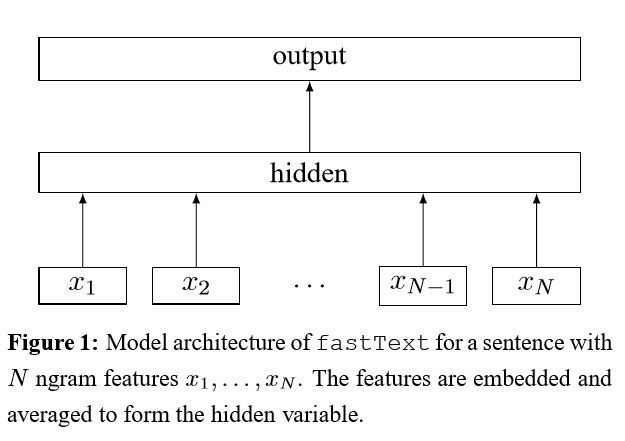
暗示技巧袋,以进行有效的文本分类
将每个单词嵌入句子中后,然后将该单词表示形式平均为文本表示形式,而文本表示形式又将其馈送到线性分类器中。IT使用SoftMax函数来计算预定义类的概率分布。然后使用熵来计算损失。单词表示袋不考虑单词顺序。为了考虑单词顺序,n-gram功能用于捕获有关本地单词顺序的一些部分信息;当类的数量很大时,计算线性分类器的计算昂贵。因此,它使用hhierharchical softmax来加快训练过程。
结果:性能与纸张一样好,速度也很快。
检查:p5_fasttextb_model.py
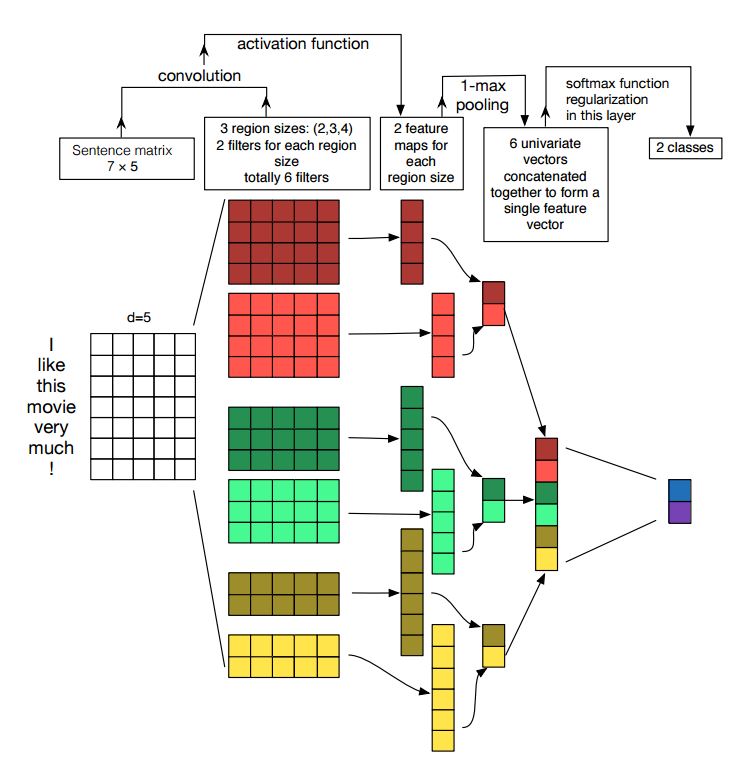
卷积神经网络的实施句子分类
结构:嵌入---> CONS --->最大池化--->完全连接的图层--------> SoftMax
检查:p7_textcnn_model.py
为了通过TextCNN获得非常好的结果,您还需要仔细阅读有关本文的敏感性分析(以及从业者的指南)卷积神经网络进行句子分类:它为您提供了一些可能影响性能的事物的见解。尽管您需要根据特定任务更改某些设置。
卷积神经网络是用于解决计算机视觉问题的主建筑框。现在,我们将展示如何将CNN用于NLP,尤其是文本分类。句子长度从一个到另一个会不同。因此,我们将使用垫子获得固定长度,n。对于句子中的每个令牌,我们将使用单词嵌入来获取固定的尺寸向量,d。因此,我们的输入是一个2维矩阵:(n,d)。这与CNN的图像相似。
首先,我们将对输入进行卷积操作。它是元素的乘积在滤波器和一部分输入之间乘以。我们使用k数量的过滤器,每个过滤器大小都是2维矩阵(F,d)。现在,输出将为k列表。每个列表的长度为n-f+1。每个元素都是标量。请注意,第二维将始终是单词嵌入的维度。我们正在使用不同大小的过滤器来从文本输入中获得丰富的功能。这与n-gram功能类似。
其次,我们将对卷积操作的输出进行最大池。对于k的列表,我们将获得k数量的标量。
第三,我们将串联标量形成最终功能。它是固定尺寸的向量。它独立于我们使用的过滤器的大小。
最后,我们将使用线性层将这些功能投影到人均标签。
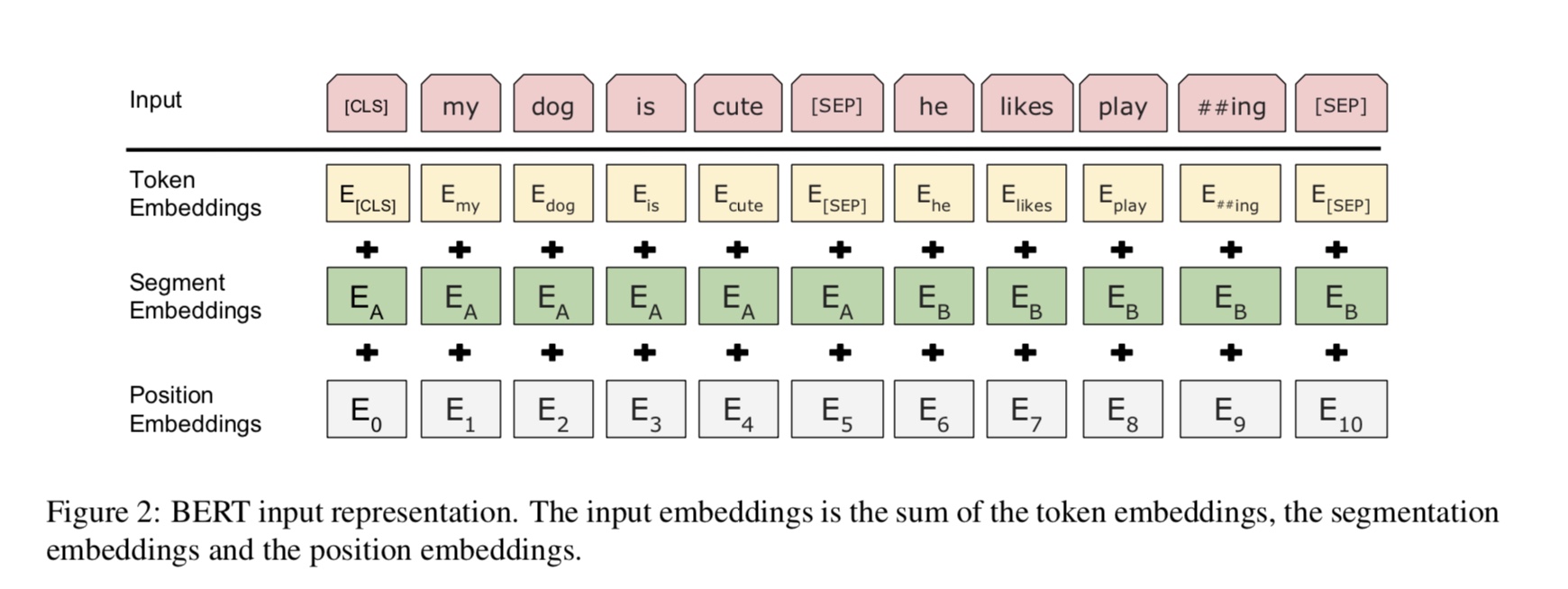
目前,BERT在10个以上的NLP任务上实现了最先进的结果。该模型背后的关键思想是我们可以
通过使用具有大量原始数据的一种语言模型来预先训练模型,您可以轻松找到它。
由于该模型的大多数参数都是预训练的,因此只需要用于分类器的最后一层需要使用不同的任务。
结果,该模型是通用且非常强大的。您可以根据预先训练的模型进行微调
短时间。
但是,这个模型很大。序列长度为128,您可能只能以32批量的批量训练;长时间
诸如序列长度512之类的文档,它只能训练正常GPU(11克)的批量4;很少有人
可以从头开始预先训练该模型,因为训练需要数天或几周,而正常的GPU记忆太小
对于此模型。
特别是,骨干模型是变压器,您需要在这里找到它。它使用两种
预先培训模型的任务。
一般而言,给定句子,掩盖了一定比例的单词,您需要预测掩盖的单词
基于这个蒙面的句子。蒙面的单词被随机封闭。
我们通过深层变压器编码器馈入输入,然后使用对应于蒙版的最终隐藏状态
可以预测哪个单词被掩盖的位置,就像我们将训练语言模型一样。
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
许多语言理解任务,例如问答,推论,需要理解关系
在句子之间。但是,语言模型只能在没有句子的情况下理解。下一个句子
预测是一项示例任务,可以帮助模型在这类任务中更好地理解。
机会的50%是第二句话的下一个句子,而不是下一个句子的50%。
给定两个句子,要求该模型预测第二句是否是真实的下一个句子
第一个。
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
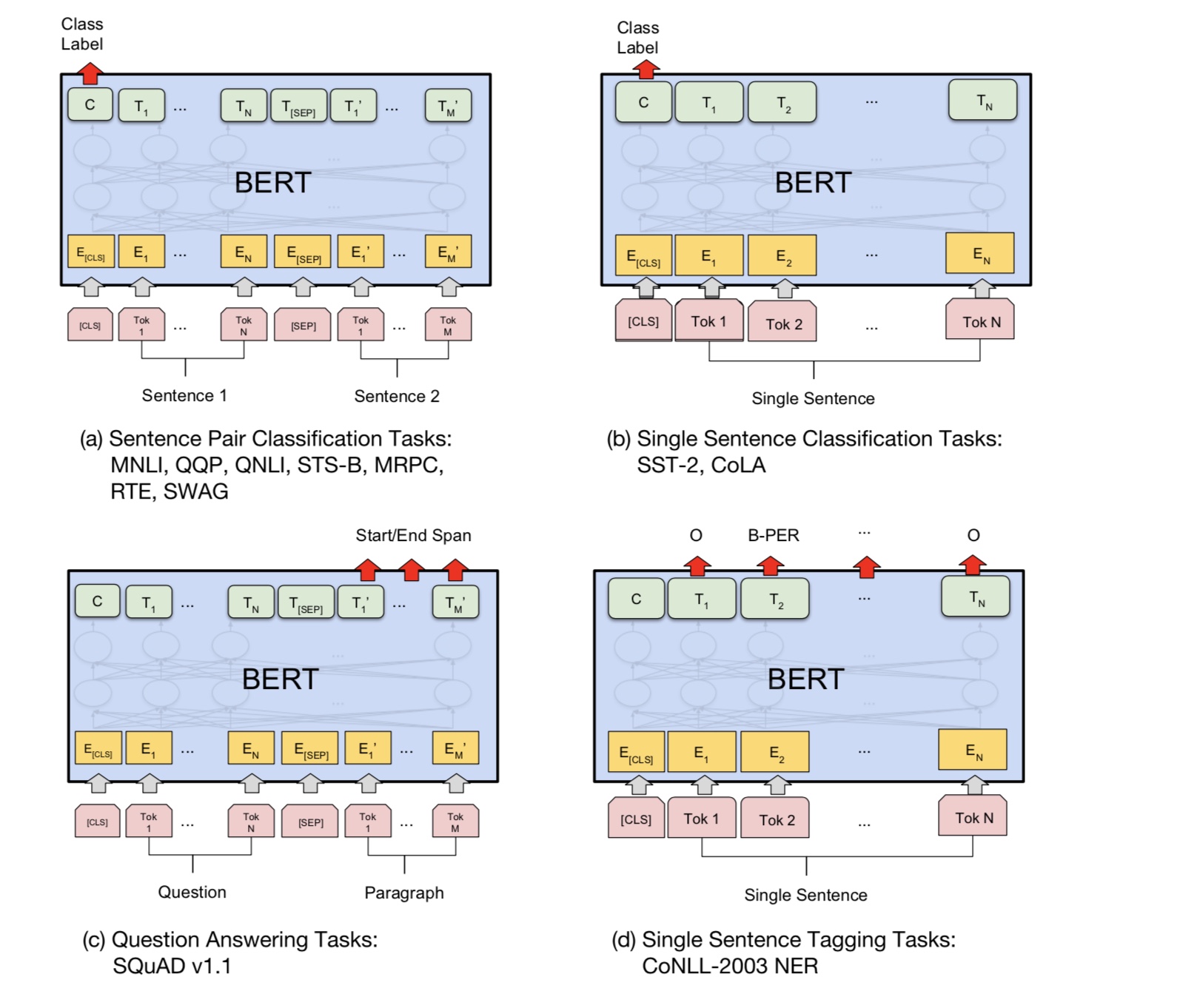
基本上,您可以下载预训练的模型,只能使用自己的数据对您的任务进行微调。
对于分类任务,您可以添加处理器来定义要允许输入和从源数据标签的格式。
在文件夹A00_Bert下运行以下命令:
python train_bert_multi-label.py
它在9个时期后达到0.368。或者,您可以使用BERT使用BERT运行多标签分类
sentiment_analysis_fine_grain带有bert
您可以使用会话和供稿样式来恢复模型和供稿数据,然后获取逻辑以进行在线预测。
用伯特在线预测
最初,它基于文件而不是在线训练或评估模型。
首先,您可以使用Google的预训练模型下载。在您的数据集上运行一些时代,并找到合适的
序列长度。
其次,您可以在自己的数据中预先培训基本模型,只要您找到与
您的任务,然后对您的特定任务进行微调。
第三,您可以更改损失功能和最后一层,以更好地适合您的任务。
此外,您可以添加定义一些预训练的任务,这些任务将帮助模型更好地了解您的任务。
正如我们从实验中获得的那样,预训练的任务独立于模型,并且预训练并不局限于
上面的任务。
结构V1:嵌入--->双向LSTM ---> Concat输出---->平均-----> SoftMax层
检查:p8_textrnn_model.py
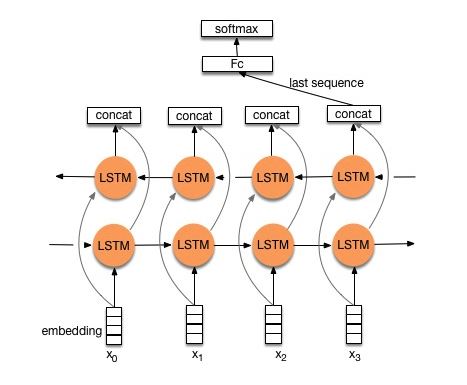
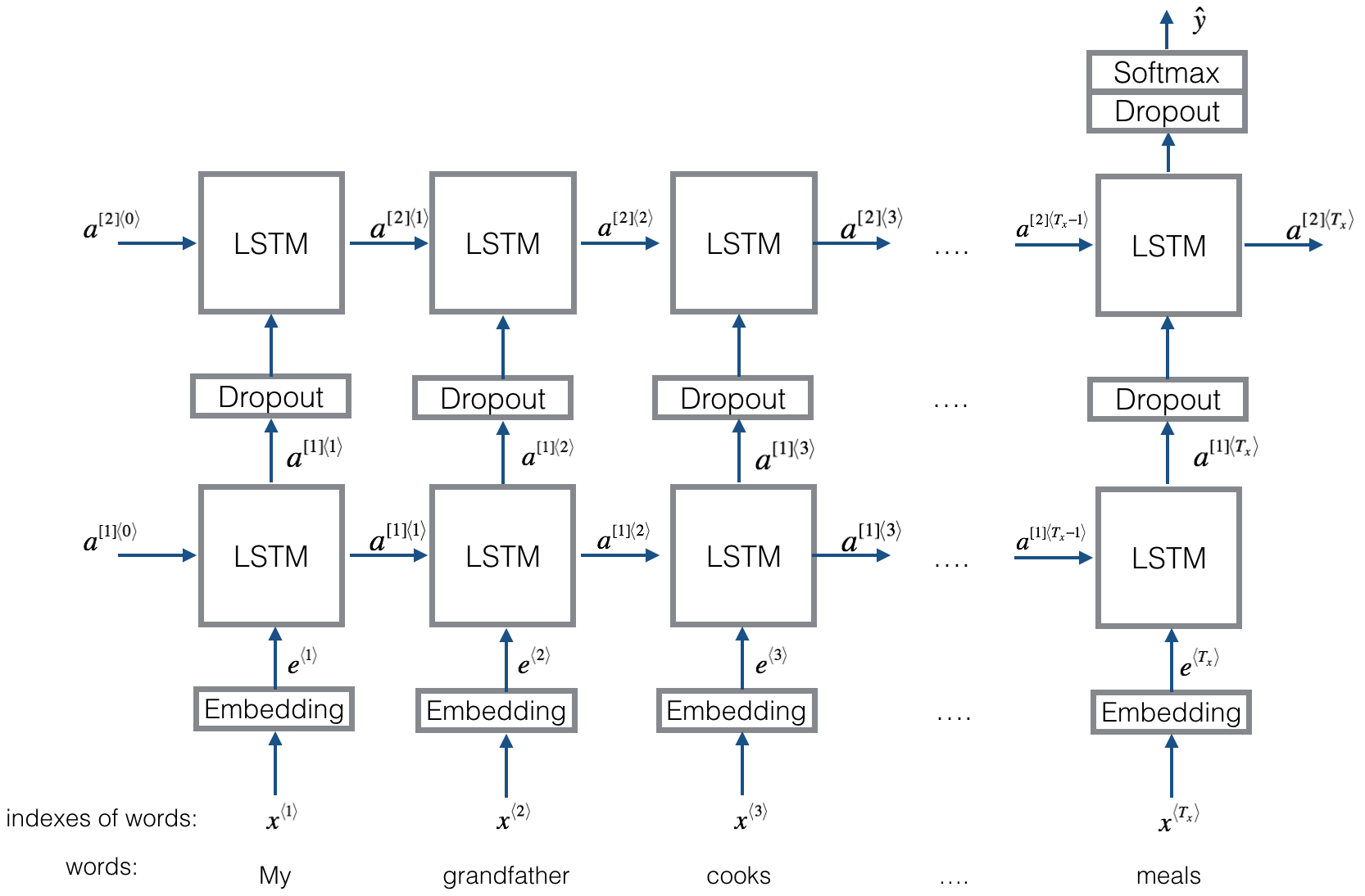
结构V2:嵌入 - >双向LSTM ---->辍学 - > Concat Ouput ---> lstm ---> lstm ---> droput-> fc layer-> softmax layer
检查:p8_textrnn_model_multilayer.py
结构与Textrnn相同。但是输入是特殊设计的。 eginput:“计算机是多少?笔记本电脑的EOS价格”。其中“ eos”是一个特殊的令牌问题1和Question2。
检查:p9_bilstmtextrelation_model.py
结构:首先使用两个不同的卷积来提取两个句子的特征。然后加入两个功能。使用线性变换层将投影投影到目标标签,然后将SoftMax投影。
检查:p9_twocnntextrelation_model.py
结构:一个句子的一个双向LSTM(获取输出1),另一个句子的另一个双向LSTM(get Uptown2)。然后:SoftMax(输出1 M输出2)
检查:p9_bilstmtextrelationtwornn_model.py
有关更多详细信息,您可以转到:聊天机器人的深度学习,第2部分 - 在TensorFlow中实现基于检索的模型
用于文本分类的卷积神经网络
用于文本分类的卷积神经网络的实施
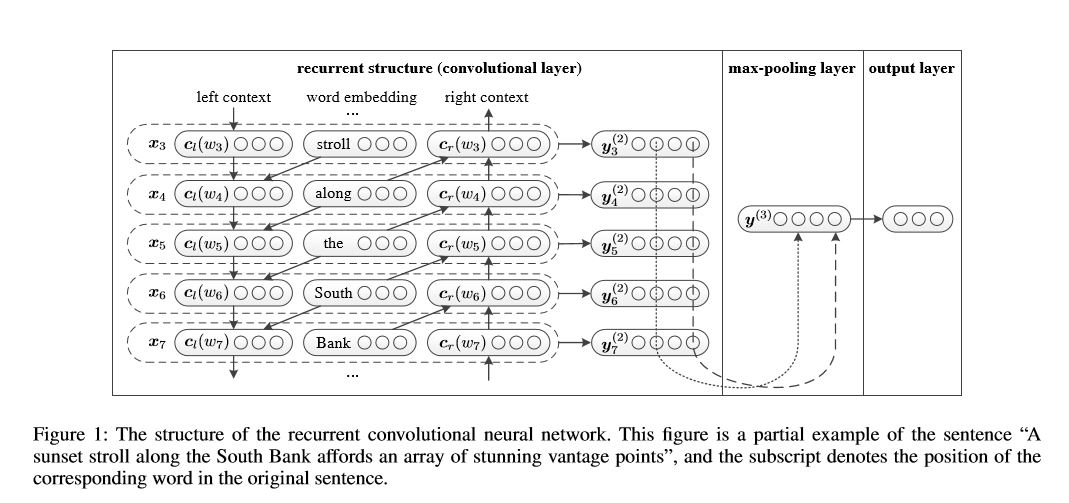
结构:1)经常性结构(卷积层)2)最大池3)完全连接的层+softmax
它在句子或左侧上下文中的句子或文档中学习代表每个单词:
表示当前词= [left_side_context_vector,current_word_embedding,right_side_context_vecotor]。
对于左侧上下文,它使用经常性结构,是前一个单词的无线性转换和左侧上下文。类似于右侧上下文。
检查:p71_textrcnn_model.py
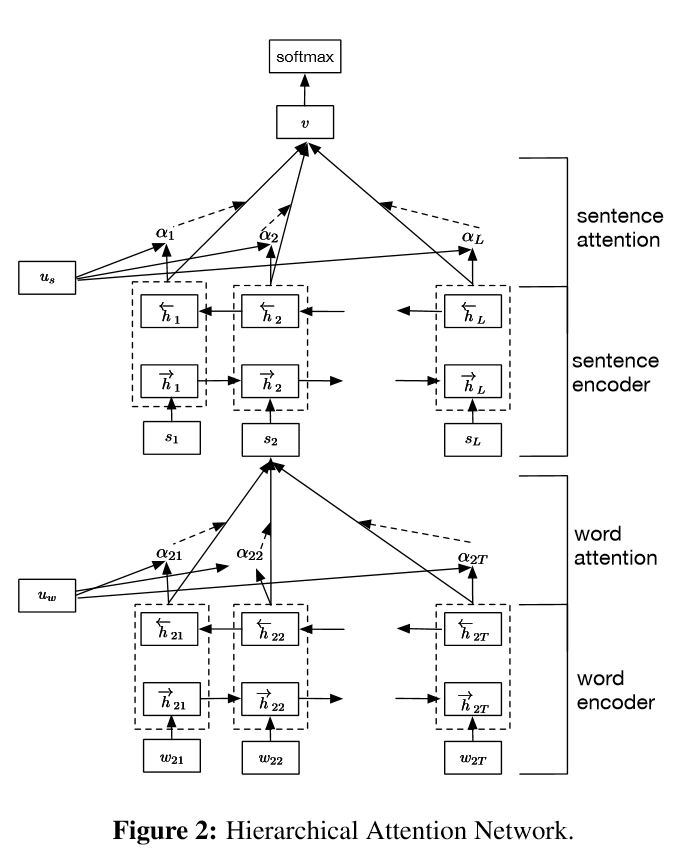
实施用于文档分类的分层注意网络
结构:
嵌入
单词编码器:单词级别的双向gru,以获取单词的丰富代表
单词注意:单词级别的关注以获取句子中的重要信息
句子编码器:句子级别的双向gru以丰富的句子代表
句子口:句子级别的关注以在句子中获得重要句子
FC+SoftMax
在NLP中,可以对单句进行文本分类,但也可以用于多个句子。我们可以称其为文档分类。单词是形式的句子。和句子是要记录的形式。在这种情况下,可能存在一种内在结构。那么,我们如何对这些任务进行建模呢?文档的所有部分是否同样相关?以及我们如何确定哪个部分比另一部分更重要?
它有两个独特的功能:
1)它具有层次结构,反映了文档的层次结构;
2)它在单词和句子级别上使用了两个级别的注意机制。它使模型能够以不同级别捕获重要信息。
单词编码器:对于句子中的每个单词,它都嵌入分布向量空间中的单词向量中。它使用双向gru来编码句子。通过来自两个方向的串联矢量,它现在可以形成句子的表示,这也可以捕获上下文信息。
单词注意:对于句子而言,相同的单词比另一个更重要。因此使用注意机制。它首先使用一层MLP来获取句子的隐藏表示形式,然后测量单词作为UIT与单词级别上下文vector uw的相似性的重要性,并通过SoftMax函数获得正常的重要性。
句子编码器:对于句子向量,双向gru用于编码它。类似于Word编码器。
句子注意:句子级向量用于衡量句子之间的重要性。类似于单词关注。
数据输入:
一般而言,此模型的输入应具有服务器句子而不是Sinle句子。形状为:[无,句子_lenght]。没有任何意思是batch_size。
在我的培训数据中,在每个示例中,我都有四个部分。每个部分的长度相同。我将四个部分围成一个句子。该模型将将句子分为四个部分,以形成形状的张量:[none,num_sentence,stone_length]。其中num_sesence是句子的数量(在我的设置中等于4)。
检查:p1_hierarchicalatetention_model.py
为了细心的关注,您可以检查专心的关注
实施SEQ2SEQ,通过共同学习对齐和翻译,从神经机器翻译中引起了人们的注意
I.结构:
1)嵌入2)Bi-Gru也从源句子(向前和向后)获得丰富的代表。 3)引起注意的解码器。
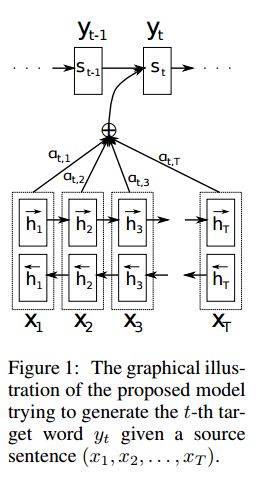
II.数据输入:
有两种输入:1)编码器输入,这是一个句子; 2)解码器输入,它是具有固定长度的标签列表; 3)目标标签,也是标签列表。
例如,标签为:“ L1 L2 L3 L4”,然后解码器输入为:[_ GO,L1,L2,L2,L2,L3,_PAD];目标标签将是:[L1,L2,L3,L3,_END,_PAD]。长度固定为6,任何超过的标签都将被捕捉,如果标签不足以填充,将垫板。
III。注意机制:
传输编码器输入列表和解码器的隐藏状态
计算隐藏状态与每个编码器输入的相似性,以获取每个编码器输入的可能性分布。
基于可能性分布的编码器输入的加权总和。
使用此权重总和与解码器输入一起使用RNN单元格,以获取新的隐藏状态
iv.如何香草编码器解码器作品:
源句子将使用RNN作为固定大小向量(“思想向量”)编码。然后在解码器中:
当训练时,将使用另一个RNN尝试通过使用此“思想向量”作为初始状态来获取一个单词,并在每个时间戳上从解码器输入中获取输入。解码器从特殊令牌“ _go”开始。执行一步后,将获得新的隐藏状态并与新输入一起,我们可以继续此过程,直到达到特殊的令牌“ _end”。我们可以通过计算横向熵损失和目标标签来计算损失。 logits通过隐藏状态的投影层获得(用于解码器步骤的输出(在GRU中,我们可以将隐藏状态使用解码器作为输出)。
测试时,没有标签。因此,我们应该为我们从以前的时间戳提供输出,并继续我们到达“ _ end”令牌的过程。
v.notices:
在这里,我使用两种词汇。一个来自词,由编码器使用;另一个用于标签,解码器使用
对于lables的词汇,我插入了三个特殊令牌:“ _ go”,“ _ end”,“ _ pad”; “ _unk”不使用,因为所有标签均已预定。
状态:它能够进行任务分类。并能够在玩具任务中生成其序列的反向顺序。您可以通过在模型中运行测试功能来检查它。检查:a2_train_classification.py(train)或a2_transformer_classification.py(型号)
我们以相相的样式进行操作。模型中还使用了降落器归一化,残留连接和掩码。
对于每个构建块,我们在下面的每个文件中都包含一个测试功能,并且我们已经成功测试了每个小部分。
序列序列序列是一个典型的模型,以解决序列产生问题,例如翻译,对话系统。大多数时候,它使用RNN作为Buidling Block来完成这些任务。 UTIT最近,人们还将卷积神经网络应用于序列问题。但是,变压器仅在注意力中心执行这些任务。它是快速的,并实现了新的最新结果。
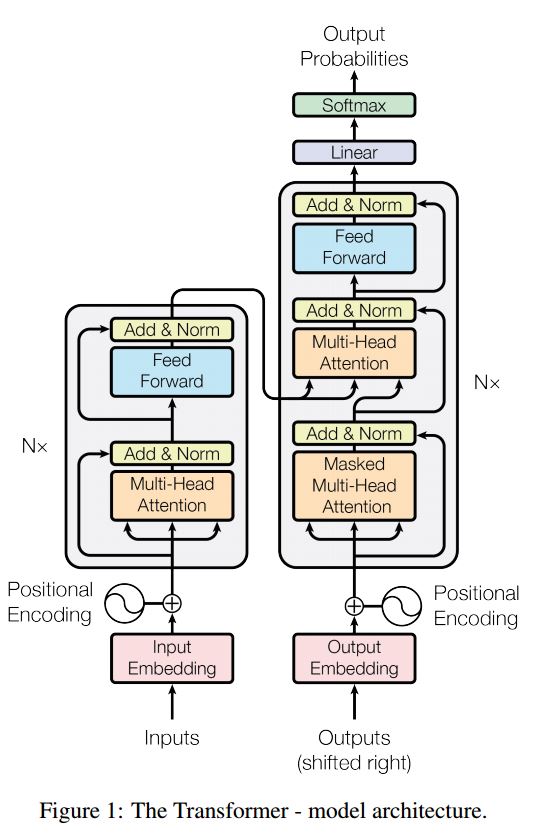
它也有两个主要部分:编码器和解码器。以下是纸上的desc:
编码器:
6层。每个层有两个子层。第一个是多头的自我注意机制。第二个是位置完全连接的前馈网络。对于每个子层。使用Layernorm(x+sublayer(x))。所有维度= 512。
解码器:
主要带走了这个模型:
使用此模型进行任务分类:
在这里,我们仅使用编码零件进行任务分类,删除了Resdiual Connection,仅使用1层。无需使用掩码。我们使用多头关注和后馈前进,以提取输入句子的特征,然后使用线性层进行投影以获取逻辑。
有关模型的详细信息,请检查:a2_transformer_classification.py
输入:1。故事:作为上下文是多语言。 2.试验:一个句子,这是一个问题,3。Ansewr:一个标签。
模型结构:
输入编码:使用单词袋来编码故事(上下文)和查询(问题);使用位置面具考虑位置
通过使用双向RNN编码故事和查询,性能从0.392提高到0.398,增加了1.5%。
动态内存:
一个。使用键的“相似性”来计算门,并带有故事输入的值。
b。通过转换每个密钥,值和输入来获取候选状态。
c。结合门和候选隐藏状态以更新当前隐藏状态。
b。使用可能性分布获得隐藏状态的加权总和。
c。查询和隐藏状态的非线性转换以获得预测标签。
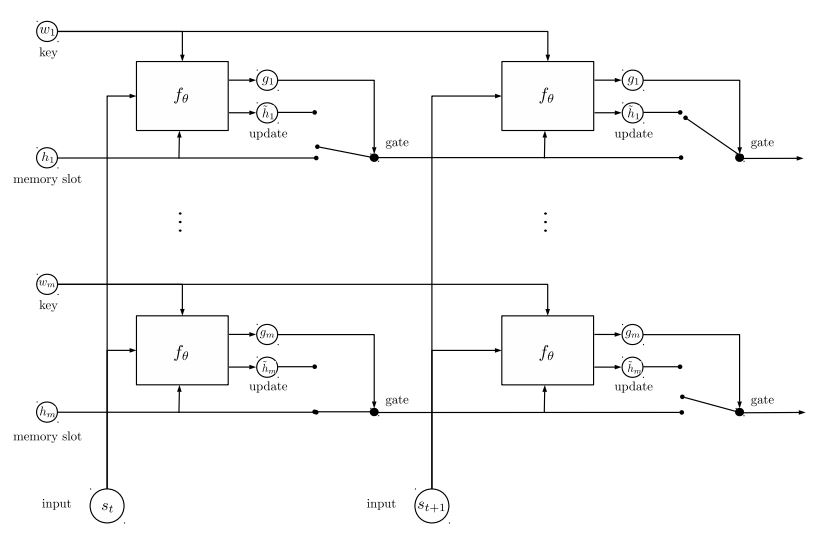
主要带走了这个模型:
使用彼此独立的键和值块。因此可以并行运行。
一起建模上下文和问题。使用记忆跟踪世界状态;并使用隐藏状态和问题(查询)的非线性转换来做出预测。
简单的模型也可以实现非常好的性能。简单的编码用作使用袋。
有关模型的详细信息,请检查:a3_entity_network.py
在此模型下,它具有一个测试功能,该功能要求该模型计算故事(上下文)和查询(问题)的数字。但是故事的重量比查询小。
模型的前景:
1.输入模块:将原始文本编码为向量表示
2.问题模块:编码问题到向量表示
3. episodic内存模块:使用输入,它选择了通过注意机制重点关注的输入的哪些部分,考虑到问题和先前的内存=====>它使“内存” vecotr调整。
4.答案模块:从最终内存向量生成答案。
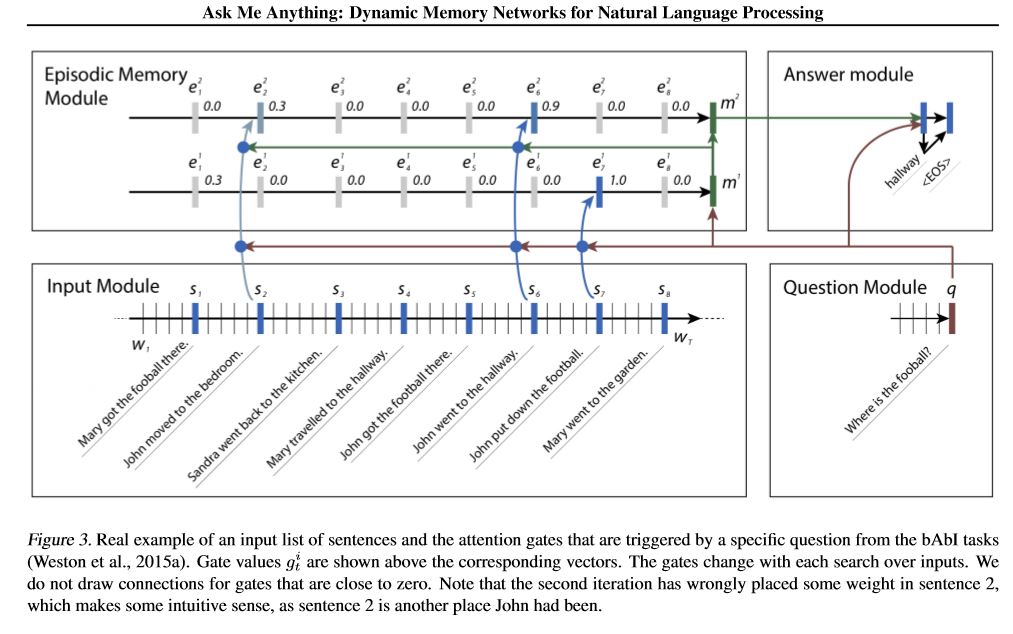
细节:
1.输入模块:
A.single句子:使用Gru获取隐藏状态B.句子列表:使用Gru为每个句子获取隐藏状态。例如[隐藏状态1,隐藏状态2,隐藏状态...,隐藏状态N]
2.问题模块:使用gru获得隐藏状态
3. Episodic内存模块:
使用注意机制和经常性网络来更新其内存。
一个。门作为注意机制:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B.内存更新机制:采用候选句子,门和以前的隐藏状态,它使用封闭式gu来更新隐藏状态。喜欢:h = f(c,h_previous,g)。最终隐藏状态是答案模块的输入。
C.需要多个情节===>及时推理。
例如,问足球在哪里?它将参加“约翰放下足球”的判决),然后在第二次通过,需要参加约翰的位置。
4.答案模块:采用最终的epoidic内存,问题,它更新隐藏的答案模块状态。
1.字符级卷积网络用于文本分类
2.跨文本分类的卷积神经网络:浅词级与深角色级别
3.文本分类的深度卷积网络
4.半监督文本分类的对流培训方法
5.启用模型
在进行大规模多标签分类的过程中,已经学习了服务器课程,以及某些列表如下:
达到高精度的最重要的是什么?这取决于您正在执行的任务。从我们在这里执行的任务中,我们认为基于从多个功能,字符和描述字符的多个功能训练的模型的集合模型可以帮助达到很高的Accuarcy;但是,在某些情况下,正如Alphago Zero所证明的那样,算法比数据或计算能力更重要,实际上Alphago Zero没有使用任何Humam数据。
是否有任何特定模型或算法的天花板?答案是肯定的。这里使用了许多不同的模型,我们发现许多模型具有相似的性能,即使结构有很大不同。在某种程度上,性能的差异并不大。
错误的案例研究有用吗?我认为这非常有用,尤其是当您做了许多不同的事情时,但是达到了限制。例如,通过进行案例研究,您可以找到模型可以做出正确预测以及它们犯错误的标签。并通过增加这些错误的预测标签的权重或从数据中找到潜在错误来提高性能。
我们如何成为机器学习特定的专家?我认为,加入机器学习竞争对手或使用大量数据开始任务,然后阅读论文并实施一些是一个很好的起点。因此,我们将有一些真正的经验和思想来处理特定任务,并知道它的挑战。但是,更重要的是,我们不仅应该遵循论文的想法,而且应该探索一些我们认为可能有助于解决这个问题的新想法。例如,通过更改经典模型的结构,甚至发明了一些新的结构,我们可能能够以更好的方式解决问题,因为它可能更适合我们正在执行的任务。
1.有效文本分类的技巧
2.验证神经网络用于句子分类
3.(以及实践指南)卷积神经网络的敏感性分析句子分类
4.聊天机器人的深度学习,第2部分 - 从www.wildml.com中实现基于检索的模型
5.文本分类的卷积卷积神经网络
6.文档分类的层次结构注意网络
7.神经机器翻译通过共同学习对齐和翻译
8.注意是您需要的
9.掩盖我任何东西:自然语言处理的动态记忆网络
10.通过经常性实体网络跟踪世界状态
11.从模型库中选择
12.Bert:深层双向变压器的预训练以了解语言理解
13.Google-Research/Bert
待续。对于任何问题,conbat [email protected]


