text_classification
1.0.0
Цель этого хранилища - изучить методы классификации текста в НЛП с глубоким обучением.
Настройте API NLP за три минуты бесплатно: DEMO NLP API
Изуменный эталон оценки для китайского (Clue Benchmark): запустите 10 задач и 9 базовых линий с одной линией кода, сравнение производительности с деталями.
Выпуск предварительно обученной модели обучения Albert_chinese с 30G+ сырым китайским корпусом, XXLARGE, XLARGE и многим другим, Target, чтобы соответствовать состоянию художественных результатов на китайском языке, 2019-октябрь-7, в Национальный день Китая!
Большое количество китайского корпуса для NLP доступно!
Google BERT достиг нового результата современности в более чем 10 задачах в NLP с использованием Pre-Train in Language Model Then Then Then
тонкая настройка. Pre-Train Texcnn: Идея от BERT для понимания языка с использованием кода и набора данных
У этого есть все виды базовых моделей для классификации текста.
Он также поддерживает многоупонентную классификацию, в которой много меток ассоциируются с предложением или документом.
Хотя многие из этих моделей просты и могут не довести вас до верхнего уровня задачи. Но некоторые из этих моделей очень
Классика, поэтому они могут быть хороши, чтобы служить базовыми моделями. Каждая модель имеет тестовую функцию под классом модели. Вы можете бежать
Это на работу в исполнение игрушек в первую очередь. Модель не зависит от набора данных.
Проверьте здесь формальный отчет о крупномасштабной классификации текста с глубоким обучением
Несколько моделей здесь также можно использовать для моделирования ответа на вопросы (с или без контекста) или для создания последовательностей.
Мы исследуем две модели SEQ2SEQ (SEQ2SEQ с вниманием, трансформатор-это все, что вам нужно) для выполнения текстовой классификации.
И эти две модели также могут использоваться для последовательностей, генерирующих и других задач. Если ваша задача-многоцелевая классификация,
Вы можете подчеркнуть проблему на создание последовательностей.
Мы реализуем две сеть памяти. Одним из них является динамическая сеть памяти. Ранее он достиг современного искусства
Ответ, анализ настроений и задачи генерации последовательности. Это так называется одной моделью для выполнения нескольких разных задач,
и достичь высокой производительности. У него четыре модуля. Ключевым компонентом является эпизодический модуль памяти. он использует механизм затвора, чтобы
производительность внимания, и используйте закрытый GRU для обновления памяти эпизода, затем у него есть еще один GRU (в вертикальном направлении), чтобы
Производительность скрытого государственного обновления. Он способен делать переходные выводы.
Вторая сеть памяти, которую мы реализовали, - это рецидивирующая сеть объектов: отслеживание состояния мира. У него есть блоки
Ключевые значения пары как память, работающие параллельно, которые достигают нового состояния искусства. Это можно использовать для моделирования вопросов
отвечая на контексты (или историю). Например, вы можете позволить модели прочитать некоторые предложения (как контекст) и спросить
Вопрос (как запрос), затем попросите модель предсказать ответ; Если вы пидете историю, такую же, как запрос, то это может сделать
Задача классификации.
Чтобы обсудить проблемы ML/DL/NLP и получить техническую поддержку друг от друга, вы можете присоединиться к QQ Group: 836811304
Фасттекст
TextCnn
Берт: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка
Textrnn
Rcnn
Иерархическая сеть внимания
seq2seq с вниманием
Трансформер («Посещение - это все, что вам нужно»)
Динамическая сеть памяти
EntityNetwork: состояние мира мира
Ансамблевые модели
Повышение:
Для одной модели стекайте идентичные модели вместе. Каждый слой является моделью. Результат будет основан на Logits, которые добавлены вместе. Единственной связи между слоями являются веса метки. Скорость ошибок прогнозирования предсказания переднего слоя на каждой метке станет весом для следующих слоев. Эти этикетки с высоким уровнем ошибок будут иметь большой вес. Таким образом, более поздние слоя будут уделять больше внимания этим неправильному лейблам и попытаться исправить предыдущую ошибку прежнего слоя. В результате мы получим гораздо сильную модель. Проверьте a00_boosting/boosting.py
и другие модели:
Bilstmtextrelation;
Twocntextrelation;
BilstmtextrelationTwornn
(Задача прогнозирования метки Mulit-Label, попросите предсказать TOP5, 3 миллиона учебных данных, полная оценка: 0,5)
| Модель | Фасттекст | TextCnn | Textrnn | Rcnn | Hierattenet | Seq2seqattn | EntityNet | Динамикемемория | Трансформатор |
|---|---|---|---|---|---|---|---|---|---|
| Счет | 0,362 | 0,405 | 0,358 | 0,395 | 0,398 | 0,322 | 0,400 | 0,392 | 0,322 |
| Обучение | 10 м | 2H | 10 часов | 2H | 2H | 3 часа | 3 часа | 5 часов | 7 часов |
Bert Model достигает 0,368 после первой 9 эпохи из набора валидации.
Ансамбль TextCnn, EntityNet, DynamicMemory: 0,411
Ensemble EntityNet, DynamicMemory: 0,403
Уведомление:
m стоять на минуты ; h стоять на часы ;
HierAtteNet означает иерархическое внимание сетик;
Seq2seqAttn означает seq2seq с вниманием;
DynamicMemory означает DynamicMemoryNetwork;
Transformer подходит для модели от «внимания - это все, что вам нужно».
xxx_model.pyxxx_train.py , чтобы тренировать модельxxx_predict.py , чтобы сделать вывод (тест).Каждая модель имеет метод испытаний в классе модели. Вы можете сначала запустить метод испытания, чтобы проверить, может ли модель работать должным образом.
Python 2.7+ Tensorflow 1.8
(TensorFlow от 1,1 до 1.13 также должен работать; большинство моделей также должны работать в другой версии TensorFlow, поскольку мы
Используйте очень мало функций Bond с определенной версией.
Если вы используете Python3, все будет хорошо, если вы измените функцию Print/Try Catch на случай, если вы выполните любую ошибку.
Модель TextCnn уже перенесена на Python 3.6
Чтобы помочь вам запустить этот репозиторий, в настоящее время мы переоцениваем обучение/проверку/тестовые данные и словарь/лейблы и сохранили
их как кэш -файл с помощью H5Py. Мы предлагаем вам загрузить его по ссылке.
Он содержит все, что вам нужно для запуска этого репозитория: данные предварительно обработаны, вы можете начать тренировать модель через минуту.
Это zip -файл около 1,8 г, содержит 3 миллиона данных обучения. Хотя после повреждения он довольно большой, но с помощью
HDF5, он нуждается только в нормальном размере памяти компьютера (EG8 g или меньше) во время обучения.
Мы используем ноутбук Jupyter: предварительный обработка. Вы можете лучше понять эту задачу и
Данные, взглянув на это. Вы также можете создавать данные самостоятельно так, как вы хотите, просто изменить несколько строк кода
Использование этой ноутбука Юпитера.
Если вы хотите попробовать модель сейчас, вы можете загрузить кэшированный файл из выше, а затем перейдите в папку 'A02_TextCnn', запустите
python p7_TextCNN_train.py
Он будет использовать данные из кэшированных файлов для обучения модели, и периодически распечатать потерю и оценку F1.
Старый образцовой источник данных: если вам нужны некоторые образцы данных и встроение слов, проведенное на Word2VEC, вы можете найти их в закрытых вопросах, таких как: Выпуск 3.
Вы также можете найти несколько образцов данных в папке «Данные». Он содержит два файла: 'sample_single_label.txt', содержит данные 50 тыс.
с единственной меткой; 'sample_multiple_label.txt', содержит 20K данных с несколькими метками. Ввод и метка отдельно по « метке ».
Если вы хотите узнать более подробно о наборе данных классификации текста или задачи, эти модели могут быть использованы, один из выбора ниже:
https://biendata.com/competition/zhihu/
Один из способов использовать этот репозиторий:
Шаг 1: Вы можете прочитать эту статью. Вы получите общее представление о различных классических моделях, используемых для выполнения текстовой классификации.
Шаг 2: Предварительные данные и/или кэшированный файл загрузки.
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
Шаг 3: Запустите список моделей здесь, и измените некоторые коды и конфигурации, как вы хотите, чтобы получить хорошую производительность.
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
Кроме того, напишите свою статью об этой теме, вы можете следить за стилем бумаги, чтобы написать. Вам может потребоваться прочитать несколько документов
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
Замените данные в 'data/sample_multiple_label.txt' и убедитесь, что формат, как ниже:
'Word1 Word2 Word3 __label__l1 __label__l2 __label__l3'
где часть 1: 'Word1 Word2 Word3' - это ввод (x), часть 2: '__label__l1 __label__l2 __label__l3'
Представляя три метки: [L1, L2, L3]. Между части1 и частью 2 должна быть пустая строка: ''.
Например: каждая строка (несколько меток) нравится:
W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __LABEL__56266661657638855119 __LABEL__49217938334638855119 __LABEL__49217938334668855119 __LABEL__49217930534666885119 __LABEL__4921793053466688585119 __LABEL__ __label__89047355555009151318 '
где '56266616576388855119', '4921793805334628695' , '8904735555009151318' - три метки, связанные с этой входной строкой 'W5466 W138990 ... C699 C317 C184
Уведомление:
Некоторая функция UTIL находится в data_util.py; Проверьте LOAD_DATA_MULTILABEL () DATA_UTIL для того, как вход и метки процесса из необработанных данных.
Существует функция для загрузки и назначения предварительного встраивания слов в модель, где встроение слов предварительно предварительно проведено в Word2VEC или FastText.
Если Word2vec.load не работает, вы можете загрузить предварительно предварительно встраиваемое слово, особенно для китайского встраивания слова. Использование следующих строк:
Импорт Генсим
от gensim.models import -keyedvectors
word2vec_model = keyedvectors.load_word2vec_format (word2vec_model_path, binary = true, unicode_errors = 'игнорировать') #
Или вы можете отключить использование флага встроенного слова предварительного слова, чтобы отключить загрузку слов.
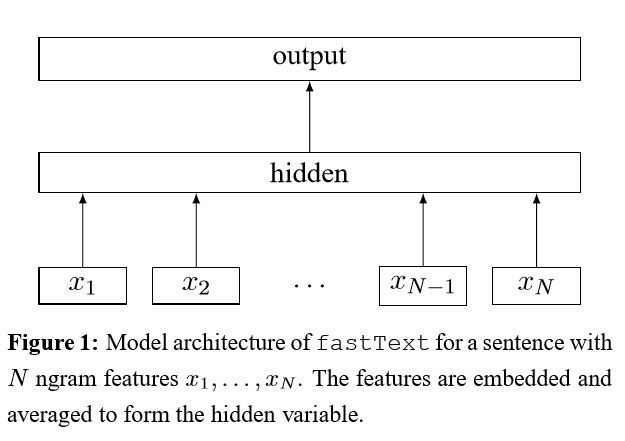
Уменьшение мешка с уловкой для эффективной классификации текста
После встраивания каждого слова в предложение это представления слова затем усредняются в текстовое представление, которое, в свою очередь, подается в линейный классификатор. Затем для вычисления потерь используется поперечная энтропия. Мешок с представлением слов не учитывает порядок слов. Чтобы принять во внимание заказ Word, N-граммовые функции используются для получения некоторой частичной информации о локальном порядке слов; Когда количество классов большое, вычисление линейного классификатора является вычислительным дорогостоящим. Таким образом, он использует Hierarchical Softmax для ускорения процесса обучения.
Результат: производительность так же хороша, как бумага, скорость также очень быстрая.
Проверьте: p5_fasttextb_model.py
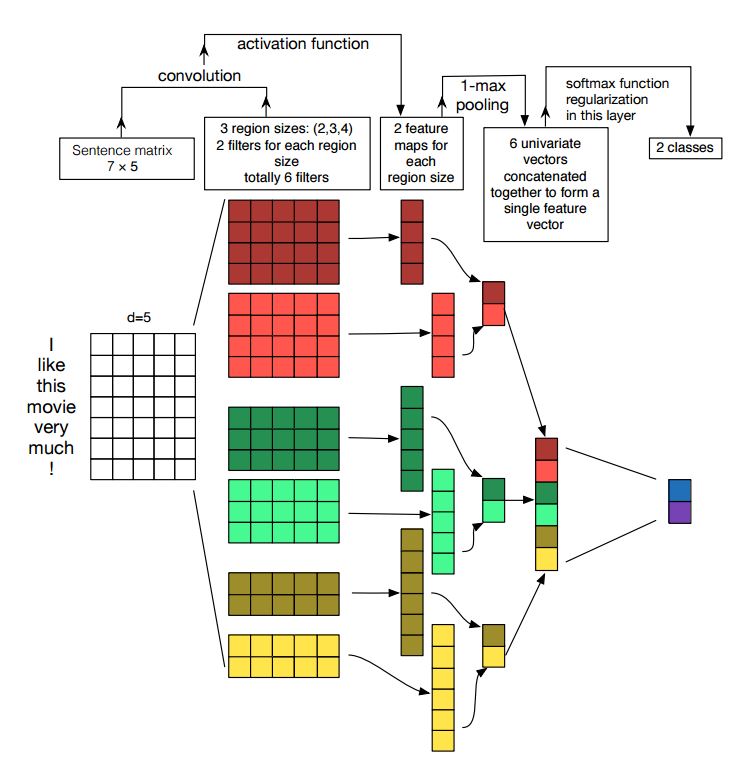
Внедрение сверточных нейронных сетей для классификации предложений
Структура: Encedding ---> conv ---> Max Pooling ---> Полностью подключенный слой --------> Softmax
Проверьте: p7_textcnn_model.py
Чтобы получить очень хороший результат с TextCnn, вам также необходимо тщательно прочитать об этом документе анализ чувствительности (и руководства по практике к) сверточных нейронных сетей для классификации предложений: это дает вам некоторое представление о вещах, которые могут повлиять на производительность. Хотя вам нужно изменить некоторые настройки в соответствии с вашей конкретной задачей.
Свожденная нейронная сеть является основной строительной коробкой для решения проблем компьютерного зрения. Теперь мы покажем, как CNN можно использовать для NLP, в частности, классификации текста. Длина предложения будет отличаться от одного к другому. Таким образом, мы будем использовать PAD, чтобы получить фиксированную длину, n. Для каждого токена в предложении мы будем использовать Word Encding для получения вектора фиксированного измерения, d. Таким образом, наш вход-2-мерная матрица: (N, D). Это похоже на изображение для CNN.
Во -первых, мы будем выполнять свертку с нашим входом. Это элементарное умножение между фильтром и частью ввода. Мы используем k Количество фильтров, каждый размер фильтра представляет собой двухмерную матрицу (F, D). Теперь вывод будет k Количество списков. Каждый список имеет длину N-F+1. Каждый элемент скаляр. Обратите внимание, что второе измерение всегда будет измерением встроенного слова. Мы используем различный размер фильтров, чтобы получить богатые функции от текстовых входов. И это что-то похожее с функциями N-грамма.
Во -вторых, мы сделаем максимальное объединение для вывода сверточной операции. Для k количество списков мы получим k количества скаляров.
В -третьих, мы будем объединять скаляры, чтобы сформировать окончательные функции. Это вектор фиксированного размера. И он не зависит от размера фильтров, которые мы используем.
Наконец, мы будем использовать линейный слой, чтобы проецировать эти функции на для каждого определенных меток.
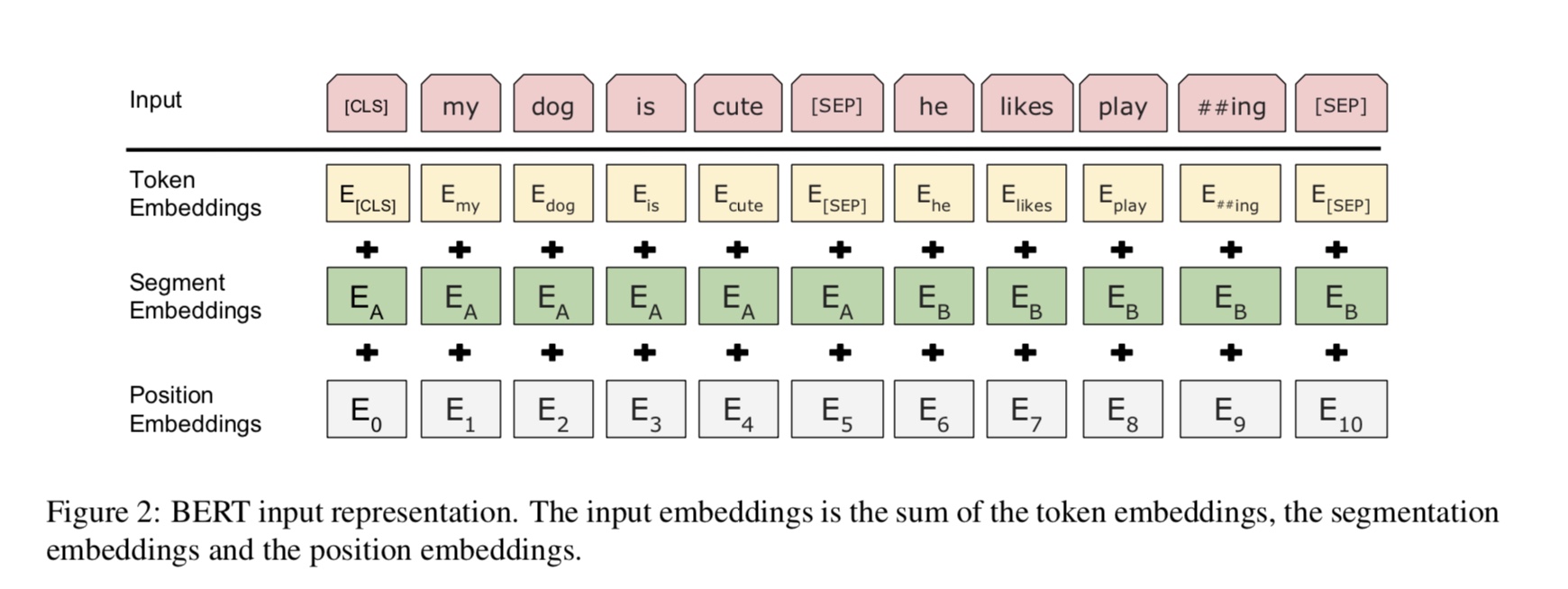
В настоящее время Берт достигает современных результатов по более чем 10 задачам NLP. Ключевые идеи этой модели заключаются в том, что мы можем
Предварительно обучить модель, используя один вид языковой модели с огромным количеством необработанных данных, где вы можете легко ее найти.
Поскольку большинство параметров модели предварительно обучены, только последний слой для классификатора необходим для различных задач.
В результате эта модель общая и очень мощная. Вы можете просто настраивать на основе предварительно обученной модели внутри
короткий период времени.
Тем не менее, эта модель довольно большая. С длиной последовательности 128 вы можете тренироваться только с размером партии 32; надолго
Документ, такой как длина последовательности 512, он может тренировать размер партии 4 для нормального графического процессора (с 11G); и очень немногие люди
может предварительно подготовить эту модель с нуля, так как на тренировку требуется много дней или недель, а память обычного графического процессора слишком мала
для этой модели.
Специально, модель основы - это трансформатор, где вы можете найти его в внимании - все, что вам нужно. Он использует два вида
Задачи, чтобы предварительно обучать модель.
Вообще говоря, учитывая предложение, некоторый процент слов замаскирован, вам нужно будет предсказать слова маскированных
на основе этого предложения в масках. Слова в масках выбираются случайным образом.
Мы кормим вход через глубокий трансформированный энкодер, а затем используем конечные скрытые состояния, соответствующие маске
Позиции, чтобы предсказать, какое слово было замаскировано, точно так же, как мы будем обучать языковую модель.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Много языкового понимания задачи, например, ответ на вопрос, вывод, нужно понимать отношения
между предложением. Тем не менее, языковая модель может понимать только без предложения. Следующее предложение
Прогнозирование - это пример задачи, чтобы помочь модели лучше понять в этих видах задачи.
50% случайности второе предложение - следующее предложение первого, 50% от не следующего.
Учитывая два предложения, модель просят предсказать, является ли второе предложение реальным следующим предложением
первый.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
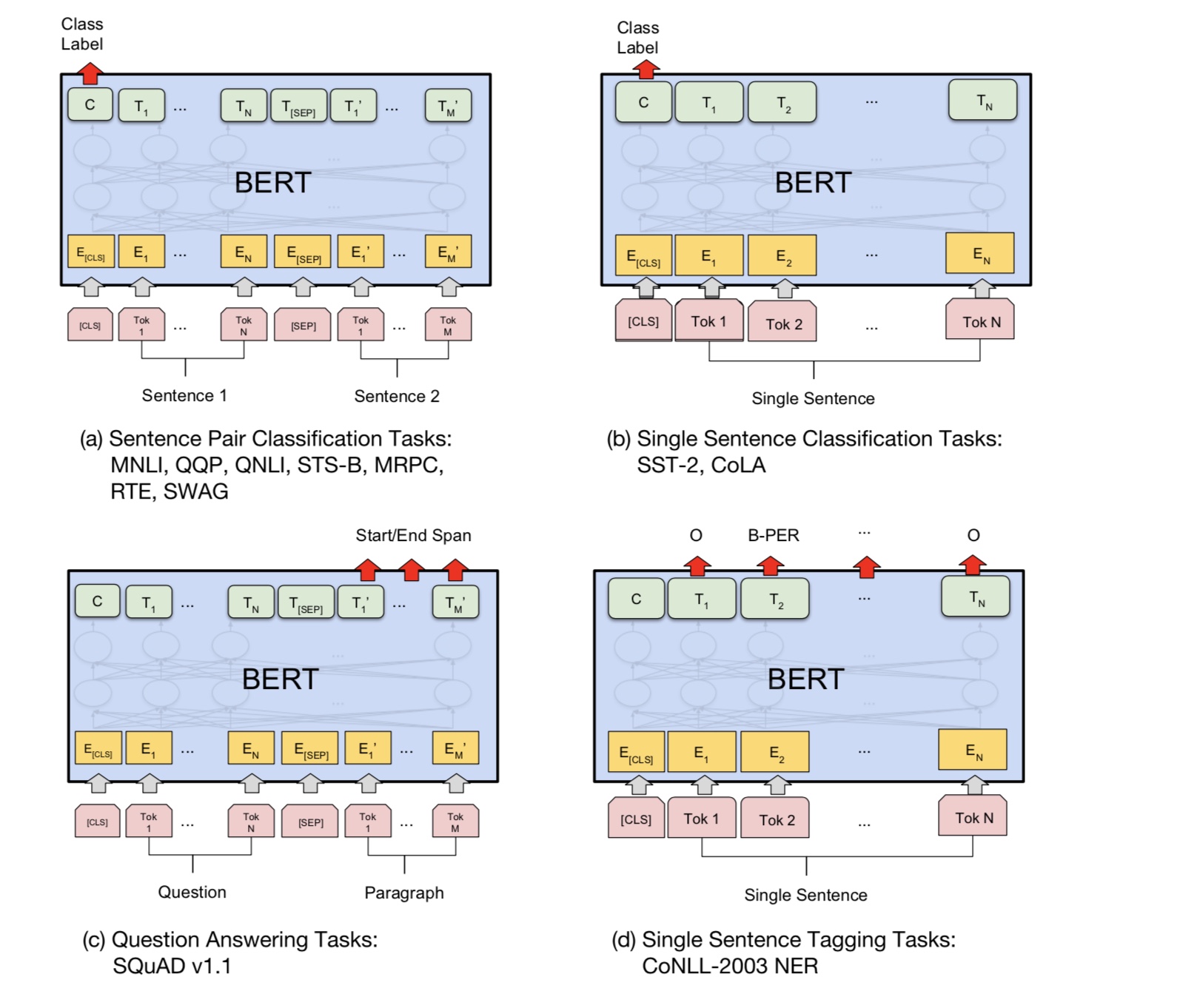
По сути, вы можете скачать предварительно обученную модель, может просто настраивать вашу задачу с помощью собственных данных.
Для задачи классификации вы можете добавить процессор для определения формата, который вы хотите, чтобы ввод и метки из исходных данных.
Запустите следующую команду под папкой A00_BERT:
python train_bert_multi-label.py
Он достигает 0,368 после 9 эпохи. Или вы можете запустить многоучанную классификацию с загружаемыми данными, используя Bert от
Spearing_analysis_fine_grain с Bert
Вы можете использовать стиль сеанса и корма для восстановления модели и данных о подаче корпокций, а затем получить логиты, чтобы сделать онлайн -прогноз.
Онлайн -прогноз с Бертом
Первоначально он обучает или оценивает модель на основе файла, а не для онлайн.
Во-первых, вы можете использовать предварительно обученную загрузку модели из Google. Запустите несколько эпох на вашем наборе данных и найдите подходящее
Длина последовательности.
Во-вторых, вы можете предварительно пробудить базовую модель в своих собственных данных, если вы можете найти набор данных, который связан с
Ваша задача, а затем настраивать вашу конкретную задачу.
В -третьих, вы можете изменить функцию потерь и последний слой, чтобы лучше соответствовать вашей задаче.
Кроме того, вы можете добавить определение некоторых предварительно обученных задач, которые помогут модели понять вашу задачу намного лучше.
Как и опыт, мы получили от экспериментов, предварительно обученная задача не зависит от модели, а предварительный тренировки не ограничивается
задачи выше.
Структура v1: внедрение ---> двунаправленное LSTM ---> Выход CONCAT ---> Средний -----> SoftMax Layer
Проверьте: p8_textrnn_model.py
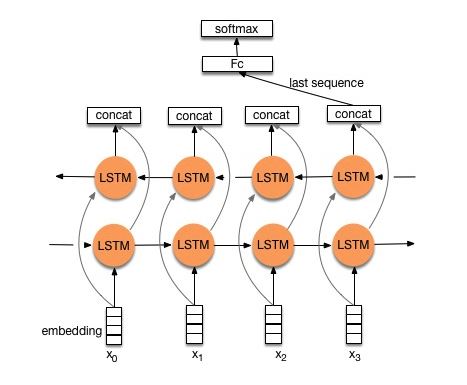
Структура v2: внедрение-> двунаправленное LSTM ----> Отступие-> CONCAT OUPUL ---> LSTM ---> DROPUT-> FC Layer-> SoftMax Layer
Проверьте: p8_textrnn_model_multilayer.py
Структура такая же, как Textrnn. Но ввод специально разработан. Эгинпут: «Сколько стоит компьютер? Цена на ноутбук». где «EOS» - это особый токен, избитый вопросом1 и вопросом2.
Проверьте: p9_bilstmtextrelation_model.py
Структура: сначала используйте два разных сверточных для извлечения функции двух предложений. Затем соберите две функции. Используйте слой линейного преобразования, чтобы вывести проекцию для целевой метки, затем Softmax.
Проверьте: p9_twocnntextrelation_model.py
Структура: один двунаправленный LSTM для одного предложения (Get Output1), еще один двунаправленный LSTM для другого предложения (Get Output2). Тогда: Softmax (выход1 мн выход2)
Проверьте: P9_BILSTMTEXTRELATIONTWORNN_MODEL.PY
Для получения более подробной информации вы можете перейти: глубокое обучение для чат-ботов, часть 2-Реализация модели на основе поиска в Tensorflow
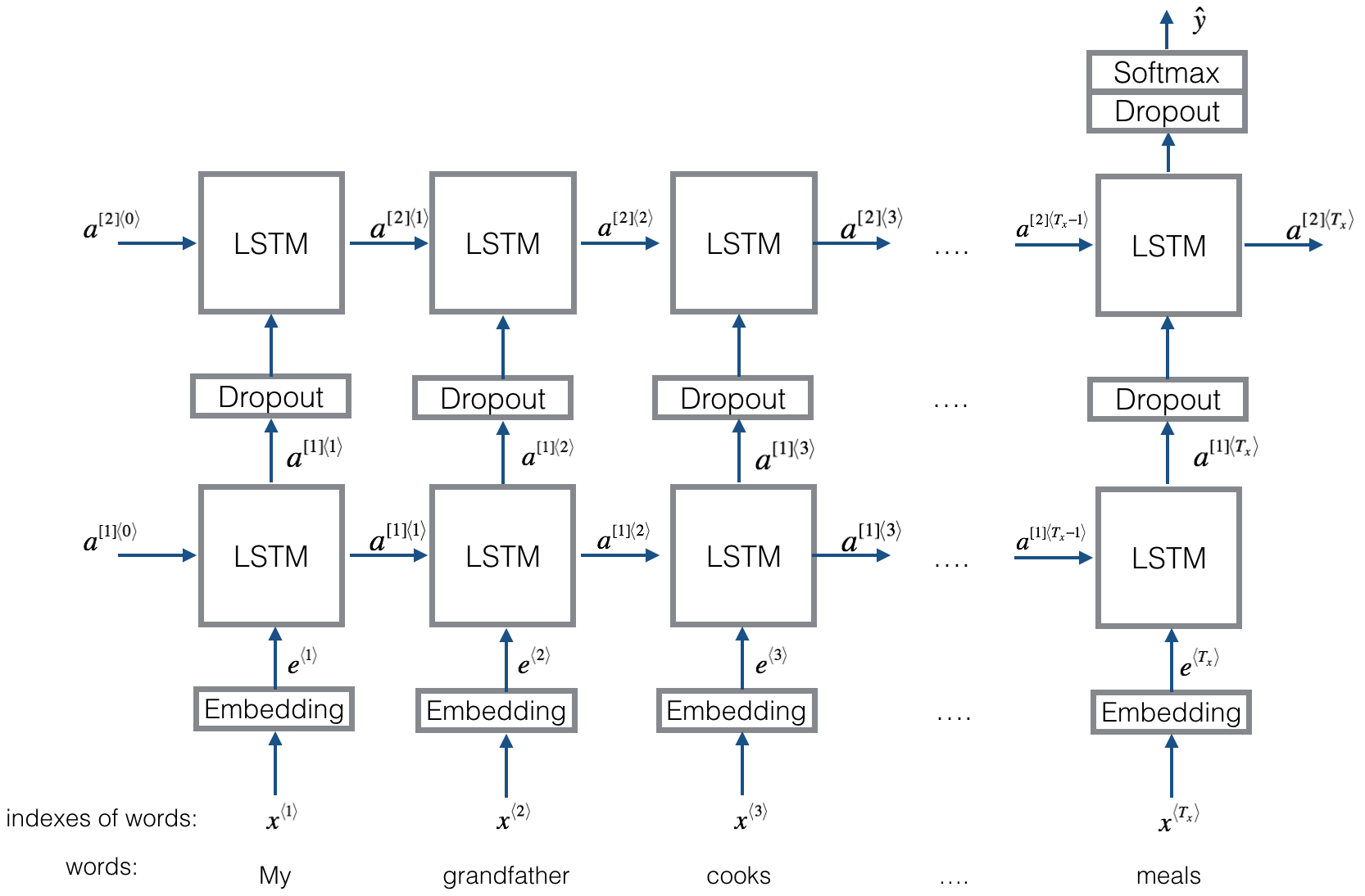
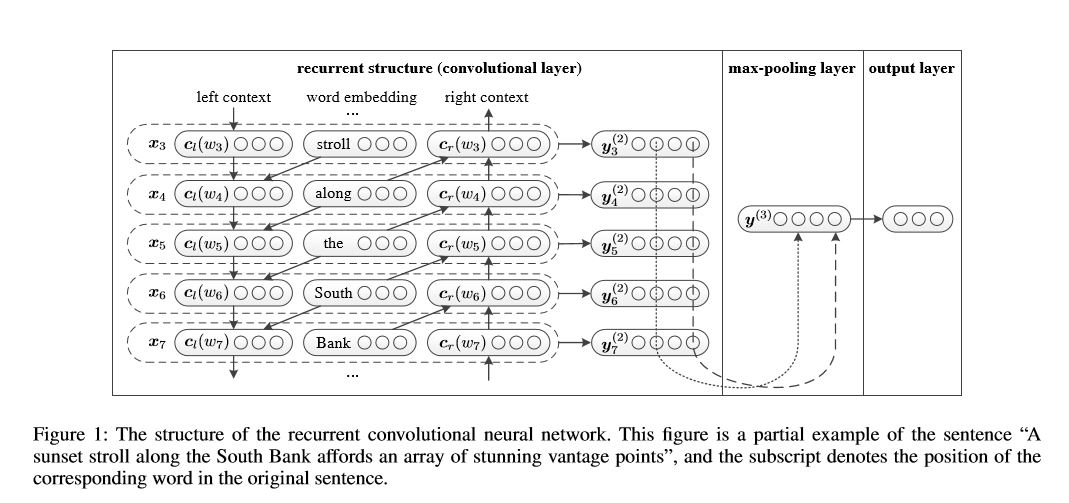
Повторяющаяся сверточная нейронная сеть для классификации текста
Внедрение повторяющейся сверточной нейронной сети для классификации текста
Структура: 1) рецидивирующая структура (сверточный слой) 2) максимальный пул 3) Полностью соединенный слой+softmax
Он изучает представление каждого слова в предложении или документе с контекстом левой стороны и правой стороной:
Представление Текущее слово = [LEATE_SIDE_CONTEXT_VECTOR, current_word_embedding, right_side_context_vecotor].
Для контекста левой стороны он использует рецидивирующую структуру, нелинейность транс-стрма предыдущего слова и левой стороны предыдущего контекста; Аналогично контексту правой стороны.
Проверьте: p71_textrcnn_model.py
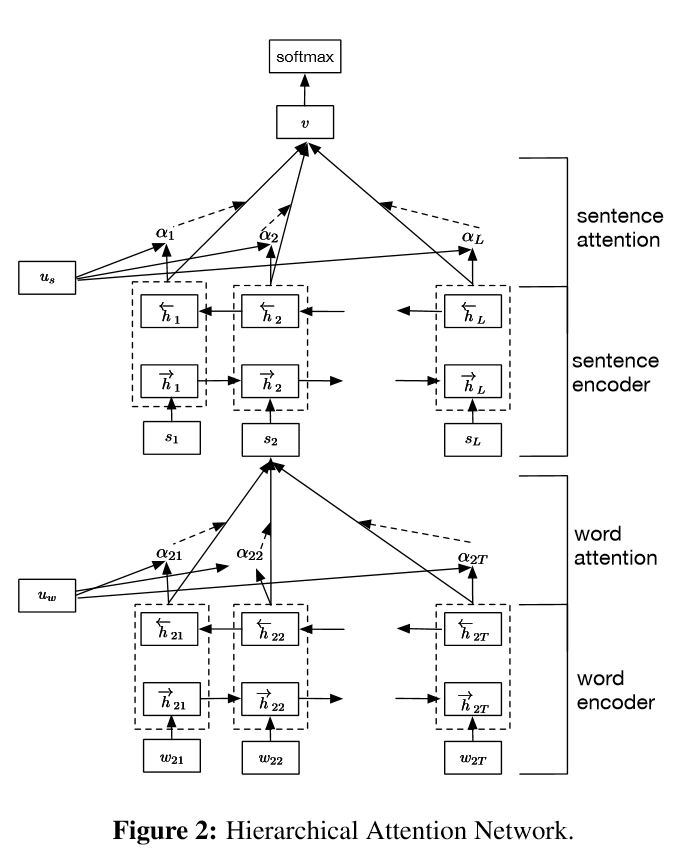
Внедрение иерархических сетей внимания для классификации документов
Структура:
внедрение
Слово энкодер: Уровень слов BI-направление GRU, чтобы получить богатое представление слов
Слово Внимание: Уровень слов Внимание, чтобы получить важную информацию в предложении
Кодер предложения: уровень предложений Bi-направленный GRU, чтобы получить богатое представление предложений.
Признание: Уровень приговора Внимание, чтобы получить важное предложение среди предложений
FC+Softmax
В NLP классификация текста может быть выполнена для единого предложения, но ее также можно использовать для нескольких предложений. Мы можем назвать это классификацией документов. Слова являются формой для предложения. И предложение является формой для документирования. В этом случае может существует внутренняя структура. Итак, как мы можем моделировать такую задачу? Все части документа одинаково актуальны? И как мы определяем, какая часть важнее другой?
Он имеет две уникальные функции:
1) он имеет иерархическую структуру, которая отражает иерархическую структуру документов;
2) Он имеет два уровня механизмов внимания, используемых на уровне слова и уровня предложения. Это позволяет модели захватить важную информацию на разных уровнях.
Word Encoder: для каждого слова в предложении он включен в вектор слов в векторное пространство распределения. Он использует двунаправленный GRU, чтобы кодировать предложение. С помощью конкатенатного вектора с двух направлений, теперь он может сформировать представление предложения, которое также отражает контекстную информацию.
Внимание слова: те же слова важнее другого для предложения. Таким образом, механизм внимания используется. Сначала он использует один слой MLP, чтобы получить скрытое представление предложения UIT, а затем измерить важность слова как сходства UIT с вектором контекста слова UW и получает нормализованную важность с помощью функции SoftMax.
Предложение Encoder: для векторов предложения, двунаправленный GRU используется для его кодирования. Аналогично Word Encoder.
Внимание предложения: вектор уровня предложения используется для измерения важности среди предложений. Аналогично слову внимания.
Ввод данных:
Вообще говоря, ввод этой модели должен иметь серверы, а не предложения Sinle. Форма: [нет, предложение_колт]. где никто не означает batch_size.
В моих учебных данных, для каждого примера у меня есть четыре части. Каждая часть имеет одинаковую длину. Я объединяю четыре части, чтобы сформировать одно предложение. Модель разделяет предложение на четыре части, чтобы сформировать тензор с формой: [нет, num_sentence, predence_length]. где num_sentence - это количество предложений (равное 4, в моем настройке).
Проверьте: p1_hierarchicalattention_model.py
Для внимательного внимания вы можете проверить внимательное внимание
Реализация SEQ2SEQ с вниманием, полученным от перевода нейронной машины путем совместного обучения для выравнивания и перевода
I. Структура:
1) Внедрение 2) Bi-Gru также получите богатое представление из исходных предложений (вперед и назад). 3) Декодер с вниманием.
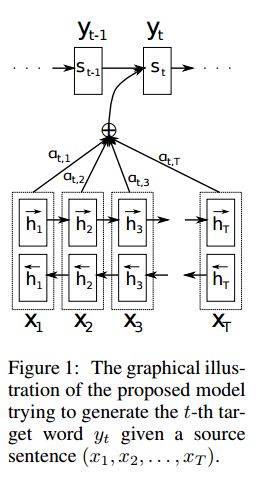
II.INPUT данных:
Есть два вида трех видов входов: 1) входы энкодера, которые являются предложением; 2) Входы декодера, это список меток с фиксированной длиной; 3) целевые этикетки, это также список метков.
Например, этикетки: «L1 L2 L3 L4», тогда входные входы будут: [_ Go, L1, L2, L2, L3, _PAD]; Целевая метка будет: [L1, L2, L3, L3, _end, _pad]. Длина установлена до 6, любые этикетки превышения будут транслированы, будут провалиться, если этикетка недостаточно для заполнения.
III. Механизм присмотра:
Список ввода энкодера передачи и скрытое состояние декодера
Рассчитайте сходство скрытого состояния с каждым входом энкодера, чтобы получить распределение возможностей для каждого ввода энкодера.
взвешенная сумма ввода энкодера на основе распределения возможностей.
Идите, хотя ячейка RNN с использованием этой суммы веса вместе с входом декодера, чтобы получить новое скрытое состояние
Iv. Как работает декодер ванильного энкодера:
Предложение источника будет закодироваться с использованием RNN в качестве вектора фиксированного размера («вектор мысли»). Затем во время декодера:
Когда он тренируется, другой RNN будет использован, чтобы попытаться получить слово, используя этот «вектор мысли» в качестве состояния init, и принять ввод от ввода декодера на каждой метке времени. Декодер начинается с специального токена "_go". После того, как один шаг будет выполнен, новое скрытое состояние будет получено и вместе с новым вводом, мы можем продолжить этот процесс, пока не дойдем до специального токена «_END». Мы можем рассчитать потерю путем вычисления потери поперечной энтропии логитов и целевой метки. Logits - это проецируемый слой для скрытого состояния (для вывода шага декодера (в Gru мы можем просто использовать скрытые состояния от декодера в качестве вывода).
Когда он тестирует, на этикетке нет. Таким образом, мы должны подавать вывод, который мы получаем с предыдущей метки времени, и продолжить утилит процесса, который мы достигли «_END».
V.notices:
Здесь я использую два вида словари. один из слов, используемый энкодером; другой для ярлыков, используемых декодером
Для словарного запаса лихеры я вставляю три специальных токена: «_ Go», «_ End», «_ Pad»; «_Unk» не используется, поскольку все этикетки предварительно определен.
Статус: он смог выполнить классификацию задач. и способен генерировать обратный порядок своих последовательностей в задаче игрушки. Вы можете проверить это, запустив функцию тестирования в модели. Проверка: a2_train_classification.py (train) или a2_transformer_classification.py (модель)
Мы делаем это в стиле Parallell. Нормализация, остаточная связь и маска также используются в модели.
Для каждого строительного блока мы включаем тестовую функцию в каждый файл ниже, и мы успешно проверяем каждый маленький кусочек.
Последовательность к последовательности с вниманием является типичной моделью для решения задачи генерации последовательностей, такой как трансляция, система диалога. Большую часть времени он использует RNN в качестве блок -блока для выполнения этих задач. UTIL Недавно люди также применяют сверточную нейронную сеть для последовательности к проблеме последовательности. Трансформатор, однако, выполняет эти задачи исключительно на Mechansim. Это быстро и достигает нового современного результата.
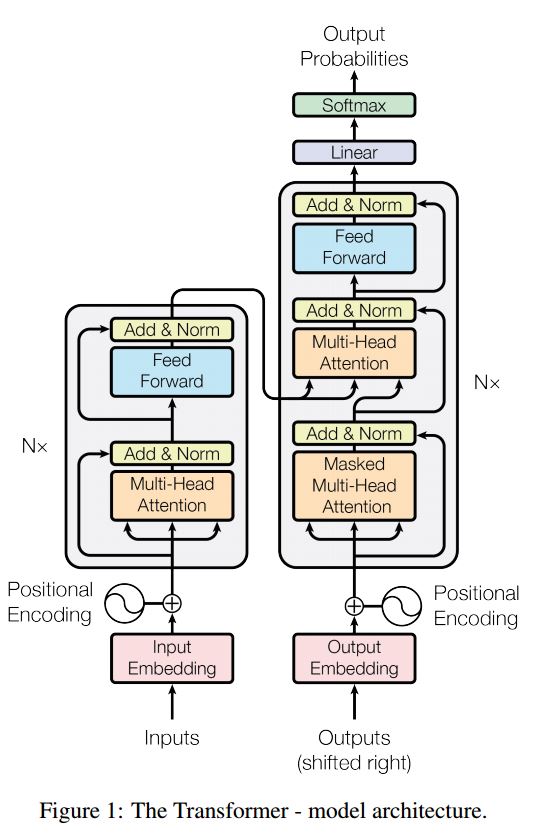
Он также имеет две основные части: энкодер и декодер. Ниже находится DESC из бумаги:
Энкодер:
6 слоев. УЧЕТНЫЕ СЛОВА Имеют два подслои. Первый-это механизм самоуверенного самообучения; Второе-это позиция полностью подключенная сеть подачи. Для каждого подварителя. Используйте Layeronorm (x+Sublayer (x)). Все измерение = 512.
Декодер:
Основной заберите из этой модели:
Используйте эту модель, чтобы выполнить классификацию задач:
Здесь мы используем только часть Encode для классификации задач, удаленного соединения, используя только 1 слой. Нет необходимости использовать маску. Мы используем многоуровневое внимание и Postionwise Feed вперед, чтобы извлечь функции входного предложения, а затем используем линейный слой, чтобы проецировать его для получения логитов.
Для получения подробной информации, пожалуйста, проверьте: A2_Transformer_classification.py
Ввод: 1. История: Это многоценные, как контекст. 2. КВЕРИ: предложение, которое является вопросом, 3. Ansewr: единственный ярлык.
Структура модели:
Входной кодирование: используйте мешок слова, чтобы кодировать историю (контекст) и запрос (вопрос); принять во внимание положение, используя маску положения
Используя двунаправленную RNN для кодирования истории и запроса, повышение производительности с 0,392 до 0,398, увеличится на 1,5%.
Динамическая память:
а Вычислить Gate, используя «сходство» ключей, значения с вводом истории.
беременный Получите кандидат скрытый состояние, преобразуя каждый ключ, значение и вход.
в Объедините ворота и кандидат скрытого состояния для обновления текущего скрытого состояния.
беременный Получите взвешенную сумму скрытого состояния, используя вероятность распределения.
в Нелинейность преобразования запросов и скрытого состояния для получения предсказания метки.
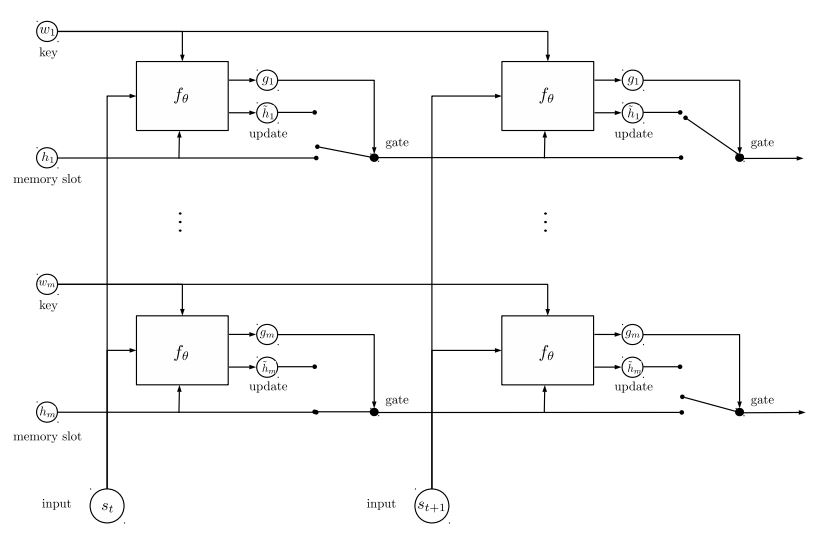
Основной заберите из этой модели:
Используйте блоки клавиш и значений, которые не зависят друг от друга. Так что это можно запустить параллельно.
контекст моделирования и вопрос вместе. Используйте память, чтобы отслеживать состояние мира; и использовать нелинейность преобразования скрытого состояния и вопроса (запрос), чтобы сделать прогноз.
Простая модель также может достичь очень хорошей производительности. Простой код в качестве использования пакета слова.
Для получения подробной информации, пожалуйста, проверьте: a3_entity_network.py
В соответствии с этой моделью, он имеет тестовую функцию, которая просит эту модель подсчитывать числа как для истории (контекст), так и для запроса (вопрос). Но вес истории меньше, чем запрос.
Перспективы модели:
1. INPUT MODULE: кодировать необработанные тексты в векторное представление
2. Модуль вопроса: кодировать вопрос в векторное представление
3. Модуль эпизодической памяти: с входами он выбирает, на какие части входов сосредоточиться на механизме внимания, с учетом вопроса и предыдущей памяти ====> Это поднимает Vecotr «память».
4. Ответ -модуль: генерируйте ответ от конечного вектора памяти.
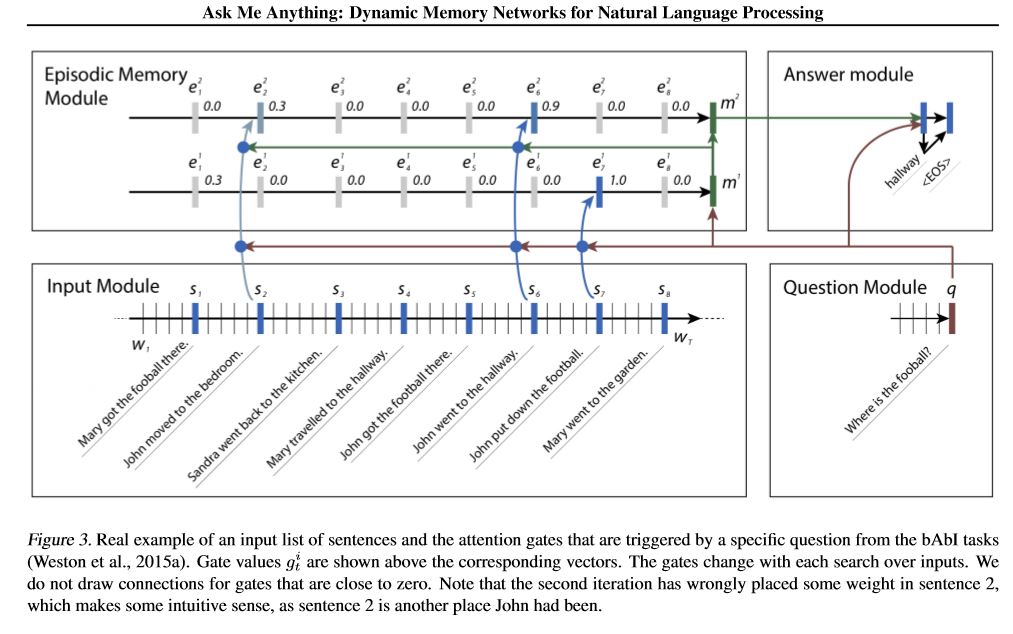
Деталь:
1. Внедорожный модуль:
А. Например, [скрытые государства 1, скрытые государства 2, скрытые государства ..., скрытое государство n]
2. Модуль вопроса: используйте GRU, чтобы получить скрытое состояние
3. Модуль эпизодической памяти:
Используйте механизм внимания и повторяющуюся сеть для обновления его памяти.
а ворота как механизм внимания:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B. Memory Обновление механизм: возьмите предложение кандидата, ворота и предыдущее скрытое состояние, он использует закрытый GRU для обновления скрытого состояния. как: h = f (c, h_previous, g). Окончательное скрытое состояние - это вход для модуля ответа.
c.need для нескольких эпизодов ===> Переходной вывод.
например, спросите, где футбол? Он будет присутствовать на предложении «Джон положить футбол»), а затем во втором перевале ему нужно посетить местоположение Джона.
4. Модуль Answer: Возьмите окончательную эпсоидическую память, вопрос, он обновил скрытое состояние ответа модуля.
1. Спроективные сети на уровне характера для классификации текста
2. Конволюционные нейронные сети для категоризации текста: неглубокий уровень уровня слова и глубокий уровень символов
3. Очень глубокие сверточные сети для классификации текста
4. Методы обучения в обращении для полупрофильной текстовой классификации
5. МОДЕЛИ
Во время процесса выполнения крупномасштабной классификации с несколькими маркировками были извлечены сервельные уроки, а также в некотором списке, как показано ниже:
Что самое важное для достижения высокой точности? Это зависит от задачи, которую вы выполняете. Из задачи, которую мы провели здесь, мы считаем, что ансамблевые модели, основанные на моделях, обученных нескольким функциям, включая слово, символ заголовка и описание, могут помочь в достижении очень высокой аварии; Однако, в некоторых случаях, как продемонстрировал просто Alphago Zero, алгоритм более важен, чем данные или вычислительная мощность, на самом деле Alphago Zero не использовал никаких данных Humam.
Есть ли потолок для какой -либо конкретной модели или алгоритма? Ответ да. Здесь использовалось множество разных моделей, мы обнаружили, что многие модели имеют аналогичные характеристики, хотя по структуре существуют совершенно разные. В некоторой степени разница в производительности не такая большая.
Является ли тематическое исследование ошибки полезно? Я думаю, что это вполне полезно, особенно когда вы сделали много разных вещей, но достигли предела. Например, выполняя тематическое исследование, вы можете найти этикетки, которые модели могут сделать правильный прогноз, и где они совершают ошибки. И увлажнить производительность путем увеличения веса этих неправильных предсказанных метков или поиска потенциальных ошибок из данных.
Как мы можем стать экспертом в специфике машинного обучения? По моему мнению, присоединяйтесь к конкурсе машинного обучения или начните задачу с большим количеством данных, затем прочитайте документы и реализуйте некоторые, является хорошей отправной точкой. Таким образом, у нас будет какой -то действительно опыт и идеи выполнения конкретной задачи и знаем о проблемах. Но что более важно, так это то, что мы должны не только следовать идеям из статей, но и изучить некоторые новые идеи, которые, по нашему мнению, могут помочь, чтобы подать эту проблему. Например, изменяя структуры классических моделей или даже изобретая некоторые новые структуры, мы можем решить проблему гораздо лучше, так как она может более подходить для задачи, которую мы выполняем.
1. сумка трюков для эффективной классификации текста
2. Конволюционные нейронные сети для классификации предложений
3. Анализ чувствительности (и практических руководств по) сверточной нейронной сети для классификации предложения
4. Deep Learning для чат-ботов, часть 2-Реализация модели на основе поиска в Tensorflow, от www.wildml.com
5. Повторная сверточная нейронная сеть для классификации текста
6. Гирархические сети внимания для классификации документов
7. Повод на один из машин, научившись совместно выровнять и переводить
8. Примечание - это все, что вам нужно
9. Закажите мне все: динамические сети памяти для обработки естественного языка
10. Обращение с государством мира с рецидивирующими организационными сетями
11.semble отбор из библиотек моделей
12.bert: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка
13. Google-Research/Bert
продолжение следует. Для любой проблемы, concat [email protected]


