text_classification
1.0.0
O objetivo deste repositório é explorar os métodos de classificação de texto na PNL com aprendizado profundo.
Personalize uma API de PNL em três minutos, de graça: demonstração da API NLP
Referência de avaliação de entendimento de idiomas para chinês (referência da pista): Execute 10 tarefas e 9 linhas de base com uma linha de código, comparação de desempenho com detalhes.
Liberando modelo pré-treinado de treinamento albert_chinese com corpus chinês de 30g+ cru, xxlarge, xlarge e muito mais, alvo de corresponder à performance de última geração em chinês, 2019-out-7, durante o dia nacional da China!
Grande quantidade de corpus chinês para PNL disponível!
O Bert do Google alcançou um novo resultado de ponta em mais de 10 tarefas na PNL usando o pré-treino no modelo de idioma então
afinação. Texcnn pré-treino: IDEA DE BERT PAR
Possui todos os tipos de modelos de linha de base para classificação de texto.
Também suporta a classificação de vários rótulos, onde os vários rótulos se associam a uma frase ou documento.
Embora muitos desses modelos sejam simples e não possam levar você ao nível superior da tarefa. Mas alguns desses modelos são muito
Clássico, então eles podem ser bons para servir como modelos de linha de base. Cada modelo tem uma função de teste na classe Model. você pode correr
Tarefa de brinquedo de desempenho primeiro. O modelo é independente do conjunto de dados.
Verifique aqui o relatório formal de classificação de texto em larga escala com vários rótulos com aprendizado profundo
Vários modelos aqui também podem ser usados para modelar a resposta das perguntas (com ou sem contexto) ou para fazer sequências geradoras.
Exploramos dois modelos SEQ2SEQ (SEQ2SEQ com atenção, é tudo o que você precisa) para fazer classificação de texto.
E esses dois modelos também podem ser usados para seqüências de geração e outras tarefas. Se sua tarefa é uma classificação de vários rótulos,
Você pode lançar o problema para as seqüências de geração.
Implementamos duas redes de memória. Um é a rede de memória dinâmica. Anteriormente, chegou ao estado da arte em questão
Responder, análise de sentimentos e tarefas de geração de sequência. é o que é chamado um modelo para realizar várias tarefas diferentes,
e atingir alto desempenho. Tem quatro módulos. O componente -chave é o módulo de memória episódica. usa mecanismo de portão para
Atenção de desempenho e usar o Gated-Gru para atualizar a memória do episódio, então ele tem outro GRU (em uma direção vertical) para
Atualização de estado oculta de desempenho. Tem capacidade de fazer inferência transitiva.
A segunda rede de memória que implementamos é a Rede de Entidade Recorrente: Rastreamento do Estado do Mundo. tem blocos de
Os pares de valores-chave como memória, executados em paralelo, que alcançam novo estado de arte. Pode ser usado para modelar a pergunta
respondendo com contextos (ou história). Por exemplo, você pode deixar o modelo ler algumas frases (como contexto) e perguntar a um
Pergunta (como consulta) e peça ao modelo para prever uma resposta; Se você alimentar a história da mesma forma que a consulta, pode fazer
tarefa de classificação.
Para discutir problemas de ML/DL/PNL e obter suporte técnico um do outro, você pode ingressar no QQ Group: 836811304
FastText
Textcnn
Bert: pré-treinamento de transformadores bidirecionais profundos para compreensão de idiomas
Textrnn
Rcnn
Rede de atenção hierárquica
SEQ2SEQ com atenção
Transformer ("Participe é tudo que você precisa")
Rede de memória dinâmica
EntityNetwork: Rastreando o estado do mundo
Modelos de conjunto
Boosting:
Para um único modelo, empilhe modelos idênticos. Cada camada é um modelo. O resultado será baseado em logits adicionados. A única conexão entre as camadas são os pesos da etiqueta. A taxa de erro de previsão da camada frontal de cada rótulo se tornará peso para as próximas camadas. Esses rótulos com alta taxa de erro terão grande peso. Portanto, as camadas posteriores prestarão mais atenção aos rótulos mal previstos e tentarão corrigir um erro anterior da antiga camada. Como resultado, teremos um modelo muito forte. Verifique a00_boosting/boosting.py
e outros modelos:
BilstmtextreLation;
twocnntextration;
BilstmtextreLationTwornn
(Tarefa de previsão do rótulo Mulit-Label, peça para previsão Top5, 3 milhões de dados de treinamento, pontuação completa: 0,5)
| Modelo | FastText | Textcnn | Textrnn | Rcnn | Hierattenet | SEQ2SEQATTN | Entitynet | DynamicMemory | Transformador |
|---|---|---|---|---|---|---|---|---|---|
| Pontuação | 0,362 | 0,405 | 0,358 | 0,395 | 0,398 | 0,322 | 0,400 | 0,392 | 0,322 |
| Treinamento | 10m | 2h | 10h | 2h | 2h | 3h | 3h | 5h | 7h |
O Modelo Bert alcança 0,368 após a primeira época 9 do conjunto de validação.
Conjunto de textcnn, entitynet, dynamicMemory: 0.411
Ensemble EntityNet, DynamicMemory: 0.403
Perceber:
m fica por minutos ; h defende horas ;
HierAtteNet significa rede hierárquica de atenção;
Seq2seqAttn significa seq2seq com atenção;
DynamicMemory significa DynamicMemoryNetwork;
Transformer Stand para o modelo de 'Atenção é tudo o que você precisa'.
xxx_model.pyxxx_train.py para treinar o modeloxxx_predict.py para fazer inferência (teste).Cada modelo possui um método de teste na classe Model. Você pode executar o método de teste primeiro para verificar se o modelo pode funcionar corretamente.
Python 2.7+ Tensorflow 1.8
(Tensorflow 1.1 a 1.13 também deve funcionar; a maioria dos modelos também deve funcionar bem em outra versão do tensorflow, pois nós
Use muito poucos recursos Bond em determinada versão.
Se você usar o Python3, ficará bem, desde que você altere a função Print/Try Catch, caso você atenda a algum erro.
O modelo TextCNN já está transfomed para Python 3.6
Para ajudá-lo a executar este repositório, atualmente re-generamos dados de treinamento/validação/teste e vocabulário/etiquetas e salvamos
eles como arquivo de cache usando H5PY. Sugerimos que você faça o download do link acima.
Ele contém tudo o que você precisa para executar este repositório: os dados são pré-processados, você pode começar a treinar o modelo em um minuto.
É um arquivo zip cerca de 1,8g, contém 3 milhões de dados de treinamento. embora depois de descompactar, é muito grande, mas com a ajuda de
HDF5, ele só precisa de um tamanho normal de memória do computador (EG8 g ou menos) durante o treinamento.
Usamos o Jupyter Notebook: pré-processamento.ipynb para pré-processo. você pode ter uma melhor compreensão dessa tarefa e
dados dando uma olhada disso. Você também pode gerar dados por si mesmo da maneira que seu desejo, basta alterar poucas linhas de código
Usando este notebook Jupyter.
Se você quiser experimentar um modelo agora, poderá Dowload em cache de acima e vá para a pasta 'a02_textcnn', execute
python p7_TextCNN_train.py
Ele usará dados de arquivos em cache para treinar o modelo e imprimir a perda e a pontuação F1 periodicamente.
Fonte de dados de amostra antiga: se você precisar de alguns dados de amostra e incorporação de palavras por treinado no Word2Vec, poderá encontrá-los em problemas fechados, como: Edição 3.
Você também pode encontrar alguns dados de amostra na pasta "dados". Ele contém dois arquivos: 'sample_single_label.txt', contém 50k dados
com rótulo único; 'Sample_multiple_label.txt', contém 20K de dados com vários rótulos. A entrada e a etiqueta de são separadas por " etiqueta ".
Se você quiser saber mais detalhes sobre o conjunto de dados de classificação de texto ou tarefa que esses modelos podem ser usados, um de escolher está abaixo:
https://biendata.com/competition/zhihu/
Uma maneira de usar este repositório:
Etapa 1: você pode ler este artigo. Você terá uma idéia geral de vários modelos clássicos usados para fazer a classificação de texto.
Etapa 2: Dados pré-processo e/ou download do arquivo em cache.
a. take a look a look of jupyter notebook('pre-processing.ipynb'), where you can familiar with this text
classification task and data set. you will also know how we pre-process data and generate training/validation/test
set. there are a list of things you can try at the end of this jupyter.
b. download zip file that contains cached files, so you will have all necessary data, and can start to train models.
Etapa 3: Execute alguns dos modelos Lista aqui e altere alguns códigos e configurações como você quiser, para obter um bom desempenho.
record performances, and things you done that works, and things that are not.
for example, you can take this sequence to explore:
1) fasttext---> 2)TextCNN---> 3)Transformer---> 4)BERT
Além disso, escreva seu artigo sobre este tópico, você pode seguir o estilo do artigo para escrever. Pode ser necessário ler alguns papéis
on the way, many of these papers list in the # Reference at the end of this article; or join a machine learning
competition, and apply it with what you've learned.
Substitua os dados em 'dados/sample_multiple_label.txt' e verifique se o formato está abaixo:
'word1 word2 word3 __label__l1 __label__l2 __label__l3'
onde parte1: 'word1 word2 word3' é entrada (x), parte2: '__label__l1 __label__l2 __label__l3'
Representando, existem três rótulos: [L1, L2, L3]. Entre a Part1 e a Part2, deve haver uma string vazia: ''.
Por exemplo: cada linha (vários rótulos) como:
'W5466 W138990 W1638 W4301 W6 W470 W202 C1834 C1400 C134 C57 C73 C699 C317 C184 __LABEL__562666166763888119 __label__562666166763888119 __label__49216666167638881919142666666616388819 __label__8904735555009151318 '
onde '5626661657638885119', '4921793805334628695' '' 8904735555009151318 'são três etiquetas associados a esta string de entrada' c5466669990 ...
Perceber:
Alguma função utilizada está em data_util.py; Verifique o load_data_multilabel () de data_util para obter como a entrada do processo e os rótulos dos dados brutos.
Existe uma função para carregar e atribuir palavras pré -tenhadas incorporando o modelo, onde a incorporação de palavras é pré -treinada no Word2Vec ou FastText.
Se o word2vec.load não funcionar, você poderá carregar a incorporação de palavras pré -gravadas, especialmente para o uso de incorporação de palavras chinesas seguintes:
importar gensim
de gensim.models importam keyedvetores
word2vec_model = KeyEdVectors.load_word2vec_format (word2vec_model_path, binário = true, unicode_errors = 'ignore') #
Ou você pode desativar o uso do sinalizador de incorporação de palavras pré -TRARAN para desativar a incorporação de palavras de carregamento.
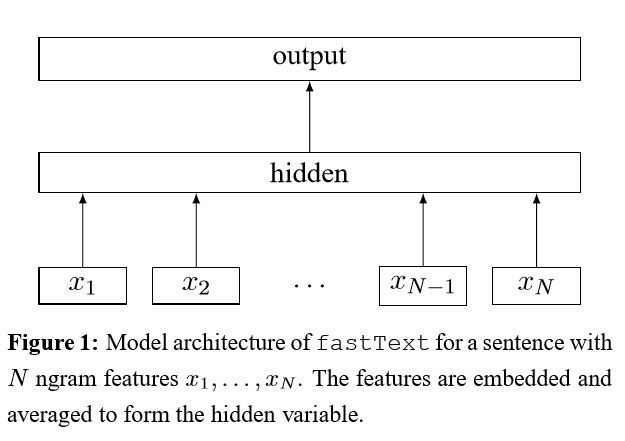
Implicação do saco de truques para classificação de texto eficiente
Após incorporar cada palavra na frase, essas representações de palavras são calculadas em média em uma representação de texto, que, por sua vez, é alimentada a um classificador linear. Use a função Softmax para calcular a distribuição de probabilidade sobre as classes predefinidas. Em seguida, a entropia cruzada é usada para calcular a perda. O saco de representação de palavras não considera a ordem das palavras. Para levar em consideração a ordem das palavras, os recursos de n-grama são usados para capturar algumas informações parciais sobre a ordem local da palavra; Quando o número de classes é grande, calcular o classificador linear é caro computacional. Por isso, usa o Softmax Hierárquico para acelerar o processo de treinamento.
Resultado: O desempenho é tão bom quanto o papel, a velocidade também é muito rápida.
Verifique: p5_fasttextb_model.py
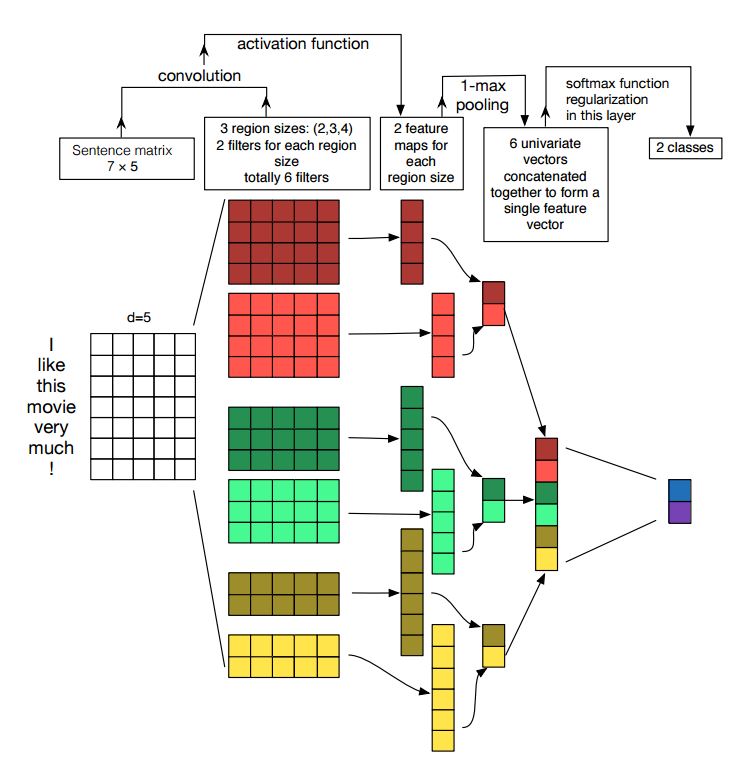
Implementação de redes neurais convolucionais para classificação de frases
Estrutura: Incorporação ---> Conv ---> Max Pooling ---> Camada totalmente conectada --------> Softmax
Verifique: p7_textcnn_model.py
Para obter um resultado muito bom com o TextCNN, você também precisa ler cuidadosamente sobre este artigo uma análise de sensibilidade do (e do guia dos profissionais para) redes neurais convolucionais para classificação de frases: fornece algumas idéias de coisas que podem afetar o desempenho. Embora você precise alterar algumas configurações de acordo com sua tarefa específica.
A rede neural convolucional é a principal caixa de construção para resolver problemas de visão computacional. Agora, mostraremos como a CNN pode ser usada para a PNL, em particular a classificação de texto. O comprimento da frase será diferente de um para outro. Então, usaremos o PAD para obter comprimento fixo, n. Para cada token na frase, usaremos a incorporação do Word para obter um vetor de dimensão fixa, d. Portanto, nossa entrada é uma matriz de duas dimensões: (n, d). Isso é semelhante com a imagem para a CNN.
Em primeiro lugar, faremos uma operação convolucional para nossa entrada. É uma multiplicação entre filtro e parte da entrada. Utilizamos o número de filtros K, cada tamanho de filtro é uma matriz de duas dimensões (f, d). Agora a saída será k número de listas. Cada lista tem um comprimento de n-f+1. Cada elemento é um escalar. Observe que a segunda dimensão será sempre a dimensão da incorporação de palavras. Estamos usando um tamanho diferente dos filtros para obter recursos ricos das entradas de texto. E isso é algo semelhante aos recursos n-gram.
Em segundo lugar, faremos o pool máximo para a saída da operação convolucional. Para K número de listas, obteremos K número de escalares.
Em terceiro lugar, concatenaremos os escalares para formar recursos finais. É um vetor de tamanho fixo. E é independente do tamanho dos filtros que usamos.
Finalmente, usaremos a camada linear para projetar esses recursos em rótulos por definidos.
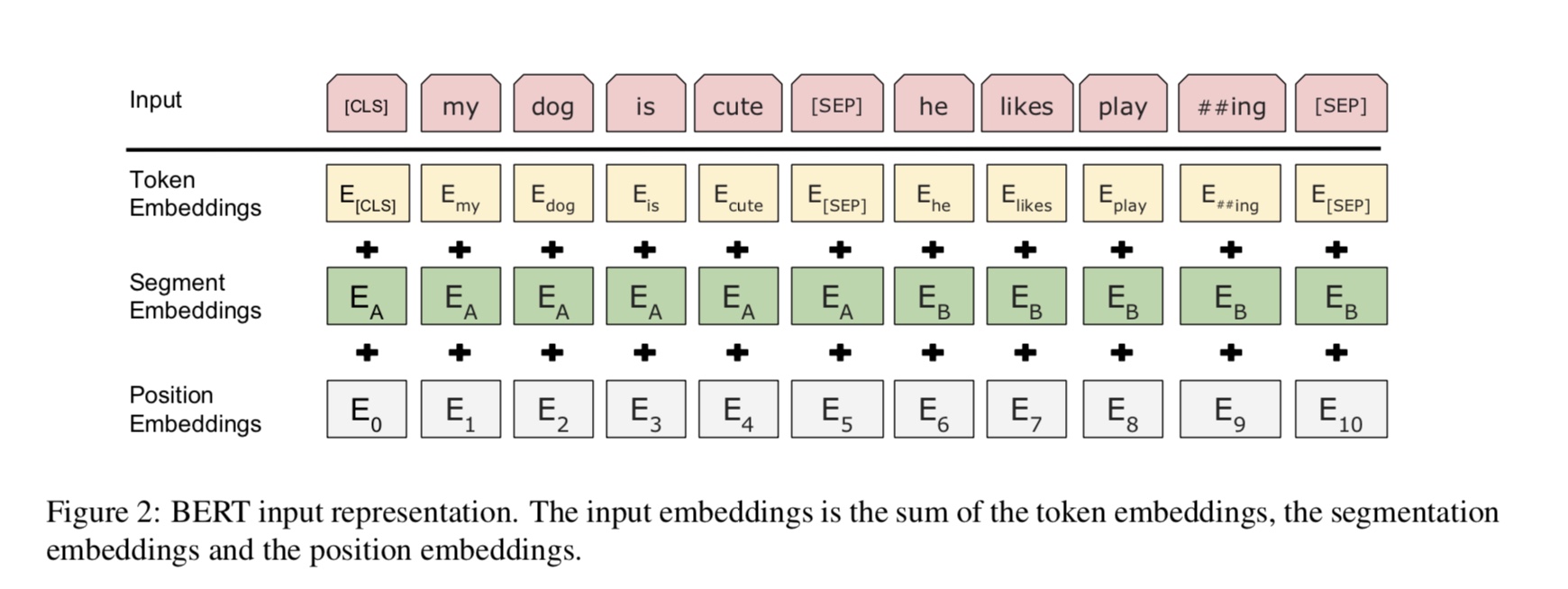
Atualmente, o BERT atinge os resultados de ponta em mais de 10 tarefas de PNL. As principais idéias por trás deste modelo é que podemos
Pré-trep o modelo usando um tipo de modelo de idioma com enorme quantidade de dados brutos, onde você pode encontrá-lo facilmente.
Como a maioria dos parâmetros do modelo é pré-treinada, apenas a última camada para o classificador precisa ser necessária para tarefas diferentes.
Como resultado, esse modelo é genérico e muito poderoso. Você pode apenas ajustar com base no modelo pré-treinado dentro
um curto período de tempo.
No entanto, esse modelo é muito grande. Com o comprimento da sequência 128, você só pode treinar com um tamanho de lote de 32; por muito tempo
Documento como o comprimento da sequência 512, ele só pode treinar um tamanho de lote 4 para uma GPU normal (com 11g); e muito poucas pessoas
pode pré-treinar esse modelo do zero, pois leva muitos dias ou semanas para treinar, e a memória de uma GPU normal é muito pequena
Para este modelo.
Especialmente, o modelo de espinha dorsal é o transformador, onde você pode encontrá -lo em atenção é tudo o que você precisa. usa dois tipos de
tarefas para pré-treinar o modelo.
De um modo geral, dada uma frase, alguma porcentagem de palavras é mascarada, você precisará prever as palavras mascaradas
com base nesta frase mascarada. Palavras mascaradas são escolhidas aleatoriamente.
Alimentamos a entrada através de um codificador de transformador profundo e depois usamos os estados ocultos finais correspondentes ao mascarado
Posições para prever qual palavra foi mascarada, exatamente como se fossemos um modelo de idioma.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Muitas tarefas de entendimento de idiomas, como resposta a perguntas, inferência, precisam entender o relacionamento
entre a frase. No entanto, o modelo de idioma só é capaz de entender sem uma frase. Próxima frase
A previsão é uma tarefa de amostra para ajudar o modelo a entender melhor nesses tipos de tarefas.
50% da chance A segunda frase é a próxima frase do primeiro, 50% do próximo.
Dada duas frases, o modelo é solicitado a prever se a segunda frase é a próxima frase real de
o primeiro.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : IsNext
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
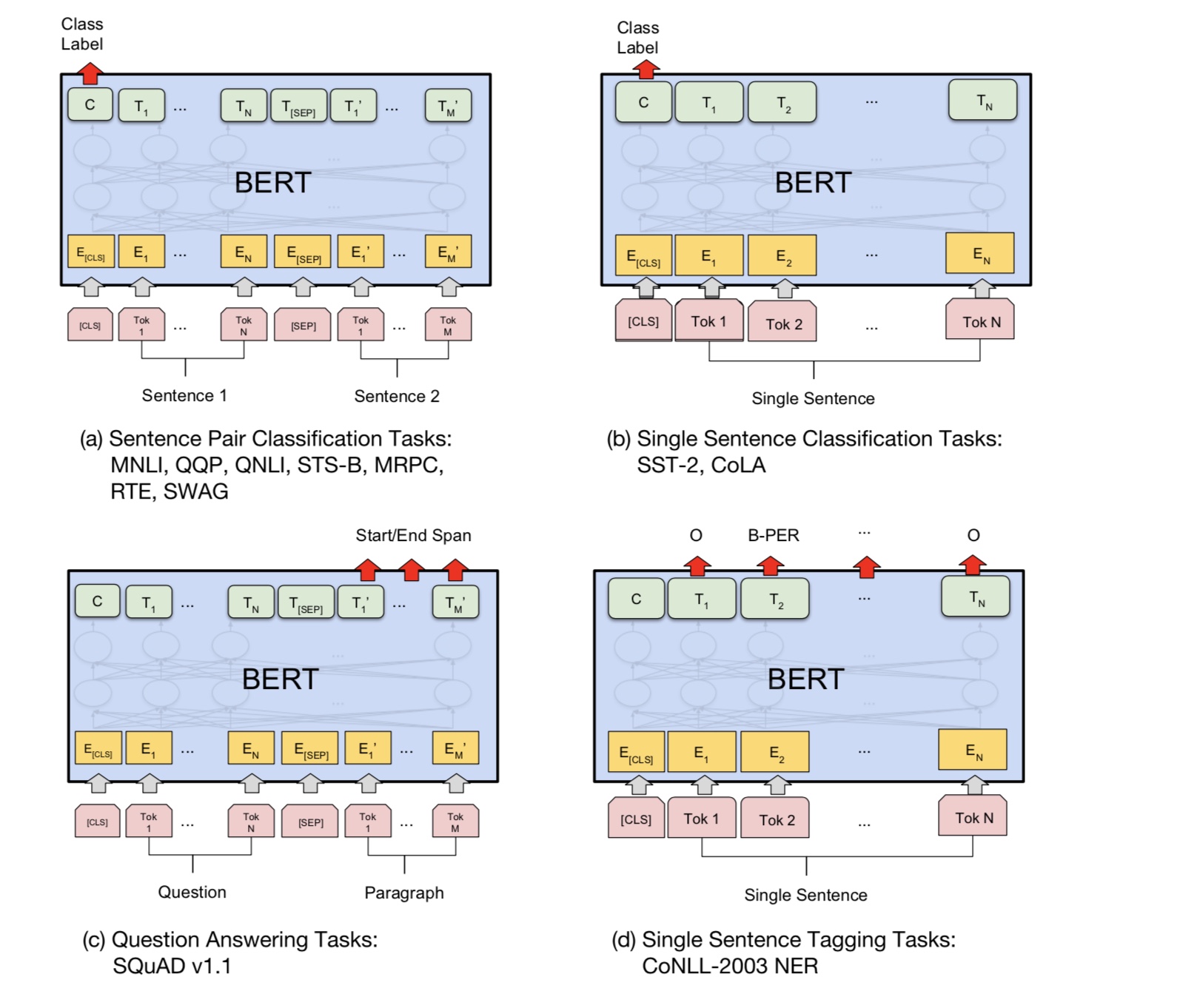
Basicamente, você pode baixar o modelo pré-treinado, pode ajustar sua tarefa com seus próprios dados.
Para a tarefa de classificação, você pode adicionar processador para definir o formato que deseja permitir que a entrada e os rótulos dos dados de origem.
Execute o seguinte comando na pasta A00_BERT:
python train_bert_multi-label.py
Atinge 0,368 após 9 época. Ou você pode executar a classificação de vários rótulos com dados para download usando Bert de
sentimento_analysis_fine_grain com bert
Você pode usar o estilo de sessão e alimentação para restaurar e alimentar dados e obter logits para fazer uma previsão on -line.
Previsão online com Bert
Originalmente, ele treina ou avalia o modelo com base no arquivo, não para online.
Em primeiro lugar, você pode usar download de modelo pré-treinado do Google. Execute algumas épocas no conjunto de dados e encontre um adequado
comprimento da sequência.
em segundo lugar, você pode pré-treinar o modelo básico em seus próprios dados, desde que possa encontrar um conjunto de dados relacionado a
Sua tarefa, depois ajustando sua tarefa específica.
Em terceiro lugar, você pode alterar a função de perda e a última camada para melhor se adequar à sua tarefa.
Além disso, você pode adicionar definir algumas tarefas pré-treinadas que ajudarão o modelo a entender sua tarefa muito melhor.
Como experiente que obtivemos de experimentos, a tarefa pré-treinada é independente do modelo e o pré-trep não é limite para
as tarefas acima.
Estrutura V1: Incorporação ---> LSTM bidirecional ---> Saída concat ---> média -----> Softmax Camada
Verifique: p8_textrnn_model.py
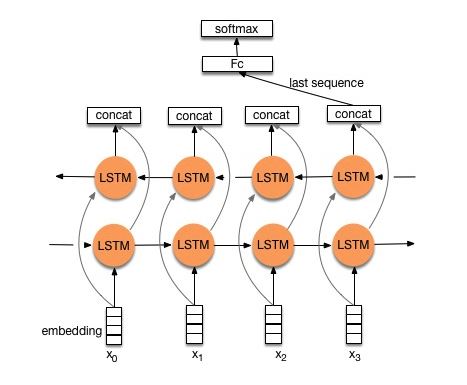
Estrutura V2: Incorporação-> LSTM bidirecional ----> abandono-> concat °
Verifique: p8_textrnn_model_multilayer.py
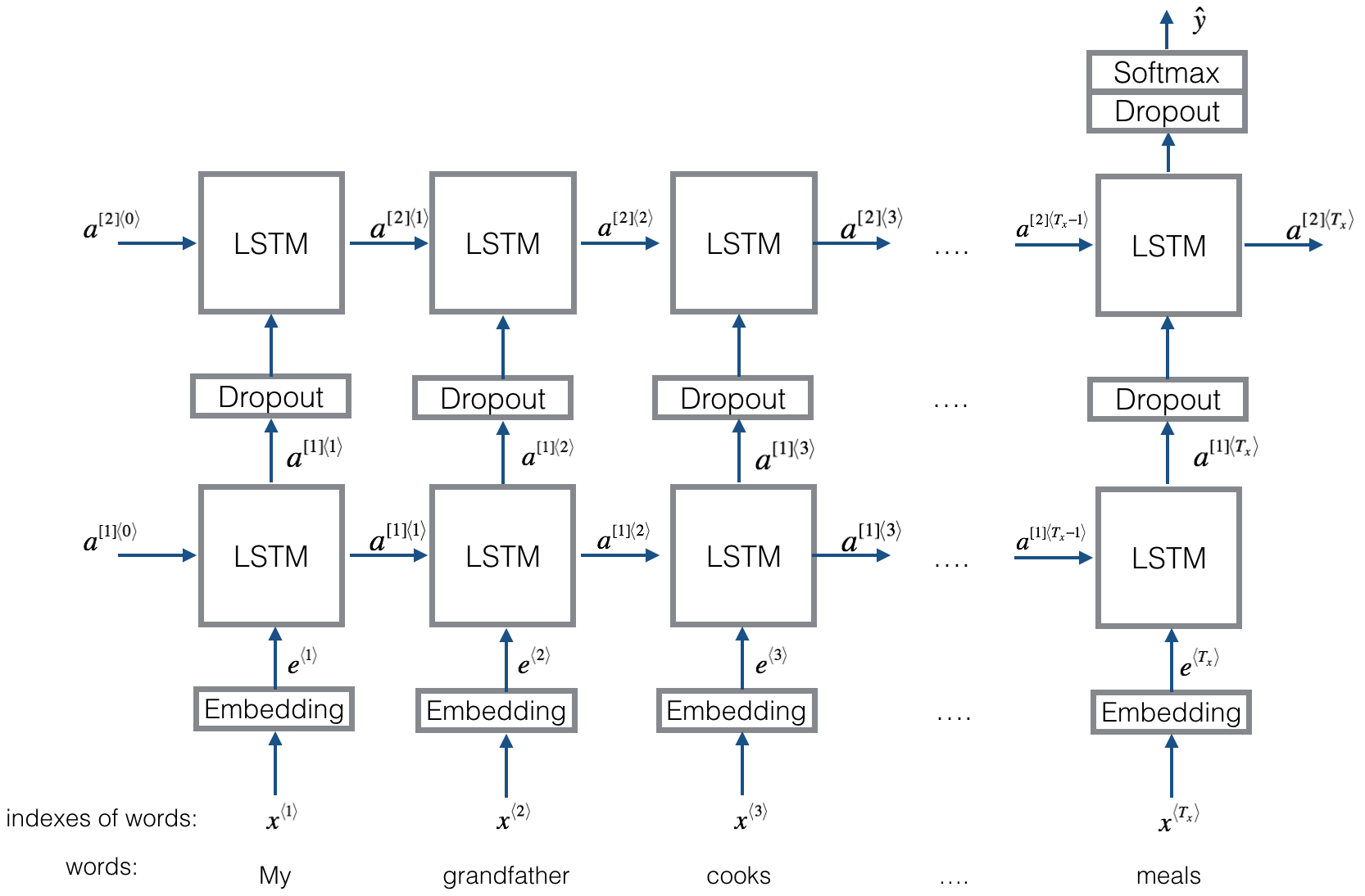
Estrutura igual ao textrnn. Mas a entrada é projetada especial. Eginput: "Quanto custa o computador? EOS Preço do laptop". Onde 'EOS' é uma pergunta Especial de Spings Sping1 e Questão 2.
Verifique: p9_bilstmtexTreLation_model.py
Estrutura: primeiro use dois diferentes convolucionais para extrair o recurso de duas frases. Em seguida, concate dois recursos. Use a camada de transformação linear para projeção para obter rótulo de destino e depois softmax.
Verifique: p9_twocnntexTreLation_model.py
Estrutura: Um LSTM bidirecional para uma frase (Get Output1), outro LSTM bidirecional para outra frase (Get Output2). Então: Softmax (saída1 M output2)
Verifique: p9_bilstmtexTreLationTwornn_model.py
Para mais detalhes, você pode acessar: Deep Learning for Chatbots, Parte 2-Implementando um modelo baseado em recuperação no TensorFlow
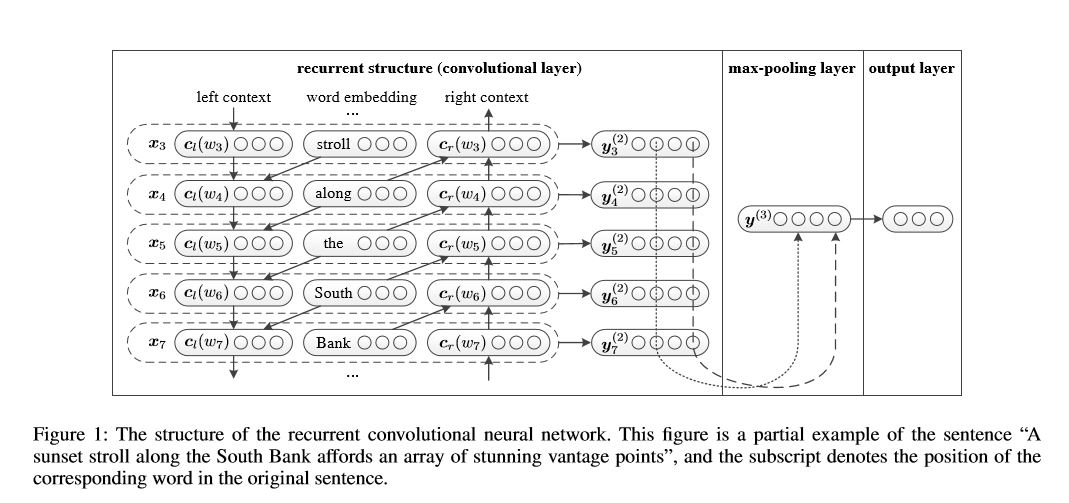
Rede neural convolucional recorrente para classificação de texto
Implementação de rede neural convolucional recorrente para classificação de texto
Estrutura: 1) Estrutura recorrente (camada convolucional) 2) Poolamento máximo 3) camada totalmente conectada+softmax
Aprenda a representação de cada palavra na frase ou documento com o contexto lateral esquerdo e o contexto lateral direito:
Representação Word atual = [esquerd_side_context_vector, current_word_embedding, RETREIRO_SED_CONTEXT_VECOTOR].
Para o contexto do lado esquerdo, ele usa uma estrutura recorrente, uma transfrome sem linearidade da palavra anterior e o contexto anterior do lado esquerdo; Da mesma forma ao contexto lateral direito.
Verifique: p71_textrcnn_model.py
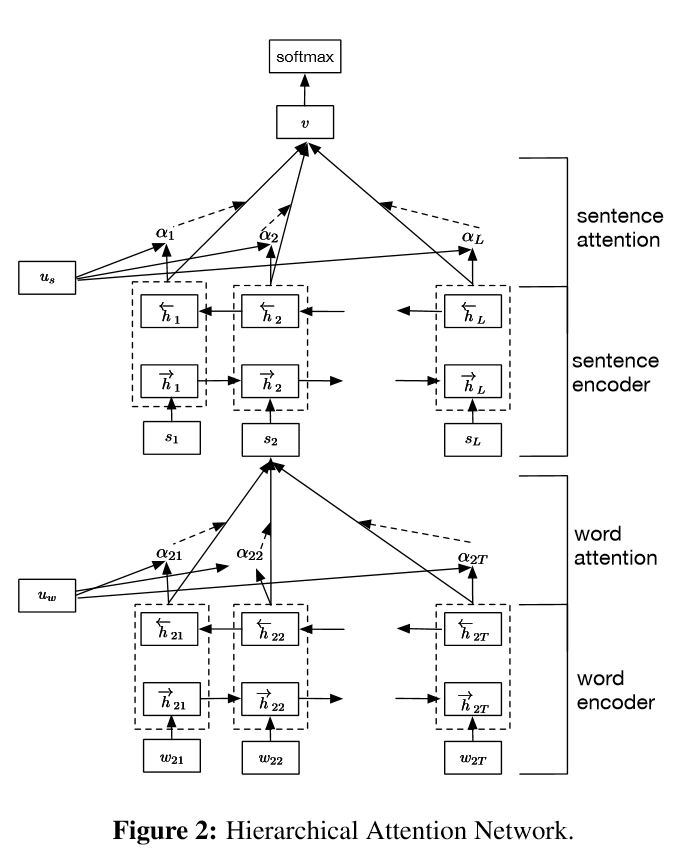
Implementação de redes de atenção hierárquica para classificação de documentos
Estrutura:
incorporação
Encoder de palavras: nível de palavra GRU bidirecional para obter uma rica representação de palavras
Atenção da palavra: atenção do nível da palavra para obter informações importantes em uma frase
Codificador de frases: nível de frase GRU bidirecional para obter uma rica representação de frases
Atenção da frase: atenção ao nível da sentença para obter sentença importante entre as sentenças
FC+Softmax
Na PNL, a classificação de texto pode ser feita para frase única, mas também pode ser usada para várias frases. Podemos chamá -lo de classificação de documentos. Palavras são forma para frase. E sentença são forma para documentar. Nesta circunstância, pode existir uma estrutura intrínseca. Então, como podemos modelar esse tipo de tarefa? Todas as partes do documento são igualmente relevantes? E como determinamos qual parte é mais importante que outra?
Tem dois recursos únicos:
1) possui uma estrutura hierárquica que reflete a estrutura hierárquica dos documentos;
2) Possui dois níveis de mecanismos de atenção usados na palavra e no nível da frase. Ele permite que o modelo capture informações importantes em diferentes níveis.
Encoder de palavras: para cada palavras em uma frase, ele é incorporado ao vetor de palavras no espaço do vetor de distribuição. Ele usa um GRU bidirecional para codificar a frase. Por vetor concatenado de duas direção, agora ele pode formar uma representação da frase, que também captura informações contextuais.
Atenção da palavra: As mesmas palavras são mais importantes que outra para a frase. Portanto, o mecanismo de atenção é usado. Primeiro, usa uma camada MLP para obter a representação oculta da frase e depois meça a importância da palavra como a semelhança do UIT com um vetor de contexto de nível de palavra UW e obtenha uma importância normalizada através de uma função softmax.
Codificador de frases: Para vetores de sentença, Gru bidirecional é usado para codificá -lo. Da mesma forma ao codificador de palavras.
Atenção da frase: o vetor de nível de sentença é usado para medir a importância entre as sentenças. Da mesma forma à atenção da palavra.
Entrada de dados:
De um modo geral, a entrada desse modelo deve ter frases servidores em vez de sentença pecada. A forma é: [nenhum, sentença_lenght]. onde mais significa o batch_size.
Nos meus dados de treinamento, para cada exemplo, tenho quatro partes. Cada parte tem o mesmo comprimento. Eu concato quatro partes para formar uma única frase. O modelo dividirá a frase em quatro partes, para formar um tensor com forma: [nenhum, num_sentence, sentença_length]. onde num_sentence é o número de frases (igual a 4, na minha configuração).
Verifique: p1_hierchicalattion_model.py
Para atenção atenta, você pode verificar a atenção atenta
Implementação seq2seq com atenção derivada da tradução da máquina neural aprendendo em conjunto para alinhar e traduzir
I.Structure:
1) Incorporação 2) Bi-Gru também obtenha uma representação rica das frases da fonte (para frente e para trás). 3) decodificador com atenção.
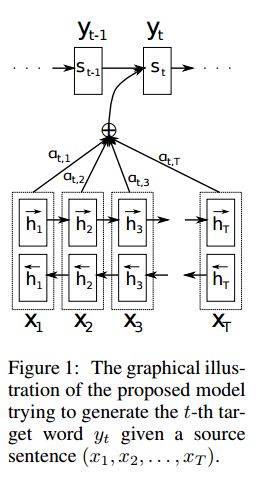
Ii.Input of Data:
Existem dois tipos de três tipos de entradas: 1) entradas do codificador, que é uma frase; 2) Entradas de decodificadores, é a lista de rótulos com comprimento fixo; 3) rótulos de destino, também é uma lista de etiquetas.
Por exemplo, os rótulos são: "L1 L2 L3 L4", então as entradas do decodificador serão: [_ Go, L1, L2, L2, L3, _pad]; O rótulo de destino será: [L1, L2, L3, L3, _END, _PAD]. O comprimento é fixado para 6, qualquer rótulo excedente será trancado, será necessário se a etiqueta não for suficiente para preencher.
III. Mecanismo de Attência:
Lista de entrada do codificador de transferência e estado oculto do decodificador
Calcule a similaridade do estado oculto com cada entrada do codificador, para obter a distribuição de possibilidades para cada entrada do codificador.
Soma ponderada da entrada do codificador com base na distribuição da possibilidade.
vá embora a célula RNN usando esta soma de peso juntamente com a entrada do decodificador para obter um novo estado oculto
Iv.Como o decodificador do codificador de baunilha obras:
A frase de origem será codificada usando o RNN como vetor de tamanho fixo ("vetor de pensamento"). Então, durante o decodificador:
Quando estiver treinando, outro RNN será usado para tentar obter uma palavra usando esse "vetor de pensamento" como estado init e obtenha a entrada da entrada do decodificador em cada registro de data e hora. O decodificador inicia a partir de token especial "_go". Depois que uma etapa é executada, o novo estado oculto estará e junto com a nova entrada, podemos continuar esse processo até chegar a um token especial "_end". Podemos calcular a perda pela perda de entropia cruzada de computação de logits e rótulo de destino. Os logits estão passando por uma camada de projeção para o estado oculto (para saída da etapa do decodificador (no GRU, podemos usar apenas estados ocultos do decodificador como saída).
Quando está testando, não há rótulo. Portanto, devemos alimentar a saída que obtemos do registro de data e hora anteriores e continuar o processo, chegamos ao token "_end".
V.Notices:
Aqui eu uso dois tipos de vocabulários. Um é de palavras, usado pelo codificador; Outro é para rótulos, usado pelo decodificador
Para o vocabulário de Lables, insiro três token especiais: "_ Go", "_ end", "_ pad"; "_Unk" não é usado, pois todos os rótulos são predefinidos.
Status: foi capaz de fazer a classificação de tarefas. e capaz de gerar ordem reversa de suas seqüências na tarefa de brinquedos. Você pode verificar executando a função de teste no modelo. Verificação: a2_train_classification.py (trem) ou a2_transformer_classification.py (modelo)
Fazemos isso no estilo parallell. normalização da camada, conexão residual e máscara também são usadas no modelo.
Para todos os blocos de construção, incluímos uma função de teste em cada arquivo abaixo e testamos cada pequena peça com sucesso.
A sequência da sequência com atenção é um modelo típico para resolver o problema de geração de sequência, como o sistema de diálogo traduzido. Na maioria das vezes, ele usa o RNN como bloco de compra para realizar essas tarefas. Recentemente, as pessoas também aplicam rede neural convolucional para o problema de sequência de sequência. Transformador, no entanto, executa essas tarefas apenas na atenção mechansim. É rápido e obtém um novo resultado de ponta.
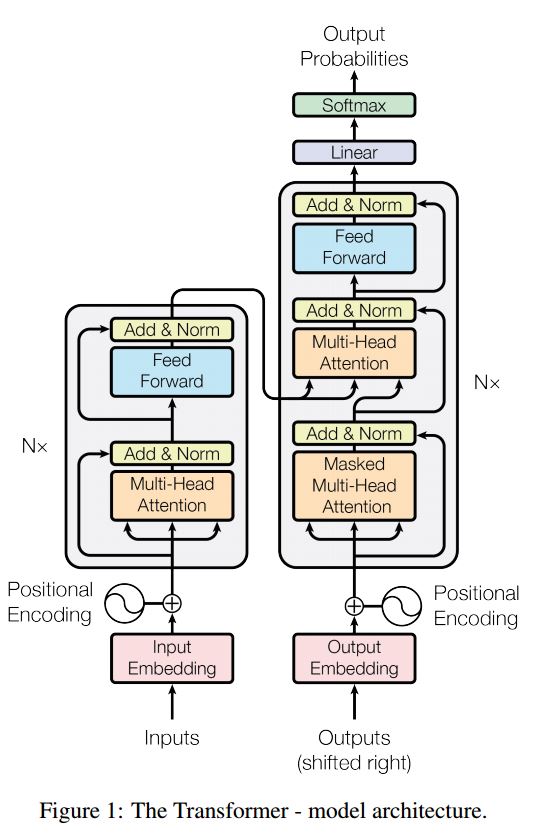
Ele também possui duas partes principais: codificador e decodificador. Abaixo está o DESC do papel:
Codificador:
6 camadas. Cada camadas tem duas sub-camadas. O primeiro é o mecanismo de auto-ataque de várias cabeças; O segundo é uma rede de feed-forward totalmente conectada em posição de posição. Para cada subcamada. Use camadas (x+subcamada (x)). toda dimensão = 512.
Decodificador:
Taçar principal deste modelo:
Use este modelo para fazer a classificação de tarefas:
Aqui, usamos apenas a parte do codificação para classificação de tarefas, removeu a conexão resdiual, usamos apenas 1 camada. Não precisa usar a máscara. Utilizamos a atenção de várias cabeças e a alimentação positiva para extrair recursos da frase de entrada e, em seguida, usamos a camada linear para projetá-la para obter logits.
Para obter detalhes do modelo, verifique: a2_transformer_classification.py
Entrada: 1. História: são multi-sinceras, como contexto. 2.Query: uma frase, que é uma pergunta, 3. Ansewr: um único rótulo.
Estrutura do modelo:
Codificação de entrada: use saco de palavras para codificar a história (contexto) e a consulta (pergunta); Leve em conta a posição usando a máscara de posição
Ao usar o RNN bidirecional para codificar a história e a consulta, o aumento do desempenho de 0,392 a 0,398 aumenta 1,5%.
Memória dinâmica:
um. Calcule o portão usando a 'similaridade' das chaves, valores com a entrada da história.
b. Obtenha o estado oculto do candidato transformar cada chave, valor e entrada.
c. Combine o portão e o candidato oculto estado para atualizar o estado oculto atual.
b. Obtenha uma soma ponderada do estado oculto usando a distribuição da possibilidade.
c. Transformação não linearidade do estado de consulta e oculto para obter o rótulo previsto.
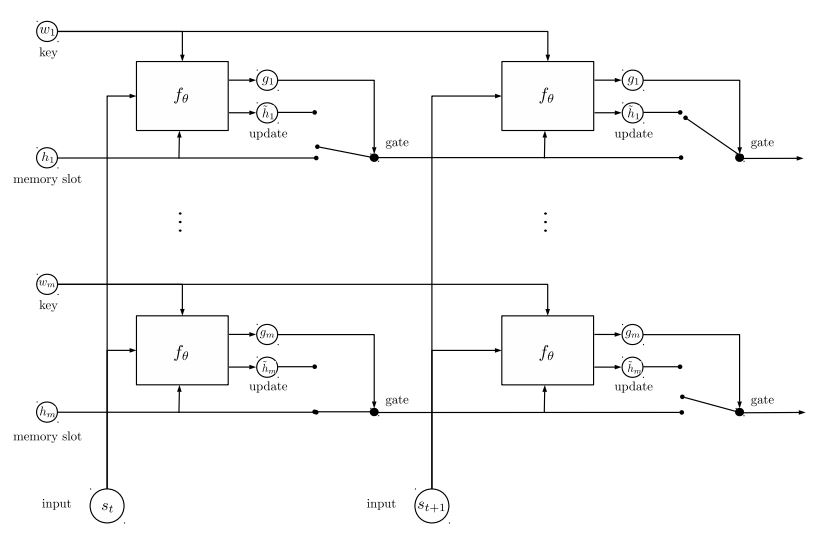
Taçar principal deste modelo:
Use blocos de chaves e valores, que são independentes um do outro. Portanto, pode ser executado em paralelo.
Modelando o contexto e a pergunta juntos. Use a memória para rastrear o estado do mundo; e use a transformação de não linearidade do estado oculto e pergunta (consulta) para fazer uma previsão.
O modelo simples também pode obter um desempenho muito bom. Encoda simples como use saco de palavra.
Para obter detalhes do modelo, verifique: a3_entity_network.py
Sob esse modelo, ele possui uma função de teste, que solicita que esse modelo conte números para a história (contexto) e a consulta (pergunta). Mas os pesos da história são menores que a consulta.
Perspectiva do modelo:
1.Input Module: codifique textos brutos na representação vetorial
2. Módulo de inquérito: codificar a questão da representação vetorial
3. Módulo de memória episódico: com as entradas, escolhe em quais partes das entradas se concentrarem através do mecanismo de atenção, levando em consideração a pergunta e a memória anterior ====> podia a 'memória' vecotr.
4.Swer Module: Gere uma resposta a partir do vetor de memória final.
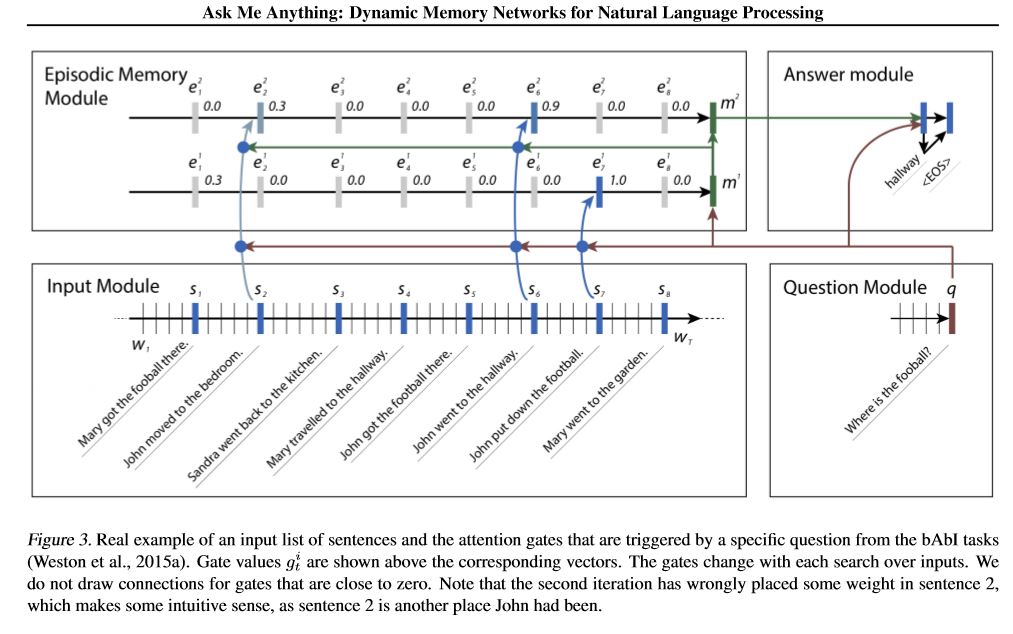
Detalhe:
1. módulo de invasão:
a. Single Single: Use Gru para obter o estado oculto B. Lista de frases: use Gru para obter os estados ocultos para cada frase. Por exemplo, [Estados Hidden 1, Estados Hidden 2, Estados Hidden ..., Estado oculto n]
2. Módulo de inquérito: Use Gru para obter o estado oculto
3. Módulo de memória episódico:
Use um mecanismo de atenção e uma rede recorrente para atualizar sua memória.
um. Portão como mecanismo de atenção:
two-layer feed forward nueral network.input is candidate fact c,previous memory m and question q. features get by take: element-wise,matmul and absolute distance of q with c, and q with m.
B. Mecanismo de Atualização da Memória: Tire a frase do candidato, o portão e o estado oculto anterior, ele usa o Gated-Gru para atualizar o estado oculto. Como: h = f (c, h_previous, g). O estado oculto final é a entrada para o módulo de resposta.
C.NENCEDO para vários episódios ===> Inferência transitiva.
Por exemplo, pergunte onde está o futebol? Ele atenderá à sentença de "John With the Football"), depois no segundo passe, ele precisa participar da localização de John.
4.Swer Módulo: Pegue a memória epsoídica final, a pergunta, ele atualiza o Módulo de Estado de Resposta oculto.
1. Redes convolucionais no nível do caráter para classificação de texto
2. Redes neurais Convolucionárias para Categorização de Texto: Nível de Palavra rasa versus nível de caráter profundo
3. Redes convolucionais muito profundas para classificação de texto
4. Métodos de treinamento adversário para classificação de texto semi-supervisionada
5.ENSEMBLE MODELOS
Durante o processo de fazer grande escala de classificação de vários rótulos, as aulas de servidor foram aprendidas e alguma lista como abaixo:
Qual é a coisa mais importante para alcançar uma alta precisão? Depende da tarefa que você está executando. A partir da tarefa que conduzimos aqui, acreditamos que os modelos de conjunto com base em modelos treinados a partir de vários recursos, incluindo palavras, caráter para título e descrição, podem ajudar a atingir um accuarcy muito alto; No entanto, em alguns casos, como apenas o AlphaGo Zero demonstrou, o algoritmo é mais importante do que os dados ou o poder computacional, na verdade, o AlphaGo Zero não usou dados Humam.
Existe um teto para qualquer modelo ou algoritmo específico? A resposta é sim. Muitos modelos diferentes foram usados aqui, descobrimos que muitos modelos têm performances semelhantes, embora existam estrutura bastante diferente. Em certa medida, a diferença de desempenho não é tão grande.
O estudo de caso de erro é útil? Eu acho que é bastante útil, especialmente quando você fez muitas coisas diferentes, mas atingiu um limite. Por exemplo, ao fazer estudo de caso, você pode encontrar rótulos que os modelos podem fazer previsão correta e onde eles cometem erros. E para importar o desempenho aumentando os pesos desses rótulos previstos errados ou encontrando possíveis erros a partir de dados.
Como podemos nos tornar especialistas em um aprendizado específico de máquina? Na minha opinião, participe de uma competição de aprendizado de máquina ou inicie uma tarefa com muitos dados, depois leia papéis e implemente alguns, é um bom ponto de partida. Portanto, teremos alguma experiência e idéias para lidar com tarefas específicas e conhecer os desafios dela. Mas o mais importante é que não apenas sigamos as idéias de artigos, mas também explorar algumas novas idéias que achamos que podem ajudar a relaxar o problema. Por exemplo, alterando estruturas de modelos clássicos ou até inventar algumas novas estruturas, podemos enfrentar o problema de uma maneira muito melhor, pois pode ser mais adequado para a tarefa que estamos realizando.
1.Bag de truques para classificação de texto eficiente
2. Redes neurais Convolucionárias para Classificação de Sentença
3.a Análise de sensibilidade do (e Guia de profissionais para) redes neurais convolucionais para classificação de sentenças
4. Aprendizagem para chatbots, parte 2-Implementando um modelo baseado em recuperação em Tensorflow, de www.wildml.com
5. Rede neural convolucional recorrente para classificação de texto
6. Redes de atenção hierárquica para classificação de documentos
7. Tradução de máquinas em nó, aprendendo em conjunto a alinhar e traduzir
8.TETENÇÃO É TUDO VOCÊ PRECISA
9.Asque -me qualquer coisa: redes de memória dinâmica para processamento de linguagem natural
10.Tracking o estado do mundo com redes de entidades recorrentes
11.Ensemble Seleção de bibliotecas de modelos
12.Bert: Pré-treinamento de profundos transformadores bidirecionais para entendimento de idiomas
13. Google-Research/Bert
continua. Para qualquer problema, Concat [email protected]


