BERT CH NER
1.0.0
基於tensorflow官方代碼修改。
Tensorflow: 1.13
Python: 3.6
tensorflow2.0 會報錯。
https://www.biendata.com/competition/sohu2019/
在搜狐這個文本比賽中寫了一個baseline,使用了bert以及bert+lstm+crf來進行實體識別。
其後只使用BERT的結果如下,具體評測方案請看比賽說明,這裡的話只做了實體部分,情感全部為POS進行的測試得分。

使用bert+lstm+crf 結果如下

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
在souhu文件下
因為在處理中文時,會有一些奇怪的符號,比如u3000等,需要你提前處理,否則label_id和inputs_id對應不上,因為bert自帶的tokenization會處理掉這些符號。所以可以使用bert自帶的BasicTokenizer來先將數據文本預處理一下從而與label對應上。
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])基於上課老師課程作業發布的中文數據集下使用BERT來訓練命名實體識別NER任務。
之前也用了Bi+LSTM+CRF進行識別,效果也不錯,這次使用BERT來進行訓練,也算是對BERT源碼進行一個閱讀和理解吧。
雖然之前網上也有很多使用BERT的例子和教程,但是我覺得都不是很完整,有些缺乏註釋對新手不太友好,有些則是問題不同修改的代碼也不同,自己也在路上遇到了不少的坑。所以記錄一下。
tmp 文件夾下
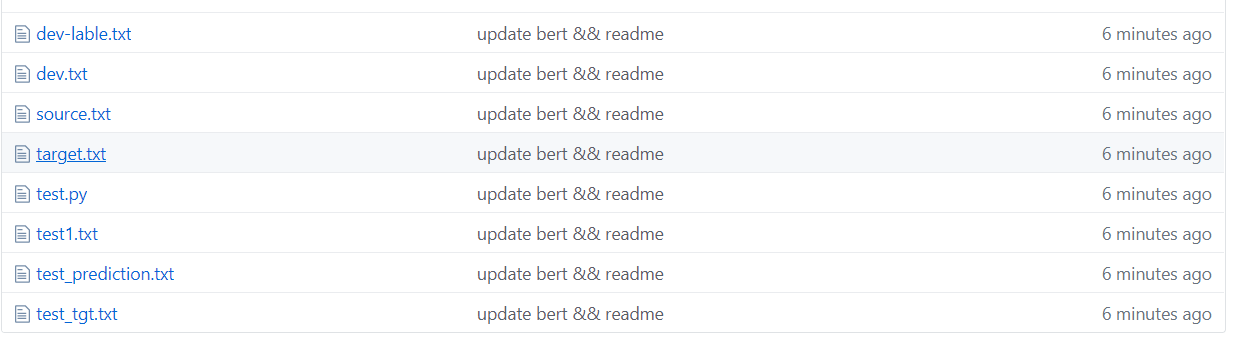
如上圖,對數據集進行了分割,其中source是訓練集中文,target是訓練集的label。
test1 測試集,test_tgt 測試集label。 dev 驗證集dev-lable 驗證集label。
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor BERT分詞器在對字符分詞會遇到一些問題。
比如輸入叩問澳門=- =- =- 賀澳門回歸進入倒計時,label :OO B-LOC I-LOC OOOO B-LOC I-LOC OOOOOOO
會把輸入的=- 處理成兩個字符,所以會導致label對應不上,需要手動處理一下。比如如下每次取第一個字符的label。 其實這個問題在處理英文會遇到,WordPiece會將一個詞分成若干token,所以需要手動處理(這只是一個簡單處理方式)。
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

其中共設置了10個類別,PAD是當句子長度未達到max_seq_length時,補充0的類別。
CLS是每個句首前加一個標誌[CLS]的類別,SEP是句尾同理。 (因為BERT處理句子是會在句首句尾加上這兩個符號。)
其實BERT需要根據具體的問題來修改相對應的代碼,NER算是序列標註一類的問題,可以算分類問題吧。
然後修改的主要是run_classifier.py部分即可,我把修改下游任務後的代碼放到了run_NER.py裡。
代碼中除了數據部分的預處理之外,還需要自己修改一下評估函數、損失函數。
首先下載BERT基於中文預訓練的模型(BERT官方github頁面可下載),存放到BERT_BASE_DIR文件夾下,之後將數據放到NER_DIR文件夾下。即可開始訓練。 sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
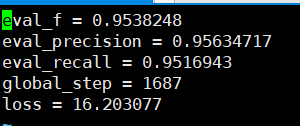
可以基於驗證集看到的準確率召回率都在95%以上。
下面可以看看預測測試集的幾個例子。

下圖為使用BERT預測的類別。可以與真實的類別對比看到預測還是很準確的。

真實類別如下圖。

其實在讀了BERT的論文後,結合代碼進行下游任務的微調能夠理解的更深刻。
其實改造下游任務主要是把自己數據改造成它們需要的格式,然後將輸出類別根據需要改一下,然後修改一下評估函數和損失函數。
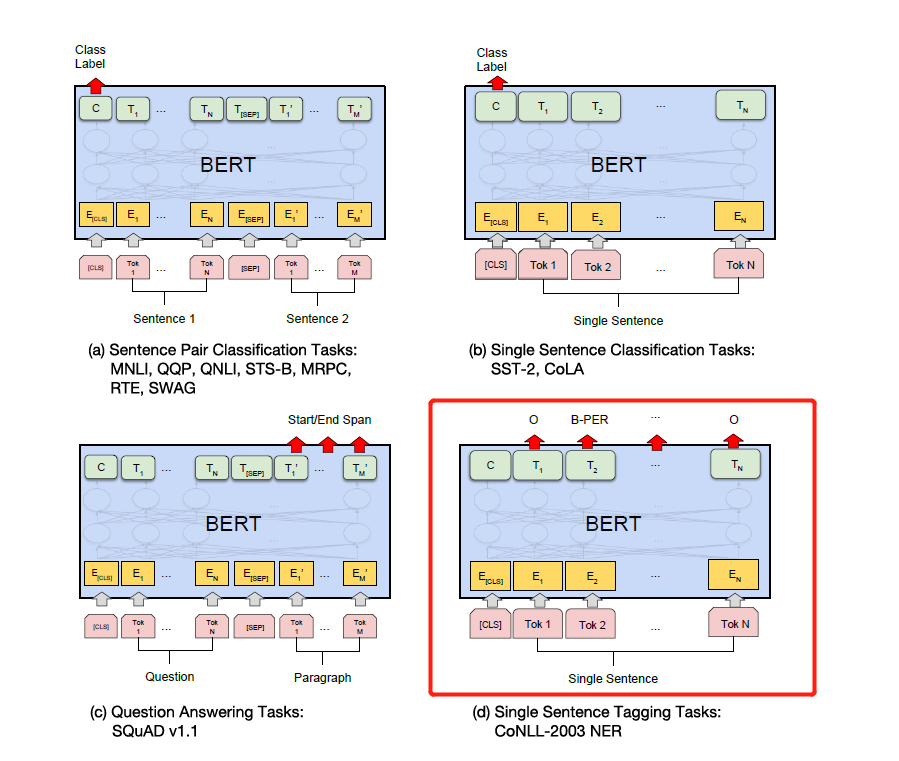
如下圖根據具體的下游任務修改label即可。如下圖的第四個就是在NER上進行修改,
之後會寫一篇Attention is all you need 和bert論文的詳解,會結合代碼來解釋一下細節,比如Add & Norm是如何實現的,為什麼要Add & Norm。 == 感覺不用寫了bert已經火遍大街了不重複造輪子了。建議大家直接莽源代碼和論文。
最後BERT還有很多奇淫技巧需要大家來探索。 。比如可以取中間層向量來拼接,再比如凍結中間層等等。
後來自己又用pytorch版本的BERT做了幾個比賽和做實驗發論文,個人覺得pytorch版本的bert更簡單好用,更方便的凍結BERT中間層,還可以在訓練過程中梯度累積,直接繼承BERTmodel就可以寫自己的模型了。
(自己用pytorch又做了NER的BERT實驗,想開源但是懶得整理....哪天閒了再開源吧ps 網上已經一大堆開源了233)
pytorch真香..改起來比tensorflow簡單多了..
個人建議如果自己做比賽或者發論文做實驗用pytorch版本.. pytorch已經在學術界稱霸了..但是工業界tensorflow還是應用很廣。
參考:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/BERT-NER
https://github.com/huggingface/transformers pytorch版本
留坑,哈哈讀讀論文看看代碼去。
https://mp.weixin.qq.com/s/29y2bg4KE-HNwsimD3aauw
https://github.com/zihangdai/xlnet
好吧前幾天又看見了谷歌開源的T5模型,從XLNet、RoBERTa、ALBERT、SpanBERT發展到現在T5....根本頂不住.. 現在NLP比賽基本也都被預訓練霸榜了..不用預訓練根本拿不到好成績...


