BERT CH NER
1.0.0
Modifié en fonction du code TensorFlow officiel.
TensorFlow: 1.13
Python: 3.6
Tensorflow2.0 rapportera une erreur.
https://www.biendata.com/competition/sohu2019/
Dans ce concours de texte de SOHU, une ligne de base a été écrite, en utilisant Bert et Bert + LSTM + CRF pour la reconnaissance des entités.
Les résultats de l'utilisation uniquement de Bert sont les suivants. Veuillez consulter la description du concours pour le plan d'évaluation spécifique. Ici, seule la partie physique est terminée, et toutes les émotions sont les scores de test réalisés par POS.

Le résultat est le suivant en utilisant Bert + LSTM + CRF

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Sous le fichier Souhu
Parce que lorsque vous traitez avec le chinois, il y aura des symboles étranges, tels que u3000, etc., que vous devez traiter à l'avance, sinon Label_id et Inputs_id ne correspondra pas, car la tokenisation apportée par BET traitera ces symboles. Par conséquent, vous pouvez utiliser le BasicTokensizer qui est livré avec BET pour prétraiter d'abord le texte des données pour correspondre à l'étiquette.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])Bert est utilisé pour former des entités nommées pour reconnaître les tâches NER basées sur l'ensemble de données chinois publié par les cours de l'enseignant.
J'ai utilisé BI + LSTM + CRF pour la reconnaissance auparavant, et l'effet était également bon. Cette fois, j'ai utilisé Bert pour la formation, qui peut être considéré comme la lecture et la compréhension du code source Bert.
Bien qu'il y ait eu de nombreux exemples et tutoriels sur l'utilisation de Bert auparavant, je ne pense pas que ce soit très complet. Un peu de commentaires n'est pas très amical avec les novices, et certains ont des problèmes différents. Différents codes sont modifiés. J'ai rencontré de nombreux pièges sur la route. Alors enregistrez-le.
Sous le dossier TMP
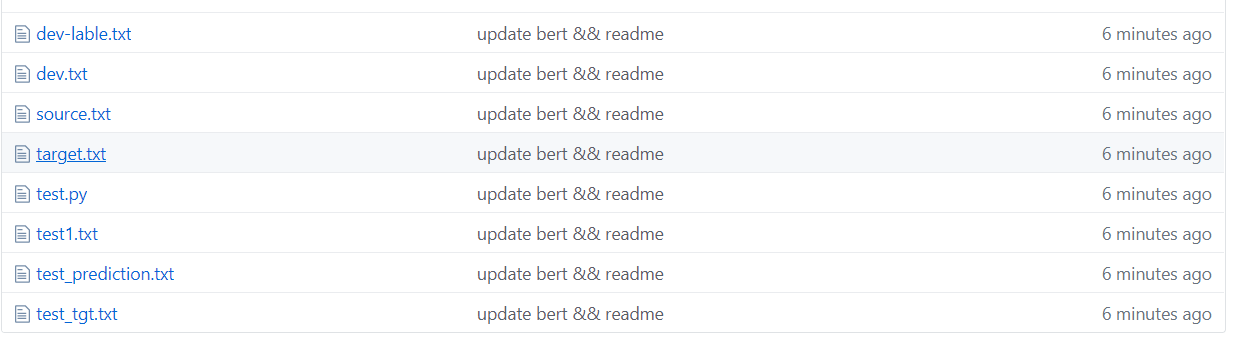
Comme le montre la figure ci-dessus, l'ensemble de données est segmenté, où la source est le texte de l'ensemble de formation et de la cible est l'étiquette de l'ensemble de formation.
Test1 Test Set, Test_TGT Test Set Label. Définir l'étiquette du jeu de validation de dévalage de développement.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor Le participe Bert Word rencontrera quelques problèmes en ce qui concerne les participes des mots de caractère.
Par exemple, entrée et question MacaU = - = - = - Félicitations au retour de Macau au compte à rebours, étiquette: oo b-loc-loc ooooo b-loc-loc oooooooo
L'entrée = - sera traité en deux caractères, de sorte que l'étiquette ne correspondra pas et ne doit pas être traitée manuellement. Par exemple, prenez l'étiquette du premier caractère à chaque fois comme suit. En fait, ce problème sera rencontré lorsqu'il s'agit de l'anglais. La pièce de bouche divisera un mot en plusieurs jetons, il doit donc être traité manuellement (ce n'est qu'un moyen simple de le faire face).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

Il y a 10 catégories au total, et le pad est la catégorie qui complète 0 lorsque la longueur de la phrase n'atteint pas max_seq_length.
CLS est la catégorie où un drapeau [CLS] est ajouté avant le début de chaque phrase, et SEP est le même que la fin de la phrase. (Parce que Bert ajoutera ces deux symboles au début et à la fin de la phrase.)
En fait, Bert doit modifier le code correspondant en fonction de problèmes spécifiques. NER est considéré comme un problème de marquage de séquence, qui peut être considéré comme un problème de classification.
Ensuite, la partie principale de la modification est le run_classifier.py. J'ai mis le code après avoir modifié la tâche en aval dans run_ner.py.
En plus du prétraitement de la pièce de données, vous devez également modifier vous-même la fonction d'évaluation et la fonction de perte.
Tout d'abord, téléchargez le modèle Bert basé sur le chinois pré-formé (la page officielle Bert Github peut être téléchargée), la stocker dans le dossier Bert_Base_Dir, puis mettre les données dans le dossier NER_DIR. Vous pouvez commencer à vous entraîner. sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
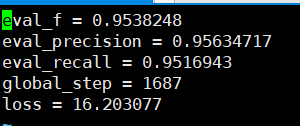
Les rappels de précision qui peuvent être vus sur la base de l'ensemble de vérification sont tous supérieurs à 95%.
Voici quelques exemples de l'ensemble de tests de prédiction.

La figure suivante montre les catégories prédites à l'aide de Bert. Il est toujours très précis de voir que la prédiction peut être comparée à la catégorie réelle.

La catégorie réelle est indiquée ci-dessous.

En fait, après avoir lu le papier de Bert, vous pouvez comprendre plus profondément en combinant le code pour affiner les tâches en aval.
En fait, la tâche en aval consiste à transformer vos données au format dont ils ont besoin, puis à modifier la catégorie de sortie au besoin, puis à modifier la fonction d'évaluation et la fonction de perte.
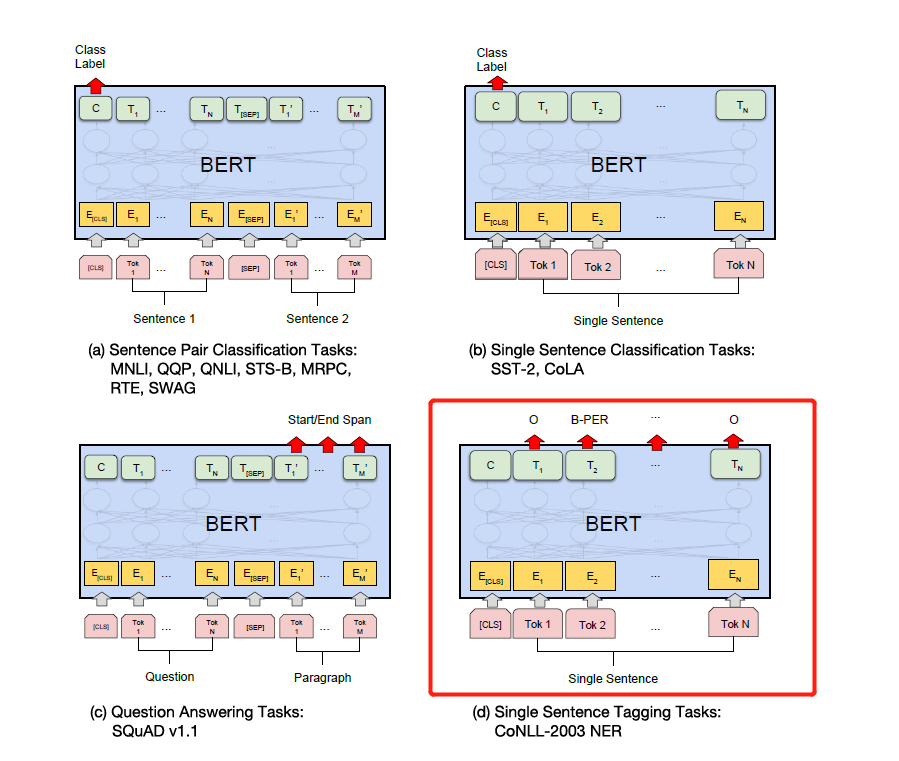
Modifiez simplement l'étiquette en fonction des tâches en aval spécifiques dans la figure ci-dessous. Le quatrième dans la figure ci-dessous est de le modifier sur NER.
Plus tard, j'écrirai une explication détaillée de l'attention est tout ce dont vous avez besoin et du papier Bert, et je vais expliquer les détails en combinaison avec le code, tels que la façon dont Add & Norm est implémenté et pourquoi Add & Norm est nécessaire. == J'ai l'impression de ne plus avoir besoin de l'écrire. Bert est devenu populaire dans les rues et je ne ferai pas de roues répétées. Nous vous recommandons de vous procurer directement du code et du papier.
Enfin, il existe de nombreuses techniques étranges et érotiques à explorer. . Par exemple, vous pouvez prendre des vecteurs de couche intermédiaire pour épisser, puis geler les couches intermédiaires, etc.
Plus tard, j'ai utilisé la version Pytorch de Bert pour faire plusieurs compétitions et expériences pour publier des articles. Je pense personnellement que la version Pytorch de Bert est plus simple et plus facile à utiliser, et il est plus pratique de geler la couche intermédiaire de Bert. Il peut également accumuler des gradients pendant le processus de formation. Vous pouvez hériter directement du modèle Bert et écrire votre propre modèle.
(J'ai utilisé Pytorch pour faire l'expérience Bert de NER. Je veux open source mais je suis trop paresseux pour le régler ... Je vais open source un jour quand je serai libre. Il y a déjà beaucoup d'open source sur Internet. 233 déjà)
Pytorch est tellement délicieux ... c'est beaucoup plus simple à modifier que TensorFlow ...
Je recommande personnellement que si vous faites des compétitions ou publiez des articles et des expériences, utilisez la version Pytorch. Pytorch a dominé le monde académique. Cependant, Tensorflow dans l'industrie est encore largement utilisé.
se référer à:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformateurs version pytorch
Laissez une fosse, haha, lisez le papier et lisez le code.
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
Eh bien, il y a quelques jours, j'ai vu le modèle T5 open source de Google, de XLNET, Roberta, Albert, Spanbert à T5 maintenant ... Je ne peux pas le supporter du tout ... Maintenant, les compétitions NLP sont essentiellement dominées par la pré-formation ... Je ne peux pas obtenir de bons résultats sans pré-formation ...


