BERT CH NER
1.0.0
Modificado com base no código oficial do tensorflow.
Tensorflow: 1.13
Python: 3.6
Tensorflow2.0 relatará um erro.
https://www.biendata.com/competition/sohu2019/
Nesta competição de texto de Sohu, uma linha de base foi escrita, usando Bert e Bert+LSTM+CRF para reconhecimento de entidades.
Os resultados do uso apenas de Bert são os seguintes. Consulte a descrição da competição para o plano de avaliação específico. Aqui, apenas a parte física é feita e todas as emoções são as pontuações dos testes realizadas pelo POS.

O resultado é o seguinte usando o BERT+LSTM+CRF

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Sob o arquivo Souhu
Porque ao lidar com chinês, haverá alguns símbolos estranhos, como u3000, etc., que você precisa processar com antecedência, caso contrário, etiquetas_id e inputs_id não corresponderão, porque a tokenização trazida pela BET processará esses símbolos. Portanto, você pode usar o Basictenizer que vem com a BET para pré -processar o texto dos dados primeiro para corresponder ao rótulo.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])Bert é usado para treinar entidades nomeadas para reconhecer tarefas NER com base no conjunto de dados chinês publicado pelos cursos do professor.
Eu usei o BI+LSTM+CRF para reconhecimento antes, e o efeito também foi bom. Desta vez, usei Bert para treinamento, que pode ser considerado como leitura e compreensão do código -fonte Bert.
Embora houvesse muitos exemplos e tutoriais sobre o uso de Bert antes, acho que não está muito completo. Alguma falta de comentários não é muito amigável para os novatos, e outros têm problemas diferentes. Códigos diferentes são modificados. Eu encontrei muitas armadilhas na estrada. Então grave.
Sob a pasta TMP
Conforme mostrado na figura acima, o conjunto de dados é segmentado, onde a fonte é o texto no conjunto de treinamento e o destino é o rótulo do conjunto de treinamento.
TEST1 Conjunto de testes, Test_TGT Test Set Set Label. Definir Definir Definir o rótulo do conjunto de validação de dev-lable.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor O particípio da palavra bert encontrará alguns problemas quando se trata de particípios de palavras de personagem.
Por exemplo, entrada e pergunta macau =-=-=-Parabéns ao retorno de Macau à contagem regressiva, etiqueta: oo B-Loc i-Loc ooooo B-Loc i-Loc oooooooo
O input =- será processado em dois caracteres, para que o rótulo não corresponda e precisará ser processado manualmente. Por exemplo, pegue o rótulo do primeiro caractere a cada vez. De fato, esse problema será encontrado ao lidar com o inglês. A palavra -palavra dividirá uma palavra em vários tokens, por isso precisa ser processado manualmente (essa é apenas uma maneira simples de lidar com isso).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

Existem 10 categorias no total, e o PAD é a categoria que complementa 0 quando o comprimento da frase não atinge o max_seq_length.
CLS é a categoria em que um sinalizador [CLS] é adicionado antes do início de cada frase e o SEP é o mesmo que o final da frase. (Porque Bert adicionará esses dois símbolos ao início e no final da frase.)
De fato, Bert precisa modificar o código correspondente com base em problemas específicos. O NER é considerado um problema de marcação de sequência, que pode ser considerado um problema de classificação.
Em seguida, a parte principal da modificação é o run_classifier.py. Coloquei o código depois de modificar a tarefa a jusante em run_ner.py.
Além de pré -processamento da parte dos dados, você também precisa modificar a função de avaliação e a perda de perda.
Primeiro, faça o download do modelo Bert com base no chinês pré-treinado (a página oficial do Bert Github pode ser baixada), armazene-o na pasta Bert_base_dir e, em seguida, coloque os dados na pasta NER_DIR. Você pode começar a treinar. sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
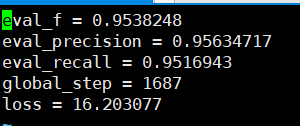
A precisão recalls que podem ser vistos com base no conjunto de verificação estão acima de 95%.
Aqui estão alguns exemplos do conjunto de testes de previsão.

A figura a seguir mostra as categorias previstas usando Bert. Ainda é muito preciso ver que a previsão pode ser comparada com a categoria real.

A categoria real é mostrada abaixo.

De fato, depois de ler o artigo de Bert, você pode entender mais profundamente combinando o código para ajustar as tarefas a jusante.
De fato, a tarefa a jusante é transformar seus dados no formato de que precisam e alterar a categoria de saída conforme necessário e modificar a função de avaliação e a função de perda.
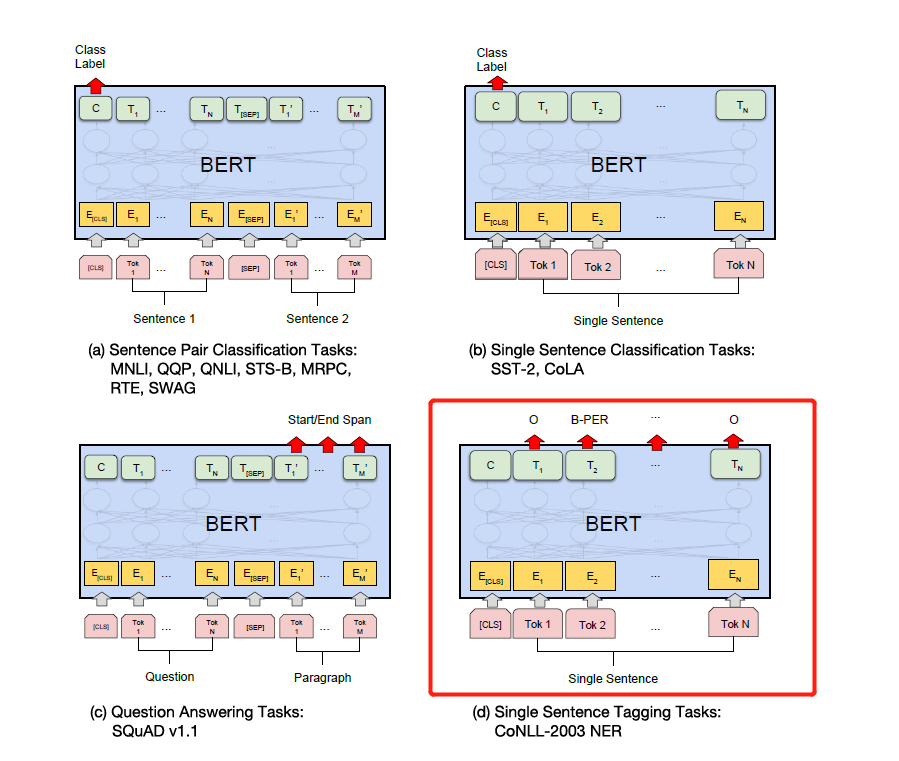
Basta modificar o rótulo de acordo com as tarefas específicas a jusante na figura abaixo. O quarto na figura abaixo é modificá -lo no NER.
Mais tarde, escreverei uma explicação detalhada da atenção é tudo o que você precisa e o papel Bert, e explicarei os detalhes em combinação com o código, como como a ADD & NORM é implementada e por que a ADD & NORM é necessária. == Sinto que não preciso mais escrever. Bert se tornou popular em todas as ruas e não vou fazer rodas repetidas. Recomendamos que você diretamente o código e o papel.
Finalmente, existem muitas técnicas estranhas e eróticas para Bert explorar. . Por exemplo, você pode levar vetores de camada intermediária para emendar e depois congelar camadas intermediárias, etc.
Mais tarde, usei a versão Pytorch de Bert para fazer várias competições e experimentos para publicar artigos. Pessoalmente, acho que a versão Pytorch do BERT é mais simples e mais fácil de usar, e é mais conveniente congelar a camada intermediária Bert. Também pode acumular gradientes durante o processo de treinamento. Você pode herdar diretamente o modelo Bert e escrever seu próprio modelo.
(Eu usei Pytorch para fazer o experimento de Bert do NER. Quero abrir o código -fonte, mas estou com preguiça de resolver isso ... vou abrir o código um dia quando estou livre. Já existem muito código aberto na internet. 233 já)
Pytorch é tão delicioso ... é muito mais simples de modificar do que o tensorflow ...
Pessoalmente, recomendo que, se você fizer competições ou publicar artigos e experimentos, use a versão Pytorch. Pytorch dominou o mundo acadêmico. No entanto, o tensorflow no setor ainda é amplamente utilizado.
Consulte:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers pytorch versão
Deixe um poço, haha, leia o artigo e leia o código.
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
Bem, alguns dias atrás, vi o modelo T5 de código aberto do Google, de XLNet, Roberta, Albert, Spanbert para T5 agora ... Não consigo suportar nada ... Agora, as competições de PNL são basicamente dominadas pelo pré-treinamento ... Não consigo obter bons resultados sem pré-treinamento ...


