BERT CH NER
1.0.0
Dimodifikasi berdasarkan kode TensorFlow resmi.
TensorFlow: 1.13
Python: 3.6
TensorFlow2.0 akan melaporkan kesalahan.
https://www.biendata.com/competition/sohu2019/
Dalam kompetisi teks SOHU ini, garis dasar ditulis, menggunakan Bert dan Bert+LSTM+CRF untuk pengakuan entitas.
Hasil menggunakan hanya Bert adalah sebagai berikut. Silakan lihat deskripsi kompetisi untuk rencana evaluasi spesifik. Di sini, hanya bagian fisik yang dilakukan, dan semua emosi adalah nilai ujian yang dilakukan oleh POS.

Hasilnya adalah sebagai berikut menggunakan Bert+LSTM+CRF

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Di bawah file souhu
Karena ketika berhadapan dengan orang Cina, akan ada beberapa simbol aneh, seperti u3000, dll., Yang perlu Anda proses terlebih dahulu, jika tidak label_id dan inputs_id tidak akan sesuai, karena tokenisasi yang dibawa oleh BET akan memproses simbol -simbol ini. Oleh karena itu, Anda dapat menggunakan basictokenizer yang dilengkapi dengan taruhan untuk preprocess teks data terlebih dahulu untuk sesuai dengan label.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])Bert digunakan untuk melatih entitas bernama untuk mengenali tugas -tugas NER berdasarkan dataset Cina yang diterbitkan oleh kursus guru.
Saya menggunakan BI+LSTM+CRF untuk pengakuan sebelumnya, dan efeknya juga baik. Kali ini saya menggunakan Bert untuk pelatihan, yang dapat dianggap membaca dan memahami kode sumber Bert.
Meskipun ada banyak contoh dan tutorial tentang penggunaan Bert sebelumnya, saya tidak berpikir itu sangat lengkap. Beberapa kurangnya komentar tidak terlalu ramah kepada pemula, dan beberapa memiliki masalah yang berbeda. Kode yang berbeda dimodifikasi. Saya telah menemukan banyak jebakan di jalan. Jadi rekam.
Di bawah folder TMP
Seperti yang ditunjukkan pada gambar di atas, set data tersegmentasi, di mana sumber adalah teks dalam set pelatihan dan target adalah label set pelatihan.
Test1 Test Set, Test_tgt Test Set Label. set validasi dev label set validasi-lable validasi.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor Bert Word Participle akan menghadapi beberapa masalah ketika datang ke karakter participles.
Misalnya, input dan pertanyaan macau =-=-=-Selamat untuk kembalinya Macau ke hitungan mundur, label: oo b-loc i-loc oooooo b-loc i-loc ooooooooo
Input =- akan diproses menjadi dua karakter, sehingga label tidak akan sesuai dan perlu diproses secara manual. Misalnya, ambil label karakter pertama setiap kali sebagai berikut. Bahkan, masalah ini akan ditemui saat berhadapan dengan bahasa Inggris. Wordpiece akan membagi satu kata menjadi beberapa token, sehingga perlu diproses secara manual (ini hanya cara sederhana untuk menghadapinya).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

Ada 10 kategori secara total, dan PAD adalah kategori yang melengkapi 0 ketika panjang kalimat tidak mencapai max_seq_length.
CLS adalah kategori di mana bendera [CLS] ditambahkan sebelum awal setiap kalimat, dan SEP sama dengan akhir kalimat. (Karena Bert akan menambahkan dua simbol ini ke awal dan akhir kalimat.)
Bahkan, Bert perlu memodifikasi kode yang sesuai berdasarkan masalah tertentu. NER dianggap sebagai masalah pelabelan urutan, yang dapat dianggap sebagai masalah klasifikasi.
Maka bagian utama dari modifikasi adalah run_classifier.py. Saya meletakkan kode setelah memodifikasi tugas hilir di run_ner.py.
Selain preprocessing bagian data, Anda juga perlu memodifikasi fungsi evaluasi dan fungsi kerugian sendiri.
Pertama, unduh model Bert berdasarkan pra-terlatih Cina (halaman resmi Bert GitHub dapat diunduh), menyimpannya di folder Bert_base_dir, dan kemudian memasukkan data di folder NER_DIR. Anda bisa memulai pelatihan. sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
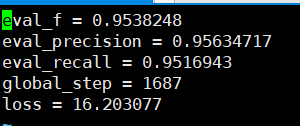
Keakuratan penarikan yang dapat dilihat berdasarkan set verifikasi semuanya di atas 95%.
Berikut adalah beberapa contoh dari set tes prediksi.

Gambar berikut menunjukkan kategori yang diprediksi menggunakan Bert. Masih sangat akurat untuk melihat bahwa prediksi dapat dibandingkan dengan kategori nyata.

Kategori sebenarnya ditunjukkan di bawah ini.

Bahkan, setelah membaca Makalah Bert, Anda dapat memahami lebih dalam dengan menggabungkan kode untuk menyempurnakan tugas hilir.
Faktanya, tugas hilir adalah mengubah data Anda menjadi format yang mereka butuhkan, kemudian ubah kategori output sesuai kebutuhan, dan kemudian memodifikasi fungsi evaluasi dan fungsi kerugian.
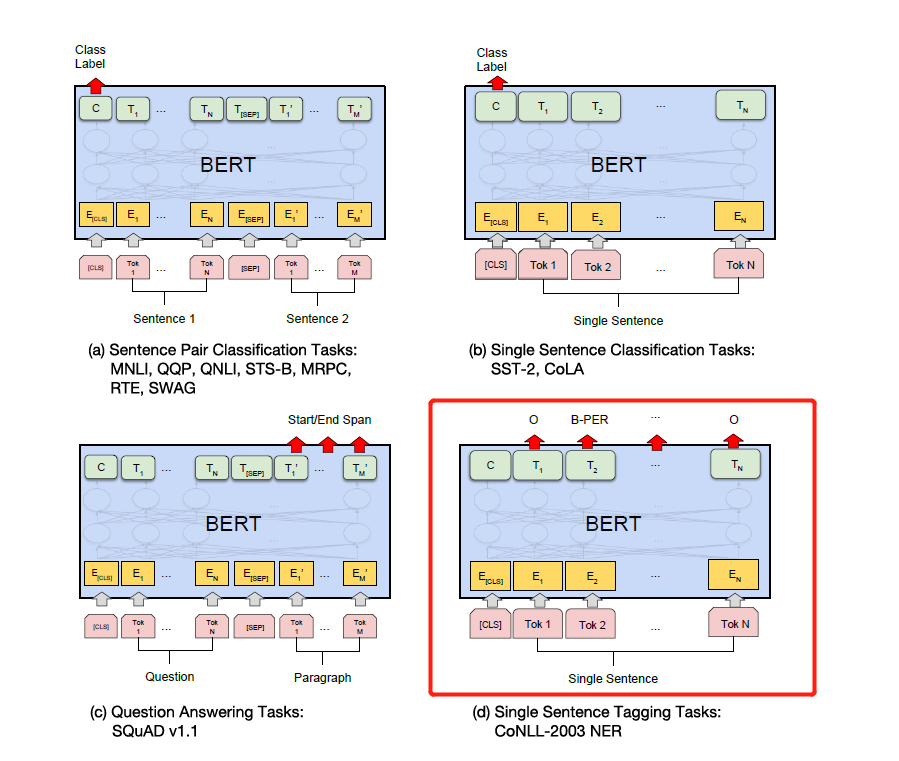
Cukup ubah label sesuai dengan tugas hilir spesifik pada gambar di bawah ini. Yang keempat pada gambar di bawah ini adalah untuk memodifikasinya di NER.
Nanti, saya akan menulis penjelasan terperinci tentang perhatian adalah semua yang Anda butuhkan dan kertas Bert, dan saya akan menjelaskan detail dalam kombinasi dengan kode, seperti bagaimana Add & Norm diterapkan dan mengapa Add & Norm diperlukan. == Saya merasa tidak perlu menulisnya lagi. Bert telah menjadi populer di seluruh jalan dan saya tidak akan membuat roda berulang. Kami menyarankan Anda sumber dan kertas secara langsung.
Akhirnya, ada banyak teknik aneh dan erotis untuk dijelajahi Bert. . Misalnya, Anda dapat menggunakan vektor lapisan menengah untuk menyambungkan, dan kemudian membekukan lapisan perantara, dll.
Kemudian, saya menggunakan versi Pytorch dari Bert untuk melakukan beberapa kompetisi dan eksperimen untuk menerbitkan makalah. Saya pribadi berpikir bahwa versi Pytorch dari Bert lebih sederhana dan lebih mudah digunakan, dan lebih nyaman untuk membekukan lapisan perantara Bert. Ini juga dapat mengumpulkan gradien selama proses pelatihan. Anda dapat secara langsung mewarisi model Bert dan menulis model Anda sendiri.
(Saya menggunakan pytorch untuk melakukan eksperimen NER.
Pytorch sangat lezat ... jauh lebih sederhana untuk dimodifikasi daripada tensorflow ...
Saya pribadi merekomendasikan bahwa jika Anda melakukan kompetisi atau mempublikasikan makalah dan eksperimen, gunakan versi Pytorch .. Pytorch telah mendominasi dunia akademik. Namun, TensorFlow dalam industri ini masih banyak digunakan.
Lihat:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers versi pytorch
Tinggalkan lubang, haha, baca koran dan baca kodenya.
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
Nah, beberapa hari yang lalu, saya melihat model T5 open source Google, dari Xlnet, Roberta, Albert, Spanbert ke T5 sekarang ... Saya tidak tahan sama sekali ... sekarang kompetisi NLP pada dasarnya didominasi oleh pra-pelatihan ... Saya tidak bisa mendapatkan hasil yang baik tanpa pra-pelatihan ...


