BERT CH NER
1.0.0
Geändert basierend auf dem offiziellen TensorFlow -Code.
Tensorflow: 1.13
Python: 3.6
TensorFlow2.0 meldet einen Fehler.
https://www.biendata.com/competition/sohu2019/
In diesem Textwettbewerb von Sohu wurde eine Grundlinie unter Verwendung von Bert und Bert+LSTM+CRF zur Entitätserkennung geschrieben.
Die Ergebnisse der Verwendung von nur Bert sind wie folgt. Bitte beachten Sie die Wettbewerbsbeschreibung für den spezifischen Bewertungsplan. Hier ist nur der physische Teil durchgeführt, und alle Emotionen sind die von POS durchgeführten Testergebnisse.

Das Ergebnis ist wie folgt unter Verwendung von Bert+LSTM+CRF wie folgt

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Unter der Souhu -Datei
Denn im Umgang mit Chinesen gibt es einige seltsame Symbole wie u3000 usw., die Sie im Voraus verarbeiten müssen, ansonsten label_id und Inputs_id entspricht nicht, da die von Wette mitgelieferte Tokenisierung diese Symbole verarbeitet. Daher können Sie den Basictokenizer verwenden, der mit Wette geliefert wird, um den Datentext zuerst vorzubereiten, um dem Etikett zu entsprechen.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])Bert wird verwendet, um benannte Entitäten zu trainieren, um NER -Aufgaben basierend auf dem chinesischen Datensatz zu erkennen, das von den Lehrerkursen veröffentlicht wurde.
Ich habe zuvor Bi+LSTM+CRF zur Erkennung verwendet, und der Effekt war auch gut. Dieses Mal habe ich Bert zum Training verwendet, das als Lesen und Verständnis des Bert -Quellcodes angesehen werden kann.
Obwohl es schon viele Beispiele und Tutorials zur Verwendung von Bert gab, denke ich nicht, dass es sehr vollständig ist. Einige mangelnde Kommentare sind nicht sehr freundlich gegenüber Anfängern, und einige haben unterschiedliche Probleme. Verschiedene Codes werden geändert. Ich habe viele Fallstricke auf der Straße gestoßen. Also zeichne es auf.
Unter dem TMP -Ordner
Wie in der obigen Abbildung gezeigt, ist der Datensatz segmentiert, wobei Quelle der Text im Trainingssatz und das Ziel der Beschriftung des Trainingssatzes ist.
Test1 -Testsatz, test_tgt Test Set Label. Dev Validation Set Dev-Lable Validierungssatzetikett.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor Das Partizip -Wort -Wort wird auf einige Probleme stoßen, wenn es um Partizipte von Charakteren geht.
Zum Beispiel Eingabe und Frage Macau =-=-=-Herzlichen Glückwunsch an Macaus Rückkehr zum Countdown, Label: oo b-loc i-loc ooooo b-loc i-loc oooooooo
Die Eingabe =- wird in zwei Zeichen verarbeitet, sodass das Etikett nicht entspricht und manuell verarbeitet werden muss. Nehmen Sie beispielsweise jedes Mal wie folgt das Etikett des ersten Zeichens. Tatsächlich wird dieses Problem beim Umgang mit Englisch auftreten. Das Wortstück teilt ein Wort in mehrere Token, sodass es manuell verarbeitet werden muss (dies ist nur eine einfache Möglichkeit, damit umzugehen).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

Insgesamt gibt es 10 Kategorien, und Pad ist die Kategorie, die 0 ergänzt, wenn die Satzlänge nicht max_seq_length erreicht.
CLS ist die Kategorie, in der ein Flag [CLS] vor Beginn jedes Satzes hinzugefügt wird, und SEP ist das gleiche wie das Ende des Satzes. (Weil Bert diese beiden Symbole zu Beginn und Ende des Satzes hinzufügt.)
Tatsächlich muss Bert den entsprechenden Code basierend auf bestimmten Problemen ändern. NER wird als Problem der Sequenzmarkierung angesehen, das als Klassifizierungsproblem angesehen werden kann.
Dann ist der Hauptteil der Modifikation der run_classifier.py. Ich habe den Code nach der Änderung der nachgeschalteten Aufgabe in run_ner.py eingesetzt.
Zusätzlich zur Vorverarbeitung des Datenteils müssen Sie auch die Funktions- und Verlustfunktion selbst ändern.
Laden Sie zunächst das Bert-Modell basierend auf chinesischen vorgebreiteten (offiziellen Bert Github-Seite herunter), speichern Sie es im Ordner BERT_BASE_DIR und legen Sie die Daten in den Ordner ner_dir. Sie können mit dem Training beginnen. sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
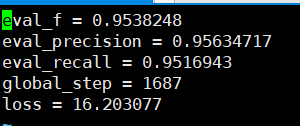
Die Genauigkeit erinnert sich an, die basierend auf dem Bestätigungssatz zu sehen sind, alle über 95%.
Hier sind einige Beispiele für den Vorhersage -Testsatz.

Die folgende Abbildung zeigt die mit Bert vorhergesagten Kategorien. Es ist immer noch sehr genau festgestellt, dass die Vorhersage mit der realen Kategorie verglichen werden kann.

Die reale Kategorie ist unten gezeigt.

Nach dem Lesen von Berts Papier können Sie den Code tiefer verstehen, indem Sie die nachgelagerten Aufgaben feinstimmen.
Tatsächlich besteht die nachgeschaltete Aufgabe darin, Ihre Daten in das von ihnen benötigte Format umzuwandeln, dann die Ausgangskategorie nach Bedarf zu ändern und dann die Funktions- und Verlustfunktion zu ändern.
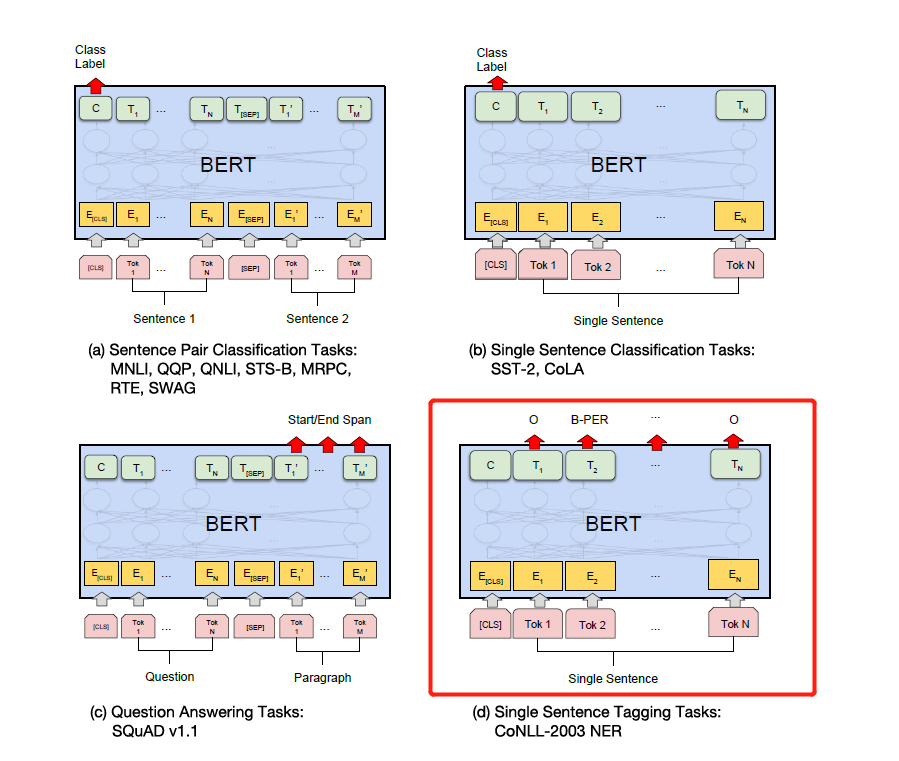
Ändern Sie einfach die Beschriftung gemäß den spezifischen nachgeschalteten Aufgaben in der folgenden Abbildung. Der vierte in der folgenden Abbildung besteht darin, es auf NER zu ändern.
Später werde ich eine detaillierte Erklärung der Aufmerksamkeit schreiben, die Sie benötigen, und Bert Paper, und ich werde die Details in Kombination mit dem Code erläutern, z. B. wie Add & Norm implementiert wird und warum Add & Norm benötigt wird. == Ich habe das Gefühl, dass ich es nicht mehr schreiben muss. Bert ist auf der ganzen Straßen beliebt geworden und ich werde keine wiederholten Räder machen. Wir empfehlen Ihnen, Code und Papier direkt zu beschreiben.
Schließlich gibt es viele seltsame und erotische Techniken, die Bert erforschen kann. . Zum Beispiel können Sie Zwischenschichtvektoren zum Spleißen nehmen und dann Zwischenschichten usw. einfrieren, usw.
Später habe ich die Pytorch -Version von Bert verwendet, um mehrere Wettbewerbe und Experimente zu veröffentlichen, um Papiere zu veröffentlichen. Ich persönlich denke, dass die Pytorch -Version von Bert einfacher und einfacher zu bedienen ist, und es ist bequemer, die Bert -Zwischenschicht einzufrieren. Es kann auch Gradienten während des Trainingsprozesses sammeln. Sie können das Bert -Modell direkt erben und Ihr eigenes Modell schreiben.
(Ich habe Pytorch verwendet, um das Bert -Experiment von Ner durchzuführen. Ich möchte Open Source, aber ich bin zu faul, um es zu klären ... Ich werde eines Tages Open Source Open Source, wenn ich frei bin. Es gibt bereits viel Open Source im Internet. 233 bereits)
Pytorch ist so lecker ... es ist viel einfacher zu ändern als Tensorflow ...
Ich persönlich empfehle, dass, wenn Sie Wettbewerbe durchführen oder Papiere und Experimente veröffentlichen, die Pytorch -Version verwenden. Pytorch hat die akademische Welt dominiert. Tensorflow in der Branche ist jedoch immer noch weit verbreitet.
Siehe:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers pytorch Version
Lassen Sie eine Grube, haha, lesen Sie das Papier und lesen Sie den Code.
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
Nun, vor ein paar Tagen habe ich das Open Source T5-Modell von Google von XLNET, Roberta, Albert, Spanbert bis T5 jetzt gesehen ... Ich kann es überhaupt nicht ausstehen ... jetzt werden NLP-Wettbewerbe im Grunde genommen von der Voraussetzung dominiert ... Ich kann ohne Voraussetzung keine guten Ergebnisse erzielen, ohne vorzubereiten ...


