BERT CH NER
1.0.0
公式のTensorflowコードに基づいて変更されました。
Tensorflow:1.13
Python:3.6
Tensorflow2.0はエラーを報告します。
https://www.biendata.com/competition/sohu2019/
Sohuのこのテキスト競争では、BertとBert+LSTM+CRFを使用してエンティティ認識を使用して、ベースラインが書かれました。
BERTのみを使用した結果は次のとおりです。特定の評価計画の競争の説明をご覧ください。ここでは、物理的な部分のみが行われ、すべての感情はPOSによって実施されるテストスコアです。

結果は、BERT+LSTM+CRFを使用して次のとおりです

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Souhuファイルの下
中国語を扱う場合、事前に処理する必要がある u3000などの奇妙なシンボルがあるため、label_idとinputs_idは対応しません。したがって、BETに付属のBasictokenizerを使用して、最初にデータテキストを前処理してラベルに対応することができます。
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])Bertは、教師のコースワークが発行した中国のデータセットに基づいてNERタスクを認識するために、指名されたエンティティを訓練するために使用されます。
以前に認識するためにBi+LSTM+CRFを使用しましたが、その効果も良好でした。今回はBertを使用してトレーニングに使用しました。これは、Bertソースコードの読み取りと理解と見なすことができます。
以前にBertを使用することに関する多くの例とチュートリアルがありましたが、それが完全に完全だとは思いません。コメントの欠如は初心者にはそれほど友好的ではなく、いくつかの問題があります。さまざまなコードが変更されています。私は道路上の多くの落とし穴に遭遇しました。だからそれを記録してください。
TMPフォルダーの下
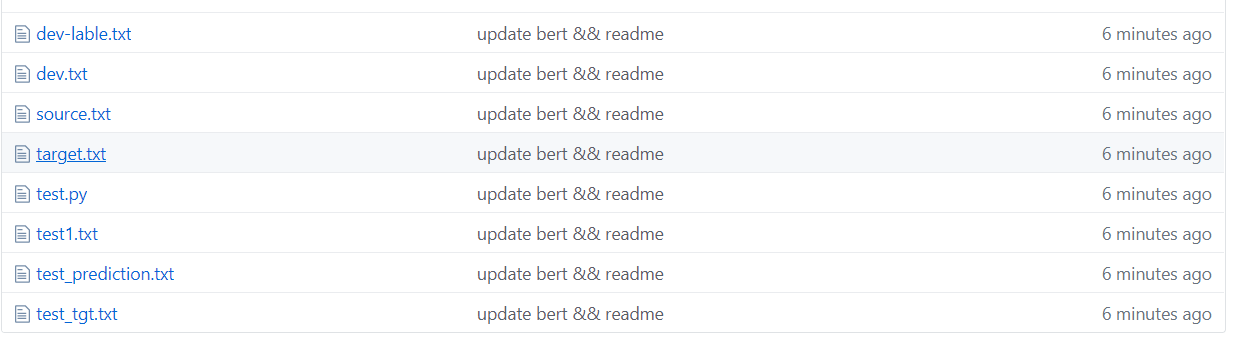
上の図に示すように、データセットはセグメント化されており、ソースはトレーニングセットのテキストであり、ターゲットはトレーニングセットのラベルです。
test1テストセット、test_tgtテストセットラベル。開発検証セット開発可能な検証セットラベル。
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor Bert Word分詞は、キャラクターワード分詞に関してはいくつかの問題に遭遇します。
たとえば、入力と質問Macau = - = - = - マカオのカウントダウンへの復帰、ラベル:OO B-LOC I-LOC OOOOO B-LOC I-LOC OOOOOOO
入力= - は2つの文字に処理されるため、ラベルは手動で処理する必要がなく、処理する必要があります。たとえば、次のように毎回最初のキャラクターのラベルを取ります。実際、この問題は英語を扱うときに発生します。 WordPieceは単語をいくつかのトークンに分割するため、手動で処理する必要があります(これは単純な方法です)。
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

合計には10のカテゴリがあり、パッドは、文の長さがmax_seq_lengthに達していない場合に0をサプリメントするカテゴリです。
CLSは、各文の開始前にフラグ[CLS]が追加されるカテゴリであり、SEPは文の終了と同じです。 (Bertがこれらの2つのシンボルを文の開始と終了に追加するからです。)
実際、Bertは特定の問題に基づいて対応するコードを変更する必要があります。 NERは、シーケンスラベル付けの問題と考えられており、分類問題と見なすことができます。
変更の主な部分はrun_classifier.pyです。 run_ner.pyのダウンストリームタスクを変更した後、コードを配置します。
データパーツの前処理に加えて、評価機能と損失関数を自分で変更する必要もあります。
まず、中国の事前訓練(公式Bert Githubページをダウンロードできます)に基づいてBERTモデルをダウンロードし、BERT_BASE_DIRフォルダーに保存してから、NER_DIRフォルダーにデータを配置します。トレーニングを開始できます。 sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
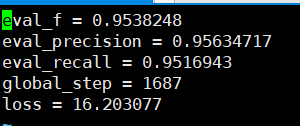
検証セットに基づいて見ることができる精度のリコールはすべて95%を超えています。
予測テストセットの例をいくつか紹介します。

次の図は、Bertを使用して予測されたカテゴリを示しています。予測を実際のカテゴリと比較できることを確認することは、まだ非常に正確です。

実際のカテゴリを以下に示します。

実際、Bertの論文を読んだ後、コードを組み合わせてダウンストリームタスクを微調整することで、より深く理解できます。
実際、ダウンストリームタスクは、データを必要に応じてデータを変更し、必要に応じて出力カテゴリを変更し、評価関数と損失関数を変更することです。
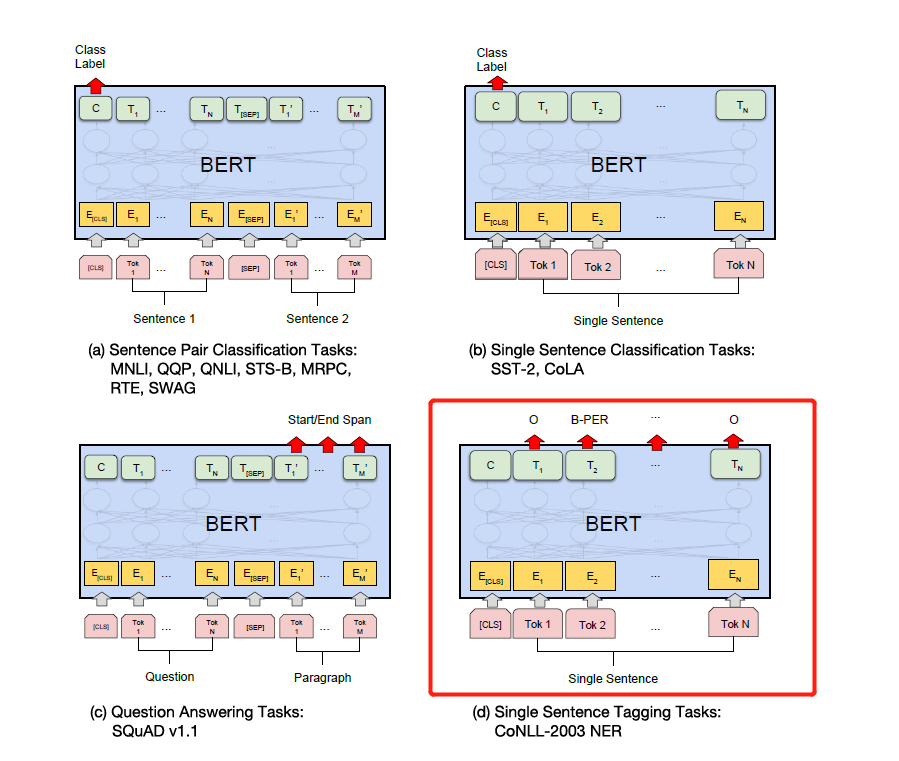
下の図の特定の下流タスクに従ってラベルを変更するだけです。下の図の4番目は、NERで変更することです。
後で、注意の詳細な説明を書きます。あなたが必要とするすべてとバートペーパーで、ADDとNORMの実装方法やADD&NORMが必要な理由など、コードと組み合わせて詳細を説明します。 ==もう書く必要がないと感じています。バートは路上で人気があり、私は繰り返しホイールを作りません。コードと紙を直接ソースすることをお勧めします。
最後に、バートが探求するための多くの奇妙でエロティックなテクニックがあります。 。たとえば、中間層ベクトルを使用してスプライスしてから、中間層などを凍結できます。
その後、PytorchバージョンのBertを使用して、いくつかの競技と実験を行い、論文を公開しました。個人的には、BertのPytorchバージョンはよりシンプルで使いやすく、Bert中級層を凍結する方が便利だと思います。また、トレーニングプロセス中に勾配を蓄積する可能性があります。 Bertモデルを直接継承して、独自のモデルを作成できます。
(私はPytorchを使用してNERのBERT実験を行いました。オープンソースを取りたいですが、私はそれを整理するにはあまりにも怠けています...私はいつか自由なときにオープンソースになります。すでにインターネットには多くのオープンソースがあります。233すでに)
Pytorchはとても美味しいです... Tensorflowよりも変更するのははるかに簡単です...
個人的には、競争をしたり、論文や実験を公開したりする場合は、Pytorchバージョンを使用することをお勧めします。Pytorchは学問の世界を支配しています。ただし、業界のTensorflowは依然として広く使用されています。
参照:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers pytorchバージョン
ピットを残して、ハハ、論文を読んでコードを読んでください。
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
まあ、数日前、私はGoogleのオープンソースT5モデル、XLNET、ロベルタ、ロベルタ、アルバート、スパンバートからT5まで...まったく我慢できません...今、NLP競技は基本的にトレーニング前に支配されています...私はトレーニング前なしでは良い結果を得ることができません...


