BERT CH NER
1.0.0
Изменено на основе официального кода Tensorflow.
Tensorflow: 1.13
Python: 3.6
TensorFlow2.0 сообщит об ошибке.
https://www.biendata.com/competition/sohu2019/
В этом текстовом конкурсе Соху была написана базовая линия с использованием Bert и Bert+LSTM+CRF для распознавания сущности.
Результаты использования только BERT заключаются в следующем. Пожалуйста, смотрите описание конкуренции для конкретного плана оценки. Здесь выполнена только физическая часть, и все эмоции являются результатами тестов, проведенных POS.

Результат заключается в следующем с использованием BERT+LSTM+CRF

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Под файлом souhu
Потому что, имея дело с китайцем, будут некоторые странные символы, такие как u3000 и т. Д., Которые вам необходимо обработать заранее, в противном случае label_id и inputs_id не будет соответствовать, потому что токенизация, принесенная BET, обработает эти символы. Следовательно, вы можете использовать базовый разборщик, который поставляется с ставкой, чтобы сначала предварительно обработать текст данных, чтобы соответствовать этикетке.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])Берт используется для обучения названных организациям распознавать NER -задачи на основе китайского набора данных, опубликованного курсовой работой учителя.
Я использовал BI+LSTM+CRF для распознавания раньше, и эффект также был хорошим. На этот раз я использовал Bert для обучения, что можно рассматривать как чтение и понимание исходного кода BERT.
Хотя раньше было много примеров и учебных пособий по использованию BERT, я не думаю, что это очень полное. Некоторые недостатки комментариев не очень дружелюбны для новичков, а у некоторых разные проблемы. Различные коды изменены. Я столкнулся с множеством ловушек на дороге. Так что запишите это.
Под папкой TMP
Как показано на рисунке выше, набор данных сегментирован, где источник является текстом в учебном наборе, а цель - этикетка обучающего набора.
Тестовый набор тестирования, метка теста TEST_TGT. Dev Validation Set Dev-Lable Validation Set Mabel.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor Причастие Bert Word столкнется с некоторыми проблемами, когда дело доходит до причастий слова персонажа.
Например, ввод и вопрос macau =-=-=-Поздравляем возвращения Макао в обратный отсчет, метка: oo b-loc i-loc oooooo b-loc i-loc ooooooooo
Вход =- будет обработана в два символа, поэтому этикетка не будет соответствовать и должна быть обработана вручную. Например, возьмите этикетку первого персонажа каждый раз следующим образом. На самом деле, эта проблема будет столкнулась при работе с английским языком. Wordsiece разделит слово на несколько жетонов, поэтому его необходимо обрабатывать вручную (это просто простой способ справиться с ним).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

Всего есть 10 категорий, а PAD - это категория, которая дополняет 0, когда длина предложения не достигает max_seq_length.
CLS - это категория, где флаг [CLS] добавляется до начала каждого предложения, а SEP такой же, как и конец предложения. (Потому что Берт добавит эти два символа в начало и конец предложения.)
Фактически, Берт должен изменить соответствующий код на основе конкретных задач. NER считается проблемой маркировки последовательности, которую можно считать проблемой классификации.
Тогда основной частью модификации является run_classifier.py. Я поместил код после изменения задачи вниз по течению в run_ner.py.
В дополнение к предварительной обработке детали данных, вам также необходимо изменить функцию оценки и функцию потерь самостоятельно.
Во-первых, загрузите модель BERT на основе предварительно обученного китайского (официальная страница Bert Github может быть загружена), хранить ее в папке BERT_BASE_DIR, а затем поместите данные в папку NER_DIR. Вы можете начать обучение. SH Run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
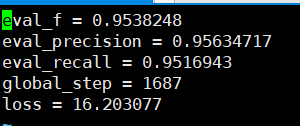
Отзывы о точности, которые можно увидеть на основе набора проверки, выше 95%.
Вот несколько примеров набора тестов прогнозирования.

На следующем рисунке показаны категории, предсказанные с использованием BERT. По -прежнему очень точно видеть, что прогноз можно сравнить с реальной категорией.

Реальная категория показана ниже.

На самом деле, прочитав статью Берта, вы можете более глубоко понять, объединив код с тонкой настройкой вниз по течению задач.
Фактически, нижняя задача состоит в том, чтобы преобразовать ваши данные в необходимый им формат, а затем изменить выходную категорию по мере необходимости, а затем изменить функцию оценки и функцию потерь.
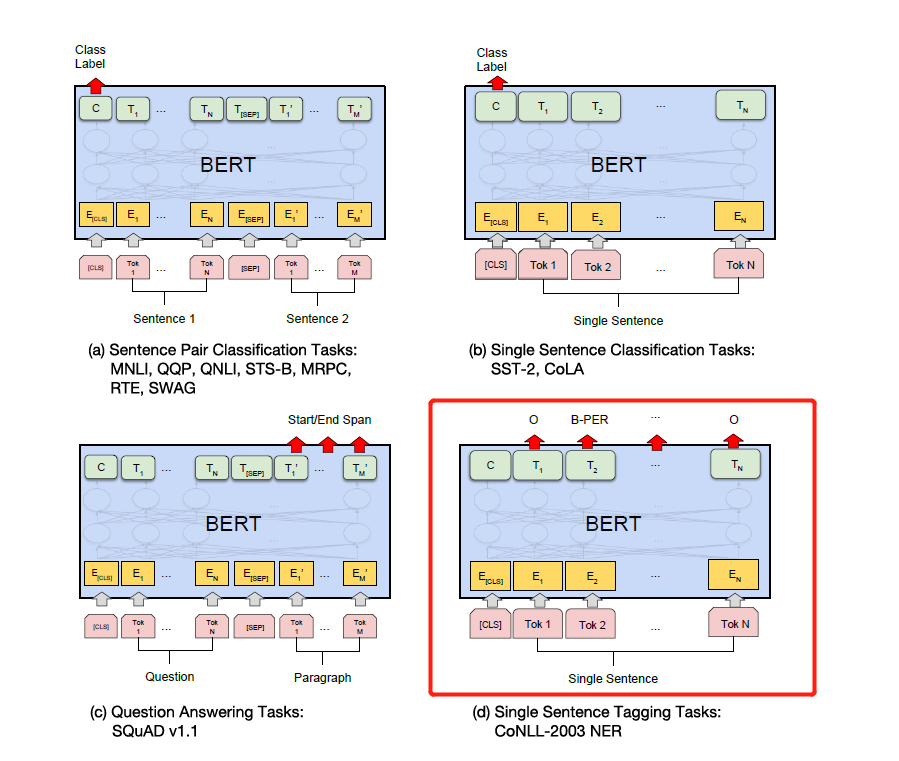
Просто измените этикетку в соответствии с конкретными нисходящими задачами на рисунке ниже. Четвертый на рисунке ниже - изменить его на NER.
Позже я напишу подробное объяснение внимания - это все, что вам нужно, и Bert Paper, и я объясню детали в сочетании с кодом, например, как реализуется Add & Norm, и почему необходимо добавление и норм. == Я чувствую, что мне больше не нужно писать. Берт стал популярным на улицах, и я не буду делать повторяющиеся колеса. Мы рекомендуем вам напрямую исходный код и бумагу.
Наконец, у Берта есть много странных и эротических техник. Полем Например, вы можете взять векторы промежуточного слоя для сплайсинга, а затем заморозить промежуточные слои и т. Д.
Позже я использовал версию Bert Pytorch, чтобы провести несколько соревнований и экспериментов для публикации документов. Я лично думаю, что версия Bert Pytorch проще и проще в использовании, и более удобно заморозить промежуточный слой Bert. Это также может накапливать градиенты во время тренировочного процесса. Вы можете напрямую унаследовать модель BERT и написать свою собственную модель.
(Я использовал Pytorch, чтобы провести эксперимент с BERT NER. Я хочу открыть исходный код, но я слишком ленив, чтобы разобраться ... Я открою исходный код однажды, когда я свободен. Уже много открытых исходных кодов в Интернете. 233 уже) уже) уже) уже).
Pytorch настолько вкусен ... это намного проще, чем Tensorflow ...
Я лично рекомендую, чтобы вы проводили соревнования или публикуете статьи и эксперименты, используйте версию Pytorch. Pytorch доминировал в академическом мире. Тем не менее, TensorFlow в отрасли все еще широко используется.
См.
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers pytorch версии
Оставьте яму, ха -ха, прочитайте газету и прочитайте код.
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
Что ж, несколько дней назад я видел модель Google с открытым исходным кодом T5, от XLnet, Roberta, Albert, Spanbert до T5 ... Я не могу вынести ее вообще ... Теперь соревнования NLP в основном преобладают предварительным обучением ... Я не могу получить хорошие результаты без предварительного обучения ...


