BERT CH NER
1.0.0
تم تعديله بناءً على رمز TensorFlow الرسمي.
TensorFlow: 1.13
بيثون: 3.6
سوف TensorFlow2.0 الإبلاغ عن خطأ.
https://www.biendata.com/competition/sohu2019/
في هذه المسابقة النصية لـ Sohu ، تمت كتابة خط الأساس ، باستخدام Bert و Bert+LSTM+CRF للتعرف على الكيان.
نتائج استخدام BERT فقط هي كما يلي. يرجى الاطلاع على وصف المنافسة لخطة التقييم المحددة. هنا ، يتم تنفيذ الجزء المادي فقط ، وجميع العواطف هي درجات الاختبار التي أجراها نقاط البيع.

والنتيجة هي كما يلي باستخدام Bert+LSTM+CRF

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
تحت ملف Souhu
لأنه عند التعامل مع الصينيين ، سيكون هناك بعض الرموز الغريبة ، مثل u3000 ، وما إلى ذلك ، والتي تحتاج إلى معالجتها مقدمًا ، وإلا فلن تتوافق الملصقات و inputs_id ، لأن الرمز المميز الذي تم تقديمه بواسطة BET سيعالج هذه الرموز. لذلك ، يمكنك استخدام BasicTokenizer الذي يأتي مع رهان لمعالجة نص البيانات مسبقًا أولاً لتتوافق مع التسمية.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])يتم استخدام Bert لتدريب الكيانات المسمى للتعرف على مهام NER بناءً على مجموعة البيانات الصينية التي نشرتها الدورات الدراسية للمعلم.
لقد استخدمت BI+LSTM+CRF للاعتراف من قبل ، وكان التأثير جيدًا أيضًا. هذه المرة استخدمت BERT للتدريب ، والتي يمكن اعتبارها قراءة وفهم رمز مصدر BERT.
على الرغم من وجود العديد من الأمثلة والدروس التعليمية حول استخدام BERT من قبل ، لا أعتقد أنها كاملة للغاية. بعض الافتقار إلى التعليقات ليست ودية للغاية للمبتدئين ، والبعض الآخر يعاني من مشاكل مختلفة. يتم تعديل الرموز المختلفة. لقد واجهت العديد من المزالق على الطريق. لذا سجله.
تحت مجلد TMP
كما هو موضح في الشكل أعلاه ، يتم تقسيم مجموعة البيانات ، حيث يكون المصدر هو النص في مجموعة التدريب والهدف هو تسمية مجموعة التدريب.
Test1 Test Set ، Test_TGT Test Set Label. مجموعة التحقق من صحة DEV Set Dev-Lable.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor ستواجه Bert Word Gollly بعض المشكلات عندما يتعلق الأمر بمشاركات كلمة الشخصية.
على سبيل المثال ، الإدخال والسؤال macau =-=-=-تهانينا لعودة ماكاو إلى العد التنازلي ، التسمية: oo b-loc oooooo b-loc i-loc oooooooo
ستتم معالجة الإدخال =- في حرفين ، لذلك لن تتوافق الملصق ويجب معالجته يدويًا. على سبيل المثال ، خذ ملصق الحرف الأول في كل مرة على النحو التالي. في الواقع ، ستتم مواجهة هذه المشكلة عند التعامل مع اللغة الإنجليزية. ستقسم WordPiece كلمة إلى عدة رموز ، لذلك يجب معالجتها يدويًا (هذه مجرد طريقة بسيطة للتعامل معها).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

هناك 10 فئات في المجموع ، و PAD هي الفئة التي تكمل 0 عندما لا يصل طول الجملة إلى MAX_SEQ_LENGTH.
CLS هي الفئة التي تتم إضافة العلم [CLS] قبل بداية كل جملة ، و SEP هي نفسها نهاية الجملة. (لأن بيرت سيضيف هذين الرموسين إلى بداية ونهاية الجملة.)
في الواقع ، يحتاج BERT إلى تعديل الكود المقابل بناءً على مشاكل محددة. يعتبر NER مشكلة في وضع العلامات التسلسل ، والتي يمكن اعتبارها مشكلة تصنيف.
ثم الجزء الرئيسي من التعديل هو run_classifier.py. أضع الرمز بعد تعديل مهمة المصب في Run_ner.py.
بالإضافة إلى المعالجة المسبقة لجزء البيانات ، تحتاج أيضًا إلى تعديل وظيفة التقييم ووظيفة الخسارة بنفسك.
أولاً ، قم بتنزيل نموذج BERT استنادًا إلى صينية تم تدريبه مسبقًا (يمكن تنزيل صفحة Bert Github الرسمية) ، وتخزينها في مجلد BERT_BASE_DIR ، ثم وضع البيانات في مجلد NER_DIR. يمكنك البدء في التدريب. sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
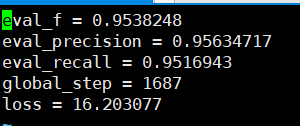
تتذكر الدقة التي يمكن رؤيتها بناءً على مجموعة التحقق من 95 ٪.
فيما يلي بعض الأمثلة على مجموعة اختبار التنبؤ.

يوضح الشكل التالي الفئات المتوقعة باستخدام BERT. لا يزال الأمر دقيقًا للغاية لترى أنه يمكن مقارنة التنبؤ بالفئة الحقيقية.

يظهر الفئة الحقيقية أدناه.

في الواقع ، بعد قراءة ورقة Bert ، يمكنك أن تفهم بعمق أكبر من خلال الجمع بين الكود لضبط المهام المصب.
في الواقع ، تتمثل المهمة المصب في تحويل بياناتك إلى التنسيق الذي يحتاجونه ، ثم تغيير فئة الإخراج حسب الحاجة ، ثم تعديل وظيفة التقييم ووظيفة الخسارة.
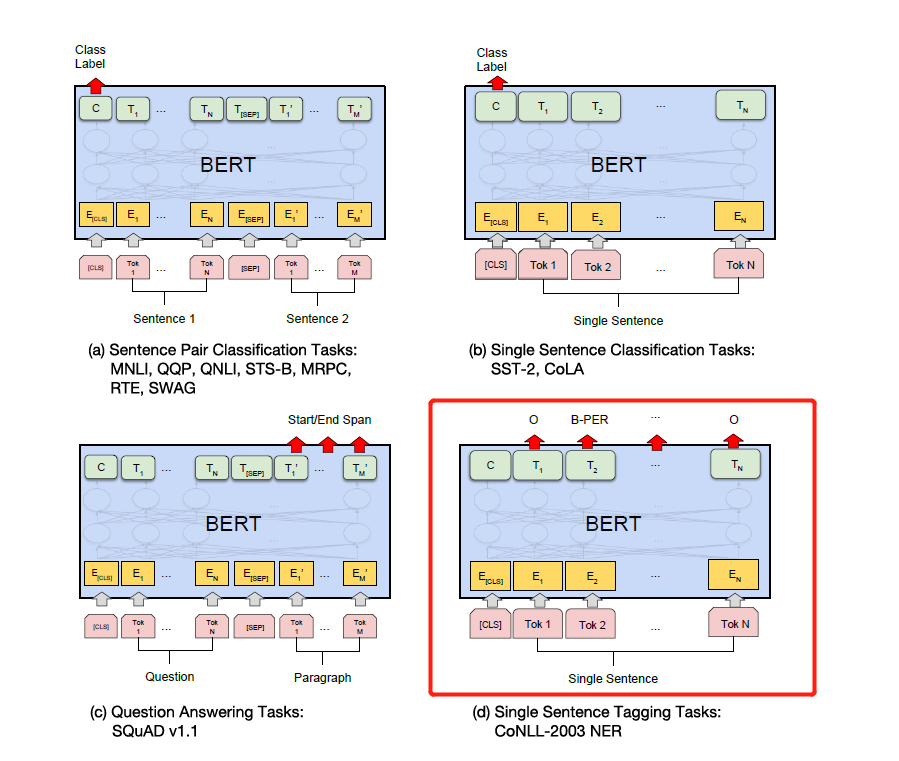
ما عليك سوى تعديل الملصق وفقًا لمهام المصب المحددة في الشكل أدناه. الرابع في الشكل أدناه هو تعديله على ner.
في وقت لاحق ، سأكتب شرحًا مفصلاً للانتباه هو كل ما تحتاجه وورق Bert ، وسأشرح التفاصيل بالاشتراك مع الكود ، مثل كيفية تنفيذ Add & Norm ولماذا يلزم الإضافة والنورم. == أشعر أنني لست بحاجة إلى كتابته بعد الآن. أصبح بيرت شائعًا في جميع أنحاء الشوارع ولن أصنع عجلات متكررة. نوصيك مباشرة برمز المصدر والورق.
أخيرًا ، هناك العديد من التقنيات الغريبة والمثيرة لبيرت لاستكشافها. . على سبيل المثال ، يمكنك أن تأخذ متجهات الطبقة المتوسطة للتصحيح ، ثم تجميد الطبقات الوسيطة ، إلخ.
في وقت لاحق ، استخدمت إصدار Pytorch من Bert للقيام بالعديد من المسابقات والتجارب لنشر الأوراق. أنا شخصياً أعتقد أن إصدار Pytorch من Bert أبسط وأسهل في الاستخدام ، وهو أكثر ملاءمة لتجميد الطبقة الوسيطة Bert. يمكن أن يتراكم التدرجات أثناء عملية التدريب. يمكنك أن ترث نموذج Bert مباشرة وكتابة النموذج الخاص بك.
(لقد استخدمت Pytorch للقيام بتجربة Bert of Ner. أريد فتح المصدر ولكني كسول جدًا في حلها ... سأفتح المصدر يومًا ما عندما أكون مجانيًا. هناك بالفعل الكثير من المصدر المفتوح على الإنترنت. 233 بالفعل)
Pytorch لذيذ جدًا ... من الأسهل بكثير تعديله من TensorFlow ...
أنا شخصياً أوصي بأنه إذا قمت بالمسابقات أو نشرت الأوراق والتجارب ، فاستخدم إصدار Pytorch .. لقد سيطر Pytorch على العالم الأكاديمي. ومع ذلك ، لا يزال Tensorflow في الصناعة يستخدم على نطاق واسع.
الرجوع إلى:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers إصدار pytorch
اترك حفرة ، هاها ، اقرأ الورقة وقراءة الرمز.
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
حسنًا ، قبل بضعة أيام ، رأيت طراز Google Open Source T5 ، من XLNET و Roberta و Albert و Spanbert إلى T5 الآن ... لا يمكنني تحمله على الإطلاق ... الآن تهيمن على مسابقات NLP من قبل التدريب المسبق ... لا يمكنني الحصول على نتائج جيدة دون التدريب المسبق ...


