BERT CH NER
1.0.0
Modified based on the official tensorflow code.
Tensorflow: 1.13
Python: 3.6
Tensorflow2.0 will report an error.
https://www.biendata.com/competition/sohu2019/
In this text competition of Sohu, a baseline was written, using bert and bert+lstm+crf for entity recognition.
The results of using only BERT are as follows. Please see the competition description for the specific evaluation plan. Here, only the physical part is done, and all emotions are the test scores conducted by POS.

The result is as follows using bert+lstm+crf

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Under the souhu file
Because when dealing with Chinese, there will be some strange symbols, such as u3000, etc., which you need to process in advance, otherwise label_id and inputs_id will not correspond to, because the tokenization brought by bet will process these symbols. Therefore, you can use the BasicTokenizer that comes with bet to preprocess the data text first to correspond to the label.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])BERT is used to train named entities to recognize NER tasks based on the Chinese dataset published by the teacher's coursework.
I used Bi+LSTM+CRF for recognition before, and the effect was also good. This time I used BERT for training, which can be regarded as reading and understanding the BERT source code.
Although there were many examples and tutorials on using BERT before, I don’t think it’s very complete. Some lack of comments is not very friendly to novices, and some have different problems. Different codes are modified. I have encountered many pitfalls on the road. So record it.
Under the tmp folder
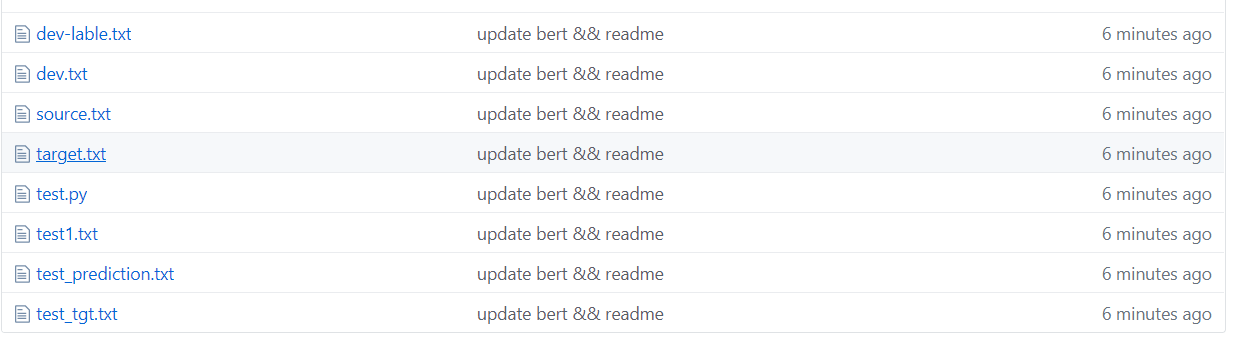
As shown in the figure above, the data set is segmented, where source is the text in the training set and target is the label of the training set.
test1 test set, test_tgt test set label. dev validation set dev-lable validation set label.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor The BERT word participle will encounter some problems when it comes to character word participles.
For example, input and question Macau =- =- =- Congratulations to Macau’s return to the countdown, label:OO B-LOC I-LOC OOOOO B-LOC I-LOC OOOOOOOO
The input =- will be processed into two characters, so the label will not correspond to and needs to be processed manually. For example, take the label of the first character each time as follows. In fact, this problem will be encountered when dealing with English. WordPiece will divide a word into several tokens, so it needs to be processed manually (this is just a simple way to deal with it).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

There are 10 categories in total, and PAD is the category that supplements 0 when the sentence length does not reach max_seq_length.
CLS is the category where a flag [CLS] is added before the beginning of each sentence, and SEP is the same as the end of the sentence. (Because BERT will add these two symbols to the beginning and end of the sentence.)
In fact, BERT needs to modify the corresponding code based on specific problems. NER is considered a problem of sequence labeling, which can be considered a classification problem.
Then the main part of the modification is the run_classifier.py. I put the code after modifying the downstream task in run_NER.py.
In addition to preprocessing of the data part, you also need to modify the evaluation function and loss function yourself.
First, download the BERT model based on Chinese pre-trained (the official BERT github page can be downloaded), store it in the BERT_BASE_DIR folder, and then put the data in the NER_DIR folder. You can start training. sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
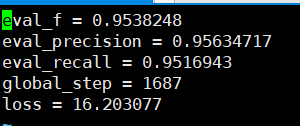
The accuracy recalls that can be seen based on the verification set are all above 95%.
Here are some examples of the prediction test set.

The following figure shows the categories predicted using BERT. It is still very accurate to see that the prediction can be compared with the real category.

The real category is shown below.

In fact, after reading BERT's paper, you can understand more deeply by combining the code to fine-tune downstream tasks.
In fact, the downstream task is to transform your own data into the format they need, then change the output category as needed, and then modify the evaluation function and loss function.
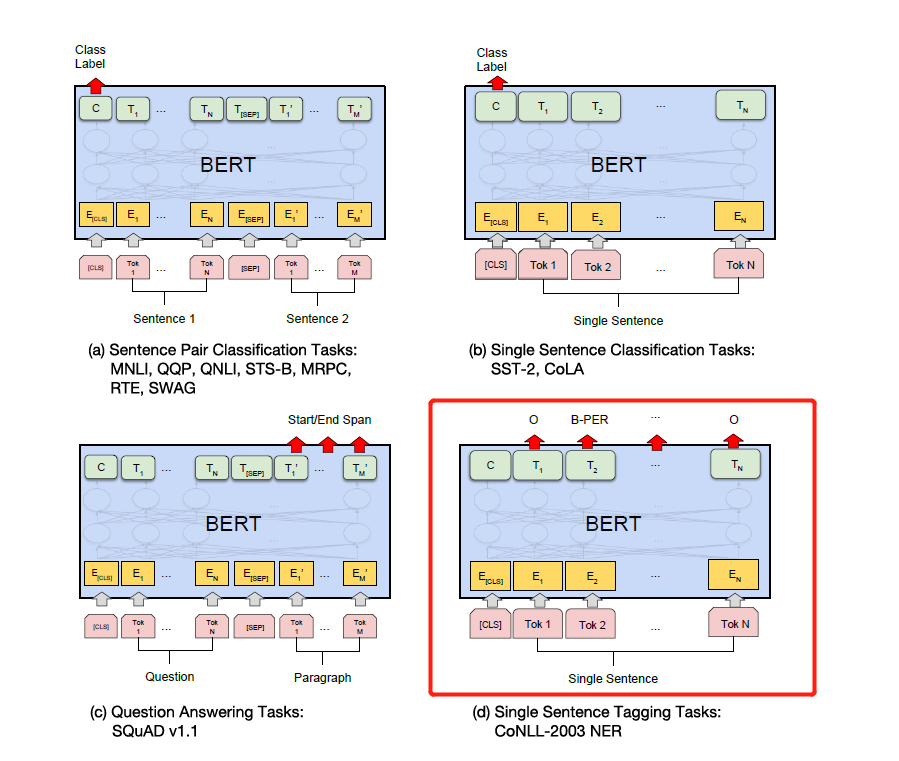
Just modify the label according to the specific downstream tasks in the figure below. The fourth one in the figure below is to modify it on NER.
Later, I will write a detailed explanation of the Attention is all you need and bert paper, and I will explain the details in combination with the code, such as how Add & Norm is implemented and why Add & Norm is needed. == I feel like I don’t need to write it anymore. Bert has become popular all over the streets and I won’t make repeated wheels. We recommend that you directly source code and paper.
Finally, there are many strange and erotic techniques for BERT to explore. . For example, you can take intermediate layer vectors to splice, and then freeze intermediate layers, etc.
Later, I used the pytorch version of BERT to do several competitions and experiments to publish papers. I personally think that the pytorch version of BERT is simpler and easier to use, and it is more convenient to freeze the BERT intermediate layer. It can also accumulate gradients during the training process. You can directly inherit the BERT model and write your own model.
(I used pytorch to do the BERT experiment of NER again. I want to open source but I am too lazy to sort it out... I will open source one day when I am free. There are already a lot of open source on the Internet. 233 already)
pytorch is so delicious...it's much simpler to modify than tensorflow...
I personally recommend that if you do competitions or publish papers and experiments, use the pytorch version.. pytorch has dominated the academic world. However, tensorflow in the industry is still widely used.
refer to:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/BERT-NER
https://github.com/huggingface/transformers pytorch version
Leave a pit, haha, read the paper and read the code.
https://mp.weixin.qq.com/s/29y2bg4KE-HNwsimD3aauw
https://github.com/zihangdai/xlnet
Well, a few days ago, I saw Google's open source T5 model, from XLNet, RoBERTa, ALBERT, SpanBERT to T5 now... I can't stand it at all... Now NLP competitions are basically dominated by pre-training... I can't get good results without pre-training...


