BERT CH NER
1.0.0
공식 텐서 플로 코드를 기반으로 수정되었습니다.
텐서 플로 : 1.13
파이썬 : 3.6
TensorFlow2.0은 오류를보고합니다.
https://www.biendata.com/competition/sohu2019/
Sohu 의이 텍스트 경쟁에서, 기준선은 Bert 및 Bert+LSTM+CRF를 사용하여 엔티티 인식을 사용했습니다.
버트 만 사용한 결과는 다음과 같습니다. 특정 평가 계획에 대한 경쟁 설명을 참조하십시오. 여기서는 물리적 부분 만 수행되며 모든 감정은 POS가 수행 한 시험 점수입니다.

결과는 Bert+LSTM+CRF를 사용하여 다음과 같습니다

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Souhu 파일 아래
중국어를 다룰 때 u3000 등과 같은 이상한 기호가 있기 때문에 미리 처리해야합니다. 그렇지 않으면 BET에 의해 가져 오는 토큰 화이 이러한 기호를 처리하기 때문에 label_id 및 inputs_id는 해당하지 않습니다. 따라서 베팅과 함께 제공되는 Basickokenizer를 사용하여 데이터 텍스트를 먼저 전처리하여 레이블에 해당합니다.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])Bert는 교사의 교과 과정에서 게시 한 중국 데이터 세트를 기반으로 NER 작업을 인식하도록 지명 된 엔티티를 교육하는 데 사용됩니다.
나는 이전에 인식을 위해 BI+LSTM+CRF를 사용했으며 그 효과도 좋았습니다. 이번에는 교육에 Bert를 사용했는데, 이는 Bert 소스 코드를 읽고 이해하는 것으로 간주 될 수 있습니다.
이전에 Bert 사용에 관한 많은 예와 튜토리얼이 있었지만 그다지 완전하다고 생각하지 않습니다. 의견이 부족한 것은 초보자에게는 그다지 친근하지 않으며 일부는 다른 문제가 있습니다. 다른 코드가 수정되었습니다. 나는 도로에서 많은 함정을 만났다. 그러니 녹음하십시오.
TMP 폴더 아래
위의 그림과 같이, 데이터 세트는 세그먼트 화되며, 여기서 소스는 훈련 세트의 텍스트이며 대상은 교육 세트의 레이블입니다.
test1 테스트 세트, test_tgt 테스트 세트 레이블. DEV 유효성 검사 세트 DEV-LABLE 유효성 검사 세트 레이블.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor Bert Word 분사는 캐릭터 단어 분사와 관련하여 몇 가지 문제가 발생합니다.
예를 들어, 입력 및 질문 macau =-=-=-마카오가 카운트 다운으로 돌아 오는 데 축하합니다.
입력 =-는 두 문자로 처리되므로 레이블은 수동으로 해당하지 않으며 수동으로 처리 할 필요가 있습니다. 예를 들어, 다음과 같이 매번 첫 번째 문자의 레이블을 사용하십시오. 실제로이 문제는 영어를 다룰 때 발생합니다. WordPiece는 단어를 여러 토큰으로 나눌 것이므로 수동으로 처리해야합니다 (이는 간단한 방법 일뿐입니다).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

총 10 개의 카테고리가 있으며 PAD는 문장 길이가 max_seq_length에 도달하지 않을 때 0을 보완하는 범주입니다.
CLS는 각 문장의 시작 이전에 플래그 [CLS]가 추가되는 범주이며 SEP는 문장의 끝과 동일합니다. (Bert는 문장의 시작과 끝에이 두 가지 기호를 추가하기 때문입니다.)
실제로 Bert는 특정 문제에 따라 해당 코드를 수정해야합니다. NER은 분류 문제로 간주 될 수있는 서열 라벨링의 문제로 간주됩니다.
그런 다음 수정의 주요 부분은 run_classifier.py입니다. run_ner.py에서 다운 스트림 작업을 수정 한 후 코드를 넣었습니다.
데이터 부분의 전처리 외에도 평가 기능 및 손실 기능을 직접 수정해야합니다.
먼저 중국어 미리 훈련 된 중국어 (공식 Bert Github 페이지를 다운로드 할 수 있음)를 기반으로 Bert 모델을 다운로드하고 Bert_base_dir 폴더에 저장 한 다음 NER_DIR 폴더에 데이터를 넣습니다. 훈련을 시작할 수 있습니다. sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
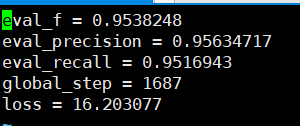
검증 세트를 기반으로 볼 수있는 정확도는 모두 95%이상입니다.
예측 테스트 세트의 몇 가지 예는 다음과 같습니다.

다음 그림은 Bert를 사용하여 예측 된 범주를 보여줍니다. 예측이 실제 범주와 비교 될 수 있음을 보는 것은 여전히 매우 정확합니다.

실제 범주는 다음과 같습니다.

실제로 Bert의 논문을 읽은 후에는 코드를 결합하여 다운 스트림 작업을 미세 조정하여 더 깊이 이해할 수 있습니다.
실제로 다운 스트림 작업은 데이터를 필요한 형식으로 변환 한 다음 필요에 따라 출력 범주를 변경 한 다음 평가 기능 및 손실 함수를 수정하는 것입니다.
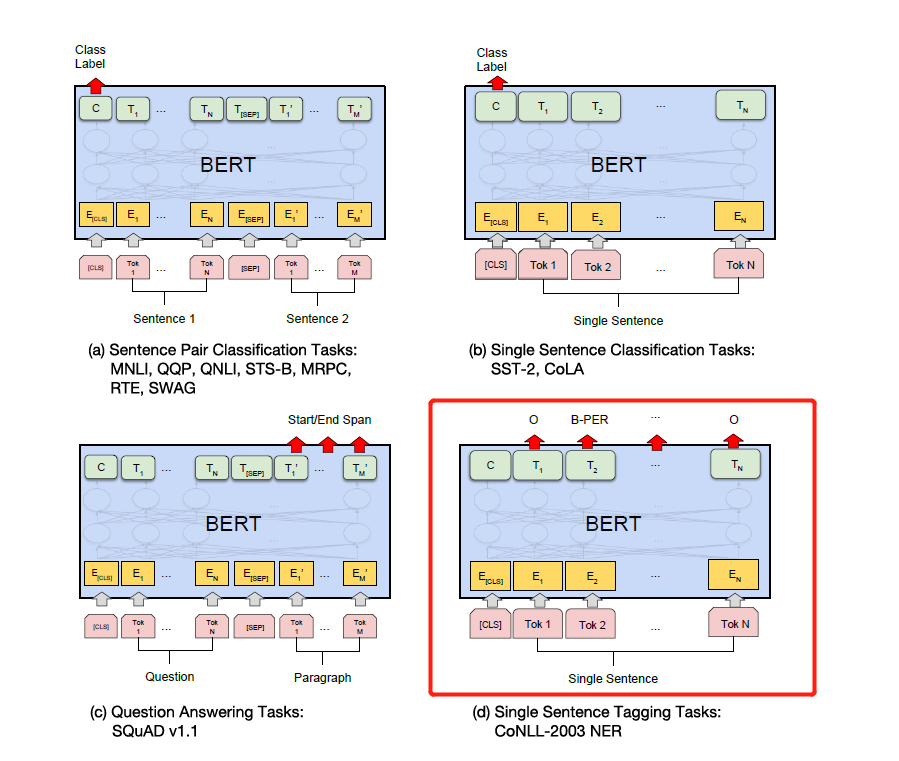
아래 그림의 특정 다운 스트림 작업에 따라 레이블을 수정하십시오. 아래 그림의 네 번째는 NER에서 수정하는 것입니다.
나중에, 나는 당신이 필요로하는 모든 것과 Bert 용지에 대한 자세한 설명을 작성하고, Add & Norm이 구현되는지, Add & Norm이 필요한 이유와 같은 코드와 함께 세부 사항을 설명 할 것입니다. == 더 이상 쓸 필요가 없다고 생각합니다. 버트는 거리 전체에서 인기를 얻었으며 반복적 인 바퀴를 만들지 않을 것입니다. 직접 코드와 종이를 소스하는 것이 좋습니다.
마지막으로, Bert가 탐험 할 수있는 이상하고 에로틱 한 기술이 많이 있습니다. . 예를 들어, 중간 층 벡터를 스플 라이스로 가져간 다음 중간 층을 동결 할 수 있습니다.
나중에 Pytorch 버전의 Bert를 사용하여 여러 대회와 실험을 수행하여 논문을 게시했습니다. 나는 개인적으로 Bert의 Pytorch 버전이 더 간단하고 사용하기 쉽다고 생각하며 Bert 중간 층을 동결하는 것이 더 편리합니다. 또한 훈련 과정에서 그라디언트를 축적 할 수 있습니다. 버트 모델을 직접 상속하고 자신의 모델을 쓸 수 있습니다.
(나는 Pytorch를 사용하여 NER의 Bert 실험을 수행했습니다. 나는 오픈 소스를 원하지만 그것을 분류하기에는 너무 게으르다 ... 나는 자유롭고 언젠가 오픈 소스를 열 것입니다. 인터넷에 이미 많은 오픈 소스가 있습니다. 이미 233 이미) 이미)
Pytorch는 너무 맛있습니다 ... Tensorflow보다 수정하는 것이 훨씬 간단합니다 ...
개인적으로 경쟁을하거나 논문과 실험을하는 경우 Pytorch 버전을 사용하는 것이 좋습니다. Pytorch는 학문적 세계를 지배했습니다. 그러나 업계의 Tensorflow는 여전히 널리 사용됩니다.
참조 :
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers pytorch 버전
구덩이를 남겨두고 하하, 종이를 읽고 코드를 읽으십시오.
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
글쎄, 며칠 전, XLNET, Roberta, Albert, Spanbert에서 T5에 이르기까지 Google의 오픈 소스 T5 모델을 보았습니다 ... 이제 전혀 참을 수 없습니다 ... 이제 NLP 경쟁은 기본적으로 사전 훈련으로 지배적입니다 ... 사전 훈련 없이는 좋은 결과를 얻을 수 없습니다 ...


