BERT CH NER
1.0.0
Modificado basado en el código oficial de TensorFlow.
TensorFlow: 1.13
Python: 3.6
TensorFlow2.0 informará un error.
https://www.biendata.com/competition/sohu2019/
En esta competencia de texto de Sohu, se escribió una línea de base, utilizando Bert y Bert+LSTM+CRF para el reconocimiento de entidades.
Los resultados de usar solo Bert son los siguientes. Consulte la descripción de la competencia para el plan de evaluación específico. Aquí, solo se realiza la parte física, y todas las emociones son los puntajes de prueba realizados por POS.

El resultado es el siguiente usando Bert+LSTM+CRF

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
Bajo el archivo Souhu
Porque al tratar con el chino, habrá algunos símbolos extraños, como u3000, etc., que debe procesar con anticipación, de lo contrario etiqueta_id e inputs_id no corresponderá, porque la tokenización traída por BET procesará estos símbolos. Por lo tanto, puede usar el Basictokenizer que viene con BET para preprocesar el texto de datos primero para corresponder a la etiqueta.
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])Bert se utiliza para capacitar a entidades nombradas para reconocer tareas NER basadas en el conjunto de datos chino publicado por los cursos del maestro.
Usé Bi+LSTM+CRF para el reconocimiento antes, y el efecto también fue bueno. Esta vez utilicé Bert para el entrenamiento, que puede considerarse como lectura y comprensión del código fuente de Bert.
Aunque hubo muchos ejemplos y tutoriales sobre el uso de Bert antes, no creo que sea muy completo. Algunas falta de comentarios no son muy amigables con los novatos, y otros tienen problemas diferentes. Se modifican diferentes códigos. Me he encontrado con muchas dificultades en el camino. Así que registelo.
Debajo de la carpeta TMP
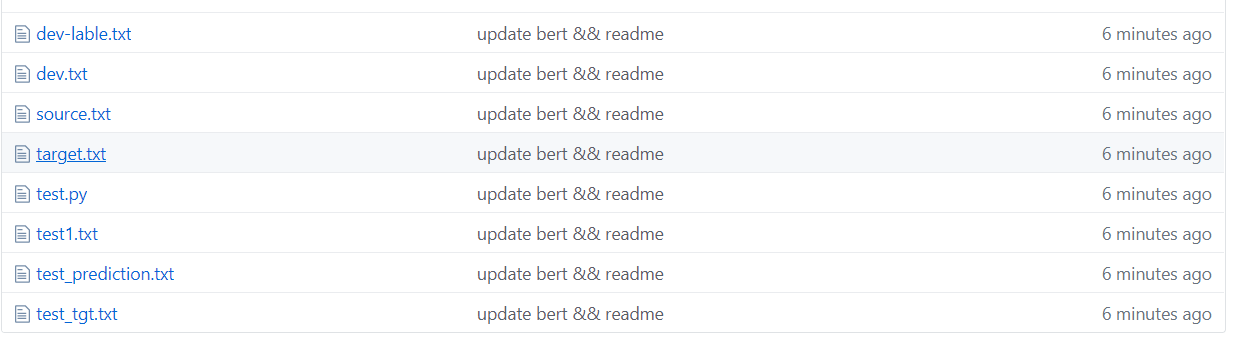
Como se muestra en la figura anterior, el conjunto de datos está segmentado, donde la fuente es el texto en el conjunto de entrenamiento y el objetivo es la etiqueta del conjunto de entrenamiento.
Test1 Test Set, Test_tgt Test Set Etiqueta. La validación de dev Validation Conjunto de la etiqueta del conjunto de validación Dev-Lable.
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor El participio de Bert Word encontrará algunos problemas cuando se trata de participantes en palabras de caracteres.
Por ejemplo, entrada y pregunta Macau =-=-=-Felicitaciones al retorno de Macao a la cuenta regresiva, etiqueta: oo b-Loc I-Loc ooooo B-Loc I-Loc oooooooo
La entrada =- se procesará en dos caracteres, por lo que la etiqueta no correspondirá y debe procesarse manualmente. Por ejemplo, tome la etiqueta del primer personaje cada vez como sigue. De hecho, este problema se encontrará cuando se trata de inglés. La obra de palabras dividirá una palabra en varios tokens, por lo que debe procesarse manualmente (esta es solo una forma simple de lidiar con ella).
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

Hay 10 categorías en total, y PAD es la categoría que complementa 0 cuando la longitud de la oración no alcanza max_seq_length.
CLS es la categoría donde se agrega una bandera [CLS] antes del comienzo de cada oración, y SEP es la misma que el final de la oración. (Porque Bert agregará estos dos símbolos al principio y al final de la oración).
De hecho, Bert necesita modificar el código correspondiente basado en problemas específicos. NER se considera un problema de etiquetado de secuencia, que puede considerarse un problema de clasificación.
Entonces la parte principal de la modificación es run_classifier.py. Puse el código después de modificar la tarea posterior en run_ner.py.
Además del preprocesamiento de la parte de datos, también debe modificar la función de evaluación y la función de pérdida usted mismo.
Primero, descargue el modelo BERT basado en la capacitación previa china (la página oficial de Bert Github se puede descargar), guárdelo en la carpeta Bert_Base_Dir y luego coloque los datos en la carpeta NER_DIR. Puedes comenzar a entrenar. sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
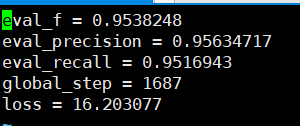
Los retiros de precisión que se pueden ver en función del conjunto de verificación están por encima del 95%.
Aquí hay algunos ejemplos del conjunto de pruebas de predicción.

La siguiente figura muestra las categorías predichas usando Bert. Todavía es muy preciso ver que la predicción se puede comparar con la categoría real.

La categoría real se muestra a continuación.

De hecho, después de leer el artículo de Bert, puede comprender más profundamente combinando el código para ajustar las tareas aguas abajo.
De hecho, la tarea posterior es transformar sus datos en el formato que necesitan, luego cambiar la categoría de salida según sea necesario y luego modificar la función de evaluación y la función de pérdida.
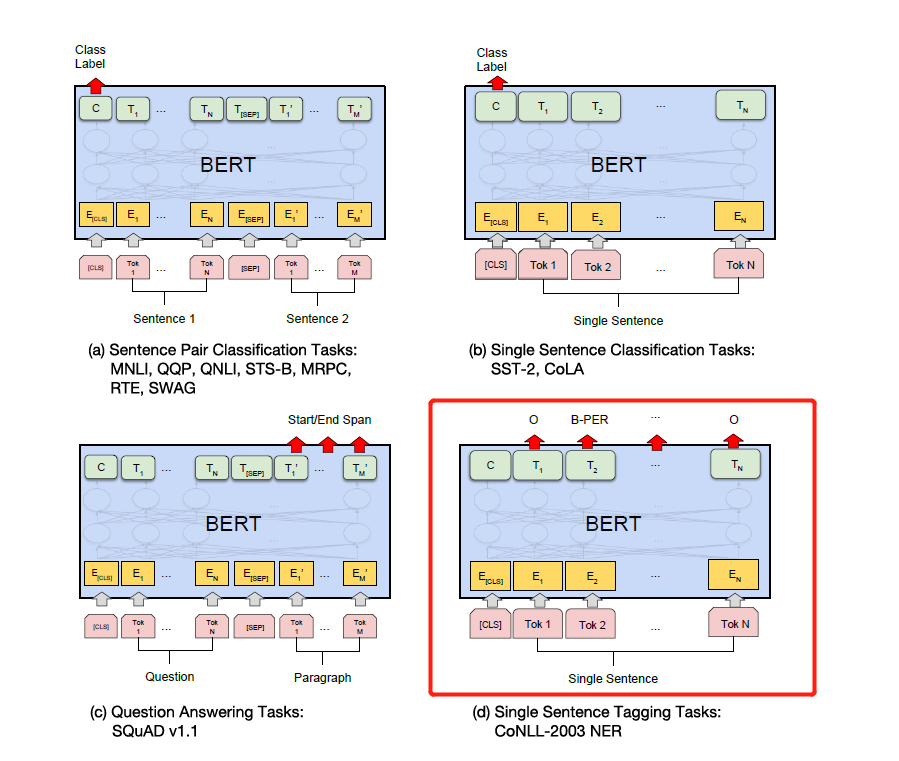
Simplemente modifique la etiqueta de acuerdo con las tareas específicas aguas abajo en la figura a continuación. El cuarto en la figura a continuación es modificarlo en NER.
Más tarde, escribiré una explicación detallada de la atención es todo lo que necesita y Bert Paper, y explicaré los detalles en combinación con el código, como cómo se implementa Add & Norm y por qué se necesita ADD & Norm. == Siento que ya no necesito escribirlo. Bert se ha vuelto popular en todas las calles y no haré ruedas repetidas. Recomendamos que el código fuente y el papel directamente.
Finalmente, hay muchas técnicas extrañas y eróticas para que Bert explore. . Por ejemplo, puede llevar a los vectores intermedios a empalme, y luego congelar capas intermedias, etc.
Más tarde, utilicé la versión Pytorch de Bert para hacer varias competiciones y experimentos para publicar artículos. Personalmente, creo que la versión Pytorch de Bert es más simple y más fácil de usar, y es más conveniente congelar la capa intermedia de Bert. También puede acumular gradientes durante el proceso de capacitación. Puede heredar directamente el modelo Bert y escribir su propio modelo.
(Usé Pytorch para hacer el experimento Bert de Ner. Quiero abrir el código, pero soy demasiado vago para resolverlo ... Abriré el código algún día cuando sea libre. Ya hay mucho código abierto en Internet. 233 ya)
Pytorch es tan delicioso ... es mucho más simple de modificar que TensorFlow ...
Personalmente, recomiendo que si realiza competiciones o publica documentos y experimentos, use la versión de Pytorch. Pytorch ha dominado el mundo académico. Sin embargo, TensorFlow en la industria todavía se usa ampliamente.
referirse a:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers versión pytorch
Deja un pozo, jaja, lee el documento y lee el código.
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
Bueno, hace unos días, vi el modelo T5 de código abierto de Google, desde XLNet, Roberta, Albert, Spanbert hasta T5 ahora ... No puedo soportarlo en absoluto ... Ahora las competiciones de PNL están básicamente dominadas por la capacitación ... no puedo obtener buenos resultados sin pre-entrenamiento ...


