BERT CH NER
1.0.0
แก้ไขตามรหัส Tensorflow อย่างเป็นทางการ
Tensorflow: 1.13
Python: 3.6
TensorFlow2.0 จะรายงานข้อผิดพลาด
https://www.biendata.com/competition/sohu2019/
ในการแข่งขันข้อความนี้ของ SOHU มีการเขียนพื้นฐานโดยใช้ Bert และ Bert+LSTM+CRF สำหรับการจดจำเอนทิตี
ผลลัพธ์ของการใช้เบิร์ตเท่านั้นมีดังนี้ โปรดดูคำอธิบายการแข่งขันสำหรับแผนการประเมินผลเฉพาะ ที่นี่มีเพียงส่วนทางกายภาพเท่านั้นและอารมณ์ทั้งหมดเป็นคะแนนการทดสอบที่ดำเนินการโดย POS

ผลลัพธ์มีดังนี้โดยใช้ BERT+LSTM+CRF

export BERT_BASE_DIR=/opt/hanyaopeng/souhu/data/chinese_L-12_H-768_A-12
export NER_DIR=/opt/hanyaopeng/souhu/data/data_v2
python run_souhuv2.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--output_dir= $BERT_BASE_DIR /outputv2/
--train_batch_size=32
--vocab_file= $BERT_BASE_DIR /vocab.txt
--max_seq_length=256
--learning_rate=2e-5
--num_train_epochs=10.0
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
ภายใต้ไฟล์ Souhu
เพราะเมื่อจัดการกับภาษาจีนจะมีสัญลักษณ์แปลก ๆ บางอย่างเช่น u3000 ฯลฯ ซึ่งคุณต้องดำเนินการล่วงหน้ามิฉะนั้น label_id และอินพุตจะไม่สอดคล้องกับเนื่องจากโทเค็นที่นำโดยการเดิมพันจะประมวลผลสัญลักษณ์เหล่านี้ ดังนั้นคุณสามารถใช้ basictokenizer ที่มาพร้อมกับการเดิมพันเพื่อประมวลผลข้อความข้อมูลล่วงหน้าก่อนเพื่อให้สอดคล้องกับฉลาก
tokenizer = tokenization . BasicTokenizer ( do_lower_case = True )
text = tokenizer . tokenize ( text )
text = '' . join ([ l for l in text ])เบิร์ตใช้ในการฝึกอบรมเอนทิตีที่มีชื่อเพื่อรับรู้งาน ner ตามชุดข้อมูลจีนที่เผยแพร่โดยหลักสูตรของครู
ฉันใช้ BI+LSTM+CRF เพื่อรับรู้มาก่อนและเอฟเฟกต์ก็ดีเช่นกัน ครั้งนี้ฉันใช้เบิร์ตสำหรับการฝึกอบรมซึ่งถือได้ว่าเป็นการอ่านและทำความเข้าใจกับซอร์สโค้ดเบิร์ต
แม้ว่าจะมีตัวอย่างมากมายและแบบฝึกหัดเกี่ยวกับการใช้เบิร์ตมาก่อน แต่ฉันไม่คิดว่ามันจะสมบูรณ์มาก การขาดความคิดเห็นบางอย่างไม่เป็นมิตรกับสามเณรและบางคนมีปัญหาที่แตกต่างกัน มีการแก้ไขรหัสที่แตกต่างกัน ฉันได้พบกับข้อผิดพลาดมากมายบนท้องถนน ดังนั้นบันทึกไว้
ภายใต้โฟลเดอร์ TMP
ดังที่แสดงในรูปด้านบนชุดข้อมูลจะถูกแบ่งส่วนซึ่งแหล่งที่มาคือข้อความในชุดการฝึกอบรมและเป้าหมายคือฉลากของชุดการฝึกอบรม
ชุดทดสอบ 1 ชุดทดสอบชุดทดสอบ test_tgt ชุดตรวจสอบความถูกต้องของ Dev Dev-Lable Set Label
需要将数据处理成如下格式,一个句子对应一个label .句子和label的每个字都用空格分开。
如: line = [我 爱 国 科 大 哈 哈] str
label = [ O O B I E O O ] str的type 用空格分开
具体请看代码中的NerProcessor 和 NerBaiduProcessor คำนามคำของ Bert Word จะประสบปัญหาบางอย่างเมื่อพูดถึงคำศัพท์ของตัวละคร
ตัวอย่างเช่นอินพุตและคำถาม macau =-=-=-ขอแสดงความยินดีกับการกลับไปที่การนับถอยหลังของมาเก๊
อินพุต =- จะถูกประมวลผลเป็นสองอักขระดังนั้นฉลากจะไม่สอดคล้องกับและจำเป็นต้องดำเนินการด้วยตนเอง ตัวอย่างเช่นใช้ฉลากของตัวละครตัวแรกในแต่ละครั้งดังนี้ ในความเป็นจริงปัญหานี้จะพบเมื่อจัดการกับภาษาอังกฤษ WordPiece จะแบ่งคำออกเป็นโทเค็นหลายอย่างดังนั้นจึงจำเป็นต้องดำเนินการด้วยตนเอง (นี่เป็นเพียงวิธีง่ายๆในการจัดการกับมัน)
la = example.label.split(' ')
tokens_a = []
labellist = []
for i,t in enumerate(example.text_a.split(' ')):
tt = tokenizer.tokenize(t)
if len(tt) == 1 :
tokens_a.append(tt[0])
labellist.append(la[i])
elif len(tt) > 1:
tokens_a.append(tt[0])
labellist.append(la[i])
assert len(tokens_a) == len(labellist)

มี 10 หมวดหมู่ทั้งหมดและ PAD เป็นหมวดหมู่ที่เสริม 0 เมื่อความยาวประโยคไม่ถึง MAX_SEQ_LENGTH
CLS เป็นหมวดหมู่ที่มีการเพิ่มธง [CLS] ก่อนที่จะเริ่มต้นประโยคแต่ละประโยคและ SEP ก็เหมือนกับส่วนท้ายของประโยค (เพราะเบิร์ตจะเพิ่มสัญลักษณ์ทั้งสองนี้ลงในจุดเริ่มต้นและจุดสิ้นสุดของประโยค)
ในความเป็นจริงเบิร์ตจำเป็นต้องแก้ไขรหัสที่เกี่ยวข้องตามปัญหาเฉพาะ NER ถือเป็นปัญหาของการติดฉลากลำดับซึ่งถือได้ว่าเป็นปัญหาการจำแนกประเภท
จากนั้นส่วนหลักของการดัดแปลงคือ run_classifier.py ฉันใส่รหัสหลังจากแก้ไขงานดาวน์สตรีมใน run_ner.py
นอกเหนือจากการประมวลผลส่วนข้อมูลล่วงหน้าคุณต้องปรับเปลี่ยนฟังก์ชั่นการประเมินและฟังก์ชั่นการสูญเสียด้วยตัวเอง
ขั้นแรกให้ดาวน์โหลดรุ่น Bert ตามการฝึกอบรมก่อนภาษาจีน (หน้า Bert GitHub อย่างเป็นทางการสามารถดาวน์โหลดได้) เก็บไว้ในโฟลเดอร์ BERT_BASE_DIR จากนั้นใส่ข้อมูลในโฟลเดอร์ NER_DIR คุณสามารถเริ่มการฝึกอบรม sh run.sh
export BERT_BASE_DIR=/opt/xxx/chinese_L-12_H-768_A-12
export NER_DIR=/opt/xxx/tmp
python run_NER.py
--task_name=NER
--do_train=true
--do_eval=true
--do_predict=true
--data_dir= $NER_DIR /
--vocab_file= $BERT_BASE_DIR /vocab.txt
--bert_config_file= $BERT_BASE_DIR /bert_config.json
--init_checkpoint= $BERT_BASE_DIR /bert_model.ckpt
--max_seq_length=256 # 根据实际句子长度可调
--train_batch_size=32 # 可调
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir= $BERT_BASE_DIR /output/
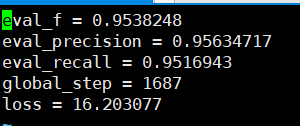
ความแม่นยำในการเรียกคืนที่สามารถมองเห็นได้ตามชุดการตรวจสอบมีทั้งหมดสูงกว่า 95%
นี่คือตัวอย่างของชุดทดสอบการทำนาย

รูปต่อไปนี้แสดงหมวดหมู่ที่คาดการณ์ไว้โดยใช้ Bert มันยังแม่นยำมากที่จะเห็นว่าการทำนายสามารถเปรียบเทียบกับหมวดหมู่จริงได้

หมวดหมู่จริงแสดงด้านล่าง

ในความเป็นจริงหลังจากอ่านกระดาษของ Bert คุณสามารถเข้าใจอย่างลึกซึ้งยิ่งขึ้นโดยการรวมรหัสเพื่อปรับแต่งงานดาวน์สตรีม
ในความเป็นจริงงานดาวน์สตรีมคือการแปลงข้อมูลของคุณเป็นรูปแบบที่ต้องการจากนั้นเปลี่ยนหมวดหมู่เอาต์พุตตามต้องการจากนั้นแก้ไขฟังก์ชั่นการประเมินและฟังก์ชั่นการสูญเสีย
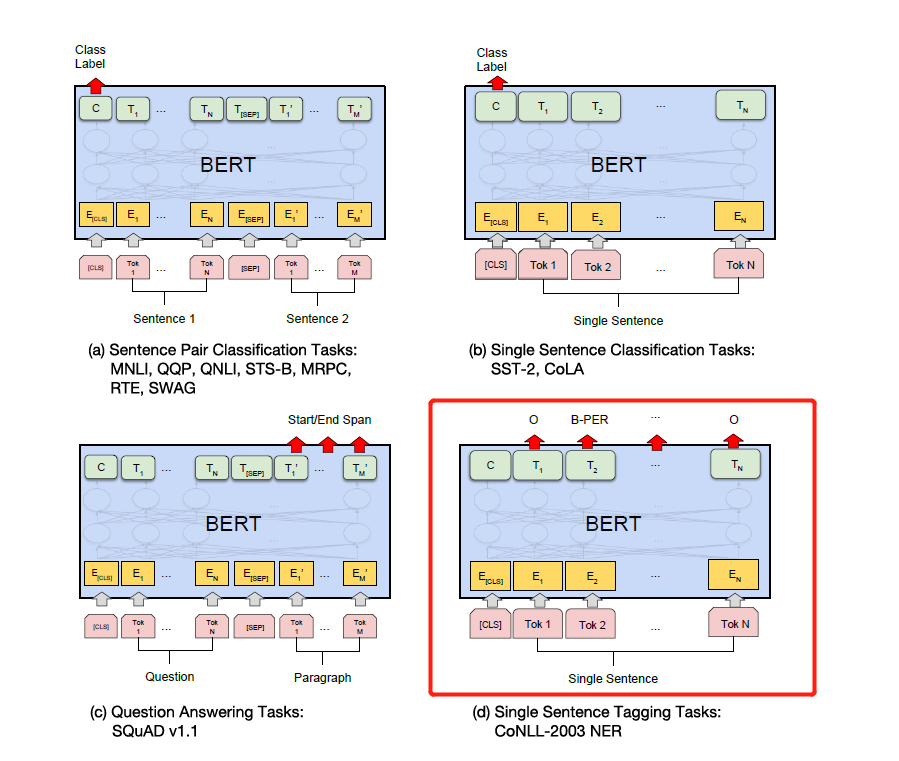
เพียงปรับเปลี่ยนฉลากตามงานดาวน์สตรีมเฉพาะในรูปด้านล่าง อันที่สี่ในรูปด้านล่างคือการแก้ไขใน NER
ต่อมาฉันจะเขียนคำอธิบายโดยละเอียดเกี่ยวกับความสนใจคือสิ่งที่คุณต้องการและกระดาษเบิร์ตและฉันจะอธิบายรายละเอียดร่วมกับรหัสเช่นวิธีการใช้ Add & Norm และทำไมต้องเพิ่ม & norm == ฉันรู้สึกว่าฉันไม่จำเป็นต้องเขียนอีกต่อไป เบิร์ตได้รับความนิยมทั่วถนนและฉันจะไม่ทำล้อซ้ำ เราขอแนะนำให้คุณใช้ซอร์สโค้ดและกระดาษโดยตรง
ในที่สุดก็มีเทคนิคแปลก ๆ และเร้าอารมณ์มากมายสำหรับเบิร์ตในการสำรวจ - ตัวอย่างเช่นคุณสามารถใช้เวกเตอร์เลเยอร์ระดับกลางเพื่อประกบแล้วแช่แข็งเลเยอร์กลาง ฯลฯ
ต่อมาฉันใช้ Bert เวอร์ชัน Pytorch เพื่อทำการแข่งขันและการทดลองหลายครั้งเพื่อเผยแพร่เอกสาร โดยส่วนตัวแล้วฉันคิดว่า Bert เวอร์ชัน Pytorch นั้นง่ายกว่าและใช้งานง่ายกว่าและสะดวกกว่าในการแช่แข็งชั้นกลางของ Bert นอกจากนี้ยังสามารถสะสมการไล่ระดับสีในระหว่างกระบวนการฝึกอบรม คุณสามารถสืบทอดโมเดล Bert โดยตรงและเขียนโมเดลของคุณเอง
(ฉันใช้ Pytorch เพื่อทำการทดลอง Bert ของ Ner ฉันต้องการโอเพนซอร์ส แต่ฉันขี้เกียจเกินไปที่จะแยกแยะ ... ฉันจะโอเพนซอร์สหนึ่งวันเมื่อฉันว่างมีโอเพ่นซอร์สมากมายบนอินเทอร์เน็ตแล้ว 233 แล้ว)
Pytorch อร่อยมาก ... มันง่ายกว่าที่จะปรับเปลี่ยนมากกว่า tensorflow ...
โดยส่วนตัวแล้วฉันขอแนะนำว่าหากคุณทำการแข่งขันหรือเผยแพร่เอกสารและการทดลองให้ใช้เวอร์ชัน Pytorch .. Pytorch ได้ครองโลกวิชาการแล้ว อย่างไรก็ตามเทนเซอร์โฟลว์ในอุตสาหกรรมยังคงใช้กันอย่างแพร่หลาย
อ้างถึง:
https://github.com/google-research/bert
https://github.com/kyzhouhzau/bert-ner
https://github.com/huggingface/transformers Pytorch เวอร์ชัน
ทิ้งหลุมฮ่าฮ่าอ่านกระดาษและอ่านรหัส
https://mp.weixin.qq.com/s/29y2bg4ke-hnwsimd3aauw
https://github.com/zihangdai/xlnet
ไม่กี่วันที่ผ่านมาฉันเห็นโมเดลโอเพนซอร์ส T5 ของ Google จาก XLNET, Roberta, Albert, Spanbert ถึง T5 ตอนนี้ ... ฉันไม่สามารถยืนได้เลย ... ตอนนี้การแข่งขัน NLP นั้นถูกครอบงำโดยการฝึกอบรมก่อน ...


