BRIO
1.0.0
該倉庫包含我們紙奶油店的代碼,數據和訓練有素的模型:將順序提出抽象性摘要。
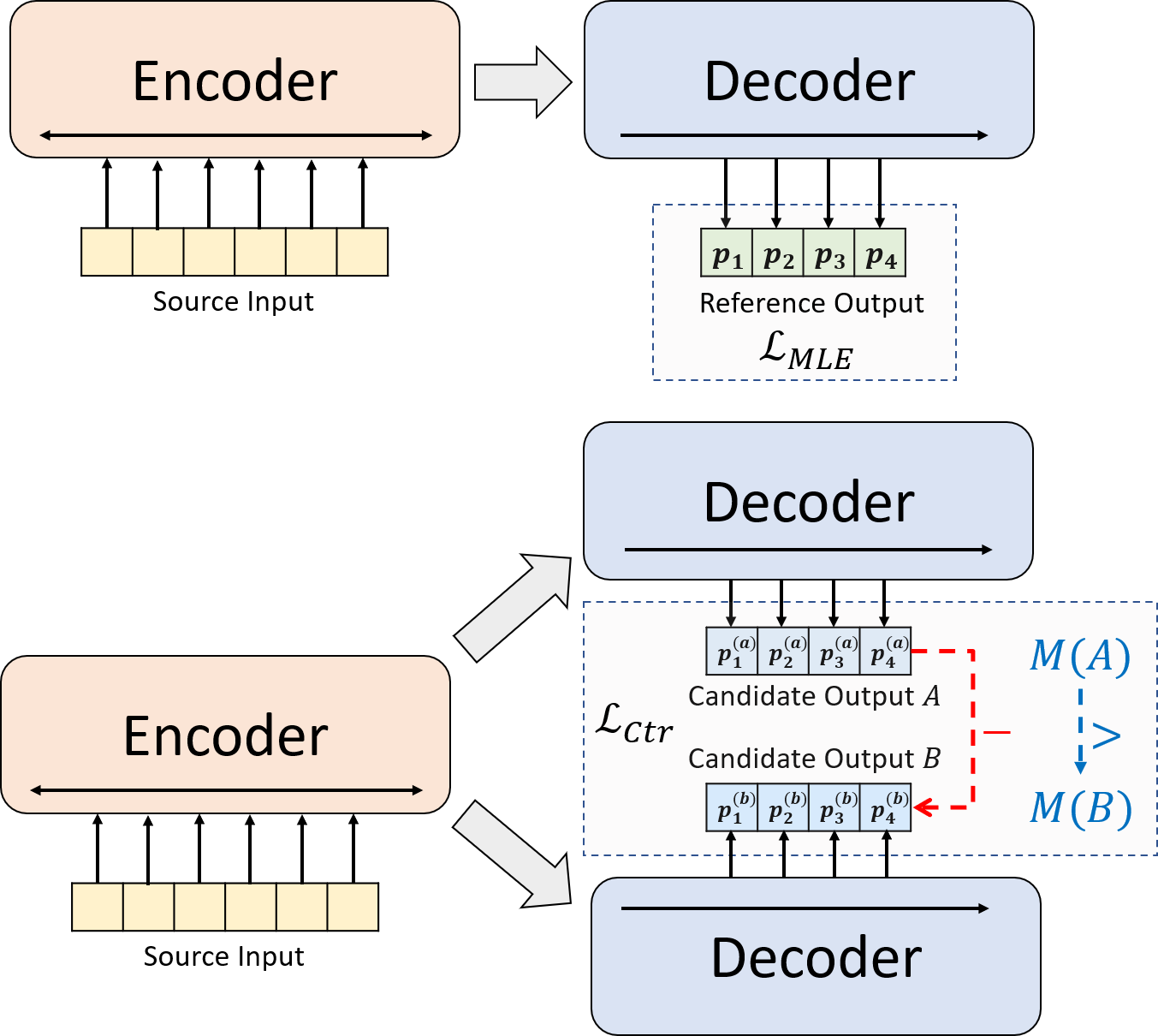
我們提出了一種用於神經抽象摘要的新型培訓範式。我們不用單獨使用MLE培訓,而是引入了對比度學習組件,該組件鼓勵抽像模型更準確地估算系統生成的摘要的可能性。
python3.8conda create --name env --file spec-file.txtpip install -r requirements.txt激活Conda Env)compare_mt > https://github.com/neulab/compare-mt git clone https://github.com/neulab/compare-mt.git
cd ./compare-mt
pip install -r requirements.txt
python setup.py install我們的代碼基於HuggingFace的Transformers庫。
cal_rouge.py >胭脂計算config.py >模型配置data_utils.py > dataloaderlabel_smoothing_loss.py >標籤平滑損失main.py >培訓和評估程序model.py - >型號modeling_bart.py , modeling_pegasus.py >從變形金剛庫修改以支持更有效的訓練preprocess.py >數據預處理utils.py >實用程序功能gen_candidate.py >生成候選摘要應為我們的實驗創建以下目錄。
./cache >存儲模型檢查點./result result->存儲評估結果我們將以下數據集用於實驗。
您可以在CNNDM,CNNDM(CASED)和XSUM上下載我們實驗的預處理數據。
Donwloading後,您應該在此根目錄中解壓縮zip文件。
對於NYT,您將需要獲得許可證,請關注https://github.com/kedz/summarization-datasets進行預處理。
要從預訓練的模型中生成候選摘要,請運行
python gen_candidate.py --gpuid [gpuid] --src_dir [path of the input file (e.g. test.source)] --tgt_dir [path of the output file] --dataset [cnndm/xsum] 對於數據預處理,請運行
python preprocess.py --src_dir [path of the raw data] --tgt_dir [output path] --split [train/val/test] --cand_num [number of candidate summaries] --dataset [cnndm/xsum/nyt] -l [lowercase if the flag is set] src_dir應包含以下文件(以測試拆分為例):
test.sourcetest.source.tokenizedtest.targettest.target.tokenizedtest.outtest.out.tokenized test.out.tokenized文件的每一行應包含一個test.out 。特別是,您應該將一個數據樣本的候選摘要放在test.out和test.out.tokenized中的相鄰行中。
注意:在數據預處理後,您還應將原始文件test.source , test.target放入創建的數據文件夾(例如./cnndm/diverse/test.source )中。
我們使用Standford Corenlp提供的PTB令牌(在此處下載)。請注意,令牌化文本僅用於評估。為了使文件歸為文件,您可以運行(以test.source為例)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat test.source | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > test.source.tokenized我們已在./examples/raw_data raw_data中提供了示例文件。
預處理過程將將處理後的數據存儲為tgt_dir中的單獨的JSON文件。
# starting from the root directory
# create folders
mkdir ./cnndm
mkdir ./cnndm/diverse
mkdir ./cnndm/diverse/test
# suppose that the raw files are at ./raw_data, the results will be saved at ./cnndm/diverse/test
# please remember to put the source file and the target file on test set into the folder, e.g. ./cnndm/diverse/test.source
python preprocess.py --src_dir ./raw_data --tgt_dir ./cnndm/diverse --split test --cand_num 16 --dataset cnndm -l
您可以在main.py中指定超參數。我們還提供CNNDM(NYT共享相同設置)和XSUM config.py的特定設置。
python main.py --cuda --gpuid [list of gpuid] --config [name of the config (cnndm/xsum)] -l 檢查點和日誌將保存在./cache的子文件夾中。
python main.py --cuda --gpuid 0 1 2 3 --config cnndm -l python main.py --cuda --gpuid [list of gpuid] -l --config [name of the config (cnndm/xsum)] --model_pt [model path]模型路徑應為./cache目錄中的子目錄,例如cnndm/model.pt (它不應包含前綴./cache/ )。
對於胭脂計算,我們在論文中使用標準胭脂perl包。在計算胭脂分數之前,我們在較低和令牌化(使用PTB令牌)文本。請注意,該軟件包計算出的分數將與評估的訓練/間隔階段中計算/報告的胭脂分數有所不同,因為我們使用純粹的基於Python的胭脂實現來計算這些分數以提高效率。
如果在設置Rouge Perl軟件包時遇到問題(不幸的是,發生了很多:(),則可以考慮使用純基於Python的Rouge軟件包,例如我們從Comparare-Mt軟件包中使用的一個。
我們在cal_rouge.py中提供評估腳本。如果您要使用Perl Rouge軟件包,請將13行更改為Perl Rouge軟件包的路徑。
_ROUGE_PATH = '/YOUR-ABSOLUTE-PATH/ROUGE-RELEASE-1.5.5/'要評估模型性能,請首先使用以下命令來生成摘要。
python main.py --cuda --gpuid [single gpu] --config [name of the config (cnndm/xsum)] -e --model_pt [model path] -g [evaluate the model as a generator] -r [evaluate the model as a scorer/reranker]模型路徑應為./cache目錄中的子目錄,例如cnndm/model.pt (它不應包含前綴./cache/ )。輸出將保存在具有相同名稱的./result點文件夾的子文件夾中。
# write the system-generated files to a file: ./result/cnndm/test.out
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_generation.bin -g
# tokenize the output file - > ./result/cnndm/test.out.tokenized (you may use other tokenizers)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat ./result/cnndm/test.out | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > ./result/cnndm/test.out.tokenized
# calculate the ROUGE scores using ROUGE Perl Package
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l
# calculate the ROUGE scores using ROUGE Python Implementation
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l -p # rerank the candidate summaries
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_ranking.bin -r
# calculate the ROUGE scores using ROUGE Perl Package
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l
# calculate the ROUGE scores using ROUGE Python Implementation
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l -p 以下是由標準胭脂perl軟件包計算出的胭脂分數。
| Rouge-1 | Rouge-2 | 胭脂-l | |
|---|---|---|---|
| 巴特 | 44.29 | 21.17 | 41.09 |
| Brio-Ctr | 47.28 | 22.93 | 44.15 |
| Brio-mul | 47.78 | 23.55 | 44.57 |
| Brio-mul(殼體) | 48.01 | 23.76 | 44.63 |
| Rouge-1 | Rouge-2 | 胭脂-l | |
|---|---|---|---|
| 飛馬 | 47.46 | 24.69 | 39.53 |
| Brio-Ctr | 48.13 | 25.13 | 39.84 |
| Brio-mul | 49.07 | 25.59 | 40.40 |
| Rouge-1 | Rouge-2 | 胭脂-l | |
|---|---|---|---|
| 巴特 | 55.78 | 36.61 | 52.60 |
| Brio-Ctr | 55.98 | 36.54 | 52.51 |
| Brio-mul | 57.75 | 38.64 | 54.54 |
我們在這些數據集上的模型輸出可以在./output中找到。
我們總結了下面的輸出和模型檢查點。您可以使用model.load_state_dict(torch.load(path_to_checkpoint))加載這些檢查點。
| 檢查點 | 模型輸出 | 參考輸出 | |
|---|---|---|---|
| CNNDM | model_generation.bin model_ranking.bin | cnndm.test.ours.out | cnndm.test.Reference |
| CNNDM(外殼) | model_generation.bin | cnndm.test.ours.cased.out | cnndm.test.cased.Reference |
| XSUM | model_generation.bin model_ranking.bin | xsum.test.ours.out | xsum.test.Reference |
您可以從擁抱面變壓器加載我們的訓練有素的型號,以供發電。我們關於CNNDM( Yale-LILY/brio-cnndm-uncased , Yale-LILY/brio-cnndm-cased )的模型檢查點是標準的BART模型(即,BartforConditionalgeneration),而我們的XSUM模型檢查點是Xsum( Yale-LILY/brio-xsum-cased )的模型檢查點,是一種標準的PEGASENDECTION(YALILY/BRIO-XSSUM-cASED)。
from transformers import BartTokenizer , PegasusTokenizer
from transformers import BartForConditionalGeneration , PegasusForConditionalGeneration
IS_CNNDM = True # whether to use CNNDM dataset or XSum dataset
LOWER = False
ARTICLE_TO_SUMMARIZE = "Manchester United superstar Cristiano Ronaldo scored his 806th career goal in Old Trafford,
breaking FIFA's all-time record for most goals in competitive matches in men's football history.
It was the second of three goals the Portuguese attacker scored during the game,
leading United to a 3-2 victory over Tottenham and finishing the day with 807 total career goals.
The previous FIFA goal record was held by Josef Bican, with 805 goals."
# Load our model checkpoints
if IS_CNNDM :
model = BartForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
tokenizer = BartTokenizer . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
else :
model = PegasusForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
tokenizer = PegasusTokenizer . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
max_length = 1024 if IS_CNNDM else 512
# generation example
if LOWER :
article = ARTICLE_TO_SUMMARIZE . lower ()
else :
article = ARTICLE_TO_SUMMARIZE
inputs = tokenizer ([ article ], max_length = max_length , return_tensors = "pt" , truncation = True )
# Generate Summary
summary_ids = model . generate ( inputs [ "input_ids" ])
print ( tokenizer . batch_decode ( summary_ids , skip_special_tokens = True , clean_up_tokenization_spaces = False )[ 0 ])注意:我們的擁抱面檢查點不能直接加載到代碼中的Pytorch型號( BRIO )上,因為我們的Pytorch型號是Bart/Pegasus上的包裝器,以提高培訓效率。但是,您可以使用它來啟動我們的pytorch模型,例如
model = BRIO ( 'Yale-LILY/brio-cnndm-uncased' , tok . pad_token_id , is_pegasus = False )

