BRIO
1.0.0
Repo ini berisi kode, data, dan model terlatih untuk kertas brio kami: membawa urutan ringkasan abstraktif.
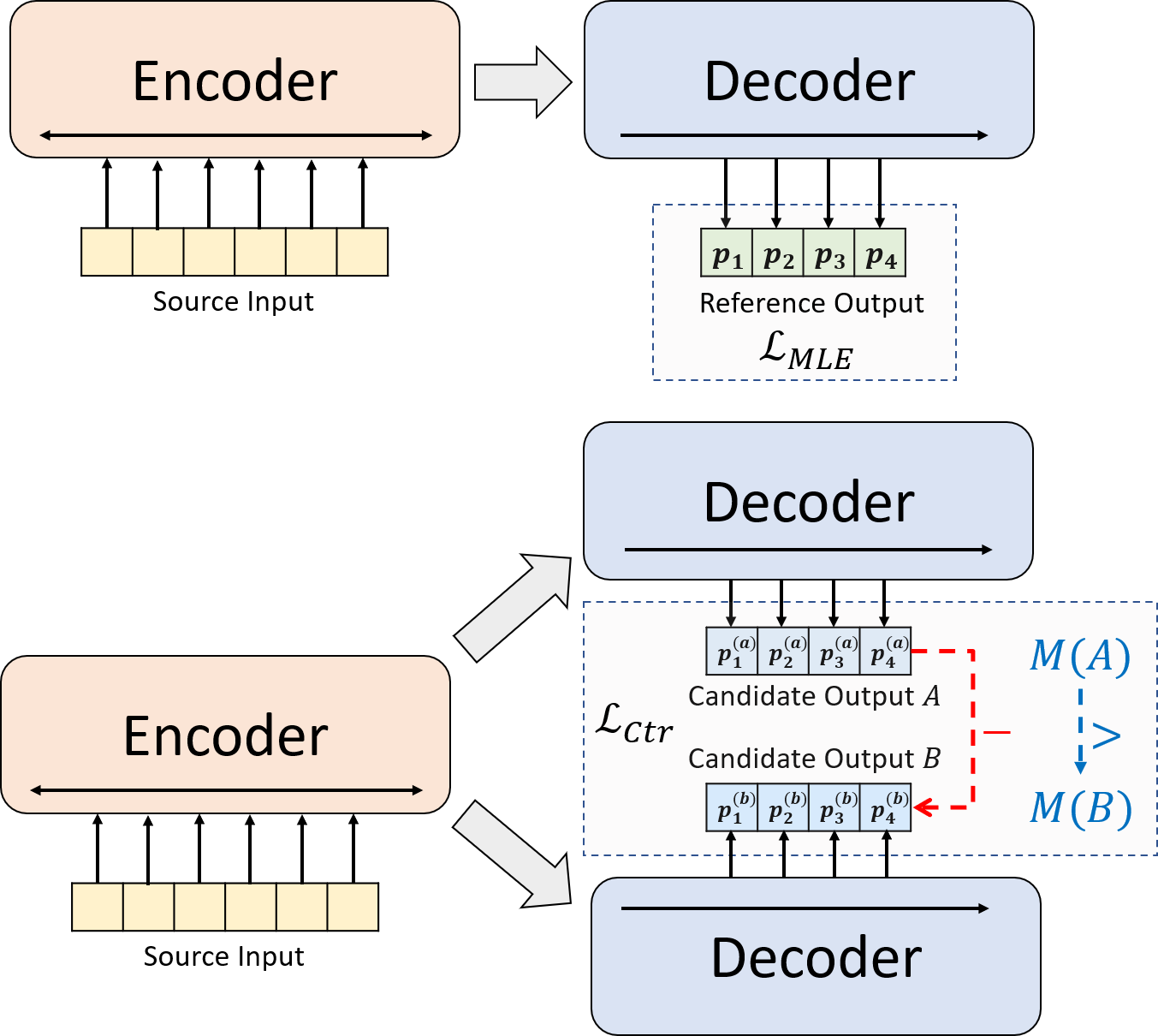
Kami menyajikan paradigma pelatihan baru untuk ringkasan abstraktif saraf. Alih-alih menggunakan pelatihan MLE saja, kami memperkenalkan komponen pembelajaran yang kontras, yang mendorong model abstraktif untuk memperkirakan probabilitas ringkasan yang dihasilkan sistem lebih akurat.
python3.8conda create --name env --file spec-file.txtpip install -r requirements.txtcompare_mt -> https://github.com/neulab/compare-mt git clone https://github.com/neulab/compare-mt.git
cd ./compare-mt
pip install -r requirements.txt
python setup.py installKode kami didasarkan pada perpustakaan Transformers HuggingFace.
cal_rouge.py -> Perhitungan Rougeconfig.py -> Model Configurationdata_utils.py -> Dataloaderlabel_smoothing_loss.py -> label smoothing lossmain.py -> Prosedur Pelatihan dan Evaluasimodel.py -> modelmodeling_bart.py , modeling_pegasus.py -> dimodifikasi dari perpustakaan Transformers untuk mendukung pelatihan yang lebih efisienpreprocess.py -> data preprocessingutils.py -> fungsi utilitasgen_candidate.py -> menghasilkan ringkasan kandidatDirektori berikut harus dibuat untuk percobaan kami.
./cache -> menyimpan pos pemeriksaan model./result -> Menyimpan Hasil Evaluasi Kami menggunakan dataset berikut untuk percobaan kami.
Anda dapat mengunduh data yang diproses sebelumnya untuk percobaan kami pada CNNDM, CNNDM (CASED) dan XSUM.
Setelah DONWLOADING, Anda harus membuka ritsleting file zip di direktori root ini.
Untuk NYT, Anda harus mendapatkan lisensi dan silakan ikuti https://github.com/kedz/summarization-datasets untuk pra-pemrosesan.
Untuk menghasilkan ringkasan kandidat dari model pra-terlatih, silakan jalankan
python gen_candidate.py --gpuid [gpuid] --src_dir [path of the input file (e.g. test.source)] --tgt_dir [path of the output file] --dataset [cnndm/xsum] Untuk preprocessing data, silakan jalankan
python preprocess.py --src_dir [path of the raw data] --tgt_dir [output path] --split [train/val/test] --cand_num [number of candidate summaries] --dataset [cnndm/xsum/nyt] -l [lowercase if the flag is set] src_dir harus berisi file -file berikut (menggunakan tes split sebagai contoh):
test.sourcetest.source.tokenizedtest.targettest.target.tokenizedtest.outtest.out.tokenized Setiap baris file ini harus berisi sampel kecuali untuk test.out dan test.out.tokenized . Secara khusus, Anda harus menempatkan ringkasan kandidat untuk satu sampel data di garis tetangga di test.out dan test.out.tokenized .
Catatan : Setelah preprocessing data, Anda juga harus memasukkan test.source , test.target ke dalam folder data yang dibuat (mis ./cnndm/diverse/test.source )
Kami menggunakan tokenizer PTB yang disediakan oleh Standford Corenlp (unduh di sini). Harap dicatat bahwa teks tokenized hanya digunakan untuk evaluasi. Untuk tokenize file, Anda dapat menjalankan (menggunakan test.source sebagai contoh)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat test.source | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > test.source.tokenized Kami telah memberikan file contoh di ./examples/raw_data .
Prosedur preprocessing akan menyimpan data yang diproses sebagai file JSON terpisah di tgt_dir .
# starting from the root directory
# create folders
mkdir ./cnndm
mkdir ./cnndm/diverse
mkdir ./cnndm/diverse/test
# suppose that the raw files are at ./raw_data, the results will be saved at ./cnndm/diverse/test
# please remember to put the source file and the target file on test set into the folder, e.g. ./cnndm/diverse/test.source
python preprocess.py --src_dir ./raw_data --tgt_dir ./cnndm/diverse --split test --cand_num 16 --dataset cnndm -l
Anda dapat menentukan hiper-parameter di main.py Kami juga memberikan pengaturan spesifik pada CNNDM (NYT berbagi pengaturan yang sama) dan XSUM di config.py .
python main.py --cuda --gpuid [list of gpuid] --config [name of the config (cnndm/xsum)] -l Pos Pemeriksaan dan Log akan disimpan dalam subfolder ./cache .
python main.py --cuda --gpuid 0 1 2 3 --config cnndm -l python main.py --cuda --gpuid [list of gpuid] -l --config [name of the config (cnndm/xsum)] --model_pt [model path] Jalur model harus menjadi subdirektori di direktori ./cache , misalnya cnndm/model.pt (itu tidak boleh berisi awalan ./cache/ ).
Untuk perhitungan Rouge, kami menggunakan paket Rouge Perl standar dari sini di koran kami. Kami menurunkan dan tokenized (menggunakan tokenizer PTB) sebelum menghitung skor Rouge. Harap dicatat bahwa skor yang dihitung oleh paket ini akan sangat berbeda dari skor Rouge yang dihitung/dilaporkan selama tahap evaluasi pelatihan/intermidiate, karena kami menggunakan implementasi rouge berbasis Python murni untuk menghitung skor tersebut untuk efisiensi yang lebih baik.
Jika Anda mengalami masalah saat menyiapkan paket Rouge Perl (sayangnya itu terjadi banyak :(), Anda dapat mempertimbangkan menggunakan paket Rouge berbasis Python murni seperti yang kami gunakan dari paket perbandingan-MT.
Kami memberikan skrip evaluasi di cal_rouge.py . Jika Anda akan menggunakan paket Perl Rouge, silakan ubah baris 13 ke jalur paket Perl Rouge Anda.
_ROUGE_PATH = '/YOUR-ABSOLUTE-PATH/ROUGE-RELEASE-1.5.5/'Untuk mengevaluasi kinerja model, silakan gunakan perintah berikut untuk menghasilkan ringkasan.
python main.py --cuda --gpuid [single gpu] --config [name of the config (cnndm/xsum)] -e --model_pt [model path] -g [evaluate the model as a generator] -r [evaluate the model as a scorer/reranker] Jalur model harus menjadi subdirektori di direktori ./cache , misalnya cnndm/model.pt (itu tidak boleh berisi awalan ./cache/ ). Output akan disimpan dalam subfolder ./result memiliki nama yang sama dari folder pos pemeriksaan.
# write the system-generated files to a file: ./result/cnndm/test.out
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_generation.bin -g
# tokenize the output file - > ./result/cnndm/test.out.tokenized (you may use other tokenizers)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat ./result/cnndm/test.out | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > ./result/cnndm/test.out.tokenized
# calculate the ROUGE scores using ROUGE Perl Package
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l
# calculate the ROUGE scores using ROUGE Python Implementation
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l -p # rerank the candidate summaries
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_ranking.bin -r
# calculate the ROUGE scores using ROUGE Perl Package
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l
# calculate the ROUGE scores using ROUGE Python Implementation
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l -p Berikut ini adalah skor Rouge yang dikalsualkan oleh paket Perl Rouge Standard.
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Bart | 44.29 | 21.17 | 41.09 |
| Brio-Ctr | 47.28 | 22.93 | 44.15 |
| Brio-Mul | 47.78 | 23.55 | 44.57 |
| Brio-Mul (Cased) | 48.01 | 23.76 | 44.63 |
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Pegasus | 47.46 | 24.69 | 39.53 |
| Brio-Ctr | 48.13 | 25.13 | 39.84 |
| Brio-Mul | 49.07 | 25.59 | 40.40 |
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Bart | 55.78 | 36.61 | 52.60 |
| Brio-Ctr | 55.98 | 36.54 | 52.51 |
| Brio-Mul | 57.75 | 38.64 | 54.54 |
Output model kami pada dataset ini dapat ditemukan di ./output .
Kami merangkum output dan model pos pemeriksaan di bawah ini. Anda dapat memuat pos pemeriksaan ini menggunakan model.load_state_dict(torch.load(path_to_checkpoint)) .
| Pos pemeriksaan | Output model | Output referensi | |
|---|---|---|---|
| CNNDM | model_generation.bin model_ranking.bin | cnndm.test.ours.out | cnndm.test.referensi |
| CNNDM (cased) | model_generation.bin | cnndm.test.ours.cased.out | cnndm.test.cased.reference |
| Xsum | model_generation.bin model_ranking.bin | xsum.test.ours.out | xsum.test.referensi |
Anda dapat memuat model terlatih kami untuk generasi dari transformator pelukan. Pemeriksaan model kami pada CNNDM ( Yale-LILY/brio-cnndm-uncased , Yale-LILY/brio-cnndm-cased ) adalah model BART standar (yaitu, bartforconditionalgeneration) sedangkan model model kami ( Yale-LILY/brio-xsum-cased ) adalah pegasus standar.
from transformers import BartTokenizer , PegasusTokenizer
from transformers import BartForConditionalGeneration , PegasusForConditionalGeneration
IS_CNNDM = True # whether to use CNNDM dataset or XSum dataset
LOWER = False
ARTICLE_TO_SUMMARIZE = "Manchester United superstar Cristiano Ronaldo scored his 806th career goal in Old Trafford,
breaking FIFA's all-time record for most goals in competitive matches in men's football history.
It was the second of three goals the Portuguese attacker scored during the game,
leading United to a 3-2 victory over Tottenham and finishing the day with 807 total career goals.
The previous FIFA goal record was held by Josef Bican, with 805 goals."
# Load our model checkpoints
if IS_CNNDM :
model = BartForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
tokenizer = BartTokenizer . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
else :
model = PegasusForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
tokenizer = PegasusTokenizer . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
max_length = 1024 if IS_CNNDM else 512
# generation example
if LOWER :
article = ARTICLE_TO_SUMMARIZE . lower ()
else :
article = ARTICLE_TO_SUMMARIZE
inputs = tokenizer ([ article ], max_length = max_length , return_tensors = "pt" , truncation = True )
# Generate Summary
summary_ids = model . generate ( inputs [ "input_ids" ])
print ( tokenizer . batch_decode ( summary_ids , skip_special_tokens = True , clean_up_tokenization_spaces = False )[ 0 ]) Catatan : Pos Pemeriksaan kami pada HuggingFace tidak dapat secara langsung dimuat ke model Pytorch ( BRIO ) dalam kode kami karena model Pytorch kami adalah pembungkus pada BART/Pegasus untuk efisiensi pelatihan yang lebih baik. Namun, Anda dapat menggunakannya untuk memulai model Pytorch kami, misalnya,
model = BRIO ( 'Yale-LILY/brio-cnndm-uncased' , tok . pad_token_id , is_pegasus = False )

