BRIO
1.0.0
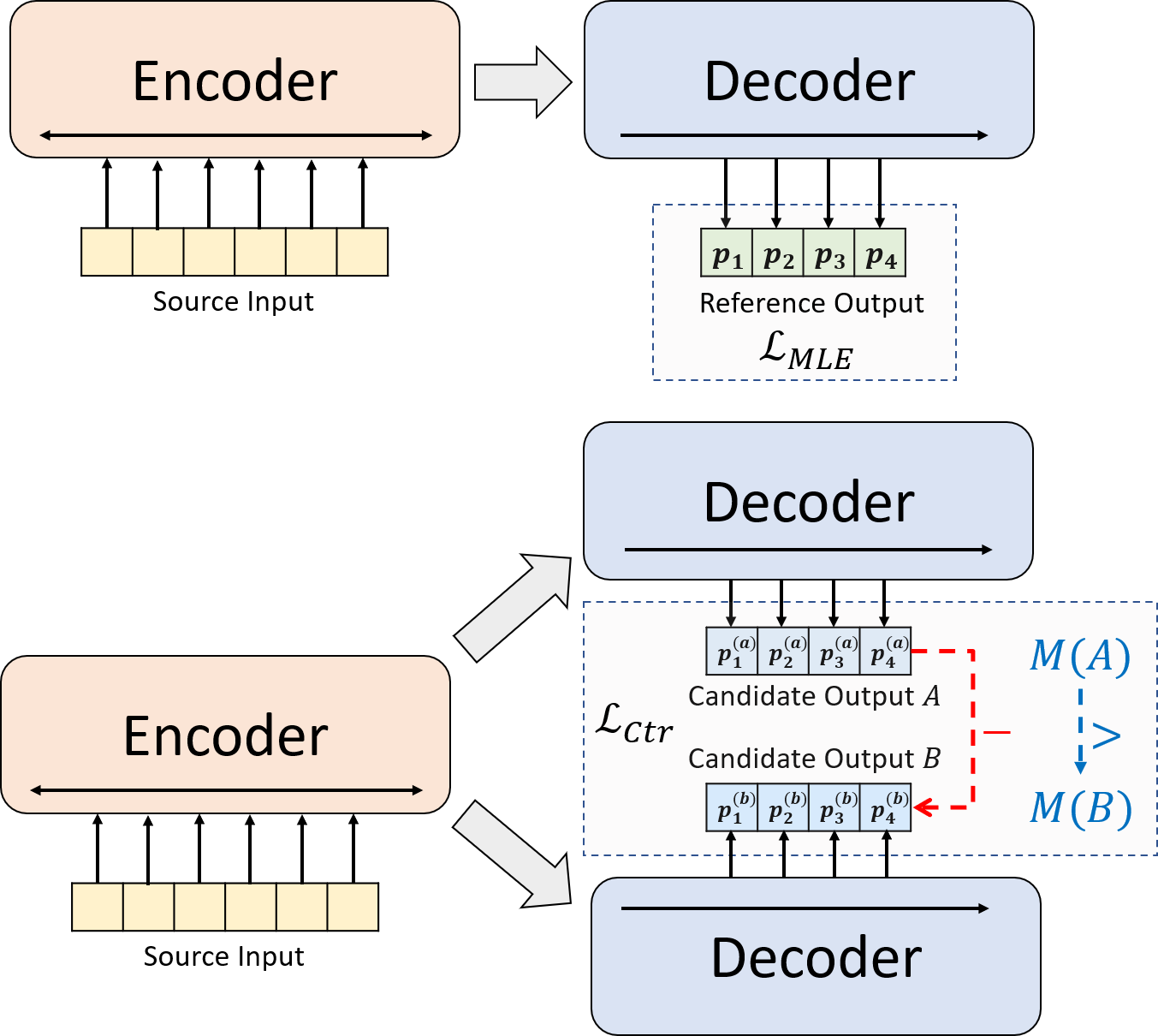
Dieses Repo enthält den Code, die Daten und die geschulten Modelle für unser Papier Brio: die Bestellung in die abstraktive Zusammenfassung bringen.
Wir präsentieren ein neuartiges Trainingsparadigma für die neuronale abstraktische Zusammenfassung. Anstatt das MLE-Training allein zu verwenden, führen wir eine kontrastive Lernkomponente ein, die die abstraktischen Modelle dazu ermutigt, die Wahrscheinlichkeit von systemgenerierten Zusammenfassungen genauer abzuschätzen.
python3.8conda create --name env --file spec-file.txtpip install -r requirements.txtcompare_mt -> https://github.com/neulab/compare-mt git clone https://github.com/neulab/compare-mt.git
cd ./compare-mt
pip install -r requirements.txt
python setup.py installUnser Code basiert auf der Transformers Library von Huggingface.
cal_rouge.py -> Rouge -Berechnungconfig.py -> Modellkonfigurationdata_utils.py -> Dataloaderlabel_smoothing_loss.py -> LABE -Glättungsverlust beschriftenmain.py -> Schulungs- und Bewertungsverfahrenmodel.py -> Modellemodeling_bart.py , modeling_pegasus.py -> Aus der Transformators Library geändert, um ein effizienteres Training zu unterstützenpreprocess.py -> Datenvorverarbeitungutils.py -> Dienstprogrammfunktionengen_candidate.py -> Kandidatenzusammenfassungen generierenFür unsere Experimente sollten die folgenden Verzeichnisse erstellt werden.
./cache -> Speichern Modellkontrollpunkte./result -> Speichern Sie die Bewertungsergebnisse Wir verwenden die folgenden Datensätze für unsere Experimente.
Sie können die vorverarbeiteten Daten für unsere Experimente zu CNNDM, CNNDM (CAST) und XSUM herunterladen.
Nach Donwloading sollten Sie die Zip -Dateien in diesem Stammverzeichnis entpacken.
Für NYT müssen Sie die Lizenz erhalten und https://github.com/kedz/summarization-datasets für die Vorverarbeitung folgen.
Um die Zusammenfassungen der Kandidaten aus einem vorgeborenen Modell zu generieren, rennen Sie bitte
python gen_candidate.py --gpuid [gpuid] --src_dir [path of the input file (e.g. test.source)] --tgt_dir [path of the output file] --dataset [cnndm/xsum] Für die Datenvorverarbeitung führen Sie bitte aus
python preprocess.py --src_dir [path of the raw data] --tgt_dir [output path] --split [train/val/test] --cand_num [number of candidate summaries] --dataset [cnndm/xsum/nyt] -l [lowercase if the flag is set] src_dir sollte die folgenden Dateien enthalten (unter Verwendung des Beispiels als Beispiel):
test.sourcetest.source.tokenizedtest.targettest.target.tokenizedtest.outtest.out.tokenized Jede Zeile dieser Dateien sollte eine Probe mit Ausnahme von test.out und test.out.tokenized enthalten. Insbesondere sollten Sie die Kandidatenzusammenfassungen für eine Datenprobe in den benachbarten Linien in test.out und test.out.tokenized einfügen.
Hinweise : Nach der Datenvorverarbeitung sollten Sie auch die RAW -Datei test.source , test.target in den erstellten Datenordner einfügen (z ./cnndm/diverse/test.source )
Wir verwenden den von Standford CoreLP (Download hier heruntergeladen). Bitte beachten Sie, dass tokenisierte Texte nur zur Bewertung verwendet werden. Um eine Datei zu tokenisieren, können Sie ausführen (mit Test.ource als Beispiel).
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat test.source | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > test.source.tokenized Wir haben die Beispieldateien in ./examples/raw_data bereitgestellt.
Die Vorverarbeitungsverfahren speichert die verarbeiteten Daten als separate JSON -Dateien in tgt_dir .
# starting from the root directory
# create folders
mkdir ./cnndm
mkdir ./cnndm/diverse
mkdir ./cnndm/diverse/test
# suppose that the raw files are at ./raw_data, the results will be saved at ./cnndm/diverse/test
# please remember to put the source file and the target file on test set into the folder, e.g. ./cnndm/diverse/test.source
python preprocess.py --src_dir ./raw_data --tgt_dir ./cnndm/diverse --split test --cand_num 16 --dataset cnndm -l
Sie können die Hyperparameter in main.py angeben. Wir geben auch die spezifischen Einstellungen auf CNNDM (NYT Share dieselbe Einstellung) und XSUM in config.py an.
python main.py --cuda --gpuid [list of gpuid] --config [name of the config (cnndm/xsum)] -l Die Kontrollpunkte und das Protokoll werden in einem Unterordner von ./cache gespeichert.
python main.py --cuda --gpuid 0 1 2 3 --config cnndm -l python main.py --cuda --gpuid [list of gpuid] -l --config [name of the config (cnndm/xsum)] --model_pt [model path] Der Modellpfad sollte ein Unterverzeichnis im Verzeichnis ./cache ./cache/ cnndm/model.pt .
Für die Berechnung von Rouge verwenden wir das Standard -Rouge Perl -Paket von hier in unserem Artikel. Wir senken und tokenisierte (unter Verwendung von PTB -Tokenizer) -Texten, bevor wir die Rouge -Scores berechnen. Bitte beachten Sie, dass die von diesem Paket berechneten Ergebnisse sich von den während des Trainings-/Intermidiate-Evalution berechneten/gemeldeten Rouge-Bewertungen unterscheiden würden, da wir eine reine Python-basierte Rouge-Implementierung verwenden, um diese Bewertungen für eine bessere Effizienz zu berechnen.
Wenn Sie bei der Einrichtung des Rouge Perl-Pakets auf Probleme stoßen (leider passiert es viel :(), können Sie in Betracht ziehen, ein reines Python-basiertes Rouge-Paket zu verwenden, wie das, das wir aus dem Paket für das Vergleiche-MT verwendet haben.
Wir bieten das Evaluierungsskript in cal_rouge.py . Wenn Sie das Perl Rouge -Paket verwenden, wechseln Sie die Zeile 13 in den Pfad Ihres Perl Rouge -Pakets.
_ROUGE_PATH = '/YOUR-ABSOLUTE-PATH/ROUGE-RELEASE-1.5.5/'Um die Modellleistung zu bewerten, verwenden Sie bitte zunächst den folgenden Befehl, um die Zusammenfassungen zu generieren.
python main.py --cuda --gpuid [single gpu] --config [name of the config (cnndm/xsum)] -e --model_pt [model path] -g [evaluate the model as a generator] -r [evaluate the model as a scorer/reranker] Der Modellpfad sollte ein Unterverzeichnis im Verzeichnis ./cache ./cache/ cnndm/model.pt . Die Ausgabe wird in einem Unterordner von ./result mit demselben Namen wie des Checkpoint -Ordners gespeichert.
# write the system-generated files to a file: ./result/cnndm/test.out
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_generation.bin -g
# tokenize the output file - > ./result/cnndm/test.out.tokenized (you may use other tokenizers)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat ./result/cnndm/test.out | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > ./result/cnndm/test.out.tokenized
# calculate the ROUGE scores using ROUGE Perl Package
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l
# calculate the ROUGE scores using ROUGE Python Implementation
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l -p # rerank the candidate summaries
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_ranking.bin -r
# calculate the ROUGE scores using ROUGE Perl Package
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l
# calculate the ROUGE scores using ROUGE Python Implementation
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l -p Im Folgenden finden Sie Rouge -Scores, die durch das Standard -Rouge Perl -Paket berechnet wurden.
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Bart | 44.29 | 21.17 | 41.09 |
| BRIO-CTR | 47,28 | 22.93 | 44.15 |
| Brio-Mul | 47.78 | 23.55 | 44,57 |
| Brio-Mul (Gehäuse) | 48.01 | 23.76 | 44,63 |
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Pegasus | 47,46 | 24.69 | 39,53 |
| BRIO-CTR | 48.13 | 25.13 | 39,84 |
| Brio-Mul | 49.07 | 25.59 | 40.40 |
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Bart | 55.78 | 36.61 | 52.60 |
| BRIO-CTR | 55.98 | 36.54 | 52,51 |
| Brio-Mul | 57.75 | 38,64 | 54,54 |
Unsere Modellausgaben auf diesen Datensätzen finden Sie in ./output .
Wir fassen die folgenden Ausgänge und Modell -Checkpoints zusammen. Sie können diese Kontrollpunkte mit model.load_state_dict(torch.load(path_to_checkpoint)) laden.
| Kontrollpunkte | Modellausgabe | Referenzausgabe | |
|---|---|---|---|
| Cnndm | model_generation.bin model_ranking.bin | cnndm.test.ours.out | cnndm.test.reference |
| CNNDM (Gehäuse) | model_generation.bin | cnndm.test.ours.cased.out | cnndm.test.cased.Reference |
| Xsum | model_generation.bin model_ranking.bin | xsum.test.ours.out | xsum.test.Reference |
Sie können unsere geschulten Modelle für die Generation von Huggingface -Transformatoren laden. Unser Modellkontrollpunkt für CNNDM ( Yale-LILY/brio-cnndm-uncased , Yale-LILY/brio-cnndm-cased ) ist ein Standard-BART-Modell (dh Bartforconditionalgeneration), während unser Modell-Checkpoint auf XSUM ( Yale-LILY/brio-xsum-cased ) ein Standard-Peegasus-Modell (IEBE) (IEGASUSS) (I., I., IEGASUS).
from transformers import BartTokenizer , PegasusTokenizer
from transformers import BartForConditionalGeneration , PegasusForConditionalGeneration
IS_CNNDM = True # whether to use CNNDM dataset or XSum dataset
LOWER = False
ARTICLE_TO_SUMMARIZE = "Manchester United superstar Cristiano Ronaldo scored his 806th career goal in Old Trafford,
breaking FIFA's all-time record for most goals in competitive matches in men's football history.
It was the second of three goals the Portuguese attacker scored during the game,
leading United to a 3-2 victory over Tottenham and finishing the day with 807 total career goals.
The previous FIFA goal record was held by Josef Bican, with 805 goals."
# Load our model checkpoints
if IS_CNNDM :
model = BartForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
tokenizer = BartTokenizer . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
else :
model = PegasusForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
tokenizer = PegasusTokenizer . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
max_length = 1024 if IS_CNNDM else 512
# generation example
if LOWER :
article = ARTICLE_TO_SUMMARIZE . lower ()
else :
article = ARTICLE_TO_SUMMARIZE
inputs = tokenizer ([ article ], max_length = max_length , return_tensors = "pt" , truncation = True )
# Generate Summary
summary_ids = model . generate ( inputs [ "input_ids" ])
print ( tokenizer . batch_decode ( summary_ids , skip_special_tokens = True , clean_up_tokenization_spaces = False )[ 0 ]) Hinweise : Unsere Checkpoints on Huggingface können in unserem Code nicht direkt an das Pytorch -Modell ( BRIO ) geladen werden, da unser Pytorch -Modell ein Wrapper auf BART/Pegasus für eine bessere Trainingseffizienz ist. Sie können es jedoch verwenden, um unser Pytorch -Modell, z.
model = BRIO ( 'Yale-LILY/brio-cnndm-uncased' , tok . pad_token_id , is_pegasus = False )

