BRIO
1.0.0
Este repositório contém o código, dados e modelos treinados para o nosso papel Brio: trazendo ordem para resumo abstrato.
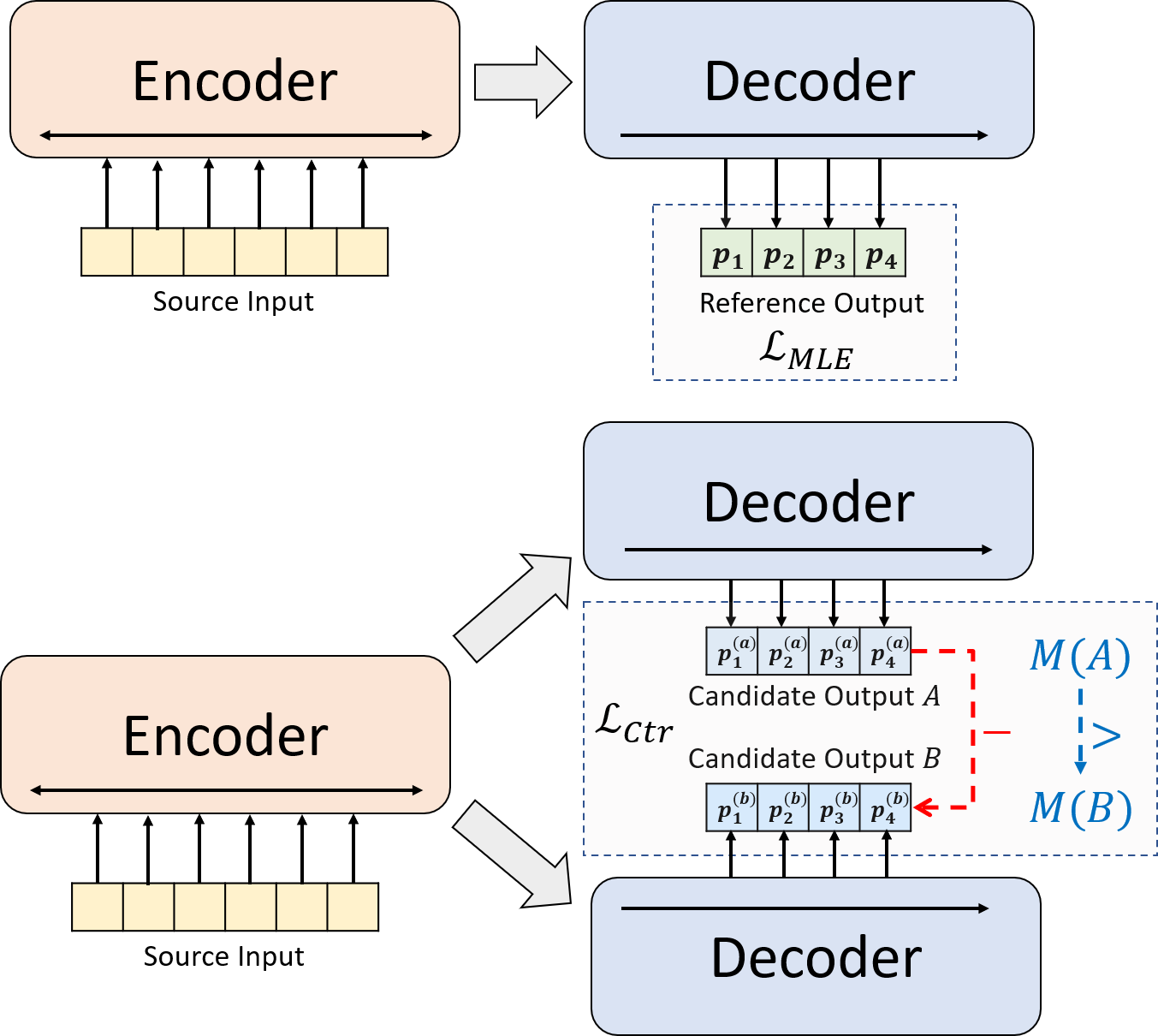
Apresentamos um novo paradigma de treinamento para resumo abstrato neural. Em vez de usar o treinamento da MLE sozinho, introduzimos um componente de aprendizado contrastante, que incentiva os modelos abstratos para estimar a probabilidade de resumos gerados pelo sistema com mais precisão.
python3.8conda create --name env --file spec-file.txtpip install -r requirements.txtcompare_mt -> https://github.com/neulab/compare-mt git clone https://github.com/neulab/compare-mt.git
cd ./compare-mt
pip install -r requirements.txt
python setup.py installNosso código é baseado na biblioteca Transformers da Huggingface.
cal_rouge.py -> cálculo do Rougeconfig.py -> Configuração do modelodata_utils.py -> Dataloaderlabel_smoothing_loss.py -> Perda de suavização de etiquetasmain.py -> Procedimento de treinamento e avaliaçãomodel.py -> modelosmodeling_bart.py , modeling_pegasus.py -> Modificado da Biblioteca Transformers para suportar treinamento mais eficientepreprocess.py -> pré -processamento de dadosutils.py -> Funções de utilitáriogen_candidate.py -> gerar resumos de candidatosOs diretórios a seguir devem ser criados para nossos experimentos.
./cache -> armazenamento de pontos de verificação do modelo./result -> Armazenamento de resultados de avaliação Usamos os seguintes conjuntos de dados para nossos experimentos.
Você pode baixar os dados pré -processados para nossos experimentos no CNNDM, CNNDM (CASED) e XSUM.
Após o DonWloading, você deve descompactar os arquivos ZIP neste diretório raiz.
Para o NYT, você precisará obter a licença e siga https://github.com/kedz/summarization-datasets para pré-processamento.
Para gerar os resumos de candidatos a partir de um modelo pré-treinado, execute
python gen_candidate.py --gpuid [gpuid] --src_dir [path of the input file (e.g. test.source)] --tgt_dir [path of the output file] --dataset [cnndm/xsum] Para pré -processamento de dados, corra
python preprocess.py --src_dir [path of the raw data] --tgt_dir [output path] --split [train/val/test] --cand_num [number of candidate summaries] --dataset [cnndm/xsum/nyt] -l [lowercase if the flag is set] src_dir deve conter os seguintes arquivos (usando o teste de teste como exemplo):
test.sourcetest.source.tokenizedtest.targettest.target.tokenizedtest.outtest.out.tokenized Cada linha desses arquivos deve conter uma amostra, exceto para test.out e test.out.tokenized . Em particular, você deve colocar os resumos do candidato para uma amostra de dados em linhas vizinhas em test.out e test.out.tokenized .
Notas : Após o pré -processamento dos dados, você também deve colocar o arquivo bruto test.source , test.target na pasta de dados criada (por exemplo ./cnndm/diverse/test.source )
Usamos o tokenizador PTB fornecido por Standford Corenlp (download aqui). Observe que os textos tokenizados são usados apenas para avaliação. Para tokenizar um arquivo, você pode ser executado (usando test.source como exemplo)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat test.source | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > test.source.tokenized Fornecemos os exemplos arquivos em ./examples/raw_data Examples/raw_data.
O procedimento de pré -processamento armazenará os dados processados como arquivos JSON separados no tgt_dir .
# starting from the root directory
# create folders
mkdir ./cnndm
mkdir ./cnndm/diverse
mkdir ./cnndm/diverse/test
# suppose that the raw files are at ./raw_data, the results will be saved at ./cnndm/diverse/test
# please remember to put the source file and the target file on test set into the folder, e.g. ./cnndm/diverse/test.source
python preprocess.py --src_dir ./raw_data --tgt_dir ./cnndm/diverse --split test --cand_num 16 --dataset cnndm -l
Você pode especificar os hiper-parâmetros em main.py Também fornecemos as configurações específicas no CNNDM (NYT compartilham a mesma configuração) e Xsum em config.py .
python main.py --cuda --gpuid [list of gpuid] --config [name of the config (cnndm/xsum)] -l Os pontos de verificação e o log serão salvos em uma subpasta de ./cache .
python main.py --cuda --gpuid 0 1 2 3 --config cnndm -l python main.py --cuda --gpuid [list of gpuid] -l --config [name of the config (cnndm/xsum)] --model_pt [model path] O caminho do modelo deve ser um subdiretório no diretório ./cache , por exemplo, cnndm/model.pt (não deve conter o prefixo ./cache/ ).
Para o cálculo do Rouge, usamos o pacote Rouge Perl padrão daqui em nosso artigo. Nós reduzimos e tokenizamos (usando o tokenizador PTB) textos antes de calcular as pontuações do Rouge. Observe que as pontuações calculadas por este pacote seriam de maneira significativamente diferente das pontuações do Rouge calculadas/relatadas durante o estágio de avaliação de treinamento/intermidato, porque usamos uma implementação de Rouge baseada em Python pura para calcular essas pontuações para obter melhor eficiência.
Se você encontrar problemas ao configurar o pacote Rouge Perl (infelizmente isso acontece muito :(), você pode considerar o uso do pacote Rouge baseado em Python, como o que usamos no pacote Compare-MT.
Fornecemos o script de avaliação em cal_rouge.py . Se você vai usar o pacote Perl Rouge, altere a linha 13 no caminho do seu pacote Perl Rouge.
_ROUGE_PATH = '/YOUR-ABSOLUTE-PATH/ROUGE-RELEASE-1.5.5/'Para avaliar o desempenho do modelo, primeiro use o seguinte comando para gerar os resumos.
python main.py --cuda --gpuid [single gpu] --config [name of the config (cnndm/xsum)] -e --model_pt [model path] -g [evaluate the model as a generator] -r [evaluate the model as a scorer/reranker] O caminho do modelo deve ser um subdiretório no diretório ./cache , por exemplo, cnndm/model.pt (não deve conter o prefixo ./cache/ ). A saída será salva em uma subpasta de ./result tendo o mesmo nome da pasta do ponto de verificação.
# write the system-generated files to a file: ./result/cnndm/test.out
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_generation.bin -g
# tokenize the output file - > ./result/cnndm/test.out.tokenized (you may use other tokenizers)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat ./result/cnndm/test.out | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > ./result/cnndm/test.out.tokenized
# calculate the ROUGE scores using ROUGE Perl Package
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l
# calculate the ROUGE scores using ROUGE Python Implementation
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l -p # rerank the candidate summaries
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_ranking.bin -r
# calculate the ROUGE scores using ROUGE Perl Package
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l
# calculate the ROUGE scores using ROUGE Python Implementation
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l -p Os seguintes são as pontuações Rouge calculadas pelo pacote Rouge Perl padrão.
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Bart | 44.29 | 21.17 | 41.09 |
| BRIO-CTR | 47.28 | 22.93 | 44.15 |
| BRIO-MUL | 47.78 | 23.55 | 44.57 |
| BRIO-MUL (CASED) | 48.01 | 23.76 | 44.63 |
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Pegasus | 47.46 | 24.69 | 39.53 |
| BRIO-CTR | 48.13 | 25.13 | 39.84 |
| BRIO-MUL | 49.07 | 25.59 | 40.40 |
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Bart | 55.78 | 36.61 | 52.60 |
| BRIO-CTR | 55.98 | 36.54 | 52.51 |
| BRIO-MUL | 57,75 | 38.64 | 54.54 |
Nosso modelo sai nesses conjuntos de dados pode ser encontrado em ./output .
Resumimos as saídas e os pontos de verificação do modelo abaixo. Você pode carregar esses pontos de verificação usando model.load_state_dict(torch.load(path_to_checkpoint)) .
| Pontos de verificação | Saída de modelo | Saída de referência | |
|---|---|---|---|
| Cnndm | Model_generation.bin model_ranking.bin | cnndm.test.ours.out | CNNDM.Test.Reference |
| CNNDM (CASED) | Model_generation.bin | cnndm.test.ours.cased.out | CNNDM.Test.Cased.Reference |
| Xsum | Model_generation.bin model_ranking.bin | xsum.test.ours.out | xsum.test.reference |
Você pode carregar nossos modelos treinados para a geração de Transformers Huggingface. Nosso ponto de verificação do modelo CNNDM ( Yale-LILY/brio-cnndm-uncased Yale-LILY/brio-cnndm-cased ) é um modelo BART padrão (ou seja, a generação de bartforcondicional), enquanto nosso ponto de verificação do modelo no modelo ( Yale-LILY/brio-xsum-cased baseado) é um modelo padrão de pegas (ie-lily/segasal)
from transformers import BartTokenizer , PegasusTokenizer
from transformers import BartForConditionalGeneration , PegasusForConditionalGeneration
IS_CNNDM = True # whether to use CNNDM dataset or XSum dataset
LOWER = False
ARTICLE_TO_SUMMARIZE = "Manchester United superstar Cristiano Ronaldo scored his 806th career goal in Old Trafford,
breaking FIFA's all-time record for most goals in competitive matches in men's football history.
It was the second of three goals the Portuguese attacker scored during the game,
leading United to a 3-2 victory over Tottenham and finishing the day with 807 total career goals.
The previous FIFA goal record was held by Josef Bican, with 805 goals."
# Load our model checkpoints
if IS_CNNDM :
model = BartForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
tokenizer = BartTokenizer . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
else :
model = PegasusForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
tokenizer = PegasusTokenizer . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
max_length = 1024 if IS_CNNDM else 512
# generation example
if LOWER :
article = ARTICLE_TO_SUMMARIZE . lower ()
else :
article = ARTICLE_TO_SUMMARIZE
inputs = tokenizer ([ article ], max_length = max_length , return_tensors = "pt" , truncation = True )
# Generate Summary
summary_ids = model . generate ( inputs [ "input_ids" ])
print ( tokenizer . batch_decode ( summary_ids , skip_special_tokens = True , clean_up_tokenization_spaces = False )[ 0 ]) Notas : Nossos pontos de verificação no HuggingFace não podem ser carregados diretamente no modelo Pytorch ( BRIO ) em nosso código, porque nosso modelo Pytorch é um invólucro no Bart/Pegasus para melhor eficiência de treinamento. No entanto, você pode usá -lo para iniciar nosso modelo Pytorch, por exemplo,
model = BRIO ( 'Yale-LILY/brio-cnndm-uncased' , tok . pad_token_id , is_pegasus = False )

