BRIO
1.0.0
Ce dépôt contient le code, les données et les modèles formés pour notre Brio papier: apporter l'ordre à une résumé abstractif.
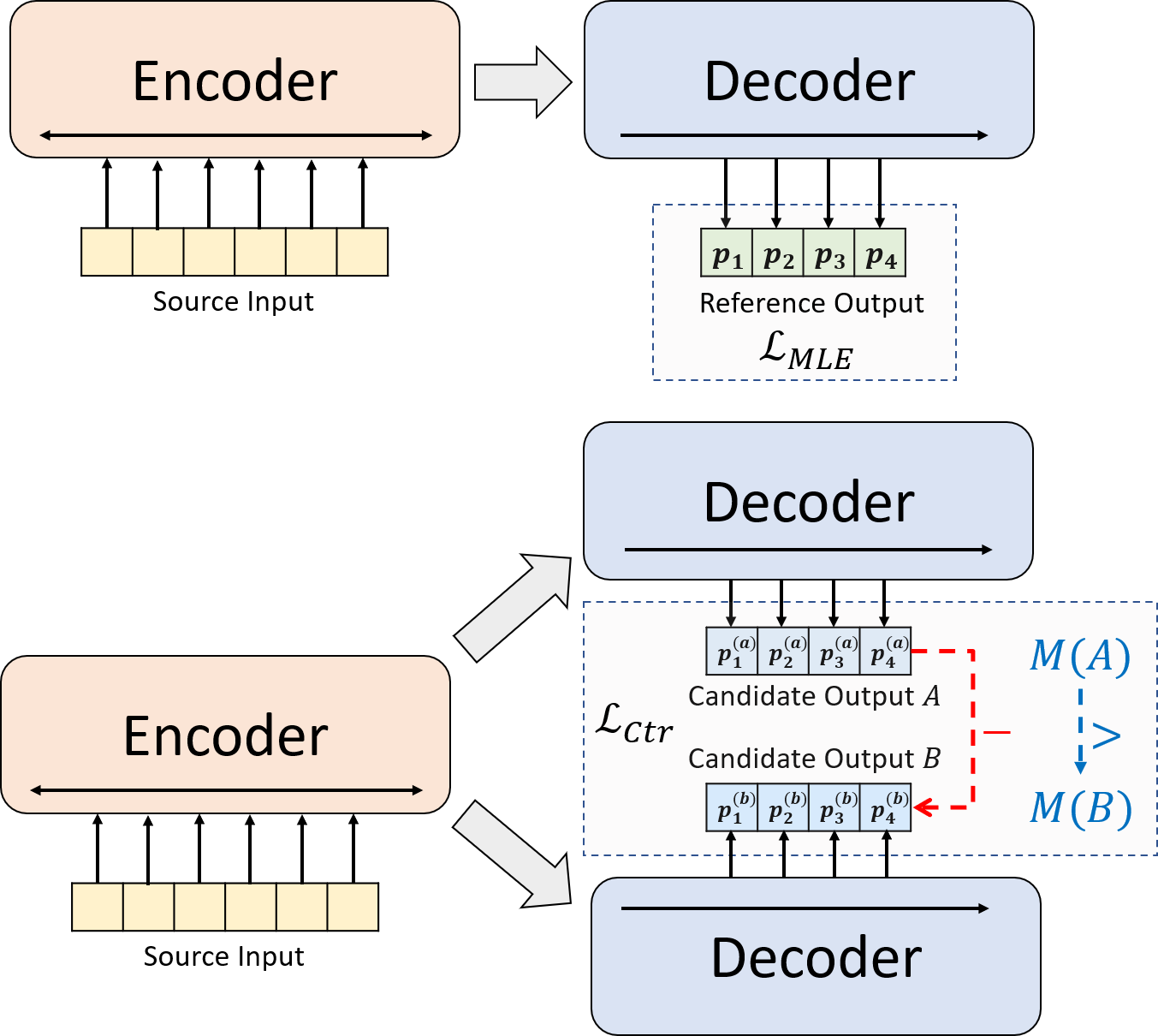
Nous présentons un nouveau paradigme de formation pour le résumé abstractif neuronal. Au lieu d'utiliser la formation MLE seule, nous introduisons une composante d'apprentissage contrastive, qui encourage les modèles abstractifs à estimer plus précisément la probabilité de résumés générés par le système.
python3.8conda create --name env --file spec-file.txtpip install -r requirements.txtcompare_mt -> https://github.com/neulab/compare-mt git clone https://github.com/neulab/compare-mt.git
cd ./compare-mt
pip install -r requirements.txt
python setup.py installNotre code est basé sur la bibliothèque Transformers de HuggingFace.
cal_rouge.py -> calcul Rougeconfig.py -> Configuration du modèledata_utils.py -> DatalOaderlabel_smoothing_loss.py -> Légnation de lissage de l'étiquettemain.py -> Procédure de formation et d'évaluationmodel.py -> Modèlesmodeling_bart.py , modeling_pegasus.py -> Modifié de la bibliothèque Transformers pour prendre en charge une formation plus efficacepreprocess.py -> Prétraitement des donnéesutils.py -> fonctions utilitairesgen_candidate.py -> générer des résumés de candidatsLes répertoires suivants doivent être créés pour nos expériences.
./cache -> Stockage des points de contrôle du modèle./result -> Stockage des résultats de l'évaluation Nous utilisons les ensembles de données suivants pour nos expériences.
Vous pouvez télécharger les données prétraitées pour nos expériences sur CNNDM, CNNDM (BASED) et XSUM.
Après DonWloading, vous devez décompresser les fichiers zip dans ce répertoire racine.
Pour NYT, vous devrez obtenir la licence et suivez https://github.com/kedz/summarisation-datasets pour le prétraitement.
Pour générer les résumés des candidats à partir d'un modèle pré-formé, veuillez exécuter
python gen_candidate.py --gpuid [gpuid] --src_dir [path of the input file (e.g. test.source)] --tgt_dir [path of the output file] --dataset [cnndm/xsum] Pour le prétraitement des données, veuillez exécuter
python preprocess.py --src_dir [path of the raw data] --tgt_dir [output path] --split [train/val/test] --cand_num [number of candidate summaries] --dataset [cnndm/xsum/nyt] -l [lowercase if the flag is set] src_dir doit contenir les fichiers suivants (en utilisant Test Split comme exemple):
test.sourcetest.source.tokenizedtest.targettest.target.tokenizedtest.outtest.out.tokenized Chaque ligne de ces fichiers doit contenir un échantillon à l'exception de test.out et test.out.tokenized . En particulier, vous devez mettre les résumés des candidats pour un échantillon de données sur les lignes voisines dans test.out et test.out.tokenized .
Remarques : Après le prétraitement des données, vous devez également placer le fichier brut test.source , test.target dans le dossier de données créé (par exemple ./cnndm/diverse/test.source diverse/test.source)
Nous utilisons le tokenzer PTB fourni par Standford Corenlp (téléchargement ici). Veuillez noter que les textes tokenisés ne sont utilisés que pour l'évaluation. Pour tokensize un fichier, vous pouvez exécuter (en utilisant Test.source comme exemple)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat test.source | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > test.source.tokenized Nous avons fourni les fichiers d'exemples dans ./examples/raw_data .
La procédure de prétraitement stockera les données traitées sous forme de fichiers JSON séparés dans tgt_dir .
# starting from the root directory
# create folders
mkdir ./cnndm
mkdir ./cnndm/diverse
mkdir ./cnndm/diverse/test
# suppose that the raw files are at ./raw_data, the results will be saved at ./cnndm/diverse/test
# please remember to put the source file and the target file on test set into the folder, e.g. ./cnndm/diverse/test.source
python preprocess.py --src_dir ./raw_data --tgt_dir ./cnndm/diverse --split test --cand_num 16 --dataset cnndm -l
Vous pouvez spécifier les hyper-paramètres dans main.py Nous fournissons également les paramètres spécifiques sur CNNDM (NYT Partagez le même paramètre) et XSUM dans config.py .
python main.py --cuda --gpuid [list of gpuid] --config [name of the config (cnndm/xsum)] -l Les points de contrôle et le journal seront enregistrés dans un sous-dossier de ./cache .
python main.py --cuda --gpuid 0 1 2 3 --config cnndm -l python main.py --cuda --gpuid [list of gpuid] -l --config [name of the config (cnndm/xsum)] --model_pt [model path] Le chemin du modèle doit être un sous-répertoire dans le répertoire ./cache , par exemple cnndm/model.pt (il ne devrait pas contenir le préfixe ./cache/ ).
Pour le calcul de Rouge, nous utilisons le package Rouge Perl standard à partir d'ici dans notre article. Nous avons des textes à baisse et à tokenisés à tokenisés (en utilisant PTB) avant de calculer les scores rouges. Veuillez noter que les scores calculés par ce package seraient vivement différents des scores rouges calculés / rapportés pendant la formation / intermidante étape de l'évaluation, car nous utilisons une implémentation Rouge basée sur un python pour calculer ces scores pour une meilleure efficacité.
Si vous rencontrez des problèmes lors de la configuration du package Rouge Perl (malheureusement, cela arrive beaucoup :(), vous pouvez envisager d'utiliser le package Rouge basé sur Python tel que celui que nous avons utilisé dans le package Compare-MT.
Nous fournissons le script d'évaluation dans cal_rouge.py . Si vous allez utiliser le package Perl Rouge, veuillez changer la ligne 13 dans le chemin de votre package Perl Rouge.
_ROUGE_PATH = '/YOUR-ABSOLUTE-PATH/ROUGE-RELEASE-1.5.5/'Pour évaluer les performances du modèle, veuillez d'abord utiliser la commande suivante pour générer les résumés.
python main.py --cuda --gpuid [single gpu] --config [name of the config (cnndm/xsum)] -e --model_pt [model path] -g [evaluate the model as a generator] -r [evaluate the model as a scorer/reranker] Le chemin du modèle doit être un sous-répertoire dans le répertoire ./cache , par exemple cnndm/model.pt (il ne devrait pas contenir le préfixe ./cache/ ). La sortie sera enregistrée dans un sous-dossier de ./result ayant le même nom du dossier de point de contrôle.
# write the system-generated files to a file: ./result/cnndm/test.out
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_generation.bin -g
# tokenize the output file - > ./result/cnndm/test.out.tokenized (you may use other tokenizers)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat ./result/cnndm/test.out | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > ./result/cnndm/test.out.tokenized
# calculate the ROUGE scores using ROUGE Perl Package
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l
# calculate the ROUGE scores using ROUGE Python Implementation
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l -p # rerank the candidate summaries
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_ranking.bin -r
# calculate the ROUGE scores using ROUGE Perl Package
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l
# calculate the ROUGE scores using ROUGE Python Implementation
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l -p Voici les scores rouges calculés par le package Rouge Perl standard.
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Barbe | 44.29 | 21.17 | 41.09 |
| Brio-ctr | 47.28 | 22.93 | 44.15 |
| Brio-mul | 47.78 | 23.55 | 44,57 |
| Brio-Mul (Based) | 48.01 | 23.76 | 44.63 |
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Pégase | 47.46 | 24.69 | 39.53 |
| Brio-ctr | 48.13 | 25.13 | 39.84 |
| Brio-mul | 49.07 | 25.59 | 40.40 |
| Rouge-1 | Rouge-2 | Rouge-l | |
|---|---|---|---|
| Barbe | 55,78 | 36.61 | 52.60 |
| Brio-ctr | 55,98 | 36.54 | 52.51 |
| Brio-mul | 57,75 | 38,64 | 54,54 |
Notre modèle de sortie sur ces ensembles de données peut être trouvé dans ./output .
Nous résumons les sorties et les points de contrôle du modèle ci-dessous. Vous pouvez charger ces points de contrôle à l'aide de model.load_state_dict(torch.load(path_to_checkpoint)) .
| Points de contrôle | Sortie du modèle | Sortie de référence | |
|---|---|---|---|
| Cnndm | Model_generation.bin Model_ranking.bin | cnndm.test.ours.out | cnndm.test.reference |
| CNNDM (BASED) | Model_generation.bin | cnndm | Cnndm.Test.Casé.Reference |
| Xsum | Model_generation.bin Model_ranking.bin | xsum.test.ours.out | xsum.test.reference |
Vous pouvez charger nos modèles qualifiés pour la génération à partir de transformateurs à câlins. Notre point de contrôle de modèle sur CNNDM ( Yale-LILY/brio-cnndm-uncased , Yale-LILY/brio-cnndm-cased ) est un modèle BART standard (c'est-à-dire, BartforConditionalGeneration) tandis que notre point de contrôle de modèle sur XSUM ( Yale-LILY/brio-xsum-cased ) est un modèle standard de Pegasus (IE, PegasusforconditionalGentional).
from transformers import BartTokenizer , PegasusTokenizer
from transformers import BartForConditionalGeneration , PegasusForConditionalGeneration
IS_CNNDM = True # whether to use CNNDM dataset or XSum dataset
LOWER = False
ARTICLE_TO_SUMMARIZE = "Manchester United superstar Cristiano Ronaldo scored his 806th career goal in Old Trafford,
breaking FIFA's all-time record for most goals in competitive matches in men's football history.
It was the second of three goals the Portuguese attacker scored during the game,
leading United to a 3-2 victory over Tottenham and finishing the day with 807 total career goals.
The previous FIFA goal record was held by Josef Bican, with 805 goals."
# Load our model checkpoints
if IS_CNNDM :
model = BartForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
tokenizer = BartTokenizer . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
else :
model = PegasusForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
tokenizer = PegasusTokenizer . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
max_length = 1024 if IS_CNNDM else 512
# generation example
if LOWER :
article = ARTICLE_TO_SUMMARIZE . lower ()
else :
article = ARTICLE_TO_SUMMARIZE
inputs = tokenizer ([ article ], max_length = max_length , return_tensors = "pt" , truncation = True )
# Generate Summary
summary_ids = model . generate ( inputs [ "input_ids" ])
print ( tokenizer . batch_decode ( summary_ids , skip_special_tokens = True , clean_up_tokenization_spaces = False )[ 0 ]) Remarques : Nos points de contrôle sur HuggingFace ne peuvent pas être directement chargés au modèle Pytorch ( BRIO ) dans notre code car notre modèle Pytorch est un wrapper sur Bart / Pegasus pour une meilleure efficacité de formation. Cependant, vous pouvez l'utiliser pour initié notre modèle Pytorch, par exemple,
model = BRIO ( 'Yale-LILY/brio-cnndm-uncased' , tok . pad_token_id , is_pegasus = False )

