BRIO
1.0.0
Este repositorio contiene el código, los datos y los modelos capacitados para nuestro documento Brio: Traer el orden al resumen abstracto.
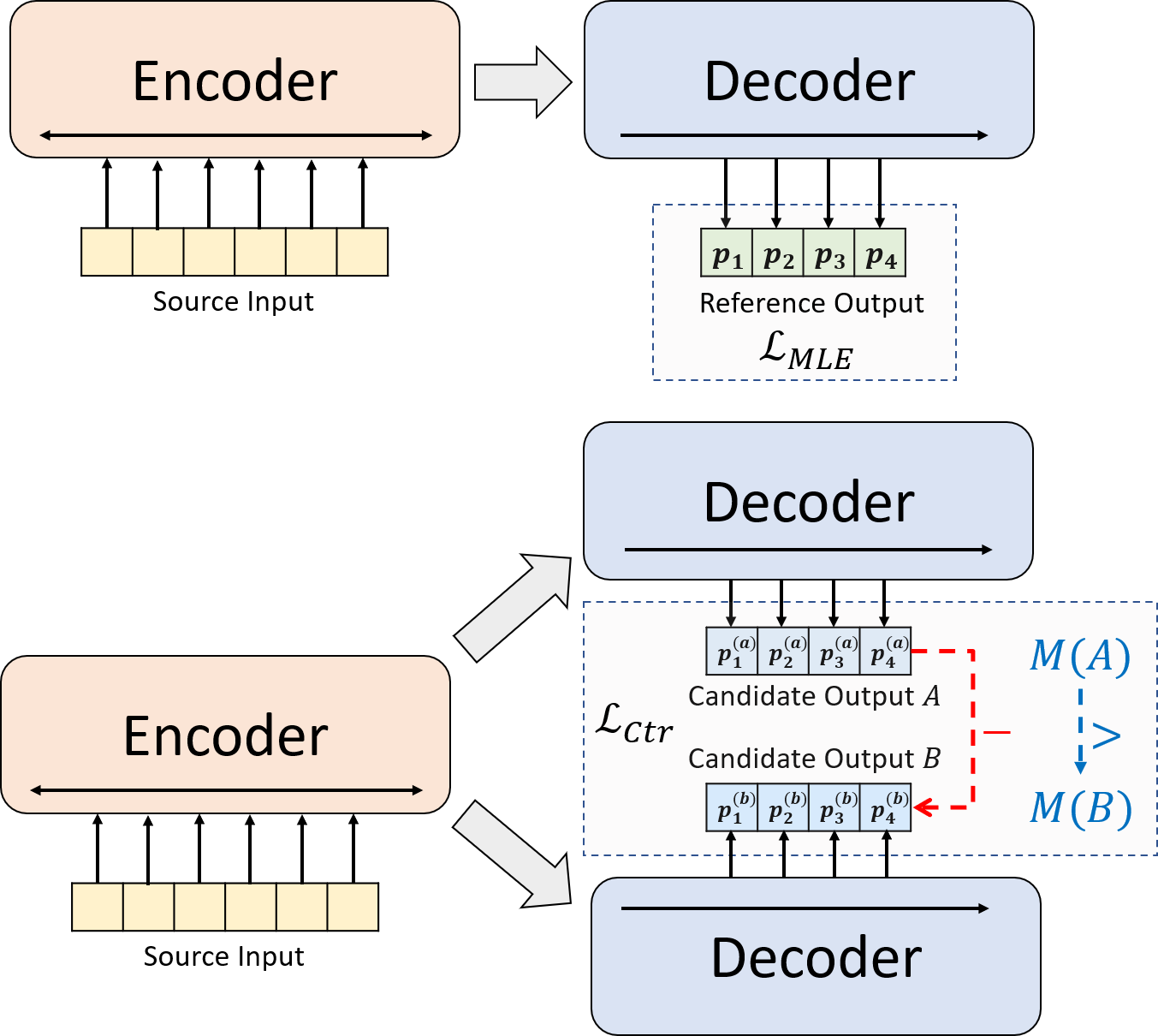
Presentamos un paradigma de entrenamiento novedoso para resumen neural abstracto. En lugar de usar la capacitación de MLE solo, presentamos un componente de aprendizaje contrastante, que alienta a los modelos abstractores a estimar la probabilidad de resúmenes generados por el sistema con mayor precisión.
python3.8conda create --name env --file spec-file.txtpip install -r requirements.txtcompare_mt -> https://github.com/neulab/compare-mt git clone https://github.com/neulab/compare-mt.git
cd ./compare-mt
pip install -r requirements.txt
python setup.py installNuestro código se basa en la biblioteca Transformers de Huggingface.
cal_rouge.py -> Cálculo de Rougeconfig.py -> Configuración del modelodata_utils.py -> dataLoaderlabel_smoothing_loss.py -> pérdida de suavizado de etiquetamain.py -> Procedimiento de capacitación y evaluaciónmodel.py -> modelosmodeling_bart.py , modeling_pegasus.py -> modificado de la biblioteca de transformadores para admitir capacitación más eficientepreprocess.py -> Preprocesamiento de datosutils.py -> funciones de utilidadgen_candidate.py -> Generar resúmenes de candidatosSe deben crear los siguientes directorios para nuestros experimentos.
./cache -> almacenamiento de puntos de control del modelo./result -> almacenar resultados de evaluación Utilizamos los siguientes conjuntos de datos para nuestros experimentos.
Puede descargar los datos preprocesados para nuestros experimentos en CNNDM, CNNDM (Cosed) y XSUM.
Después de DonwLoading, debe descomponer los archivos zip en este directorio raíz.
Para NYT, deberá obtener la licencia y siga https://github.com/kedz/summarization-datasets para su preprocesamiento.
Para generar los resúmenes de los candidatos a partir de un modelo previamente capacitado, ejecute
python gen_candidate.py --gpuid [gpuid] --src_dir [path of the input file (e.g. test.source)] --tgt_dir [path of the output file] --dataset [cnndm/xsum] Para el preprocesamiento de datos, ejecute
python preprocess.py --src_dir [path of the raw data] --tgt_dir [output path] --split [train/val/test] --cand_num [number of candidate summaries] --dataset [cnndm/xsum/nyt] -l [lowercase if the flag is set] src_dir debe contener los siguientes archivos (usando la división de prueba como ejemplo):
test.sourcetest.source.tokenizedtest.targettest.target.tokenizedtest.outtest.out.tokenized Cada línea de estos archivos debe contener una muestra excepto test.out y test.out.tokenized . En particular, debe poner los resúmenes de los candidatos para una muestra de datos en las líneas vecinas en test.out y test.out.tokenized .
Notas : Después del preprocesamiento de los datos, también debe colocar el archivo sin procesar test.source , test.target en la carpeta de datos creada (por ejemplo ./cnndm/diverse/test.source diverse/test.source)
Utilizamos el tokenizador PTB proporcionado por Standford Corenlp (descargar aquí). Tenga en cuenta que los textos tokenizados solo se usan para la evaluación. Para tokenizar un archivo, puede ejecutar (usando test.surce como ejemplo)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat test.source | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > test.source.tokenized Hemos proporcionado los archivos de ejemplos en ./examples/raw_data .
El procedimiento de preprocesamiento almacenará los datos procesados como archivos JSON separados en tgt_dir .
# starting from the root directory
# create folders
mkdir ./cnndm
mkdir ./cnndm/diverse
mkdir ./cnndm/diverse/test
# suppose that the raw files are at ./raw_data, the results will be saved at ./cnndm/diverse/test
# please remember to put the source file and the target file on test set into the folder, e.g. ./cnndm/diverse/test.source
python preprocess.py --src_dir ./raw_data --tgt_dir ./cnndm/diverse --split test --cand_num 16 --dataset cnndm -l
Puede especificar los hiperparametros en main.py También proporcionamos la configuración específica en CNNDM (NYT compartir la misma configuración) y XSUM en config.py .
python main.py --cuda --gpuid [list of gpuid] --config [name of the config (cnndm/xsum)] -l Los puntos de control y el registro se guardarán en una subcarpeta de ./cache .
python main.py --cuda --gpuid 0 1 2 3 --config cnndm -l python main.py --cuda --gpuid [list of gpuid] -l --config [name of the config (cnndm/xsum)] --model_pt [model path] La ruta del modelo debe ser un subdirectorio en el directorio ./cache , por ejemplo, cnndm/model.pt (no debe contener el prefijo ./cache/ ).
Para el cálculo de Rouge, utilizamos el paquete Rouge Perl estándar desde aquí en nuestro documento. Bajamos y tokenizamos (usando textos PTB Tokenizer) antes de calcular las puntuaciones de Rouge. Tenga en cuenta que los puntajes calculados por este paquete serían muy diferentes de las puntuaciones de Rouge calculadas/informadas durante la etapa de evaluación de entrenamiento/intermidia, porque utilizamos una implementación de Rouge basada en Python puro para calcular esos puntajes para una mejor eficiencia.
Si encuentra problemas al configurar el paquete Rouge Perl (desafortunadamente sucede mucho :(), puede considerar usar el paquete Rouge basado en Python Pure como el que usamos del paquete Compare-MT.
Proporcionamos el script de evaluación en cal_rouge.py . Si va a utilizar el paquete Perl Rouge, cambie la línea 13 en la ruta de su paquete Perl Rouge.
_ROUGE_PATH = '/YOUR-ABSOLUTE-PATH/ROUGE-RELEASE-1.5.5/'Para evaluar el rendimiento del modelo, primero use el siguiente comando para generar los resúmenes.
python main.py --cuda --gpuid [single gpu] --config [name of the config (cnndm/xsum)] -e --model_pt [model path] -g [evaluate the model as a generator] -r [evaluate the model as a scorer/reranker] La ruta del modelo debe ser un subdirectorio en el directorio ./cache , por ejemplo, cnndm/model.pt (no debe contener el prefijo ./cache/ ). La salida se guardará en una subcarpeta de ./result con el mismo nombre de la carpeta de punto de control.
# write the system-generated files to a file: ./result/cnndm/test.out
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_generation.bin -g
# tokenize the output file - > ./result/cnndm/test.out.tokenized (you may use other tokenizers)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat ./result/cnndm/test.out | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > ./result/cnndm/test.out.tokenized
# calculate the ROUGE scores using ROUGE Perl Package
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l
# calculate the ROUGE scores using ROUGE Python Implementation
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l -p # rerank the candidate summaries
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_ranking.bin -r
# calculate the ROUGE scores using ROUGE Perl Package
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l
# calculate the ROUGE scores using ROUGE Python Implementation
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l -p Los siguientes son puntajes Rouge calculados por el paquete Rouge Perl estándar.
| Rouge-1 | Rouge-2 | Ruge-l | |
|---|---|---|---|
| Barbar | 44.29 | 21.17 | 41.09 |
| Brio-ctr | 47.28 | 22.93 | 44.15 |
| Brio | 47.78 | 23.55 | 44.57 |
| Brio-Mul (revestido) | 48.01 | 23.76 | 44.63 |
| Rouge-1 | Rouge-2 | Ruge-l | |
|---|---|---|---|
| Pegaso | 47.46 | 24.69 | 39.53 |
| Brio-ctr | 48.13 | 25.13 | 39.84 |
| Brio | 49.07 | 25.59 | 40.40 |
| Rouge-1 | Rouge-2 | Ruge-l | |
|---|---|---|---|
| Barbar | 55.78 | 36.61 | 52.60 |
| Brio-ctr | 55.98 | 36.54 | 52.51 |
| Brio | 57.75 | 38.64 | 54.54 |
Nuestras salidas de modelo en estos conjuntos de datos se pueden encontrar en ./output .
Resumimos las salidas y los puntos de control del modelo a continuación. Puede cargar estos puntos de control utilizando model.load_state_dict(torch.load(path_to_checkpoint)) .
| Puntos de control | Salida de modelo | Salida de referencia | |
|---|---|---|---|
| CNNDM | model_generation.bin model_ranking.bin | cnndm.test.ours.out | cnndm.test.reference |
| CNNDM (cubierto) | model_generation.bin | cnndm.test.ours.cased.out | cnndm.test.cased.reference |
| Xsum | model_generation.bin model_ranking.bin | xsum.test.ours.out | xsum.test.reference |
Puede cargar nuestros modelos capacitados para la generación de Huggingface Transformers. Nuestro punto de control de modelo en CNNDM ( Yale-LILY/brio-cnndm-uncased , Yale-LILY/brio-cnndm-cased ) es un modelo BART estándar (es decir, Generación BartforCondicional), mientras que nuestro punto de control de modelo en Xsum ( Yale-LILY/brio-xsum-cased ) es un modelo PEGASUS estándar (IE, PEGASUSFORCONDICIONALAERATIONE).
from transformers import BartTokenizer , PegasusTokenizer
from transformers import BartForConditionalGeneration , PegasusForConditionalGeneration
IS_CNNDM = True # whether to use CNNDM dataset or XSum dataset
LOWER = False
ARTICLE_TO_SUMMARIZE = "Manchester United superstar Cristiano Ronaldo scored his 806th career goal in Old Trafford,
breaking FIFA's all-time record for most goals in competitive matches in men's football history.
It was the second of three goals the Portuguese attacker scored during the game,
leading United to a 3-2 victory over Tottenham and finishing the day with 807 total career goals.
The previous FIFA goal record was held by Josef Bican, with 805 goals."
# Load our model checkpoints
if IS_CNNDM :
model = BartForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
tokenizer = BartTokenizer . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
else :
model = PegasusForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
tokenizer = PegasusTokenizer . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
max_length = 1024 if IS_CNNDM else 512
# generation example
if LOWER :
article = ARTICLE_TO_SUMMARIZE . lower ()
else :
article = ARTICLE_TO_SUMMARIZE
inputs = tokenizer ([ article ], max_length = max_length , return_tensors = "pt" , truncation = True )
# Generate Summary
summary_ids = model . generate ( inputs [ "input_ids" ])
print ( tokenizer . batch_decode ( summary_ids , skip_special_tokens = True , clean_up_tokenization_spaces = False )[ 0 ]) Notas : Nuestros puntos de control en Huggingface no se pueden cargar directamente al Modelo Pytorch ( BRIO ) en nuestro código porque nuestro modelo Pytorch es un envoltorio en BART/Pegasus para una mejor eficiencia de entrenamiento. Sin embargo, puede usarlo para iniciar nuestro modelo Pytorch, por ejemplo,
model = BRIO ( 'Yale-LILY/brio-cnndm-uncased' , tok . pad_token_id , is_pegasus = False )

