BRIO
1.0.0
Этот репо содержит код, данные и обученные модели для нашего бумажного брио: привлечение порядка в абстрактную сумму.
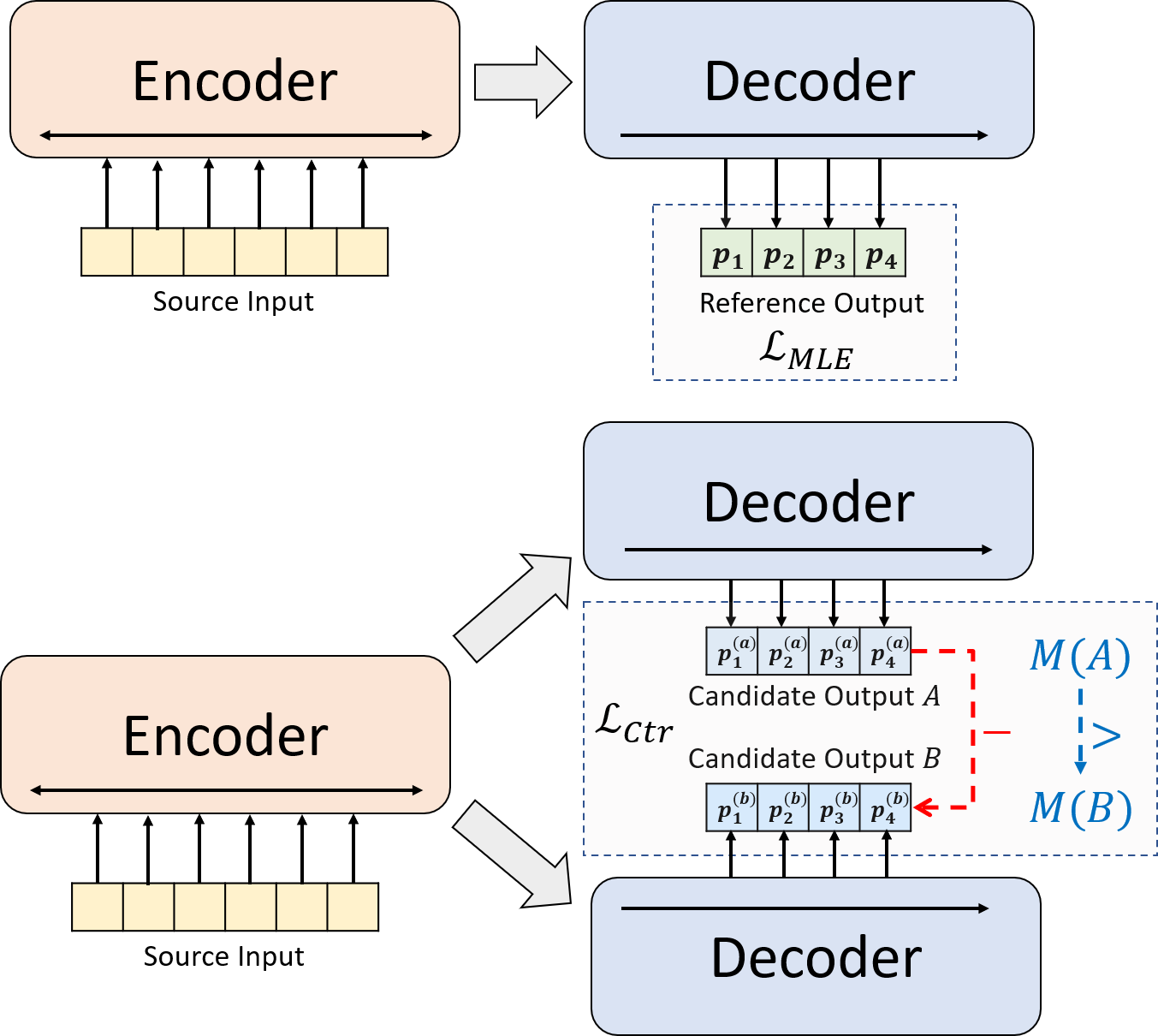
Мы представляем новую тренировочную парадигму для нейронной абстрактной суммирования. Вместо того, чтобы использовать только обучение MLE, мы вводим контрастный компонент обучения, который поощряет абстрактные модели более точно оценить вероятность резюме, созданных системой.
python3.8conda create --name env --file spec-file.txtpip install -r requirements.txtcompare_mt -> https://github.com/neulab/compare-mt git clone https://github.com/neulab/compare-mt.git
cd ./compare-mt
pip install -r requirements.txt
python setup.py installНаш код основан на библиотеке Transformers HuggingFace.
cal_rouge.py -> Расчет Rougeconfig.py -> конфигурация моделиdata_utils.py -> dataLoaderlabel_smoothing_loss.py -> Потеря сглаживания меткиmain.py -> Процедура обучения и оценкиmodel.py -> Моделиmodeling_bart.py , modeling_pegasus.py -> Модифицирован из библиотеки трансформаторов для поддержки более эффективного обученияpreprocess.py -> Предварительная обработка данныхutils.py -> функции утилитыgen_candidate.py -> генерировать резюме кандидатовСледующие каталоги должны быть созданы для наших экспериментов.
./cache -> Хранив модель контрольно -пропускных пунктов./result -> хранение результатов оценки Мы используем следующие наборы данных для наших экспериментов.
Вы можете скачать предварительные данные для наших экспериментов на CNNDM, CNNDM (CASED) и XSUM.
После загрузки Donwload вы должны расслабиться на ZIP -файлах в этом корневом каталоге.
Для NYT вам нужно будет получить лицензию и, пожалуйста, следуйте https://github.com/kedz/summarization-datasets для предварительной обработки.
Чтобы генерировать резюме кандидата из предварительно обученной модели, пожалуйста, запустите
python gen_candidate.py --gpuid [gpuid] --src_dir [path of the input file (e.g. test.source)] --tgt_dir [path of the output file] --dataset [cnndm/xsum] Для предварительной обработки данных, пожалуйста, запустите
python preprocess.py --src_dir [path of the raw data] --tgt_dir [output path] --split [train/val/test] --cand_num [number of candidate summaries] --dataset [cnndm/xsum/nyt] -l [lowercase if the flag is set] src_dir должен содержать следующие файлы (в качестве примера с использованием тестового разделения):
test.sourcetest.source.tokenizedtest.targettest.target.tokenizedtest.outtest.out.tokenized Каждая строка этих файлов должна содержать образец, за исключением test.out и test.out.tokenized . В частности, вы должны поместить сводки кандидата для одного образца данных в соседних линиях в test.out и test.out.tokenized .
Примечания : После предварительной обработки данных ./cnndm/diverse/test.source также должны поместить test.source File test.target
Мы используем токенизатор PTB, предоставленный Standford Corenlp (скачать здесь). Обратите внимание, что токенизированные тексты используются только для оценки. Чтобы токенизировать файл, вы можете запустить (используя test.source в качестве примера)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat test.source | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > test.source.tokenized Мы предоставили примеры файлы в ./examples/raw_data .
Процедура предварительной обработки будет хранить обработанные данные как отдельные файлы JSON в tgt_dir .
# starting from the root directory
# create folders
mkdir ./cnndm
mkdir ./cnndm/diverse
mkdir ./cnndm/diverse/test
# suppose that the raw files are at ./raw_data, the results will be saved at ./cnndm/diverse/test
# please remember to put the source file and the target file on test set into the folder, e.g. ./cnndm/diverse/test.source
python preprocess.py --src_dir ./raw_data --tgt_dir ./cnndm/diverse --split test --cand_num 16 --dataset cnndm -l
Вы можете указать гиперпараметры в main.py Мы также предоставляем конкретные настройки на CNNDM (NYT совместно используют одну и ту же настройку) и XSUM в config.py .
python main.py --cuda --gpuid [list of gpuid] --config [name of the config (cnndm/xsum)] -l Контрольные точки и журнал будут сохранены в подпапке ./cache .
python main.py --cuda --gpuid 0 1 2 3 --config cnndm -l python main.py --cuda --gpuid [list of gpuid] -l --config [name of the config (cnndm/xsum)] --model_pt [model path] Путь модели должен быть подкаталогом в каталоге ./cache , например, cnndm/model.pt (он не должен содержать префикс ./cache/ ).
Для расчета Rouge мы используем стандартный пакет Rouge Perl отсюда в нашей статье. Мы общеприняты и токенизированы (с использованием текстов -токенизатора PTB), прежде чем вычислять баллы Rouge. Обратите внимание, что оценки, рассчитанные по этому пакету, будут выглядеть , по сравнению с показателями Rouge, рассчитанными/сообщенными во время обучения/промежуточного этапа оценки, поскольку мы используем реализацию Rouge на основе Python для расчета этих баллов для повышения эффективности.
Если вы столкнетесь с проблемами при настройке пакета Rouge Perl (к сожалению, это происходит много :(), вы можете рассмотреть возможность использования пакета Rouge на основе Pure Python, такого как тот, который мы использовали из пакета Compare-MT.
Мы предоставляем сценарий оценки в cal_rouge.py . Если вы собираетесь использовать Perl Rouge Package, измените линию 13 на путь вашего Perl Rouge Package.
_ROUGE_PATH = '/YOUR-ABSOLUTE-PATH/ROUGE-RELEASE-1.5.5/'Чтобы оценить производительность модели, сначала используйте следующую команду для генерации резюме.
python main.py --cuda --gpuid [single gpu] --config [name of the config (cnndm/xsum)] -e --model_pt [model path] -g [evaluate the model as a generator] -r [evaluate the model as a scorer/reranker] Путь модели должен быть подкаталогом в каталоге ./cache , например, cnndm/model.pt (он не должен содержать префикс ./cache/ ). Вывод будет сохранен в подпапке ./result , имеющего то же имя папки контрольной точки.
# write the system-generated files to a file: ./result/cnndm/test.out
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_generation.bin -g
# tokenize the output file - > ./result/cnndm/test.out.tokenized (you may use other tokenizers)
export CLASSPATH=/your_path/stanford-corenlp-3.8.0.jar
cat ./result/cnndm/test.out | java edu.stanford.nlp.process.PTBTokenizer -ioFileList -preserveLines > ./result/cnndm/test.out.tokenized
# calculate the ROUGE scores using ROUGE Perl Package
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l
# calculate the ROUGE scores using ROUGE Python Implementation
python cal_rouge.py --ref ./cnndm/test.target.tokenized --hyp ./result/cnndm/test.out.tokenized -l -p # rerank the candidate summaries
python main.py --cuda --gpuid 0 --config cnndm -e --model_pt cnndm/model_ranking.bin -r
# calculate the ROUGE scores using ROUGE Perl Package
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l
# calculate the ROUGE scores using ROUGE Python Implementation
# ./result/cnndm/reference and ./result/cnndm/candidate are two folders containing files. Each one of those files contain one summary
python cal_rouge.py --ref ./result/cnndm/reference --hyp ./result/cnndm/candidate -l -p Ниже приведены оценки Rouge, вычисленные по стандартному пакету Rouge Perl.
| Rouge-1 | Rouge-2 | Rouge-L | |
|---|---|---|---|
| БАРТ | 44,29 | 21.17 | 41.09 |
| Brio-Ctr | 47.28 | 22.93 | 44,15 |
| БИО-МУЛ | 47.78 | 23.55 | 44,57 |
| Brio-mul (sased) | 48.01 | 23.76 | 44,63 |
| Rouge-1 | Rouge-2 | Rouge-L | |
|---|---|---|---|
| Пегас | 47.46 | 24.69 | 39,53 |
| Brio-Ctr | 48.13 | 25.13 | 39,84 |
| БИО-МУЛ | 49,07 | 25.59 | 40.40 |
| Rouge-1 | Rouge-2 | Rouge-L | |
|---|---|---|---|
| БАРТ | 55,78 | 36.61 | 52,60 |
| Brio-Ctr | 55,98 | 36.54 | 52,51 |
| БИО-МУЛ | 57,75 | 38.64 | 54,54 |
Наши выходы модели на этих наборах данных можно найти в ./output .
Мы суммируем выходы и модель контрольно -пропускных пунктов ниже. Вы можете загрузить эти контрольные точки с помощью model.load_state_dict(torch.load(path_to_checkpoint)) .
| Контрольные точки | Выход модели | Справочный выход | |
|---|---|---|---|
| Cnndm | model_generation.bin model_ranking.bin | cnndm.test.ours.out | Cnndm.test.Reference |
| Cnndm (обложка) | model_generation.bin | cnndm.test.ours.cade.out | cnndm.test.cased.Reference |
| Xsum | model_generation.bin model_ranking.bin | xsum.test.ours.out | xsum.test.reference |
Вы можете загрузить наши обученные модели для поколения из трансформаторов HuggingFace. Наша модель контрольная точка на CNNDM ( Yale-LILY/brio-cnndm-uncased , Yale-LILY/brio-cnndm-cased , представляет собой стандартную модель BART (IE, BartForConditionAlgeneration), в то время как наша модель контрольная точка на XSUM ( Yale-LILY/brio-xsum-cased , основанная на стандартной модели Pegasus).
from transformers import BartTokenizer , PegasusTokenizer
from transformers import BartForConditionalGeneration , PegasusForConditionalGeneration
IS_CNNDM = True # whether to use CNNDM dataset or XSum dataset
LOWER = False
ARTICLE_TO_SUMMARIZE = "Manchester United superstar Cristiano Ronaldo scored his 806th career goal in Old Trafford,
breaking FIFA's all-time record for most goals in competitive matches in men's football history.
It was the second of three goals the Portuguese attacker scored during the game,
leading United to a 3-2 victory over Tottenham and finishing the day with 807 total career goals.
The previous FIFA goal record was held by Josef Bican, with 805 goals."
# Load our model checkpoints
if IS_CNNDM :
model = BartForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
tokenizer = BartTokenizer . from_pretrained ( 'Yale-LILY/brio-cnndm-uncased' )
else :
model = PegasusForConditionalGeneration . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
tokenizer = PegasusTokenizer . from_pretrained ( 'Yale-LILY/brio-xsum-cased' )
max_length = 1024 if IS_CNNDM else 512
# generation example
if LOWER :
article = ARTICLE_TO_SUMMARIZE . lower ()
else :
article = ARTICLE_TO_SUMMARIZE
inputs = tokenizer ([ article ], max_length = max_length , return_tensors = "pt" , truncation = True )
# Generate Summary
summary_ids = model . generate ( inputs [ "input_ids" ])
print ( tokenizer . batch_decode ( summary_ids , skip_special_tokens = True , clean_up_tokenization_spaces = False )[ 0 ]) Примечания : Наши контрольно -пропускные пункты на Huggingface не могут быть напрямую загружены в модель Pytorch ( BRIO ) в нашем коде, потому что наша модель Pytorch является оберткой на BART/Pegasus для повышения эффективности обучения. Тем не менее, вы можете использовать его, чтобы инициировать нашу модель Pytorch, например,
model = BRIO ( 'Yale-LILY/brio-cnndm-uncased' , tok . pad_token_id , is_pegasus = False )

