mlm scoring
1.0.0
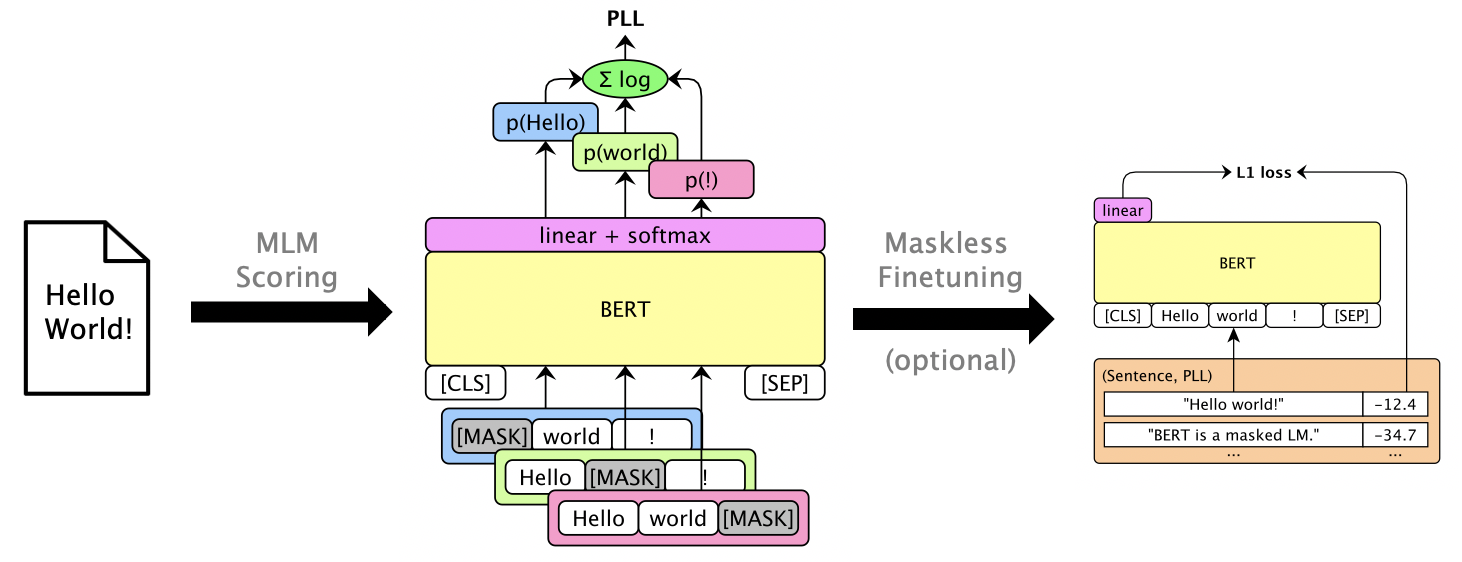
該軟件包使用Bert,Roberta和XLM等蒙版的LMS來評分句子,並通過偽log-likelihoods得分來恢復n-最佳列表,這些分數是通過掩蓋單個單詞來計算的。我們還支持GPT-2等自迴旋LMS。示例用途包括:
論文:朱利安·薩拉薩爾(Julian Salazar),戴維斯·林格(Davis Liang),托恩(Toan) “蒙版語言模型得分”,ACL 2020。
需要Python 3.6+。克隆此存儲庫並安裝:
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.有些模型通過Gluonnlp,而其他模型則通過?變壓器,因此現在我們需要MXNET和PYTORCH。您現在可以直接導入庫:
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](MXNET和PYTORCH界面將很快統一!)
運行mlm score --help以查看支持的模型等。請參閱examples/demo/format.json有關文件格式。對於輸入,“得分”是可選的。輸出將添加包含PLL分數的“得分”字段。
有三種分數類型,具體取決於模型:
--no-mask )我們使用bert base(未基於)在GPU 0上為librispeech dev-other的三種話進行了假設:
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json一個人可以通過對數線性插值來恢復N最佳列表。運行mlm rescore --help以查看所有選項。輸入一個是一個具有原始分數的文件;輸入兩個是mlm score的分數。
我們在不同的LM權重下使用BERT的得分(從上一節)恢復了聲學得分(從dev-other.am.json ):
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
done最初的wer為12.2%,而被奪回的WER為8.5%。
可以對LMS進行封裝,以提供可用的PLL分數而無需掩蓋。請參閱LibrisPeech無面膜登錄。
運行pip install -e .[dev]安裝額外的測試軟件包。然後:
pytest --cov=src/mlm 。

